再一次问好。今天,我们期待着基础课程“数据科学的数学”的开始,继续进行一系列翻译。
在最近的一篇文章中,我们讨论了如何通过将PyCaret集成到Power BI中来在Power BI中创建异常检测器,并帮助分析师和数据分析师轻松地将机器学习添加到报表和仪表板中。在本文中,我们将研究如何使用PyCaret和Power BI执行群集分析。如果您以前从未听说过有关PyCaret的信息,则可以在这里开始了解它。我们将在今天的指南中讨论什么:- 什么是集群?群集的类型。
- 在没有老师的情况下学习并在Power BI中实现群集模型。
- 分析结果并在仪表板上显示信息。
- 如何在Power BI中的生产上部署群集模型?
在我们开始之前...
如果您以前已经使用过Python,则很可能您的计算机上已经安装了Anaconda。如果没有,你可以用Python 3.7下载蟒蛇分布以上从这里。环境设定
在开始使用Power BI中的PyCaret机器学习功能之前,您需要创建一个虚拟环境并将其安装在其中pycaret。为此,我们需要执行三个步骤:步骤1-创建虚拟环境打开Anaconda命令提示符并输入以下内容:conda create --name myenv python=3.7
第2步-安装PyCaret在Anaconda命令提示符处运行以下命令:pip install pycaret
安装可能需要15到20分钟。如果在安装过程中遇到任何问题,可以在GitHub的页面上熟悉其解决方案。步骤3-在安装了Python的Power BI中指示创建的虚拟环境必须与Power BI关联。您可以使用Power BI Desktop中的全局设置(文件->选项->全局-> Python脚本)来执行此操作。Anaconda环境默认放置在目录中:C:\Users\username\AppData\Local\Continuum\anaconda3\envs\myenv
