 在业余时间的最后几年,我参加了铁人三项赛。这项运动在世界许多国家非常受欢迎,尤其是在美国,澳大利亚和欧洲。目前在俄罗斯和独联体国家迅速普及。它涉及的是业余爱好者,而不是专业人士。与铁人三项比赛不同,铁人三项比赛包括参加比赛和为比赛做系统的准备,即使他们不是专业人士,也不仅仅是在游泳池里游泳,早上骑自行车和慢跑。在您的朋友中肯定已经有至少一个“铁人”或计划成为一个铁人。大规模,多种距离和各种条件,一项三项运动-所有这些都有可能形成大量数据。每年,世界上都会举行数百项铁人三项比赛,数十万人参加。比赛由几个组织者举办。当然,它们每个人都以自己的权利发布结果。但是对于来自俄罗斯和某些独联体国家的运动员来说,tristats.ru将所有结果收集在一个位置上-在相同名称的网站上。这使得搜索结果非常方便,无论您是您的朋友还是竞争对手,甚至您的偶像。但是对我来说,它也提供了以编程方式分析大量结果的机会。结果发布在trilife:请阅读。这是我的第一个此类项目,因为直到最近我才原则上开始进行数据分析以及使用python。因此,我想向您介绍这项工作的技术实施方式,尤其是在此过程中,各种细微差别浮出水面,有时需要采取特殊的方法。这将涉及报废,解析,转换类型和格式,还原不完整的数据,创建有代表性的样本,可视化,向量化甚至并行计算。原来容量很大,所以我将所有内容分成五个部分,以便我可以分配信息并记住休息后从哪里开始。在继续之前,最好先阅读一下研究结果的文章,因为这里基本上描述了其创造的厨房。需要10到15分钟。你读了...吗?那我们走吧!
在业余时间的最后几年,我参加了铁人三项赛。这项运动在世界许多国家非常受欢迎,尤其是在美国,澳大利亚和欧洲。目前在俄罗斯和独联体国家迅速普及。它涉及的是业余爱好者,而不是专业人士。与铁人三项比赛不同,铁人三项比赛包括参加比赛和为比赛做系统的准备,即使他们不是专业人士,也不仅仅是在游泳池里游泳,早上骑自行车和慢跑。在您的朋友中肯定已经有至少一个“铁人”或计划成为一个铁人。大规模,多种距离和各种条件,一项三项运动-所有这些都有可能形成大量数据。每年,世界上都会举行数百项铁人三项比赛,数十万人参加。比赛由几个组织者举办。当然,它们每个人都以自己的权利发布结果。但是对于来自俄罗斯和某些独联体国家的运动员来说,tristats.ru将所有结果收集在一个位置上-在相同名称的网站上。这使得搜索结果非常方便,无论您是您的朋友还是竞争对手,甚至您的偶像。但是对我来说,它也提供了以编程方式分析大量结果的机会。结果发布在trilife:请阅读。这是我的第一个此类项目,因为直到最近我才原则上开始进行数据分析以及使用python。因此,我想向您介绍这项工作的技术实施方式,尤其是在此过程中,各种细微差别浮出水面,有时需要采取特殊的方法。这将涉及报废,解析,转换类型和格式,还原不完整的数据,创建有代表性的样本,可视化,向量化甚至并行计算。原来容量很大,所以我将所有内容分成五个部分,以便我可以分配信息并记住休息后从哪里开始。在继续之前,最好先阅读一下研究结果的文章,因为这里基本上描述了其创造的厨房。需要10到15分钟。你读了...吗?那我们走吧!第1部分。刮取和解析
给出:网站tristats.ru。我们感兴趣的表有两种。这实际上是所有比赛的摘要表,以及每个比赛的结果协议。
 首要任务是以编程方式获取此数据并将其保存以备进一步处理。碰巧的是,那时我是Web技术的新手,因此并不立即知道该怎么做。我从了解的内容开始着手-查看页面代码。可以使用鼠标右键或F12键完成此操作。
首要任务是以编程方式获取此数据并将其保存以备进一步处理。碰巧的是,那时我是Web技术的新手,因此并不立即知道该怎么做。我从了解的内容开始着手-查看页面代码。可以使用鼠标右键或F12键完成此操作。 Chrome中的菜单包含两个选项:查看页面代码和查看代码。不是最明显的分裂。自然,它们给出不同的结果。查看代码的那个,它与F12相同- 浏览器中显示的内容的直接文本html-表示是元素方式的。
Chrome中的菜单包含两个选项:查看页面代码和查看代码。不是最明显的分裂。自然,它们给出不同的结果。查看代码的那个,它与F12相同- 浏览器中显示的内容的直接文本html-表示是元素方式的。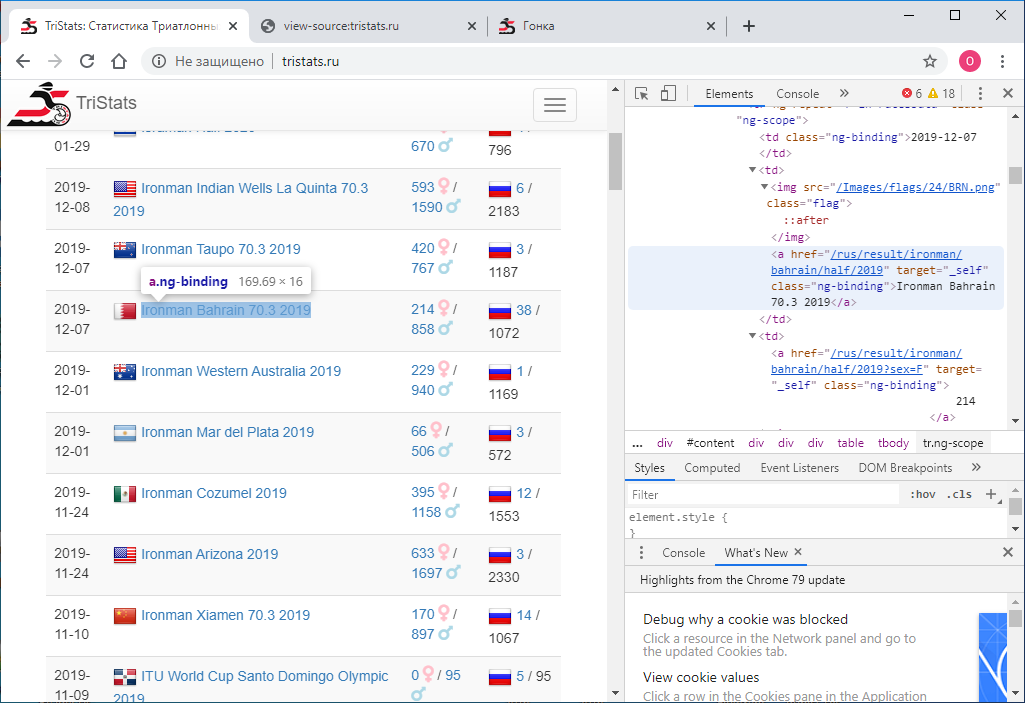 反过来,查看页面代码将提供页面的源代码。也是html,但是那里没有数据,只有卸载它们的JS脚本的名称。好的。
反过来,查看页面代码将提供页面的源代码。也是html,但是那里没有数据,只有卸载它们的JS脚本的名称。好的。 现在我们需要了解如何使用python将每个页面的代码另存为单独的文本文件。我尝试这样:
现在我们需要了解如何使用python将每个页面的代码另存为单独的文本文件。我尝试这样:import requests
r = requests.get(url='http://tristats.ru/')
print(r.content)
我得到了源代码。但是我需要执行它的结果。经过研究,搜索和询问后,我意识到我需要一个自动执行浏览器操作的工具,例如硒。我说了还有适用于Google Chrome的ChromeDriver。然后我按如下方式使用它:from selenium import webdriver
from selenium.webdriver.chrome.service import Service
service = Service(r'C:\ChromeDriver\chromedriver.exe')
service.start()
driver = webdriver.Remote(service.service_url)
driver.get('http://www.tristats.ru/')
print(driver.page_source)
driver.quit()
此代码将启动浏览器窗口,并在其中打开指定URL的页面。结果,我们已经获得了带有所需数据的html代码。但是有一个障碍。结果只有100个参赛者,比赛的总数几乎是2000。事实是,最初只有前100个条目显示在浏览器中,并且只有滚动到页面的最底部时,才会加载下100个条目,依此类推。因此,有必要以编程方式实现滚动。为此,请使用以下命令:driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
每次滚动时,我们都会检查加载页面的代码是否已更改。如果没有更改,我们将检查几次可靠性(例如10),则整个页面已加载,您可以停止。在滚动之间,我们将超时设置为一秒,以便页面有时间加载。(即使她没有时间,我们也有保留时间-另外9秒)。完整的代码如下所示:from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
service = Service(r'C:\ChromeDriver\chromedriver.exe')
service.start()
driver = webdriver.Remote(service.service_url)
driver.get('http://www.tristats.ru/')
prev_html = ''
scroll_attempt = 0
while scroll_attempt < 10:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(1)
if prev_html == driver.page_source:
scroll_attempt += 1
else:
prev_html = driver.page_source
scroll_attempt = 0
with open(r'D:\tri\summary.txt', 'w') as f:
f.write(prev_html)
driver.quit()
因此,我们有一个html文件,其中包含所有种族的摘要表。需要解析它。为此,请使用lxml库。from lxml import html
首先,我们找到表的所有行。要确定字符串的符号,只需在文本编辑器中查看html文件。 例如,它可以是“ tr ng-repeat ='r in racesData'class ='ng-scope'”或某些无法在任何标签中找到的片段。
例如,它可以是“ tr ng-repeat ='r in racesData'class ='ng-scope'”或某些无法在任何标签中找到的片段。with open(r'D:\tri\summary.txt', 'r') as f:
sum_html = f.read()
tree = html.fromstring(sum_html)
rows = tree.findall(".//*[@ng-repeat='r in racesData']")
然后我们启动pandas数据框,并将表格每一行的每个元素写入此数据框。import pandas as pd
rs = pd.DataFrame(columns=['date','name','link','males','females','rus','total'], index=range(len(rows)))
为了弄清楚每个特定元素的隐藏位置,您只需要在同一文本编辑器中查看行中元素之一的html代码。<tr ng-repeat="r in racesData" class="ng-scope">
<td class="ng-binding">2015-04-26</td>
<td>
<img src="/Images/flags/24/USA.png" class="flag">
<a href="/rus/result/ironman/texas/half/2015" target="_self" class="ng-binding">Ironman Texas 70.3 2015</a>
</td>
<td>
<a href="/rus/result/ironman/texas/half/2015?sex=F" target="_self" class="ng-binding">605</a>
<i class="fas fa-venus fa-lg" style="color:Pink"></i>
/
<a href="/rus/result/ironman/texas/half/2015?sex=M" target="_self" class="ng-binding">1539</a>
<i class="fas fa-mars fa-lg" style="color:LightBlue"></i>
</td>
<td class="ng-binding">
<img src="/Images/flags/24/rus.png" class="flag">
<a ng-if="r.CountryCount > 0" href="/rus/result/ironman/texas/half/2015?country=rus" target="_self" class="ng-binding ng-scope">2</a>
/ 2144
</td>
</tr>
在这里为儿童进行硬编码导航的最简单方法是,其中没有很多儿童。for i in range(len(rows)):
rs.loc[i,'date'] = rows[i].getchildren()[0].text.strip()
rs.loc[i,'name'] = rows[i].getchildren()[1].getchildren()[1].text.strip()
rs.loc[i,'link'] = rows[i].getchildren()[1].getchildren()[1].attrib['href'].strip()
rs.loc[i,'males'] = rows[i].getchildren()[2].getchildren()[2].text.strip()
rs.loc[i,'females'] = rows[i].getchildren()[2].getchildren()[0].text.strip()
rs.loc[i,'rus'] = rows[i].getchildren()[3].getchildren()[3].text.strip()
rs.loc[i,'total'] = rows[i].getchildren()[3].text_content().split('/')[1].strip()
结果如下:
将数据框保存到文件中。我使用pickle,但可能是csv或其他名称。import pickle as pkl
with open(r'D:\tri\summary.pkl', 'wb') as f:
pkl.dump(df,f)
在此阶段,所有数据均为字符串类型。我们稍后会进行转换。我们现在最需要的是链接。我们会将它们用于所有种族的抓取协议。我们以数据透视表的图像和相似性进行制作。在每个种族的周期中,我们将通过引用打开页面,滚动并获取页面代码。在摘要表中,我们提供了有关比赛参与者总数的信息- 总数,我们将使用它来了解直到需要继续滚动到什么位置为止。为此,我们将直接在抓取每个页面的过程中确定表中的记录数,并将其与合计的期望值进行比较。一旦相等,我们就会滚动到结尾,您可以继续进行下一场比赛。我们还将超时设置为60秒。在这段时间吃,我们没有得到总,进入下一场比赛。页面代码将保存到文件中。我们将所有种族的文件保存在一个文件夹中,并以种族名称(即摘要表中“ 事件”列中的值)命名。为避免名称冲突,必须在数据透视表中所有种族具有不同的名称。检查一下:df[df.duplicated(subset = 'event', keep=False)]
service.start()
driver = webdriver.Remote(service.service_url)
timeout = 60
for index, row in df.iterrows():
try:
driver.get('http://www.tristats.ru' + row['link'])
start = time.time()
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(1)
race_html = driver.page_source
tree = html.fromstring(race_html)
race_rows = tree.findall(".//*[@ng-repeat='r in resultsData']")
if len(race_rows) == int(row['total']):
break
if time.time() - start > timeout:
print('timeout')
break
with open(os.path.join(r'D:\tri\races', row['event'] + '.txt'), 'w') as f:
f.write(race_html)
except:
traceback.print_exc()
time.sleep(1)
driver.quit()
这是一个漫长的过程。但是,当一切都设置好之后,这种繁琐的机制开始旋转,一个又一个地添加数据文件时,就会产生一种令人兴奋的感觉。每分钟仅加载大约三个协议,非常缓慢。左转过夜。花了大约10个小时。到早上,大多数协议都已上传。在使用网络时,通常会发生一些故障。再次尝试快速恢复它们。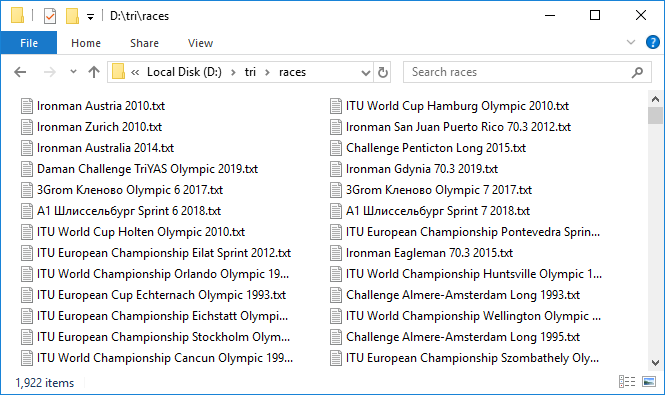 因此,我们有1,922个文件,总容量接近3 GB。凉!但是处理近300场比赛以超时结束。有什么事?选择性地检查,结果证明确实来自数据透视表的总值与我们检查的竞争协议中的条目数可能不一致。这很可悲,因为尚不清楚造成这种差异的原因是什么。要么是由于并非所有人都会完成任务,要么是由于数据库中存在某种错误。通常,数据不完整的第一个信号。无论如何,我们都会检查条目数为100或0的条目,这些条目是最可疑的候选人。一共有八个。在严密控制下再次下载它们。顺便说一句,其中两个实际上有100个条目。好吧,我们有所有数据。我们通过解析。同样,在一个周期中,我们将运行每个种族,读取文件,并将内容保存在pandas DataFrame中。我们将这些数据帧组合成dict,其中种族的名称将为键-也就是说,数据透视表中的事件值或具有种族页面的html代码的文件的名称是重合的。
因此,我们有1,922个文件,总容量接近3 GB。凉!但是处理近300场比赛以超时结束。有什么事?选择性地检查,结果证明确实来自数据透视表的总值与我们检查的竞争协议中的条目数可能不一致。这很可悲,因为尚不清楚造成这种差异的原因是什么。要么是由于并非所有人都会完成任务,要么是由于数据库中存在某种错误。通常,数据不完整的第一个信号。无论如何,我们都会检查条目数为100或0的条目,这些条目是最可疑的候选人。一共有八个。在严密控制下再次下载它们。顺便说一句,其中两个实际上有100个条目。好吧,我们有所有数据。我们通过解析。同样,在一个周期中,我们将运行每个种族,读取文件,并将内容保存在pandas DataFrame中。我们将这些数据帧组合成dict,其中种族的名称将为键-也就是说,数据透视表中的事件值或具有种族页面的html代码的文件的名称是重合的。rd = {}
for e in rs['event']:
place = []
... sex = [], name=..., country, group, place_in_group, swim, t1, bike, t2, run
result = []
with open(os.path.join(r'D:\tri\races', e + '.txt'), 'r')
race_html = f.read()
tree = html.fromstring(race_html)
rows = tree.findall(".//*[@ng-repeat='r in resultsData']")
for j in range(len(rows)):
row = rows[j]
