A few weeks ago in a conversation over dinner, a colleague complained about some kind of slow process. He calculated the number of bytes generated, the number of processing cycles, and ultimately, the amount of RAM. A colleague said that a modern GPU with a memory bandwidth of more than 500 GB / s would eat up its task and not choke.It seemed to me that this is an interesting approach. Personally, I have not previously evaluated performance objectives from this perspective. Yes, I know about the difference in processor and memory performance. I know how to write code that makes heavy use of the cache. I know the approximate delay figures. But this is not enough to immediately assess the memory bandwidth.Here is a thought experiment. Imagine in memory a continuous array of a billion 32-bit integers. This is 4 gigabytes. How long will it take to iterate over this array and add up the values? How many bytes per second can the CPU read from RAM? Continuous data? Random access? How well can this process be parallelized?You will say that these are useless questions. Real programs are too complex to make such a naive landmark. And there is! The real answer is “depending on the situation.”However, I think this issue is worth exploring. I am not trying to find the answer . But I think that we can define some upper and lower boundaries, some interesting points in the middle and learn something in the process.
I know how to write code that makes heavy use of the cache. I know the approximate delay figures. But this is not enough to immediately assess the memory bandwidth.Here is a thought experiment. Imagine in memory a continuous array of a billion 32-bit integers. This is 4 gigabytes. How long will it take to iterate over this array and add up the values? How many bytes per second can the CPU read from RAM? Continuous data? Random access? How well can this process be parallelized?You will say that these are useless questions. Real programs are too complex to make such a naive landmark. And there is! The real answer is “depending on the situation.”However, I think this issue is worth exploring. I am not trying to find the answer . But I think that we can define some upper and lower boundaries, some interesting points in the middle and learn something in the process.The numbers every programmer should know
If you read programming blogs, you probably came across "numbers that every programmer should know." They look something like this:Link to L1 cache 0.5 ns
Incorrect 5 ns prediction
Link to L2 cache 7 ns 14x to L1 cache
Mutex Capture / Release 25 ns
Link to main memory 100 ns 20x to L2 cache, 200x to L1 cache
Compress 1000 bytes with Zippy 3000 ns 3 μs
Sending 1000 bytes over a 1 Gbps network 10,000 ns 10 μs
Random Read 4000 with SSD 150,000 ns 150 μs ~ 1GB / s SSD
Read 1 MB sequentially from 250,000 ns 250 μs
Round-trip packet inside the data center 500,000 ns 500 μs
1 MB sequential read in SSD 1,000,000 ns 1,000 μs 1 ms ~ 1 GB / s SSD, 4x memory
Disk search 10,000,000 ns 10,000 μs 10 ms 20x to data center
Read 1 MB sequentially from disk 20,000,000 ns 20,000 μs 20 ms 80x to memory, 20x to SSD
Package Sending CA-> Netherlands-> CA 150,000,000 ns 150,000 μs 150 ms
Source: Jonas BonerGreat list. He pops up on HackerNews at least once a year. Every programmer should know these numbers.But these numbers are about something else. Latency and bandwidth are not the same thing.Delay in 2020
That list was compiled in 2012, and this article of 2020, times have changed. Here are the numbers for Intel i7 with StackOverflow .Hit in L1 cache, ~ 4 cycles (2.1 - 1.2 ns)
Hit in the L2 cache, ~ 10 cycles (5.3 - 3.0 ns)
Hit in the L3 cache, for a single core ~ 40 cycles (21.4 - 12.0 ns)
Hit in L3 cache, together for another kernel ~ 65 cycles (34.8 - 19.5 ns)
Hit the L3 cache, with a change for another kernel ~ 75 cycles (40.2 - 22.5 ns)
Local RAM ~ 60 ns
Interesting! What changed?- L1 has become slower;
0,5 → 1,5
- L2 faster;
7 → 4,2
- The ratio of L1 and L2 is much reduced;
2,5x 14(wow!)