什么是集群?
聚类是一种根据相似特征将数据分为几组的方法。这样的组可用于研究数据,识别模式以及分析数据子集。群集数据有助于识别基础数据结构,这在许多行业中都非常有用。以下是业务集群中的一些常见用法:- 营销客户细分。
- 分析促销和折扣的消费者行为。
- 在暴发期间识别风团,例如COVID-19。
聚类类型
考虑到群集任务的主观性质,有各种算法更适合解决某些类型的任务。每种算法都有其自身的特征和数学依据,这是聚类分布的基础。在今天的教程中,我们将讨论使用称为PyCaret的Python库在Power BI中进行聚类分析,并且我们不会深入研究数学。 今天,我们将使用k-means方法-一种没有老师的最简单,最受欢迎的教学方法。您可以在此处找到有关k-means方法的更多信息。
今天,我们将使用k-means方法-一种没有老师的最简单,最受欢迎的教学方法。您可以在此处找到有关k-means方法的更多信息。商业环境
在本指南中,我们将使用世界卫生组织全球卫生支出数据库中的预制数据集。它包含了2000年至2017年200多个国家/地区的卫生支出占其国内生产总值的百分比我们的任务是使用k-means方法在此数据中找到模式和组。数据可以在这里找到。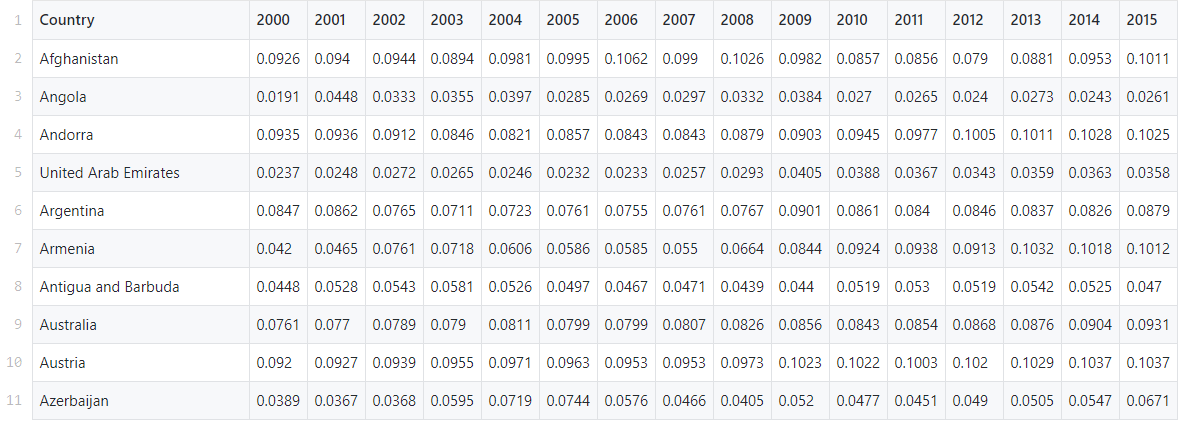
所以,让我们开始吧
现在,您已经设置了Anaconda环境,安装了PyCaret,您已经了解了集群分析的基础知识和业务环境,是时候开始做生意了。1.数据采集
第一步是将数据集导入Power BI Desktop。您可以使用Web连接器下载数据。(Power BI Desktop→获取数据→从Web)。 链接到csv文件:https : //github.com/pycaret/powerbi-clustering/blob/master/clustering.csv。
