注意佩雷夫。注意:尽管此评论并不声称是对Kubernetes中永久存储数据的现有解决方案进行精心开发的技术比较的状态,但对于与此问题相关的管理员来说,这可能是一个很好的起点。最关注的是比雷埃夫斯解决方案,这种解决方案的熟悉程度不仅会给Linstor爱好者带来好处,还会使那些从未听说过这些项目的人受益。 这是Kubernetes存储解决方案的不科学的概述。问题陈述:需要具有在节点的磁盘上创建持久卷的能力,如果节点损坏或重新启动,该卷的数据将被保存。进行这种比较的动机是需要将公司的服务器群从多个专用的裸机服务器迁移到Kubernetes集群。我的公司是一家巴西的初创公司Escavador,具有巨大的计算需求(主要是CPU),并且预算非常有限。我们开发用于构建法律数据的NLP解决方案。
这是Kubernetes存储解决方案的不科学的概述。问题陈述:需要具有在节点的磁盘上创建持久卷的能力,如果节点损坏或重新启动,该卷的数据将被保存。进行这种比较的动机是需要将公司的服务器群从多个专用的裸机服务器迁移到Kubernetes集群。我的公司是一家巴西的初创公司Escavador,具有巨大的计算需求(主要是CPU),并且预算非常有限。我们开发用于构建法律数据的NLP解决方案。 由于COVID-19的危机,巴西雷亚尔兑美元汇率跌至历史新低实际上,我们的国家货币被低估了,因此高级开发人员的平均工资仅为每月2000美元。因此,我们无法承受在云服务上花费大量资金的奢侈行为。上一次进行计算时,(由于使用服务器)与我为AWS支付的费用相比,我们节省了75%。换句话说,可以聘请另一位开发商来节省资金-我认为这是对资金的更为合理的利用。受Vito Botta的一系列出版物的启发,我决定使用Rancher创建K8s集群(到目前为止非常好……)。 Vito还对各种存储解决方案进行了出色的分析。明显的赢家是林斯托(他甚至在特殊联盟)。剧透:我同意他的看法。一段时间以来,我一直在关注Kubernetes周围的交通,但直到最近才决定参与其中。这主要是由于提供商提供了新的Ryzen处理器产品线。然后,令我惊讶的是,许多解决方案仍处于开发阶段或处于不成熟状态(尤其是对于裸机集群:VM虚拟化,MetalLB等)。尽管以众多商业和开源解决方案为代表,但裸露的电子仓库仍处于成熟阶段。我决定比较主要的有前途的和免费的解决方案(同时测试一种商业产品以了解我正在失去的东西)。CNCF Landscape的
由于COVID-19的危机,巴西雷亚尔兑美元汇率跌至历史新低实际上,我们的国家货币被低估了,因此高级开发人员的平均工资仅为每月2000美元。因此,我们无法承受在云服务上花费大量资金的奢侈行为。上一次进行计算时,(由于使用服务器)与我为AWS支付的费用相比,我们节省了75%。换句话说,可以聘请另一位开发商来节省资金-我认为这是对资金的更为合理的利用。受Vito Botta的一系列出版物的启发,我决定使用Rancher创建K8s集群(到目前为止非常好……)。 Vito还对各种存储解决方案进行了出色的分析。明显的赢家是林斯托(他甚至在特殊联盟)。剧透:我同意他的看法。一段时间以来,我一直在关注Kubernetes周围的交通,但直到最近才决定参与其中。这主要是由于提供商提供了新的Ryzen处理器产品线。然后,令我惊讶的是,许多解决方案仍处于开发阶段或处于不成熟状态(尤其是对于裸机集群:VM虚拟化,MetalLB等)。尽管以众多商业和开源解决方案为代表,但裸露的电子仓库仍处于成熟阶段。我决定比较主要的有前途的和免费的解决方案(同时测试一种商业产品以了解我正在失去的东西)。CNCF Landscape的 存储解决方案范围但首先,我想警告您,我是K8的新手。为了进行实验,使用了4个具有以下配置的工作程序:Ryzen 3700X处理器,64 GB ECC内存,NVMe 2 TB大小。使用
存储解决方案范围但首先,我想警告您,我是K8的新手。为了进行实验,使用了4个具有以下配置的工作程序:Ryzen 3700X处理器,64 GB ECC内存,NVMe 2 TB大小。使用sotoaster/dbench:latest带有标志的图像(对中)进行基准测试O_DIRECT。长角牛
