嗨,我叫Alexander Vasin,我是Edadil的后端开发人员。这种材料的想法始于我想将入门级作业(Ya.Disk)解析到Yandex 后端开发学校的事实。我开始描述某些技术选择和测试方法的所有细微差别……事实证明这根本不是分析,而是关于如何用Python编写后端的非常详细的指南。从最初的想法开始,仅对服务有要求,在此示例中可以方便地拆卸工具和技术。结果,我醒来了十万个字符。要仔细考虑所有细节,确实需要太多。因此,该程序适用于下一个100 KB:如何从选择工具到部署如何构建服务后端。 TL; DR:这是带有应用程序的GitHub代表和谁喜欢(真正的)长读-请在猫的陪伴下进行。我们将使用Python开发和测试REST API服务,将其包装在轻量级Docker容器中,并使用Ansible进行部署。
TL; DR:这是带有应用程序的GitHub代表和谁喜欢(真正的)长读-请在猫的陪伴下进行。我们将使用Python开发和测试REST API服务,将其包装在轻量级Docker容器中,并使用Ansible进行部署。您可以使用不同的工具以不同的方式实现REST API服务。所描述的解决方案不是唯一的解决方案,我根据个人经验和偏好选择了实现和工具。
我们做什么?
想象一下,一家在线礼品店计划在不同地区发起一项行动。为了使销售策略有效,需要进行市场分析。该商店有一个供应商,该供应商定期发送(例如,通过邮件)卸载有关居民信息的数据。让我们开发一个Python REST API服务,该服务将分析提供的数据并按月确定来自不同城市的不同年龄段居民的礼物需求。我们在服务中实现以下处理程序:POST /imports
添加带有数据的新上传;
GET /imports/$import_id/citizens
返回指定流量的居民;
PATCH /imports/$import_id/citizens/$citizen_id
在指定的卸载过程中更改有关居民(及其亲属)的信息;
GET /imports/$import_id/citizens/birthdays
, ( ), ;
GET /imports/$import_id/towns/stat/percentile/age
50-, 75- 99- ( ) .
?
因此,我们正在使用熟悉的框架,库和DBMS用Python编写服务。在视频课程的4个讲座中,描述了各种DBMS及其功能。在我的实现中,我选择了PostgreSQL DBMS ,它已建立了可靠的解决方案,并提供了出色的俄语文档,强大的俄语社区(您可以随时用俄语找到问题的答案),甚至免费课程。关系模型非常通用,并且被许多开发人员很好地理解。尽管可以在任何NoSQL DBMS上完成相同的操作,但是在本文中,我们将考虑PostgreSQL。该服务的主要目标-数据库和客户端之间通过网络进行的数据传输-并不意味着处理器上会有很大的负载,但是需要能够一次处理多个请求。在10个讲座中考虑了异步方法。它使您可以在同一OS进程中高效地为多个客户端提供服务(例如,与Flask / Django中使用的前叉模型不同,该模型创建了多个进程来处理来自用户的请求,每个进程都消耗内存,但是大部分时间是空闲的)因此,作为编写服务的库,我选择了异步aiohttp。视频课程