- L3 cache has now become the standard;
12 40
- RAM has become faster;
100 → 60
We will not draw far-reaching conclusions. It is unclear how the original numbers were calculated. We will not compare apples with oranges.Here are some figures from wikichip on the bandwidth and cache size of my processor.Memory Bandwidth: 39.74 Gigabytes per second
L1 cache: 192 kilobytes (32 KB per core)
L2 Cache: 1.5 megabytes (256 KB per core)
L3 Cache: 12 megabytes (shared; 2 MB per core)
What I want to know:- RAM performance upper limit
- lower limit
- L1 / L2 / L3 Cache Limits
Naive benchmarking
Let's do some tests. To measure bandwidth, I wrote a simple C ++ program. Very approximately she looks like this.
std::vector<int> nums;
for (size_t i = 0; i < 1024*1024*1024; ++i)
nums.push_back(rng() % 1024);
for (int thread_count = 1; thread_count <= MAX_THREADS; ++thread_count) {
auto slice_len = nums.size() / thread_count;
for (size_t thread = 0; thread < thread_count; ++thread) {
auto begin = nums.begin() + thread * slice_len;
auto end = (thread == thread_count - 1)
? nums.end() : begin + slice_len;
futures.push_back(std::async([begin, end] {
int64_t sum = 0;
for (auto ptr = begin; ptr < end; ++ptr)
sum += *ptr;
return sum;
}));
}
int64_t sum = 0;
for (auto& future : futures)
sum += future.get();
}
Some details are omitted. But you understood the idea. Create a large, continuous array of elements. Divide the array into separate fragments. Process each fragment in a separate thread. Accumulate results.You also need to measure random access. It is very difficult. I tried several ways, eventually decided to mix pre-computed indexes. Each index exists exactly once. Then the inner loop iterates over the indices and computes sum += nums[index].std::vector<int> nums = ;
std::vector<uint32_t> indices = ;
int64_t sum = 0;
for (auto ptr = indices.begin(); ptr < indices.end(); ++ptr) {
auto idx = *ptr;
sum += nums[idx];
}
return sum;
