在Uchi.ru中,我们尝试通过A / B测试进行甚至很小的改进,在本学年中有250多项,A / B测试是强大的变更测试工具,没有它,很难想象互联网产品的正常开发。同时,尽管表面上看起来很简单,但是在A / B测试过程中,无论是在实验的设计阶段还是在对结果进行总结时,都可能出现严重的错误。在本文中,我将讨论测试的一些技术方面:当提前完成测试以及一次测试多个假设时,我们如何确定测试期限,进行总结以及如何避免错误结果。 对于我们(以及许多人)而言,典型的A / B测试方案如下所示:
对于我们(以及许多人)而言,典型的A / B测试方案如下所示:- 我们正在开发一项功能,但是在将其推广给所有受众之前,我们希望确保它可以改善目标指标,例如参与度。
- 我们确定测试的启动时间。
- 我们将用户随机分为两组。
- 我们向一组展示具有功能的产品版本(实验组),向另一组展示旧的(控件)版本。
- 在此过程中,我们将监控指标,以便及时停止特别失败的测试。
- 测试到期后,我们比较实验组和对照组的指标。
- 如果实验组的指标在统计学上明显优于对照组,则我们将推出所有测试功能。如果没有统计学意义,我们以阴性结果结束测试。
一如既往,细节上看起来一切都很逻辑和简单。统计意义,标准和错误
任何A / B测试都具有随机性的元素:组指标不仅取决于其功能,还取决于用户进入其中的方式以及行为方式。为了可靠地得出有关团队优势的结论,您需要在测试中收集足够的观察结果,但是即使如此,您也无法避免犯错误。它们分为两种类型:- 如果我们修复组之间的差异,则会发生第一种错误,尽管实际上并不存在。文本还将包含一个等效术语-错误的肯定结果。本文专门针对此类错误。
- 如果我们纠正了不存在差异的情况,则会发生第二种错误,尽管实际上是这样。
在大量实验中,重要的是第一类错误的可能性要小。可以使用统计方法进行控制。例如,我们希望每个实验中第一类错误的概率不超过5%(这只是一个方便的值,您可以根据自己的需要选择另一个值)。然后,我们将以0.05的显着性水平进行实验:- 对照组A和实验组B进行了A / B测试。目标是验证B组与A组在某些度量标准上是否不同。
- 我们提出了无效的统计假设:A组和B组没有差异,并且观察到的差异由噪声解释。默认情况下,我们总是认为在证明相反之前没有区别。
- 我们使用严格的数学规则(例如统计标准,例如学生的标准)检查假设。
- 结果,我们得到了p值。它在0到1的范围内,表示在零假设为真的情况下(即在组之间不存在差异的情况下)看到组之间当前或更大的极端差异的可能性。
- 将p值与0.05的显着性水平进行比较。如果它更大,我们接受没有差异的零假设,否则我们认为两组之间存在统计学上的显着差异。
可以用参数或非参数标准检验假设。参数变量依赖于随机变量样本分布的参数并具有更大的功效(它们较少犯第二类错误),但是它们对所研究的随机变量的分布提出了要求。最常见的参数测试是学生测试。对于两个独立的样本(A / B测试用例),有时称为韦尔奇判据。如果研究数量呈正态分布,则此标准正确运行。似乎在真实数据上几乎从未满足过此要求,但实际上测试需要样本平均值的正态分布,而不是样本本身。在实践中,这意味着如果您在测试中有很多观察结果(数十到数百个)并且分布中没有很长的尾巴,则可以应用该标准。初始观测值分布的性质并不重要。读者可以独立地验证学生准则是否正确工作,即使是从伯努利或指数分布生成的样本上也是如此。在非参数标准中,曼-惠特尼标准很受欢迎。如果您的样本很小或有较大的离群值,则应使用该方法(该方法会比较中位数,因此可以抵抗离群值)。同样,为了使准则正常工作,样本应具有很少的匹配值。在实践中,我们从来不必应用非参数标准,在我们的测试中,我们始终使用学生标准。多重假设检验问题
最明显和最简单的问题:如果在测试中,除对照组外,还有几个实验组,然后将结果的显着性水平汇总为0.05,将导致第一种错误的比例成倍增加。这是因为,对于统计标准的每次应用,第一类错误的概率将为5%。随着组数 和显着性水平 一些实验小组会偶然获胜的概率是:
例如,对于三个实验组,我们得到了14.3%,而不是预期的5%。Bonferroni对多个假设检验的更正解决了该问题:您只需要将显着性水平除以比较次数(即组)即可使用。对于上面的示例,考虑到修正,显着性水平将为0.05 / 3 = 0.0167,并且至少一个第一种错误的可能性为4.9%。希尔法-邦费罗尼— , , , .
p-value ,
:
P-value
. , p-value
, . - , . ( , ) p-value, . A/B- — , — .
严格来说,按不同指标或受众群体进行分组比较也要经受多重测试的问题。从形式上来说,很难将所有检查都考虑在内,因为它们的数量很难预先预测,有时它们不是独立的(尤其是涉及不同的指标而不是分片的时候)。没有通用的配方,只能依靠常识并记住,如果您使用不同的指标检查了很多切片,那么在任何测试中您都可以看到据称具有统计学意义的结果。因此,例如,应该谨慎对待来自大城市的新移动用户的第五天保留时间的显着增加。偷窥问题
多重假设检验的一个特殊情况是偷看问题。关键是测试期间的p值可能会意外下降到可接受的显着性水平以下。如果您仔细监控实验,则可以抓住这一时刻,并在统计意义上犯错误。假设我们放弃了本文开头所述的测试设置,并决定每天以5%的显着性水平(或在测试过程中多次)评估库存。综上所述,我了解到,如果p值低于0.05,则测试为阳性,否则为连续。使用这种策略,假阳性结果的比例将与支票的数量成正比,并且在第一个月将达到28%。如此巨大的差异似乎违反直觉,因此我们转向A / A测试的方法,这对于A / B测试方案的开发是必不可少的。A / A测试的想法很简单:使用随机分组对随机数据模拟很多A / B测试。两组之间显然没有区别,因此您可以准确地估计A / B测试方案中第一类错误的比例。下面的gif显示了四个此类测试的p值如何每天变化。相等的0.05显着性水平由虚线表示。当p值低于此值时,我们将测试图着色为红色。如果此时将测试结果相加,则认为成功。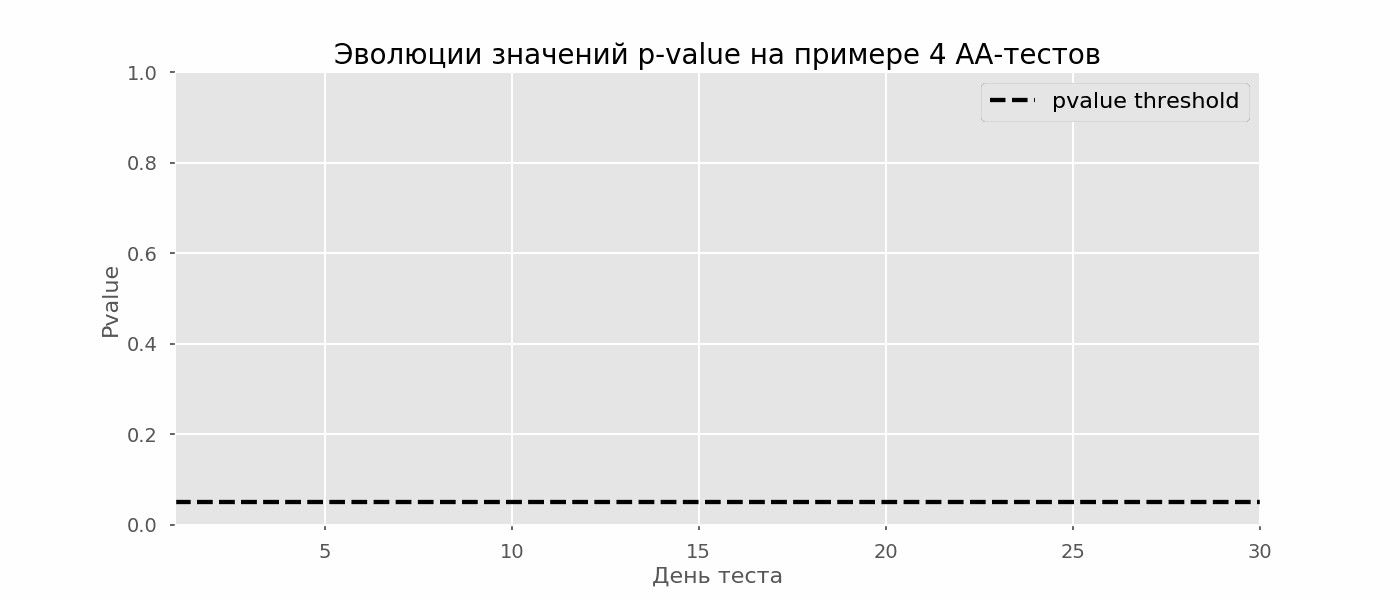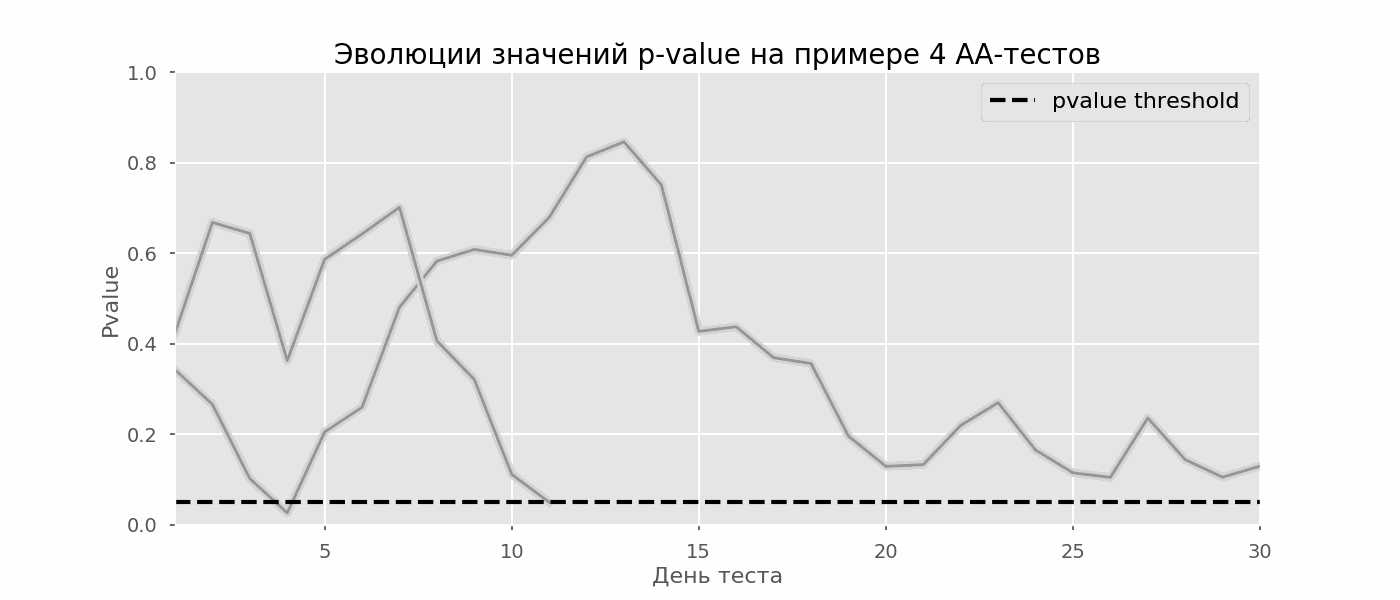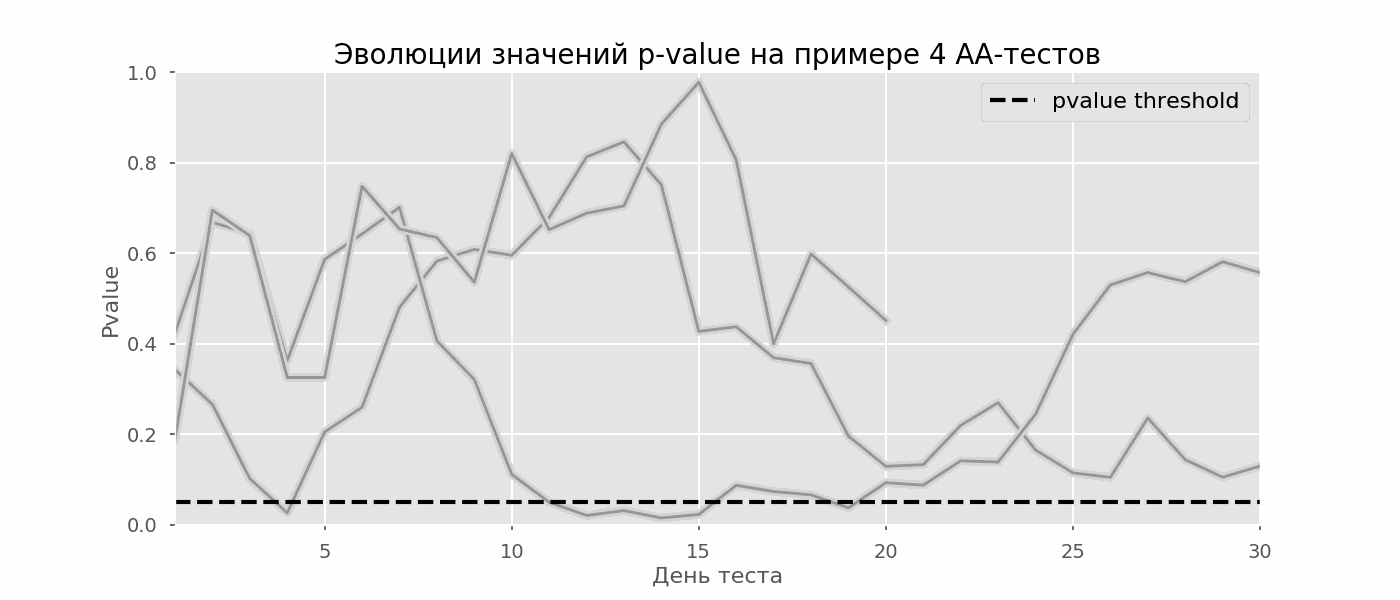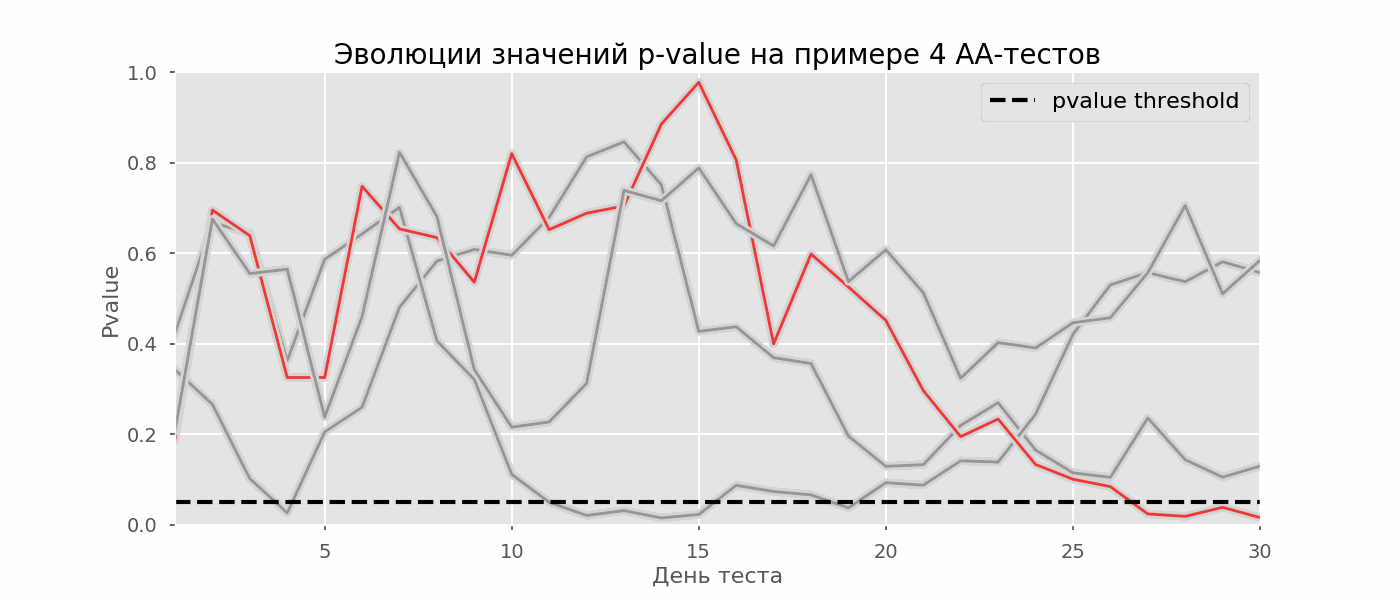 同样,我们计算了持续一个月的一万次A / A检验,并将该方案中假阳性结果的分数与学期末和每天的求和结果进行比较。为了清楚起见,这是前100次模拟的p值每天的漫游时间表。每行是一个测试的p值,测试的轨迹以红色突出显示,结果被错误地认为是成功的(越少越好),虚线是识别该测试成功的必要p值。
同样,我们计算了持续一个月的一万次A / A检验,并将该方案中假阳性结果的分数与学期末和每天的求和结果进行比较。为了清楚起见,这是前100次模拟的p值每天的漫游时间表。每行是一个测试的p值,测试的轨迹以红色突出显示,结果被错误地认为是成功的(越少越好),虚线是识别该测试成功的必要p值。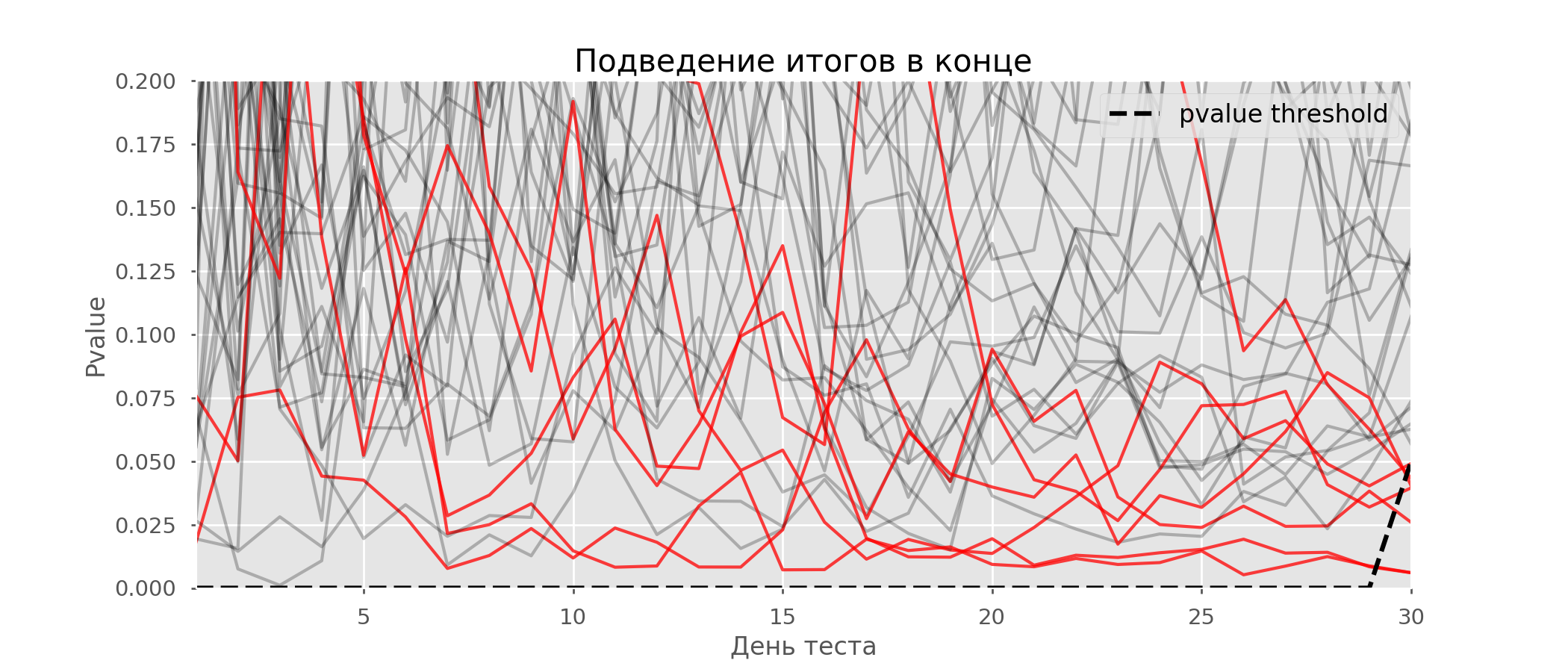 在图表上,您可以算出7个假阳性测试,而在1万个测试中,总共有502个,即5%。应该注意的是,在观察过程中,许多检验的p值均低于0.05,但到观察结果结束时,其p值已超过显着性水平。现在,让我们每天进行汇报以评估测试方案:
在图表上,您可以算出7个假阳性测试,而在1万个测试中,总共有502个,即5%。应该注意的是,在观察过程中,许多检验的p值均低于0.05,但到观察结果结束时,其p值已超过显着性水平。现在,让我们每天进行汇报以评估测试方案: 红线太多了,什么都不清楚。当p值达到临界值时,我们将通过破坏测试线来重新绘制:
红线太多了,什么都不清楚。当p值达到临界值时,我们将通过破坏测试线来重新绘制: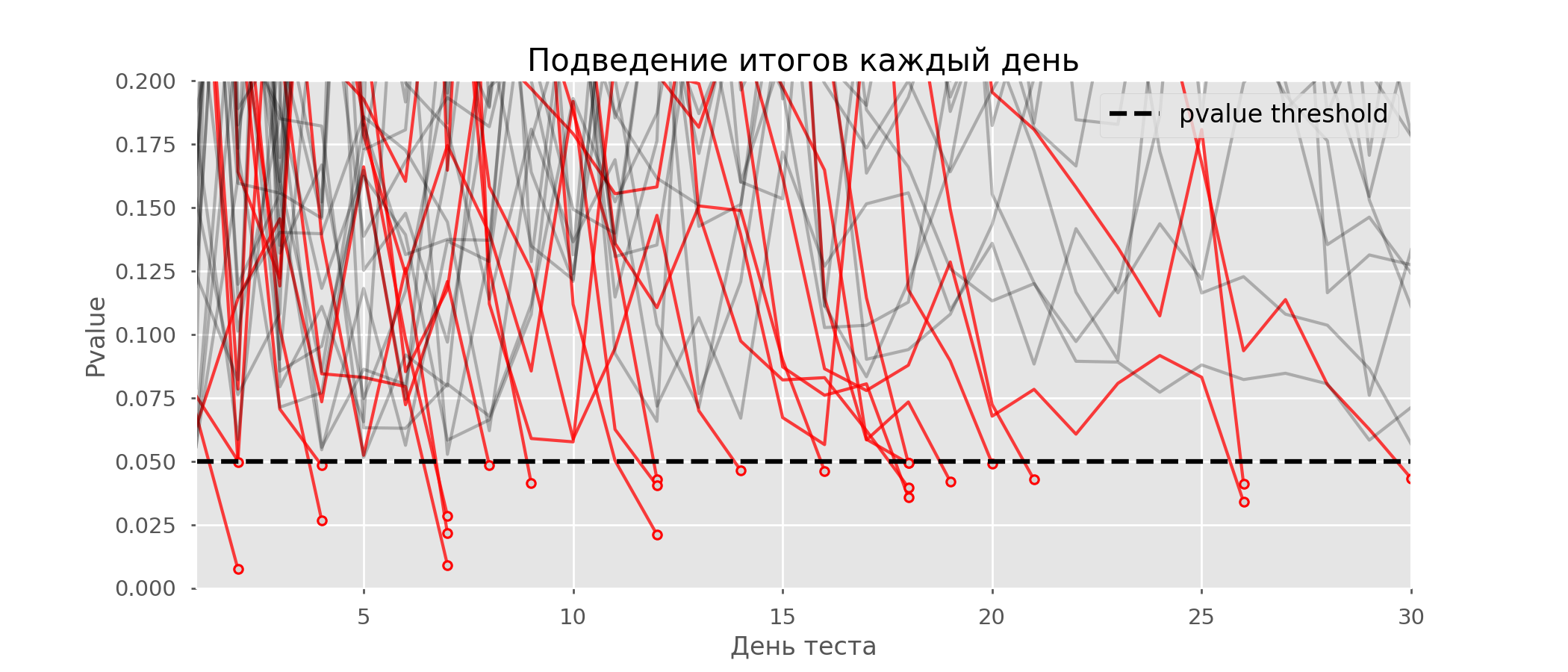 在1万个假阳性测试中,总共有2813个假阳性测试,占28%。显然,这种方案是不可行的。尽管窥视问题是多次测试的特例,但由于标准校正过于保守,因此不值得应用标准校正。下图显示了假阳性结果的百分比,取决于测试组的数量(红线)和窥视的数量(绿线)。
在1万个假阳性测试中,总共有2813个假阳性测试,占28%。显然,这种方案是不可行的。尽管窥视问题是多次测试的特例,但由于标准校正过于保守,因此不值得应用标准校正。下图显示了假阳性结果的百分比,取决于测试组的数量(红线)和窥视的数量(绿线)。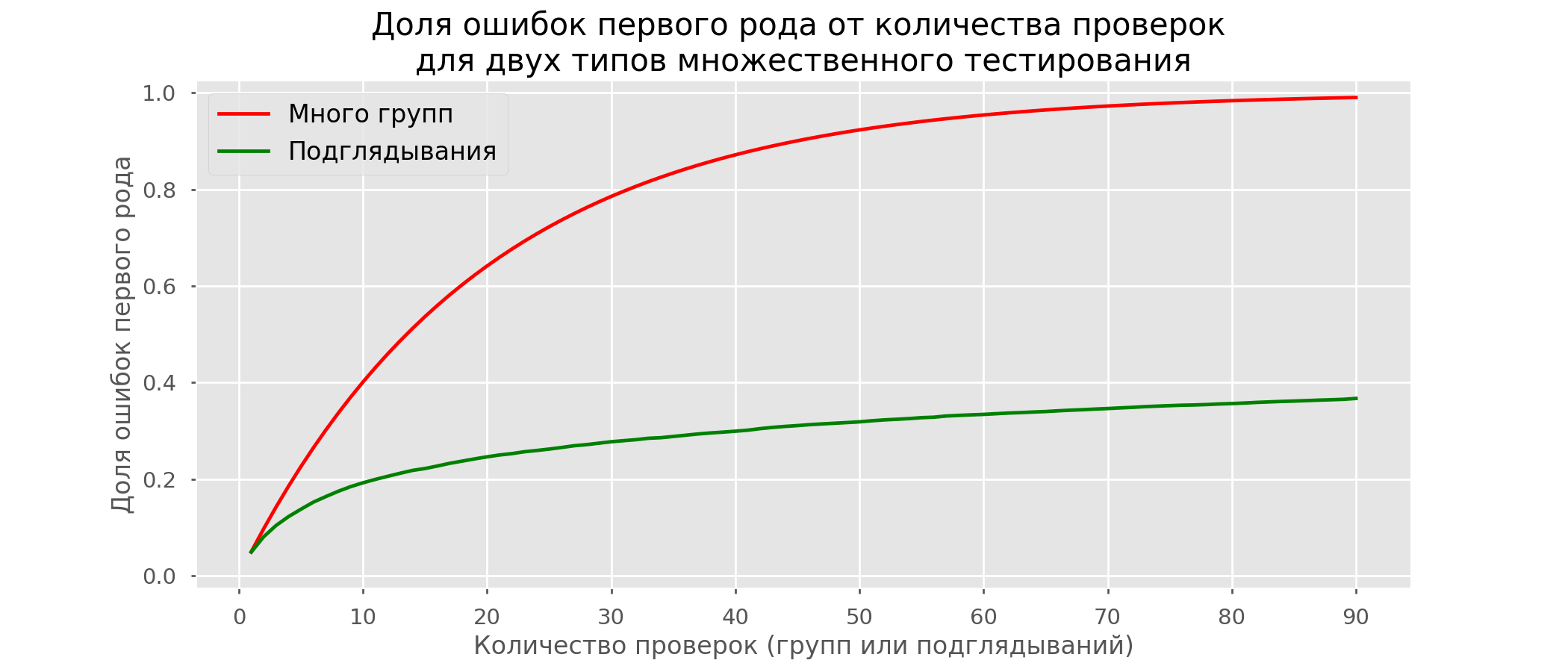 尽管在无限远和窥视时接近1,但错误的比例增长得慢得多。这是因为在这种情况下,比较不再是独立的。
尽管在无限远和窥视时接近1,但错误的比例增长得慢得多。这是因为在这种情况下,比较不再是独立的。早期测试方法
有一些测试选项可以让您过早地参加测试。我将讨论其中两个:重要性保持不变(Pocock校正),并且依赖于窥视次数(O'Brien-Fleming校正)。严格来说,对于这两个更正,您都需要提前知道最大测试时间以及测试开始和结束之间的检查次数。此外,检查应在大约相等的时间间隔(或相等数量的观察值)进行。波科克
方法是我们每天汇总测试结果,但重要性降低(更严格)。例如,如果我们知道进行的检查不超过30次,则显着性水平应设置为等于0.006(根据使用蒙特卡洛方法(即根据经验)的窥视次数选择)。在我们的模拟中,我们得到4%的假阳性结果-显然,阈值可能会增加。 尽管很幼稚,但是一些大公司还是使用这种特殊方法。如果您根据敏感指标和大量流量做出决策,这将非常简单可靠。例如,在Avito中,默认情况下,重要性级别设置为0.005。
尽管很幼稚,但是一些大公司还是使用这种特殊方法。如果您根据敏感指标和大量流量做出决策,这将非常简单可靠。例如,在Avito中,默认情况下,重要性级别设置为0.005。奥布莱恩·弗莱明
在这种方法中,重要性级别根据验证编号而变化。有必要预先确定测试中的步骤(或窥视)的数量,并计算每个步骤的显着性水平。我们越早尝试完成测试,将应用越严格的标准。学生统计阈值 (包括最后一步中的值 )对应于所需的显着性水平取决于验证号 (取值从1到支票总数 并根据经验获得的公式进行计算:
赔率码from sklearn.linear_model import LinearRegression
from sklearn.metrics import explained_variance_score
import matplotlib.pyplot as plt
total_steps = [
2, 3, 4, 5, 6, 8, 10, 15, 20, 25, 30, 50, 60
]
last_z = [
1.969, 1.993, 2.014, 2.031, 2.045, 2.066, 2.081,
2.107, 2.123, 2.134, 2.143, 2.164, 2.17
]
features = [
[1/t, 1/t**0.5] for t in total_steps
]
lr = LinearRegression()
lr.fit(features, last_z)
print(lr.coef_)
print(lr.intercept_)
print(explained_variance_score(lr.predict(features), last_z))
total_steps_extended = np.arange(2, 80)
features_extended = [ [1/t, 1/t**0.5] for t in total_steps_extended ]
plt.plot(total_steps_extended, lr.predict(features_extended))
plt.scatter(total_steps, last_z, s=30, color='black')
plt.show()
相关显着性水平通过百分位数计算 与学生统计值相对应的标准分布 :perc = scipy.stats.norm.cdf(Z)
pval_thresholds = (1 − perc) * 2
在相同的模拟中,它看起来像这样: 假阳性结果是10000个中的501,或预期的5%。请注意,显着性水平甚至到最后都没有达到5%的值,因为在所有检查中都应“涂抹”这5%。在公司,如果我们进行测试并可能尽早停止,我们将使用此更正。您可以在此处阅读有关相同和其他修订的内容。
假阳性结果是10000个中的501,或预期的5%。请注意,显着性水平甚至到最后都没有达到5%的值,因为在所有检查中都应“涂抹”这5%。在公司,如果我们进行测试并可能尽早停止,我们将使用此更正。您可以在此处阅读有关相同和其他修订的内容。A / B测试计算器
我们产品的特性使得任何度量标准的分布会根据测试的受众(例如,班级号)和一年中的时间而有很大的不同。因此,本着“每个组中键入100万用户时测试将结束”或“已解决任务数达到1亿时测试将结束”的精神,将无法接受测试结束日期的规则。也就是说,它会起作用,但实际上,为此,有必要考虑太多因素:- 什么班参加考试;
- 考试分发给老师或学生;
- 学年时间;
- 测试所有用户或仅测试新用户。
但是,在我们的A / B测试方案中,您总是需要提前确定结束日期。为了预测测试的持续时间,我们开发了一个内部应用程序-A / B测试计算器。根据过去一年中来自选定细分市场的用户活动,该应用程序计算必须运行测试的时间,才能通过选定指标将提升显着地固定在X%。还自动考虑了对多个测试的校正,并为早期测试停止计算了阈值显着性水平。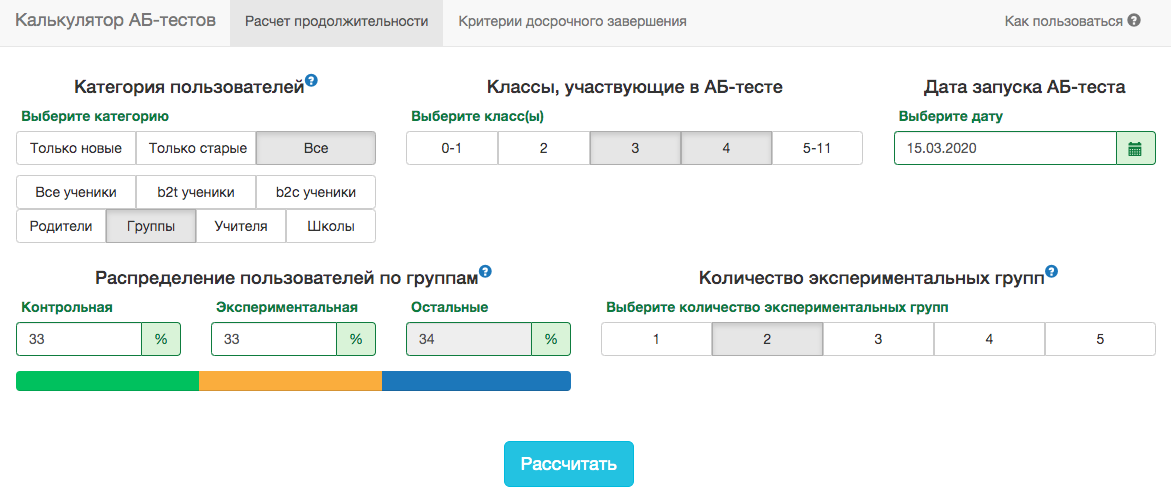 所有度量标准都是在测试对象级别上计算的。如果度量标准是已解决问题的数量,则在教师级别的测试中,这将是他的学生已解决问题的总和。由于我们使用学生准则,因此我们可以为所有可能的切片预先计算计算器所需的单位。从测试开始的每一天,您需要知道测试中的人数,指标的平均值 及其方差 。固定对照组的份额实验组 测试的预期收益 以百分比为单位,您可以计算学生统计数据的期望值 以及每天测试的相应p值:
所有度量标准都是在测试对象级别上计算的。如果度量标准是已解决问题的数量,则在教师级别的测试中,这将是他的学生已解决问题的总和。由于我们使用学生准则,因此我们可以为所有可能的切片预先计算计算器所需的单位。从测试开始的每一天,您需要知道测试中的人数,指标的平均值 及其方差 。固定对照组的份额实验组 测试的预期收益 以百分比为单位,您可以计算学生统计数据的期望值 以及每天测试的相应p值:
接下来,很容易每天获得p值:pvalue = (1 − scipy.stats.norm.cdf(ttest_stat_value)) * 2
了解p值和显着性水平,并考虑到测试的每一天,在测试的任何持续时间内的所有校正,您可以计算出可以检测到的最小隆起(在英语文献中-MDE,最小可检测效果)。此后,很容易解决反问题-确定确定预期上升所需的天数。结论
最后,我想回顾一下本文的主要信息:- 如果您按组比较指标的平均值,最有可能的是,学生准则将适合您。例外是极小的样本量(数十个观察值)或异常的度量分布(实际上,我还没有看到这种情况)。
- 如果测试中有多个组,请对多个假设测试使用更正。最简单的Bonferroni校正即可。
- .
- . .
- . , , , , O'Brien-Fleming.
- A/B-, A/A-.
尽管有上述所有内容,但由于数学上的严格性,业务和常识不应受到影响。有时,对于未在测试中显着增加的所有功能,都可以推出其功能,而根本不需要测试就不可避免地会发生一些变化。但是,如果您每年进行数百次测试,那么准确的分析就尤为重要。否则,存在误报测试数量与真正有用的数量相当的风险。