的第5讲讲述SQLAlchemy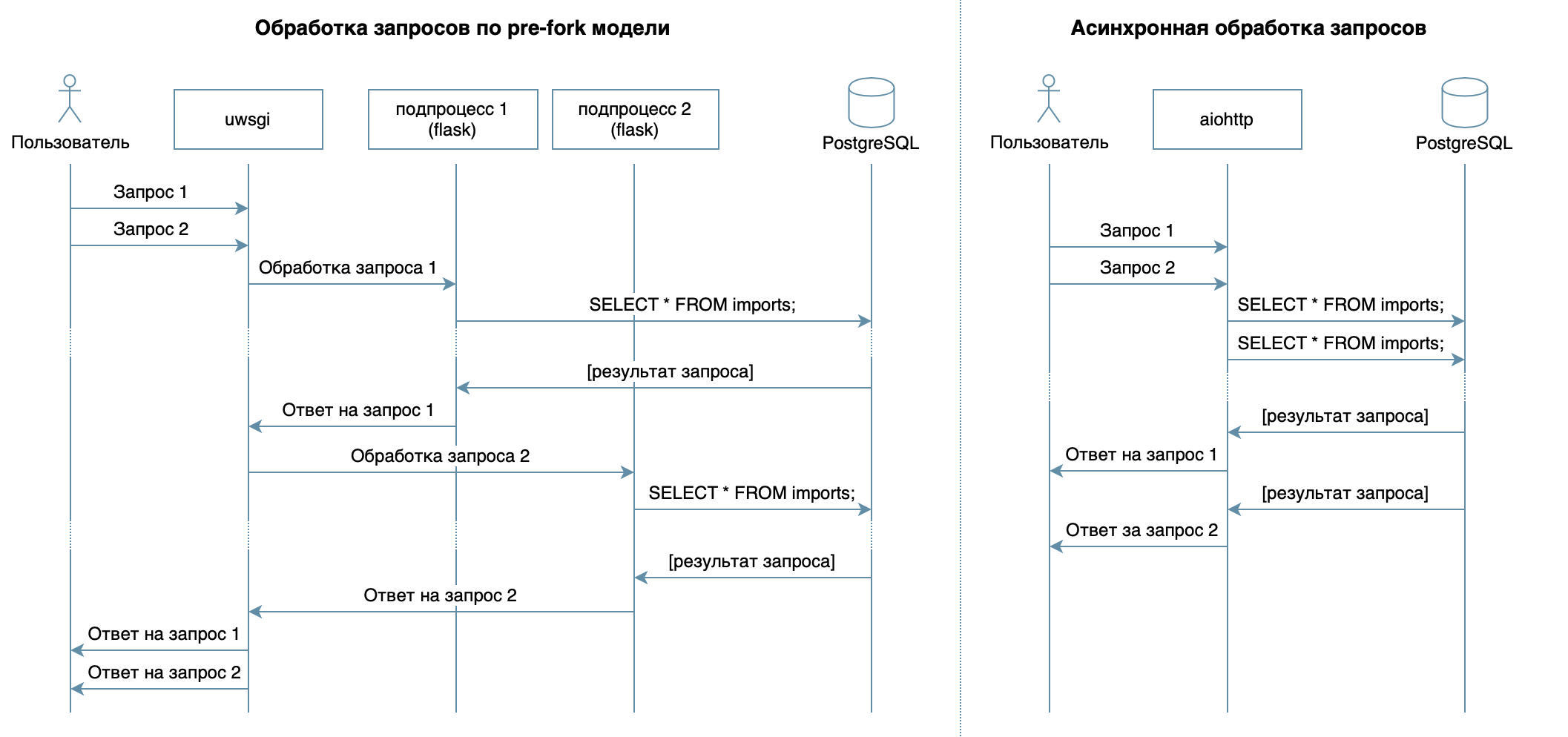 允许您将复杂的查询分解为多个部分,重复使用它们,使用动态字段集生成查询(例如,PATCH处理器允许使用任意字段进行部分驻留更新),并直接关注业务逻辑。asyncpg驱动程序可以处理这些请求并以最快的速度传输数据,而asyncpgsa将帮助他们结识朋友。我最喜欢的用于管理数据库状态和进行迁移的工具是Alembic。顺便说一下,我最近在Moscow Python中谈到了它。棉花糖计划简洁地描述了验证的逻辑(包括检查家庭纽带)。使用aiohttp-spec模块我链接了aiohttp处理程序和用于数据验证的方案,其好处是可以生成Swagger格式的文档并将其显示在图形界面中。为了编写测试,我
允许您将复杂的查询分解为多个部分,重复使用它们,使用动态字段集生成查询(例如,PATCH处理器允许使用任意字段进行部分驻留更新),并直接关注业务逻辑。asyncpg驱动程序可以处理这些请求并以最快的速度传输数据,而asyncpgsa将帮助他们结识朋友。我最喜欢的用于管理数据库状态和进行迁移的工具是Alembic。顺便说一下,我最近在Moscow Python中谈到了它。棉花糖计划简洁地描述了验证的逻辑(包括检查家庭纽带)。使用aiohttp-spec模块我链接了aiohttp处理程序和用于数据验证的方案,其好处是可以生成Swagger格式的文档并将其显示在图形界面中。为了编写测试,我pytest在3个讲座中选择了更多有关测试的内容。为了调试和分析该项目,我使用了PyCharm调试器(第9节)。在第7章的演讲中,介绍了如何在打包的任何计算机上(甚至在不同的OS上)运行Docker,而无需调整应用程序环境来启动和轻松地在服务器上安装/更新/删除应用程序。对于部署,我选择了Ansible。它允许您以声明方式描述服务器及其服务的所需状态,通过ssh进行工作,并且不需要特殊的软件。发展历程
我决定给Python包起一个名称,analyzer并使用以下结构: 在文件中,
在文件中,analyzer/__init__.py我发布了有关该包的一般信息:描述(docstring),版本,许可证,开发人员联系方式。可以使用内置的帮助进行查看$ python
>>> import analyzer
>>> help(analyzer)
Help on package analyzer:
NAME
analyzer
DESCRIPTION
REST API, .