链接到csv文件:https : //github.com/pycaret/powerbi-clustering/blob/master/clustering.csv。2.模型训练
要学习Power BI中的群集模型,我们需要在Power Query Editor中执行一个Python脚本(Power Query Editor→Transform→Run python script)。使用以下代码作为脚本:from pycaret.clustering import *
dataset = get_clusters(dataset, num_clusters=5, ignore_features=['Country'])
 我们使用参数忽略了集合的“国家/地区”列
我们使用参数忽略了集合的“国家/地区”列ignore_features。有很多原因可能导致您需要排除某些列以更好地训练机器学习模型。PyCaret允许您隐藏不必要的列而不是删除它们,因为将来可能需要使用它们进行进一步分析。例如,现在我们不想使用“国家”进行培训,而是将此列传递给ignore_features。PyCaret中有8种现成的机器学习算法。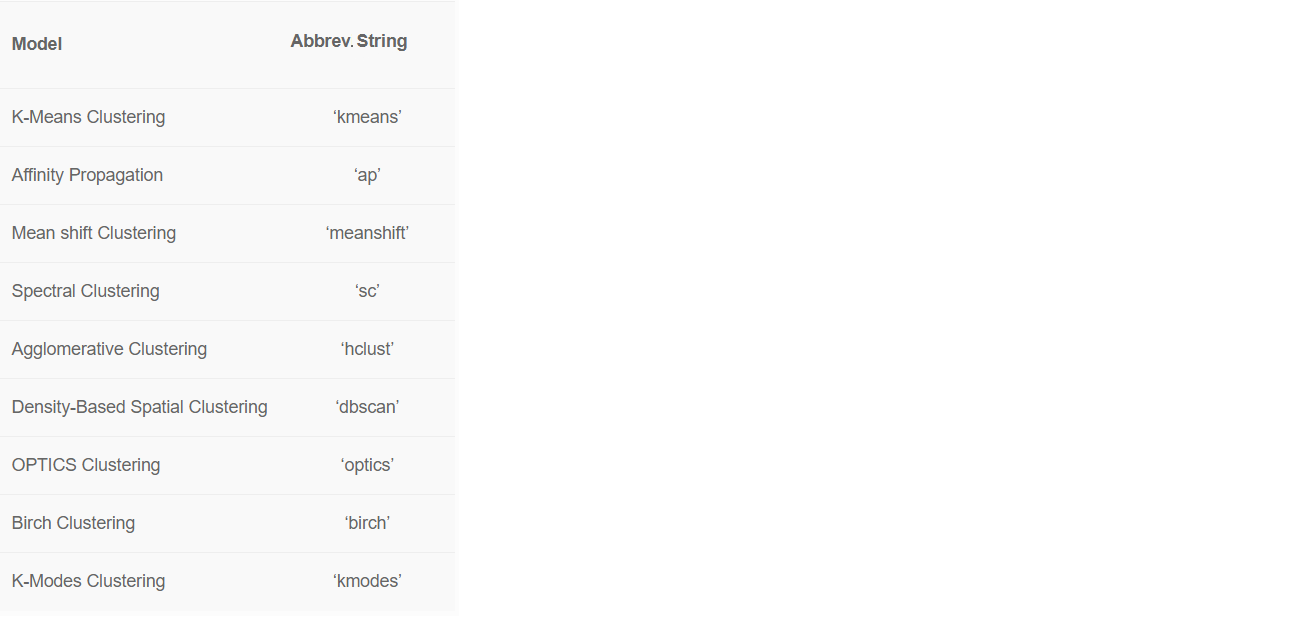 默认情况下,PyCaret在四个聚类上训练k均值聚类模型。但是默认值可以轻松更改:
默认情况下,PyCaret在四个聚类上训练k均值聚类模型。但是默认值可以轻松更改:- 要改变模型的类型,使用的模型参数在
get_clusters()。 - 要更改群集数,请使用选项
num_clusters。
例如,这是将k-means聚类为6个聚类的方法。from pycaret.clustering import *
