NiFi越来越受欢迎,每发布一个新版本,NiFi就会提供越来越多的数据处理工具。但是,可能有必要拥有自己的工具来解决特定问题。
Apache Nifi的基本软件包中包含300多个处理器。Nifi处理器 它是在NiFi生态系统中创建数据流的主要构建块。处理器提供了一个接口,NiFi通过该接口可以访问流文件,其属性和内容。自己的定制处理器将节省能源,时间和用户注意力,因为在界面中只显示一个,而不会执行很多简单的处理器元素,而只执行一个(好,或者您写了多少)。像标准处理器一样,自定义处理器允许您执行各种操作并处理流文件的内容。今天,我们将讨论扩展功能的标准工具。
它是在NiFi生态系统中创建数据流的主要构建块。处理器提供了一个接口,NiFi通过该接口可以访问流文件,其属性和内容。自己的定制处理器将节省能源,时间和用户注意力,因为在界面中只显示一个,而不会执行很多简单的处理器元素,而只执行一个(好,或者您写了多少)。像标准处理器一样,自定义处理器允许您执行各种操作并处理流文件的内容。今天,我们将讨论扩展功能的标准工具。执行脚本
ExecuteScript是一种通用处理器,旨在以编程语言(Groovy,Jython,Javascript,JRuby)实现业务逻辑。这种方法使您可以快速获得所需的功能。要提供对脚本中NiFi组件的访问,可以使用以下变量:Session:类型为org.apache.nifi.processor.ProcessSession的变量。该变量允许您对流文件执行操作,例如create(),putAttribute()和Transfer()以及read()和write()。上下文:org.apache.nifi.processor.ProcessContext。它可用于获取处理器属性,关系,控制器服务和StateManager。REL_SUCCESS:关系“成功”。REL_FAILURE:失败关系动态属性:在ExecuteScript中定义的动态属性作为变量传递到脚本引擎,并设置为PropertyValue。这使您可以获取属性的值,将值转换为适当的数据类型,例如逻辑等。要使用,只需使用我们的脚本或脚本本身选择Script Engine并指定文件的位置。
让我们看几个示例:
从队列中获取一个流文件Script File Script Body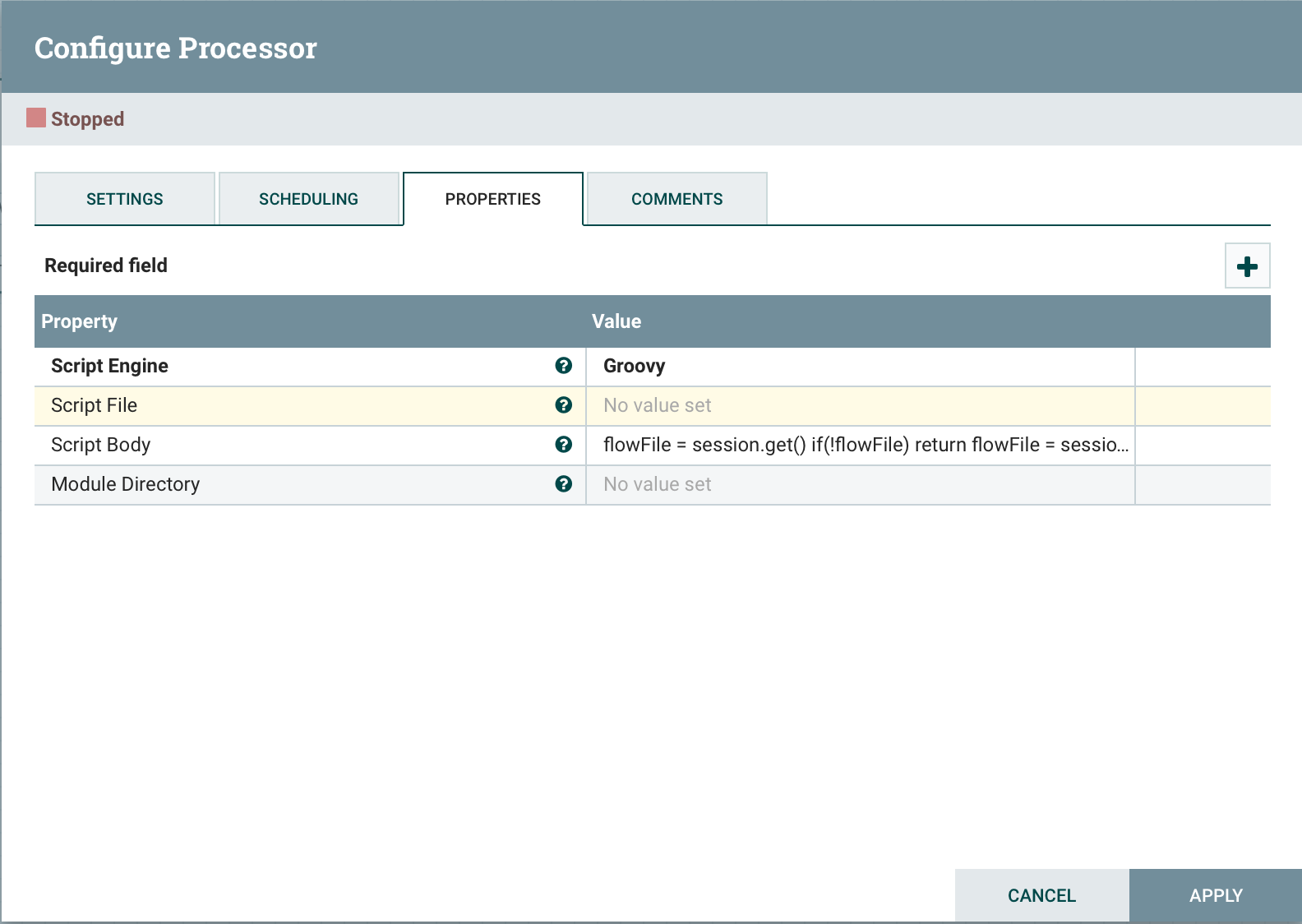
flowFile = session.get()
if(!flowFile) return
生成一个新的FlowFileflowFile = session.create()
// Additional processing here
将属性添加到FlowFileflowFile = session.get()
