在上一篇文章中,我谈到了监视PostgreSQL数据库的问题:增长wait-应用程序已“停在”某人的锁上。如果这是过去的一次异常-是了解原始原因的机会。
对于DBA,这种情况是最不愉快的一种:- 乍一看,基地正在运作
- 没有服务器资源耗尽
- ...但是有些要求“放慢了速度”
 “立即” 捕获锁的机会非常小,它们只能持续几秒钟,但会使请求的计划执行时间恶化数十倍。但是,您只是不想坐下来捕捉网上发生的事情,而要在一个平静的环境中找出事实
“立即” 捕获锁的机会非常小,它们只能持续几秒钟,但会使请求的计划执行时间恶化数十倍。但是,您只是不想坐下来捕捉网上发生的事情,而要在一个平静的环境中找出事实,由哪些开发人员来惩罚到底是什么问题-谁,谁与谁以及由于数据库的哪些资源发生冲突。但是如何?确实,与具有计划的请求不同,该请求使您可以详细了解资源的用途和花费的时间,该锁不会留下明显的痕迹 ……除非输入简短的日志:但是让我们尝试抓住它!process ... still waiting for ...
我们抓住了日志中的锁
但是,即使至少要在日志中显示此行,也必须正确配置服务器:log_lock_waits = 'on'
...并为我们的分析设置最小边界:deadlock_timeout = '100ms'
启用log_lock_waits此参数后,此参数还将确定有关等待阻塞的消息将在什么时间后写入服务器日志。如果您要调查由锁引起的延迟,则与通常的值相比,将其减少是有意义的deadlock_timeout。
在此期间没有时间“解开”的所有死锁将被撕裂。这是“常规”锁-通过几个条目转储到日志中:2019-03-27 00:06:46.026 MSK [38162:84/166010018] [inside.tensor.ru] [local] csr-inside-bl10:10081: MergeRequest LOG: process 38162 still waiting for ExclusiveLock on advisory lock [225382138,225386226,141586103,2] after 100.047 ms
2019-03-27 00:06:46.026 MSK [38162:84/166010018] [inside.tensor.ru] [local] csr-inside-bl10:10081: MergeRequest DETAIL: Process holding the lock: 38154. Wait queue: 38162.
2019-03-27 00:06:46.026 MSK [38162:84/166010018] [inside.tensor.ru] [local] csr-inside-bl10:10081: MergeRequest CONTEXT: SQL statement "SELECT pg_advisory_xact_lock( '""'::regclass::oid::integer, 141586103::integer )"
PL/pgSQL function inline_code_block line 2 at PERFORM
2019-03-27 00:06:46.026 MSK [38162:84/166010018] [inside.tensor.ru] [local] csr-inside-bl10:10081: MergeRequest STATEMENT: DO $$ BEGIN
PERFORM pg_advisory_xact_lock( '""'::regclass::oid::integer, 141586103::integer );
EXCEPTION
WHEN query_canceled THEN RETURN;
END; $$;
…
2019-03-27 00:06:46.077 MSK [38162:84/166010018] [inside.tensor.ru] [local] csr-inside-bl10:10081: MergeRequest LOG: process 38162 acquired ExclusiveLock on advisory lock [225382138,225386226,141586103,2] after 150.741 ms