我真的很喜欢Longhorn。它与Rancher完全集成,您可以一键通过Helm安装它。 从Rancher安装Longhorn这是一个开源工具,具有Cloud Native Computing Foundation(CNCF)的沙箱项目状态。它的开发是由Rancher资助的-Rancher是一家相当成功的公司,拥有著名的[同名]产品。
从Rancher安装Longhorn这是一个开源工具,具有Cloud Native Computing Foundation(CNCF)的沙箱项目状态。它的开发是由Rancher资助的-Rancher是一家相当成功的公司,拥有著名的[同名]产品。 还提供了出色的图形界面 -一切都可以用它完成。有了性能,一切都是有序的。该项目仍处于测试阶段,已通过GitHub上的问题得到证实。测试时,我使用2个副本和Longhorn 0.8.0启动了基准测试:
还提供了出色的图形界面 -一切都可以用它完成。有了性能,一切都是有序的。该项目仍处于测试阶段,已通过GitHub上的问题得到证实。测试时,我使用2个副本和Longhorn 0.8.0启动了基准测试:- 随机读取/写入,IOPS:28.2k / 16.2k;
- 读/写带宽:205 Mb / s / 108 Mb / s;
- 平均读写延迟(usec):593.27 / 644.27;
- 顺序读/写:201 Mb / s / 108 Mb / s;
- 混合随机读/写,IOPS:14.7k / 4904。
Openebs
该项目还具有CNCF沙箱状态。GitHub上有很多明星,这看起来是一个非常有前途的解决方案。在他的评论中,Vito Botta抱怨性能不足。这是Mayadata首席执行官的回答:信息非常陈旧。OpenEBS曾经支持3个,但是现在如果支持动态调配和localPV编排(可以以NVMe速度运行),它现在支持4个引擎。此外,MayaStor引擎现在已打开,并且已经收到好评(尽管它具有alpha状态)。
在OpenEBS项目页面上,有这样的状态说明:OpenEBS — Kubernetes. OpenEBS sandbox- CNCF 2019- , - (local, nfs, zfs, nvme) on-premise, . OpenEBS - stateful- — Litmus Project, — OpenEBS. OpenEBS production 2018 ; 2,5 docker pull'.
它具有许多引擎,而在性能方面,最后一个似乎很有希望:“ MayaStor-带有NVMe over Fabrics的alpha引擎”。las,由于alpha版本状态,我没有对其进行测试。在测试中,jiva引擎使用了1.8.0版。另外,我以前检查过cStor,但是没有保存结果,但是结果却比jiva慢一点。对于基准测试,安装了带有所有默认设置的Helm图表openebs-jiva-default,并使用了由Helm()标准创建的存储类。事实证明,性能是所考虑的所有解决方案中最差的(对于改进的建议,我将不胜感激)。带有jiva引擎的OpenEBS 1.8.0(3个副本?):- 随机读/写,IOPS:2182/1527;
- 读/写带宽:65.0 Mb / s / 41.9 Mb / s;
- / (usec): 1825.49 / 2612.87;
- /: 95.5 / / 37.8 /;
- /, IOPS: 2607 / 856.
. Evan Powell, OpenEBS ( , StackStorm Nexenta):, Bruno! OpenEBS . Jiva, ARM overhead' . Bloomberg DynamicLocal PV OpenEBS. Elastic , . , OpenEBS Director (https://account.mayadata.io/signup). — , .