parts = row.text_content().split('\n')
parts = [r.strip() for r in parts if r.strip() != '']
place.append(parts[0])
if len([a for a in row.findall('.//i')]) > 0:
sex.append([a for a in row.findall('.//i')][0].attrib['ng-if'][10:-1])
else:
sex.append('')
name.append(parts[1])
if len(parts) > 10:
country.append(parts[2].strip())
k=0
else:
country.append('')
k=1
group.append(parts[3-k])
... place_in_group.append(...), swim.append ..., t1, bike, t2, run
result.append(parts[10-k])
race = pd.DataFrame()
race['place'] = place
... race['sex'] = sex, race['name'] = ..., 'country', 'group', 'place_in_group', 'swim', ' t1', 'bike', 't2', 'run'
race['result'] = result
rd[e] = race
with open(r'D:\tri\details.pkl', 'wb') as f:
pkl.dump(rd,f)
for index, row in rs.iterrows():
e = row['event']
with open(os.path.join(r'D:\tri\races', e + '.txt'), 'r') as f:
race_html = f.read()
tree = html.fromstring(race_html)
header_elem = [tb for tb in tree.findall('.//tbody') if tb.getchildren()[0].getchildren()[0].text == ''][0]
location = header_elem.getchildren()[1].getchildren()[1].text.strip()
rs.loc[index, 'loc'] = location
with open(r'D:\tri\summary1.pkl', 'wb') as f:
pkl.dump(df,f)
第2部分。类型转换和格式化
因此,我们下载了所有数据并将其放入数据框中。但是,所有值均为str类型。这适用于日期,结果,位置和所有其他参数。所有参数都必须转换为适当的类型。让我们从数据透视表开始。日期和时间
event,loc和link将保持不变。日期转换为熊猫日期时间,如下所示:rs['date'] = pd.to_datetime(rs['date'])
其余的转换为整数类型:cols = ['males', 'females', 'rus', 'total']
rs[cols] = rs[cols].astype(int)
一切顺利,没有出现错误。这样就可以了-保存:with open(r'D:\tri\summary2.pkl', 'wb') as f:
pkl.dump(rs, f)
现在正在竞速数据帧。由于所有种族更方便,更快速地一次处理,而不是一次处理,因此我们将使用concat方法将它们收集到一个大的ar数据帧(所有记录的简称)中。ar = pd.concat(rd)
ar包含1,416,365个条目。现在,将位置和组中的位置转换为整数值。ar[['place', 'place in group']] = ar[['place', 'place in group']].astype(int))
接下来,我们使用临时值处理列。我们将它们从熊猫中以Timedelta类型投放。但是,要使转换成功,您需要正确准备数据。您可以看到一些小于一个小时的值没有指定提示。需要添加它。for col in ['swim', 't1', 'bike', 't2', 'run', 'result']:
strlen = ar[col].str.len()
ar.loc[strlen==5, col] = '0:' + ar.loc[strlen==5, col]
ar.loc[strlen==4, col] = '0:0' + ar.loc[strlen==4, col]
现在,仍然剩余的字符串看起来像这样:转换为Timedelta:for col in ['swim', 't1', 'bike', 't2', 'run', 'result']:
ar[col] = pd.to_timedelta(ar[col])
地板
继续。检查性别列中是否只有M和F的值:ar['sex'].unique()
Out: ['M', 'F', '']
实际上,仍然存在一个空字符串,即未指定性别。让我们看看有多少种这样的情况:len(ar[ar['sex'] == ''])
Out: 2538
没什么好。将来,我们将尝试进一步降低该值。同时,将性别列保留为线条形式。我们将保存结果,然后再进行更严重和风险更大的转换。为了保持文件之间的连续性,我们将组合的数据帧ar转换回数据帧rd的字典:for event in ar.index.get_level_values(0).unique():
rd[event] = ar.loc[event]
with open(r'D:\tri\details1.pkl', 'wb') as f:
pkl.dump(rd,f)
顺便说一下,由于某些列类型的转换,数据表的大小从数据透视表的367 KB减少到295 KB,对于竞速协议从251 MB减少到168 MB。国家代码
现在让我们看看这个国家。ar['country'].unique()
Out: ['CRO', 'CZE', 'SLO', 'SRB', 'BUL', 'SVK', 'SWE', 'BIH', 'POL', 'MK', 'ROU', 'GRE', 'FRA', 'HUN', 'NOR', 'AUT', 'MNE', 'GBR', 'RUS', 'UAE', 'USA', 'GER', 'URU', 'CRC', 'ITA', 'DEN', 'TUR', 'SUI', 'MEX', 'BLR', 'EST', 'NED', 'AUS', 'BGI', 'BEL', 'ESP', 'POR', 'UKR', 'CAN', 'IRL', 'JPN', 'HKG', 'JEY', 'SGP', 'BRA', 'QAT', 'LUX', 'RSA', 'NZL', 'LAT', 'PHI', 'KSA', 'SEY', 'MAS', 'OMA', 'ARG', 'ECU', 'THA', 'JOR', 'BRN', 'CIV', 'FIN', 'IRN', 'BER', 'LBA', 'KUW', 'LTU', 'SRI', 'HON', 'INA', 'LBN', 'PAN', 'EGY', 'MLT', 'WAL', 'ISL', 'CYP', 'DOM', 'IND', 'VIE', 'MRI', 'AZE', 'MLD', 'LIE', 'VEN', 'ALG', 'SYR', 'MAR', 'KZK', 'PER', 'COL', 'IRQ', 'PAK', 'CZK', 'KAZ', 'CHN', 'NEP', 'ISR', 'MKD', 'FRO', 'BAN', 'ARU', 'CPV', 'ALB', 'BIZ', 'TPE', 'KGZ', 'BNN', 'CUB', 'SNG', 'VTN', 'THI', 'PRG', 'KOR', 'RE', 'TW', 'VN', 'MOL', 'FRE', 'AND', 'MDV', 'GUA', 'MON', 'ARM', 'F.I.TRI.', 'BAHREIN', 'SUECIA', 'REPUBLICA CHECA', 'BRASIL', 'CHI', 'MDA', 'TUN', 'NDL', 'Danish(Dane)', 'Welsh', 'Austrian', 'Unknown', 'AFG', 'Argentinean', 'Pitcairn', 'South African', 'Greenland', 'ESTADOS UNIDOS', 'LUXEMBURGO', 'SUDAFRICA', 'NUEVA ZELANDA', 'RUMANIA', 'PM', 'BAH', 'LTV', 'ESA', 'LAB', 'GIB', 'GUT', 'SAR', 'ita', 'aut', 'ger', 'esp', 'gbr', 'hun', 'den', 'usa', 'sui', 'slo', 'cze', 'svk', 'fra', 'fin', 'isr', 'irn', 'irl', 'bel', 'ned', 'sco', 'pol', 'SMR', 'mex', 'STEEL T BG', 'KINO MANA', 'IVB', 'TCH', 'SCO', 'KEN', 'BAS', 'ZIM', 'Joe', 'PUR', 'SWZ', 'Mark', 'WLS', 'MYA', 'BOT', 'REU', 'NAM', 'NCL', 'BOL', 'GGY', 'ISV', 'TWN', 'GUM', 'FIJ', 'COK', 'NGR', 'IRI', 'GAB', 'ANT', 'GEO', 'COG', 'sue', 'SUD', 'BAR', 'CAY', 'BO', 'VE', 'AX', 'MD', 'PAR', 'UM', 'SEN', 'NIG', 'RWA', 'YEM', 'PLE', 'GHA', 'ITU', 'UZB', 'MGL', 'MAC', 'DMA', 'TAH', 'TTO', 'AHO', 'JAM', 'SKN', 'GRN', 'PRK', 'NFK', 'SOL', 'Sandy', 'SAM', 'PNG', 'SGS', 'Suchy, Jorg', 'SOG', 'GEQ', 'BVT', 'DJI', 'CHA', 'ANG', 'YUG', 'IOT', 'HAI', 'SJM', 'CUW', 'BHU', 'ERI', 'FLK', 'HMD', 'GUF', 'ESH', 'sandy', 'UMI', 'selsmark, 'Alise', 'Eddie', '31/3, Colin', 'CC', '', '', '', '', '', ' ', '', '', '', '-', '', 'GRL', 'UGA', 'VAT', 'ETH', 'ASA', 'PYF', 'ATA', 'ALA', 'MTQ', 'ZZ', 'CXR', 'AIA', 'TJK', 'GUY', 'KR', 'PF', 'BN', 'MO', 'LA', 'CAM', 'NCA', 'ZAM', 'MAD', 'TOG', 'VIR', 'ATF', 'VAN', 'SLE', 'GLP', 'SCG', 'LAO', 'IMN', 'BUR', 'IR', 'SY', 'CMR', 'GBS', 'SUR', 'MOZ', 'BLM', 'MSR', 'CAF', 'BEN', 'COD', 'CCK', 'TUV', 'TGA', 'GI', 'XKX', 'NRU', 'NC', 'LBR', 'TAN', 'VIN', 'SSD', 'GP', 'PS', 'IM', 'JE', '', 'MLI', 'FSM', 'LCA', 'GMB', 'MHL', 'NH', 'FL', 'CT', 'UT', 'AQ', 'Korea', 'Taiwan', 'NewCaledonia', 'Czech Republic', 'PLW', 'BRU', 'RUN', 'NIU', 'KIR', 'SOM', 'TKM', 'SPM', 'BDI', 'COM', 'TCA', 'SHN', 'DO2', 'DCF', 'PCN', 'MNP', 'MYT', 'SXM', 'MAF', 'GUI', 'AN', 'Slovak republic', 'Channel Islands', 'Reunion', 'Wales', 'Scotland', 'ica', 'WLF', 'D', 'F', 'I', 'B', 'L', 'E', 'A', 'S', 'N', 'H', 'R', 'NU', 'BES', 'Bavaria', 'TLS', 'J', 'TKL', 'Tirol"', 'P', '?????', 'EU', 'ES-IB', 'ES-CT', '', 'SOO', 'LZE', '', '', '', '', '', '']
412个唯一值。基本上,一个国家用大写的三位字母代码表示。但是显然,并非总是如此。实际上,有一个国际标准ISO 3166,其中对所有国家(包括已经不存在的国家)都规定了相应的三位数和两位数代码。对于python,可以在pycountry包中找到该标准的一种实现。运作方式如下:import pycountry as pyco
pyco.countries.get(alpha_3 = 'RUS')
Out: Country(alpha_2='RU', alpha_3='RUS', name='Russian Federation', numeric='643')
因此,我们将检查所有三位数字的代码,以大写字母表示,并在country.get(...)和Historic_countries.get(...)中给出响应:valid_a3 = [c for c in ar['country'].unique() if pyco.countries.get(alpha_3 = c.upper()) != None or pyco.historic_countries.get(alpha_3 = c.upper()) != None])
在412个中,有190个,不到一半。对于其余的222个(我们用tofix表示其列表),我们将创建一个fix匹配字典,其中的键将是原始名称,值将是根据ISO标准的三位数代码。tofix = list(set(ar['country'].unique()) - set(valid_a3))
首先,使用pycountry.countries.get(alpha_2 = ...)检查两位数的代码,导致大写:for icc in tofix:
if pyco.countries.get(alpha_2 = icc.upper()) != None:
fix[icc] = pyco.countries.get(alpha_2 = icc.upper()).alpha_3
else:
if pyco.historic_countries.get(alpha_2 = icc.upper()) != None:
fix[icc] = pyco.historic_countries.get(alpha_2 = icc.upper()).alpha_3
然后通过pycountry.countries.get(name = ...),pycountry.countries.get(common_name = ...)的全名,将其引导为str.title()形式:for icc in tofix:
if pyco.countries.get(common_name = icc.title()) != None:
fix[icc] = pyco.countries.get(common_name = icc.title()).alpha_3
else:
if pyco.countries.get(name = icc.title()) != None:
fix[icc] = pyco.countries.get(name = icc.title()).alpha_3
else:
if pyco.historic_countries.get(name = icc.title()) != None:
fix[icc] = pyco.historic_countries.get(name = icc.title()).alpha_3
因此,我们将无法识别的值的数量减少到190个。仍然很多:
