碰巧系统有故障,速度变慢,崩溃了。系统越大,找到原因的难度就越大。要找出为什么某些东西无法按预期工作,修复或防止将来出现问题,您需要查看内部。为此,系统必须具有可观测性,这是通过广义上的仪器化来实现的。在HighLoad ++上, Peter Zaitsev(Percona)审查了Linux中可用的跟踪基础结构,并讨论了bpfTrace(顾名思义)具有许多优点。我们制作了该报告的文本版本,以便您查看详细信息并且随时可以获取其他材料。仪表可分为两个大块:- 静态,将信息集合连接到代码中时:记录日志,计数器,时间等。
- Dynamic,如果代码本身未检测到,但是有必要时可以执行。
另一个分类选项基于记录数据的方法:- 跟踪 -如果某些代码有效,则会生成事件。
- 采样 -例如每秒检查系统状态100次,并确定系统中正在发生的情况。
静态仪器已经存在了很多年,几乎涵盖了所有领域。在Linux上,许多标准工具(例如Vmstat或top)都使用它。他们从procfs中读取数据,大致来说,是从内核代码中写入不同的计时器和计数器。但是您不能插入太多这些计数器;您无法用它们覆盖世界上的所有事物。因此,动态检测可能很有用,它使您可以精确地观察所需的内容。例如,如果TCP / IP堆栈有任何问题,那么您可以深入了解并指导特定的细节。
跟踪
DTrace是由Sun Microsystems创建的最早的已知动态跟踪框架之一。它于2001年开始制作,并于2005年首次在Solaris 10中发布。事实证明这种方法非常流行,后来又进入了许多其他发行版。有趣的是,DTrace允许您同时检测内核空间和用户空间。您可以在任何函数调用上放置跟踪,并专门指示程序:引入特殊的DTrace跟踪点,对于用户而言,比函数名称更容易理解。这对于Solaris尤其重要,因为它不是开放式操作系统。不可能只看一下代码并了解跟踪点就需要像现在可以在新的开源Linux软件中完成的功能一样。DTrace独特的功能(尤其是在当时)是其中之一,虽然未启用跟踪,但不花钱。它的工作方式是用DTrace调用简单地替换一些CPU指令,该调用在返回时执行这些指令。在DTrace中,检测是用一种特殊的D语言编写的,类似于C和Awk。后来,DTrace几乎出现在Linux之外的所有地方:2007年在MacOS上,2008年在FreeBSD上,2010年在NetBSD上。2011年,Oracle将DTrace包含在Oracle Unbreakable Linux中。但是很少有人使用Oracle Linux,并且DTrace从未进入主Linux。有趣的是,在2017年,Oracle最终在GPLv2下许可了DTrace,从原则上讲,它可以在没有许可困难的情况下将其包括在主线Linux中,但是为时已晚。当时,Linux具有良好的BPF,主要用于标准化。DTrace甚至将包含在Windows中;现在在某些测试版本中可用。Linux追踪
在Linux中是什么而不是DTrace?实际上,在Linux中,有很多东西以开源精神的最好(或最坏)表现形式出现,在这段时间里已经积累了许多不同的跟踪框架。因此,弄清楚什么不是那么简单。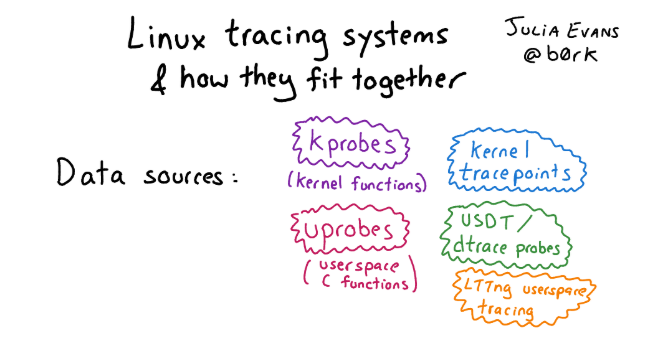 如果您想了解这种变化并且对历史感兴趣,请参阅带有图片的文章以及Linux中跟踪方法的详细说明。如果我们通常讨论Linux中的跟踪基础结构,则分为三个级别:
如果您想了解这种变化并且对历史感兴趣,请参阅带有图片的文章以及Linux中跟踪方法的详细说明。如果我们通常讨论Linux中的跟踪基础结构,则分为三个级别:- 内核检测的接口: Kprobe,Uprobe,Dtrace探针等。
- «», . , probe, , user space . : , user space, Kernel Module, - , eBPF.
