 您好,habrozhiteli!Paul和Harvey Daytels重新审视了Python,并使用独特的方法快速解决了现代IT人员面临的问题。您可以使用五百多种实际任务-从片段到40个大型方案和实例以及完整实现。带Jupyter Notebooks的IPython使您可以快速学习现代Python编程习惯。第1章至第5章以及第6章至第7章的片段将为第11章至第16章提供解决人工智能问题的清晰示例。您将学习自然语言处理,Twitter上的情感分析,IBM Watson认知计算,分类和回归问题上的老师进行机器学习,聚类中没有老师的机器学习,深度学习和卷积神经网络的模式识别,递归神经网络,大型来自Hadoop,Spark和NoSQL,IoT等的数据。您将(直接或间接)使用云服务,包括Twitter,Google Translate,IBM Watson,Microsoft Azure,OpenMapQuest,PubNub等
您好,habrozhiteli!Paul和Harvey Daytels重新审视了Python,并使用独特的方法快速解决了现代IT人员面临的问题。您可以使用五百多种实际任务-从片段到40个大型方案和实例以及完整实现。带Jupyter Notebooks的IPython使您可以快速学习现代Python编程习惯。第1章至第5章以及第6章至第7章的片段将为第11章至第16章提供解决人工智能问题的清晰示例。您将学习自然语言处理,Twitter上的情感分析,IBM Watson认知计算,分类和回归问题上的老师进行机器学习,聚类中没有老师的机器学习,深度学习和卷积神经网络的模式识别,递归神经网络,大型来自Hadoop,Spark和NoSQL,IoT等的数据。您将(直接或间接)使用云服务,包括Twitter,Google Translate,IBM Watson,Microsoft Azure,OpenMapQuest,PubNub等9.12.2。在熊猫库DataFrame集合中读取CSV文件
前两章的“数据科学导论”部分介绍了使用熊猫的基础知识。现在,我们将演示用于下载CSV文件的熊猫工具,然后执行基本的数据分析操作。数据集
在实际的数据科学示例中,将使用各种免费和开放的数据集来演示机器学习和自然语言处理的概念。 Internet上有大量免费数据集。流行的Rdatasets存储库包含指向1,100多个免费CSV数据集的链接。这些工具包最初是随R编程语言一起提供的,以简化统计程序的研究和开发,但是,它们与R语言无关,现在可以在GitHub上找到这些工具包:https ://vincentarelbundock.imtqy.com/Rdatasets/ Datasets.html该存储库非常流行,以至于有一个专门用于访问Rdatasets的pydataset模块。有关安装pydataset和访问数据集的说明,请访问:https
: //github.com/iamaziz/PyDataset另一个很好的数据集来源:https ://github.com/awesomedata/awesome-public-datasets泰坦尼克号碰撞数据集是初学者最常用的机器学习数据集,其中列出了所有乘客以及泰坦尼克号与冰山相撞并于1912年4月14日至15日沉没时是否幸免于难。我们将使用此集来显示如何加载数据集,查看其数据以及获取描述性统计信息。其他受欢迎的数据集将在本书稍后的数据科学示例章节中进行探讨。使用本地CSV文件要将CSV数据集加载到DataFrame中,可以使用pandas库的read_csv函数。以下代码段下载并显示了本章前面创建的CSV account.csv文件:In [1]: import pandas as pd
In [2]: df = pd.read_csv('accounts.csv',
...: names=['account', 'name', 'balance'])
...:
In [3]: df
Out[3]:
account name balance
0 100 Jones 24.98
1 200 Doe 345.67
2 300 White 0.00
3 400 Stone -42.16
4 500 Rich 224.62
names参数指定DataFrame的列名称。如果没有此参数,read_csv会认为CSV文件的第一行包含逗号分隔的列名列表。要将DataFrame数据保存在CSV文件中,请调用DataFrame集合的to_csv方法:In [4]: df.to_csv('accounts_from_dataframe.csv', index=False)
关键参数index = False表示不应将行名(片段[3]中DataFrame输出的左侧的0–4)写入文件。结果文件的第一行包含列名称:account,name,balance
100,Jones,24.98
200,Doe,345.67
300,White,0.0
400,Stone,-42.16
500,Rich,224.62
9.12.3。读取泰坦尼克号灾难数据集
泰坦尼克号灾难数据集是最流行的机器学习数据集之一,并且可用多种格式提供,包括CSV。通过URL下载泰坦尼克号灾难数据集
如果您有一个以CSV格式表示数据集的URL,则可以使用read_csv函数将其加载到DataFrame中-假设是从GitHub:In [1]: import pandas as pd
In [2]: titanic = pd.read_csv('https://vincentarelbundock.imtqy.com/' +
...: 'Rdatasets/csv/carData/TitanicSurvival.csv')
...:
查看泰坦尼克号灾难数据集的某些行该数据集包含1300多行,每行代表一位乘客。根据维基百科,机上大约有1317名乘客,其中815人死亡1。对于大型数据集,在输出DataFrame时仅显示前30行,然后显示省略号“ ...”和后30行。为了节省空间,我们将使用DataFrame集合的head和tail方法查看第一行和最后五行。两种方法默认都返回五行,但是可以在参数中传递显示的行数:在[3]中:pd.set_option('precision',2)#浮点值的格式请注意:pandas根据列或列名称中的最宽值(取决于宽度最大的值)来调整每列的宽度;行1305的age列中的NaN是NaN-数据集中缺少值的标志。设置列名称数据集中第一列的名称看起来很奇怪(“未命名:0”)。可以通过自定义列名称来解决此问题。将“未命名:0”替换为“名称”,并将“ passengerClass”减少为“ class”:

9.12.4。以Titanic灾难数据集为例进行简单数据分析
现在,我们将使用熊猫来进行简单的数据分析,以描述性统计的某些特征为例。当您为包含数字和非数字列的DataFrame集合调用describe时,describe仅计算数字列的统计特征-在这种情况下,仅计算age列: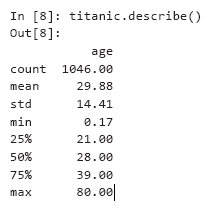 注意计数(1046)和数据集中数据的行数的差异(1309-调用tail时,最后一行的索引为1308)。仅1046行数据(计数值)包含年龄值。其余的结果丢失,并用NaN标记,如第1305行所示。执行计算时,pandas库默认情况下会忽略丢失的数据(NaN)。对于1046名有效年龄的乘客,平均年龄(预期)为29.88岁。最小的乘客(最小)只有两个月大(0.17 * 12等于2.04),最大的乘客(最大)是80岁。中位年龄为28岁(以四分位数的50%表示)。 25%的四分位数表示上半年乘客的年龄中位数(按年龄排列),75%的四分位数是下半部分乘客的中位数。假设您要计算有关尚存乘客的统计信息。我们可以将幸存的列与值“是”进行比较,以获取具有True / False值的新Series集合,然后使用describe描述结果:
注意计数(1046)和数据集中数据的行数的差异(1309-调用tail时,最后一行的索引为1308)。仅1046行数据(计数值)包含年龄值。其余的结果丢失,并用NaN标记,如第1305行所示。执行计算时,pandas库默认情况下会忽略丢失的数据(NaN)。对于1046名有效年龄的乘客,平均年龄(预期)为29.88岁。最小的乘客(最小)只有两个月大(0.17 * 12等于2.04),最大的乘客(最大)是80岁。中位年龄为28岁(以四分位数的50%表示)。 25%的四分位数表示上半年乘客的年龄中位数(按年龄排列),75%的四分位数是下半部分乘客的中位数。假设您要计算有关尚存乘客的统计信息。我们可以将幸存的列与值“是”进行比较,以获取具有True / False值的新Series集合,然后使用describe描述结果:In [9]: (titanic.survived == 'yes').describe()
Out[9]:
count 1309
unique 2
top False
freq 809
Name: survived, dtype: object
对于非数值数据,describe描述显示统计的各种特征:- count-结果中元素的总数;
- 唯一-结果是唯一值的数量(2)-真(乘客幸存)或假(乘客死亡);
- top-结果中最常遇到的值;
- freq-值top的出现次数。
9.12.5。乘客年龄的条形图
可视化是更好地了解数据的好方法。Pandas包含许多基于Matplotlib的内置可视化工具。要使用它们,首先在IPython中启用Matplotlib支持:In [10]: %matplotlib
直方图清楚地显示了数值数据在一系列值上的分布。DataFrame集合的hist方法自动分析每个数字列的数据并构建相应的直方图。要查看数据的每个数字列的直方图,请为您的DataFrame集合调用hist:In [11]: histogram = titanic.hist()
泰坦尼克号灾难数据集仅包含一个数字列数据,因此该图显示了年龄分布的直方图。对于具有多个数字列的数据集,hist为每个数字列创建一个单独的直方图。»书上的更多信息可以在找到出版商的网站» 目录» 摘录对于Khabrozhiteley上的优惠券优惠25% - 的Python在缴付书(发布日期-纸质版6月5日),电子书发送。