大家好,我叫Fedor Indukaev,我是Yandex.Routing的分析师。今天,我想向您介绍可视化相交集的任务,以及我为解决该问题而创建的开源Python包。在此过程中,我们将学习维恩图和欧拉图有何不同,熟悉顺序分配服务,并切向触及生物信息学等科学领域。我们将从简单到更复杂。走!它是关于什么的,为什么需要它?
几乎每个从事探索性数据分析的人都必须至少回答一次此类问题的答案:- 有一个具有几个独立二进制变量的数据集。他们中的哪些经常在一起?
- 有几个具有相同性质的对象的表具有ID。来自不同表的ID集如何相关-每个表都有其自己的ID,或者所有表中的ID都相同,或者这些集有所不同,但只是略有不同?
- 有几种。哪些生物具有相似的基因或蛋白质集?
- 如果类别重叠,如何绘制像饼图一样的图?(确实,这并不是每个人都遇到的问题:请参见下图中的百分比。)
所有这些问题都可以简化为相同的措词。听起来像是:给出了几个有限的集合,可能彼此相交,我们需要评估它们的相对位置-也就是说,要了解它们的相交程度。我们将专注于可视化和软件工具来帮助解决此问题。维恩图
我认为这种带有两个或三个圆圈的图纸对每个人都是熟悉的,不需要解释:维恩图的一个特点是它是静态的。其上的数字相等且对称放置。该图显示了所有可能的交点,即使其中大多数实际上是空的。此类图适合于说明其确切尺寸未知或不重要的抽象概念或集。这里的基本信息不包含在时间表中,而是包含在签名中。
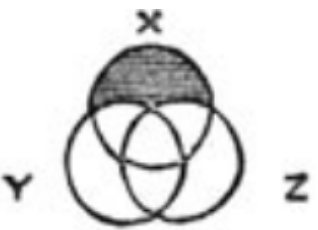 这就是英国数学家和哲学家约翰·文恩(John Venn)所构思的。在他1880年的文章中他提出了以图形方式显示逻辑命题的图表。例如,语句“任何X是Y或Z”在右边给出了一个图(该插图取自原始文章)。不满足要求的区域用黑色阴影阴影:那些既不是Y也不是Z的X。本文的主要信息是,不改变图形形状和排列的静态图形比动态Euler图更适合逻辑目的。将走到下面。显然,在数据分析中,维恩图的范围是有限的。它们仅提供定性信息,而不提供定量信息,既不反映交叉点的大小,也不反映其空虚。如果这不能阻止您,则可以使用venn软件包,该软件包可为套。对于每个没有一两个典型的图片,只有签名会有所不同:如果我们想更动态地依赖数据,则应注意另一种方法:欧拉图。
这就是英国数学家和哲学家约翰·文恩(John Venn)所构思的。在他1880年的文章中他提出了以图形方式显示逻辑命题的图表。例如,语句“任何X是Y或Z”在右边给出了一个图(该插图取自原始文章)。不满足要求的区域用黑色阴影阴影:那些既不是Y也不是Z的X。本文的主要信息是,不改变图形形状和排列的静态图形比动态Euler图更适合逻辑目的。将走到下面。显然,在数据分析中,维恩图的范围是有限的。它们仅提供定性信息,而不提供定量信息,既不反映交叉点的大小,也不反映其空虚。如果这不能阻止您,则可以使用venn软件包,该软件包可为套。对于每个没有一两个典型的图片,只有签名会有所不同:如果我们想更动态地依赖数据,则应注意另一种方法:欧拉图。欧拉图