In calculating the throughput, I do not consider the memory of the index array. Only bytes that contribute to the total are counted sum. I do not benchmark my hardware, but assess the ability to work with data sets of different sizes and with different access schemes.We will carry out tests with three data types:int- the main 32-bit integermatri4x4- contains int[16]; fits in a 64-byte cache linematrix4x4_simd- uses built-in tools__m256iBig block
My first test works with a large block of memory. A 1 GB block of Nitems is highlighted and filled with small random values. A simple loop iterates over an array N times, so it accesses the memory in volume N to calculate the sum int64_t. Several threads split the array, and each gets access to the same number of elements.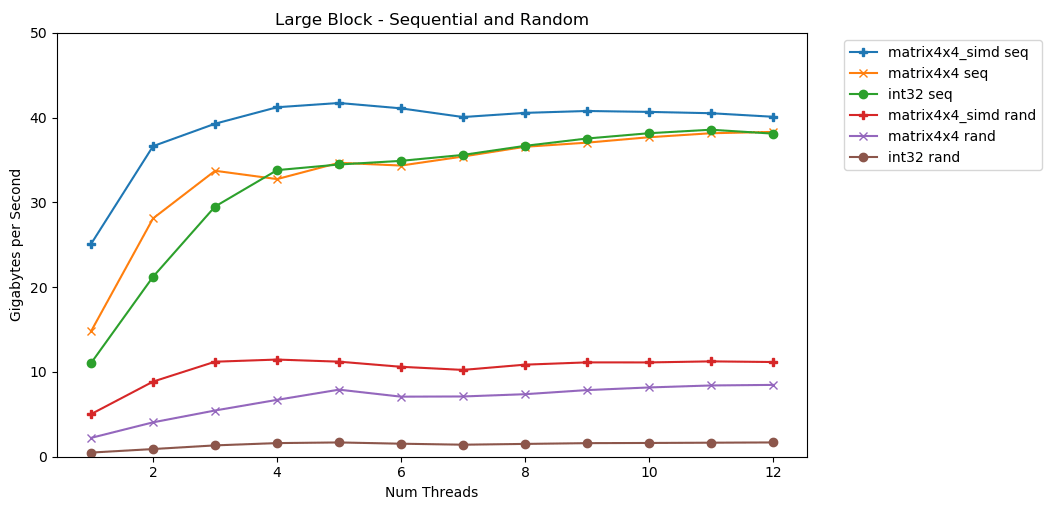 TA-dah! In this graph, we take the average execution time of the summation operation and convert it from
TA-dah! In this graph, we take the average execution time of the summation operation and convert it from runtime_in_nanosecondsto gigabytes_per_second.Pretty good result. int32can sequentially read 11 GB / s in a single stream. It scales linearly until it reaches 38 GB / s. Tests matrix4x4and matrix4x4_simdfaster, but rest against the same ceiling.There is a clear and obvious ceiling on how much data we can read from RAM per second. On my system, this is approximately 40 GB / s. This complies with current specifications listed above.Judging by the bottom three graphs, random access is slow. Very, very slow. Single-threaded performance int32is a negligible 0.46 GB / s. This is 24 times slower than sequential stacking at 11.03 GB / s! The test matrix4x4shows the best result, because it runs on full cache lines. But it is still four to seven times slower than sequential access, and peaks at only 8 GB / s.Small block: sequential read
On my system, the L1 / L2 / L3 cache size for each stream is 32 KB, 256 KB, and 2 MB. What happens if you take a 32-kilobyte block of elements and iterate over it 125,000 times? This is 4 GB of memory, but we will always go to the cache.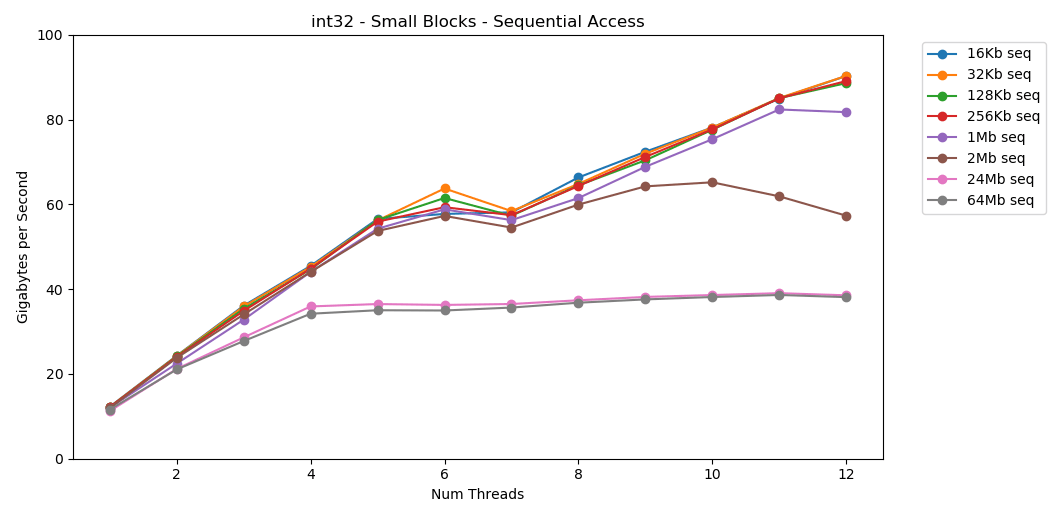 Awesome! Single-threaded performance is similar to reading a large block, about 12 GB / s. Except that this time, multithreading breaks through the 40 GB / s ceiling. It makes sense. The data remains in the cache, so the RAM bottleneck does not appear. For data that did not fit in the L3 cache, the same ceiling of about 38 GB / s applies.The test