if(!flowFile) return
flowFile = session.putAttribute(flowFile, 'myAttr', 'myValue')
提取并处理所有属性。flowFile = session.get() if(!flowFile) return
flowFile.getAttributes().each { key,value ->
// Do something with the key/value pair
}
记录仪log.info('Found these things: {} {} {}', ['Hello',1,true] as Object[])
您可以在ExecuteScript中使用高级功能,有关更多信息,请参见ExecuteScript Cookbook。ExecuteGroovyScript
ExecuteGroovyScript具有与ExecuteScript相同的功能,但是您不能只使用一种-groovy,而不能使用有效语言的动物园。该处理器的主要优点是可以更方便地使用服务服务。除了标准的变量集Session,Context等。您可以使用CTL和SQL前缀定义动态属性。从1.11版开始,出现了对RecordReader和Record Writer的支持。所有属性都是HashMap,它使用“服务名称”作为键,并且值是取决于属性的特定对象:RecordWriter HashMap<String,RecordSetWriterFactory>
RecordReader HashMap<String,RecordReaderFactory>
SQL HashMap<String,groovy.sql.Sql>
CTL HashMap<String,ControllerService>
这些信息已经使生活更加轻松。我们可以查看源代码或查找特定类的文档。使用数据库如果定义SQL.DB属性并绑定DBCPService,则将从代码中访问该属性,SQL.DB.rows('select * from table') 处理器将在执行并处理事务之前自动接受dbcp服务的连接。当发生错误时,数据库事务将自动回滚;如果成功,则将提交数据库事务。在ExecuteGroovyScript中,您可以通过实现适当的静态方法来拦截启动和停止事件。
处理器将在执行并处理事务之前自动接受dbcp服务的连接。当发生错误时,数据库事务将自动回滚;如果成功,则将提交数据库事务。在ExecuteGroovyScript中,您可以通过实现适当的静态方法来拦截启动和停止事件。import org.apache.nifi.processor.ProcessContext
...
