在本文中,我将讲述并展示一个示例,该示例展示了一个具有最低数据科学经验的人如何能够从论坛中收集数据并使用LDA模型对帖子进行主题建模,并揭示了患有乳糜泻的人们的痛苦话题。去年,我需要紧急提高我在机器学习领域的知识。我是数据科学,机器学习和AI的产品经理,或者是技术产品经理AI / ML的产品经理。仅仅针对非技术领域用户的项目中的业务技能和产品开发能力是远远不够的。您需要了解ML行业的基本技术概念,并在必要时能够自己编写示例来演示产品。大约5年以来,我一直在开发前端项目,在JS和React上开发复杂的Web应用程序,但是我从未涉及过机器学习,笔记本电脑和算法。因此,当我看到来自Otus的消息,他们毫不犹豫地开设了为期五个月的机器学习实验课程时,我决定接受试用测试并上了课程。在五个月的时间里,每周有两个小时的讲座和作业。在这里,我了解了ML的基础知识:各种回归算法,分类,模型集成,梯度提升甚至受到轻微影响的云技术。原则上,如果您认真听每一堂课,那么就有足够的例子和作业说明。但是,有时候,像在其他任何编码项目中一样,我不得不转向文档。考虑到我全职工作,学习起来非常方便,因为我可以随时修改在线讲座的记录。在本课程培训结束时,每个人都必须参加最后的项目。这个项目的主意是自发产生的,那时我开始在斯坦福大学进行创业培训,在那里我加入了为患有腹腔不耐受症的人开展该项目的团队。在市场研究期间,我很想知道什么担心,他们在说什么,具有此功能的人抱怨什么。随着研究的进行,我在celiac.com上找到了一个论坛与大量有关乳糜泻的材料。显然,手动滚动并阅读超过10万篇文章是不切实际的。因此,我想到了这个主意,运用我在本课程中获得的知识:收集来自某个主题的论坛中的所有问题和评论,并使用每个主题中最常用的词进行主题建模。步骤1.从论坛收集数据
该论坛包括许多不同大小的主题。该论坛总共有大约115,000个主题和大约100万个帖子,并对它们进行了评论。我对特定的子主题“应付乳糜泻”感兴趣,字面意思是“应付乳糜泻”,如果在俄语中,则意味着更多的“继续诊断乳糜泻并以某种方式应对困难”。该子主题包含大约175,000条评论。数据下载分为两个阶段。首先,我必须浏览该主题下的所有页面,并收集所有文章的所有链接,以便在下一步中,我已经可以收集评论。url_coping = 'https://www.celiac.com/forums/forum/5-coping-with-celiac-disease/'
由于论坛原来已经很老了,所以我很幸运,并且该站点没有任何安全问题,因此,要收集数据,只需使用来自fake_useragent,Beautiful Soup库中的User-Agent组合即可使用html标记并知道页面数:
def get_pages_count(url):
response = requests.get(url, headers={'User-Agent': UserAgent().chrome})
soup = BeautifulSoup(response.content, 'html.parser')
last_page_section = soup.find('li', attrs = {'class':'ipsPagination_last'})
if (last_page_section):
count_link = last_page_section.find('a')
return int(count_link['data-page'])
else:
return 1
coping_pages_count = get_pages_count(url_coping)
然后下载每个页面的HTML DOM,以使用BeautifulSoup Python库轻松地从其中提取数据。
def retrieve_pages(pages_count, url):
pages = []
for page in range(pages_count):
response = requests.get('{}page/{}'.format(url, page), headers={'User-Agent': UserAgent().chrome})
soup = BeautifulSoup(response.content, 'html.parser')
pages.append(soup)
return pages
coping_pages = retrieve_pages(coping_pages_count, url_coping)
要下载数据,我需要确定必要的分析字段:在DOM中找到这些字段的值并将其保存在字典中。我本人来自前端背景,因此对家庭和对象的工作对我来说微不足道。def collect_post_info(pages):
posts = []
for page in pages:
posts_list_soup = page.find('ol', attrs = {'class': 'ipsDataList'}).findAll('li', attrs = {'class': 'ipsDataItem'})
for post_soup in posts_list_soup:
post = {}
post['id'] = uuid.uuid4()
title_section = post_soup.find('span', attrs = {'class':'ipsType_break ipsContained'})
if (title_section):
title_section_a = title_section.find('a')