- -, , : Perf, SystemTap, SysDig, BCC .. bpfTtrace , , .
eBPF — Linux
通过所有这些框架,eBPF近年来已成为Linux上的标准。这是一种更高级,高度灵活且有效的工具,几乎可以执行所有操作。什么是eBPF?它来自何处?实际上,eBPF是扩展的Berkeley数据包过滤器,而BPF于1992年作为虚拟机开发,用于通过防火墙进行有效的数据包过滤。最初,他与监视,可观察性或跟踪无关。在更现代的版本中,eBPF已经扩展(因此扩展了单词),作为处理事件的通用框架。当前版本与JIT编译器集成在一起,以提高效率。eBPF与经典BPF的区别:- 寄存器已添加;
- 出现了一个堆栈;
- 还有其他数据结构(地图)。
 现在,人们最经常忘记的是有一个旧的BPF,而eBPF简称为BPF。在大多数现代表达式中,eBPF和BPF是相同的。因此,该工具称为bpfTrace,而不是eBpfTrace。自2014年以来,eBPF已被包括在主线Linux中,并且逐渐被包括在许多Linux工具中,包括Perf,SystemTap和SysDig。有一个标准化。有趣的是,发展仍在进行中。现代内核越来越支持eBPF。
现在,人们最经常忘记的是有一个旧的BPF,而eBPF简称为BPF。在大多数现代表达式中,eBPF和BPF是相同的。因此,该工具称为bpfTrace,而不是eBpfTrace。自2014年以来,eBPF已被包括在主线Linux中,并且逐渐被包括在许多Linux工具中,包括Perf,SystemTap和SysDig。有一个标准化。有趣的是,发展仍在进行中。现代内核越来越支持eBPF。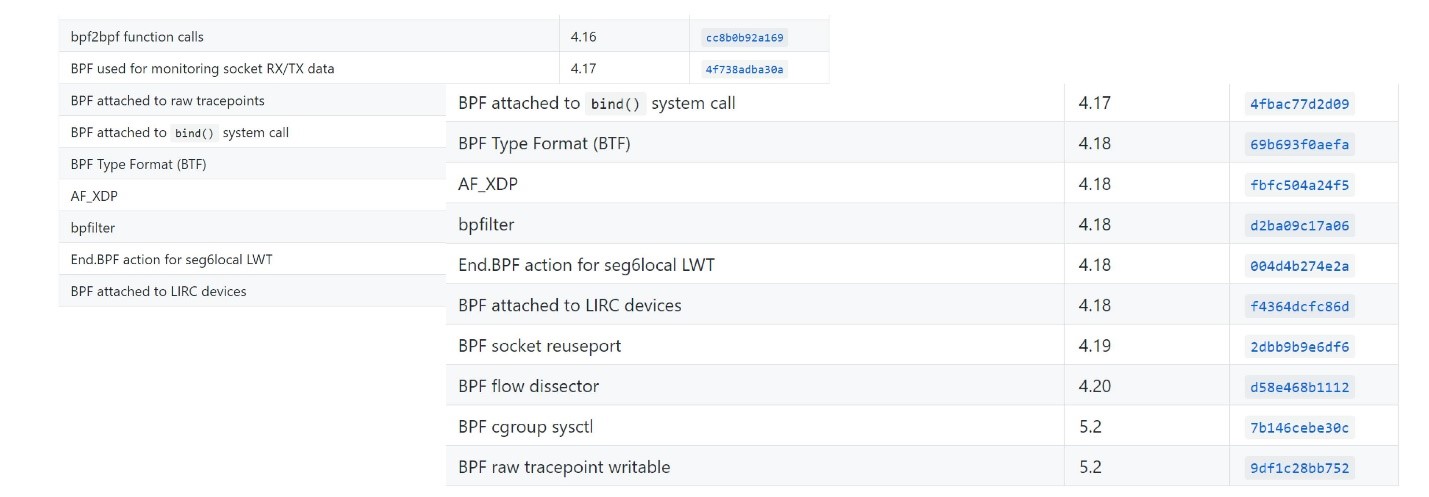 您可以在这里看到什么现代内核版本。
您可以在这里看到什么现代内核版本。EBPF计划
那么什么是eBPF?为什么它很有趣?eBPF是具有其特殊字节码的程序,该字节码直接包含在内核中并执行跟踪事件的处理。而且,它是用特殊的字节码制成的,这一事实使内核可以进行一定的验证,证明该代码相当安全。例如,检查它是否不使用循环,因为内核关键部分中的循环会挂起整个系统。但这不允许完全安全。例如,如果您编写一个非常复杂的eBPF程序,将其插入内核中每秒发生一千万次的事件,那么一切都会大大减慢速度。但是与此同时,当通过insmod插入一些内核模块,并且这些模块中可能包含任何内核模块时,eBPF比旧方法安全得多。如果有人犯了一个错误,或者仅仅是因为二进制不兼容,那么整个内核就会崩溃。eBPF代码可由LLVM Clang编译,也就是说,大体上,使用C的子集来创建eBPF程序,这当然很复杂。而且重要的是编译依赖于内核:标头用于了解使用了哪些结构以及它们的用途,等等。从某种意义上说,要么总是提供某些与特定内核相关的模块,要么需要重新编译,因此这不是很方便。该图显示了eBPF的工作方式。 http://www.brendangregg.com/ebpf.html用户创建一个eBPF程序。此外,内核本身会检查并加载它。之后,eBPF可以连接到各种用于跟踪,处理信息的工具,并将其保存在地图(用于临时存储的数据结构)中。然后,用户程序可以读取统计信息,接收性能事件等。它显示了哪些eBPF在哪些版本的Linux内核中具有功能。
