我们将继续朝着基于Redd FPGA复合体创建真实设备的方向发展。对于另一个全硬件项目,我需要一个简单的逻辑分析器,因此我们将朝着这个方向发展。幸运-进入USB总线分析仪(但是从长远来看,这仍然是可行的)。任何分析仪的核心都是RAM,它是先将数据上传到RAM然后再检索的单元。今天我们将设计它。为此,我们将控制DMA模块。通常,DMA是我最喜欢的主题。我什至在一些ARM控制器上写了一篇有关DMA的精彩文章。从那篇文章中可以明显看出,DMA从总线上获取时钟周期。在当前文章中,我们将考虑基于FPGA的处理器系统的运行情况。
硬件创作
我们开始创建硬件。为了了解DMA块与时钟周期有多少冲突,我们将需要在Avalon-MM总线(Avalon Memory-Mapped)上的高负载下进行准确的测量。我们已经发现,Altera JTAG至Avalon-MM桥无法提供高总线负载。因此,今天我们必须在系统中添加一个处理器内核,以便它可以高速访问总线。如何做到这一点已经说明这里。为了达到最佳效果,让我们为处理器核心禁用两个缓存,但是创建一个强连接的总线,如此处所示。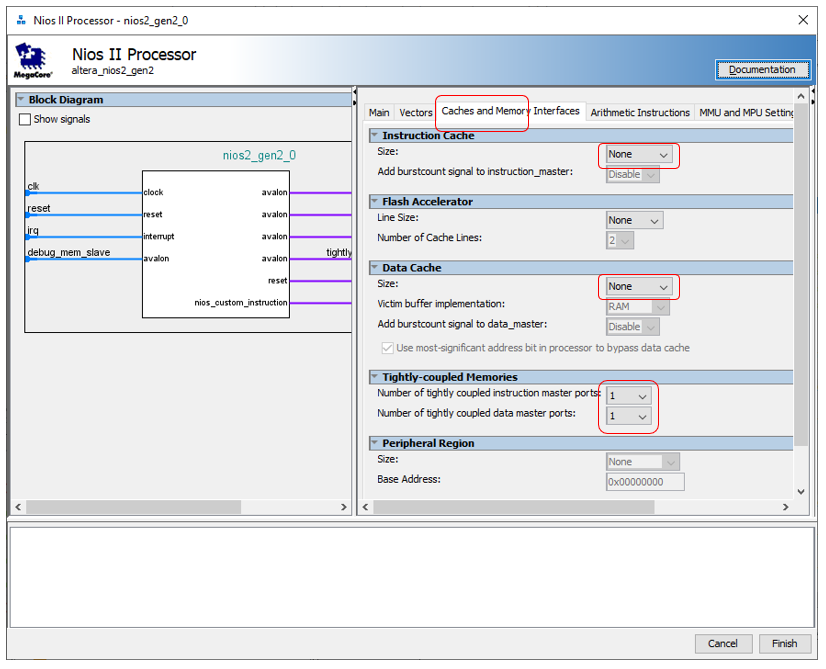 添加8 KB的程序存储器和数据存储器。请记住,内存必须是双端口的,并且地址必须在特定范围内(为防止其跳转,锁定,我们在这里讨论了其原因)。
添加8 KB的程序存储器和数据存储器。请记住,内存必须是双端口的,并且地址必须在特定范围内(为防止其跳转,锁定,我们在这里讨论了其原因)。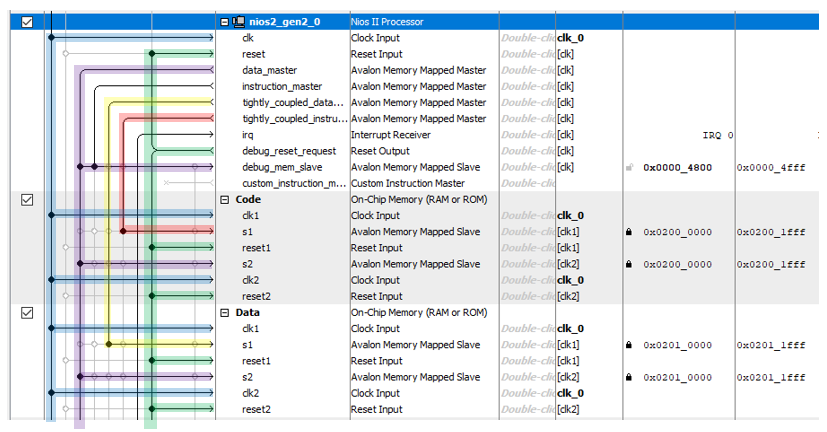 我们已经创建了该项目一千次,因此在创建过程中没有什么特别有趣的(如果有的话,这里描述了创建项目的所有步骤)。基地准备好了。现在,我们需要一个数据源,将其放入内存中。理想的事情是一个不断计时的计时器。如果在某种程度上DMA块无法处理数据,那么我们将立即通过丢失的值看到它。好吧,也就是说,如果内存中有值1234和1236,则意味着在时钟上,当计时器发出1235时,DMA块没有传输数据。建立档案Timer_ST.sv具有以下简单计数器:
我们已经创建了该项目一千次,因此在创建过程中没有什么特别有趣的(如果有的话,这里描述了创建项目的所有步骤)。基地准备好了。现在,我们需要一个数据源,将其放入内存中。理想的事情是一个不断计时的计时器。如果在某种程度上DMA块无法处理数据,那么我们将立即通过丢失的值看到它。好吧,也就是说,如果内存中有值1234和1236,则意味着在时钟上,当计时器发出1235时,DMA块没有传输数据。建立档案Timer_ST.sv具有以下简单计数器:module Timer_ST (
input clk,
input reset,
input logic source_ready,
output logic source_valid,
output logic[31:0] source_data
);
logic [31:0] counter;
always @ (posedge clk, posedge reset)
if (reset == 1)
begin
counter <= 0;
end else