您可能会注意到其中仍然有很多三位数的代码,但这不是ISO。然后怎样呢?事实证明,还有另一个标准- 奥林匹克运动会。不幸的是,它的实现不包含在pycountry中,您必须寻找其他东西。在datahub.io上以csv文件的形式找到了解决方案。将此文件的内容放在名为cdf的pandas DataFrame中。国际奥委会 - Intenational奥林匹克委员会(IOC)['URU', '', 'PAR', 'SUECIA', 'KUW', 'South African', '', 'Austrian', 'ISV', 'H', 'SCO', 'ES-CT', ', 'GUI', 'BOT', 'SEY', 'BIZ', 'LAB', 'PUR', ' ', 'Scotland', '', '', 'TCH', 'TGA', 'UT', 'BAH', 'GEQ', 'NEP', 'TAH', 'ica', 'FRE', 'E', 'TOG', 'MYA', '', 'Danish (Dane)', 'SAM', 'TPE', 'MON', 'ger', 'Unknown', 'sui', 'R', 'SUI', 'A', 'GRN', 'KZK', 'Wales', '', 'GBS', 'ESA', 'Bavaria', 'Czech Republic', '31/3, Colin', 'SOL', 'SKN', '', 'MGL', 'XKX', 'WLS', 'MOL', 'FIJ', 'CAY', 'ES-IB', 'BER', 'PLE', 'MRI', 'B', 'KSA', '', '', 'LAT', 'GRE', 'ARU', '', 'THI', 'NGR', 'MAD', 'SOG', 'MLD', '?????', 'AHO', 'sco', 'UAE', 'RUMANIA', 'CRO', 'RSA', 'NUEVA ZELANDA', 'KINO MANA', 'PHI', 'sue', 'Tirol"', 'IRI', 'POR', 'CZK', 'SAR', 'D', 'BRASIL', 'DCF', 'HAI', 'ned', 'N', 'BAHREIN', 'VTN', 'EU', 'CAM', 'Mark', 'BUL', 'Welsh', 'VIN', 'HON', 'ESTADOS UNIDOS', 'I', 'GUA', 'OMA', 'CRC', 'PRG', 'NIG', 'BHU', 'Joe', 'GER', 'RUN', 'ALG', '', 'Channel Islands', 'Reunion', 'REPUBLICA CHECA', 'slo', 'ANG', 'NewCaledonia', 'GUT', 'VIE', 'ASA', 'BAR', 'SRI', 'L', '', 'J', 'BAS', 'LUXEMBURGO', 'S', 'CHI', 'SNG', 'BNN', 'den', 'F.I.TRI.', 'STEEL T BG', 'NCA', 'Slovak republic', 'MAS', 'LZE', '-', 'F', 'BRU', '', 'LBA', 'NDL', 'DEN', 'IVB', 'BAN', 'Sandy', 'ZAM', 'sandy', 'Korea', 'SOO', 'BGI', '', 'LTV', 'selsmark, Alise', 'TAN', 'NED', '', 'Suchy, Jorg', 'SLO', 'SUDAFRICA', 'ZIM', 'Eddie', 'INA', '', 'SUD', 'VAN', 'FL', 'P', 'ITU', 'ZZ', 'Argentinean', 'CHA', 'DO2', 'WAL']
len(([x for x in tofix if x.upper() in list(cdf['ioc'])]))
Out: 82
在tofix的三位数代码中,找到了 82个相应的IOC。将它们添加到我们的匹配字典中。for icc in tofix:
if icc.upper() in list(cdf['ioc']):
ind = cdf[cdf['ioc'] == icc.upper()].index[0]
fix[icc] = cdf.loc[ind, 'iso3']
还剩108个原始值。它们是手动完成的,有时会向Google寻求帮助。
但是,即使手动控制也不能完全解决问题。剩下49个已经无法解释的值。这些值大多数可能只是数据错误。{'BGI': 'BRB', 'WAL': 'GBR', 'MLD': 'MDA', 'KZK': 'KAZ', 'CZK': 'CZE', 'BNN': 'BEN', 'SNG': 'SGP', 'VTN': 'VNM', 'THI': 'THA', 'PRG': 'PRT', 'MOL': 'MDA', 'FRE': 'FRA', 'F.I.TRI.': 'ITA', 'BAHREIN': 'BHR', 'SUECIA': 'SWE', 'REPUBLICA CHECA': 'CZE', 'BRASIL': 'BRA', 'NDL': 'NLD', 'Danish (Dane)': 'DNK', 'Welsh': 'GBR', 'Austrian': 'AUT', 'Argentinean': 'ARG', 'South African': 'ZAF', 'ESTADOS UNIDOS': 'USA', 'LUXEMBURGO': 'LUX', 'SUDAFRICA': 'ZAF', 'NUEVA ZELANDA': 'NZL', 'RUMANIA': 'ROU', 'sco': 'GBR', 'SCO': 'GBR', 'WLS': 'GBR', '': 'IND', '': 'IRL', '': 'ARM', '': 'BGR', '': 'SRB', ' ': 'BLR', '': 'GBR', '': 'FRA', '': 'HND', '-': 'CRI', '': 'AZE', 'Korea': 'KOR', 'NewCaledonia': 'FRA', 'Czech Republic': 'CZE', 'Slovak republic': 'SVK', 'Channel Islands': 'FRA', 'Reunion': 'FRA', 'Wales': 'GBR', 'Scotland': 'GBR', 'Bavaria': 'DEU', 'Tirol"': 'AUT', '': 'KGZ', '': 'BLR', '': 'BLR', '': 'BLR', '': 'RUS', '': 'BLR', '': 'RUS'}
unfixed = [x for x in tofix if x not in fix.keys()]
Out: ['', 'H', 'ES-CT', 'LAB', 'TCH', 'UT', 'TAH', 'ica', 'E', 'Unknown', 'R', 'A', '31/3, Colin', 'XKX', 'ES-IB','B','SOG','?????','KINO MANA','sue','SAR','D', 'DCF', 'N', 'EU', 'Mark', 'I', 'Joe', 'RUN', 'GUT', 'L', 'J', 'BAS', 'S', 'STEEL T BG', 'LZE', 'F', 'Sandy', 'DO2', 'sandy', 'SOO', 'LTV', 'selsmark, Alise', 'Suchy, Jorg' 'Eddie', 'FL', 'P', 'ITU', 'ZZ']
这些关键字在匹配的字典中将有一个空字符串。for cc in unfixed:
fix[cc] = ''
最后,我们向匹配的字典代码添加有效的但以小写形式编写的字典代码。for cc in valid_a3:
if cc.upper() != cc:
fix[cc] = cc.upper()
现在是时候应用找到的替代品了。要保存初始数据以进行进一步比较,请将country列复制到country raw。然后,使用创建的匹配字典,我们在不对应于ISO 的国家/地区列值中进行校正。for cc in fix:
ind = ar[ar['country'] == cc].index
ar.loc[ind,'country'] = fix[cc]
当然,这里不能没有向量化,表几乎有一百五十万行。但是根据字典,我们做一个循环,但是还有什么呢?检查更改了多少条记录:len(ar[ar['country'] != ar['country raw']])
Out: 315955
也就是说,占总数的20%以上。ar[ar['country'] != ar['country raw']].sample(10)
len(ar[ar['country'] == ''])
Out: 3221
这是没有国家或有非正式国家的记录数。唯一国家/地区的数量从412个减少到250个。在这里,它们是:
现在没有偏差。如先前所做的那样,在将合并的数据帧转换回数据帧的字典之后,我们将结果保存在新的details2.pkl文件中。['', 'ABW', 'AFG', 'AGO', 'AIA', 'ALA', 'ALB', 'AND', 'ANT', 'ARE', 'ARG', 'ARM', 'ASM', 'ATA', 'ATF', 'AUS', 'AUT', 'AZE', 'BDI', 'BEL', 'BEN', 'BES', 'BGD', 'BGR', 'BHR', 'BHS', 'BIH', 'BLM', 'BLR', 'BLZ', 'BMU', 'BOL', 'BRA', 'BRB', 'BRN', 'BTN', 'BUR', 'BVT', 'BWA', 'CAF', 'CAN', 'CCK', 'CHE', 'CHL', 'CHN', 'CIV', 'CMR', 'COD', 'COG', 'COK', 'COL', 'COM', 'CPV', 'CRI', 'CTE', 'CUB', 'CUW', 'CXR', 'CYM', 'CYP', 'CZE', 'DEU', 'DJI', 'DMA', 'DNK', 'DOM', 'DZA', 'ECU', 'EGY', 'ERI', 'ESH', 'ESP', 'EST', 'ETH', 'FIN', 'FJI', 'FLK', 'FRA', 'FRO', 'FSM', 'GAB', 'GBR', 'GEO', 'GGY', 'GHA', 'GIB', 'GIN', 'GLP', 'GMB', 'GNB', 'GNQ', 'GRC', 'GRD', 'GRL', 'GTM', 'GUF', 'GUM', 'GUY', 'HKG', 'HMD', 'HND', 'HRV', 'HTI', 'HUN', 'IDN', 'IMN', 'IND', 'IOT', 'IRL', 'IRN', 'IRQ', 'ISL', 'ISR', 'ITA', 'JAM', 'JEY', 'JOR', 'JPN', 'KAZ', 'KEN', 'KGZ', 'KHM', 'KIR', 'KNA', 'KOR', 'KWT', 'LAO', 'LBN', 'LBR', 'LBY', 'LCA', 'LIE', 'LKA', 'LTU', 'LUX', 'LVA', 'MAC', 'MAF', 'MAR', 'MCO', 'MDA', 'MDG', 'MDV', 'MEX', 'MHL', 'MKD', 'MLI', 'MLT', 'MMR', 'MNE', 'MNG', 'MNP', 'MOZ', 'MSR', 'MTQ', 'MUS', 'MYS', 'MYT', 'NAM', 'NCL', 'NER', 'NFK', 'NGA', 'NHB', 'NIC', 'NIU', 'NLD', 'NOR', 'NPL', 'NRU', 'NZL', 'OMN', 'PAK', 'PAN', 'PCN', 'PER', 'PHL', 'PLW', 'PNG', 'POL', 'PRI', 'PRK', 'PRT', 'PRY', 'PSE', 'PYF', 'QAT', 'REU', 'ROU', 'RUS', 'RWA', 'SAU', 'SCG', 'SDN', 'SEN', 'SGP', 'SGS', 'SHN', 'SJM', 'SLB', 'SLE', 'SLV', 'SMR', 'SOM', 'SPM', 'SRB', 'SSD', 'SUR', 'SVK', 'SVN', 'SWE', 'SWZ', 'SXM', 'SYC', 'SYR', 'TCA', 'TCD', 'TGO', 'THA', 'TJK', 'TKL', 'TKM', 'TLS', 'TON', 'TTO', 'TUN', 'TUR', 'TUV', 'TWN', 'TZA', 'UGA', 'UKR', 'UMI', 'URY', 'USA', 'UZB', 'VAT', 'VCT', 'VEN', 'VGB', 'VIR', 'VNM', 'VUT', 'WLF', 'WSM', 'YEM', 'YUG', 'ZAF', 'ZMB', 'ZWE']
位置
现在回想一下,在国家/地区表loc列中也提到了国家。还需要使其具有标准外观。这是一个略有不同的故事:ISO和奥林匹克代码均不可见。一切都以相当自由的形式描述。地址的城市,国家/地区和其他组成部分以逗号(随机顺序)列出。首先在某个地方,最后在某个地方。 pycountry在这里无济于事。并且有很多记录-在1922年的比赛中有525个独特的位置(以其原始形式)。
但是在这里找到了合适的工具。这是geopy,即地理定位器Nominatim。它是这样的:from geopy.geocoders import Nominatim
geolocator = Nominatim(user_agent='triathlon results researcher')
geolocator.geocode(' , , ', language='en')
Out: Location( , – , , Altaysky District, Altai Krai, Siberian Federal District, Russia, (51.78897945, 85.73956296106752, 0.0))
根据要求,它以随机形式给出结构化的答案-地址和坐标。如果您在此处设置语言(英语),那么它会翻译。首先,我们需要国家/地区的标准名称,以便随后将其转换为ISO代码。它仅在address属性中排在最后。由于geolocator每次都会向服务器发送请求,因此此过程并不快,需要500分钟才能记录500条记录。而且,碰巧没有答案。在这种情况下,第二个请求有时会有所帮助。在我的第一反应中没有收到130个请求。其中大多数经过两次重试处理。但是,即使再进行几次重试也没有处理34个名称。他们来了:['Tongyeong, Korea, Korea, South', 'Constanta, Mamaia, Romania, Romania', 'Weihai, China, China', '. , .', 'Odaiba Marin Park, Tokyo, Japan, Japan', 'Sweden, Smaland, Kalmar', 'Cholpon-Ata city, Resort Center "Kapriz", Kyrgyzstan', 'Luxembourg, Region Moselle, Moselle', 'Chita Peninsula, Japan', 'Kraichgau Region, Germany', 'Jintang, Chengdu, Sichuan Province, China, China', 'Madrid, Spain, Spain', 'North American Pro Championship, St. George, Utah, USA', 'Milan Idroscalo Linate, Italy', 'Dexing, Jiangxi Province, China, China', 'Mooloolaba, Australia, Australia', 'Nathan Benderson Park (NBP), 5851 Nathan Benderson Circle, Sarasota, FL 34235., United States', 'Strathclyde Country Park, North Lanarkshire, Glasgow, Great Britain', 'Quijing, China', 'United States of America , Hawaii, Kohala Coast', 'Buffalo City, East London, South Africa', 'Spain, Vall de Cardener', ', . ', 'Asian TriClub Championship, Hefei, China', 'Taizhou, Jiangsu Province, China, China', ', , «»', 'Buffalo, Gallagher Beach, Furhmann Blvd, United States', 'North American Pro Championship | St. George, Utah, USA', 'Weihai, Shandong, China, China', 'Tarzo - Revine Lago, Italy', 'Lausanee, Switzerland', 'Queenstown, New Zealand, New Zealand', 'Makuhari, Japan, Japan', 'Szombathlely, Hungary']
可以看出,在许多国家中都多次提到该国,这实际上是在干扰。通常,我必须手动处理这些剩余的名称,并获得所有的标准地址。此外,从这些地址中,我选择了一个国家,并将该国家写在数据透视表的新列中。正如我说过的那样,由于使用geopy工作并不很快,因此我决定立即保存位置坐标-纬度和经度。他们将派上用场,以便以后在地图上可视化。之后,使用pyco.countries.get(name ='...')。Alpha_3按名称搜索国家/地区,并分配一个三位数的代码。距离
枢轴工作台上需要执行的另一项重要操作是确定每次比赛的距离。这对我们将来计算速度很有用。铁人三项中,主要有四个距离-短跑,奥林匹克,半铁和铁。您可以看到,在比赛名称中通常会标明距离-这些是Sprint,Olympic,Half和Full Words 。此外,不同的组织者都有自己的距离指定。例如,钢铁侠的一半被指定为70.3(按距离数表示),奥林匹克运动会被指定为5150(公里数(51.5)),并且铁杆可以指定为“ 满”或者,由于缺乏解释-例如Ironman Arizona 2019。铁人-他是铁!在“挑战”中,铁杆距离指定为Long,半铁杆距离指定为Middle。根据公里数,我们的俄罗斯IronStar表示满为226,一半为113,但通常还会出现“ 满”和“ 半 ”字样。现在应用所有这些知识,并根据名称中出现的关键字标记所有种族。sprints = rs.loc[[i for i in rs.index if 'sprint' in rs.loc[i, 'event'].lower()]]