http://www.brendangregg.com/ebpf.html用户创建一个eBPF程序。此外,内核本身会检查并加载它。之后,eBPF可以连接到各种用于跟踪,处理信息的工具,并将其保存在地图(用于临时存储的数据结构)中。然后,用户程序可以读取统计信息,接收性能事件等。它显示了哪些eBPF在哪些版本的Linux内核中具有功能。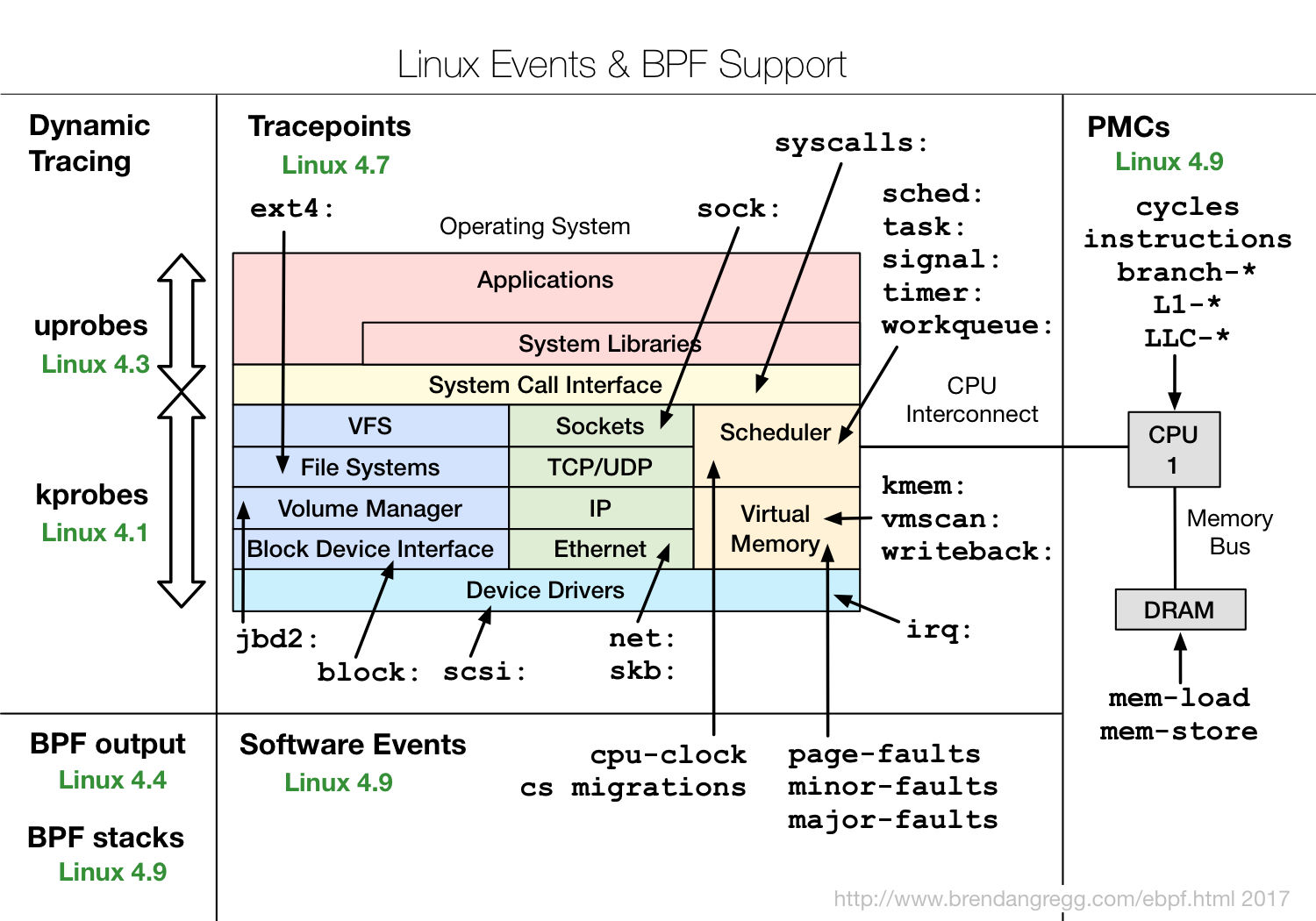 可以看出,几乎涵盖了Linux内核的所有子系统,并且与硬件数据的集成很好,eBPF可以访问各种缓存未命中或分支未命中预测等。如果您对eBPF感兴趣,请查看IO Visor项目,其中包含大多数工具。IO Visor公司正在从事他们的开发,他们将拥有最新版本和非常好的文档。Linux发行版上出现了越来越多的eBPF工具,因此我建议您始终使用最新的可用版本。
可以看出,几乎涵盖了Linux内核的所有子系统,并且与硬件数据的集成很好,eBPF可以访问各种缓存未命中或分支未命中预测等。如果您对eBPF感兴趣,请查看IO Visor项目,其中包含大多数工具。IO Visor公司正在从事他们的开发,他们将拥有最新版本和非常好的文档。Linux发行版上出现了越来越多的eBPF工具,因此我建议您始终使用最新的可用版本。EBPF表现
在性能方面,eBPF非常有效。要了解多少以及是否有开销,您可以添加一个探针,该探针每秒抽动数次,并检查执行它需要多长时间。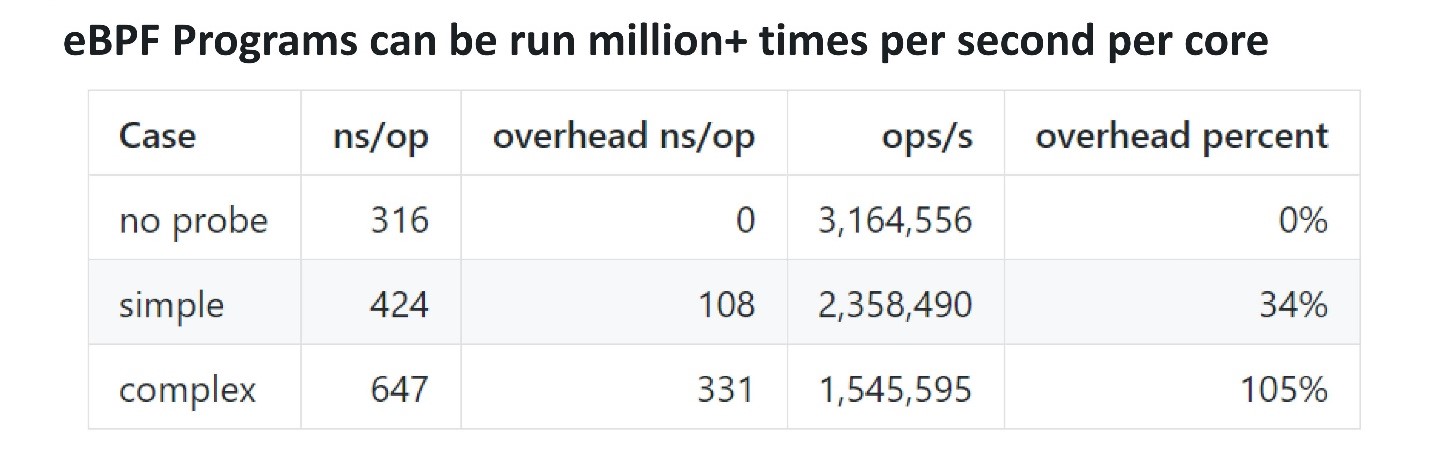 来自Cloudflare的家伙做出了基准。一个简单的eBPF探针大约花费了100 ns,而一个更复杂的探针则花费了300 ns。这意味着甚至一个复杂的探针也可以每秒大约300万次在单个内核上被调用。如果探针在多核处理器上每秒震荡10万或一百万次,则不会对性能造成太大影响。
来自Cloudflare的家伙做出了基准。一个简单的eBPF探针大约花费了100 ns,而一个更复杂的探针则花费了300 ns。这意味着甚至一个复杂的探针也可以每秒大约300万次在单个内核上被调用。如果探针在多核处理器上每秒震荡10万或一百万次,则不会对性能造成太大影响。eBPF的前端
如果您对eBPF和总体可观察性主题感兴趣,那么您可能听说过Brendan Gregg。他撰写并讨论了很多内容,并制作了精美的图片,展示了eBPF的工具。 在这里,您可以看到,例如,您可以使用Raw BPF(仅编写字节代码)即可,这将提供全部功能,但是使用起来非常困难。 Raw BPF涉及如何在汇编器中编写Web应用程序-原则上可以,但不需要这样做。有趣的是,一方面,bpfTrace允许您从BCC和原始BPF中获得几乎所有内容,但使用起来却容易得多。我认为,两个工具最有用:
在这里,您可以看到,例如,您可以使用Raw BPF(仅编写字节代码)即可,这将提供全部功能,但是使用起来非常困难。 Raw BPF涉及如何在汇编器中编写Web应用程序-原则上可以,但不需要这样做。有趣的是,一方面,bpfTrace允许您从BCC和原始BPF中获得几乎所有内容,但使用起来却容易得多。我认为,两个工具最有用:- 密件抄送。尽管根据Gregg的方案,BCC很复杂,但它包含许多现成的功能,可以从命令行简单地启动它们。
- BpfTrace。它使您可以简单地编写自己的工具包或使用现成的解决方案。
您可以想象一下,如果您查看两个版本中相同工具的代码,那么在bpfTrace上编写代码会容易得多。
DTrace和bpfTrace
通常,DTrace和bpfTrace用于同一事物。 http://www.brendangregg.com/blog/2018-10-08/dtrace-for-linux-2018.html不同之处在于BPF生态系统中还有一个BCC可用于复杂的工具。DTrace中没有BCC等效项,因此,要制作复杂的工具箱,通常使用Shell + DTrace捆绑包。创建bpfTrace时,没有完全模拟DTrace的任务。也就是说,您不能使用DTrace脚本并在bpfTrace上运行它。但这没有多大意义,因为底层工具中的逻辑非常简单。在Linux,Solaris和FreeBSD中,了解需要连接到哪些跟踪点,系统调用的名称以及它们直接在底层进行的操作通常更为重要。那就是产生差异的地方。在这种情况下,bpfTrace是在DTrace之后15年制成的。它具有DTrace所没有的一些其他功能。例如,他可以进行堆栈跟踪。但是,当然,很多是从DTrace继承的。例如,函数名称和语法相似,尽管不完全相同。DTrace和bpfTrace脚本的代码大小相近,而复杂度和语言功能则相似。
http://www.brendangregg.com/blog/2018-10-08/dtrace-for-linux-2018.html不同之处在于BPF生态系统中还有一个BCC可用于复杂的工具。DTrace中没有BCC等效项,因此,要制作复杂的工具箱,通常使用Shell + DTrace捆绑包。创建bpfTrace时,没有完全模拟DTrace的任务。也就是说,您不能使用DTrace脚本并在bpfTrace上运行它。但这没有多大意义,因为底层工具中的逻辑非常简单。在Linux,Solaris和FreeBSD中,了解需要连接到哪些跟踪点,系统调用的名称以及它们直接在底层进行的操作通常更为重要。那就是产生差异的地方。在这种情况下,bpfTrace是在DTrace之后15年制成的。它具有DTrace所没有的一些其他功能。例如,他可以进行堆栈跟踪。但是,当然,很多是从DTrace继承的。例如,函数名称和语法相似,尽管不完全相同。DTrace和bpfTrace脚本的代码大小相近,而复杂度和语言功能则相似。