此示例表明,从锁定出现在日志中到解决它的那一刻之间,我们只有50ms。仅在此时间间隔内,我们至少可以获得有关它的一些信息,并且我们能够做到这一点的速度越快,我们可以分析的锁就越多。对我们来说,最重要的信息是等待锁定的进程的PID。通过它,我们可以比较日志和数据库状态之间的信息。并且同时找出特定的锁有多问题-即“挂”了多长时间。为此,我们在内容LOG记录上只需要几个RegExp :const RE_lock_detect = /^process (\d+) still waiting for (.*) on (.*) after (\d+\.\d{3}) ms(?: at character \d+)?$/;
const RE_lock_acquire = /^process (\d+) acquired (.*) on (.*) after (\d+\.\d{3}) ms(?: at character \d+)?$/;
我们到日志
实际上,它仍然有些不足-获取日志,了解如何对其进行监视并做出相应的响应。我们已经拥有了所有功能-在线日志解析器和预先激活的数据库连接,我在有关PostgreSQL监控系统的文章中谈到了该方法: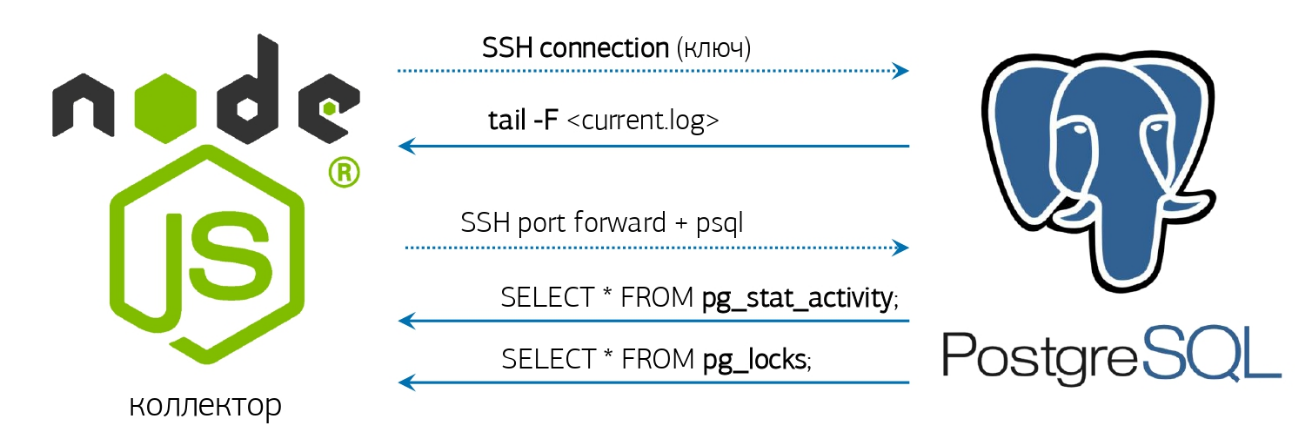 但是,如果您没有部署任何类似的系统,那么就可以了“就在控制台旁边”!如果安装的PostgreSQL 10及更高版本很幸运,因为出现了pg_current_logfile()函数,该函数显式给出当前日志文件的名称。从控制台获取它很容易:
但是,如果您没有部署任何类似的系统,那么就可以了“就在控制台旁边”!如果安装的PostgreSQL 10及更高版本很幸运,因为出现了pg_current_logfile()函数,该函数显式给出当前日志文件的名称。从控制台获取它很容易:psql -U postgres postgres -t -A -c "SELECT CASE WHEN substr(current_setting('log_directory'), 1, 1) <> '/' THEN current_setting('data_directory') ELSE '' END || '/' || pg_current_logfile()"
如果该版本突然更年轻-一切都会出现,但会稍微复杂一点:ps uw -U postgres \
| grep [l]ogger \
| awk '{print "/proc/"$2"/fd"}' \
| xargs ls -l \
| grep `cd; psql -U postgres postgres -t -A -c "SELECT CASE WHEN substr(current_setting('log_directory'), 1, 1) = '/' THEN current_setting('log_directory') ELSE current_setting('data_directory') || '/' || current_setting('log_directory') END"` \
| awk '{print $NF}'
我们tail -f得到完整的文件名,然后输入该文件名,并在那里查找外观'still waiting for'。好吧,一旦该线程中出现问题,我们就会调用...解析请求
las,日志中的阻塞对象绝不是导致冲突的资源。例如,如果您尝试并行创建相同名称的索引,则log中只会出现类似的内容still waiting for ExclusiveLock on transaction 12345。因此,对于我们感兴趣的过程,我们将必须从数据库中删除所有锁的状态。仅关于一对流程(谁锁定了谁/谁期望它)的信息是不够的,因为交易之间经常存在对不同资源的期望“链”:tx1 [resA] -> tx2 [resA]
tx2 [resB] -> tx3 [resB]
...