Awesome! Single-threaded performance is similar to reading a large block, about 12 GB / s. Except that this time, multithreading breaks through the 40 GB / s ceiling. It makes sense. The data remains in the cache, so the RAM bottleneck does not appear. For data that did not fit in the L3 cache, the same ceiling of about 38 GB / s applies.The test matrix4x4shows similar results to the circuit, but even faster; 31 GB / s in single-threaded mode, 171 GB / s in multi-threaded.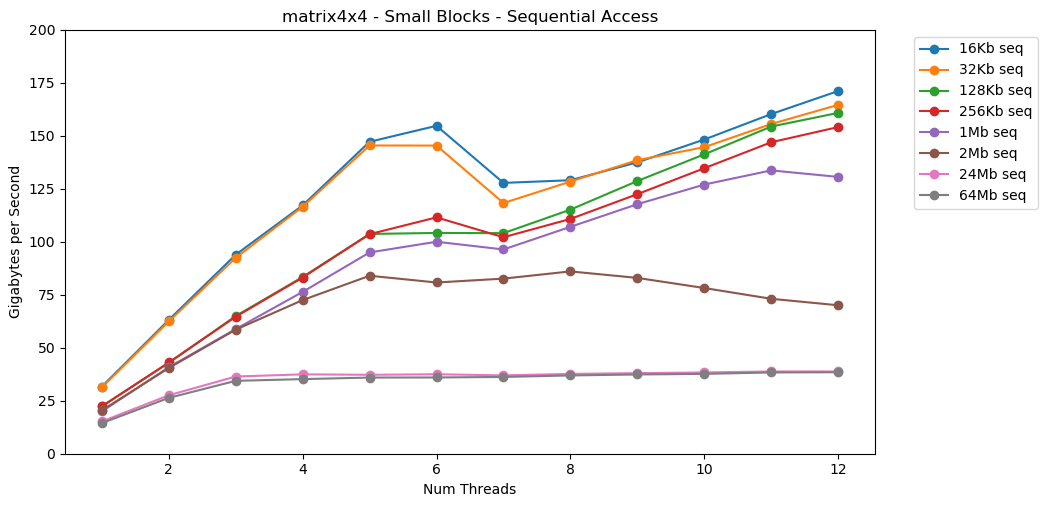 Now let's look at
Now let's look at matrix4x4_simd. Pay attention to the y axis.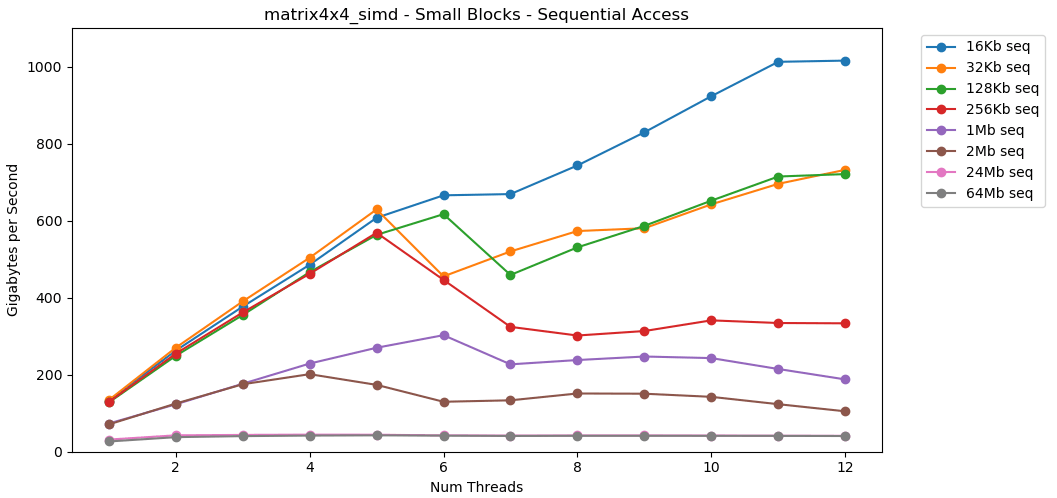
matrix4x4_simdperformed exceptionally fast. It is 10 times faster than int32. On a 16 KB block, it even breaks through 1000 GB / s!Obviously, this is a surface synthetic test. Most applications do not perform the same operation with the same data a million times in a row. The test does not show performance in the real world.But the lesson is clear. Inside the cache, data is processed quickly . With a very high ceiling when using SIMD: more than 100 GB / s in single-threaded mode, more than 1000 GB / s in multi-threaded. Writing data to the cache is slow and with a hard limit of about 40 GB / s.Small block: random read
Let's do the same, but now with random access. This is my favorite part of the article.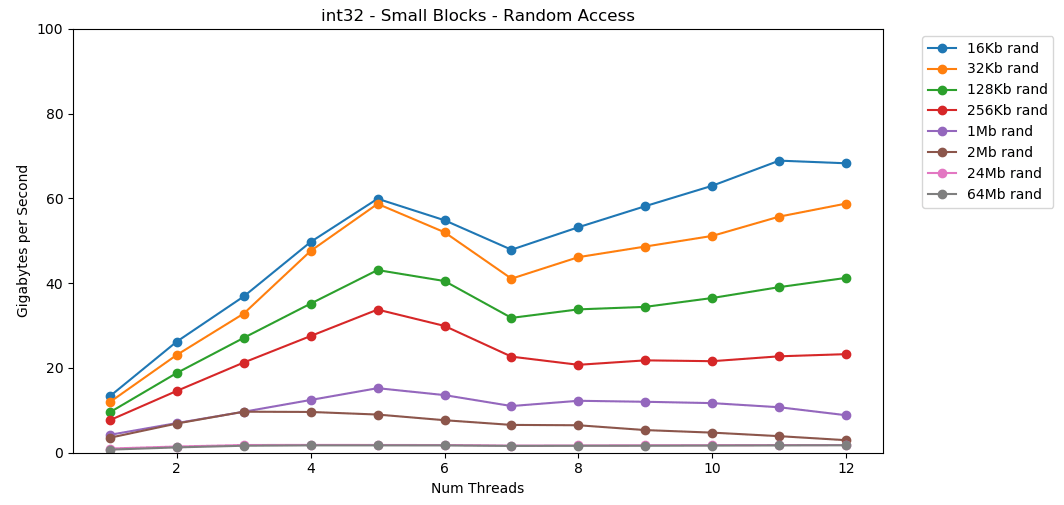 Reading random values from RAM is slow, only 0.46 GB / s. Reading random values from the L1 cache is very fast: 13 GB / s. This is faster than reading serial data
Reading random values from RAM is slow, only 0.46 GB / s. Reading random values from the L1 cache is very fast: 13 GB / s. This is faster than reading serial data int32from RAM (11 GB / s).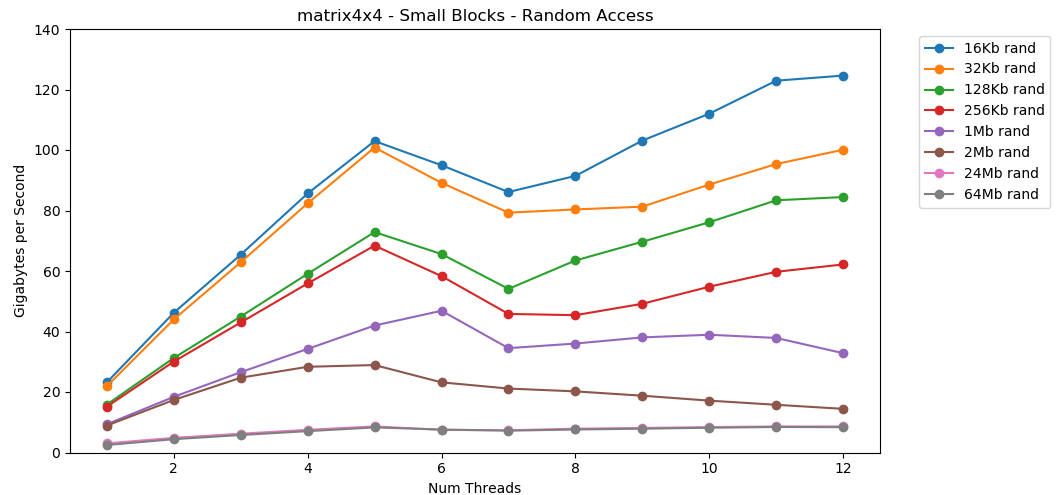 The test