dataset = get_clusters(dataset, model='kmodes', num_clusters=6, ignore_features=['Country'])
结论:
 带有聚类标签的另一列已添加到原始数据集中。然后使用year列中的所有值对数据进行规范化并在Power BI中进一步可视化。这就是最终结果在Power BI中的外观。
带有聚类标签的另一列已添加到原始数据集中。然后使用year列中的所有值对数据进行规范化并在Power BI中进一步可视化。这就是最终结果在Power BI中的外观。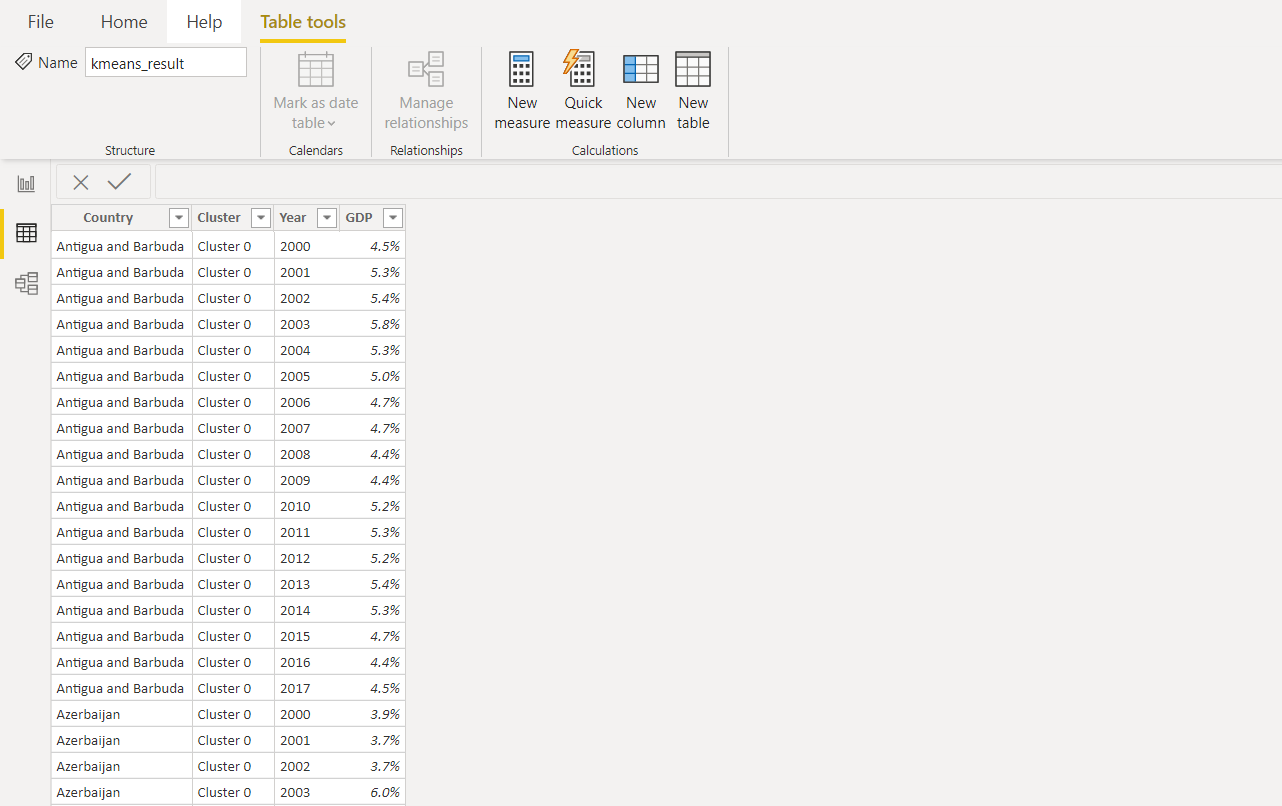
3.仪表板
在Power BI中获得群集标签后,可以在Power BI的仪表板中可视化它们以进行分析: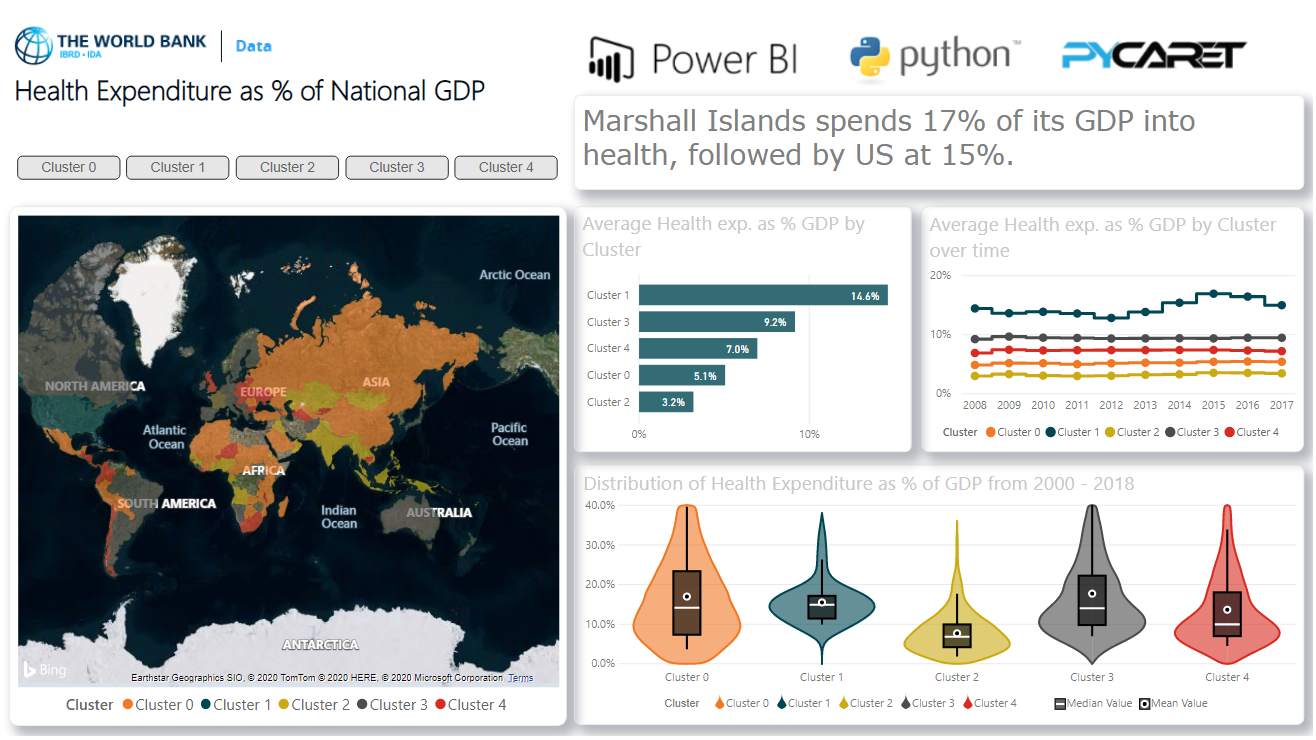
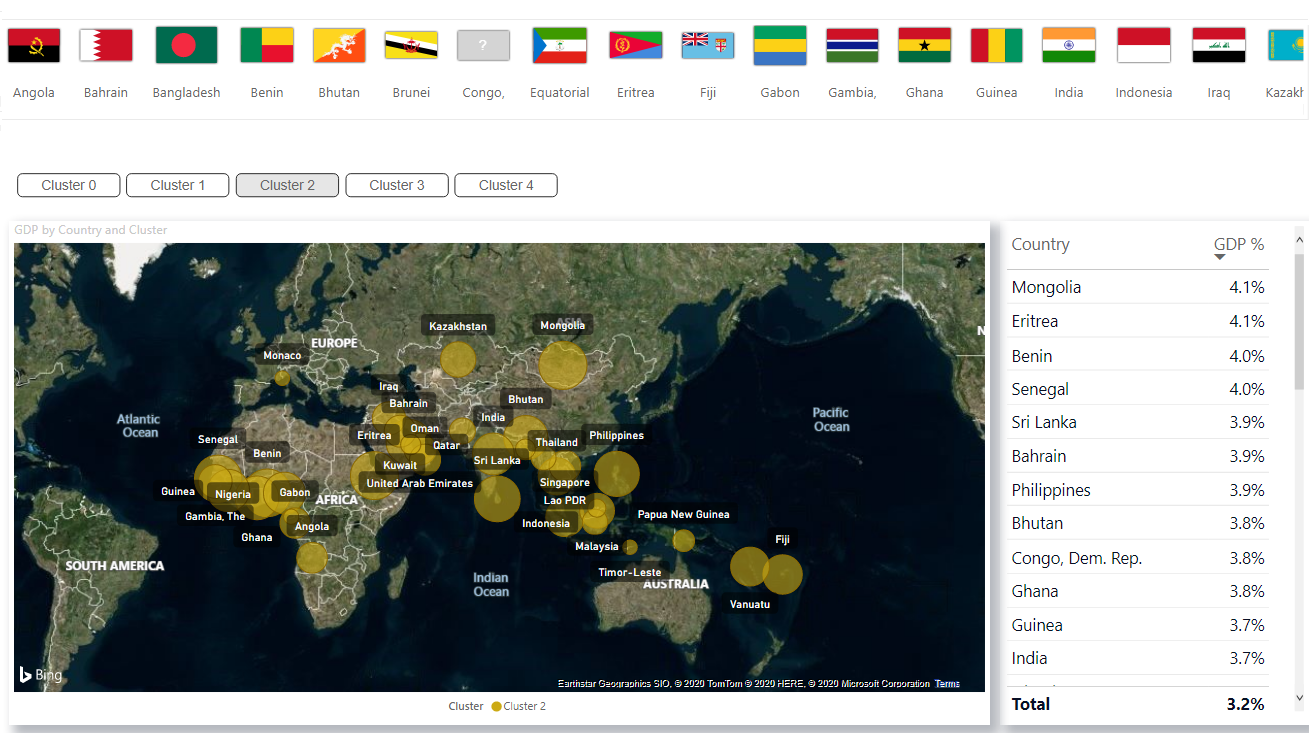 您可以从GitHub下载PBIX文件和数据集。
您可以从GitHub下载PBIX文件和数据集。集群实施
上面,我们演示了Power BI中最简单的群集实现。我注意到,每次在Power BI中更新数据集时,此方法都会训练聚类模型。由于以下原因,这可能是一个问题:- 当在新数据上对模型进行重新训练时,聚类标签可能会更改(即,如果较早地将某些数据点分配给了第一个聚类,则在重新训练时,它们可以被分配给第二个聚类);
- 您将不需要每次重新训练模型都花费几个小时。
在Power BI中实现群集而不是一遍又一遍地重新学习的一种更有效的方法是,使用预先训练的模型来创建群集标签。早期模型训练