PACKAGE CONTENTS
api (package)
db (package)
utils (package)
DATA
__all__ = ('__author__', '__email__', '__license__', '__maintainer__',...
__email__ = 'alvassin@yandex.ru'
__license__ = 'MIT'
__maintainer__ = 'Alexander Vasin'
VERSION
0.0.1
AUTHOR
Alexander Vasin
FILE
/Users/alvassin/Work/backendschool2019/analyzer/__init__.py
该软件包有两个输入点-REST API服务(analyzer/api/__main__.py)和数据库状态管理实用程序(analyzer/db/__main__.py)。文件的调用__main__.py是有原因的-首先,这样的名称引起了人们的注意,它清楚地表明文件是入口点。其次,由于这种进入点的方法 python -m:
$ python -m analyzer.api --help
$ python -m analyzer.db --help
为什么需要从setup.py开始?
展望未来,我们将考虑如何分发应用程序:它可以打包为zip(以及wheel / egg-)归档文件,rpm包,macOS的pkg文件,并安装在远程计算机,虚拟机,MacBook或Docker-容器。该文件的主要目的setup.py是用的应用程序描述该软件包。
该文件必须包含有关程序包的常规信息(名称,版本,作者等),但是您还可以在其中指定工作所需的模块,“额外”依赖项(例如,用于测试),入口点(例如,可执行命令)。 )和口译员的要求。
Setuptools插件使您可以从描述的软件包中收集工件。有内置的插件:zip,egg,rpm,macOS pkg。其余的插件通过PyPI分发:wheel,distutils/setuptoolsxar,pex。在最下面一行描述一个文件,我们获得了很多机会。这就是为什么要开始开发新项目的原因setup.py。在函数中,setup()相关模块由列表指示:setup(..., install_requires=["aiohttp", "SQLAlchemy"])
但是我在单独的文件中描述了依赖项,requirements.txt并requirements.dev.txt在中使用了其内容setup.py。对我来说,它似乎更灵活,而且还有一个秘密:稍后,它将允许您更快地构建Docker映像。在安装应用程序本身之前,将依赖性设置为一个单独的步骤,并且在重建Docker容器时,它将位于缓存中。为了setup.py能够从文件requirements.txt和中读取依赖项requirements.dev.txt,编写了该函数:def load_requirements(fname: str) -> list:
requirements = []
with open(fname, 'r') as fp:
for req in parse_requirements(fp.read()):
extras = '[{}]'.format(','.join(req.extras)) if req.extras else ''
requirements.append(
'{}{}{}'.format(req.name, extras, req.specifier)
)
return requirements
值得一提的是,setuptools当默认组件源分布仅包括汇编文件.py,.c,.cpp和.h。对于依赖项文件requirements.txt,请requirements.dev.txt在文件中明确指定它们MANIFEST.in。完全setup.pyimport os
from importlib.machinery import SourceFileLoader
from pkg_resources import parse_requirements
from setuptools import find_packages, setup
module_name = 'analyzer'
module = SourceFileLoader(
module_name, os.path.join(module_name, '__init__.py')
).load_module()
def load_requirements(fname: str) -> list:
requirements = []
with open(fname, 'r') as fp:
for req in parse_requirements(fp.read()):
extras = '[{}]'.format(','.join(req.extras)) if req.extras else ''
requirements.append(
'{}{}{}'.format(req.name, extras, req.specifier)
)
return requirements
setup(
name=module_name,
version=module.__version__,
author=module.__author__,
author_email=module.__email__,
license=module.__license__,
description=module.__doc__,
long_description=open('README.rst').read(),
url='https://github.com/alvassin/backendschool2019',
platforms='all',
classifiers=[
'Intended Audience :: Developers',
'Natural Language :: Russian',
'Operating System :: MacOS',
'Operating System :: POSIX',
'Programming Language :: Python',
'Programming Language :: Python :: 3',
'Programming Language :: Python :: 3.8',
'Programming Language :: Python :: Implementation :: CPython'
],
python_requires='>=3.8',
packages=find_packages(exclude=['tests']),
install_requires=load_requirements('requirements.txt'),
extras_require={'dev': load_requirements('requirements.dev.txt')},
entry_points={
'console_scripts': [
'{0}-api = {0}.api.__main__:main'.format(module_name),
'{0}-db = {0}.db.__main__:main'.format(module_name)
]
},
include_package_data=True
)
您可以使用以下命令在开发模式下安装项目(在可编辑模式下,Python不会将整个软件包安装在文件夹中site-packages,而只会创建链接,因此对软件包文件所做的任何更改将立即可见):
pip install -e '.[dev]'
pip install -e .
