一般而言,特别是英语,有很多不同的学习外语的方法。但是无论采用哪种方法,学习单词仍然是必要的。为此,有许多不同的模拟器可供选择,需要学习的单词。但是,它们的能力有时还不够。在这些模拟器之一上,我已经学到了足够的单词。并面临一个问题。模拟器提供了一个俄语单词,作为回应,您需要用英语写这个单词,播音员(实际上是语音合成器)然后发出英语版本的声音。我将所有单词完美地写下来,但是,当我看到英文文本时,我只记得我教过这个单词,但我不记得它是什么意思。也就是说,我意识到我缺乏对单词的识别。所选模拟器的另一个缺点是提供了空位供输入,必须在其中输入字母,而且我总是提示一个单词中应该有多少个字母,这不是运动。基于这些考虑,我意识到我想使我的模拟器能够重复学习的单词。该模拟器在翻译方向上应为英语-俄语,并具有英语文本的语音功能,以训练听力。解决问题的步骤如下:- 我从两列中准备了一个csv文件:“单词”和“翻译”,其中包括我需要的所有单词。
- 我下载了Balabolka的控制台版本,这是著名的免费程序tts(文本到语音),用于从文件和剪贴板中对任何文本进行语音处理。
- 我在Windows 10操作系统下的Jupiter Notebook中编写了工作代码。
我没有立即来使用Balabolka。起初我想使用pyttsx3库,但是初始化pyttsx3.init()包时崩溃了很多错误,并且启动pyttsx3.init('dummy')时没有声音。我没有成功克服此程序包的相互误解,因此我不得不寻找其他选择,而我成功使用Balabolka。我得到的代码是这样的:import subprocess, clipboard
import pandas as pd
标准启动。如果熊猫知道一切,那么子流程和剪贴板库对我来说是陌生的。子进程包访问命令行版本的Balabolka,以模拟命令行。剪贴板包允许您将文本复制到剪贴板,语音合成器将从中读取文本。words = pd.read_csv ('C:/.../Python_Scripts/words.csv', delimiter=';')
words.head()
我阅读了准备好的带有单词和翻译的csv文件。words.shape
而且我总是控制变量的值,变量中写的内容以及操作方式。words1 = words.sample(frac=1)
words1.head()
我将单词混入文件中,例如卡片,以免记住单词的顺序。words10 = words1.iloc[0:100]
有时没有足够的时间浏览整个单词文件,在这里您可以限制重复单词的数量。for i in range (len (words10)):
path = r'C:\...\balcon\balcon.exe'
flag = ' -n Slt -s -3 -c'
clipboard.copy (words10['word'].iloc[i])
subprocess.Popen(path + flag, creationflags=0, close_fds = True)
print ("\033[1m {}\033[0m" .format(words10['word'].iloc[i]))
tr = input ()
print ("\033[1m {}\033[0m" .format(words10['translate'].iloc[i]))
res = words10['translate'].iloc[i] == tr
if res == True:
print("\033[1m\033[36m {}\033[0m" .format(''))
else:
print("\033[1m\033[31m {}\033[0m" .format(''))
i = +1
程序本身的文本。在path变量中,我将Balabolka的控制台版本称为balcon.exe文件。控制台将自己的调用参数写入flag变量。具体来说,我在这里使用:- 免费语音-n Slt(它是从语音合成器Olga Yakovleva的开发人员下载的,我以所需的发音清晰度拾起了英语语音,实际上,该语音可以是其他任何一种)
- 发音速度-s -3(此选项表示降低标准的发音速度-3)
- 从剪贴板中读取-c(Balabolka可以从文件和剪贴板中读取文本;我选择了剪贴板,因为用单词创建成千上万个文件是一项艰巨的任务)。
程序的结果如下所示: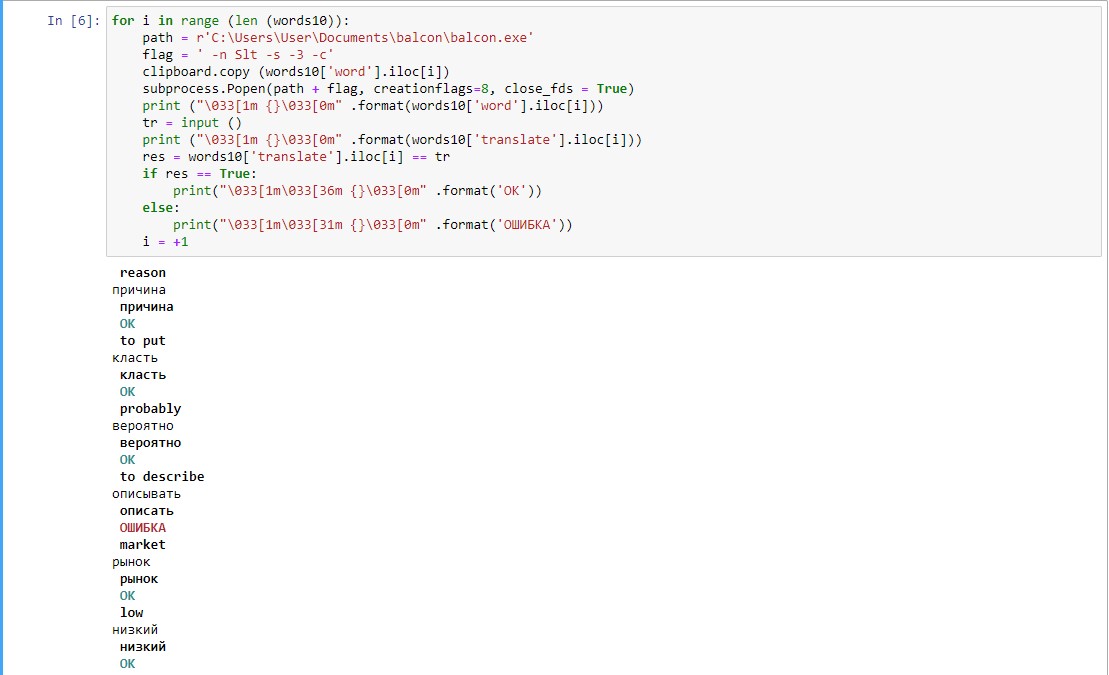 最初,没有突出显示文本的长输出“香肠”看起来是完全不可读的(首先是英文单词,然后是我输入的答案,然后是正确翻译的输出,然后是比较原始版本和输入的结果,每个单词共四行)。这使得分析错误非常困难。我必须使用ANSI代码,以便以后可以快速找到错误的单词。这个最简单的模拟器并不伪装成原始的。已经创建了许多更高级的程序,但是要解决我自己的本地问题,此结果适合我。我可以从头到尾控制它。可以修改脚本,删除英语单词的拼写,仅留下声音并训练听力。您还可以更改英语单词的翻译和训练方向,这在原始模拟器中对我来说是不够的,整个故事由此而生。如果这个简单的脚本可以帮助那些不具备强大编程技能的人创建自己的模拟器或基于此代码实现其他东西,我将感到很高兴。
最初,没有突出显示文本的长输出“香肠”看起来是完全不可读的(首先是英文单词,然后是我输入的答案,然后是正确翻译的输出,然后是比较原始版本和输入的结果,每个单词共四行)。这使得分析错误非常困难。我必须使用ANSI代码,以便以后可以快速找到错误的单词。这个最简单的模拟器并不伪装成原始的。已经创建了许多更高级的程序,但是要解决我自己的本地问题,此结果适合我。我可以从头到尾控制它。可以修改脚本,删除英语单词的拼写,仅留下声音并训练听力。您还可以更改英语单词的翻译和训练方向,这在原始模拟器中对我来说是不够的,整个故事由此而生。如果这个简单的脚本可以帮助那些不具备强大编程技能的人创建自己的模拟器或基于此代码实现其他东西,我将感到很高兴。