与维恩图不同,此处选择图形在平面上的形状和位置以显示集合或概念的关系。如果某个交集是空的,则数字也尽可能不重叠,如有关动植物的数字所示。请注意,讲座中有关该问题的图与其他两个图不同。重要的是,不仅图形的位置重要,而且交叉点的大小也很重要-所有幽默都包含在其中。这个想法可以用于我们的任务。取两三套,并画出面积与这些套的大小成比例的圆。然后,我们将尝试在平面上排列圆,使重叠区域也与相交的大小成比例。这正是软件包的功能(尽管其名称)matplotlib-venn: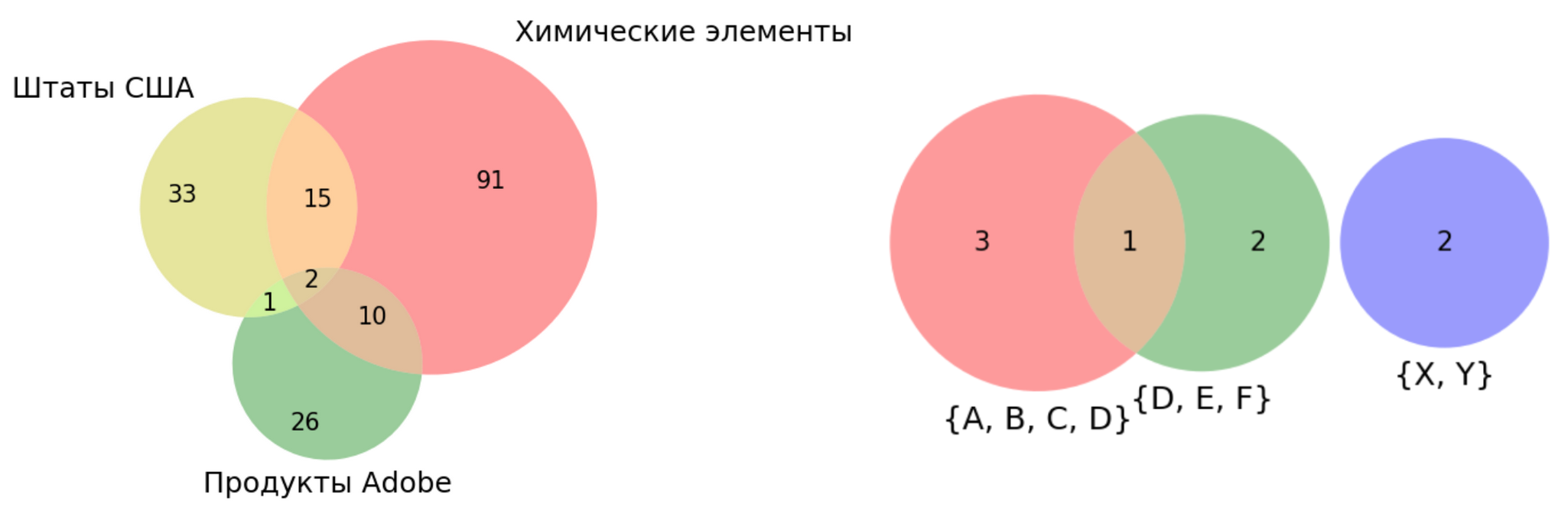 按比例绘制两组非常容易。但是已经三点了,该方法可能会失败。例如,让三个集合之一恰好是另两个集合的交集:图片看起来不太好,出现了一个奇怪的区域,编号为0。但是没有什么奇怪的,因为两个圆的交点不能表示为一个圆。这是一个更加令人沮丧的示例:两个集合及其对称差(联合减去交集):原来是完全奇怪的事情:注意有多少个零!如果我们使用矩形而不是圆形(矩形的交点也是矩形),则第一个示例仍然可以保存,而第二个示例至少需要非凸形状。嗯,超过三套,此软件包原则上不支持。我不知道其他用于开发Euler-Venn方法的Python公共工具,而我自己的实验历史将会更进一步。但是在继续之前,我将做一点题外话,解释为什么我什至承担了可视化场景的任务。
按比例绘制两组非常容易。但是已经三点了,该方法可能会失败。例如,让三个集合之一恰好是另两个集合的交集:图片看起来不太好,出现了一个奇怪的区域,编号为0。但是没有什么奇怪的,因为两个圆的交点不能表示为一个圆。这是一个更加令人沮丧的示例:两个集合及其对称差(联合减去交集):原来是完全奇怪的事情:注意有多少个零!如果我们使用矩形而不是圆形(矩形的交点也是矩形),则第一个示例仍然可以保存,而第二个示例至少需要非凸形状。嗯,超过三套,此软件包原则上不支持。我不知道其他用于开发Euler-Venn方法的Python公共工具,而我自己的实验历史将会更进一步。但是在继续之前,我将做一点题外话,解释为什么我什至承担了可视化场景的任务。关于构建最佳路线的API的几点说明
