来自Google Blog编辑器:您是否想知道Google Cloud技术解决方案(TSE)工程师如何处理您的技术支持电话? TSE技术支持工程师的职责是检测并解决用户发现的问题的根源。其中一些问题非常简单,但是有时您会遇到上诉,需要立即引起数位工程师的注意。在本文中,TSE的一名员工将向我们介绍他最近的实践中的一个非常棘手的问题- 丢失DNS数据包的情况。在这个故事的过程中,我们将看到工程师如何设法解决这种情况,以及他们在消除错误的过程中学到了什么新知识。我们希望这个故事不仅可以告诉您一个根深蒂固的错误,还可以帮助您理解提交支持Google Cloud的请求时发生的过程。 故障排除是一门科学,也是一门艺术。一切始于建立有关系统非标准行为原因的假设,然后再测试其强度。但是,在提出假设之前,我们必须清楚地识别并准确地提出问题。如果这个问题听起来太含糊,那么您必须适当地分析所有内容;这是故障排除的“艺术”。在Google Cloud的上下文中,由于Google Cloud努力保证其用户的隐私,因此此类过程有时会很复杂。因此,TSE工程师无权编辑系统,也无法像用户一样广泛地查看配置。因此,为了检验我们的任何假设,我们(工程师)无法快速修改系统。一些用户认为,我们将像汽车服务中的机制一样对所有问题进行修复,并仅向我们发送虚拟机的ID,而实际上,该过程以对话格式进行:收集信息,生成和确认(或驳斥)假设,并最终解决问题是建立在与客户的沟通上的。
故障排除是一门科学,也是一门艺术。一切始于建立有关系统非标准行为原因的假设,然后再测试其强度。但是,在提出假设之前,我们必须清楚地识别并准确地提出问题。如果这个问题听起来太含糊,那么您必须适当地分析所有内容;这是故障排除的“艺术”。在Google Cloud的上下文中,由于Google Cloud努力保证其用户的隐私,因此此类过程有时会很复杂。因此,TSE工程师无权编辑系统,也无法像用户一样广泛地查看配置。因此,为了检验我们的任何假设,我们(工程师)无法快速修改系统。一些用户认为,我们将像汽车服务中的机制一样对所有问题进行修复,并仅向我们发送虚拟机的ID,而实际上,该过程以对话格式进行:收集信息,生成和确认(或驳斥)假设,并最终解决问题是建立在与客户的沟通上的。正在考虑的问题
今天,我们的故事结局不错。成功解决提出的案例的原因之一是对该问题的非常详细和准确的描述。在下面,您可以看到第一张票证的副本(已编辑,以便隐藏机密信息): 此消息为我们提供了许多有用的信息:
此消息为我们提供了许多有用的信息:- 指定的虚拟机
- 指出了问题-DNS无法正常工作
- 指出问题在何处显现-VM和容器
- 指出了用户识别问题所采取的步骤。
该呼吁被注册为“ P1:关键影响-生产中无法使用的服务”,这意味着根据“跟随太阳”计划对情况进行24/7的持续监控(该链接可以更详细地了解用户呼叫的优先级),并由一个技术支持团队进行传输在每个时区移动 实际上,当问题到达我们在苏黎世的团队时,她设法绕过了地球。此时,用户已采取措施以减少后果,但是,由于仍未找到主要原因,因此他担心重复出现这种情况。到苏黎世机票时,我们已经掌握了以下信息:- 内容
/etc/hosts - 内容
/etc/resolv.conf - 结论
iptables-save - 该命令编译的
ngreppcap文件
有了这些数据,我们就可以开始“调查”和故障排除阶段了。我们的第一步
首先,我们检查了元数据服务器的日志和状态,并确保其正常运行。元数据服务器以IP地址169.254.169.254进行响应,并负责控制域名。我们还仔细检查了防火墙是否可以在VM上正常工作,并且不会阻止数据包。这是一个奇怪的问题:nmap测试驳斥了我们有关UDP数据包丢失的主要假设,因此我们在精神上推论出了更多选择和检查方法:- 数据包是否有选择地消失?=>检查iptables规则
- MTU是否太小?=>检查输出
ip a show - 问题仅影响UDP数据包还是TCP?=>开走
dig +tcp - 是否返回生成的挖掘数据包?=>开走
tcpdump - libdns是否正常工作?=>开车离开
strace以验证双向数据包传输
