Prelude
This is the second of four articles in a series that will provide insight into the mechanics and design of pointers, stacks, heaps, escape analysis, and Go / Value semantics. This post is about heaps and escape analysis.Table of Contents:- Language Mechanics On Stacks And Pointers ( translation )
- Language Mechanics On Escape Analysis
- Language Mechanics On Memory Profiling
- Design Philosophy On Data And Semantics
Introduction
In the first post in this series, I talked about the basics of pointer mechanics using an example in which the value is distributed across the stack between goroutines. I did not show you what happens when you split the value on the stack. To understand this, you need to find out about another area of memory where the values may be: about the “heap”. With this knowledge, you can begin to study “escape analysis”.Escape analysis is a process that the compiler uses to determine the placement of values created by your program. In particular, the compiler performs static code analysis to determine if the value can be placed on the stack frame for the function that builds it, or if the value should be "escaped" into the heap. There is not a single keyword or function in Go that you could use to tell the compiler which decision to make. Only the way you write your code conditionally allows you to influence this decision.Heaps
A heap is a second area of memory, in addition to the stack, used to store values. The heap is not self-cleaning like stacks, so using this memory is more expensive. First of all, the costs are associated with the garbage collector (GC), which should keep this area clean. When the GC starts, it will use 25% of your processor’s available power. In addition, it can potentially create microseconds of “stop the world” delays. The advantage of having a GC is that you don't have to worry about managing heap memory that has historically been complex and error prone.Values in the heap provoke memory allocations in Go. These allocations put pressure on the GC because every value in the heap that the pointer no longer refers to must be deleted. The more values you need to check and delete, the more work the GC must do at each start. Therefore, the stimulation algorithm is constantly working to balance heap size and execution speed.Stack sharing
In Go, no goroutines are allowed to have a pointer pointing to a memory on the stack of another goroutine. This is due to the fact that the stack memory for goroutines can be replaced with a new memory block, when the stack should increase or decrease. If at run time you had to track the stack pointers in another goroutine, you would have to manage too much, and the “stop the world” delay when updating pointers to these stacks would be staggering.Here is an example of a stack that is replaced several times due to growth. Look at the output in lines 2 and 6. You'll see twice the address changes of the string value inside the main stack frame.play.golang.org/p/pxn5u4EBSIEscape mechanics
Each time a value is shared outside the region of the stack frame of a function, it is placed (or allocated) in a heap. The task of escape analysis algorithms is to find such situations and maintain the integrity level in the program. Integrity is to ensure that access to any value is always accurate, consistent and efficient.Take a look at this example to learn the basic mechanisms of escape analysis.play.golang.org/p/Y_VZxYteKOListing 101 package main
02
03 type user struct {
04 name string
05 email string
06 }
07
08 func main() {
09 u1 := createUserV1()
10 u2 := createUserV2()
11
12 println("u1", &u1, "u2", &u2)
13 }
14
15
16 func createUserV1() user {
17 u := user{
18 name: "Bill",
19 email: "bill@ardanlabs.com",
20 }