begin
counter <= counter + 1;
end
assign source_valid = 1;
assign source_data [31:24] = counter [7:0];
assign source_data [23:16] = counter [15:8];
assign source_data [15:8] = counter [23:16];
assign source_data [7:0] = counter [31:24];
endmodule
这个计数器就像一个先驱:它总是准备就绪(在输出source_valid始终为1),并且始终计数(复位状态时刻除外)。为什么模块恰好具有这些信号-我们在本文中进行了讨论。现在,我们创建自己的组件(此处描述了如何完成)。自动化为我们错误地选择了Avalon_MM总线。替换为avalon_streaming_source并映射信号,如下所示: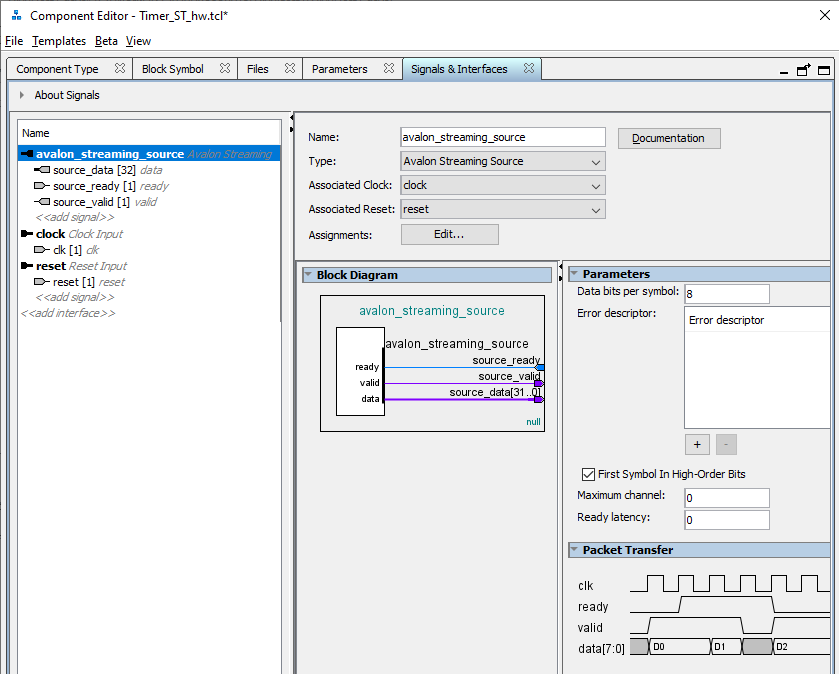 好极了。将我们的组件添加到系统中。现在我们正在寻找DMA块...我们发现不是一个,而是三个。所有这些都在Altera 的文档《嵌入式外围设备IP用户指南》中进行了描述(与往常一样,我给出名称,但没有给出链接,因为链接总是会变化)。
好极了。将我们的组件添加到系统中。现在我们正在寻找DMA块...我们发现不是一个,而是三个。所有这些都在Altera 的文档《嵌入式外围设备IP用户指南》中进行了描述(与往常一样,我给出名称,但没有给出链接,因为链接总是会变化)。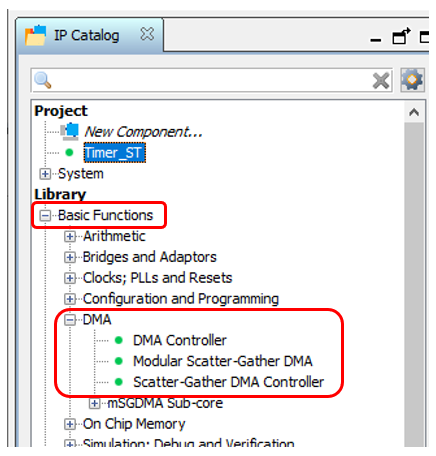 使用哪一个?我无法抗拒怀旧之情。早在2012年,我就建立了一个基于PCIe总线的系统。 Altera的所有手册均包含基于这些模块中第一个模块的示例。但是他使用PCIe组件的速度不超过每秒4兆字节。在那些日子里,我吐口水并写了我的DMA块。现在我不记得他的速度了,但是他将SATA驱动器中的数据驱动到了当时驱动器和SSD的能力极限。也就是说,我已经在此块上磨了一下牙。但是,我不会对这三个方面进行比较。事实上,今天我们必须使用基于Avalon-ST(Avalon流接口)的源,并且只有Modular Scatter-Gather DMA块支持此类源。在这里,我们将其放在图表上。在块设置中,选择模式流到内存映射。另外-我想从启动到填充SDRAM来驱动数据,因此我将最大数据传输单位从1 KB替换为4 MB。没错,我被警告说,最后,FMax参数不会太热(即使您将最大块替换为2 KB)。但是对于今天,FMax是可以接受的(104 MHz),然后我们将其找出来。我保持其余参数不变。您还可以将传输模式设置为“仅全字访问”,这会将FMax增大到109 MHz。但是我们今天不会为性能而战。