olympics1 = rs.loc[[i for i in rs.index if 'olympic' in rs.loc[i, 'event'].lower()]]
olympics2 = rs.loc[[i for i in rs.index if '5150' in rs.loc[i, 'event'].lower()]]
olympics = pd.concat([olympics1, olympics2])
rsd = pd.concat([sprints, olympics, halfs, fulls])
在rsd中,有1925条记录,即比总比赛数多3条记录,因此有些记录属于两个标准。让我们看看它们:rsd[rsd.duplicated(keep=False)]['event'].sort_index()
olympics.drop(65)
我们将与相交的Ironman Dun Laoghaire Full Swim 70.3 2019相同,这是最佳时间4:00。这是典型的一半。从指数85删除记录充盈。fulls.drop(85)
现在,我们在主数据框中写下距离信息,然后看看发生了什么:rs['dist'] = ''
rs.loc[sprints.index,'dist'] = 'sprint'
rs.loc[olympics.index,'dist'] = 'olympic'
rs.loc[halfs.index,'dist'] = 'half'
rs.loc[fulls.index,'dist'] = 'full'
rs.sample(10)
len(rs[rs['dist'] == ''])
Out: 0
并检查我们有问题的,模棱两可的:rs.loc[[38,65,82],['event','dist']]
pkl.dump(rs, open(r'D:\tri\summary5.pkl', 'wb'))
年龄组
现在回到赛车协议。我们已经分析了参与者的性别,国家和结果,并将其归为标准格式。但是还剩下两列-组,实际上是名称本身。让我们从小组开始。在铁人三项赛中,习惯上按年龄段划分参与者。一群专业人士也经常脱颖而出。实际上,偏移量是在每个这样的组中单独分配的-每个组中的前三个位置均被授予。在团体中,正在为锦标赛选择资格,例如在Konu上。合并所有记录,查看通常存在哪些组。rd = pkl.load(open(r'D:\tri\details2.pkl', 'rb'))
ar = pd.concat(rd)
ar['group'].unique()
原来,有很多组-581。随机选择了一百个这样的样子:
让我们看看其中哪个是最多的:['MSenior', 'FAmat.', 'M20', 'M65-59', 'F25-29', 'F18-22', 'M75-59', 'MPro', 'F24', 'MCORP M', 'F21-30', 'MSenior 4', 'M40-50', 'FAWAD', 'M16-29', 'MK40-49', 'F65-70', 'F65-70', 'M12-15', 'MK18-29', 'M50up', 'FSEMIFINAL 2 PRO', 'F16', 'MWhite', 'MOpen 25-29', 'F', 'MPT TRI-2', 'M16-24', 'FQUALIFIER 1 PRO', 'F15-17', 'FSEMIFINAL 2 JUNIOR', 'FOpen 60-64', 'M75-80', 'F60-69', 'FJUNIOR A', 'F17-18', 'FAWAD BLIND', 'M75-79', 'M18-29', 'MJUN19-23', 'M60-up', 'M70', 'MPTS5', 'F35-40', "M'S PT1", 'M50-54', 'F65-69', 'F17-20', 'MP4', 'M16-29', 'F18up', 'MJU', 'MPT4', 'MPT TRI-3', 'MU24-39', 'MK35-39', 'F18-20', "M'S", 'F50-55', 'M75-80', 'MXTRI', 'F40-45', 'MJUNIOR B', 'F15', 'F18-19', 'M20-29', 'MAWAD PC4', 'M30-37', 'F21-30', 'Mpro', 'MSEMIFINAL 1 JUNIOR', 'M25-34', 'MAmat.', 'FAWAD PC5', 'FA', 'F50-60', 'FSenior 1', 'M80-84', 'FK45-49', 'F75-79', 'M<23', 'MPTS3', 'M70-75', 'M50-60', 'FQUALIFIER 3 PRO', 'M9', 'F31-40', 'MJUN16-19', 'F18-19', 'M PARA', 'F35-44', 'MParaathlete', 'F18-34', 'FA', 'FAWAD PC2', 'FAll Ages', 'M PARA', 'F31-40', 'MM85', 'M25-39']
ar['group'].value_counts()[:30]
Out:
M40-44 199157
M35-39 183738
M45-49 166796
M30-34 154732
M50-54 107307
M25-29 88980
M55-59 50659
F40-44 48036
F35-39 47414
F30-34 45838
F45-49 39618
MPRO 38445
F25-29 31718
F50-54 26253
M18-24 24534
FPRO 23810
M60-64 20773
M 12799
F55-59 12470
M65-69 8039
F18-24 7772
MJUNIOR 6605
F60-64 5067
M20-24 4580
FJUNIOR 4105
M30-39 3964
M40-49 3319
F 3306
M70-74 3072
F20-24 2522
您会看到,这是一个五年小组,分别针对男性和女性,以及专业团体MPRO和FPRO。因此,我们的标准将是:ag = ['MPRO', 'M18-24', 'M25-29', 'M30-34', 'M35-39', 'M40-44', 'M45-49', 'M50-54', 'M55-59', 'M60-64', 'M65-69', 'M70-74', 'M75-79', 'M80-84', 'M85-90', 'FPRO', 'F18-24', 'F25-29', 'F30-34', 'F35-39', 'F40-44', 'F45-49', 'F50-54', 'F55-59', 'F60-64', 'F65-69', 'F70-74', 'F75-79', 'F80-84', 'F85-90']
这套产品几乎覆盖了所有整理器的95%。当然,我们将无法使所有小组都达到这一标准。但我们会寻找与它们相似的东西,并至少提供一部分。首先,我们将大写字母删除空格。发生了什么:
将它们转换为我们的标准格式。['F25-29F', 'F30-34F', 'F30-34-34', 'F35-39F', 'F40-44F', 'F45-49F', 'F50-54F', 'F55-59F', 'FAG:FPRO', 'FK30-34', 'FK35-39', 'FK40-44', 'FK45-49', 'FOPEN50-54', 'FOPEN60-64', 'MAG:MPRO', 'MK30-34', 'MK30-39', 'MK35-39', 'MK40-44', 'MK40-49', 'MK50-59', 'M40-44', 'MM85-89', 'MOPEN25-29', 'MOPEN30-34', 'MOPEN35-39', 'MOPEN40-44', 'MOPEN45-49', 'MOPEN50-54', 'MOPEN70-74', 'MPRO:', 'MPROM', 'M0-44"']
fix = { 'F25-29F': 'F25-29', 'F30-34F' : 'F30-34', 'F30-34-34': 'F30-34', 'F35-39F': 'F35-39', 'F40-44F': 'F40-44', 'F45-49F': 'F45-49', 'F50-54F': 'F50-54', 'F55-59F': 'F55-59', 'FAG:FPRO': 'FPRO', 'FK30-34': 'F30-34', 'FK35-39': 'F35-39', 'FK40-44': 'F40-44', 'FK45-49': 'F45-49', 'FOPEN50-54': 'F50-54', 'FOPEN60-64': 'F60-64', 'MAG:MPRO': 'MPRO', 'MK30-34': 'M30-34', 'MK30-39': 'M30-39', 'MK35-39': 'M35-39', 'MK40-44': 'M40-44', 'MK40-49': 'M40-49', 'MK50-59': 'M50-59', 'M40-44': 'M40-44', 'MM85-89': 'M85-89', 'MOPEN25-29': 'M25-29', 'MOPEN30-34': 'M30-34', 'MOPEN35-39': 'M35-39', 'MOPEN40-44': 'M40-44', 'MOPEN45-49': 'M45-49', 'MOPEN50-54': 'M50-54', 'MOPEN70-74': 'M70- 74', 'MPRO:' :'MPRO', 'MPROM': 'MPRO', 'M0-44"' : 'M40-44'}
现在,我们将转换应用于主数据帧ar,但首先将原始组值保存到新的组原始列。ar['group raw'] = ar['group']
在组列中,我们仅保留符合我们标准的那些值。现在我们可以欣赏我们的努力:len(ar[(ar['group'] != ar['group raw'])&(ar['group']!='')])
Out: 273
在一百五十万的水平上只有一点点。但是直到尝试,您才知道。选定的10如下所示:将数据框转换回rd字典后,保存新版本的数据框。pkl.dump(rd, open(r'D:\tri\details3.pkl', 'wb'))
名称
现在,让我们来照顾名字。让我们选择性地查看来自不同种族的100个名字:list(ar['name'].sample(100))
Out: ['Case, Christine', 'Van der westhuizen, Wouter', 'Grace, Scott', 'Sader, Markus', 'Schuller, Gunnar', 'Juul-Andersen, Jeppe', 'Nelson, Matthew', ' ', 'Westman, Pehr', 'Becker, Christoph', 'Bolton, Jarrad', 'Coto, Ricardo', 'Davies, Luke', 'Daniltchev, Alexandre', 'Escobar Labastida, Emmanuelle', 'Idzikowski, Jacek', 'Fairaislova Iveta', 'Fisher, Kulani', 'Didenko, Viktor', 'Osborne, Jane', 'Kadralinov, Zhalgas', 'Perkins, Chad', 'Caddell, Martha', 'Lynaire PARISH', 'Busing, Lynn', 'Nikitin, Evgeny', 'ANSON MONZON, ROBERTO', 'Kaub, Bernd', 'Bank, Morten', 'Kennedy, Ian', 'Kahl, Stephen', 'Vossough, Andreas', 'Gale, Karen', 'Mullally, Kristin', 'Alex FRASER', 'Dierkes, Manuela', 'Gillett, David', 'Green, Erica', 'Cunnew, Elliott', 'Sukk, Gaspar', 'Markina Veronika', 'Thomas KVARICS', 'Wu, Lewen', 'Van Enk, W.J.J', 'Escobar, Rosario', 'Healey, Pat', 'Scheef, Heike', 'Ancheta, Marlon', 'Heck, Andreas', 'Vargas Iii, Raul', 'Seferoglou, Maria', 'chris GUZMAN', 'Casey, Timothy', 'Olshanikov Konstantin', 'Rasmus Nerrand', 'Lehmann Bence', 'Amacker, Kirby', 'Parks, Chris', 'Tom, Troy', 'Karlsson, Ulf', 'Halfkann, Dorothee', 'Szabo, Gergely', 'Antipov Mikhail', 'Von Alvensleben, Alvo', 'Gruber, Peter', 'Leblanc, Jean-Philippe', 'Bouchard, Jean-Francois', 'Marchiotto MASSIMO', 'Green, Molly', 'Alder, Christoph', 'Morris, Huw', 'Deceur, Marc', 'Queenan, Derek', 'Krause, Carolin', 'Cockings, Antony', 'Ziehmer Chris', 'Stiene, John', 'Chmet Daniela', 'Chris RIORDAN', 'Wintle, Mel', ' ', 'GASPARINI CHRISTIAN', 'Westbrook, Christohper', 'Martens, Wim', 'Papson, Chris', 'Burdess, Shaun', 'Proctor, Shane', 'Cruzinha, Pedro', 'Hamard, Jacques', 'Petersen, Brett', 'Sahyoun, Sebastien', "O'Connell, Keith", 'Symoshenko, Zhan', 'Luternauer, Jan', 'Coronado, Basil', 'Smith, Alex', 'Dittberner, Felix', 'N?sman, Henrik', 'King, Malisa', 'PUHLMANN Andre']
情况很复杂。条目有多种选择:名字姓氏,姓氏名字,姓氏,名字,姓氏,名字等。即,不同的顺序,不同的寄存器,在某些地方有分隔符-逗号。西里尔语也有许多协议。也没有统一性,并且可能会出现以下格式:“姓氏名”,“名字姓氏”,“名字中间名姓氏”,“名字姓氏中间名”。尽管实际上,中间名也出现在拉丁语拼写中。顺便说一句,这里出现了另一个问题-音译。还应注意,即使没有中间名,记录也可能不限于两个单词。例如,对于西班牙裔,姓名加姓通常由三个或四个词组成。荷兰人的前缀是Van,中国人和韩国人的别名通常是三个单词。通常,您需要以某种方式来解散整个重传并将其标准化到最大。通常,在一场比赛中,每个人的名称格式都相同,但是即使在这里,也存在我们无法处理的错误。让我们开始将现有值存储在新的列名称raw中:ar['name raw'] = ar['name']
绝大多数协议使用拉丁语,所以我想做的第一件事就是音译。让我们看看参与者名称中可以包含哪些字符。set( ''.join(ar['name'].unique()))
Out: [' ', '!', '"', '#', '&', "'", '(', ')', '*', '+', ',', '-', '.', '/', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ':', ';', '>', '?', '@', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', '[', '\\', ']', '^', '_', '`', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '|', '\x7f', '\xa0', '¤', '¦', '§', '', '«', '\xad', '', '°', '±', 'µ', '¶', '·', '»', '', 'І', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', 'є', 'і', 'ў', '–', '—', '‘', '’', '‚', '“', '”', '„', '†', '‡', '…', '‰', '›', '']
那里只有什么!除了实际的字母和空格外,还有许多不同的古怪字符。其中,句点“。”,连字符“-”和撇号“'”可以被认为是有效的,也就是说,不会错误地出现。此外,还注意到在许多德国和挪威名字和姓氏中都有一个问号“?”。显然,它们正在替换扩展拉丁字母中的字符-'?','A','o','u',?这是示例:
逗号虽然经常发生,但在某些种族中只是一个分隔符,因此它也属于不可接受的类别。数字也不应出现在名称中。Pierre-Alexandre Petit, Jean-louis Lafontaine, Faris Al-Sultan, Jean-Francois Evrard, Paul O'Mahony, Aidan O'Farrell, John O'Neill, Nick D'Alton, Ward D'Hulster, Hans P.J. Cami, Luis E. Benavides, Maximo Jr. Rueda, Prof. Dr. Tim-Nicolas Korf, Dr. Boris Scharlowsk, Eberhard Gro?mann, Magdalena Wei?, Gro?er Axel, Meyer-Szary Krystian, Morten Halkj?r, RASMUSSEN S?ren Balle