post['title'] = title_section_a['title']
post['url'] = title_section_a['data-ipshover-target']
author_section = post_soup.find('div', attrs = {'class':'ipsDataItem_meta'})
if (author_section):
author_section_a = post_soup.find('a')
author_section_time = post_soup.find('time')
post['author'] = author_section_a['data-ipshover-target']
post['last_action'] = author_section_time['datetime']
stats_section = post_soup.find('ul', attrs = {'class':'ipsDataItem_stats'})
if (stats_section):
stats_section_replies = post_soup.find('span', attrs = {'class':'ipsDataItem_stats_number'})
if (stats_section_replies):
post['replies'] = stats_section_replies.getText()
stats_section_views = post_soup.find('li', attrs = {'class':'ipsType_light'})
if (stats_section_views):
post['views'] = stats_section_views.find('span', attrs = {'class':'ipsDataItem_stats_number'}).getText()
posts.append(post)
return posts
我总共收集了约15,450个关于该主题的帖子。coping_posts_info = collect_post_info(coping_pages)
现在可以将它们转移到DataFrame中,以便将它们精美地放置在其中,同时将它们保存在一个csv文件中,这样一来,如果笔记本意外损坏或我意外在其中重新定义了一个变量,就不必再等待从站点收集数据了。df_coping = pd.DataFrame(coping_posts_info,
columns =['title', 'url', 'author', 'last_action', 'replies', 'views'])
df_coping['replies'] = df_coping['replies'].astype(int)
df_coping['views'] = df_coping['views'].apply(lambda x: int(x.replace(',','')))
df_coping.to_csv('celiac_forum_coping.csv', sep=',')
在收集了帖子集之后,我开始收集评论本身。def collect_postpage_details(pages, df):
comments = []
for i, page in enumerate(pages):
articles = page.findAll('article')
for k, article in enumerate(articles):
comment = {
'url': df['url'][i]
}
if(k == 0):
comment['question'] = 1
else:
comment['question'] = 0
comment_section = article.find('div', attrs = {'class':'ipsComment_content'})
if (comment_section):
comment_section_p = comment_section.find('p')
if(comment_section_p):
comment['comment'] = comment_section_p.getText()
comment['date'] = comment_section.find('time')['datetime']
author_section = article.find('strong')
if (author_section):
author_section_url = author_section.find('a')
if (author_section_url):
comment['author'] = author_section_url['data-ipshover-target']
comments.append(comment)
return comments
coping_data = collect_postpage_details(coping_comments_pages, df_coping)
df_coping_comments.to_csv('celiac_forum_coping_comments_1.csv', sep=',')
步骤2数据分析和主题建模