bpfTrace
让我们更详细地了解bpfTrace中的内容,如何使用它以及需要什么。使用bpfTrace的Linux要求: 要使用所有功能,您需要的版本至少为4.9。BpfTrace允许您进行许多不同的探查,从用于在用户应用程序,内核探针等中检测函数调用的uprobe开始。
要使用所有功能,您需要的版本至少为4.9。BpfTrace允许您进行许多不同的探查,从用于在用户应用程序,内核探针等中检测函数调用的uprobe开始。 有趣的是,自定义uprobe功能有一个uretprobe等效项。对于内核,相同的是kprobe和kretprobe。这意味着实际上,在跟踪框架中,您可以在调用函数时以及完成此函数时生成事件-这通常用于计时。或者您可以分析该函数返回的值并根据调用该函数的参数对其进行分组。如果捕获到一个函数调用并从中返回,则可以做很多很酷的事情。在bpfTrace中,它的工作方式是这样的:我们编写了一个bpf程序,将其解析,转换为C,然后通过Clang处理,该程序会生成bpf字节代码,然后加载该程序。
有趣的是,自定义uprobe功能有一个uretprobe等效项。对于内核,相同的是kprobe和kretprobe。这意味着实际上,在跟踪框架中,您可以在调用函数时以及完成此函数时生成事件-这通常用于计时。或者您可以分析该函数返回的值并根据调用该函数的参数对其进行分组。如果捕获到一个函数调用并从中返回,则可以做很多很酷的事情。在bpfTrace中,它的工作方式是这样的:我们编写了一个bpf程序,将其解析,转换为C,然后通过Clang处理,该程序会生成bpf字节代码,然后加载该程序。 该过程非常困难,因此存在局限性。在功能强大的服务器上,bpfTrace可以很好地工作。但是将Clang拖到一个小型嵌入式设备上以了解发生了什么不是一个好主意。帘布层适合于此。当然,它不具有bpfTrace的所有功能,但可以直接生成字节码。
该过程非常困难,因此存在局限性。在功能强大的服务器上,bpfTrace可以很好地工作。但是将Clang拖到一个小型嵌入式设备上以了解发生了什么不是一个好主意。帘布层适合于此。当然,它不具有bpfTrace的所有功能,但可以直接生成字节码。Linux支援
bpfTrace的稳定版本大约于一年前发布,因此在较旧的Linux发行版中不可用。最好打包或编译IO Visor分发的最新版本。有趣的是,最新的Ubuntu LTS 18.04没有bpfTrace,但可以使用snap软件包进行交付。一方面,这很方便,但是另一方面,由于制作和隔离snap包的方式,并非所有功能都可以使用。对于内核跟踪,具有snap的程序包效果很好;对于用户跟踪,它可能无法正常工作。