使用哪一个?我无法抗拒怀旧之情。早在2012年,我就建立了一个基于PCIe总线的系统。 Altera的所有手册均包含基于这些模块中第一个模块的示例。但是他使用PCIe组件的速度不超过每秒4兆字节。在那些日子里,我吐口水并写了我的DMA块。现在我不记得他的速度了,但是他将SATA驱动器中的数据驱动到了当时驱动器和SSD的能力极限。也就是说,我已经在此块上磨了一下牙。但是,我不会对这三个方面进行比较。事实上,今天我们必须使用基于Avalon-ST(Avalon流接口)的源,并且只有Modular Scatter-Gather DMA块支持此类源。在这里,我们将其放在图表上。在块设置中,选择模式流到内存映射。另外-我想从启动到填充SDRAM来驱动数据,因此我将最大数据传输单位从1 KB替换为4 MB。没错,我被警告说,最后,FMax参数不会太热(即使您将最大块替换为2 KB)。但是对于今天,FMax是可以接受的(104 MHz),然后我们将其找出来。我保持其余参数不变。您还可以将传输模式设置为“仅全字访问”,这会将FMax增大到109 MHz。但是我们今天不会为性能而战。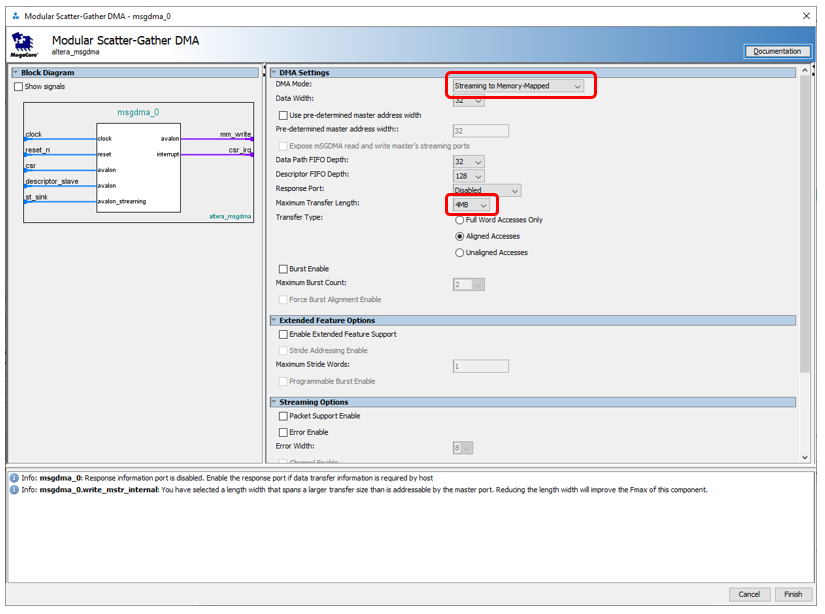 所以。源是DMA。接收器... SDRAM?在未来的战斗条件下,是的。但是今天,我们需要具有已知特征的记忆。不幸的是,SDRAM需要定期发送占用几个时钟周期的命令,而且此内存可能会被重新占用。因此,我们现在将使用内置的FPGA存储器代替它。一切都一步一步为她工作,没有不可预测的延迟。由于SDRAM控制器是单端口的,因此内置存储器也可以专门用于单端口模式。这很重要。事实是,我们要使用DMA块主控器写入存储器,但另一方面,我们要使用处理器内核或Altera JTAG-to-Avalon-MM块从该存储器读取。手伸出来,将读写块连接到两个不同的端口上……但是你做不到!相反,问题的条件禁止这样做。因为今天是可能的,但明天我们将用专用的单端口内存代替它。通常,我们得到这样一个由三个部分组成的块(计时器,DMA和内存):
所以。源是DMA。接收器... SDRAM?在未来的战斗条件下,是的。但是今天,我们需要具有已知特征的记忆。不幸的是,SDRAM需要定期发送占用几个时钟周期的命令,而且此内存可能会被重新占用。因此,我们现在将使用内置的FPGA存储器代替它。一切都一步一步为她工作,没有不可预测的延迟。由于SDRAM控制器是单端口的,因此内置存储器也可以专门用于单端口模式。这很重要。事实是,我们要使用DMA块主控器写入存储器,但另一方面,我们要使用处理器内核或Altera JTAG-to-Avalon-MM块从该存储器读取。手伸出来,将读写块连接到两个不同的端口上……但是你做不到!相反,问题的条件禁止这样做。因为今天是可能的,但明天我们将用专用的单端口内存代替它。通常,我们得到这样一个由三个部分组成的块(计时器,DMA和内存): 好吧,纯粹出于形式上的考虑,我将UT和sysid添加到JTAG系统中(尽管第二个系统没有帮助,无论如何我仍然不得不使用JTAG适配器)。这是什么,以及它们的添加如何解决小问题,我们已经进行了研究。我不会给轮胎上色,轮胎一切都很好。只需展示一下项目中的外观即可:
好吧,纯粹出于形式上的考虑,我将UT和sysid添加到JTAG系统中(尽管第二个系统没有帮助,无论如何我仍然不得不使用JTAG适配器)。这是什么,以及它们的添加如何解决小问题,我们已经进行了研究。我不会给轮胎上色,轮胎一切都很好。只需展示一下项目中的外观即可: 就是这样。系统准备就绪。我们分配地址,分配处理器向量,生成系统(不要忘记您需要使用与项目本身相同的名称进行保存,然后它将进入层次结构的顶层),将其添加到项目中。使重置支脚虚拟,将clk连接到pin_25支脚。我们正在组装该项目,将其倒入设备中……由于总的偏僻位置,在空荡荡的办公室里,这是多么可怜的事情?..对她来说,这很孤独又令人恐惧,也许是一个...但是我分心了。
就是这样。系统准备就绪。我们分配地址,分配处理器向量,生成系统(不要忘记您需要使用与项目本身相同的名称进行保存,然后它将进入层次结构的顶层),将其添加到项目中。使重置支脚虚拟,将clk连接到pin_25支脚。我们正在组装该项目,将其倒入设备中……由于总的偏僻位置,在空荡荡的办公室里,这是多么可怜的事情?..对她来说,这很孤独又令人恐惧,也许是一个...但是我分心了。创建软件零件
训练
在BSP编辑器中,随着手的通常动作,我打开了C ++支持。我经常插入这种情况的屏幕截图,以至于我停止这样做。但是,尽管已经看到了另一个屏幕截图,但仍然如此普遍。因此,让我们再讨论一次。我们记得系统正在尝试将数据放入最大的内存中。这就是Buffer。因此,我们将所有内容强制为Data: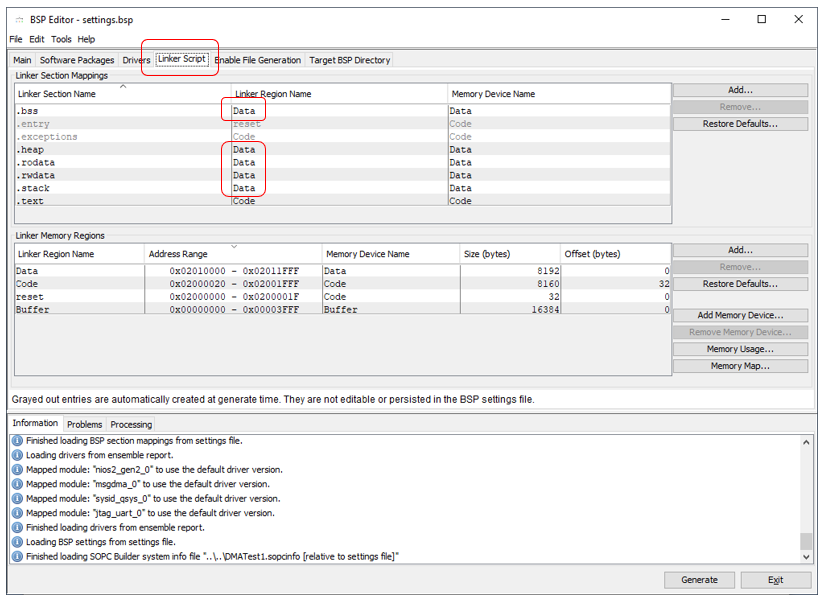
程序实验
我们编写的代码只是用源的内容填充内存(以计数器的角色)。查看代码#include "sys/alt_stdio.h"
#include <altera_msgdma.h>
#include <altera_msgdma_descriptor_regs.h>
#include <system.h>
#include <string.h>
int main()
{
alt_putstr("Hello from Nios II!\n");
memset (BUFFER_BASE,0,BUFFER_SIZE_VALUE);
// ,
IOWR_ALTERA_MSGDMA_CSR_CONTROL(MSGDMA_0_CSR_BASE,
ALTERA_MSGDMA_CSR_STOP_DESCRIPTORS_MASK);
// , ,
// , . .
// FIFO
IOWR_ALTERA_MSGDMA_DESCRIPTOR_READ_ADDRESS(MSGDMA_0_DESCRIPTOR_SLAVE_BASE,
(alt_u32)0);
IOWR_ALTERA_MSGDMA_DESCRIPTOR_WRITE_ADDRESS(MSGDMA_0_DESCRIPTOR_SLAVE_BASE,
(alt_u32)BUFFER_BASE);
IOWR_ALTERA_MSGDMA_DESCRIPTOR_LENGTH(MSGDMA_0_DESCRIPTOR_SLAVE_BASE,
BUFFER_SIZE_VALUE);
IOWR_ALTERA_MSGDMA_DESCRIPTOR_CONTROL_STANDARD(MSGDMA_0_DESCRIPTOR_SLAVE_BASE,
ALTERA_MSGDMA_DESCRIPTOR_CONTROL_GO_MASK);
// ,
IOWR_ALTERA_MSGDMA_CSR_CONTROL(MSGDMA_0_CSR_BASE,