StorageOS
这是一种商业解决方案,在使用多达110 GB的空间时是免费的。可以通过产品用户界面注册获得免费的开发人员许可证;它最多提供500 GB的空间。在Rancher中,它被列为合作伙伴,因此使用Helm进行的安装非常容易且省力。为用户提供了基本的控制面板。此产品的测试受到限制,因为它是商业产品,并且不适合我们的价值。但是我仍然想看看商业项目有什么能力。该测试使用称为“快速”的现有存储类(模板0.2.19,1个主目录+ 0个副本?)。结果是惊人的。它们大大超出了以前的解决方案。- 随机读取/写入,IOPS:117k / 90.4k;
- 读/写带宽:2124 Mb / s / 457 Mb / s;
- 平均读写延迟(usec):63.44 / 86.52;
- 顺序读/写:1907 Mb / s / 448 Mb / s;
- 混合随机读/写,IOPS:81.9k / 27.3k
比雷埃夫斯(基于Linstor)
许可证:GPLv3早已提到的Vito Botta最终选择了Linstor,这是尝试此解决方案的另一个原因。乍一看,该项目看起来很奇怪。GitHub上几乎没有星星,这是一个不寻常的名称,甚至在CNCF Landscape中也不存在。但是,经过仔细检查,一切并没有那么可怕,因为:- DRBD被用作基本的复制机制(实际上,它是由同一个人开发的)。同时,DRBD 8.x成为正式Linux内核的一部分已有十多年了。我们谈论的是经过20多年磨练的技术。
- 媒体由LINSTOR控制,这也是同一家公司的成熟技术。Linstor服务器的第一版于2018年2月在GitHub上发布。它与各种技术/系统兼容,例如Proxmox,OpenNebula和OpenStack。
- 显然,Linbit正在积极开发该项目,并不断在其中引入新功能和改进。DRBD的第10版仍然具有alpha状态,但是它已经具有一些独特的功能,例如擦除编码(类似于RAID5 / 6-大约翻译的功能)。
- 公司采取了某些措施,成为CNCF项目之一。
好的,该项目看起来很有说服力,可将其宝贵的数据委托给他。但是他能够重播其他选择吗?让我们来看看。安装
Vito谈论在这里安装Linstor 。但是,在评论中,一位Linstor开发人员推荐了一个名为Piraeus的新项目。据我了解,Piraeus正在成为Linbit开源项目,它将与K8s相关的所有内容结合在一起。该小组正在研究适当的操作员,但是目前,可以使用此YAML文件安装Piraeus:kubectl apply -f https://raw.githubusercontent.com/bratao/piraeus/master/deploy/all.yaml
注意!您可以从我的个人存储库中获取配置。查看官方资料库!我更新了图像的版本以解决在Ubuntu中使用时出现的错误。官方的比雷埃夫斯仓库可以在这里找到。您还可以使用kvaps存储库(它似乎比官方的piraeus存储库更动态):https : //github.com/kvaps/kube-linstor (借此机会向Andrey致意va-大约 perev。)。 安装后所有节点均正常工作
安装后所有节点均正常工作管理
使用命令行进行管理。可以从piraeus-controller节点的命令外壳访问它。 控制器节点正在运行linstor-server。它是drbd上的抽象层,能够管理整个节点群。下面的屏幕截图显示了一些最常用任务的有用命令,例如:
控制器节点正在运行linstor-server。它是drbd上的抽象层,能够管理整个节点群。下面的屏幕截图显示了一些最常用任务的有用命令,例如:linstor node list -显示已连接节点及其状态的列表;linstor volume list -显示创建的卷及其位置的列表;linstor node info -显示每个节点的功能。
 Linstor命令完整的命令列表可在官方文档中找到:LINSTOR用户指南。在发生脑裂的情况下,可以直接通过节点访问drbd。
Linstor命令完整的命令列表可在官方文档中找到:LINSTOR用户指南。在发生脑裂的情况下,可以直接通过节点访问drbd。灾难恢复
我尽力删除了群集,包括在节点上进行硬重置。但是林斯特出奇的顽强。Drbd完美地认识到一个称为“裂脑”的问题。在我的情况下,辅助节点无法复制。Split brain — , - , - Primary, «» . , . , , .