就像我说的,我们部门进行Yandex.routing。我们的一项服务可帮助在线商店,送货服务以及包括物流在内的任何公司建立最佳运输路线。客户端通过发送API请求与服务进行交互。每个请求都包含具有坐标,交货间隔等的订单(交货点)列表,以及需要交货的机器列表。我们的算法会消化所有这些数据,并在考虑到交通拥堵,车辆通行能力等因素的前提下产生最佳路线。像流行的Yandex B2C服务一样,我们有数百个客户,而不是数百万个客户。因此,每个客户的幸福对我们尤为重要,此外,有可能给予他更多的关注并更深入地研究他的任务。为此,特别有用的是拥有一些工具来帮助您了解客户向我们发送了哪些请求。我举一个例子。假设有一天,从Romashka收到24个请求。这可能意味着:- 他们在全国各地工作,并为24个仓库建立了24条路线集。
- 只有一个仓库,但是客户不断收到新订单。要考虑它们,您需要每小时更新一次路由。
- 来自客户端的请求形成了一个错误,由于该错误,他无法连续24次获得对单个任务的良好解决方案。
先验的是完全不清楚真正发生了什么。但是,如果我们可以快速比较24套订单ID,情况将立即变得清晰起来。如果它们根本不相交-这是第一种情况(24个仓库)。如果集合从一个流向另一个,则第二个(路由的计划更新)。好吧,可能有24套几乎完全相同的迹象表明客户需要帮助。简化任务:从圆形到条纹
一段时间以来,我使用了matplotlib-venn软件包,但是“两个半”集的限制当然令人沮丧。考虑到解决此问题的不同方法,我决定尝试从圆形和通常为二维的图元过渡到一维的水平条纹。然后可以将交叉点垂直叠加,如下所示:眼睛感觉到的线性尺寸要好于正方形,构造不需要复杂的三角函数,并且沿Y轴的集合间距使图形的过载程度降低。此外,我们的第一个失败的示例(两个集合以及它们的交集作为第三集合)本身就得到了改进:对称差异的问题仍然存在。但是我们将以戈尔迪结作为亚历山大大帝来对待它:让我们在必要时将其中之一切成两部分:红色集用两个条纹而不是两个条纹描绘,但这没什么不对。两者的高度相同且颜色相同,因此在视觉上可以很好地阅读它们的统一。很容易验证以这种方式,只要精确遵守比例,就可以描绘出任意三个集合。因此,问题在于等于2或3可以视为已解决。这种方法的另一个优点是可以很容易地应用于任意数量的集合,我们将很快进行处理。所有需要的不是解决一个,而是解决任意数量的换行符。但是首先,是一些简单的组合。一点算术
让我们看一下具有三个圆圈的维恩图,并计算圆圈彼此之间划分的区域数:每个区域是由其位于三个圆的内部还是外部确定的,但是外部区域是多余的。我们总计。当所有圆圈重合时,三个圆圈的其他位置最多可以提供1个以内的区域。将此参数从圈子转移到集合,我们得到任何套互相打破不超过这样的基本零件。重要的是,这些部分中的每个部分要么全部包含,要么不全部包含在任何这些组中。在我们的新图中,列就是这样的基本部分。更多套!