ALTERA_MSGDMA_CSR_STOP_ON_ERROR_MASK
& (~ALTERA_MSGDMA_CSR_STOP_DESCRIPTORS_MASK)
&(~ALTERA_MSGDMA_CSR_GLOBAL_INTERRUPT_MASK)) ;
//
static const alt_u32 errMask = ALTERA_MSGDMA_CSR_STOPPED_ON_ERROR_MASK |
ALTERA_MSGDMA_CSR_STOPPED_ON_EARLY_TERMINATION_MASK |
ALTERA_MSGDMA_CSR_STOP_STATE_MASK |
ALTERA_MSGDMA_CSR_RESET_STATE_MASK;
volatile alt_u32 status;
do
{
status = IORD_ALTERA_MSGDMA_CSR_STATUS(MSGDMA_0_CSR_BASE);
} while (!(status & errMask) &&(status & ALTERA_MSGDMA_CSR_BUSY_MASK));
alt_putstr("You can play with memory!\n");
/* Event loop never exits. */
while (1);
return 0;
}
我们开始,我们等待消息“您可以玩记忆!”,将程序置于暂停状态,并从地址0开始查看内存。起初,我很害怕: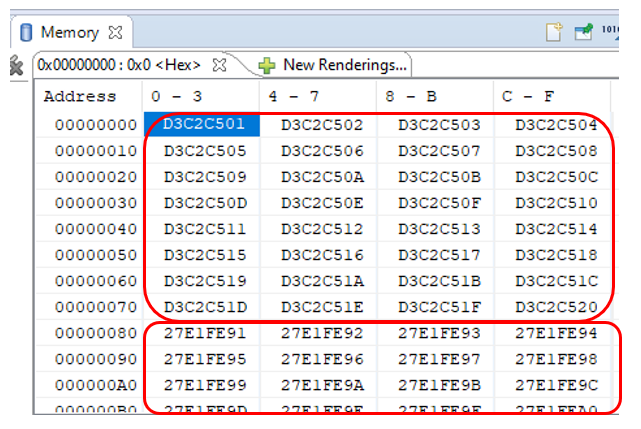 从地址0x80开始,计数器急剧改变其值。而且,数量非常大。但是事实证明一切都很好。在我们这里,计数器永不停止且始终处于就绪状态,并且DMA具有自己的预读队列。让我提醒您DMA块的设置:
从地址0x80开始,计数器急剧改变其值。而且,数量非常大。但是事实证明一切都很好。在我们这里,计数器永不停止且始终处于就绪状态,并且DMA具有自己的预读队列。让我提醒您DMA块的设置: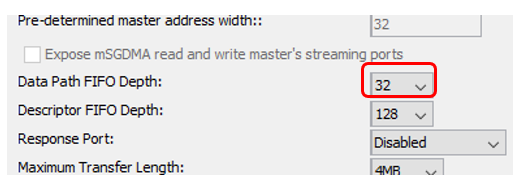 0x80字节是0x20的32位字。仅32位小数。都适合。在调试条件下,这并不可怕。在战斗条件下,源将更正确地工作(其准备状态将被重置)。因此,我们只是忽略此部分。在其他区域,仪表按顺序计数。我将仅显示转储片段的宽度。用我完整检查过的一个词。
0x80字节是0x20的32位字。仅32位小数。都适合。在调试条件下,这并不可怕。在战斗条件下,源将更正确地工作(其准备状态将被重置)。因此,我们只是忽略此部分。在其他区域,仪表按顺序计数。我将仅显示转储片段的宽度。用我完整检查过的一个词。 我不相信自己的眼睛,而是编写了一个代码来自动检查数据:
我不相信自己的眼睛,而是编写了一个代码来自动检查数据: volatile alt_u32* pData = (alt_u32*)BUFFER_BASE;
volatile alt_u32 cur = pData[0x10];
int nLine = 0;
for (volatile int i=0x11;i<BUFFER_SIZE_VALUE/4;i++)