21
22 println("V1", &u)
23 return u
24 }
25
26
27 func createUserV2() *user {
28 u := user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", &u)
34 return &u
35 }
I use the go: noinline directive so that the compiler does not embed code for these functions directly in main. Embedding will remove function calls and complicate this example. I will talk about the side effects of embedding in the next post.Listing 1 shows a program with two different functions that create a value of type user and return it back to the caller. The first version of the function uses the semantics of the value when returning.Listing 216 func createUserV1() user {
17 u := user{
18 name: "Bill",
19 email: "bill@ardanlabs.com",
20 }
21
22 println("V1", &u)
23 return u
24 }
I said that the function uses the semantics of values when returning, because a value of type user created by this function is copied and passed to the call stack. This means that the calling function receives a copy of the value itself.You can see the creation of a value of type user, executed on lines 17 through 20. Then, on line 23, a copy of the value is passed to the call stack and returned to the caller. After returning the function, the stack looks as follows.Image 1 In Figure 1, you can see that a value of type user exists in both frames after calling createUserV1. In the second version of the function, pointer semantics are used to return.Listing 3
In Figure 1, you can see that a value of type user exists in both frames after calling createUserV1. In the second version of the function, pointer semantics are used to return.Listing 327 func createUserV2() *user {
28 u := user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", &u)
34 return &u
35 }
I said that a function uses pointer semantics when returning, because a value of type user created by this function is shared by the call stack. This means that the calling function receives a copy of the address where the values are located.You can see the same structural literal that is used in lines 28 through 31 to create a value of type user, but on line 34 the return from the function is different. Instead of passing a copy of the value back to the call stack, a copy of the address for the value is passed. Based on this, you might think that after the call the stack looks like this.Image 2 If what you see in Figure 2 is really happening, you will have an integrity problem. A pointer points down to a stack of calls to memory that is no longer valid. The next time the function is called, the indicated memory will be reformatted and reinitialized.This is where escape analysis begins to maintain integrity. In this case, the compiler will determine that it is unsafe to create a value of type user inside the createUserV2 stack frame, so instead it will create a value on the heap. This will happen immediately during construction on line 28.
If what you see in Figure 2 is really happening, you will have an integrity problem. A pointer points down to a stack of calls to memory that is no longer valid. The next time the function is called, the indicated memory will be reformatted and reinitialized.This is where escape analysis begins to maintain integrity. In this case, the compiler will determine that it is unsafe to create a value of type user inside the createUserV2 stack frame, so instead it will create a value on the heap. This will happen immediately during construction on line 28.Readability
As you learned from a previous post, a function has direct access to memory inside its frame through the frame pointer, but access to memory outside the frame requires indirect access. This means that access to values that fall into the heap must also be done indirectly through a pointer.Remember what the createUserV2 code looks like.Listing 427 func createUserV2() *user {