static onStart(ProcessContext context){
// your code
}
static onStop(ProcessContext context){
// your code
}
REL_SUCCESS << flowFile
InvokeScriptedProcessor
另一个有趣的处理器。要使用它,您需要声明一个实现Implements接口的类并定义一个处理器变量。您可以定义任何PropertyDescriptor或Relationship,还可以访问父ComponentLog并定义方法void onScheduled(ProcessContext上下文)和void onStopped(ProcessContext上下文)。在NiFi中发生预定的开始事件(onScheduled)时和停止时(onScheduled),将调用这些方法。class GroovyProcessor implements Processor {
@Override
void initialize(ProcessorInitializationContext context) { log = context.getLogger()
}
@Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) thr
@Override
Collection<ValidationResult> validate(ValidationContext context) { return null
@Override
PropertyDescriptor getPropertyDescriptor(String name) { return null }
@Override
void onPropertyModified(PropertyDescriptor descriptor, String oldValue, String n
@Override
List<PropertyDescriptor> getPropertyDescriptors() { return null }
@Override
String getIdentifier() { return null }
}
方法中必须实现逻辑 void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) @Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) throw s ProcessException {
final ProcessSession session = sessionFactory.createSession(); def
flowFile = session.create()
if (!flowFile) return
// your code
try
{ session.commit();
} catch (final Throwable t) {
session.rollback(true);
throw t;
}
}
不必描述接口中声明的所有方法,因此让我们绕过一个抽象类,在其中声明以下方法:abstract void executeScript(ProcessContext context, ProcessSession session)
我们将调用的方法void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory)
import org.apache.nifi.components.PropertyDescriptor import org.apache.nifi.components.ValidationContext import org.apache.nifi.components.ValidationResult import org.apache.nifi.logging.ComponentLog
import org.apache.nifi.processor.ProcessContext import org.apache.nifi.processor.ProcessSession
import org.apache.nifi.processor.ProcessSessionFactory import org.apache.nifi.processor.Processor
import org.apache.nifi.processor.ProcessorInitializationContext import org.apache.nifi.processor.Relationship
import org.apache.nifi.processor.exception.ProcessException
abstract class BaseGroovyProcessor implements Processor {
public ComponentLog log
public Set<Relationship> relationships;
@Override
void initialize(ProcessorInitializationContext context) { log = context.getLogger()
}
@Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) thr final ProcessSession session = sessionFactory.createSession();
try {
executeScript(context, session);
session.commit();
} catch (final Throwable t) {
session.rollback(true);
throw t;
}
}
abstract void executeScript(ProcessContext context, ProcessSession session) thro
@Override
Collection<ValidationResult> validate(ValidationContext context) { return null }
@Override
PropertyDescriptor getPropertyDescriptor(String name) { return null }
@Override
void onPropertyModified(PropertyDescriptor descriptor, String oldValue, String n
@Override
List<PropertyDescriptor> getPropertyDescriptors() { return null }
@Override
String getIdentifier() { return null }
}
现在,我们声明一个后继类BaseGroovyProcessor并描述我们的executeScript,还添加了Relationship RELSUCCESS和RELFAILURE。import org.apache.commons.lang3.tuple.Pair
import org.apache.nifi.expression.ExpressionLanguageScope import org.apache.nifi.processor.util.StandardValidators import ru.rt.nifi.common.BaseGroovyProcessor
import org.apache.nifi.components.PropertyDescriptor import org.apache.nifi.dbcp.DBCPService
import org.apache.nifi.processor.ProcessContext import org.apache.nifi.processor.ProcessSession
import org.apache.nifi.processor.exception.ProcessException import org.quartz.CronExpression
import java.sql.Connection
import java.sql.PreparedStatement import java.sql.ResultSet
import java.sql.SQLException import java.sql.Statement
class InvokeScripted extends BaseGroovyProcessor {
public static final REL_SUCCESS = new Relationship.Builder()
.name("success")
.description("If the cache was successfully communicated with it will be rou
.build()
public static final REL_FAILURE = new Relationship.Builder()
.name("failure")
.description("If unable to communicate with the cache or if the cache entry
.build()
@Override
void executeScript(ProcessContext context, ProcessSession session) throws Proces def flowFile = session.create()
if (!flowFile) return
try {
// your code
session.transfer(flowFile, REL_SUCCESS)
} catch(ProcessException | SQLException e) {
session.transfer(flowFile, REL_FAILURE)
log.error("Unable to execute SQL select query {} due to {}. No FlowFile
}
}
}
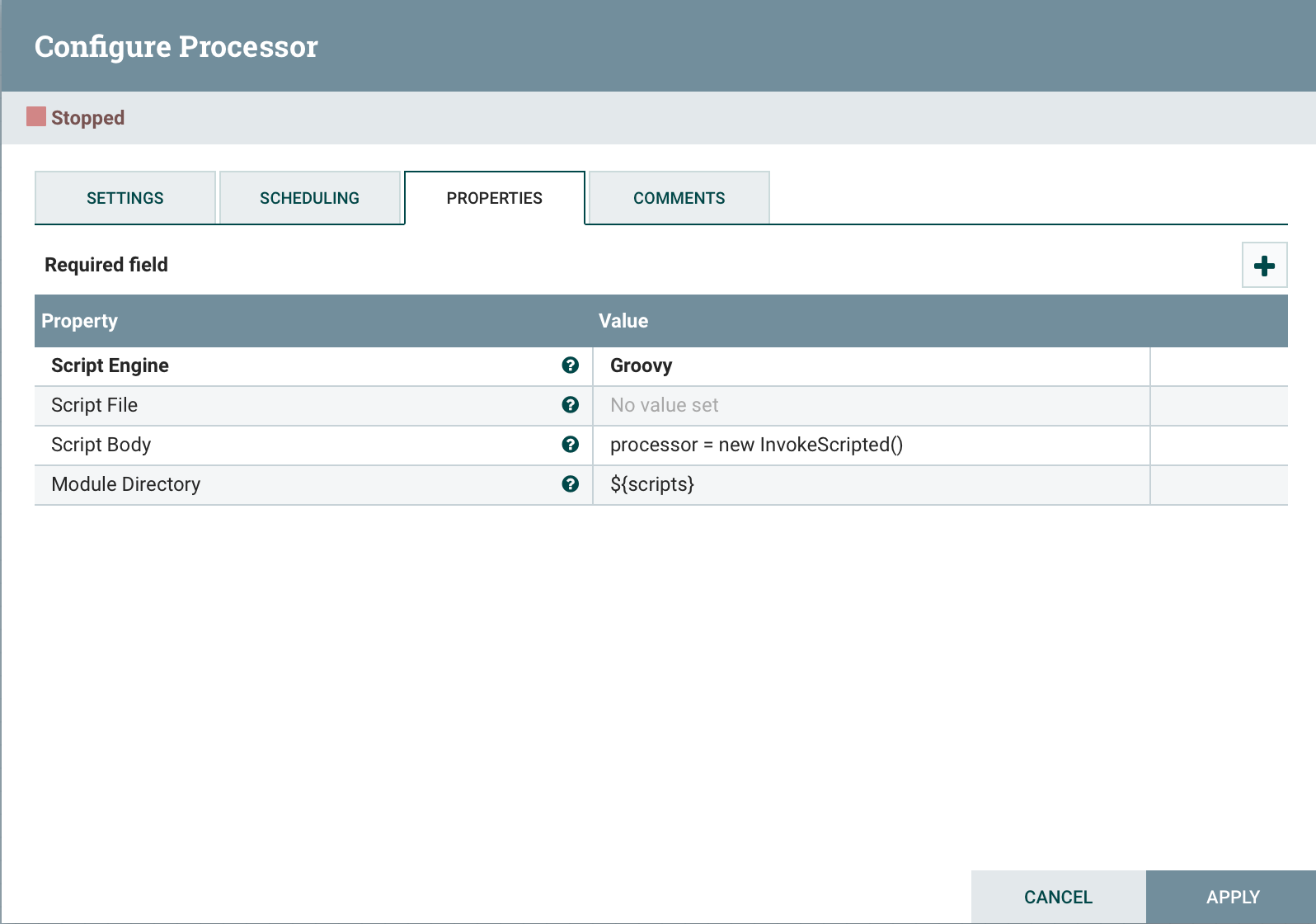 添加到代码的末尾,
添加到代码的末尾,processor = new InvokeScripted()这种方法类似于创建自定义处理器。结论
创建自定义处理器并不是最容易的事情-第一次您必须努力找出它,但是不可否认的是,此操作的好处。Rostelecom数据管理团队准备的帖子