Split brain DRBD , , Heartbeat.
可以在drbd的官方文档中找到详细信息。 辅助节点退出复制,以解决此问题,我删除了辅助数据并开始与主节点同步。由于我更喜欢图形界面,因此我使用了drbdtop实用程序。借助其帮助,您可以直观地监视状态并在节点内执行命令。我需要进入问题节点piraues上的控制台(它是
辅助节点退出复制,以解决此问题,我删除了辅助数据并开始与主节点同步。由于我更喜欢图形界面,因此我使用了drbdtop实用程序。借助其帮助,您可以直观地监视状态并在节点内执行命令。我需要进入问题节点piraues上的控制台(它是worker2-gpu): 转到该节点,在那里我安装了drdbtop。在此处下载此实用程序:
转到该节点,在那里我安装了drdbtop。在此处下载此实用程序:wget https://github.com/LINBIT/drbdtop/releases/download/v0.2.2/drbdtop-linux-amd64
chmod +x drbdtop-linux-amd64
./drbdtop-linux-amd64
 运行drbdtop实用程序看一下底部面板。上面有一些可用于修复裂脑的命令:
运行drbdtop实用程序看一下底部面板。上面有一些可用于修复裂脑的命令: 之后,节点将自动连接并同步。
之后,节点将自动连接并同步。如何增加速度?
默认情况下,Piraeus / Linstor / drbd显示出色的性能(您可以在下面看到)。默认设置是合理且安全的。但是,写入速度相当弱。由于我的服务器分散在不同的数据中心(尽管它们在物理上相对较近),所以我决定尝试调整它们的性能。优化的起点是定义复制协议。默认情况下,使用协议C,该协议在远程辅助节点上等待写入确认。以下是可能的协议的说明:- Protocol A — . , , TCP- . , TCP . .
- Protocol B — . , , .
- Protocol C ( ) — . .