在上一步中,我们从论坛收集了数据,并以153777行问题和评论的形式接收了最终数据。但是只是收集的数据并不有趣,所以我想做的第一件事就是非常简单的分析:我得出了前30个最受欢迎的主题和30个最受关注的主题的统计信息。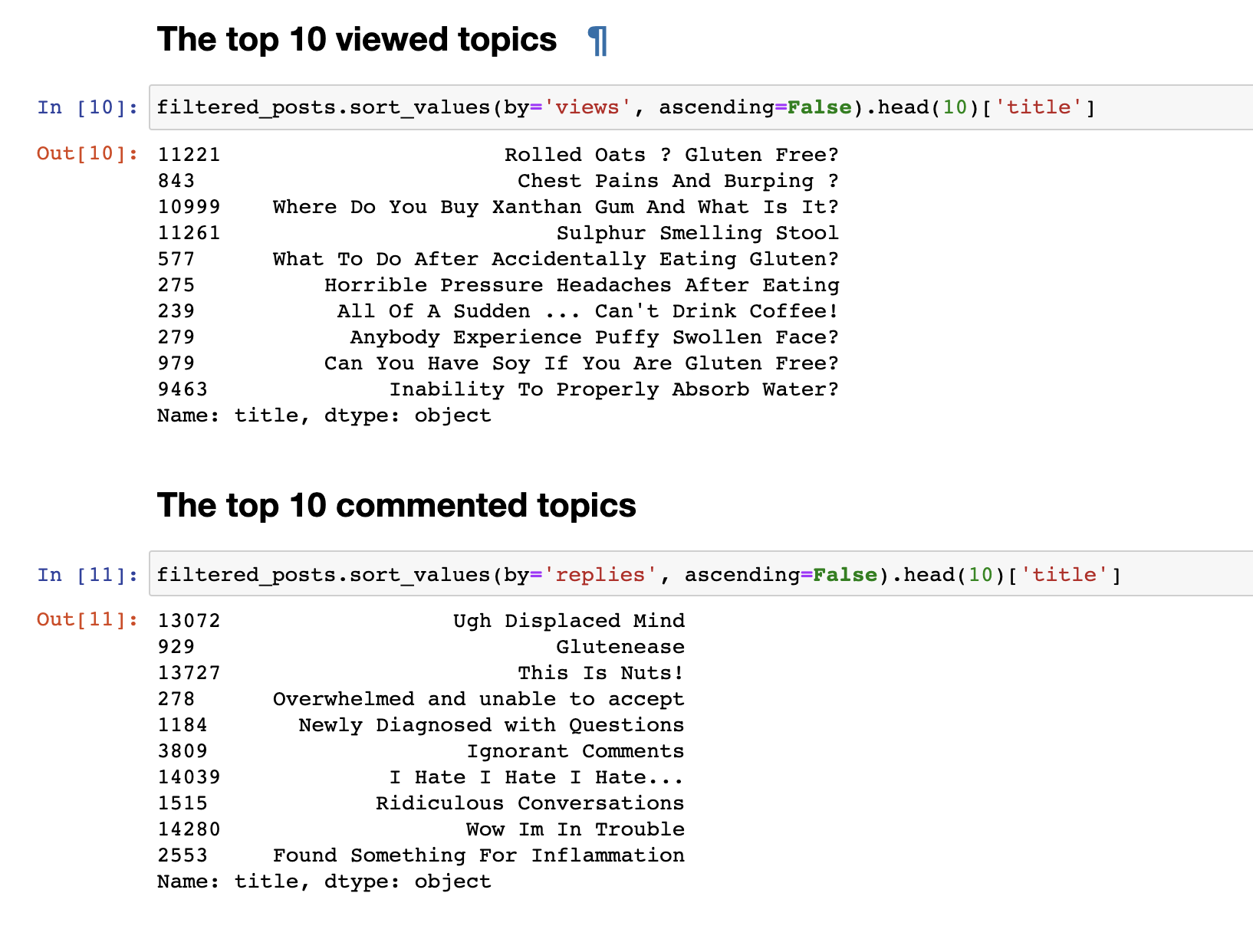 观看次数最多的帖子与评论最多的帖子不一致。即使乍一看,评论帖子的标题也很引人注目。他们的名字更让人感动:“我讨厌,我讨厌,我讨厌”或“ 傲慢的评论”或“哇,我有麻烦了。”观看最多的人的问题格式是:“我可以吃大豆吗?”,“为什么我不能正确吸收水?”其他。我们进行了简单的文本分析。要直接进行更复杂的分析,您需要准备数据本身,然后再将其提交给LDA模型的输入以按主题进行细分。为此,请删除少于30个单词的评论,以过滤掉垃圾邮件和毫无意义的简短评论。我们将它们转换为小写。
观看次数最多的帖子与评论最多的帖子不一致。即使乍一看,评论帖子的标题也很引人注目。他们的名字更让人感动:“我讨厌,我讨厌,我讨厌”或“ 傲慢的评论”或“哇,我有麻烦了。”观看最多的人的问题格式是:“我可以吃大豆吗?”,“为什么我不能正确吸收水?”其他。我们进行了简单的文本分析。要直接进行更复杂的分析,您需要准备数据本身,然后再将其提交给LDA模型的输入以按主题进行细分。为此,请删除少于30个单词的评论,以过滤掉垃圾邮件和毫无意义的简短评论。我们将它们转换为小写。
def filter_text_words(text, min_words = 30):
text = str(text)
return len(text.split()) > 30
filtered_comments = filtered_comments[filtered_comments['comment'].apply(filter_text_words)]
comments_only = filtered_comments['comment']
comments_only= comments_only.apply(lambda x: x.lower())
comments_only.head()
删除不必要的停用词以清除我们的文本选择stop_words = stopwords.words('english')
def remove_stop_words(tokens):
new_tokens = []
for t in tokens:
token = []
for word in t:
if word not in stop_words:
token.append(word)
new_tokens.append(token)
return new_tokens
tokens = remove_stop_words(data_words)
我们还添加二元组并形成一袋单词以突出显示稳定的短语,例如gluten_free,support_group和其他在分组后具有一定含义的短语。
bigram = gensim.models.Phrases(tokens, min_count=5, threshold=100)
bigram_mod = gensim.models.phrases.Phraser(bigram)
bigram_mod.save('bigram_mod.pkl')
bag_of_words = [bigram_mod[w] for w in tokens]
with open('bigrams.pkl', 'wb') as f:
pickle.dump(bag_of_words, f)
现在,我们终于准备好直接训练LDA模型本身。
id2word = corpora.Dictionary(bag_of_words)
id2word.save('id2word.pkl')
id2word.filter_extremes(no_below=3, no_above=0.4, keep_n=3*10**6)
corpus = [id2word.doc2bow(text) for text in bag_of_words]
lda_model = gensim.models.ldamodel.LdaModel(
corpus,
id2word=id2word,
eval_every=20,
random_state=42,
num_topics=30,
passes=5
)
lda_model.save('lda_default_2.pkl')
topics = lda_model.show_topics(num_topics=30, num_words=100, formatted=False)
在培训结束时,我们最终获得了所形成主题的结果。我在这篇文章的结尾处附加了该内容。for t in range(lda_model.num_topics):
plt.figure(figsize=(15, 10))
plt.imshow(WordCloud(background_color="white", max_words=100, width=900, height=900, collocations=False)
.fit_words(dict(topics[t][1])))
plt.axis("off")
plt.title("Topic #" + themes_headers[t])
plt.show()
可能值得注意的是,这些主题在内容上截然不同。根据他们的说法,很清楚人们在谈论哪些腹腔不宽容症。基本上,关于食物,去餐馆,被麸质污染的食物,可怕的痛苦,治疗,去看医生,家庭,误解以及其他人们每天因其问题而不得不面对的事情。就这样。谢谢大家的关注。我希望您发现此材料有趣而有用。但是,由于我不是DS开发人员,所以请不要严格判断。如果有什么要补充或改进的地方,我总是欢迎建设性的批评,写。查看30个主题