The test matrix4x4shows a similar result for the same template, but about twice as fast as int.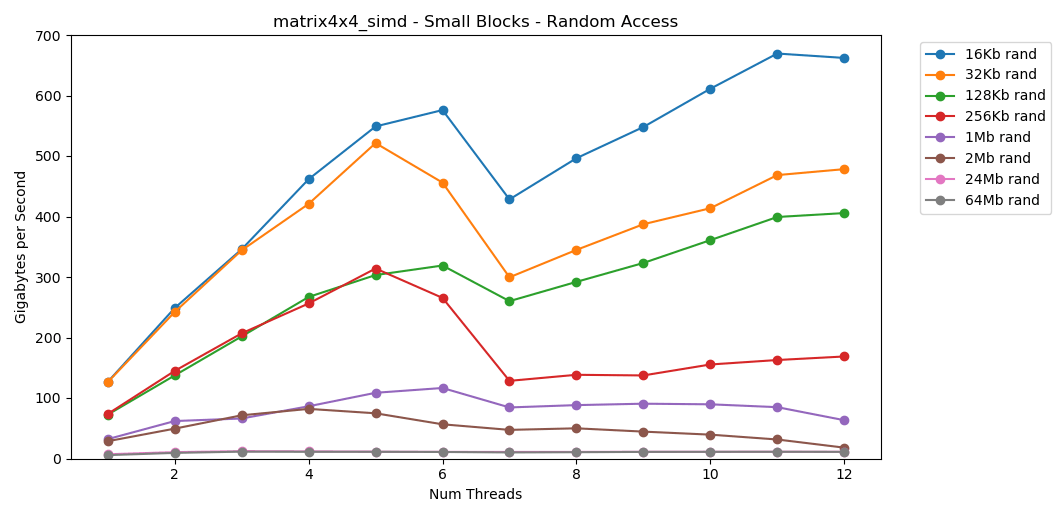 Random access is
Random access is matrix4x4_simdinsanely fast.Random Access Findings
Free reading from memory is slow. Catastrophically slow. Less than 1 GB / s for both test cases int32. At the same time, random reads from the cache are surprisingly fast. It is comparable to sequential reading from RAM.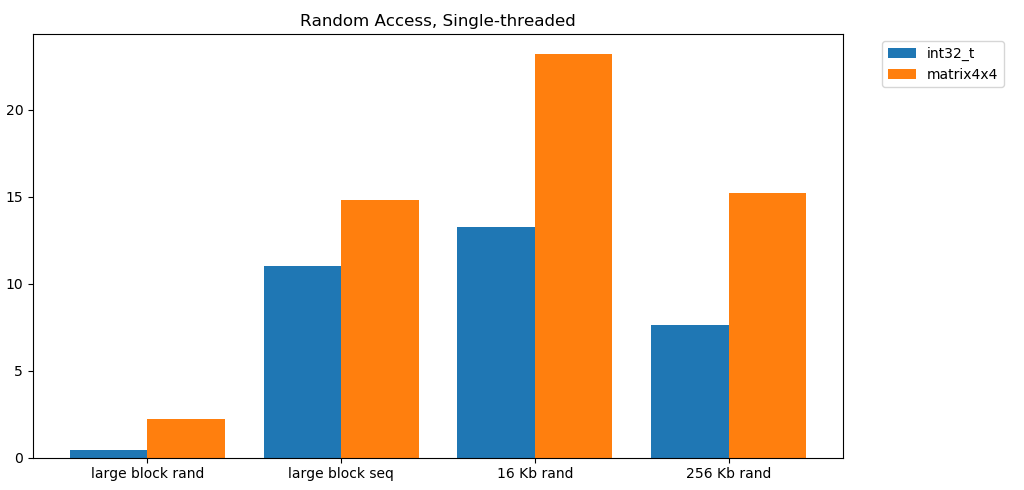 It needs to be digested. Random access to the cache is comparable in speed to sequential access to RAM. The drop from L1 16 KB to L2 256 KB is only half or less.I think that this will have profound consequences.
It needs to be digested. Random access to the cache is comparable in speed to sequential access to RAM. The drop from L1 16 KB to L2 256 KB is only half or less.I think that this will have profound consequences.Linked lists are considered harmful
Chasing a pointer (jumping on pointers) is bad. Very very bad. How much is performance decreasing? See for yourself. I did an extra test that wraps matrix4x4in std::unique_ptr. Each access goes through a pointer. Here is a terrible, just catastrophic result. 1 thread | matrix4x4 | unique_ptr | diff |
-------------------- | --------------- | ------------ | -------- |
Large Block - Seq | 14.8 GB / s | 0.8 GB / s | 19x |
16 KB - Seq | 31.6 GB / s | 2.2 GB / s | 14x |
256 KB - Seq | 22.2 GB / s | 1.9 GB / s | 12x |
Large Block - Rand | 2.2 GB / s | 0.1 GB / s | 22x |
16 KB - Rand | 23.2 GB / s | 1.7 GB / s | 14x |
256 KB - Rand | 15.2 GB / s | 0.8 GB / s | 19x |
6 threads | matrix4x4 | unique_ptr | diff |
-------------------- | --------------- | ------------ | -------- |
Large Block - Seq | 34.4 GB / s | 2.5 GB / s | 14x |
16 KB - Seq | 154.8 GB / s | 8.0 GB / s | 19x |
256 KB - Seq | 111.6 GB / s | 5.7 GB / s | 20x |
Large Block - Rand | 7.1 GB / s | 0.4 GB / s | 18x |
16 KB - Rand | 95.0 GB / s | 7.8 GB / s | 12x |