因此,在Linstor中,我还使用了异步协议(它支持同步/半同步/异步复制)。您可以使用以下命令启用它:linstor c drbd-options --protocol A --after-sb-0pri=discard-zero-changes --after-sb-1pri=discard-secondary --after-sb-2pri=disconnect --max-buffers 131072 --sndbuf-size 1085760 --rcvbuf-size 1085760 --c-max-rate 4194304 --c-fill-target 1048576
其实现的结果将是异步协议的激活,并将缓冲区增加到1 MB。比较安全。或者,您可以使用以下命令(它忽略磁盘刷新并显着增加缓冲区):linstor c drbd-options --protocol A --after-sb-0pri=discard-zero-changes --after-sb-1pri=discard-secondary --after-sb-2pri=disconnect --max-buffers 131072 --sndbuf-size 10485760 --rcvbuf-size 10485760 --disk-barrier no --disk-flushes no --c-max-rate 4194304 --c-fill-target 1048576
请注意,如果主节点发生故障,则一小部分数据可能无法到达副本。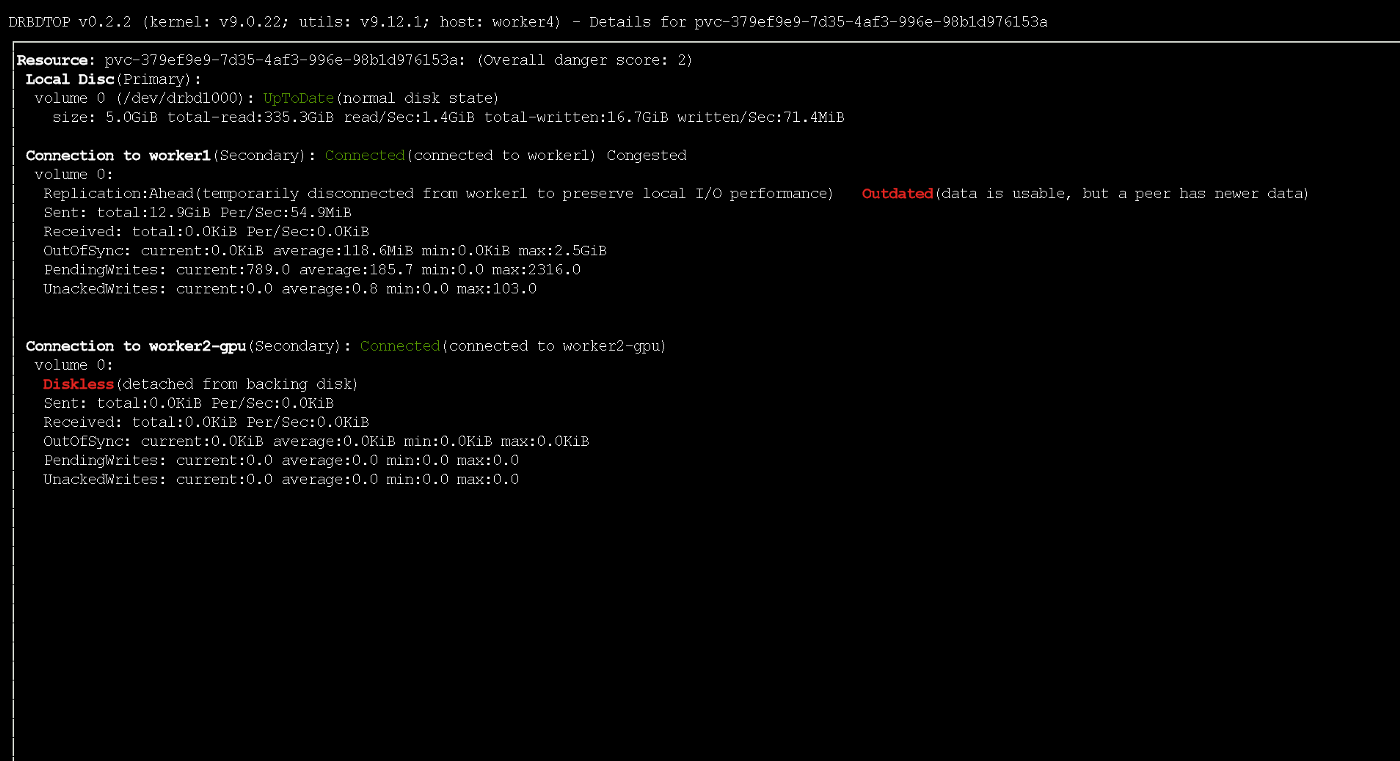 在活动记录期间,节点使用ASYNC协议临时接收过时状态
在活动记录期间,节点使用ASYNC协议临时接收过时状态测试中
所有基准测试均使用以下作业进行:kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: dbench
spec:
storageClassName: STORAGE_CLASS
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
---
apiVersion: batch/v1
kind: Job
metadata:
name: dbench
spec:
template:
spec:
containers:
- name: dbench
image: sotoaster/dbench:latest