流程跟踪示例
考虑最简单的示例,该示例使您可以获取有关IO请求的统计信息:bpftrace -e 'kprobe:vfs_read { @start[tid] = nsecs; }
kretprobe:vfs_read /@start[tid]/ { @ns[comm] = hist(nsecs - @start[tid]); delete(@start[tid]); }'
在这里,我们连接到函数vfs_readkretprobe和kprobe。此外,对于每个线程ID(tid),即对于每个请求,我们跟踪其执行的开始和结束。数据不仅可以按整个系统的整体进行分组,还可以按不同的流程进行分组。以下是MySQL的IO输出。 经典的双峰I / O分布可见。大量快速请求是从缓存中读取的数据。第二个高峰是从磁盘读取数据,而延迟要高得多。您可以将其另存为脚本(通常使用bt扩展名),编写注释,对其进行格式化以及仅作进一步使用
经典的双峰I / O分布可见。大量快速请求是从缓存中读取的数据。第二个高峰是从磁盘读取数据,而延迟要高得多。您可以将其另存为脚本(通常使用bt扩展名),编写注释,对其进行格式化以及仅作进一步使用#bpftrace read.bt。// read.bt file
tracepoint:syscalls:sys_enter_read
{
@start[tid] = nsecs;
}
tracepoint:syscalls:sys_exit_read / @start[tid]/
{
@times = hist(nsecs - @start[tid]);
delete(@start[tid]);
}
语言的一般概念非常简单。- 语法:选择要连接的探针
probe[,probe,...] /filter/ { action }。 - 过滤器:指定过滤器,例如,仅指定给定Pid的给定进程上的数据。
- 行动:一个微型程序,可以直接转换为bpf程序,并在调用bpfTrace时运行。
可以在此处找到更多详细信息。Bpftrace工具
BpfTrace也有一个工具箱。现在,在bpfTrace上实现了许多BCC上相当简单的工具。 馆藏仍然很小,但BCC中没有。例如,killsnoop允许您跟踪kill()引起的信号。如果您有兴趣查看bpf代码,则可以在bpfTrace中通过
馆藏仍然很小,但BCC中没有。例如,killsnoop允许您跟踪kill()引起的信号。如果您有兴趣查看bpf代码,则可以在bpfTrace中通过-v查看生成的字节代码。如果您想了解繁重的调查,这很有用。查看代码并估算其大小(一页或两页)后,您可以了解它的复杂性。
MySQL追踪范例
让我向您展示一个MySQL的示例,它如何工作。MySQL具有dispatch_command其中所有MySQL查询执行都发生的功能。bpftrace -e 'uprobe:/usr/sbin/mysqld:dispatch_command { printf("%s\n", str(arg2)); }'