{
if (pData[i]!=cur+1)
{
alt_printf("Problem at 0x%x\n",i*4);
if (nLine++ > 10)
{
break;
}
}
cur = pData[i];
}
他也没有透露任何问题。试图发现至少一些问题
实际上,没有问题并不总是一件好事。作为文章的一部分,我需要找到问题,然后说明如何解决这些问题。毕竟,问题很明显。繁忙的总线无法立即传递数据!应该有延迟!但是,让我们检查一下为什么一切如此美好。首先,可能会发现整个过程都在DMA块的FIFO中。将它们的大小减小到最小: 一切继续进行!好。确保我们引起对总线的访问数量大于FIFO维度。添加点击计数器:
一切继续进行!好。确保我们引起对总线的访问数量大于FIFO维度。添加点击计数器:
相同的文字: volatile alt_u32 status;
volatile int n = 0;
do
{
status = IORD_ALTERA_MSGDMA_CSR_STATUS(MSGDMA_0_CSR_BASE);
n += 1;
} while (!(status & errMask) &&(status & ALTERA_MSGDMA_CSR_BUSY_MASK));
工作结束时为29。大于16。也就是说,FIFO应该溢出。以防万一,让我们添加更多状态寄存器读数。没有帮助。悲痛的是,我断开了与远程Redd建筑群的连接,将项目重新定位到我现有的面包板上,现在可以用示波器连接到该板上(在办公室,没有人在远处,我无法到达示波器)。为计时器添加了两个端口: output clk_copy,
output ready_copy
并任命他们: assign clk_copy = clk;
assign ready_copy = source_ready;
结果,该模块开始如下所示:module Timer_ST (
input clk,
input reset,
input logic source_ready,
output logic source_valid,
output logic[31:0] source_data,
output clk_copy,
output ready_copy
);
logic [31:0] counter;
always @ (posedge clk, posedge reset)
if (reset == 1)
begin
counter <= 0;
end else
begin
counter <= counter + 1;
end
assign source_valid = 1;
assign source_data [31:24] = counter [7:0];
assign source_data [23:16] = counter [15:8];
assign source_data [15:8] = counter [23:16];
assign source_data [7:0] = counter [31:24];
assign clk_copy = clk;
assign ready_copy = source_ready;
endmodule