bs = [s for s in symbols if not (s.isalpha() or s in " . - ' ? ,")]
bs
Out: ['!', '"', '#', '&', '(', ')', '*', '+', '/', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ':', ';', '>', '@', '[', '\\', ']', '^', '_', '`', '|', '\x7f', '\xa0', '¤', '¦', '§', '', '«', '\xad', '', '°', '±', '¶', '·', '»', '–', '—', '‘', '’', '‚', '“', '”', '„', '†', '‡', '…', '‰', '›', '']
我们将暂时删除所有这些字符,以找出它们存在多少个条目:for s in bs:
ar['name'] = ar['name'].str.replace(s, '')
corr = ar[ar['name'] != ar['name raw']]
有2184条这样的记录,即仅占总数的0.15%-很少。让我们看一下其中的100个:list(corr['name raw'].sample(100))
Out: ['Scha¶ffl, Ga?nter', 'Howard, Brian &', 'Chapiewski, Guilherme (Gc)', 'Derkach 1svd_mail_ru', 'Parker H1 Lauren', 'Leal le?n, Yaneri', 'TencA, David', 'Cortas La?pez, Alejandro', 'Strid, Bja¶rn', '(Crutchfield) Horan, Katie', 'Vigneron, Jean-Michel.Vigneron@gmail.Com', '\xa0', 'Telahr, J†rgen', 'St”rmer, Melanie', 'Nagai B1 Keiji', 'Rinc?n, Mariano', 'Arkalaki, Angela (Evangelia)', 'Barbaro B1 Bonin Anna G:Charlotte', 'Ra?esch, Ja¶rg', "CAVAZZI NICCOLO\\'", 'D„nzel, Thomas', 'Ziska, Steffen (Gerhard)', 'Kobilica B1 Alen', 'Mittelholcz, Bala', 'Jimanez Aguilar, Juan Antonio', 'Achenza H1 Giovanni', 'Reppe H2 Christiane', 'Filipovic B2 Lazar', 'Machuca Ka?hnel, Ruban Alejandro', 'Gellert (Silberprinz), Christian', 'Smith (Guide), Matt', 'Lenatz H1 Benjamin', 'Da¶llinger, Christian', 'Mc Carthy B1 Patrick Donnacha G:Bryan', 'Fa¶llmer, Chris', 'Warner (Rivera), Lisa', 'Wang, Ruijia (Ray)', 'Mc Carthy B1 Donnacha', 'Jones, Nige (Paddy)', 'Sch”ler, Christoph', '\xa0', 'Holthaus, Adelhard (Allard)', 'Mi;Arro, Ana', 'Dr: Koch Stefan', '\xa0', '\xa0', 'Ziska, Steffen (Gerhard)', 'Albarraca\xadn Gonza?lez, Juan Francisco', 'Ha¶fling, Imke', 'Johnston, Eddie (Edwin)', 'Mulcahy, Bob (James)', 'Gottschalk, Bj”rn', '\xa0', 'Gretsch H2 Kendall', 'Scorse, Christopher (Chris)', 'Kiel‚basa, Pawel', 'Kalan, Magnus', 'Roderick "eric" SIMBULAN', 'Russell;, Mark', 'ROPES AND GRAY TEAM 3', 'Andrade, H?¦CTOR DANIEL', 'Landmann H2 Joshua', 'Reyes Rodra\xadguez, Aithami', 'Ziska, Steffen (Gerhard)', 'Ziska, Steffen (Gerhard)', 'Heuza, Pierre', 'Snyder B1 Riley Brad G:Colin', 'Feldmann, Ja¶rg', 'Beveridge H1 Nic', 'FAGES`, perrine', 'Frank", Dieter', 'Saarema¤el, Indrek', 'Betancort Morales, Arida–y', 'Ridderberg, Marie_Louise', '\xa0', 'Ka¶nig, Johannes', 'W Van(der Klugt', 'Ziska, Steffen (Gerhard)', 'Johnson, Nick26', 'Heinz JOHNER03', 'Ga¶rg, Andra', 'Maruo B2 Atsuko', 'Moral Pedrero H1 Eva Maria', '\xa0', 'MATUS SANTIAGO Osc1r', 'Stenbrink, Bja¶rn', 'Wangkhan, Sm1.Thaworn', 'Pullerits, Ta¶nu', 'Clausner, 8588294149', 'Castro Miranda, Josa Ignacio', 'La¶fgren, Pontuz', 'Brown, Jann ( Janine )', 'Ziska, Steffen (Gerhard)', 'Koay, Sa¶ren', 'Ba¶hm, Heiko', 'Oleksiuk B2 Vita', 'G Van(de Grift', 'Scha¶neborn, Guido', 'Mandez, A?lvaro', 'Garca\xada Fla?rez, Daniel']
结果,经过大量研究,决定:用逗号,句点和'\ xa0'符号和空格替换所有字母字符以及空格,连字符,撇号和问号,并用空字符串替换所有其他字符,即删除即可。ar['name'] = ar['name raw']
for s in symbols:
if s.isalpha() or s in " - ? '":
continue
if s in ".,\xa0":
ar['name'] = ar['name'].str.replace(s, ' ')
else:
ar['name'] = ar['name'].str.replace(s, '')
然后摆脱多余的空间:ar['name'] = ar['name'].str.split().str.join(' ')
ar['name'] = ar['name'].str.strip()
让我们看看发生什么了:ar.loc[corr.index].sample(10)
qmon = ar[(ar['name'].str.replace('?', '').str.strip() == '')&(ar['name']!='')]
它们共有3,429个,看起来像这样:我们使名称达到相同标准的目标是使相同的名称看起来相同,但以不同的方式不同。在名称仅由问号组成的情况下,它们仅在字符数上有所不同,但这并不能完全确保具有相同数字的名称实际上是相同的。因此,我们将它们全部替换为空字符串,以后将不再考虑。ar.loc[qmon.index, 'name'] = ''
名称为空字符串的条目总数为3454。不是很多,我们将生存。现在我们已经摆脱了不必要的字符,我们可以继续音译。为此,请首先将所有内容都转换为小写,以免重复工作。ar['name'] = ar['name'].str.lower()
接下来,创建一个字典:trans = {'':'a', '':'b', '':'v', '':'g', '':'d', '':'e', '':'e', '':'zh', '':'z', '':'i', '':'y', '':'k', '':'l', '':'m', '':'n', '':'o', '':'p', '':'r', '':'s', '':'t', '':'u', '':'f', '':'kh', '':'ts', '':'ch', '':'sh', '':'shch', '':'', '':'y', '':'', '':'e', '':'yu', '':'ya', 'є':'e', 'і': 'i','ў':'w','µ':'m'}
它还包括白俄罗斯语和乌克兰语中使用的所谓的西里尔字母扩展字母“є”,“і”,“ў”,以及希腊字母“ µ”。应用转换:for s in trans:
ar['name'] = ar['name'].str.replace(s, trans[s])
现在,从工作的小写字母开始,我们将所有内容转换为熟悉的格式,其中名字和姓氏以大写字母开头:ar['name'] = ar['name'].str.title()
让我们看看发生什么了。ar[ar['name raw'].str.lower().str[0].isin(trans.keys())].sample(10)
set( ''.join(ar['name'].unique()))
Out: [' ', "'", '-', '?', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J','K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
一切正确。结果,更正影响了1,253,882,占记录总数的89%,唯一名称的数量从660,207减少至599,186,即减少了61,000或几乎10%。哇!将ar记录的并集转换回rd协议字典后,保存到新文件。pkl.dump(rd, open(r'D:\tri\details4.pkl', 'wb'))
现在我们需要恢复顺序。也就是说,所有记录看起来都将是-First Name Last Name或Last Name First Name。要确定哪一个。是的,除了名称和姓氏之外,某些协议还包含中间名。可能发生的是,同一个人在不同协议中的书写方式有所不同-某个中间名的地方,而另一个中间名。这会干扰他的身份,因此请尝试删除中间名。男性的姓氏通常以“ hiv”结尾,女性的姓氏通常以“ vna”结尾。但是也有例外。例如-Ilyich,Ilyinichna,Nikitich,Nikitichna。是的,很少有这样的例外。如前所述,可以将一种协议中的名称格式视为永久性的。因此,要摆脱赞助人,您需要找到他们所处的种族。为此,请在列名称中找到片段“ vich”和“ vna”的总数并将它们与每个协议中的条目总数进行比较。如果这些数字接近,则有一个中间名,否则就没有。寻求严格的合规是不合理的,例如,即使在记录中间名的比赛中,外国人也可以参加,并且没有他的情况下,他们也会被记录下来。也有可能参与者忘记了或不想指出他的中间名。另一方面,也有以``vich''结尾的姓氏,在白俄罗斯和其他国家中有许多姓氏为斯拉夫语的姓氏。此外,我们进行了音译。可以在音译之前进行此分析,但随后有机会错过其中有中间名的协议,但最初它已经是拉丁文了。所以一切都很好。因此,我们将在该列中查找所有片段数量为“ vich”和“ vna”的协议名称超过协议中条目总数的50%。wp = {}
for e in rd:
nvich = (''.join(rd[e]['name'])).count('vich')
nvna = (''.join(rd[e]['name'])).count('vna')
if nvich + nvna > 0.5*len(rd[e]):
wp[e] = rd[e]
有29种这样的协议。有趣的是,如果不是50%而是20%,反之则是70%,结果不变,因此29种协议不变。因此,我们做出了正确的选择。因此,少于20%-姓氏的影响,超过70%-没有中间名的个人记录的影响。借助数据透视表检查了该国,结果发现其中有25个在俄罗斯,有4个在阿布哈兹。
继续。我们将只处理包含三个部分的记录,即那些(大概)有姓,名,中间名的部分。sum_n3w = 0
sum_nnot3w = 0
for e in wp:
sum_n3w += len([n for n in wp[e]['name'] if len(n.split()) == 3])
sum_nnot3w += len(wp[e]) - n3w
此类记录的大多数为86%。现在,将三个组成部分划分为name0,name1,name2的列:for e in wp:
ind3 = [i for i in rd[e].index if len(rd[e].loc[i,'name'].split()) == 3]
rd[e]['name0'] = ''
rd[e]['name1'] = ''
rd[e]['name2'] = ''
rd[e].loc[ind3, 'name0'] = rd[e].loc[ind3,'name'].str.split().str[0]
rd[e].loc[ind3, 'name1'] = rd[e].loc[ind3,'name'].str.split().str[1]
rd[e].loc[ind3, 'name2'] = rd[e].loc[ind3,'name'].str.split().str[2]
这是其中一种协议的样子:特别是,很明显,这两个组件的记录尚未处理。现在,对于每种协议,您需要确定哪一列具有中间名称。只有两个选项-name1,name2,因为它不能放在第一位。确定后,我们将收集一个没有该名称的新名称。for e in wp:
n1=(''.join(rd[e]['name1'])).count('vich')+(''.join(rd[e]['name1'])).count('vna')
n2=(''.join(rd[e]['name2'])).count('vich')+(''.join(rd[e]['name2'])).count('vna')
if (n1 > n2):
rd[e]['new name'] = rd[e]['name0'] + ' ' + rd[e]['name2']
else:
rd[e]['new name'] = rd[e]['name0'] + ' ' + rd[e]['name1']
for e in wp:
ind = rd[e][rd[e]['new name'].str.strip() != ''].index
rd[e].loc[ind, 'name'] = rd[e].loc[ind, 'new name']
rd[e] = rd[e].drop(columns = ['name0','name1','name2','new name'])
pkl.dump(rd, open(r'D:\tri\details5.pkl', 'wb'))
现在,您需要将名称重新排序。也就是说,在所有协议中,所有协议中的名称都必须先跟随其后的名字,反之亦然-首先是姓氏,然后是名字。取决于哪个,现在我们将找出答案。全名可以包含两个以上的单词,即使在删除中间名之后,情况也有些复杂。ar['nwin'] = ar['name'].str.count(' ') + 1
ar.loc[ar['name'] == '','nwin'] = 0
100*ar['nwin'].value_counts()/len(ar)
名称中的单词数记录数记录所占的百分比(%)当然,绝大多数(91%)是两个单词-只是一个名字和一个姓。但是带有三个和四个词的条目也很多。让我们看一下这些记录的国籍:ar[ar['nwin'] >= 3]['country'].value_counts()[:12]
Out:
ESP 28435
MEX 10561
USA 7608
DNK 7178
BRA 6321
NLD 5748
DEU 4310
PHL 3941
ZAF 3862
ITA 3691
BEL 3596
FRA 3323
好吧,首先是西班牙,其次是西班牙-墨西哥,这是一个西班牙裔国家,比美国更远,美国在历史上也有很多西班牙裔。巴西和菲律宾也是西班牙(和葡萄牙语)的名称。丹麦,荷兰,德国,南非,意大利,比利时和法国是另一回事,有时候姓氏有时会带有某种前缀,因此有两个以上的单词。但是,在所有这些情况下,名称本身通常由一个单词组成,姓氏由两个,三个组成。当然,该规则也有例外,但是我们将不再处理它们。首先,对于每种协议,您需要确定顺序是什么:名称-姓氏,反之亦然。怎么做?我想到了以下想法:首先,姓氏的种类通常比名字的种类大得多。即使在一个协议的框架内也是如此。其次,名称的长度通常小于姓氏的长度(即使是非复合姓氏)。我们将结合使用这些条件来确定初步订单。选择全名的第一个和最后一个单词:ar['new name'] = ar['name']
ind = ar[ar['nwin'] < 2].index
ar.loc[ind, 'new name'] = '. .'