256 KB - Rand | 58.3 GB / s | 1.6 GB / s | 36x |The sequential summation of values behind the pointer is performed at a speed of less than 1 GB / s The double-skipped random access speed of the cache is only 0.1 GB / s.Chasing a pointer slows down code execution 10-20 times. Do not let your friends use linked lists. Please think about the cache.Budget Estimation for Frames
It is common for game developers to set a limit (budget) for the load on the CPU and memory. But I have never seen a bandwidth budget.In modern games, FPS continues to grow. Now it is at 60 FPS. VR operates at a frequency of 90 Hz. I have a 144 Hz gaming monitor. It's awesome, so the 60 FPS seems like shit. I will never return to the old monitor. Esports and streamers Twitch monitors 240 Hz. This year, Asus introduced a 360 Hz monster at CES.My processor has an upper limit of about 40 GB / s. That seems like a big number! However, at a frequency of 240 Hz, only 167 MB per frame is obtained. A realistic application can generate 5 GB / s traffic at 144 Hz, which is only 69 MB per frame.Here is a table with a few numbers. | 1 | 10 | 30 | 60 | 90 | 144 | 240 | 360 |
-------- | ------- | -------- | -------- | -------- | ------ - | -------- | -------- | -------- |
40 GB / s | 40 GB | 4 GB | 1.3 GB | 667 MB | 444 MB | 278 MB | 167 MB | 111 MB |
10 GB / s | 10 GB | 1 GB | 333 MB | 166 MB | 111 MB | 69 MB | 42 MB | 28 MB |
1 GB / s | 1 GB | 100 MB | 33 MB | 17 MB | 11 MB | 7 MB | 4 MB | 3 MB |
It seems to me that it is useful to assess problems from this perspective. This makes it clear that some ideas are not feasible. Reaching 240 Hz is not easy. This will not happen by itself.The numbers every programmer should know (2020)
The previous list is out of date. Now it needs to be updated and brought into compliance by 2020.Here are a few numbers for my home computer. This is a mixture of AIDA64, Sandra and my benchmarks. The figures do not give a complete picture and are only a starting point.Latency L1: 1 ns
L2 Delay: 2.5 ns
Delay L3: 10 ns
RAM Latency: 50 ns
(per thread)
L1 band: 210 GB / s
L2 band: 80 GB / s
L3 Band: 60 GB / s
(whole system)
RAM band: 45 GB / s