经典:“萝卜的祖父,祖父的祖母,祖母的祖母……”因此,我们将编写一个请求,该请求将告诉我们确切的原因是谁成为特定PID的整个锁链故障的根本原因:WITH RECURSIVE lm AS (
SELECT
rn
, CASE
WHEN lm <> 'Share' THEN row_number() OVER(PARTITION BY lm <> 'Share' ORDER BY rn)
END rx
, lm || 'Lock' lm
FROM (
SELECT
row_number() OVER() rn
, lm
FROM
unnest(
ARRAY[
'AccessShare'
, 'RowShare'
, 'RowExclusive'
, 'ShareUpdateExclusive'
, 'Share'
, 'ShareRowExclusive'
, 'Exclusive'
, 'AccessExclusive'
]
) T(lm)
) T
)
, lt AS (
SELECT
row_number() OVER() rn
, lt
FROM
unnest(
ARRAY[
'relation'
, 'extend'
, 'page'
, 'tuple'
, 'transactionid'
, 'virtualxid'
, 'object'
, 'userlock'
, 'advisory'
, ''
]
) T(lt)
)
, lmx AS (
SELECT
lr.rn lrn
, lr.rx lrx
, lr.lm lr
, ld.rn ldn
, ld.rx ldx
, ld.lm ld
FROM
lm lr
JOIN
lm ld ON
ld.rx > (SELECT max(rx) FROM lm) - lr.rx OR
(
(lr.rx = ld.rx) IS NULL AND
(lr.rx, ld.rx) IS DISTINCT FROM (NULL, NULL) AND
ld.rn >= (SELECT max(rn) FROM lm) - lr.rn
)
)
, lcx AS (
SELECT DISTINCT
(lr.locktype, lr.database, lr.relation, lr.page, lr.tuple, lr.virtualxid, lr.transactionid::text::bigint, lr.classid, lr.objid, lr.objsubid) target
, ld.pid ldp
, ld.mode ldm
, lr.pid lrp
, lr.mode lrm
FROM
pg_locks ld
JOIN
pg_locks lr ON
lr.pid <> ld.pid AND
(lr.locktype, lr.database, lr.relation, lr.page, lr.tuple, lr.virtualxid, lr.transactionid::text::bigint, lr.classid, lr.objid, lr.objsubid) IS NOT DISTINCT FROM (ld.locktype, ld.database, ld.relation, ld.page, ld.tuple, ld.virtualxid, ld.transactionid::text::bigint, ld.classid, ld.objid, ld.objsubid) AND
(lr.granted, ld.granted) = (TRUE, FALSE)
JOIN
lmx ON
(lmx.lr, lmx.ld) = (lr.mode, ld.mode)
WHERE
(ld.pid, ld.granted) = ($1::integer, FALSE)
)
SELECT
lc.locktype "type"
, CASE lc.locktype
WHEN 'relation' THEN ARRAY[relation::text]
WHEN 'extend' THEN ARRAY[relation::text]
WHEN 'page' THEN ARRAY[relation, page]::text[]
WHEN 'tuple' THEN ARRAY[relation, page, tuple]::text[]
WHEN 'transactionid' THEN ARRAY[transactionid::text]
WHEN 'virtualxid' THEN regexp_split_to_array(virtualxid::text, '/')
WHEN 'object' THEN ARRAY[classid, objid, objsubid]::text[]