在这里,我们决定给用户打电话以进行实时故障排除。在通话过程中,我们设法验证了几件事:- 经过多次检查,我们从原因列表中排除了iptables规则。
- 我们检查网络接口和路由表,并仔细检查MTU
- 我们发现
dig +tcp google.com(TCP)正常运行,但dig google.com(UDP)无效 - 已经
tcpdump运行,而它的工作原理dig,我们发现,被返回的UDP数据包 - 我们跑
strace dig google.com,看看如何正确地掏电话sendmsg()和recvms(),但是,二是超时中断
不幸的是,这种转变即将结束,我们被迫将问题转移到下一个时区。但是,这种呼吁引起了我们团队的兴趣,一位同事建议使用scrapy的Python模块创建源DNS数据包。from scapy.all import *
answer = sr1(IP(dst="169.254.169.254")/UDP(dport=53)/DNS(rd=1,qd=DNSQR(qname="google.com")),verbose=0)
print ("169.254.169.254", answer[DNS].summary())
该片段创建DNS数据包,并将请求发送到元数据服务器。用户运行该代码,返回DNS响应,然后应用程序将其接收,这将在网络级别确认是否存在问题。在下一次“环游世界”之后,上诉将返回给我们的团队,我将其完全翻译成我自己,相信如果上诉不再从一个地方到另一个地方转圈,将会为用户带来更多便利。同时,用户请同意提供系统映像的快照。这真是个好消息:自己测试系统的能力大大加快了故障排除的速度,因为您不再需要让用户运行命令,向我发送结果并对其进行分析,我就可以自己做一切!同事们开始有点羡慕我。午餐时,我们讨论了上诉,但是没人知道发生了什么。幸运的是,用户本人已经采取了缓解措施,因此并不着急,因此我们有时间来解决问题。并且由于我们具有图像,因此我们可以进行任何我们感兴趣的测试。精细!回去一步
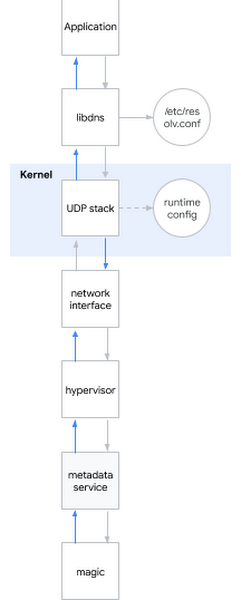
在系统工程师的面试中,最受欢迎的问题之一是:“当您ping www.google.com时会发生什么?” 问题是豪华的,因为需要从外壳到用户空间,再到系统核心,再到网络都描述候选人。我微笑:有时候面试问题在现实生活中也很有用……我决定将eychar问题应用于当前问题。粗略地说,当您尝试确定DNS名称时,会发生以下情况:- 应用程序调用系统库,例如libdns
- libdns检查系统配置,它应该使用哪个DNS服务器(在该图中为169.254.169.254,元数据服务器)
- libdns使用系统调用来创建UDP套接字(SOKET_DGRAM)并在两个方向上通过DNS请求发送UDP数据包
- 使用sysctl接口,您可以配置内核级UDP堆栈
- 内核与硬件交互以通过网络接口通过网络传输数据包
- 系统管理程序在数据包与元数据服务器联系时将其捕获并传递给元数据服务器
- 元数据服务器通过其巫术确定DNS名称,并以相同的方式返回答案
 让我提醒您我们已经设法考虑了哪些假设:假设:库损坏
让我提醒您我们已经设法考虑了哪些假设:假设:库损坏- 测试1:在系统中运行strace,检查dig是否导致正确的系统调用
- 结果:正确的系统调用被调用
- 测试2:通过反复检查来确定是否可以绕过系统库确定名称
- 结果:我们可以
- 测试3:在libdns软件包和md5sum库文件上运行rpm –V
- 结果:库代码与工作操作系统中的代码完全相同
- 测试4:在没有这种行为的情况下,将用户的根系统的映像挂载到VM上,运行chroot,查看DNS是否工作
- 结果:DNS正常工作
根据测试得出的结论:问题不在库中假设:DNS设置错误- 测试1:运行dig后,检查tcpdump并查看DNS数据包是否正确发送和返回
- 结果:数据包正确传输
- 测试2:重新检查服务器,
/etc/nsswitch.conf然后/etc/resolv.conf - 结果:一切正确
基于测试的结论:问题不在DNS配置假设中:内核损坏- 测试:安装新内核,验证签名,重新启动
- 结果:类似行为