您可以使用任何集成开发环境(IDE)或Notebook来训练模型。在此示例中,我们在Visual Studio Code中训练了群集模型。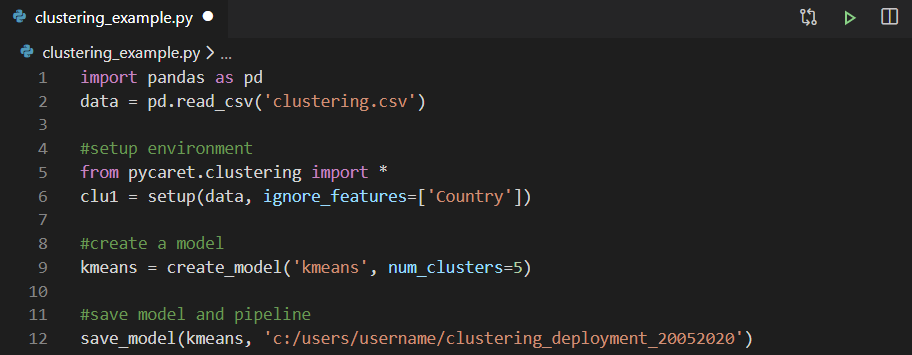 然后,将训练后的模型另存为泡菜文件,并导入到Power Query中以生成聚类标签。
然后,将训练后的模型另存为泡菜文件,并导入到Power Query中以生成聚类标签。 如果您想了解有关使用PyCaret在Jupyter Notebook中实施聚类分析的更多信息,请观看此两分钟的视频。
如果您想了解有关使用PyCaret在Jupyter Notebook中实施聚类分析的更多信息,请观看此两分钟的视频。使用预先训练的模型
运行以下代码,以从预训练的模型生成标签:from pycaret.clustering import *
dataset = predict_model('c:/.../clustering_deployment_20052020, data = dataset)
结果将与我们之前观察到的相同。唯一的区别是,使用预先训练的模型时,将使用旧模型根据新数据集而不是经过重新训练的模型生成标签。使用Power BI服务
将.pbix文件上传到Power BI服务之后,您将需要执行一些其他步骤,以确保将机器学习管道顺利集成到数据管道中。步骤如下:- 打开数据集的计划更新-这将允许您使用Python脚本来计划要更新数据集的工作簿,查看“ 配置计划的刷新”部分,该部分还包含有关Personal Gateway的信息。
- 安装个人网关-您将需要一个个人网关,该网关必须安装在安装Python的同一目录中。Power BI服务必须有权访问Python环境。在这里,您可以了解有关如何安装和配置Personal Gateway的更多信息。
如果您想了解有关聚类分析的更多信息,可以熟悉本笔记本中的指南。
上课程。