在复杂的ERP系统中,当同类对象排列在祖先-后代关系树中时,许多实体具有分层性质 -这是企业的组织结构(所有这些分支,部门和工作组),产品目录,工作区域和地理位置销售点…… 实际上,没有一个业务自动化领域至少不会实现某些层次结构。但是,即使您不是“为企业”工作,您仍然可以轻松地遇到层次关系。顺带一提,甚至您在购物中心内的家谱或楼层平面图都是相同的结构。
有很多方法可以将这种树存储在DBMS中,但是今天我们将只关注一个选项:
CREATE TABLE hier(
id
integer
PRIMARY KEY
, pid
integer
REFERENCES hier
, data
json
);
CREATE INDEX ON hier(pid);
当您窥探层次结构的深处时,它会耐心地等待使用这种结构的“幼稚”方式的效果如何[无效]。让我们分析典型的新兴任务,它们在SQL中的实现并尝试提高其性能。#1。兔子洞有多深?
为了确定起见,此结构将反映部门在组织结构中的从属地位:部门,部门,部门,分支机构,工作组……无论您怎么说。首先,我们生成10K元素的“树”INSERT INTO hier
WITH RECURSIVE T AS (
SELECT
1::integer id
, '{1}'::integer[] pids
UNION ALL
SELECT
id + 1
, pids[1:(random() * array_length(pids, 1))::integer] || (id + 1)
FROM
T
WHERE
id < 10000
)
SELECT
pids[array_length(pids, 1)] id
, pids[array_length(pids, 1) - 1] pid
FROM
T;
让我们从最简单的任务开始-查找在特定部门或层次结构中工作的所有雇员- 查找节点的所有后代。获得子孙的“深度”也将是一件好事。例如,从这些雇员的ID列表中构建某种复杂的选择,这可能是必需的。如果这些后代只有几个级别,并且数量上在一打之内,一切都会很好,但是如果超过五个级别,并且已经有几十个后代,那么可能会有问题。让我们看看如何编写(“工作”)传统的“树下”搜索选项。但是首先,我们确定哪个节点是我们研究中最有趣的。该“最深”子树:WITH RECURSIVE T AS (
SELECT
id
, pid
, ARRAY[id] path
FROM
hier
WHERE
pid IS NULL
UNION ALL
SELECT
hier.id
, hier.pid
, T.path || hier.id
FROM
T
JOIN
hier
ON hier.pid = T.id
)
TABLE T ORDER BY array_length(path, 1) DESC;
id | pid | path
---------------------------------------------
7624 | 7623 | {7615,7620,7621,7622,7623,7624}
4995 | 4994 | {4983,4985,4988,4993,4994,4995}
4991 | 4990 | {4983,4985,4988,4989,4990,4991}
...
在“最宽”子树:...
SELECT
path[1] id
, count(*)
FROM
T
GROUP BY
1
ORDER BY
2 DESC;
id | count
------------
5300 | 30
450 | 28
1239 | 27
1573 | 25
对于这些查询,我们使用了典型的递归JOIN: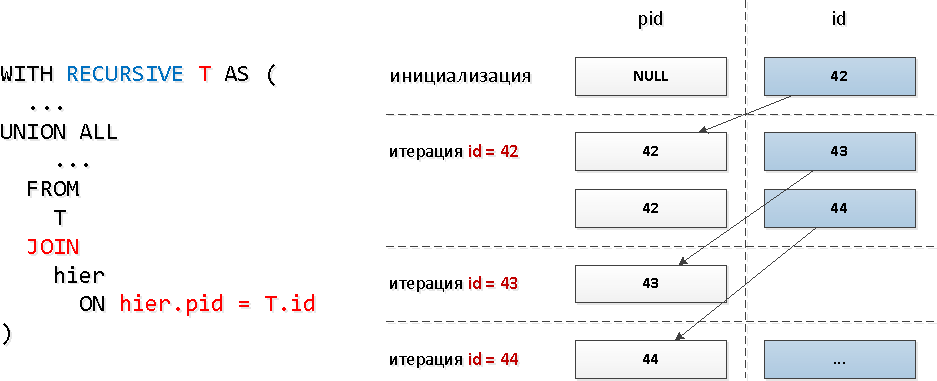 显然,在此查询模型中,迭代次数将与后代的总数一致(并且有数十个后代),这可能会占用相当多的资源,因此会占用时间。让我们检查“最宽”子树:
显然,在此查询模型中,迭代次数将与后代的总数一致(并且有数十个后代),这可能会占用相当多的资源,因此会占用时间。让我们检查“最宽”子树:WITH RECURSIVE T AS (
SELECT
id
FROM
hier
WHERE
id = 5300
UNION ALL
SELECT
hier.id
FROM
T
JOIN
hier
ON hier.pid = T.id
)
TABLE T;
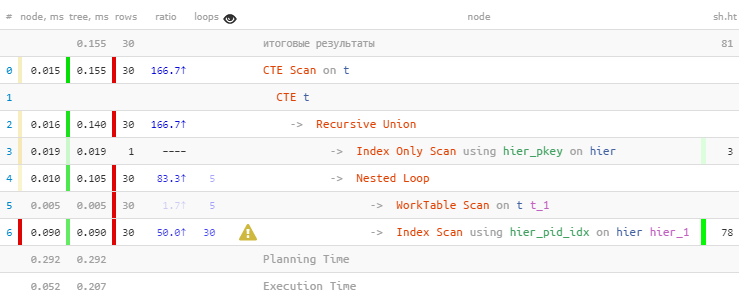 [查看explain.tensor.ru]正如预期的那样,我们找到了所有30个条目。但是他们花了整个时间的60%-因为他们对索引进行了30次搜索。而且更少-有可能吗?