基于测试的结论:内核未损坏假设:用户网络(或虚拟机管理程序的网络接口)的行为不正确- 测试1:检查防火墙设置
- 结果:防火墙在主机和GCP上都传递DNS数据包
- 测试2:拦截流量并跟踪DNS查询的传输和返回的正确性
- 结果:tcpdump确认主机已收到返回数据包
基于测试的结论:问题不在网络中假设:元数据服务器不起作用- 测试1:检查元数据服务器日志中是否存在异常
- 结果:日志中没有异常
- 测试2:通过绕过元数据服务器
dig @8.8.8.8 - 结果:即使不使用元数据服务器,也会违反权限
基于测试的结论:问题不在元数据服务器中底线:我们测试了除运行时设置以外的所有子系统!深入内核运行时设置
要配置内核运行时,可以使用命令行选项(grub)或sysctl接口。我看了一下,/etc/sysctl.conf只想到,我发现了一些自定义设置。感觉好像我已经抓住了某些东西,我取消了所有非网络或非tcp设置,而保留了山脉设置net.core。然后我转到了VM拥有主机权限的地方,并开始一个又一个地应用虚拟机损坏的虚拟机设置,直到遇到犯罪为止:net.core.rmem_default = 2147483647
这是一个破坏DNS的配置!我找到了犯罪手段。但是为什么会这样呢?我仍然需要动力。设置DNS数据包缓冲区的基本大小通过进行net.core.rmem_default。典型值在200KiB范围内变化,但是,如果服务器收到大量DNS数据包,则可以增加缓冲区的大小。例如,如果在新程序包到达时缓冲区已满,则由于应用程序处理速度不够快,您将开始丢失数据包。我们的客户端正确地增加了缓冲区大小,因为他担心数据丢失,因为他使用该应用程序通过DNS数据包收集度量。他设置的值是最大可能的值:2 31 -1(如果您设置2 31,则内核将返回“ INVALID ARGUMENT”)。突然,我意识到了为什么nmap和scapy可以正常工作:他们使用了原始套接字!原始套接字与常规套接字不同:它们绕过iptables工作,并且没有缓冲!但是,为什么“缓冲区太大”会引起问题?它显然不能按预期工作。此时,我可以在多个内核和多个发行版上重现该问题。该问题已在3.x内核中显现出来,现在也已在5.x内核中显现出来。确实,在启动时sysctl -w net.core.rmem_default=$((2**31-1))
DNS已停止工作。我开始通过一种简单的二进制搜索算法搜索工作值,发现系统可以使用2147481343,但是这个数字对我来说毫无意义。我邀请客户尝试使用此号码,他回答说该系统可与google.com一起使用,但在其他域上仍然出现错误,因此我继续进行调查。我安装了dropwatch,这是我之前应该使用的工具:它显示了软件包在内核中的确切位置。该职能有罪udp_queue_rcv_skb。我下载了内核源代码,并添加了一些功能 printk来跟踪软件包的具体位置。我很快找到了合适的条件if,然后只是盯着他看了一会儿,因为那时所有的一切最终都融为一体:2 31 -1,一个毫无意义的数字,一个闲置的域……这是一段代码__udp_enqueue_schedule_skb:if (rmem > (size + sk->sk_rcvbuf))
goto uncharge_drop;
注意:rmem 具有类型intsize 类型为u16(无符号十六位整数),并存储数据包大小sk->sk_rcybuf 是int类型,并存储缓冲区的大小,根据定义,该缓冲区的大小等于 net.core.rmem_default
当sk_rcvbuf接近2 31时,对数据包大小求和可能会导致整数溢出。并且由于它是一个int值,因此它的值变为负数,因此当该条件为false时该条件变为true(有关更多信息,请参阅参考资料)。可通过以下简单方法纠正错误:将强制转换为unsigned int。我应用了补丁程序并重新启动了系统,然后DNS重新开始工作。胜利的味道
我将调查结果转发给客户端,并发送了LKML内核补丁。我很满意:每个难题都融为一体,我可以准确地解释为什么我们观察到我们观察到的东西,最重要的是,我们能够通过共同努力找到解决问题的方法!值得一提的是,事实证明这种情况很少见,而且幸运的是,这种复杂的电话很少从我们的用户那里收到。
