或没有这些神经网络的老式动态编程。一年半前,我碰巧参加了一个公司竞赛(出于娱乐目的),为游戏Lode Runner编写了一个机器人。 20年前,我在相应的课程中努力解决了动态编程的所有问题,但几乎忘了一切,并且没有编程游戏机器人的经验。我不得不记住,分配的时间很少,在旅途中进行试验并独立踩踏耙子。但是,突然之间,一切工作都非常顺利,所以我决定以某种方式对材料进行系统化处理,而不是让读者沉迷于matan。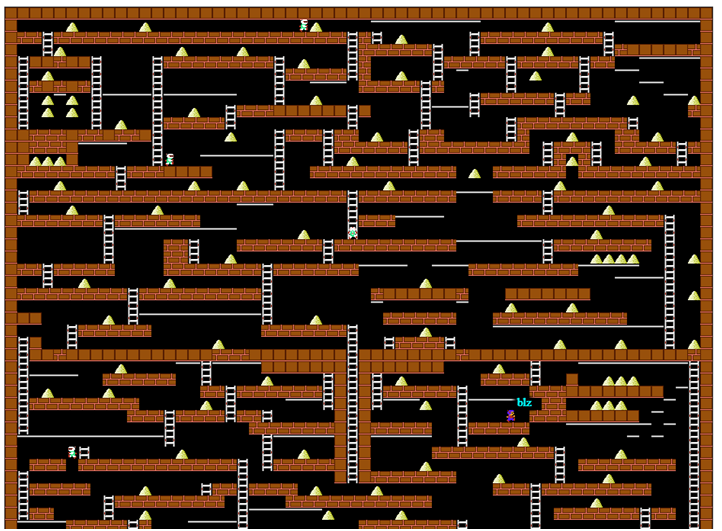 Codenjoy项目服务器的游戏屏幕首先,我们将稍微描述一下游戏规则:玩家沿着地板或管道水平移动,知道如何上下楼梯,如果没有地板则摔倒。他还可以在自己的左侧或右侧开一个孔,但并非每个表面都可以开通-有条件的话,可以使用“木”地板,而混凝土则不可以。怪物追赶玩家,掉进切孔并在其中死亡。但最重要的是,玩家必须收集金币,收集到的第一个金币将获得1个利润点,第N个金币将获得N个点数。死后,总利润仍然存在,但是对于第一个黄金,他们再次给出1分。这表明主要的事情是尽可能长寿,收集黄金在某种程度上是次要的。由于地图上存在玩家无法摆脱的地方,因此在游戏中引入了免费自杀,这将玩家随机放置在某处,但实际上破坏了整个游戏-自杀并没有中断所发现的黄金价值的增长。但是我们不会滥用此功能。游戏中的所有示例都将以简化显示的形式显示,该显示已在程序日志中使用:
Codenjoy项目服务器的游戏屏幕首先,我们将稍微描述一下游戏规则:玩家沿着地板或管道水平移动,知道如何上下楼梯,如果没有地板则摔倒。他还可以在自己的左侧或右侧开一个孔,但并非每个表面都可以开通-有条件的话,可以使用“木”地板,而混凝土则不可以。怪物追赶玩家,掉进切孔并在其中死亡。但最重要的是,玩家必须收集金币,收集到的第一个金币将获得1个利润点,第N个金币将获得N个点数。死后,总利润仍然存在,但是对于第一个黄金,他们再次给出1分。这表明主要的事情是尽可能长寿,收集黄金在某种程度上是次要的。由于地图上存在玩家无法摆脱的地方,因此在游戏中引入了免费自杀,这将玩家随机放置在某处,但实际上破坏了整个游戏-自杀并没有中断所发现的黄金价值的增长。但是我们不会滥用此功能。游戏中的所有示例都将以简化显示的形式显示,该显示已在程序日志中使用: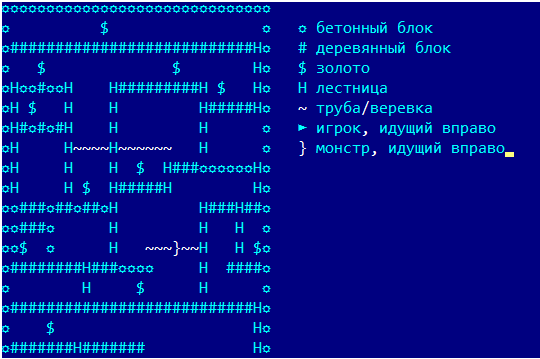
一点理论
为了使用某种数学方法来实现机器人,我们需要设置一些目标函数来描述机器人的成就,并找到使机器人最大化的动作。例如,收集黄金可获得+100,死亡则为-100500,因此没有黄金收集可杀死可能的死亡。一个单独的问题,以及我们究竟确定什么目标函数,即 游戏的状态是什么?在最简单的情况下,玩家的坐标就足够了,但在我们看来,一切都更加复杂:- 玩家坐标
- 所有玩家刺穿的所有洞的坐标
- 地图上所有黄金的坐标(或最近食用的黄金的坐标)
- 所有其他玩家的坐标
看起来很吓人。因此,让我们简化一下任务,直到我们记住吃掉的金子(稍后再返回),我们也将不记得其他玩家和怪物的坐标。因此,游戏的当前状态为:玩家动作以一种可以理解的方式改变状态:- 运动命令更改相应坐标之一
- 挖坑团队增加了一个新坑
- 在没有支撑物的情况下跌倒玩家会降低垂直坐标
- 站在支撑板上的玩家的不动作不会改变状态
现在我们需要了解如何最大化功能本身。动态编程是用于计算游戏N前进的一种古老的经典方法。没有公式是不可能的,因此我将以简化的形式给出它们。您将必须首先引入很多符号。为简单起见,我们会将时间报告与当前动作保持一致,即 当前移动是t = 0。让我们表示在t期间的游戏状态。很多方式表示机器人的所有有效操作(处于特定状态,但为简单起见,我们将不编写状态索引)表示在t的过程中的特定动作(我们省略了索引)。健康)状况作用下进入一种状态。动作a处于状态时获胜表示为。当计算它,我们假设,如果我们吃金,然后它等于G = 100,如果它们死了,则d = -100500,否则为0设是在时间t处于状态x的机器人最佳游戏的收益函数。然后我们只需要找到一个最大化动作。现在,我们写第一个公式,这很重要,同时几乎正确:
或在任意时间点
它看起来很笨拙,但含义很简单-当前动作的最佳解决方案包括下一动作的最佳解决方案和当前动作的增益。这是贝尔曼歪曲制定的最优性原则。我们对第1步中的最优值一无所知,但是如果我们知道最优值,我们将找到一个通过迭代机器人的所有动作来最大化功能的动作。递归关系的美在于我们可以找到,对其应用最佳化原理,并通过完全相同的公式将其表示为 。我们还可以轻松地在任何步骤表达回报功能。看来问题已经解决了,但这里我们面临的问题是,如果在每一步中我们必须对6个玩家动作进行排序,那么在递归的N步中,我们就必须对6 ^ N个选项进行排序,对于N = 8,这已经是一个相当不错的数字〜1.6百万例。另一方面,我们有与之无关的千兆赫微处理器,看来它们将完全应付任务,并且我们将仅通过8次移动将搜索深度限制到它们。因此,我们的规划范围是8步,但从何处获得价值?在这里,我们只是提出一个想法,即我们能够以某种方式分析该职位的前景,并根据他们的最高考虑为其分配一些价值。让哪里 这是该策略的函数,在最简单的版本中,它只是一个矩阵,我们可以根据机器人的几何坐标从中选择值。可以说,前8个举动是一种策略,然后该策略开始。实际上,没有人限制我们选择一种策略,我们稍后会加以处理,但就目前而言,为了不像野兔和刺猬的玩笑般变成猫头鹰,我们将继续战术。一般方案
因此,我们决定采用该算法。在每个步骤中,我们都会解决优化问题,找到该步骤的最佳操作,完成该操作,然后游戏进入下一步。有必要在每个步骤上解决一个新问题,因为随着游戏过程的进行,任务会有所变化,出现新的金币,有人在吃东西,玩家在移动……但是不要以为我们的巧妙算法可以提供一切。解决优化问题之后,您必须肯定添加一个处理程序,该处理程序将检查不愉快的情况:所有这些可能都需要对策略,自杀或优化算法框架之外的其他动作进行根本性的改变。这些情况的性质可能有所不同。有时,策略和战术之间的矛盾导致僵尸程序冻结到位,这对他来说似乎具有战略重要性,这是古代植物学家Buridanov Donkey发现的。 您的对手可以冻结并关闭通往梦gold以求的黄金的短路-我们稍后将处理所有这些问题。
您的对手可以冻结并关闭通往梦gold以求的黄金的短路-我们稍后将处理所有这些问题。与拖延作斗争
考虑一个简单的情况,当一个金位于机器人的右边,并且半径为8的金单元不再存在时。根据我们的公式,机器人将采取什么步骤?实际上-绝对任何。例如,即使对于三个动作,所有这些解决方案都给出完全相同的结果:- 左移-右移-右移
- 向右走-不作为-不作为
- 无为-无为-右移
所有这三个选项都会获得一个等于100的胜利,机器人可以选择不采取行动的选择,在下一步中再次解决相同的问题,再次选择不采取行动...并永远站住。我们需要修改用于计算奖金的公式,以激发漫游器尽早采取行动:
我们将下一步的未来收益乘以必须选择小于1的“通货膨胀系数”E。我们可以安全地试验0.95或0.9的值。但是不要选择太小,例如,当E = 0.5时,第8步食用的黄金只会带来0.39点。因此,我们重新发现了“直到明天才推迟今天可以吃的东西”的原则。安全
收集黄金固然很好,但是您仍然需要考虑安全性。我们有两个任务:- 如果怪物处于合适的位置,请教机器人去挖洞
- 教机器人逃避怪物