WHEN 'userlock' THEN ARRAY[classid::text]
WHEN 'advisory' THEN ARRAY[classid, objid, objsubid]::text[]
END target
, lc.pid = lcx.ldp "locked"
, lc.pid
, regexp_replace(lc.mode, 'Lock$', '') "mode"
, lc.granted
, (lc.locktype, lc.database, lc.relation, lc.page, lc.tuple, lc.virtualxid, lc.transactionid::text::bigint, lc.classid, lc.objid, lc.objsubid) IS NOT DISTINCT FROM lcx.target "conflict"
FROM
lcx
JOIN
pg_locks lc ON
lc.pid IN (lcx.ldp, lcx.lrp);
问题1-启动缓慢
如您从日志示例中看到的那样,在表示发生锁定的LOG行(DETAIL, CONTEXT, STATEMENT)旁边,还有3行()报告扩展信息。首先,我们等待所有4个条目的完整“包”的形成,然后才转向数据库。但是,只有在下一个(已经是第5个!)记录到达时,以及另一个过程的详细信息或通过超时,我们才能完成程序包的形成。显然,这两个选项都会引起不必要的等待。为了消除这些延迟,我们切换到锁记录的流处理。也就是说,现在我们在对第一条记录进行排序后立即转向目标数据库,并意识到这就是此处描述的锁。问题2-要求缓慢
但是,有些锁没有时间进行分析。他们开始更深入地研究-发现在某些服务器上,我们的分析请求执行了15-20ms!原因很普遍-基地上的活动锁总数达到几千个: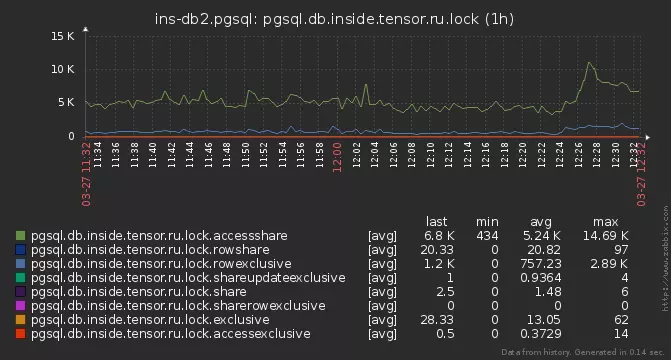
pg_locks
在这里应该注意的是,PostgreSQL中的锁并不“存储”在任何地方,而是仅在系统视图pg_locks中显示,这直接反映了该函数pg_lock_status。根据我们的要求,我们阅读了三遍!同时,我们读取了成千上万个锁实例,并丢弃了与PID无关的那些实例,锁本身设法“解析”了。解决方案是在CTE中“物化” pg_locks的状态 -在此之后,您可以多次运行它,它已经不会改变。此外,在研究了算法之后,可以将所有内容减少到仅两次扫描。动力过大
而且,如果再仔细看一下上面的查询,我们可以看到CTE lm并lmx没有以任何方式与数据绑定,而是简单地计算出模式阻塞之间始终存在相同的“静态”矩阵定义冲突。因此,让我们将其设置为quality VALUES。问题3-邻居
但是部分锁仍然被跳过。通常这是根据以下方案发生的-某人阻止了一种流行的资源,并且几个过程迅速并迅速地跑入该资源或沿链进一步发展。结果,我们捕获了第一个PID,到达了目标数据库(并且为了不使它过载,我们只保留了一个连接),进行了分析,返回结果,并获取了下一个PID ...但是在该数据库上,生命是不值得的,并且PID锁定#2已经消失了!实际上,如果我们仍然从请求中的常规列表中过滤锁,为什么我们需要分别访问每个PID的数据库?让我们立即从数据库中直接获取冲突进程的整个列表,并将其锁分配给在执行请求期间掉落的所有PID:WITH lm(ld, lr) AS (
VALUES
('AccessShareLock', '{AccessExclusiveLock}'::text[])
, ('RowShareLock', '{ExclusiveLock,AccessExclusiveLock}'::text[])
, ('RowExclusiveLock', '{ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
, ('ShareUpdateExclusiveLock', '{ShareUpdateExclusiveLock,ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
, ('ShareLock', '{RowExclusiveLock,ShareUpdateExclusiveLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
, ('ShareRowExclusiveLock', '{RowExclusiveLock,ShareUpdateExclusiveLock,ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