[查看explain.tensor.ru]正如预期的那样,我们找到了所有30个条目。但是他们花了整个时间的60%-因为他们对索引进行了30次搜索。而且更少-有可能吗?按索引进行大量校对
对于每个节点,我们是否需要进行单独的索引请求?事实证明,没有-我们可以从指数看几个键一次与一个呼叫= ANY(array)。在每个这样的标识符组中,我们可以采用上一步中由“节点”找到的所有ID。也就是说,在每个下一步中,我们将立即立即搜索某个级别的所有后代。但是,很不幸,在递归选择中,您不能在子查询中引用自己,但是我们只需要以某种方式准确选择上一级的内容即可。结果证明,您不能对整个样本进行子查询,而只能对特定字段进行子查询-能够。这个字段也可以是一个数组-这是我们需要使用的ANY。听起来有些疯狂,但是在图表上-一切都很简单。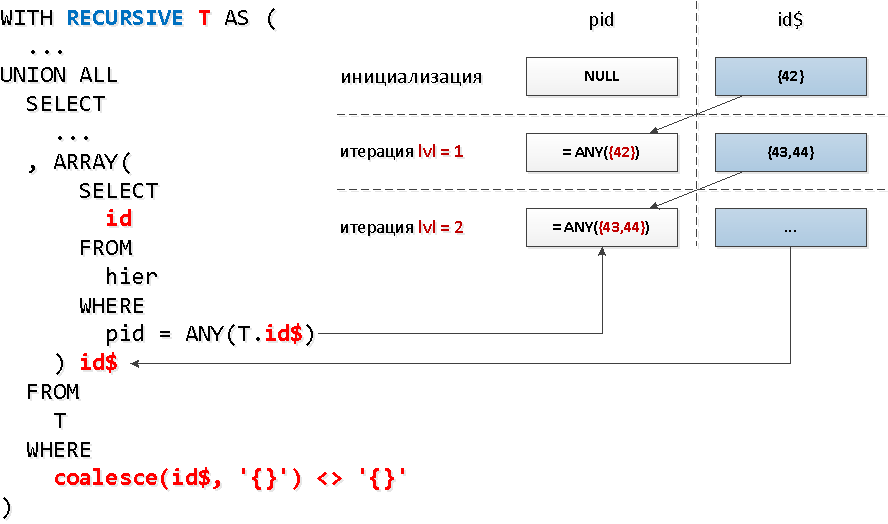
WITH RECURSIVE T AS (
SELECT
ARRAY[id] id$
FROM
hier
WHERE
id = 5300
UNION ALL
SELECT
ARRAY(
SELECT
id
FROM
hier
WHERE
pid = ANY(T.id$)
) id$
FROM
T
WHERE
coalesce(id$, '{}') <> '{}'
)
SELECT
unnest(id$) id
FROM
T;
 [请看explorer.tensor.ru]这里最重要的是甚至没有赢得1.5倍的时间,而是我们减少了缓冲区,因为我们只有5次调用索引而不是30次!另外一个好处是,在最后的嵌套消息之后,标识符仍将按“级别”排序。
[请看explorer.tensor.ru]这里最重要的是甚至没有赢得1.5倍的时间,而是我们减少了缓冲区,因为我们只有5次调用索引而不是30次!另外一个好处是,在最后的嵌套消息之后,标识符仍将按“级别”排序。节点标签
下一个有助于提高生产率的考虑因素是“叶子”不能生孩子,也就是说,他们不需要看不起任何东西。在制定任务时,这意味着如果我们沿着部门链到达员工,那么就无需在该分支机构进行进一步搜索。让我们在表中引入一个附加boolean字段,该字段立即告诉我们树中的此特定条目是否是“节点”,也就是说,它是否可以有任何子级。ALTER TABLE hier
ADD COLUMN branch boolean;
UPDATE
hier T
SET
branch = TRUE
WHERE
EXISTS(