ar['wfin'] = ar['new name'].str.split().str[0]
ar['lwin'] = ar['new name'].str.split().str[-1]
将合并的ar数据帧转换回rd字典,以便新列nwin,ns0,ns落入每个种族的数据帧。接下来,根据我们的标准,确定顺序为“名姓”的协议数和顺序相反的协议数。我们将仅考虑全名由两个单词组成的条目。同时,将名称(名字)保存在新列中:name_surname = {}
surname_name = {}
for e in rd:
d = rd[e][rd[e]['nwin'] == 2]
if len(d['fwin'].unique()) < len(d['lwin'].unique()) and len(''.join(d['fwin'])) < len(''.join(d['lwin'])):
name_surname[e] = d
rd[e]['first name'] = rd[e]['fwin']
if len(d['fwin'].unique()) > len(d['lwin'].unique()) and len(''.join(d['fwin'])) > len(''.join(d['lwin'])):
surname_name[e] = d
rd[e]['first name'] = rd[e]['lwin']
结果是:“ 姓氏名 ”命令-244个协议,“ 姓氏名 ”命令-1,508个协议。因此,我们将导致更常见的格式。由于我们同时检查了两个条件的满足情况,甚至存在严格的不平等性,因此总和小于总金额。在某些协议中,只有其中一个条件可以满足,或者可以满足,但是不太可能发生平等。但这是完全不重要的,因为已经定义了格式。现在,假设我们已经以足够高的精度确定了订单,而不会忘记它不是100%准确的,我们将使用此信息。在“ 名字”列中找到最受欢迎的名字:vc = ar['first name'].value_counts()
遇到相遇一百次以上的人:pfn=vc[vc>100]
共有1,673个,以下是前一百个,按流行程度从高到低排列:
现在,使用此列表,我们将遍历所有协议,并比较在名称的第一个单词或最后一个单词中还有更多匹配项的位置。我们将只考虑两个单词的名称。如果与最后一个单词有更多匹配项,则顺序是正确的;如果与第一个单词匹配,则相反。而且,在这里我们已经更加自信,因此您可以使用此知识,并且每次通过时,我们都会将其下一个协议的名称列表添加到初始流行名称列表中。为了避免随机错误,我们根据名称在初始列表中出现的频率对协议进行了预排序,从而为那些匹配项很少且将在周期结束时进行处理的协议准备了更广泛的列表。['Michael', 'David', 'Thomas', 'John', 'Daniel', 'Mark', 'Peter', 'Paul', 'Christian', 'Robert', 'Martin', 'James', 'Andrew', 'Chris', 'Richard', 'Andreas', 'Matthew', 'Brian', 'Patrick', 'Scott', 'Kevin', 'Stefan', 'Jason', 'Eric', 'Christopher', 'Alexander', 'Simon', 'Mike', 'Tim', 'Frank', 'Stephen', 'Steve', 'Andrea', 'Jonathan', 'Markus', 'Marco', 'Adam', 'Ryan', 'Jan', 'Tom', 'Marc', 'Carlos', 'Jennifer', 'Matt', 'Steven', 'Jeff', 'Sergey', 'William', 'Aleksandr', 'Sarah', 'Alex', 'Jose', 'Andrey', 'Benjamin', 'Sebastian', 'Ian', 'Anthony', 'Ben', 'Oliver', 'Antonio', 'Ivan', 'Sean', 'Manuel', 'Matthias', 'Nicolas', 'Dan', 'Craig', 'Dmitriy', 'Laura', 'Luis', 'Lisa', 'Kim', 'Anna', 'Nick', 'Rob', 'Maria', 'Greg', 'Aleksey', 'Javier', 'Michelle', 'Andre', 'Mario', 'Joseph', 'Christoph', 'Justin', 'Jim', 'Gary', 'Erik', 'Andy', 'Joe', 'Alberto', 'Roberto', 'Jens', 'Tobias', 'Lee', 'Nicholas', 'Dave', 'Tony', 'Olivier', 'Philippe']
sbpn = pd.DataFrame(columns = ['event', 'num pop names'], index=range(len(rd)))
for i in range(len(rd)):
e = list(rd.keys())[i]
sbpn.loc[i, 'event'] = e
sbpn.loc[i, 'num pop names'] = len(set(pfn).intersection(rd[e]['first name']))
sbnp=sbnp.sort_values(by = 'num pop names',ascending=False)
sbnp = sbnp.reset_index(drop=True)
tofix = []
for i in range(len(rd)):
e = sbpn.loc[i, 'event']
if len(set(list(rd[e]['fwin'])).intersection(pfn)) > len(set(list(rd[e]['lwin'])).intersection(pfn)):
tofix.append(e)
pfn = list(set(pfn + list(rd[e]['fwin'])))
else:
pfn = list(set(pfn + list(rd[e]['lwin'])))
有235个协议。也就是说,与第一近似(244)中所发生的相同。可以肯定的是,我选择性地查看了每个记录的前三个记录,以确保所有内容都是正确的。还要检查排序的第一阶段是否从类名称姓氏中输入了36个错误条目,并从类名称中给出了2个错误条目。我查看了每个记录的前三个记录,确实,第二个阶段运行良好。现在,实际上,仍然需要修复发现错误顺序的那些协议:for e in tofix:
ind = rd[e][rd[e]['nwin'] > 1].index
rd[e].loc[ind,'name'] = rd[e].loc[ind,'name'].str.split(n=1).str[1] + ' ' + rd[e].loc[ind,'name'].str.split(n=1).str[0]
在拆分中,我们使用参数n限制了件数。逻辑是这样的:名称是一个单词,全名中的第一个。其他所有内容都是姓(可能由几个词组成)。只需交换它们。现在我们摆脱不必要的列并保存:for e in rd:
rd[e] = rd[e].drop(columns = ['new name', 'first name', 'fwin','lwin', 'nwin'])
pkl.dump(rd, open(r'D:\tri\details6.pkl', 'wb'))
检查结果。随机打固定记录:总共固定108,000条记录。唯一全名的数量从598个减少至54.7万个。精细!完成格式化。第3部分。不完整数据的恢复
现在继续恢复丢失的数据。并且有这样。国家
让我们从国家开始。查找未显示国家/地区的所有记录:arnc = ar[ar['country'] == '']
其中有3,221个,其中随机有10个:nnc = arnc['name'].unique()
没有国家/地区的记录中唯一名称的数量为3051。让我们看看是否可以减少该数量。事实是,在铁人三项赛中,人们很少只参加一场比赛,他们通常会定期参加比赛,每个赛季几次,每年一次,不断训练。因此,对于数据中的许多名称,很可能有多个记录。要恢复有关该国家的信息,请尝试在指示该国家的记录中查找具有相同名称的记录。arwc = ar[ar['country'] != '']
nwc = arwc['name'].unique()
tofix = set(nnc).intersection(nwc)
Out: ['Kleber-Schad Ute Cathrin', 'Sellner Peter', 'Pfeiffer Christian', 'Scholl Thomas', 'Petersohn Sandra', 'Marchand Kurt', 'Janneck Britta', 'Angheben Riccardo', 'Thiele Yvonne', 'Kie?Wetter Martin', 'Schymik Gerhard', 'Clark Donald', 'Berod Brigitte', 'Theile Markus', 'Giuliattini Burbui Margherita', 'Wehrum Alexander', 'Kenny Oisin', 'Schwieger Peter', 'Grosse Bianca', 'Schafter Carsten', 'Breck Dirk', 'Mautes Christoph', 'Herrmann Andreas', 'Gilbert Kai', 'Steger Peter', 'Jirouskova Jana', 'Jehrke Michael', 'Valentine David', 'Reis Michael', 'Wanka Michael', 'Schomburg Jonas', 'Giehl Caprice', 'Zinser Carsten', 'Schumann Marcus', 'Magoni Livio', 'Lauden Yann', 'Mayer Dieter', 'Krisa Stefan', 'Haberecht Bernd', 'Schneider Achim', 'Gibanel Curto Antonio', 'Miranda Antonio', 'Juarez Pedro', 'Prelle Gerrit', 'Wuste Kay', 'Bullock Graeme', 'Hahner Martin', 'Kahl Maik', 'Schubnell Frank', 'Hastenteufel Marco', …]
其中有2236个,即接近四分之三。现在,对于此列表中的每个名称,您需要通过其所在位置的记录来确定国家/地区。但是碰巧在多个记录中和在不同的国家都可以找到相同的名称。这要么是同名,要么是搬家。因此,我们首先处理所有事物都是唯一的事物。fix = {}
for n in tofix:
nr = arwc[arwc['name'] == n]
if len(nr['country'].unique()) == 1:
fix[n] = nr['country'].iloc[0]
循环制作。但是,坦率地说,它可以解决很长时间-大约三分钟。如果有更多数量级的条目,则可能必须提出矢量实现。有2,013个条目,占潜力的90%。不同国家在不同记录中可能出现的名称,以最常出现的国家为准。if n not in fix:
nr = arwc[arwc['name'] == n]
vc = nr['country'].value_counts()
if vc[0] > vc[1]:
fix[n] = vc.index[0]
因此,找到了2,208个名称匹配,占所有潜在名称的99%。
我们应用以下对应关系:{'Kleber-Schad Ute Cathrin': 'DEU', 'Sellner Peter': 'AUT', 'Pfeiffer Christian': 'AUT', 'Scholl Thomas': 'DEU', 'Petersohn Sandra': 'DEU', 'Marchand Kurt': 'BEL', 'Janneck Britta': 'DEU', 'Angheben Riccardo': 'ITA', 'Thiele Yvonne': 'DEU', 'Kie?Wetter Martin': 'DEU', 'Clark Donald': 'GBR', 'Berod Brigitte': 'FRA', 'Theile Markus': 'DEU', 'Giuliattini Burbui Margherita': 'ITA', 'Wehrum Alexander': 'DEU', 'Kenny Oisin': 'IRL', 'Schwieger Peter': 'DEU', 'Schafter Carsten': 'DEU', 'Breck Dirk': 'DEU', 'Mautes Christoph': 'DEU', 'Herrmann Andreas': 'DEU', 'Gilbert Kai': 'DEU', 'Steger Peter': 'AUT', 'Jirouskova Jana': 'CZE', 'Jehrke Michael': 'DEU', 'Wanka Michael': 'DEU', 'Giehl Caprice': 'DEU', 'Zinser Carsten': 'DEU', 'Schumann Marcus': 'DEU', 'Magoni Livio': 'ITA', 'Lauden Yann': 'FRA', 'Mayer Dieter': 'DEU', 'Krisa Stefan': 'DEU', 'Haberecht Bernd': 'DEU', 'Schneider Achim': 'DEU', 'Gibanel Curto Antonio': 'ESP', 'Juarez Pedro': 'ESP', 'Prelle Gerrit': 'DEU', 'Wuste Kay': 'DEU', 'Bullock Graeme': 'GBR', 'Hahner Martin': 'DEU', 'Kahl Maik': 'DEU', 'Schubnell Frank': 'DEU', 'Hastenteufel Marco': 'DEU', 'Tedde Roberto': 'ITA', 'Minervini Domenico': 'ITA', 'Respondek Markus': 'DEU', 'Kramer Arne': 'DEU', 'Schreck Alex': 'DEU', 'Bichler Matthias': 'DEU', …}
for n in fix:
ind = arnc[arnc['name'] == n].index
ar.loc[ind, 'country'] = fix[n]
pkl.dump(rd, open(r'D:\tri\details7.pkl', 'wb'))
地板
与国家/地区一样,在某些记录中未指出参与者的性别。ar[ar['sex'] == '']
其中有2538个,相对较少,但我们会再次尝试使数量更少。将原始值保存在新列中。ar['sex raw'] =ar['sex']
与我们从其他协议中按名称检索信息的国家不同,这里的一切都有些复杂。事实是,数据中充满了错误,并且发现有很多名字(共有2 101个),带有两个性别的标记。arws = ar[(ar['sex'] != '')&(ar['name'] != '')]
snds = arws[arws.duplicated(subset='name',keep=False)]
snds = snds.drop_duplicates(subset=['name','sex'], keep = 'first')
snds = snds.sort_values(by='name')
snds = snds[snds.duplicated(subset = 'name', keep=False)]
snds
rss = [rd[e] for e in rd if len(rd[e][rd[e]['sex'] != '']['sex'].unique()) == 1]
共有633个协议,这似乎是完全有可能的,只是分别针对女性和男性的协议。但是事实是,几乎所有这些协议都包含男女的年龄段(男性年龄段以字母M开头,女性以字母F开头)。例如:预期年龄组的名称以男性字母M开头,以女性字母F开头。在前两个示例中,尽管性别列中存在错误'ITU World Cup Tiszaujvaros Olympic 2002'
,该群组的名称似乎仍能正确描述该成员的性别。基于几个示例,我们假设正确指示了组,并且可能错误地指示了性别。查找组名中首字母与性别不匹配的所有条目。我们将使用group group raw的初始名称,因为在标准化过程中许多记录都没有分组,但是现在我们只需要第一个字母,因此标准并不重要。ar['grflc'] = ar['group raw'].str.upper().str[0]
grncs = ar[(ar['grflc'].isin(['M','F']))&(ar['sex']!=ar['grflc'])]
有26 161个这样的记录。好吧,让我们根据年龄组的名称更正性别:ar.loc[grncs.index, 'sex'] = grncs['grflc']
让我们看一下结果:好。现在剩下多少记录没有性别?ar[(ar['sex'] == '')&(ar['name'] != '')]
原来是一个!
好吧,这个小组并没有真正表明,但是,显然,这是一个女人。艾米丽(Emily)是一位女性名字,除了该参与者(或她的同名人物)一年前结束比赛外,还标明了性别和团体。
手动恢复此处*并继续。ar.loc[arns.index, 'sex'] = 'F'
现在所有记录都带有性别。*通常来说,这样做当然是错误的-重复运行,如果在名称转换之前链中的某些内容发生了变化(例如,姓名转换),那么可能会有不止一个性别的记录超过一个,并且并非所有记录都是女性的,那么就会发生错误。因此,您必须插入繁琐的逻辑以在其他协议中搜索具有相同名称和性别的参与者,例如恢复国家/地区以及如何对其进行测试,或者,为了避免不必要的复杂化,请在此逻辑中添加仅找到一条记录的检查并且名称如此之类,否则会引发异常,从而使整个笔记本电脑停止工作,您会注意到与计划的差异并进行干预。if len(arns) == 1 and arns['name'].iloc[0] == 'Stather Emily':
ar.loc[arns.index, 'sex'] = 'F'
else:
raise Exception('Different scenario!')
看来这可以让您平静下来。但是事实是,更正是基于正确指示组的假设。确实是这样。几乎总是。几乎。尽管如此,还是偶然发现了一些不一致的地方,所以现在让我们尝试确定所有这些不一致之处,或者尽可能多。如前所述,在第一个示例中,恰恰是这样一个事实,即性别基于其自身关于男性和女性姓名的观念而与姓名不符,从而保护了我们。在男性和女性记录上找到所有姓名。在此,名称应理解为名称,而不是全名,即没有姓氏的英文名字。ar['fn'] = ar['name'].str.split().str[-1]
mfn = list(ar[ar['sex'] == 'M']['fn'].unique())
总共列出了32,508个男性名字。以下是50个最受欢迎的网址:['Michael', 'David', 'Thomas', 'John', 'Daniel', 'Mark', 'Peter', 'Paul', 'Christian', 'Robert', 'Martin', 'James', 'Andrew', 'Chris', 'Richard', 'Andreas', 'Matthew', 'Brian', 'Kevin', 'Patrick', 'Scott', 'Stefan', 'Jason', 'Eric', 'Alexander', 'Christopher', 'Simon', 'Mike', 'Tim', 'Frank', 'Stephen', 'Steve', 'Jonathan', 'Marco', 'Markus', 'Adam', 'Ryan', 'Tom', 'Jan', 'Marc', 'Carlos', 'Matt', 'Steven', 'Jeff', 'Sergey', 'William', 'Aleksandr', 'Andrey', 'Benjamin', 'Jose']