因此,我们想将这些方案推广到实际情况 :对于 集,我们得到一个网格行和列,因为我们刚才计算。仍然需要遍历每行并填写与该组中包含的基本部分相对应的单元格。为了说明,以一个五组模型为例:programming_languages = {'python', 'r', 'c', 'c++', 'java', 'julia'}
geographic_places = {'java', 'buffalo', 'turkey', 'moscow'}
letters = {'a', 'r', 'c', 'i', 'z'}
human_names = {'robin', 'julia', 'alice', 'bob', 'conrad'}
animals = {'python', 'buffalo', 'turkey', 'cat', 'dog', 'robin'}
如上所述,我们得到下图:读起来很差:线条上的空隙太多了,所有的东西都切成卷心菜。但是,由于我们不喜欢休息,为什么不直接设置使休息最小化的任务呢?毕竟,列的顺序微不足道,没有什么可以阻止我们根据需要重新排列它们。我们来解决这个问题:找到给定的零矩阵和零矩阵的列的排列,并且在行中的单位之间的间隙最小。正如我稍后将要告诉的,这实际上是汉明度量标准中旅行推销员的任务;它是NP-complete的。如果列数很少(例如,不超过12个),则可以通过穷举搜索找到必要的排列,否则,您需要求助于某些启发式方法。我们应用一个简单的贪婪算法。让我们将两列的相似度称为这些列中值重合的位置数。将两个最相似的列放在一起。接下来,我们将急于在这对货币的两侧建立顺序。在其余的列中,我们找到与两列之一最相似的一列,将其附加-依此类推。以下是应用该算法之前和之后的数字:它变得更好了。正是在这个阶段,我觉得有用的东西正在出现。经过实验,我注意到该算法倾向于停留在局部最小值。可以通过简单的随机化来很好地处理此问题:我们稍微干扰列的相似性,运行算法,重复1000次,选择1000个最佳解决方案。结果已经是相当有效的工具,但是您可以向其中添加更多有用的信息。我还制作了另外两个图表:右侧显示原始集合的大小,每个交叉点的顶部显示了其中的集合数量。实际上,这不过是行(在右侧)和列(在顶部)的二进制矩阵之和:我还添加了根据与列相同的原理对集合本身(即行)进行排序的选项:最大程度减少中断次数。结果,类似的集合被分组:在工作中的应用
自然,首先,我开始使用新工具来完成创建任务:检查客户对我们API的请求。结果令我高兴。因此,例如,一位客户的工作日看起来像。每行是对API的请求(其中包含订单的许多ID),中间的签名是发送请求的时间:全天全貌。在10:49,间隔时间为23秒的客户物流发送了两个相同的请求,共129个订单。从11:25到15:53有三个请求,它们具有152个订单的不同集合。在16:43,有114个订单到达了第三个唯一请求。为了解决此请求,物流师随后应用了四个手动编辑(可以通过我们的UI来完成)。这就是理想的一天:所有独立任务都解决了一次,不需要更正或选择参数:下面是一个示例,该示例是客户每15-30分钟发送一次请求,以考虑实时收到的订单:即使在50个集合上,该算法也清楚地揭示了数据中隐藏的结构。您可以看到如何从请求中删除旧订单并在执行时将其替换为新订单。简而言之,我完全可以通过创建的工具满足我的工作需要。香蕉规模(不是真的)
在研究现有方法时,我几次遇到《自然》杂志的一幅图画,该图画比较了香蕉和其他五种植物的基因组:请注意,区域的大小与13和149个元素(箭头所示)的关系如何:第二个要小几倍。因此,没有任何比例问题。当然,我想尝试一下这些数据,但是结果并不令人满意:该图看起来很乱。原因是,首先,几乎所有交集(可能的63个交集)都是非空的,其次,交集的大小相差三个数量级。结果,数字注释变得非常拥挤。为了使我的工具方便于此类数据,我添加了几个参数。一种允许您部分对齐列宽,另一种则可以在列宽小于指定值时隐藏注释。这个选项读得很好,但是为此,我不得不牺牲大小的确切比例。事实证明,关注生物信息学领域是正确的。我向Reddit发送了有关r /可视化,r / datascience和r / bioinformatics的有关我的工具的帖子,在后者中,这是最受欢迎的,评论真的很热情。产品转换