但是我们不告诉机器人该怎么做,我们设置利润函数的值,优化算法将选择适当的步骤。一个单独的问题是,我们无法精确计算出怪物在特定移动中的位置。因此,为简单起见,我们假设怪物就位,并且我们不需要接近它们。如果他们开始接近我们,该机器人本身就会开始逃避它们,因为它会因过于接近他们而被罚款(某种自我隔离)。因此,我们引入了两个规则:- 如果我们以d且d <= 3的距离来到怪物处,则对我们处以100,500 *(4-d)/ 4的罚款
- 如果怪物离我们足够近,并且与我们在同一条直线上,并且我们之间存在漏洞,那么我们可以获得一些利润P
我们稍后将打开“在距离d处接近怪物”的概念,但是现在让我们继续该策略。我们绕过图
从数学上讲,最佳的黄金规避问题是旅行商的一个长期解决的问题,解决这个问题并不是一件乐事。但是在解决此类问题之前,您需要考虑一个简单的问题-但是如何找到游戏中两点之间的距离?或者用一种稍微有用的形式:对于给定的金牌和地图上的任意点,找到玩家从金牌到达该点的最小移动次数。在一段时间内,我们会忘记挖洞并跳入洞中,而每1个单元格只留下自然的运动。只有我们会朝相反的方向走-从黄金到地图。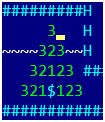 第一步,我们选择所有可以单步进入黄金的像元,并将其分配给1。在第二步中,我们选择一次从其中像元的所有像元,并将它们分配给2。图片显示了3步的情况。现在,让我们尝试以适合编程的形式将其全部写下来。我们会需要:
第一步,我们选择所有可以单步进入黄金的像元,并将其分配给1。在第二步中,我们选择一次从其中像元的所有像元,并将它们分配给2。图片显示了3步的情况。现在,让我们尝试以适合编程的形式将其全部写下来。我们会需要:- 二维数值数组距离[x,y],我们将在其中存储结果。最初,对于金坐标,对于其余点-1,它包含0。
- oldBorder数组,我们将在其中存储要从中移动的点,最初它具有一个带有黄金坐标的点
- 数组newBorder,我们将在其中存储在当前步骤中找到的点
- 对于oldBorder中的每个点p,我们找到所有点p_a,从中我们可以一步到达p(更准确地说,我们从p沿相反方向采取所有可能的步长,例如,在没有支撑的情况下向上飞行),距离[p_a] =-1
- 我们将每个这样的点p_a放置在数组newBorder中,在距离[p_a]处写入迭代次数
- 完成所有要点后:
- 交换oldBorder和newBorder的数组,然后清除newBorder
- 如果oldBorder为空,则完成算法,否则转到步骤1。
伪代码中也是如此:iter=1;
newBorder.clear();
distance.fill(-1);
distance[gold]=0;
oldBorder.push(gold);
while(oldBorder.isNotEmpty()) {
for (p: oldBorder){
for (p_a: backMove(p)) {
if (distance[p_a]==-1) {
newBorder.push(p_a);
distance[p_a]=iter;
}
}
}
Swap(newBorder, oldBorder);
newBorder.clear();
iter++;
}
在算法的输出处,我们将获得一个距离图,其中包含从游戏整个区域的每个点到黄金的距离值。此外,对于无法获得金的点,距离值为-1。数学家称这种在游戏场上的走动(形成一个图形,该图形在场上的点处形成顶点,并且连接顶点的边缘可以一步移动)“沿宽度走图”。如果我们实施递归而不是两个边界数组,则将其称为“深度遍历图”,但是由于深度可能很大(数百个),因此建议您在遍历图时避免使用递归算法。真正的算法由于挖了一个洞然后跳进去而变得更加复杂-事实证明,在4次移动中,我们向一侧移动了一个单元格,向后移动了两个单元格(因为朝相反的方向移动,然后向上移动),但是对该算法进行了轻微的修改就解决了这个问题。我给图片添加了数字,包括考虑挖一个洞并跳进去: 这让我们想起了什么?