failed to stat uprobe target file /usr/sbin/mysqld: No such file or directory
我只是想连接一个套子来打印MySQL的查询文本-这是一项原始任务。遇到了问题-说没有这样的文件。就像不在这里时一样:root@mysql1:/# ls -la /usr/sbin/mysqld
-rwxr-xr-x 1 root root 60718384 Oct 25 09:19 /usr/sbin/mysqld
这些只是一时的惊喜。如果通过快照设置,则在应用程序级别可能会出现问题。然后,我通过apt版本(较新的Ubuntu)重新安装:root@mysql1:~# bpftrace -e 'uprobe:/usr/sbin/mysqld:dispatch_command { printf("%s\n", str(arg2)); }'
Attaching 1 probe...
Could not resolve symbol: /usr/sbin/mysqld:dispatch_command
“没有这样的符号”-怎么不?我查看nm是否有这样的符号:root@mysql1:~# nm -D /usr/sbin/mysqld | grep dispatch_command
00000000005af770 T
_Z16dispatch_command19enum_server_commandP3THDPcjbb
root@localhost:~# bpftrace -e 'uprobe:/usr/sbin/mysqld:_Z16dispatch_command19enum_server_commandP3THDPcjbb { printf("%s\n", str(arg2)); }'
Attaching 1 probe...
select @@version_comment limit 1
select 1
有这样的符号,但是由于MySQL是从C ++编译的,因此在其中使用了mangling。实际上,此命令中使用的函数的当前名称如下:_Z16dispatch_command19enum_server_commandP3THDPcjbb。如果在函数中使用它,则可以连接并获取结果。在perf生态系统中,许多工具可以使自动取消管理,而bpfTrace尚不支持。另外要注意的标志-D的nm。这很重要,因为MySQL和现在的许多其他软件包都没有动态符号(调试符号)-它们在其他软件包中。如果要使用这些字符,则需要一个标志-D,否则nm将看不到它们。: ++ 25–26 , . , , .
: ++ Online . 5 900 , , -.
: DevOpsConf 2019 HighLoad++ 2019 — , .
— , .