28 u := user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", &u)
34 return &u
35 }
The syntax hides what really happens in this code. The variable u declared on line 28 represents a value of type user. The construction in Go does not tell you exactly where the value is stored in memory, so before the return statement on line 34 you do not know that the value will be heaped. This means that although u represents a value of type user, access to this value must be through a pointer.You can visualize a stack that looks like this after a function call.Image 3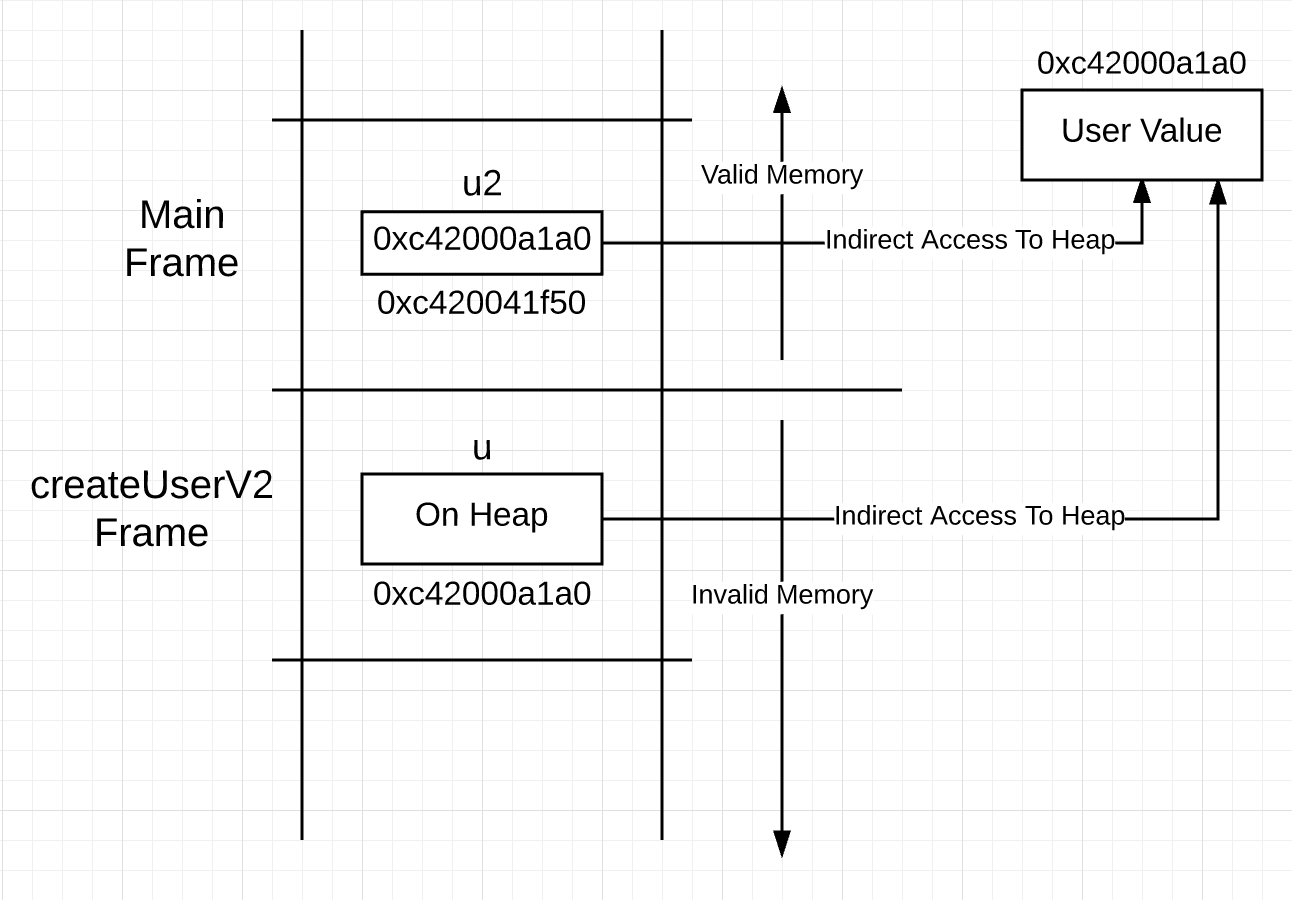 The u variable in the stack frame for createUserV2 represents the value on the heap, not on the stack. This means that using u to access a value requires access to a pointer, not the direct access suggested by the syntax. You might think, why not immediately make a pointer, since accessing the value that it represents still requires the use of a pointer?Listing 5
The u variable in the stack frame for createUserV2 represents the value on the heap, not on the stack. This means that using u to access a value requires access to a pointer, not the direct access suggested by the syntax. You might think, why not immediately make a pointer, since accessing the value that it represents still requires the use of a pointer?Listing 527 func createUserV2() *user {
28 u := &user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", u)
34 return u
35 }
If you do so, then you will lose readability, which you could not lose in your code. Move away from the function body for a second and just focus on return.Listing 634 return u
35 }
What is this return talking about? All he says is that a copy of u is pushed onto the call stack. In the meantime, what does return tell you when you use the & operator?Listing 734 return &u
35 }
Thanks to the & return operator, it now tells you that you are sharing the call stack and therefore go out into the heap. Remember that pointers are intended to be used together and while reading the code they replace the & operator with the phrase “sharing”. It is very powerful in terms of readability. This is something that I would not want to lose.Here is another example where constructing values using pointer semantics degrades readability.Listing 801 var u *user
02 err := json.Unmarshal([]byte(r), &u)
03 return u, err
In order for this code to work, when you call json.Unmarshal on line 02, you must pass a pointer to a pointer variable. A json.Unmarshal call will create a value of type user and assign its address to a pointer variable. play.golang.org/p/koI8EjpeIxWhat this code says:01: Create a pointer of type user with a null value.02: Share u variable with json.Unmarshal function.03: Return a copy of the variable u to the caller.It is not entirely obvious that a value of type user created by the json.Unmarshal function is passed to the caller.How does readability change when using semantics of values during variable declaration?Listing 901 var u user
02 err := json.Unmarshal([]byte(r), &u)
03 return &u, err
What this code says:01: Create a value of type user with a null value.02: Share u variable with json.Unmarshal function.03: Share the variable u with the caller.Everything is very clear. Line 02 splits the value of type user down the call stack in json.Unmarshal, and line 03 splits the value of the stack of calls back to the caller. This share will cause the value to move to the heap.Use the semantics of values when creating values and take advantage of the readability of the & operator to clarify how values are separated.Compiler reporting