这让我们想起了什么? 金的味道!我们的机器人会闻起来很香,就像洛基奶酪一样(但同时它也不会失去头脑,躲开怪物,甚至为它们挖洞)。让我们为他制定一个简单的贪婪策略:
金的味道!我们的机器人会闻起来很香,就像洛基奶酪一样(但同时它也不会失去头脑,躲开怪物,甚至为它们挖洞)。让我们为他制定一个简单的贪婪策略:- 对于每种金币,我们都构建一个距离图并找到与玩家的距离。
- 选择最接近玩家的金牌并拿出他的牌来计算策略
- 对于地图的每个像元,用d表示其与黄金的距离,然后表示战略价值
哪里 这是一些虚构的黄金价值,希望它的价值比现在低几倍,并且 这是一个<1的通货膨胀系数,因为假想的黄金越远,它的价格越便宜。系数E与构成了千年未解决的问题,并为创造力留出了空间。不要以为我们的机器人会一直运行到最近的黄金。假设我们在左边5个单元格的距离处有一个黄金,然后空了,在右边6和7距离处有两个黄金。由于真实的黄金比想象中的更有价值,因此机器人会向右移动。在继续采用更有趣的策略之前,我们将进行另一项改进。在游戏中,重力将玩家拉下,他只能爬上楼梯。因此,较高的黄金应被估价为较高。如果高度是从顶部开始向下报告的,那么您可以将gold(带有垂直y坐标)的值乘以。对于系数 新的术语“垂直通货膨胀率”被创造出来,至少经济学家没有使用它并且很好地反映了本质。复杂策略
挑选出一种金子后,您需要对所有金子进行处理,而我不想吸引大量数学。有一个非常优雅,简单和不正确(严格意义上来说)的解决方案-如果一种黄金在自身周围创建了一个“价值域”,那么我们就可以将所有具有黄金的单元格的所有价值域添加到一个矩阵中,并将其用作策略。是的,这不是最佳解决方案,但是中距离的几个黄金单位比一个接近的黄金更有价值。但是,新的解决方案会带来新的问题-新的价值矩阵可能包含局部最大值,在该最大值附近没有金。因为我们的机器人可以进入它们并且不想出去,所以这意味着我们需要添加一个处理程序,以检查该机器人是否在策略的局部最大值处并根据移动结果保持在适当位置。现在我们有了打击冻结的工具-通过N步取消该策略,并暂时恢复到最近的黄金策略。观察被卡住的机器人如何改变其策略并开始持续下降,吃掉所有最近的黄金,这使机器人意识到并试图爬上地图,是很有趣的。吉基尔博士和海德先生策略与策略不符
在这里,我们的机器人在地板下精疲力尽: 它已经属于优化算法之列,它仍然需要向右走3步,在右边挖一个孔然后跳进去,然后重力将自行完成所有工作。像这样:
它已经属于优化算法之列,它仍然需要向右走3步,在右边挖一个孔然后跳进去,然后重力将自行完成所有工作。像这样: 但是该机器人死机了。调试表明没有错误:机器人认为最佳策略是等待一个举动,然后按照指定的路线进行操作,并在最后分析的步骤中获得金牌。在第一种情况下,它从接收到的黄金中获得收益,从虚构的黄金中获得收益(在最后分析的迭代中,它只是在黄金所在的单元格中),而在第二种情况中,它仅从真实黄金中获得收益(尽管较早)。不再有任何策略,因为黄金下的地方烂了,前景不大。好吧,在他的下一步行动中,他再次决定采取一个暂时的休息,我们已经解决了此类问题。我必须修改策略-因为我们存储了分析阶段消耗的所有黄金,因此从策略价值的总矩阵中减去了消耗的黄金的价值卡,因此该策略考虑了策略的实现(可以不同地计算价值-仅针对完整的黄金,但是它在计算上更加复杂,因为地图上的黄金数量远远超过了我们在8步中可以吃掉的黄金数量)。但这并没有结束我们的折磨。假设战略价值矩阵具有局部最大值,并且机器人将其逼近了7步。机器人会冻结它吗?不,因为对于机器人在8步中达到本地最大值的任何路线,获胜都是相同的。好老拖延。其原因是战略收益不取决于我们进入牢房的那一刻。首先想到的是对机器人进行简单的优化,但这对毫无意义的左右行走毫无帮助。有必要治疗根本原因-考虑到每一回合的战略收益(作为新状态与当前状态的战略价值之间的差异),并将其随时间减少一个因子。那些。在表达式中引入一个额外的术语来表示获胜:
但是该机器人死机了。调试表明没有错误:机器人认为最佳策略是等待一个举动,然后按照指定的路线进行操作,并在最后分析的步骤中获得金牌。在第一种情况下,它从接收到的黄金中获得收益,从虚构的黄金中获得收益(在最后分析的迭代中,它只是在黄金所在的单元格中),而在第二种情况中,它仅从真实黄金中获得收益(尽管较早)。不再有任何策略,因为黄金下的地方烂了,前景不大。好吧,在他的下一步行动中,他再次决定采取一个暂时的休息,我们已经解决了此类问题。我必须修改策略-因为我们存储了分析阶段消耗的所有黄金,因此从策略价值的总矩阵中减去了消耗的黄金的价值卡,因此该策略考虑了策略的实现(可以不同地计算价值-仅针对完整的黄金,但是它在计算上更加复杂,因为地图上的黄金数量远远超过了我们在8步中可以吃掉的黄金数量)。但这并没有结束我们的折磨。假设战略价值矩阵具有局部最大值,并且机器人将其逼近了7步。机器人会冻结它吗?不,因为对于机器人在8步中达到本地最大值的任何路线,获胜都是相同的。好老拖延。其原因是战略收益不取决于我们进入牢房的那一刻。首先想到的是对机器人进行简单的优化,但这对毫无意义的左右行走毫无帮助。有必要治疗根本原因-考虑到每一回合的战略收益(作为新状态与当前状态的战略价值之间的差异),并将其随时间减少一个因子。那些。在表达式中引入一个额外的术语来表示获胜:
目标函数在后者上的值通常视为零: 。由于通过乘以系数使收益随每次移动而贬值,因此这将使我们的机器人获得更快的战略收益并消除观察到的问题。未经测试的策略
我尚未在实践中测试过此策略,但看起来很有希望。- 因为我们知道金点之间的所有距离以及金和玩家之间的距离,所以我们可以找到长度最短的玩家-N个金格链(其中N小,例如5或6)。即使是最简单的时间搜索也足够了。
- 选择此链中的第一个黄金,并将其值字段用作策略矩阵。
在这种情况下,最好将实物成本和假想黄金成本相抵,以使机器人不会冲入地下室来获取最近的黄金。最终改进
在学会了“散布”在地图上之后,让我们从每个怪物进行类似的“散布”几步,并找到怪物可能会进入的所有单元格,以及它将进行的步数。这将使玩家可以完全安全地从怪物头上的管道中爬行。最后一刻-在计算策略和黄金的虚拟价值时,我们没有考虑其他参与者的位置,只是在分析地图时“擦除”了他们。事实证明,单个悬挂的炮弹可以阻止进入整个区域,因此增加了一个附加处理程序-跟踪冻结的对手并在分析过程中将其替换为混凝土块。实施功能
由于主要算法是递归的,因此我们必须能够快速更改状态对象并将其返回到原始对象以进行进一步修改。我使用Java(一种具有垃圾回收的语言)对与创建短期对象相关联的数百万个更改进行排序,这可以在一轮游戏中导致多个垃圾回收,这在速度方面可能是致命的。因此,在使用的数据结构上必须格外小心,我仅使用数组和列表。好吧,或者使用Valgala项目需要您自担风险,)源代码和游戏服务器
源代码可以在github上找到。不要严格判断,匆忙已经做了很多事情。codenjoy游戏服务器将提供启动机器人和监视游戏的基础结构。在创建时,修订是相关的,使用修订1.0.26。您可以使用以下行启动服务器:call mvn -DMAVEN_OPTS=-Xmx1024m -Dmaven.test.skip=true clean jetty:run-war -Dcontext=another-context -Ploderunner
该项目本身非常好奇,可以提供各种口味的游戏。结论
如果您在没有任何初步准备的情况下就读完了这一切,并理解了所有内容,那么您就是一个难得的伙伴。