大家好!如您所知,我们SE从事(不仅限于)不同文档的文本识别。今天,我们想谈谈在复杂背景下识别文本时的另一个问题-关于识别空间。通常,我们将讨论银行卡上的名称,但首先,用字母“重影”作为例子。如您所见,在D的右侧,扭曲和背景形成了一个非常清晰的背景。此外,如果将此单元格与其他所有内容分开显示, (或神经网络)肯定会说有一个字母。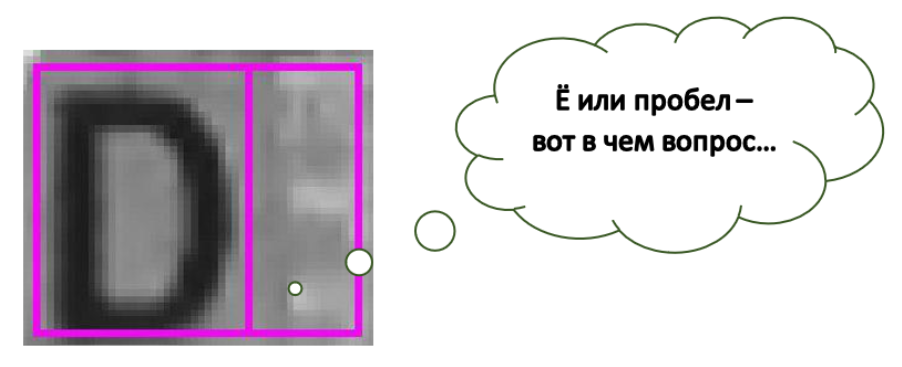 如您在图片中看到的,我们正在处理具有复杂背景的原始图像,因此我们的空间非常多样化。它们有图案,徽标,有时还有文字。例如,卡片上的VISA或MAESTRO。我们对这种“复杂空间”感兴趣,而不仅仅是白色矩形。在我们的系统中,我们考虑分别精确切割符号的矩形[1]。
如您在图片中看到的,我们正在处理具有复杂背景的原始图像,因此我们的空间非常多样化。它们有图案,徽标,有时还有文字。例如,卡片上的VISA或MAESTRO。我们对这种“复杂空间”感兴趣,而不仅仅是白色矩形。在我们的系统中,我们考虑分别精确切割符号的矩形[1]。困难是什么?
空格是没有特殊符号的符号。在复杂的背景(例如图像)中,即使对于人来说,单独分割的空间也可能难以区分。另一方面,从本质上讲,空格与其他字符不同。如果以名称代替ABIA识别了ABIA,那么就有机会通过后期处理对其进行修复。但是,如果在那儿出现IA,则不太可能有所帮助。我们不使用的方法
通常使用从图像计算出的统计数据来过滤空间。例如,考虑图片中梯度的平均绝对值或像素强度的变化,然后通过阈值将图片划分为空格和字母。但是,从图中可以看出,这种方法不适用于背景复杂的灰度图像。而且由于值的显式相关,即使将这些方法组合起来也无法使用。每个人最喜欢的二值化在这里也无济于事。例如,在此图片中:那么,如何提高识别度呢?
由于一个人需要一个空间的环境才能看到他,因此网络显示至少两个相邻的字符是合乎逻辑的。我们不希望增加识别网络的输入,该网络通常运行良好(并识别许多差距)。因此,我们将获得另一个网络-更简单。新的网络将预测图中的内容:两个空格,两个字母,一个空格和一个字母或一个字母和一个空格。因此,这样的网络与识别网络结合使用。该图显示了所使用的体系结构:左侧是识别网络的体系结构,右侧是建议的网络的体系结构。识别网络在具有一个字符的图片上运行,而新的网络则在包含两个相邻字符的双倍宽图片上运行。一个测试?
为了进行测试,我们有4320行,其名称包含130,149个字符,其中68,246个空格。首先,我们有两种方法。基本方法:我们将字符串切成字符,然后分别识别每个字符。新方法:我们还剪切了一个字符串,使用新的网络查找所有空格,然后正常识别其余字符。该表显示,空间识别的质量以及整体质量正在提高,但是字母的识别质量略有下降。但是,我们的核心网络也可以识别空间(尽管比我们想要的要差)。我们可以尝试利用这一优势。让我们看一下这两种方法的错误。而且-基于基本错误的新方法的质量,反之亦然。对于基本方法:对于新方法:从最后三个表中可以看出,要改善系统,值得使用网络额定值的平衡组合。同时,逐个字符的质量很有趣,但逐行更有趣。结论
空格-实现100%的文档识别质量的一个大问题=)空格的示例清楚地表明,不仅要看单个字符,还要看它们的组合是多么重要。但是,不要立即抓住重型火炮并学习处理整个弦乐的巨型网络。有时,只需另一个小型网络就足够了。这篇文章是使用2015年欧洲ECMS建模会议(保加利亚,瓦尔纳)的报告中的材料制作的:Sheshkus,A.&Arlazarov,VL(2015)。使用视觉上下文检测复杂背景上的空间符号。使用的资料清单1. YS Chernyshova,AV Sheshkus和VV Arlazarov,“摄像机捕捉图像中文本行识别的两步CNN框架”,IEEE Access,第1卷。8页。32587-32600,2020,DOI:10.1109 / ACCESS.2020.2974051。