如何指定依赖版本?
当开发人员积极开发其程序包时,这非常好-积极修复其中的错误,出现新功能并更快地获得反馈。但是有时,依赖库中的更改不向后兼容,如果您事先不考虑,则会导致应用程序出错。对于每个相关程序包,您可以指定一个特定版本,例如aiohttp==3.6.2。这样就可以保证应用程序将使用经过测试的依赖库的那些版本专门构建。但是这种方法有一个缺点-如果开发人员在不影响向后兼容性的从属程序包中修复了严重的错误,则此修复程序将不会进入应用程序。有一种版本控制方式语义版本控制,建议以以下格式提交版本MAJOR.MINOR.PATCH:MAJOR -当添加向后不兼容的更改时增加;MINOR -在添加新功能并支持向后兼容性时增加;PATCH -在添加具有向后兼容性支持的错误修复程序时增加。
如果依赖包遵循这一方法(其中的作者在README和更新日志文件通常会报告),就足以固定的值MAJOR,MINOR并限制了补丁版本的最低值:>= MAJOR.MINOR.PATCH, == MAJOR.MINOR.*。可以使用〜=运算符实现此要求。例如,它将aiohttp~=3.6.2允许为aiohttp版本3.6.3(而不是3.7)安装PIP 。如果指定依赖版本的间隔,这将提供另一个优势-依赖库之间不会存在版本冲突。如果要开发需要不同依赖包的库,则不要允许它使用一个特定版本,而要允许一个间隔。这样,库用户就可以更轻松地使用它(突然他们的应用程序需要相同的依赖包,但版本不同)。语义版本控制只是软件包的作者和使用者之间的协议。它不能保证作者编写的代码没有错误,也不能在新版软件包中犯错误。数据库
我们设计方案
POST / imports处理程序的描述提供了一个有关居民信息的卸载示例:上载范例{
"citizens": [
{
"citizen_id": 1,
"town": "",
"street": " ",
"building": "1675",
"apartment": 7,
"name": " ",
"birth_date": "26.12.1986",
"gender": "male",
"relatives": [2]
},
{
"citizen_id": 2,
"town": "",
"street": " ",
"building": "1675",
"apartment": 7,
"name": " ",
"birth_date": "01.04.1997",
"gender": "male",
"relatives": [1]
},
{
"citizen_id": 3,
"town": "",
"street": " ",
"building": "2",
"apartment": 11,
"name": " ",
"birth_date": "23.11.1986",
"gender": "female",
"relatives": []
},
...
]
}
首先想到的是存储所有关于居住在一个表中的信息citizens,我们的关系就由现场代表relatives的整数列表形式。但是这种方法有几个缺点GET /imports/$import_id/citizens/birthdays , , citizens . relatives UNNEST.
, 10- :
SELECT
relations.citizen_id,
relations.relative_id,
date_part('month', relatives.birth_date) as relative_birth_month
FROM (
SELECT
citizens.import_id,
citizens.citizen_id,
UNNEST(citizens.relatives) as relative_id
FROM citizens
WHERE import_id = 1
) as relations
INNER JOIN citizens as relatives ON
relations.import_id = relatives.import_id AND
relations.relative_id = relatives.citizen_id
relatives PostgreSQL, : relatives , . ( ) .