imagePullPolicy: IfNotPresent
env:
- name: DBENCH_MOUNTPOINT
value: /data
- name: FIO_SIZE
value: 1G
volumeMounts:
- name: dbench-pv
mountPath: /data
restartPolicy: Never
volumes:
- name: dbench-pv
persistentVolumeClaim:
claimName: dbench
backoffLimit: 4
机器之间的延迟如下:ttl=61 time=0.211 ms。它们之间的测量吞吐量为943 Mbps。所有节点都在运行Ubuntu 18.04。结果(sheets.com上的表)
从表中可以看出,Piraeus和StorageOS表现出最好的结果。领导者是具有两个副本和一个异步协议的比雷埃夫斯。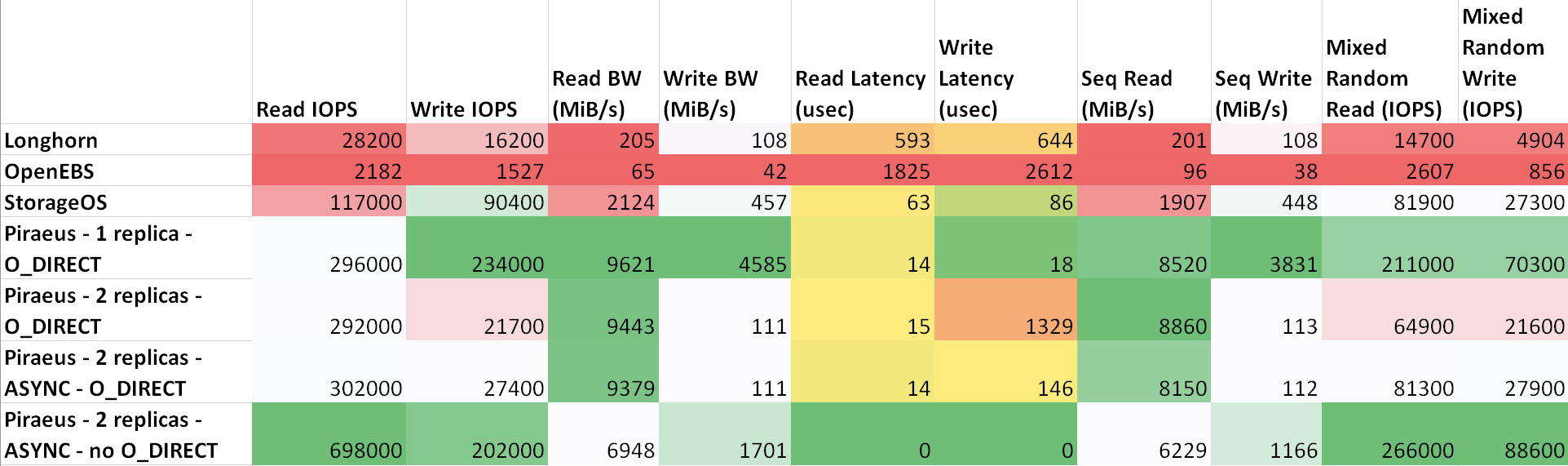
发现
我对Kubernetes中的某些存储解决方案进行了简单的比较,也许不太正确。最重要的是,我喜欢Longhorn,因为它具有出色的GUI和与Rancher的集成。但是,结果并不令人鼓舞。显然,开发人员主要专注于安全性和正确性,为以后留出了速度。一段时间以来,我一直在某些项目的生产环境中使用Linstor / Piraeus。到目前为止,一切都很好:创建和删除磁盘,重新启动节点而没有停机...我认为,比雷埃夫斯已经准备好用于生产中,但是需要改进。我在Slack的项目通道中写了一些错误,但是作为回应,它们只建议我教Kubernetes(这是正确的,因为我仍然不太了解它)。经过一番通信后,我仍然设法说服了作者,他们的init脚本中有错误。昨天,在更新内核并重新引导之后,该节点拒绝引导。事实证明,将drbd模块集成到内核的脚本编译失败。回滚到以前的内核版本可以解决该问题。通常,仅此而已。考虑到他们是在drbd之上实现的,因此它是具有出色性能的非常可靠的解决方案。如有任何问题,您可以直接与drbd管理部门联系并进行修复。互联网上有许多与此主题有关的问题和示例。如果我做错了什么,如果可以改进或需要帮助,请通过Twitter或GitHub与我联系。译者的PS
另请参阅我们的博客: