我仍然没有读过托尔斯泰的小说史诗《战争与和平》,在学校里,由于作者的“话语”,这并不有趣,而且由于某种原因,没有时间开始如此庞大的工作。但是,我认为值得研究...训练
我没有清除第三方文字和符号(拉丁文的部件号,脚注号和注释的一部分),即在小说文本将近40万个单词的背景下,即使是一千个单词的错误也不会提供错误的数据,但是我决定进行最少的准备工作。文件准备程序的一部分from collections import Counter
import matplotlib.pyplot as plt
import numpy as np
#filename = input(« : „)
filename = #
file = open(filename, 'r')
text = file.read()
text = text.replace(“\n», " ")
text =text.replace(']','').replace('[','').replace('\"','').replace(",", "").replace(".", "").replace("?", "").replace("!", "").replace(")", "").replace("(", "")
text =text.lower()
words_untill = text.split() #
…
作为一个不断处理数字的人,我对以下问题感兴趣:1.小说中最长的单词
从他的妻子那里得知列夫·尼古拉耶维奇仍然是那位绘画狂的人后,他决定找出自己为托尔斯泰的小说发明了多长时间。因此,TOP 3个长字。第一名(27个字母和一个连字符)除以“ 超自然的美丽,超自然的精致和令人无法抗拒的魅力”这两个字:...一个好的服务生如何将超自然的美丽当成一块牛肉,如果您在肮脏的厨房里看到它就不会想要,所以今晚,安娜·帕夫洛芙娜(Anna Pavlovna)首先为她的客人服务,然后是方丈,这是一种超自然的精致 ……法国人很自信,因为他在身心方面都尊重自己,男人和女人都无法抗拒的魅力。英国人以自己是世界上最舒适国家的公民而感到自信,因此,作为一个英国人,他总是知道自己需要做什么,并且知道他作为英国人所做的一切无疑是一件好事。义大利人很自信,因为他很兴奋,容易忘记自己和他人……第二名(25个字母和一个连字符)使这个词单调多样:……轻骑兵没有回头,但每经过一个中核,就好像指挥部一样,整个中队他单调不同的面孔,屏住了呼吸,而核心飞去,他站起身箍筋和再次下跌......第三位(24个字母),把字尊敬的,这个词,与以前的词不同,出现了八次,是对米哈伊尔·伊哈拉里诺维奇·库图佐夫元帅的呼吁。查找最长单词的程序的一部分from collections import Counter
import matplotlib.pyplot as plt
import numpy as np
…
words = text.split() # , ,
words = sorted(words, key = len, reverse=True) #
…
for i in range(3): #
print(words[i].ljust(30), len(words[i])) # -3
…
2.最常用的词
以前,该列表中清除了一个和两个字母的单词,以便从比较循环中删除介词和短代词。第一次迭代后,结果发现TOP-10中不包含三个字母(剑,邪恶,后方等),我依次从三个字母的单词中清除了列表,甚至在进一步实验后也从四个字母的单词中清除了该列表。话。简短单词清除程序的一部分…
words2 =[]# c,
for i in range(len(words)):#
if len(words[i])>4:
words2.append(words[i])
else: break # , , ,
…
在最常用的单词列表中没有太多的名词,因此我不得不从小说的单词列表中删除单词“ only”,“ when”,“ so”,“ now”,“ this”,“ that”,“ when” 其中,“因为”,“再次”,“突然”,“非常”,“没有”,“他的”。查找最流行单词的程序的一部分…
words_counts = Counter(words2)
n = []
pop_word = []
for word, count in words_counts.most_common(10):# -10
n.append(count)
pop_word.append(word)
print(word.ljust(20), count)
…
结果,TOP-10流行语:1.说-14112.王子-9523.时间-5444.安德烈-5005.讲话-4646.公主-4357.说-4248.人们-3919。娜塔莎(Natasha)-37610.人们-372由于搜索是在不考虑单词形式的情况下进行的,因此对于“王子”,我必须找到单词的所有形式。在澄清了数据之后,PRINCE在小说中以1435种参考文献排在首位,与动词TOLD相对。搜索所有形式的单词PRINCE…
n4 = []
form_n4 = []
for i in range(len(words_untill)):
if «» in words_untill[i]:
n4.append(1)
form_n4.append(words_untill[i])
else: n4.append(0)
print(« — » + str(len(form_n4)))
…
从清单中可以看出,动词SAID(1411)和SPEAKED(464)在小说中比动词SAID(424)更为常见,这表明男人在小说中讲的声音是女人的4.5倍(在这里听到了指责)列夫·尼古拉耶维奇(Lev Nikolaevich)的性别歧视),而公主(435)的出现频率则远低于王子。社会对娜塔莉亚·伊里尼希纳·罗斯托娃又名娜塔莎·罗斯托娃的态度也变得很有趣。在整部小说中,她一直是娜塔莎(Natasha),尽管事实上,到小说结尾,娜塔莉亚·罗斯托娃(Natalia Rostova)成为了皮埃尔·别祖霍夫(Pierre Bezukhov)的妻子。在所有形式中,Natasha在文本中出现591次,而名称Natalia和Natalie的形式仅出现9次。3.小说中的战争在哪里?
尽管有名字,小说中的“战争”以各种形式仅发生了278次。搜索单词WAR的所有形式…
n3 = []
form_n3 = []
for i in range(len(words_untill)):
if «» in words_untill[i] and «» not in words_untill[i]:# «»
n3.append(1)
form_n3.append(words_untill[i])
else: n3.append(0)
print(form_n3)
print(« — » + str(len(form_n3)))
…
我将整部小说分为1万个字,并决定在小说创作过程中追溯对“王子”,“娜塔莎”和“战争”的引用。打破一万字的小说…
: «0» — , «1» — .
…
m1=[]
m2=[]
m3 =[]
m4 = []
while i <= len(n1):
m1.append(sum(n1[i: i+10000]))# «»
m2.append(sum(n4[i: i+10000]))# «»
m3.append(sum(n3[i: i+10000]))# «»
m4.append(sum(nata1[i: i+10000]))# «»
i=i+10000
…
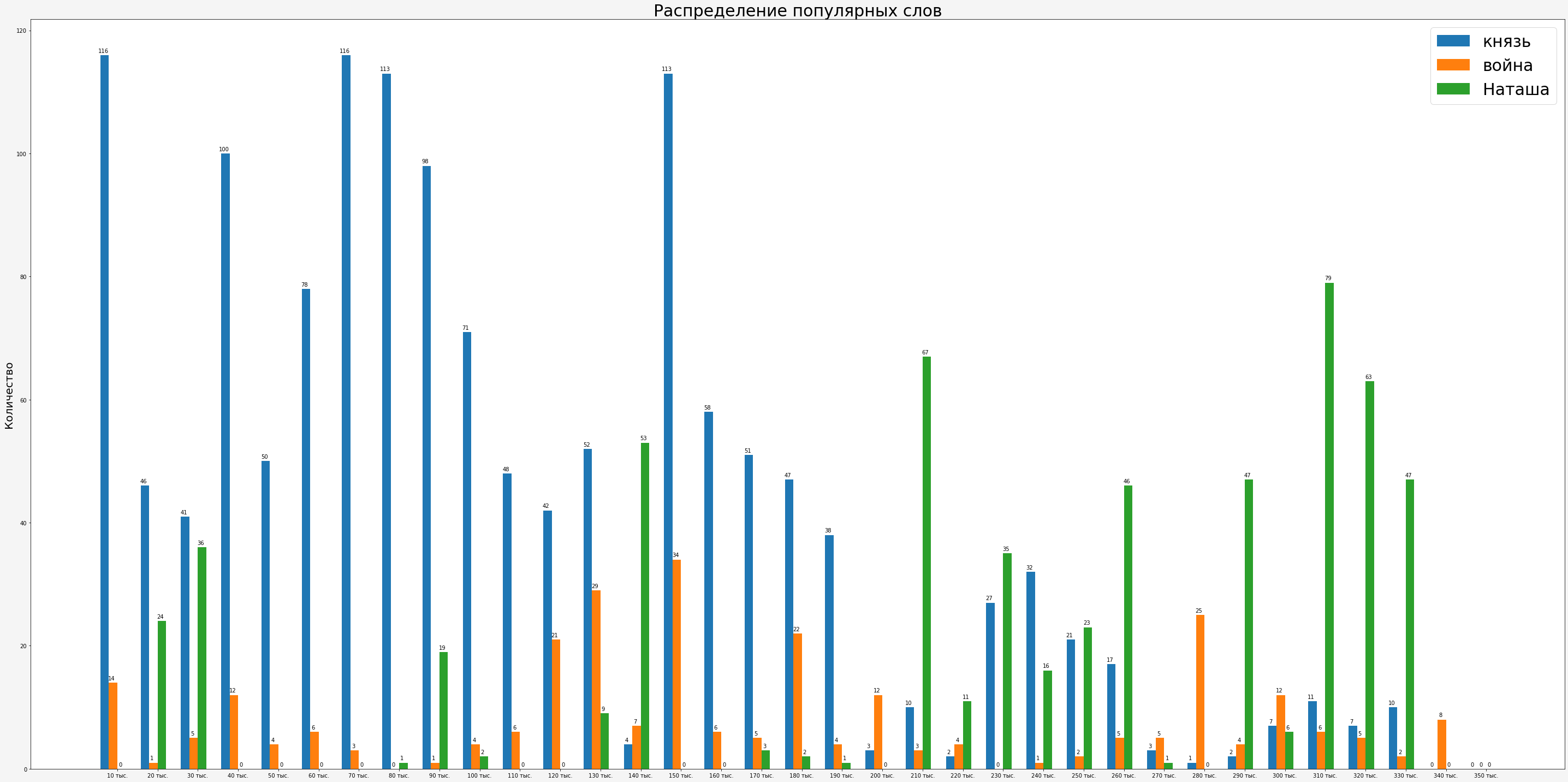 直方图显示,关于小说描写的战争描述激增之后的诸侯,少有人说,而他们越来越记得纳塔莎。在对“战争”和“纳塔莎”一词的依赖性分布中,可以清楚地看到这种反相关关系:战争越少,娜塔莎就越多。
直方图显示,关于小说描写的战争描述激增之后的诸侯,少有人说,而他们越来越记得纳塔莎。在对“战争”和“纳塔莎”一词的依赖性分布中,可以清楚地看到这种反相关关系:战争越少,娜塔莎就越多。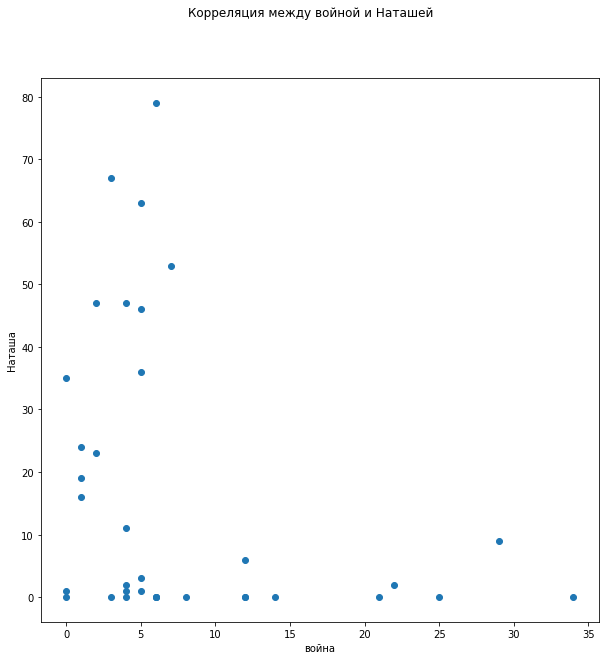 在提到“王子”和“娜塔莎”一词时,分布的反相关关系也很明显。
在提到“王子”和“娜塔莎”一词时,分布的反相关关系也很明显。 在分配对提及``王子''和``战争''一词的依存关系时,没有明显的相关性,尽管很明显,当对战争一无所知时,他们不记得王子了,但是这并不能解释在没有``战争''的情况下对``王子''的大量提及。
在分配对提及``王子''和``战争''一词的依存关系时,没有明显的相关性,尽管很明显,当对战争一无所知时,他们不记得王子了,但是这并不能解释在没有``战争''的情况下对``王子''的大量提及。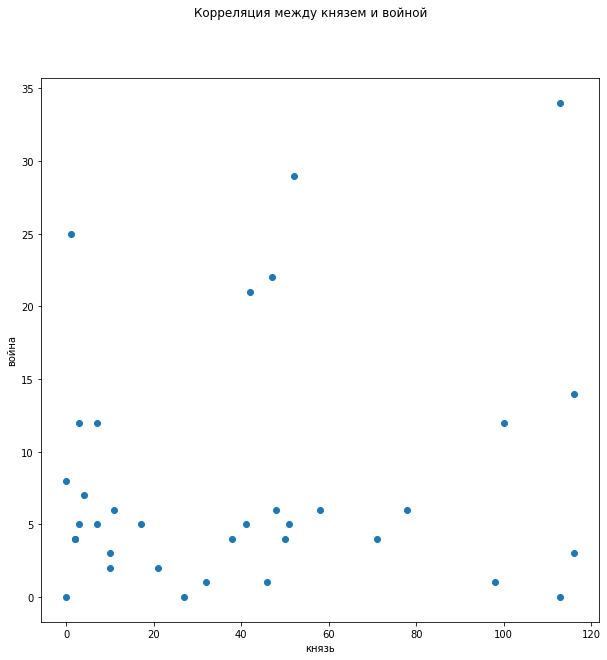 在叙述的发展过程中,有必要跟踪相关性。
在叙述的发展过程中,有必要跟踪相关性。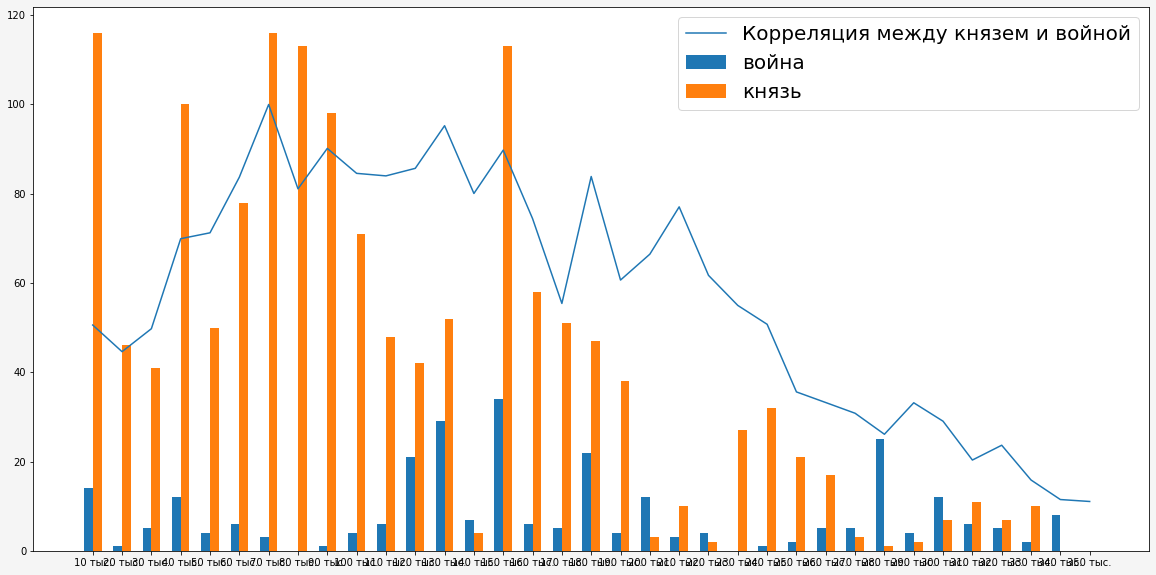 从图中可以看出,只有在小说中间存在较高的相关性,当小说中存在战争时,在小说的其他地方相关性很低,因此可以得出结论,在小说使用过程中,``王子''和``战争''的使用并不具有恒定的相关性。
从图中可以看出,只有在小说中间存在较高的相关性,当小说中存在战争时,在小说的其他地方相关性很低,因此可以得出结论,在小说使用过程中,``王子''和``战争''的使用并不具有恒定的相关性。发现
- 您需要阅读经典!!!
- 如果您想阅读有关战争而不是爱情的文章,请阅读第一卷和第三卷的第一部分。
- 如果您想阅读和平时期王子的生活,那么第二卷是完美的。
- 如果您在没有战争的情况下对爱情感兴趣,那么您应该阅读第四卷。