在家里,我有一个较小的带有水晶的手表,所以我不得不降低记忆力。结果发现我的原始程序无法放入4 KB的节中。因此,上一篇文章中提出的主题是,哦,它有多重要。系统中的内存-勉强够用!程序启动时,我们将立即准备 16个或17个小节。它由DMA模块的FIFO填充。一开始就让我感到害怕的相同效果。这些数据将构成非常错误的缓冲区填充。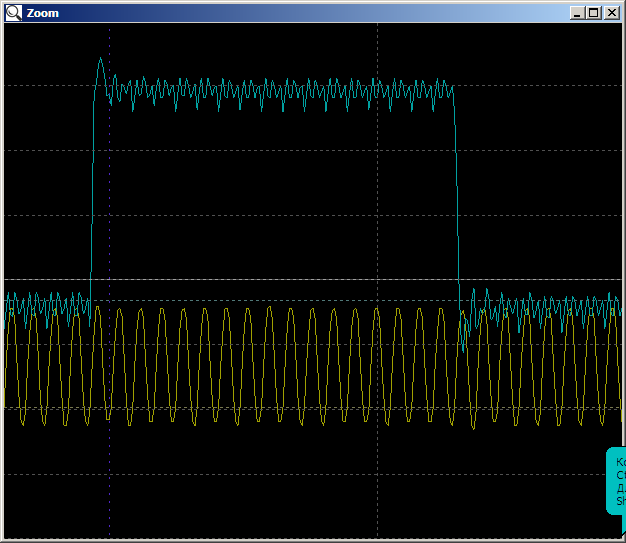 接下来,我们得到了40960纳秒的美丽画面,即2048个周期(对于家用晶体,缓冲区必须减小到8 KB,即2048个32位字)。这是它的开始:
接下来,我们得到了40960纳秒的美丽画面,即2048个周期(对于家用晶体,缓冲区必须减小到8 KB,即2048个32位字)。这是它的开始: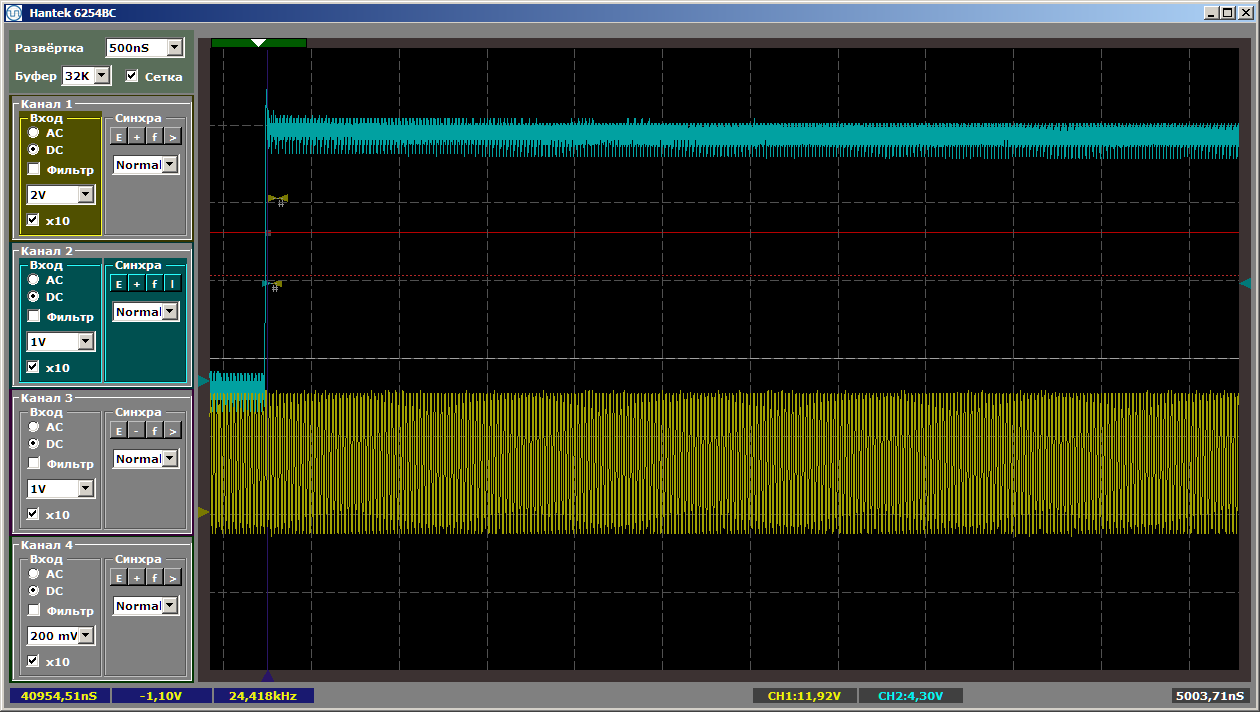 这是结尾:
这是结尾: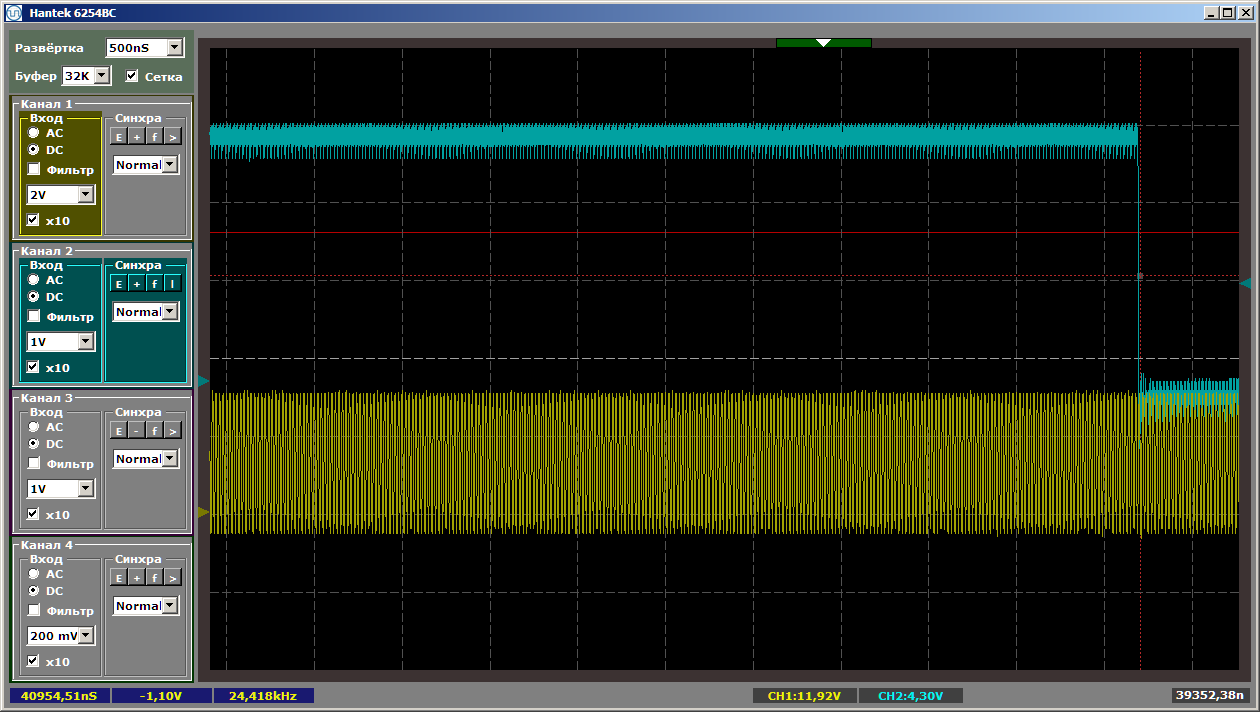 好吧,贯穿始终-没有一个失败。不,很明显这会发生,但是还是有希望的。。。也许我们应该尝试在总线上写,而不仅仅是从总线上读?我向系统添加了一个GPIO块:
好吧,贯穿始终-没有一个失败。不,很明显这会发生,但是还是有希望的。。。也许我们应该尝试在总线上写,而不仅仅是从总线上读?我向系统添加了一个GPIO块: 等待就绪时为其添加了一个条目:
等待就绪时为其添加了一个条目:
相同文字 volatile alt_u32 status;
volatile int n = 0;
do
{
status = IORD_ALTERA_MSGDMA_CSR_STATUS(MSGDMA_0_CSR_BASE);
IOWR_ALTERA_AVALON_PIO_DATA (PIO_0_BASE,0x01);
IOWR_ALTERA_AVALON_PIO_DATA (PIO_0_BASE,0x00);
n += 1;
} while (!(status & errMask) &&(status & ALTERA_MSGDMA_CSR_BUSY_MASK));
没有问题,就是这样!谁该怪?没有奇迹,但是有未开发的东西
谁该怪?带着悲痛,我开始研究Platform Designer工具的所有菜单,似乎找到了一个线索。轮胎通常看起来像什么?客户端连接到的一组电线。所以?好像是我们可以从编辑器中的图中看到这一点。只是,本文的第二个目标是展示如何将总线划分为两个独立的部分,每个部分的工作都不会相互干扰。但是,让我们看一下生成系统时出现的消息。突出显示关键字: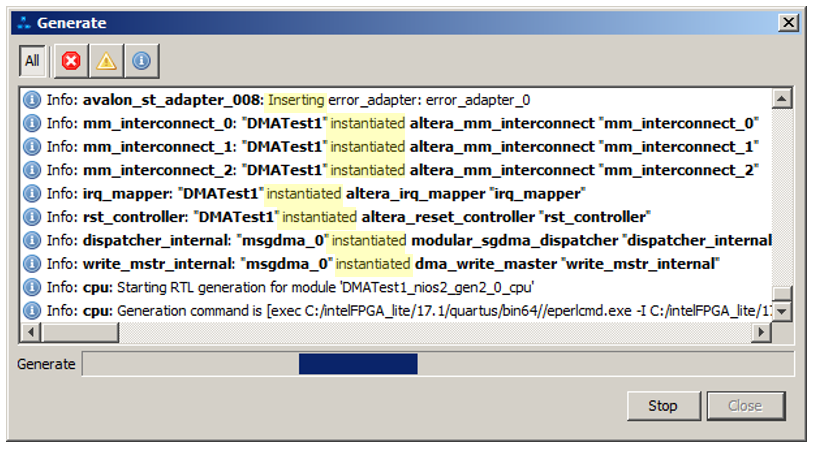 并且有很多类似的消息:它被添加,它被添加。事实证明,在用笔进行编辑后,系统还添加了许多其他内容。您如何看待所有可用的方案?我仍然在此游泳,但是通过选择以下菜单项,我们可以在本文的框架内获得最可能的答案:
并且有很多类似的消息:它被添加,它被添加。事实证明,在用笔进行编辑后,系统还添加了许多其他内容。您如何看待所有可用的方案?我仍然在此游泳,但是通过选择以下菜单项,我们可以在本文的框架内获得最可能的答案: 打开的画面本身令人印象深刻,但我不会给出。然后,