ffn = list(ar[ar['sex'] == 'F']['fn'].unique())
女性更少-14423。最受欢迎:
好,看起来很合逻辑。让我们看看是否有交叉点。['Jennifer', 'Sarah', 'Laura', 'Lisa', 'Anna', 'Michelle', 'Maria', 'Andrea', 'Nicole', 'Jessica', 'Julie', 'Elizabeth', 'Stephanie', 'Karen', 'Christine', 'Amy', 'Rebecca', 'Susan', 'Rachel', 'Anne', 'Heather', 'Kelly', 'Barbara', 'Claudia', 'Amanda', 'Sandra', 'Julia', 'Lauren', 'Melissa', 'Emma', 'Sara', 'Katie', 'Melanie', 'Kim', 'Caroline', 'Erin', 'Kate', 'Linda', 'Mary', 'Alexandra', 'Christina', 'Emily', 'Angela', 'Catherine', 'Claire', 'Elena', 'Patricia', 'Charlotte', 'Megan', 'Daniela']
mffn = set(mfn).intersection(ffn)
有。其中有2,811个,让我们仔细看看。首先,我们找出具有这些名称的记录数:armfn = ar[ar['fn'].isin(mffn)]
有725562个。一半!太神奇了!大约有37,000个唯一名称,但有一半记录共有2800个,让我们看看这些名称是什么,它们是最受欢迎的。为此,请创建一个新的数据框,其中这些名称将作为索引:df = pd.DataFrame(armfn['fn'].value_counts())
df = df.rename(columns={'fn':'total'})
我们计算每个记录有多少个男性和女性记录。df['M'] = armfn[armfn['sex'] == 'M']['fn'].value_counts()
df['F'] = armfn[armfn['sex'] == 'F']['fn'].value_counts()
df.sort_values(by = 'F', ascending=False)
import gender_guesser.detector as gg
d = gg.Detector()
d.get_gender(u'Oleg')
Out: 'male'
d.get_gender(u'Evgeniya')
Out: 'female'
一切都没事。但是,如果您检查Andrea的名字,那么他也会给出女性,但这并不是完全正确的。没错,这是出路。如果您查看检测器的名称属性,那么所有歧义都将在此处可见。d.names['Andrea']
Out: {'female': ' 4 4 3 4788 64 579 34 1 7 ',
'mostly_female': '5 6 7 ',
'male': ' 7 '}
是的,也就是说,get_gender仅为您提供了最可能的选择,但实际上它可能要复杂得多。检查其他名称:d.names['Maria']
Out: {'female': '686 6 A 85986 A BA 3B98A75457 6 ',
'mostly_female': ' BBC A 678A9 '}
d.names['Oleg']
Out: {'male': ' 6 2 99894737 3 '}
也就是说,每个名称的名称列表对应于一个或多个键值对,其中键-它是性别:male,FEMALE,mostly_male,mostly_female和andy,值-相应国家/地区的值列表:1,2,3 ... .. 9ABC。这些国家是:d.COUNTRIES
Out: ['great_britain', 'ireland', 'usa', 'italy', 'malta', 'portugal', 'spain', 'france', 'belgium', 'luxembourg', 'the_netherlands', 'east_frisia', 'germany', 'austria', 'swiss', 'iceland', 'denmark', 'norway', 'sweden', 'finland', 'estonia', 'latvia', 'lithuania', 'poland', 'czech_republic', 'slovakia', 'hungary', 'romania', 'bulgaria', 'bosniaand', 'croatia', 'kosovo', 'macedonia', 'montenegro', 'serbia', 'slovenia', 'albania', 'greece', 'russia', 'belarus', 'moldova', 'ukraine', 'armenia', 'azerbaijan', 'georgia', 'the_stans', 'turkey', 'arabia', 'israel', 'china', 'india', 'japan', 'korea', 'vietnam', 'other_countries']
我不完全理解字母数字的含义或它们在列表中的具体含义。但这并不重要,因为我决定限制自己只使用那些具有明确解释的名称。也就是说,对于它,只有一对键值对,并且键是male或female。对于我们数据框中的每个名称,写下其对性别猜测的解释:df['sex from gg'] = ''
for n in df.index:
if n in list(d.names.keys()):
options = list(d.names[n].keys())
if len(options) == 1 and options[0] == 'male':
df.loc[n, 'sex from gg'] = 'M'
if len(options) == 1 and options[0] == 'female':
df.loc[n, 'sex from gg'] = 'F'
原来有1,150个名字。这里是上面已经讨论过的最受欢迎的:好吧,还不错。现在将此逻辑应用于所有记录。all_names = ar['fn'].unique()
male_names = []
female_names = []
for n in all_names:
if n in list(d.names.keys()):
options = list(d.names[n].keys())
if len(options) == 1:
if options[0] == 'male':
male_names.append(n)
if options[0] == 'female':
female_names.append(n)
发现男性7 091人,女性5 054人。应用转换:tofixm = ar[ar['fn'].isin(male_names)]
ar.loc[tofixm.index, 'sex'] = 'M'
tofixf = ar[ar['fn'].isin(female_names)]
ar.loc[tofixf.index, 'sex'] = 'F'
我们看一下结果:ar[ar['sex']!=ar['sex raw']]
更正了30,352个条目(连同按组名进行的更正)。像往常一样,随机抽取10个:现在,我们确定已正确识别性别,我们还将加入标准组。让我们看看它们不匹配的地方:ar['gfl'] = ar['group'].str[0]
gncws = ar[(ar['sex'] != ar['gfl']) & (ar['group']!='')]
4,248个条目。替换第一个字母:ar.loc[gncws.index, 'group'] = ar.loc[gncws.index, 'sex'] + ar.loc[gncws.index, 'group'].str[1:].index, 'sex']
pkl.dump(rd, open(r'D:\tri\details8.pkl', 'wb'))
就这样,恢复不完整的数据。公告更新
仍然需要用关于男女人数等方面的最新数据来更新汇总表。rs['total raw'] = rs['total']
rs['males raw'] = rs['males']
rs['females raw'] = rs['females']
rs['rus raw'] = rs['rus']
for i in rs.index:
e = rs.loc[i,'event']
rs.loc[i,'total'] = len(rd[e])
rs.loc[i,'males'] = len(rd[e][rd[e]['sex'] == 'M'])
rs.loc[i,'females'] = len(rd[e][rd[e]['sex'] == 'F'])
rs.loc[i,'rus'] = len(rd[e][rd[e]['country'] == 'RUS'])
len(rs[rs['total'] != rs['total raw']])
Out: 288
len(rs[rs['males'] != rs['males raw']])
Out:962
len(rs[rs['females'] != rs['females raw']])
Out: 836
len(rs[rs['rus'] != rs['rus raw']])
Out: 8
pkl.dump(rs, open(r'D:\tri\summary6.pkl', 'wb'))
第4部分。采样
现在铁人三项很受欢迎。在本赛季中,有许多公开比赛,大量运动员(主要是业余运动员)参加。但这并非总是如此。自1990年以来,我们的数据中就有记录。滚动浏览tristats.ru,我注意到近年来有很多比赛,而在前几场比赛中很少。但是,既然我们的数据已经准备好了,您可以更仔细地查看它。十年期间
计算每年的比赛和完成者数量:rs['year'] = pd.DatetimeIndex(rs['date']).year
years = range(rs['year'].min(),rs['year'].max())
rsy = pd.DataFrame(columns = ['races', 'finishers', 'rus', 'RUS'], index = years)
for y in rsy.index:
rsy.loc[y,'races'] = len(rs[rs['year'] == y])
rsy.loc[y,'finishers'] = sum(rs[rs['year'] == y]['total'])
rsy.loc[y,'rus'] = sum(rs[rs['year'] == y]['rus'])
rsy.loc[y,'RUS'] = len(rs[(rs['year'] == y)&(rs['country'] == 'RUS')])
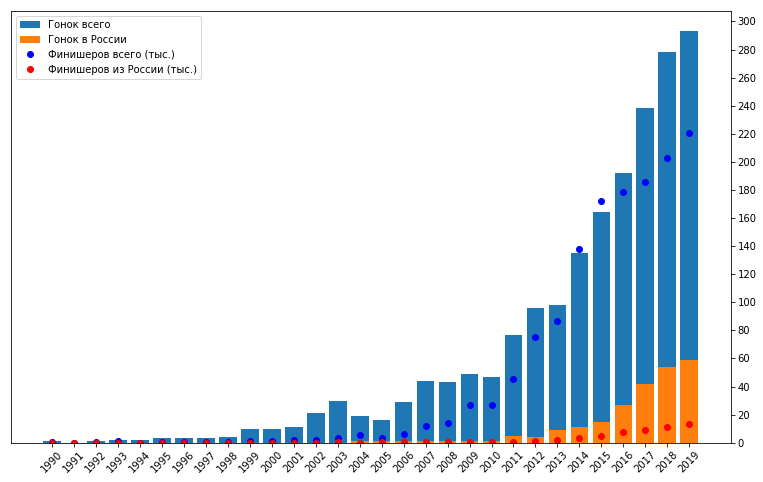 可以看出,在该时期开始和结束时的种族和参与者的数量简直是无法估量的。从2011年开始,比赛的总数大幅度增加,而俄罗斯的起跑次数也有所增加。此外,可以回溯到2009年,参与者人数有所增加。这可能表明参与者之间的兴趣增加,即需求增加,此后两年后供应增加,即启动次数。但是,请不要忘记数据可能不完整,有些甚至可能缺少许多比赛。包括由于收集数据的项目仅在2010年才开始的事实,这也可以解释此时此图的重大飞跃。因此,为了进一步分析,我决定选择过去的十年。这是一个相当长的时期,为了跟踪几年中的任何趋势,而又短到无法到达那里,主要是90年代和2000年代初期的专业比赛。
可以看出,在该时期开始和结束时的种族和参与者的数量简直是无法估量的。从2011年开始,比赛的总数大幅度增加,而俄罗斯的起跑次数也有所增加。此外,可以回溯到2009年,参与者人数有所增加。这可能表明参与者之间的兴趣增加,即需求增加,此后两年后供应增加,即启动次数。但是,请不要忘记数据可能不完整,有些甚至可能缺少许多比赛。包括由于收集数据的项目仅在2010年才开始的事实,这也可以解释此时此图的重大飞跃。因此,为了进一步分析,我决定选择过去的十年。这是一个相当长的时期,为了跟踪几年中的任何趋势,而又短到无法到达那里,主要是90年代和2000年代初期的专业比赛。rs = rs[(rs['year']>=2010)&(rs['year']<= 2019)]
 顺便说一句,在选定的时期内,有84%的比赛和94%的完成者摔倒了。
顺便说一句,在选定的时期内,有84%的比赛和94%的完成者摔倒了。业余开始
因此,选定起点的绝大多数参与者是业余运动员,因此可以从他们那里获得良好的统计数据。老实说,这是我的主要兴趣所在,因为我本人也参加了这样的比赛,但从水平上说,它离奥运会冠军很远。但是,在选定的时期内显然也进行了专业比赛。为了不混淆业余和职业比赛的指标,决定将后者从考虑中删除。如何识别它们?通过速度。我们计算它们。在数据准备的初始阶段之一,我们已经确定了每场比赛的距离类型是:冲刺,奥运,半铁,铁杆。对于每个阶段,都明确定义了各个阶段的里程数-游泳,骑自行车和跑步。短跑的分数是0.75 + 20 + 5,奥运会的分数是1.5 + 40 + 10,半决赛的分数是1.9 + 90 + 21.1。铁为8 + 180 + 42.2。当然,实际上,对于任何类型,实际数字都可能因种族而异,有条件地变化到百分之一,但是没有有关此的信息,因此我们将假定一切都是准确的。rs['km'] = ''
rs.loc[rs['dist'] == 'sprint', 'km'] = 0.75+20+5
rs.loc[rs['dist'] == 'olympic', 'km'] = 1.5+40+10
rs.loc[rs['dist'] == 'half', 'km'] = 1.9+90+21.1
rs.loc[rs['dist'] == 'full', 'km'] = 3.8+180+42.2
我们计算每场比赛的平均速度和最大速度。此处的最大值是指获得第一名的运动员的平均速度。for index, row in rs.iterrows():
e = row['event']
rd[e]['th'] = pd.TimedeltaIndex(rd[e]['result']).seconds/3600
rd[e]['v'] = rs.loc[i, 'km'] / rd[e]['th']
for index, row in rs.iterrows():
e = row['event']
rs.loc[index,'vmax'] = rd[e]['v'].max()
rs.loc[index,'vavg'] = rd[e]['v'].mean()
 好了,您可以看到大部分速度聚集在大约15 km / h和30 km / h之间的堆中,但是有一定数量的完全“宇宙”值。按平均速度排序,看看有多少:
好了,您可以看到大部分速度聚集在大约15 km / h和30 km / h之间的堆中,但是有一定数量的完全“宇宙”值。按平均速度排序,看看有多少:rs = rs.sort_values(by='vavg')
 在这里,我们更改了比例,可以更准确地估计范围。平均速度约为17 km / h至27 km / h,最大速度为18 km / h至32 km / h。另外,有些“尾巴”的平均速度非常低,非常高。低速很可能对应于Norseman之类的极限比赛,在取消游泳的情况下可能出现高速,在这种情况下,不是冲刺,而是超级冲刺,或者只是错误的数据。另一个要点是沿X轴在1200区域内的平滑台阶以及更高的平均速度值。在那里,您可以看到平均速度和最大速度之间的差异远小于图表的前三分之二。显然,这是一场职业比赛。为了更清楚地区分它们,我们计算了最大速度与平均值的比率。在专业比赛中,没有随机的人,并且所有参与者的身体素质都很高,因此该比例应该很小。
在这里,我们更改了比例,可以更准确地估计范围。平均速度约为17 km / h至27 km / h,最大速度为18 km / h至32 km / h。另外,有些“尾巴”的平均速度非常低,非常高。低速很可能对应于Norseman之类的极限比赛,在取消游泳的情况下可能出现高速,在这种情况下,不是冲刺,而是超级冲刺,或者只是错误的数据。另一个要点是沿X轴在1200区域内的平滑台阶以及更高的平均速度值。在那里,您可以看到平均速度和最大速度之间的差异远小于图表的前三分之二。显然,这是一场职业比赛。为了更清楚地区分它们,我们计算了最大速度与平均值的比率。在专业比赛中,没有随机的人,并且所有参与者的身体素质都很高,因此该比例应该很小。rs['vmdbva'] = rs['vmax']/rs['vavg']
rs = rs.sort_values(by='vmdbva')
 在此图表上,第一季度非常明显:最大速度与平均比率之比很小,平均速度较高,参与者人数很少。这是一场专业比赛。绿色曲线上的台阶大约为1.2。在样本中,我们将仅保留比率值大于1.2的记录。
在此图表上,第一季度非常明显:最大速度与平均比率之比很小,平均速度较高,参与者人数很少。这是一场专业比赛。绿色曲线上的台阶大约为1.2。在样本中,我们将仅保留比率值大于1.2的记录。rs = rs[rs['vmdbva'] > 1.2]
我们还会删除非典型的低速和高速记录。在什么是铁人三项“世界纪录”为每个距离?发布了2019年通过不同距离的记录时间。如果以中等速度计算它们,那么即使最快,也不能超过33 km / h。因此,我们将考虑平均速度较高,无效的协议,并将其从考虑中删除。rs = rs[(rs['vavg'] > 17)&(rs['vmax'] < 33)]
剩下的就是:
 现在,一切看起来都很相似,并且没有引发任何问题。所有这些选择的结果是,我们丢失了1922年协议中的777个,即40%。同时,整理机的总数没有减少太多-仅减少了13%。因此,剩下1,145场比赛还有1,231,772名完成者。该样本成为我进行分析和可视化的素材。
现在,一切看起来都很相似,并且没有引发任何问题。所有这些选择的结果是,我们丢失了1922年协议中的777个,即40%。同时,整理机的总数没有减少太多-仅减少了13%。因此,剩下1,145场比赛还有1,231,772名完成者。该样本成为我进行分析和可视化的素材。第5部分。分析和可视化
在这项工作中,适当的分析和可视化是最简单的部分。冰山一角,其水下部分只是数据的准备。实际上,该分析是对pandas Series的简单算术运算,计算平均值,进行过滤-所有这些操作都是由基本的pandas工具完成的,并且上面的代码包含了示例。反过来,可视化主要是使用最标准的matplotlib完成的。二手情节,酒吧,馅饼。但是,在某些地方,在日期和象形图的情况下,我不得不修改轴的签名,但这并不是在此处进行详细描述的内容。唯一值得一提的是地理数据的表示。至少不是matplotlib。地理数据
对于每场比赛,我们都有关于场地的信息。从一开始,我们就使用geopy来计算每个位置的坐标。每年在同一地点举行许多比赛。folium是
用于在python中渲染地理数据的非常方便的工具。运作方式如下:import folium
m = folium.Map()
folium.Marker(['55.7522200', '37.6155600'], popup='').add_to(m)
而且我们可以在Jupiter笔记本电脑中获得交互式地图。 现在,到我们的数据。首先,我们将从坐标的组合开始一个新列:
现在,到我们的数据。首先,我们将从坐标的组合开始一个新列:rs['coords'] = rs['latitude'].astype(str) + ', ' + rs['longitude'].astype(str)
独特的坐标,COORDS是291.而独特的位置LOC是324,这意味着一些名字稍微有些不同,而在同一时间,他们对应的相同点。这并不可怕,我们将通过协调来考虑唯一性。我们计算每个位置(具有唯一坐标)在整个时间内经过了多少个事件:vc = rs['coords'].value_counts()
vc
Out:
43.7009358, 7.2683912 22
43.5854823, 39.723109 20
29.03970805, -13.636291 16
47.3723941, 8.5423328 16
59.3110918, 24.420907 15
51.0834196, 10.4234469 15
54.7585694, 38.8818137 14
20.4317585, -86.9202745 13
52.3727598, 4.8936041 12
41.6132925, 2.6576102 12
... ...