, ('ExclusiveLock', '{RowShareLock,RowExclusiveLock,ShareUpdateExclusiveLock,ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
, ('AccessExclusiveLock', '{AccessShareLock,RowShareLock,RowExclusiveLock,ShareUpdateExclusiveLock,ShareLock,ShareRowExclusiveLock,ExclusiveLock,AccessExclusiveLock}'::text[])
)
, locks AS (
SELECT
(
locktype
, database
, relation
, page
, tuple
, virtualxid
, transactionid::text::bigint
, classid
, objid
, objsubid
) target
, *
FROM
pg_locks
)
, ld AS (
SELECT
*
FROM
locks
WHERE
NOT granted
)
, lr AS (
SELECT
*
FROM
locks
WHERE
target::text = ANY(ARRAY(
SELECT DISTINCT
target::text
FROM
ld
)) AND
granted
)
, lcx AS (
SELECT DISTINCT
lr.target
, ld.pid ldp
, ld.mode ldm
, lr.pid lrp
, lr.mode lrm
FROM
ld
JOIN
lr
ON lr.pid <> ld.pid AND
lr.target IS NOT DISTINCT FROM ld.target
)
SELECT
lc.locktype "type"
, CASE lc.locktype
WHEN 'relation' THEN
ARRAY[relation::text]
WHEN 'extend' THEN
ARRAY[relation::text]
WHEN 'page' THEN
ARRAY[relation, page]::text[]
WHEN 'tuple' THEN
ARRAY[relation, page, tuple]::text[]
WHEN 'transactionid' THEN
ARRAY[transactionid::text]
WHEN 'virtualxid' THEN
regexp_split_to_array(virtualxid::text, '/')
WHEN 'object' THEN
ARRAY[classid, objid, objsubid]::text[]
WHEN 'userlock' THEN
ARRAY[classid::text]
WHEN 'advisory' THEN
ARRAY[classid, objid, objsubid]::text[]
END target
, lc.pid = lcx.ldp as locked
, lc.pid
, regexp_replace(lc.mode, 'Lock$', '') "mode"
, lc.granted
, lc.target IS NOT DISTINCT FROM lcx.target as conflict
FROM
lcx
JOIN
locks lc
ON lc.pid IN (lcx.ldp, lcx.lrp);
现在,我们有时间分析甚至进入日志后仅1-2 ms的锁。分析一下
其实,为什么我们要花这么长时间?结果是什么给我们?type | target | locked | pid | mode | granted | conflict
---------------------------------------------------------------------------------------
relation | {225388639} | f | 216547 | AccessShare | t | f
relation | {423576026} | f | 216547 | AccessShare | t | f
advisory | {225386226,194303167,2} | t | 24964 | Exclusive | f | t
relation | {341894815} | t | 24964 | AccessShare | t | f
relation | {416441672} | f | 216547 | AccessShare | t | f
relation | {225964322} | f | 216547 | AccessShare | t | f