打开的画面本身令人印象深刻,但我不会给出。然后, 我将立即选择此选项卡:然后我们将看到以下内容:我将
我将立即选择此选项卡:然后我们将看到以下内容:我将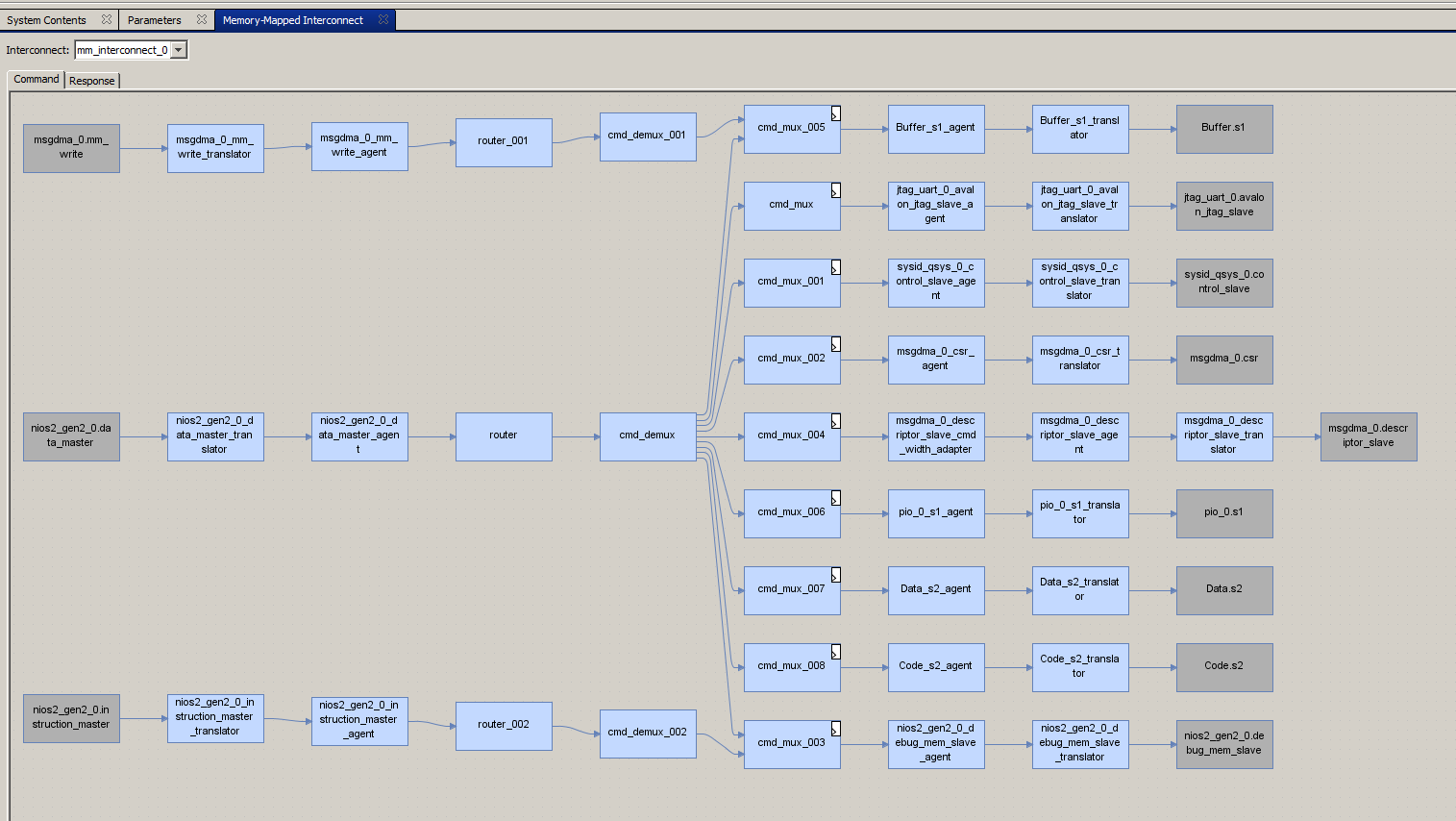 显示最重要的部分:
显示最重要的部分: 轮胎没有结合!他们被分割了!我无法辩解(也许专家会在评论中纠正我),但似乎系统已为我们插入了开关!这些开关创建了隔离的总线段,主系统可以与DMA单元并行工作,此时DMA单元可以无冲突地访问内存!
轮胎没有结合!他们被分割了!我无法辩解(也许专家会在评论中纠正我),但似乎系统已为我们插入了开关!这些开关创建了隔离的总线段,主系统可以与DMA单元并行工作,此时DMA单元可以无冲突地访问内存!我们惹出了真正的问题
掌握了所有这些知识后,我们得出结论,我们可以很好地引发问题。为了确保测试系统可以创建它们,这是必需的,这意味着开发环境确实可以独立解决它们。我们将不引用总线上的抽象设备,而是引用相同的缓冲存储器,以便cmd_mux_005块在处理器内核和DMA块之间分配总线。我们这样重写长时间受苦的等待函数: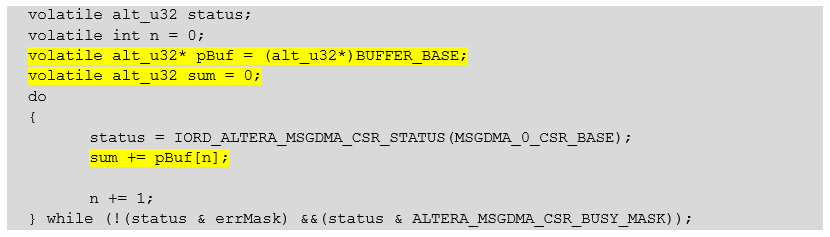
相同文字 volatile alt_u32 status;
volatile int n = 0;
volatile alt_u32* pBuf = (alt_u32*)BUFFER_BASE;
volatile alt_u32 sum = 0;
do
{
status = IORD_ALTERA_MSGDMA_CSR_STATUS(MSGDMA_0_CSR_BASE);
sum += pBuf[n];
n += 1;
} while (!(status & errMask) &&(status & ALTERA_MSGDMA_CSR_BUSY_MASK));
最后,波峰出现在波形上! 内存检查功能也发现了很多遗漏:
内存检查功能也发现了很多遗漏: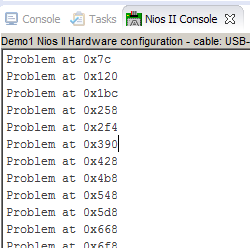 是的,我们很好地看到了数据在行与行之间的移动:
是的,我们很好地看到了数据在行与行之间的移动: 这是一个特定坏点的示例(缺少6CCE488F):
这是一个特定坏点的示例(缺少6CCE488F): 现在我们看到实验已正确完成,只是开发环境得以执行为我们优化。我不是用嘲讽而是怀着感激之情说出“全然伤害所有钢铁”的情况。感谢Quartus开发人员!
现在我们看到实验已正确完成,只是开发环境得以执行为我们优化。我不是用嘲讽而是怀着感激之情说出“全然伤害所有钢铁”的情况。感谢Quartus开发人员!结论
我们学习了如何在系统中插入DMA块以将流数据传输到内存。我们还确保在总线上下载其他设备的过程不会干扰下载过程。开发环境将自动创建一个与总线的其他部分并行运行的隔离段。当然,如果有人转向同一部分,则冲突和解决它们所花费的时间是不可避免的,但是程序员很可能会预见到这种情况。在下一篇文章中,我们将用SDRAM控制器替换RAM,并用真实的“ head”替换计时器,并制作第一个逻辑分析器。能行吗?我还不知道。我希望问题不会出现。