It would be nice to create a small, simple open source benchmark. Some C file that can be run on desktop computers, servers, mobile devices, consoles, etc. But I'm not the kind of person who writes such a tool.Denial of responsibility
Measuring memory bandwidth is difficult. Very difficult. There are probably errors in my code. Many unaccounted factors. If you have some criticism for my technique, you are probably right.Ultimately, I think this is normal. This article is not about the exact performance of my desktop. This is a problem statement from a certain point of view. And about how to learn how to do some rough mathematical calculations.Conclusion
A colleague shared an interesting opinion with me about GPU memory bandwidth and application performance. This prompted me to study the memory performance on modern computers.For approximate calculations, here are some numbers for a modern desktop:- RAM performance
- Maximum:
45 / - On average, approximately:
5 / - Minimum:
1 /
- L1 / L2 / L3 Cache Performance (per core)
- Maximum (c simd):
210 // 80 //60 / - On average, approximately:
25 // 15 //9 / - Minimum:
13 // 8 //3,5 /
Sample ratings are related to performance matrix4x4. Real code will never be so simple. But for calculations on a napkin, this is a reasonable starting point. You need to adjust this figure based on the memory access patterns in your program, the characteristics of your equipment and code.However, the most important thing is a new way to think about problems. Presenting the problem in bytes per second or bytes per frame is another lens to look through. This is a useful tool just in case.Thanks for reading.Source
Benchmark C ++Python Graphdata.jsonFurther research
This article only slightly touched on the topic. I probably won’t go into it. But if he did, then he could cover some of the following aspects:System specifications
Tests were conducted on my home PC. Only stock settings, no overclocking.- OS: Windows 10 v1903 build 18362
- CPU: Intel i7-8700k @ 3.70 GHz
- RAM: 2x16 GSkill Ripjaw DDR4-3200 (16-18-18-38 @ 1600 MHz)
- Motherboard: Asus TUF Z370-Plus Gaming