To see the decisions made by the compiler, you can ask the compiler to provide a report. All you have to do is use the -gcflags switch with the -m option when calling go build.In fact, you can use 4 levels of -m, but after 2 levels of information it becomes too much. I will use 2 levels -m.Listing 10$ go build -gcflags "-m -m"
./main.go:16: cannot inline createUserV1: marked go:noinline
./main.go:27: cannot inline createUserV2: marked go:noinline
./main.go:8: cannot inline main: non-leaf function
./main.go:22: createUserV1 &u does not escape
./main.go:34: &u escapes to heap
./main.go:34: from ~r0 (return) at ./main.go:34
./main.go:31: moved to heap: u
./main.go:33: createUserV2 &u does not escape
./main.go:12: main &u1 does not escape
./main.go:12: main &u2 does not escape
You can see that the compiler is reporting decisions to dump the value into the heap. What does the compiler say? First, look again at the createUserV1 and createUserV2 functions to refresh them in memory.Listing 1316 func createUserV1() user {
17 u := user{
18 name: "Bill",
19 email: "bill@ardanlabs.com",
20 }
21
22 println("V1", &u)
23 return u
24 }
27 func createUserV2() *user {
28 u := user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", &u)
34 return &u
35 }
Let's start with this line in the report.Listing 14./main.go:22: createUserV1 &u does not escape
This suggests that the call to the println function inside the createUserV1 function does not cause the user type to be dumped into the heap. This case had to be checked because it is used in conjunction with the println function.Next, look at these lines in the report.Listing 15./main.go:34: &u escapes to heap
./main.go:34: from ~r0 (return) at ./main.go:34
./main.go:31: moved to heap: u
./main.go:33: createUserV2 &u does not escape
These lines say that the value of the user type associated with the variable u, which has the named user type and is created on line 31, is dumped into the heap due to the return on line 34. The last line says the same as before, println call on the line 33 does not reset the user type.Reading these reports can be confusing and may vary slightly depending on whether the type of the variable in question is based on a named or literal type.Modify the u variable to be the literal type * user instead of the named type user, as it was before.Listing 1627 func createUserV2() *user {
28 u := &user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", u)
34 return u
35 }
Run the report again.Listing 17./main.go:30: &user literal escapes to heap
./main.go:30: from u (assigned) at ./main.go:28
./main.go:30: from ~r0 (return) at ./main.go:34
Now the report says that the value of the user type referenced by the variable u, which has the literal type * user and created on line 28, is dumped into the heap due to the return on line 34.Conclusion
Creating a value does not determine where it is located. Only how the value is split will determine what the compiler will do with this value. Each time you share a value in the call stack, it is dumped into the heap. There are other reasons why a value might escape from the stack. I will talk about them in the next post.The purpose of these posts is to provide guidance on choosing to use value semantics or pointer semantics for any given type. Each semantics is paired with profit and value. The semantics of the values store the values on the stack, which reduces the load on the GC. However, there are different copies of the same value that must be stored, tracked and maintained. Pointer semantics puts values in a heap, which can put pressure on the GC. However, they are effective because there is only one value that needs to be stored, tracked and maintained. The key point is the use of each semantics correctly, consistently and balanced.