SELECT
NULL
FROM
hier
WHERE
pid = T.id
LIMIT 1
);
精细!事实证明,所有树元素中只有略超过30%的元素具有后代。现在,LATERAL我们将应用稍有不同的机制-通过链接到递归部分,这将使我们能够立即访问递归“表”的字段,并使用基于节点的过滤条件的聚合函数来减少键集: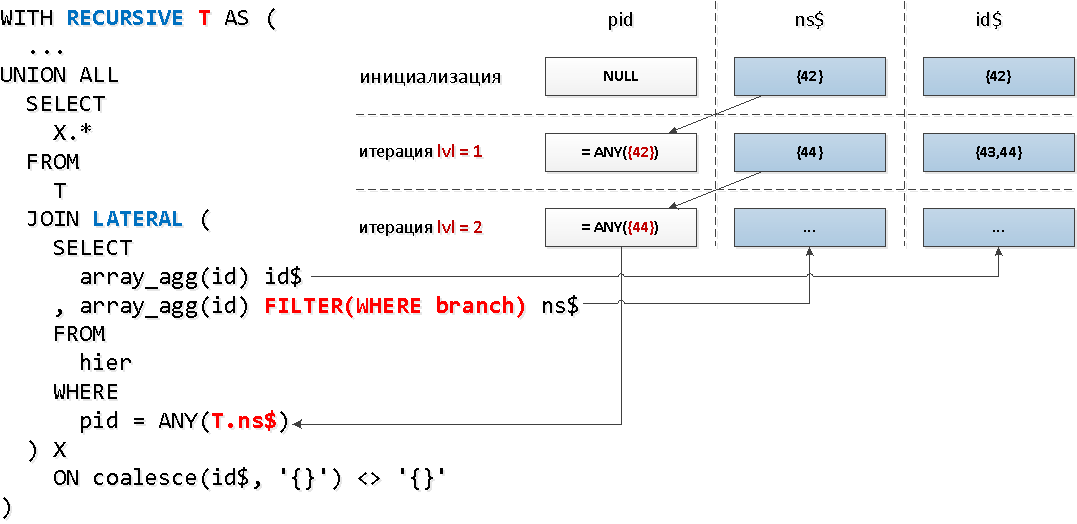
WITH RECURSIVE T AS (
SELECT
array_agg(id) id$
, array_agg(id) FILTER(WHERE branch) ns$
FROM
hier
WHERE
id = 5300
UNION ALL
SELECT
X.*
FROM
T
JOIN LATERAL (
SELECT
array_agg(id) id$
, array_agg(id) FILTER(WHERE branch) ns$
FROM
hier
WHERE
pid = ANY(T.ns$)
) X
ON coalesce(T.ns$, '{}') <> '{}'
)
SELECT
unnest(id$) id
FROM
T;
 [请看explorer.tensor.ru]我们能够减少对该指数的另一项吸引力,并且在扣除金额方面赢得了2倍以上。
[请看explorer.tensor.ru]我们能够减少对该指数的另一项吸引力,并且在扣除金额方面赢得了2倍以上。#2 回到根源
如果您需要收集“树上”所有元素的记录,同时维护有关哪个源工作表(以及使用哪些指标)导致该事件落入样本的信息(例如,生成汇总到节点的摘要报告),则此算法将非常有用。由于请求非常繁琐,因此应进一步将其作为概念验证。但是,如果它在您的数据库中占主导地位-值得考虑使用这种技术。让我们从几个简单的语句开始:- 最好只从数据库中读取一次相同的记录。
- 从数据库中的条目在“捆绑”中的读取效率要高于单独读取。
现在,让我们尝试设计所需的查询。步骤1
显然,在递归初始化时(如果没有它!),我们将不得不从源标识符集中减去叶子本身的记录:WITH RECURSIVE tree AS (
SELECT
rec
, id::text chld
FROM
hier rec
WHERE
id = ANY('{1,2,4,8,16,32,64,128,256,512,1024,2048,4096,8192}'::integer[])
UNION ALL
...
如果有人对“集合”存储在字符串而不是数组中感到陌生,那么这里有一个简单的解释。对于字符串,有一个内置的聚合“粘合”功能string_agg,但对于数组则没有。尽管自己实施并不难。第2步
现在,我们将获得一组部分ID,需要将其进一步减去。几乎总是将它们复制到源集的不同记录中-因此我们将对它们进行分组,同时保留有关源叶的信息。但是这里有三个麻烦等待着我们:- 查询的“子递归”部分不能包含聚合函数c
GROUP BY。 - 对递归“表”的调用不能在嵌套子查询中。
- 递归部分中的查询不能包含CTE。
幸运的是,所有这些问题都可以轻松绕开。让我们从头开始。递归部分中的CTE
这不是它的工作方式:WITH RECURSIVE tree AS (
...
UNION ALL
WITH T (...)
SELECT ...
)
这样就可以了,括号决定!WITH RECURSIVE tree AS (
...
UNION ALL
(
WITH T (...)
SELECT ...
)
)
嵌套查询递归“表”
嗯...对递归CTE的调用不能在子查询中。但是它可以在CTE内部!子请求已经可以引用此CTE!GROUP BY内部递归
令人不快,但是...我们还有一种简单的方法可以使用DISTINCT ON窗口函数来模拟GROUP BY !SELECT
(rec).pid id
, string_agg(chld::text, ',') chld
FROM
tree
WHERE
(rec).pid IS NOT NULL
GROUP BY 1
这样就行了!SELECT DISTINCT ON((rec).pid)
(rec).pid id
, string_agg(chld::text, ',') OVER(PARTITION BY (rec).pid) chld
FROM
tree
WHERE
(rec).pid IS NOT NULL
现在我们了解为什么数字ID变成文本-以便可以用逗号将它们粘合在一起!第三步
对于结局,我们一无所有:- 我们读取了一组分组ID上的“部分”记录
- 将减去的部分与原始工作表的“集合”匹配
- 使用“扩展”设置的字符串
unnest(string_to_array(chld, ',')::integer[])
WITH RECURSIVE tree AS (
SELECT
rec
, id::text chld
FROM
hier rec
WHERE
id = ANY('{1,2,4,8,16,32,64,128,256,512,1024,2048,4096,8192}'::integer[])
UNION ALL
(
WITH prnt AS (
SELECT DISTINCT ON((rec).pid)
(rec).pid id
, string_agg(chld::text, ',') OVER(PARTITION BY (rec).pid) chld
FROM
tree
WHERE
(rec).pid IS NOT NULL
)
, nodes AS (
SELECT
rec
FROM
hier rec
WHERE
id = ANY(ARRAY(
SELECT
id
FROM
prnt
))
)
SELECT
nodes.rec
, prnt.chld
FROM
prnt
JOIN
nodes
ON (nodes.rec).id = prnt.id
)
)
SELECT
unnest(string_to_array(chld, ',')::integer[]) leaf
, (rec).*
FROM
tree;
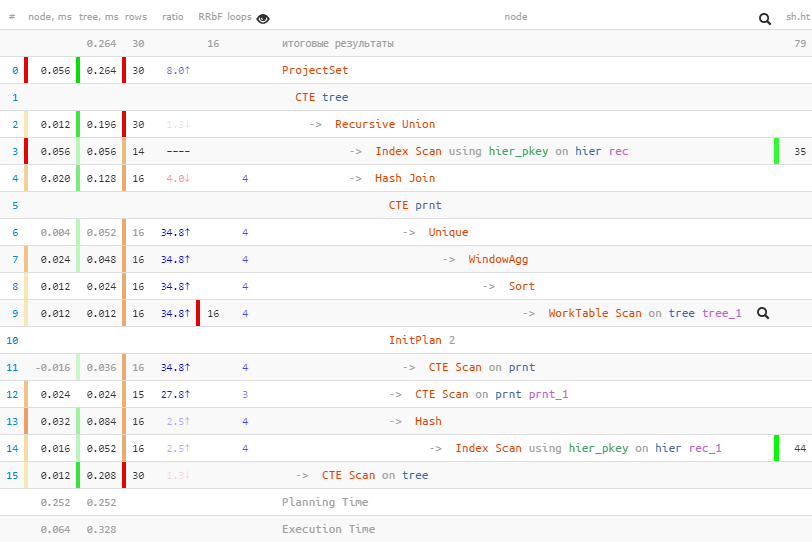 [ explain.tensor.ru]
[ explain.tensor.ru]