...
在本图中,target带有类型的值对我们很有用relation,因为每个这样的值都是表或索引的OID。现在只剩下很少的东西了-学习如何为我们仍然未知的OID询问数据库,以便将它们转换为人类可读的形式:SELECT $1::oid::regclass;
现在,知道了锁的完整“矩阵”以及每个事务将它们叠加在其上的所有对象之后,我们可以得出结论“发生了什么”,以及是什么资源导致了冲突,即使请求被阻止,我们也不为所知。例如,当阻塞请求的执行时间不足以到达日志,但事务在完成后仍处于活动状态并长时间产生问题时,则很容易发生这种情况。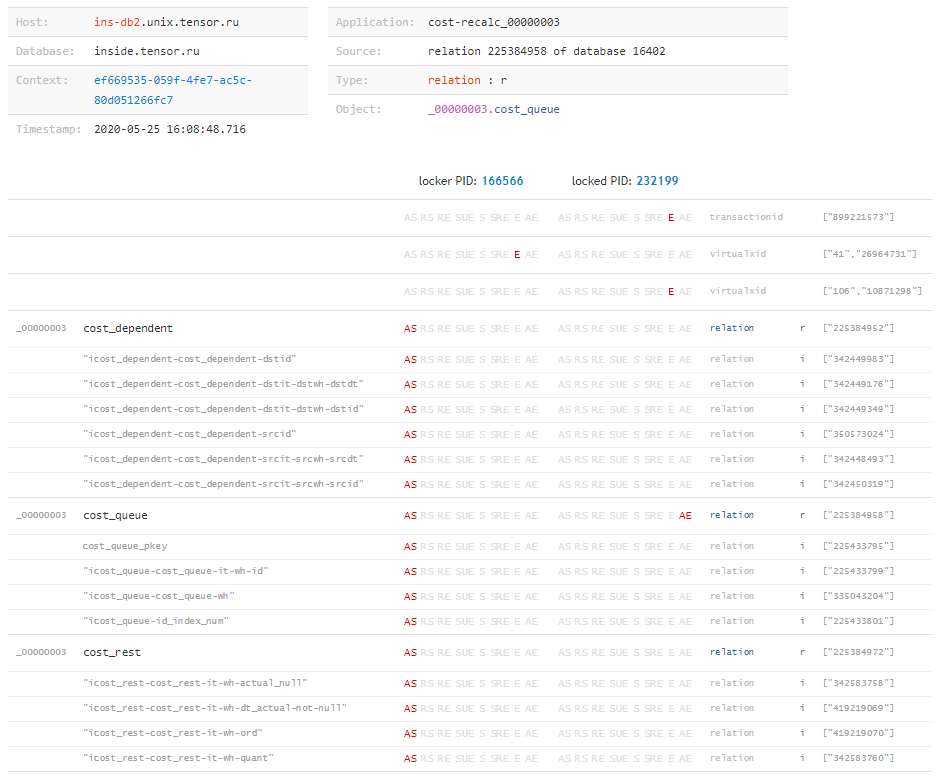 但是关于这一点-在另一篇文章中。
但是关于这一点-在另一篇文章中。“全部靠自己”
同时,我们将收集完整版本的“监视”,一旦日志中出现可疑内容,它将自动删除存档的锁状态:ps uw -U postgres \
| grep [l]ogger \
| awk '{print "/proc/"$2"/fd"}' \
| xargs ls -l \
| grep `cd; psql -U postgres postgres -t -A -c "SELECT CASE WHEN substr(current_setting('log_directory'), 1, 1) = '/' THEN current_setting('log_directory') ELSE current_setting('data_directory') || '/' || current_setting('log_directory') END"` \
| awk '{print $NF}' \
| xargs -l -I{} tail -f {} \
| stdbuf -o0 grep 'still waiting for' \
| xargs -l -I{} date '+%Y%m%d-%H%M%S.%N' \
| xargs -l -I{} psql -U postgres postgres -f detect-lock.sql -o {}-lock.log
然后detect-lock.sql放在最后一个请求。运行-并在其中获得一堆包含所需内容的文件:# cat 20200526-181433.331839375-lock.log
type | target | locked | pid | mode | granted | conflict
---------------+----------------+--------+--------+--------------+---------+----------
relation | {279588430} | t | 136325 | RowExclusive | t | f
relation | {279588422} | t | 136325 | RowExclusive | t | f
relation | {17157} | t | 136325 | RowExclusive | t | f
virtualxid | {110,12171420} | t | 136325 | Exclusive | t | f
relation | {279588430} | f | 39339 | RowExclusive | t | f
relation | {279588422} | f | 39339 | RowExclusive | t | f
relation | {17157} | f | 39339 | RowExclusive | t | f
virtualxid | {360,11744113} | f | 39339 | Exclusive | t | f
virtualxid | {638,4806358} | t | 80553 | Exclusive | t | f
advisory | {1,1,2} | t | 80553 | Exclusive | f | t
advisory | {1,1,2} | f | 80258 | Exclusive | t | t
transactionid | {3852607686} | t | 136325 | Exclusive | t | f
extend | {279588422} | t | 136325 | Exclusive | f | t
extend | {279588422} | f | 39339 | Exclusive | t | t
transactionid | {3852607712} | f | 39339 | Exclusive | t | f
(15 rows)
好吧-坐下来分析...