最后,我意识到它原来是对许多人有用的好工具。因此,这个想法诞生了,将其变成了完整的开源软件包。当然,领导人的同意是必要的,但是这些人不仅不介意,而且还支持我,为此,我要多谢他们。我主要在周末工作,我开始逐步将代码引入市场,编写测试并使用Python处理软件包系统。这是我的第一个此类项目,所以花了几个月的时间。想出一个好名字也是一项艰巨的任务,而我却很难应付。所选名称(超级维恩)之所以不能称为成功,是因为维恩图的全部本质都是静态的,但是相反,我试图准确地显示实际尺寸。但是,当我意识到这一点时,该项目已经发布,并且更改名称为时已晚。类似物
当然,我并不是第一个使用这种方法对集合进行可视化的人:通常,这个想法是表面的。开放访问中有两个类似的Web应用程序:RainBio和Linear Diagram Generator,第二个使用与我完全相同的原理。(作者还在40页上写了一篇文章,通过实验比较了比较容易理解的东西-水平线或垂直线,细线还是粗线等。在我看来,该文章对他们来说是最主要的,而工具本身只是其中的一部分。)为了将这两个应用程序与我的程序包进行比较,我们再次使用带有单词的示例。您可以自己决定哪个选项更具可读性和信息性。Rainbio线性图生成器超人其他方法
不能不提及UpSet项目,它作为Web应用程序存在,并用于R和Python的软件包。通过查看香蕉基因组数据的显示可以了解基本原理。该图在右侧裁剪,仅显示30个相交点(共62个):有趣的是,如果您使用supervenn按宽度对列进行排序,并使用宽度对齐选项使列相同,则将获得几乎相同的结果,尽管这不会立即引起注意。所缺少的只是具有交点大小的垂直线,而不是它们在图形的底部只有数字:在编写此文本时,我尝试使用UpSet的Python版本,但发现该软件包自2016年以来未进行更新,文档未以任何方式描述输入格式,并且测试用例因错误而崩溃。Web版本正在运行,它具有许多有用的辅助功能,但是由于输入数据的方式复杂,使用它非常困难。最后,可以在线获取有关集合可视化技术的有趣概述。并非所有这些工具都实现为软件工具。以下是一些引起您注意的图片:我对Bubble Sets方法(下一行)特别感兴趣,该方法使您可以在平面上给定元素排列的顶部显示小集合。例如,当元素连接到时间轴(a)或地图(b)时,这可能很方便。到目前为止,该方法仅在Java和JavaScript中实现(链接在作者页面上),如果有人承诺将其移植到Python,那将是很棒的。我给UpSet和评论的作者写了一封简短介绍该项目的信,并收到了好评。他们中的两个甚至答应将supervenn纳入他们关于场景可视化的讲座中。结论
如果您想使用该软件包,可以在GitHub和PyPI 上找到它:pip install supervenn。对于有关代码和程序包使用的任何意见,想法和批评,我将不胜感激。我将特别高兴地阅读有关如何改进大型列置换算法的建议,以及有关如何编写图表功能测试的技巧。感谢您的关注!参考文献
1. John Venn。关于命题和推理的图解和机械表示。伦敦,爱丁堡和都柏林哲学杂志,1880年七月二J.-B.拉米和R.索普拉。 RainBio:生物学中大型集合的比例可视化。 IEEE Transactions on Visualization and Computer Graphics,doi:10.1109 / TVCG.2019.2921544。3. Peter Rodgers,Gem Stapleton和Peter Chapman。用线性图可视化集。 ACM Transactions on Computer Human Interaction 22(6)pp。 27:1-27:2015年9月39日。doi:10.1145 / 2810012。4. Alexander Lex,Nils Gehlenborg,Hendrik Strobelt,Romain Vuillemot,Hanspeter PfisterUpSet:相交集的可视化。IEEE可视化和计算机图形学交易(InfoVis'14),2014年。5. Bilal Alsallakh,Luana Micallef,Wolfgang Aigner,Helwig Hauser,Silvia Miksch和Peter Rodgers。集合可视化的最新技术。计算机图形学论坛。第00卷(2015年),第0页。1–27 10.1111 / cgf.12722。6. 克里斯托弗·科林斯(Christopher Collins),杰拉尔德·佩恩(Gerald Penn)和谢拉·卡彭代尔(Sheelagh Carpendale)。气泡集:在现有的可视化中显示具有等值线的集关系。IEEE Trans。可视化和计算机图形学(IEEE信息可视化会议程序),第一卷。15,iss。6页。1009-1016,2009年。