现在创建一个地图,并以圆圈的形式在其上添加标记,其半径将取决于该地点举行的活动的数量。将带有位置名称的标记添加到标记中。m = folium.Map(location=[25,10], zoom_start=2)
for c in rs['coords'].unique():
row = [r[1] for r in rs.iterrows() if r[1]['coords'] == c][0]
folium.Circle([row['latitude'], row['longitude']],
popup=(row['location']+'\n('+str(vc[c])+' races)'),
radius = 10000*int(vc[c]),
color='darkorange',
fill=True,
stroke=True,
weight=1).add_to(m)
做完了 您可以看到结果:
参加者进度
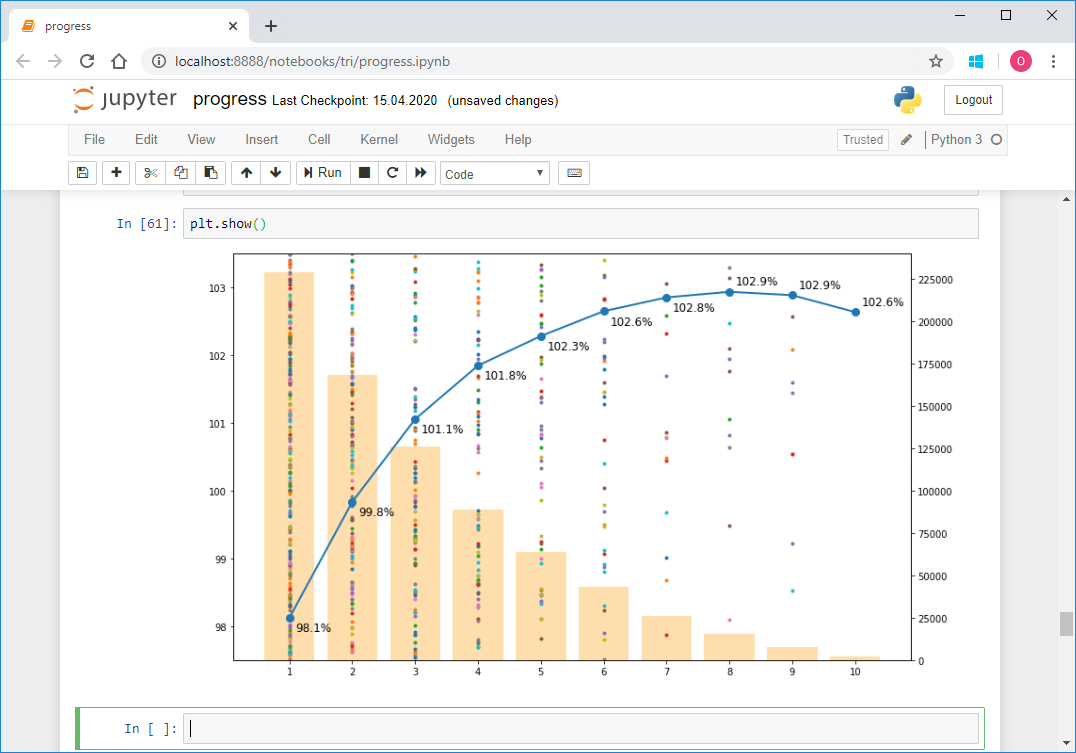
实际上,除了指导之外,按照另一个时间表进行工作也是不容易的。这是参与者的最新进度图。它是这样的: 让我们对其进行分析,同时我将给出渲染代码,作为使用matplotlib的示例:
让我们对其进行分析,同时我将给出渲染代码,作为使用matplotlib的示例:fig = plt.figure()
fig.set_size_inches(10, 6)
ax = fig.add_axes([0,0,1,1])
b = ax.bar(exp,numrecs, color = 'navajowhite')
ax1 = ax.twinx()
for i in range(len(exp_samp)):
ax1.plot(exp_samp[i], vproc_samp[i], '.')
p, = ax1.plot(exp, vpm, 'o-',markersize=8, linewidth=2, color='C0')
for i in range(len(exp)):
if i < len(exp)-1 and (vpm[i] < vpm[i+1]):
ax1.text(x = exp[i]+0.1, y = vpm[i]-0.2, s = '{0:3.1f}%'.format(vpm[i]),size=12)
else:
ax1.text(x = exp[i]+0.1, y = vpm[i]+0.1, s = '{0:3.1f}%'.format(vpm[i]),size=12)
ax.legend((b,p), (' ', ''),loc='center right')
ax.set_xlabel(' ')
ax.set_ylabel('')
ax1.set_ylabel('% ')
ax.set_xticks(np.arange(1, 11, step=1))
ax.set_yticks(np.arange(0, 230000, step=25000))
ax1.set_ylim(97.5,103.5)
ax.yaxis.set_label_position("right")
ax.yaxis.tick_right()
ax1.yaxis.set_label_position("left")
ax1.yaxis.tick_left()
plt.show()
现在介绍如何为他计算数据。首先,您必须选择至少参加过两场比赛且在不同日历年中均完成比赛且并非专业人士的参与者的姓名。首先,对于每个协议,填写一个名为date的新列,该列将指示比赛的日期。从该日期起,我们还需要一年,因此我们将列设为year。由于我们要分析每个运动员相对于比赛中平均速度的速度,因此我们立即在新列vproc中计算该速度-该速度占平均速度的百分比。for index, row in rs.iterrows():
e = row['event']
rd[e]['date'] = row['date']
rd[e]['year'] = row['year']
rd[e]['vproc'] = 100 * rd[e]['v'] / rd[e]['v'].mean()
现在的协议如下所示:
接下来,将所有协议组合到一个数据帧中。' Sprint 2019'ar = pd.concat(rd)
对于每个参与者,我们在每个日历年仅保留一个条目:ar1 = ar.drop_duplicates(subset = ['name','year'], keep='first')
接下来,从这些条目的所有唯一名称中,我们发现至少出现两次的名称:nvc = ar1['name'].value_counts()
names = list(nvc[nvc > 1].index)
共有219,890个。让我们从此列表中删除职业运动员的名称:pro_names = ar[ar['group'].isin(['MPRO','FPRO'])]['name'].unique()
names = list(set(names) - set(pro_names))
以及2010年之前开始表演的运动员的名字。为此,请上载我们在过去十年中进行采样之前保存的数据。将它们放在rsa(所有竞赛摘要)和rda(所有竞赛详细信息)对象中。rdo = {}
for e in rda:
if rsa[rsa['event'] == e]['year'].iloc[0] < 2010:
rdo[e] = rda[e]
aro = pd.concat(rdo)
old_names = aro['name'].unique()
names = list(set(names) - set(old_names))
最后,我们发现同一天出现多次的名称。因此,我们将样本中全名的出现减到最少。namesakes = ar[ar.duplicated(subset = ['name','date'], keep = False)]['name'].unique()
names = list(set(names) - set(namesakes))
因此,还有198,075个名字。从整个数据集中,我们仅选择具有找到的名称的记录:ars = ar[ar['name'].isin(names)]
现在,对于每条记录,您需要确定运动员职业生涯中的哪一年-第一,第二,第三或第十年。我们用所有名称进行循环并计算。ars['exp'] = ''
for n in names:
ind = ars[ars['name'] == n].index
yos = ars.loc[ind, 'year'].min()
ars.loc[ind, 'exp'] = ars.loc[ind, 'year'] - yos + 1
这是发生的事的一个例子:
显然,同名仍然存在。这是预料之中的,但并不可怕,因为我们将平均所有东西,并且不应有那么多。接下来,我们为图构建数组:exp = []
vpm = []
numrecs = []
for x in range(ars['exp'].min(), ars['exp'].max() + 1):
exp.append(x)
vpm.append(ars[ars['exp'] == x]['vproc'].mean())
numrecs.append(len(ars[ars['exp'] == x]))
就是这样,有一个基础: 现在,要用与特定结果相对应的点来装饰它,我们将选择1000个随机名称并使用它们的结果构建数组。
现在,要用与特定结果相对应的点来装饰它,我们将选择1000个随机名称并使用它们的结果构建数组。names_samp = random.sample(names,1000)
ars_samp = ars[ars['name'].isin(names_samp)]
ars_samp = ars_samp.reset_index(drop = True)
exp_samp = []
vproc_samp = []
for n in names_samp:
nr = ars_samp[ars_samp['name'] == n]
nr = nr.sort_values('exp')
exp_samp.append(list(nr['exp']))
vproc_samp.append(list(nr['vproc']))
添加一个循环以从此随机样本构建图形。for i in range(len(exp_samp)):
ax1.plot(exp_samp[i], vproc_samp[i], '.')
现在一切就绪: 总体而言,这并不困难。但是有一个问题。要计算一个周期中的exp经验,几乎所有20万个名称都需要八个小时。我不得不在小样本上调试算法,然后在夜间进行计算。原则上,此操作只能执行一次,但是如果您发现某种错误或想要更改某些内容,而又需要重新计算,则会开始增加负担。因此,当我打算在晚上发布报告时,事实证明,再次需要重新叙述所有内容。等到早上不是我的计划的一部分,我开始寻找一种使计算更快的方法。决定并行化。找到某处通过多处理方法做到这一点的方法。为了在Windows上工作,我们需要将每个并行任务的主要逻辑放入单独的worker.py文件中:
总体而言,这并不困难。但是有一个问题。要计算一个周期中的exp经验,几乎所有20万个名称都需要八个小时。我不得不在小样本上调试算法,然后在夜间进行计算。原则上,此操作只能执行一次,但是如果您发现某种错误或想要更改某些内容,而又需要重新计算,则会开始增加负担。因此,当我打算在晚上发布报告时,事实证明,再次需要重新叙述所有内容。等到早上不是我的计划的一部分,我开始寻找一种使计算更快的方法。决定并行化。找到某处通过多处理方法做到这一点的方法。为了在Windows上工作,我们需要将每个并行任务的主要逻辑放入单独的worker.py文件中:import pickle as pkl
def worker(args):
names = args[0]
ars=args[1]
num=args[2]
ars = ars.sort_values(by='name')
ars = ars.reset_index(drop=True)
for n in names:
ind = ars[ars['name'] == n].index
yos = ars.loc[ind, 'year'].min()
ars.loc[ind, 'exp'] = ars.loc[ind, 'year'] - yos + 1
with open(r'D:\tri\par\prog' + str(num) + '.pkl', 'wb') as f:
pkl.dump(ars,f)
该过程被转移到的姓名的一部分的名称,部分datafreyma AR仅与这些名称,和并行任务的序列号- NUM。计算被写入数据帧,最后,数据帧被写入文件。在调用此worker的笔记本电脑中,我们相应地准备了参数:num_proc = 8
args = []
for i in range(num_proc):
step = int(len(names_samp)/num_proc) + 1
names_i = names_samp[i*step:min((i+1)*step, len(names_samp))]
ars_i = ars[ars['name'].isin(names_i)]
args.append([names_i, ars_i, i])
我们开始并行计算:from multiprocessing import Pool
import workers
if __name__ == '__main__':
p=Pool(processes = num_proc)
p.map(workers.worker,args)
最后,我们从文件中读取结果,并将片段收集回整个数据框中:ars=pd.DataFrame(columns = ars.columns)
for i in range(num_proc):
with open(r'D:\tri\par\prog'+str(i)+'.pkl', 'rb') as f:
arsi = pkl.load(f)
print(len(arsi))
ars = pd.concat([ars, arsi])
因此,有可能获得40倍的加速度,而不是8个小时,从而在11分钟内完成计算并在当晚发布报告。同时,我学习了如何在python中并行化,我认为它将派上用场。在这里,由于每个任务使用的数据帧较小,因此搜索速度甚至是内核数量的8倍以上,这使得搜索速度更快。原则上,可以以此方式加快顺序计算的速度,但是问题是,您如何猜测?但是,我无法平静下来,甚至在发布之后,我就一直在思考如何使用矢量化进行计算,即对“ 熊猫系列”数据框的整列进行操作。这样的计算比任何并行周期都快一个数量级,即使在超级集群上也是如此。并想出了。事实证明,为每个名字找到职业开始的年份,有必要相反-为每年找到从事这个职业的参与者。为此,您必须首先确定样本中第一年的所有名称,即2010年。因此,我们将在今年使用这些名称处理所有记录。接下来,我们考虑下一年-2011年。再次,我们找到了今年所有带有条目的名称,但我们仅从它们中提取了未经处理的名称,即2010年未满足且在2011年使用它们进行处理的名称。在下半年,依此类推。相同的循环,但没有二十万次迭代,但总共有九次。for y in range(ars['year'].min(),ars['year'].max()):
arsynp = ars[(ars['exp'] == '') & (ars['year'] == y)]
namesy = arsynp['name'].unique()
ind = ars[ars['name'].isin(namesy)].index
ars.loc[ind, 'exp'] = ars.loc[ind,'year'] - y + 1
这个周期仅需几秒钟即可完成。而且代码变得更加简洁。结论
好吧,最后,许多工作已经完成。对我而言,这实际上是同类项目中的第一个。当我学习它时,主要目标是练习使用python及其库。此任务远未完成。结果本身也很可观。完成后我会为自己得出什么结论?第一:数据不完善。几乎所有分析任务都可能如此。即使它们是完全结构化的,并且经常以不同的方式发生,您也需要在开始计算特征并搜索趋势之前准备好对它们进行修补-查找错误,离群值,偏离标准等。其次:任何任务都有解决方案。这更像是一个口号,但通常是这样。只是,这种解决方案可能并不那么明显,并且不在于数据本身,而是可以直接使用。例如,上述参与者名称的处理或网站抓取。第三:领域知识至关重要。这样就可以更好地准备数据,删除明显无效或非标准的数据,避免解释错误,使用数据中未包含的信息(例如本项目中的距离),以社区接受的形式展示结果,同时避免出现愚蠢的错误结论。第四:在python中工作有很多工具。有时似乎值得考虑一些事情,您开始搜索-它已经存在。太好了!非常感谢创建者的贡献,尤其是这里方便使用的工具:硒用于刮削,pycountry用于根据ISO标准确定国家/地区代码,国家/地区代码(datahub)用于奥林匹克代码,geopy用于确定地址处的坐标,大叶 -用于地理数据的可视化,性别猜测 -用于名称分析,多处理 -用于并行计算,matplotlib,numpy以及当然还有熊猫 -没有它就无处可走。第五:向量化是我们的一切。能够使用内置的熊猫工具非常重要,它非常有效。我想在大多数情况下,当测量记录的数量从成千上万起时,此技能就变得非常必要。第六:处理数据是一个坏主意。有必要尝试最小化任何手动干预-首先,它不会扩展,也就是说,当数据量增加几倍时,手动处理的时间将增加到不可接受的值,其次,可重复性很差-您会忘记一些东西,会在某个地方犯错。一切都只是程序性的,如果某些东西超出了软件解决方案的通用标准,那么,可以,您可以牺牲部分数据,仍然会有更多好处。第七:该代码必须保持工作状态。看来可能会更加明显!实际上,当涉及到供您自己使用的代码(目的是发布此代码的结果)时,此处的一切都不那么严格。我在Jupiter Notebooks工作,在我看来,这种环境不必创建集成的软件产品。它被配置为逐行,分段启动,这具有它的优点-快速:同时进行开发,调试和执行。但是通常的诱惑是只编辑一些行并快速获得新结果,而不是在def中复制或包装。当然,应该避免这种诱惑。人们应该努力争取好的代码,甚至是“为了自己”,至少是因为即使对于一项分析工作来说,启动也要进行多次,并且在开始时花时间肯定会在将来获得回报。您甚至可以在笔记本电脑上以检查关键参数和引发异常的形式添加测试-这非常有用。第八:多储蓄。在每个步骤中,我都保存了文件的新版本。总共大约为10。这很方便,因为当检测到错误时,它有助于快速确定发生在哪个阶段。另外,我将源数据保存在标记为raw的列中-这使您可以快速检查结果并查看差异。第九:有必要衡量时间和结果的投入。在某些地方,我花了很长时间还原数据,这些数据只占总数的百分之一。实际上,这没有任何意义,您只需要将它们扔掉即可,仅此而已。如果是商业项目,而不是自动培训,我会这样做。这将使您更快地获得结果。帕累托原理在这里起作用-20%的时间可以达到80%的结果。最后一个:这些项目的工作大大拓宽了视野。愿意,您会从拉丁文“ Confoederatio Helvetica”那里学到一些新的东西,例如皮特凯恩群岛等陌生国家的名称,例如瑞士的ISO代码是CHE,那么西班牙的名字实际上就是铁人三项本身的名字-记录,其所有者,比赛地点,事件历史记录等。也许足够了。就这样。感谢所有读完本书的人!