此外,我决定将工作所需的所有数据恢复为第三范式,并获得以下结构:
- 导入表由一个自动递增的列组成
import_id。需要在表中创建外键检查citizens。
- citizen表存储有关居民的标量数据(除有关家庭关系的信息外的所有字段)。
使用对(import_id,citizen_id)作为主键,以确保citizen_id框架内居民的唯一性import_id。
外键citizens.import_id -> imports.import_id可确保该字段citizens.import_id仅包含现有卸载。
- relations .
( ): citizens relations .
(import_id, citizen_id, relative_id) , import_id citizen_id c relative_id.
: (relations.import_id, relations.citizen_id) -> (citizens.import_id, citizens.citizen_id) (relations.import_id, relations.relative_id) -> (citizens.import_id, citizens.citizen_id), , citizen_id relative_id .
该结构使用PostgreSQL确保数据的完整性,使您可以从数据库中有效地获取与亲戚的居民,但在通过竞争性查询更新有关居民的信息时会受到种族条件的限制(我们将仔细研究PATCH处理程序的实现)。描述SQLAlchemy中的模式
在第5章中,我讨论了如何使用SQLAlchemy创建查询,您需要使用特殊对象描述数据库架构:使用存储与数据库有关的所有元信息sqlalchemy.Table的注册表来描述表并链接到表sqlalchemy.MetaData。顺便说一句,注册表MetaData不仅可以存储Python中描述的元信息,还可以以SQLAlchemy对象的形式表示数据库的真实状态。此功能还允许Alembic比较条件并自动生成迁移代码。顺便说一下,每个数据库都有其自己的默认约束命名方案。为了避免浪费时间命名新的约束或搜索/调用要删除的约束,SQLAlchemy建议使用命名约定命名模式。可以在注册表中定义它们MetaData。创建一个MetaData注册表并将命名模式传递给它
from sqlalchemy import MetaData
convention = {
'all_column_names': lambda constraint, table: '_'.join([
column.name for column in constraint.columns.values()
]),
'ix': 'ix__%(table_name)s__%(all_column_names)s',
'uq': 'uq__%(table_name)s__%(all_column_names)s',
'ck': 'ck__%(table_name)s__%(constraint_name)s',
'fk': 'fk__%(table_name)s__%(all_column_names)s__%(referred_table_name)s',
'pk': 'pk__%(table_name)s'
}
metadata = MetaData(naming_convention=convention)
如果指定命名模式,则Alembic将在自动生成迁移过程中使用它们,并将根据它们命名所有约束。将来,MetaData将需要创建的注册表来描述表:我们用SQLAlchemy对象描述数据库模式
from enum import Enum, unique
from sqlalchemy import (
Column, Date, Enum as PgEnum, ForeignKey, ForeignKeyConstraint, Integer,
String, Table
)
@unique
class Gender(Enum):
female = 'female'
male = 'male'
imports_table = Table(
'imports',
metadata,
Column('import_id', Integer, primary_key=True)
)
citizens_table = Table(
'citizens',
metadata,
Column('import_id', Integer, ForeignKey('imports.import_id'),
primary_key=True),
Column('citizen_id', Integer, primary_key=True),
Column('town', String, nullable=False, index=True),
Column('street', String, nullable=False),
Column('building', String, nullable=False),
Column('apartment', Integer, nullable=False),
Column('name', String, nullable=False),
Column('birth_date', Date, nullable=False),
Column('gender', PgEnum(Gender, name='gender'), nullable=False),
)
relations_table = Table(
'relations',
metadata,
Column('import_id', Integer, primary_key=True),
Column('citizen_id', Integer, primary_key=True),
Column('relative_id', Integer, primary_key=True),
ForeignKeyConstraint(
('import_id', 'citizen_id'),
('citizens.import_id', 'citizens.citizen_id')
),
ForeignKeyConstraint(
('import_id', 'relative_id'),
('citizens.import_id', 'citizens.citizen_id')
),
)
自订Alembic
描述数据库模式时,有必要生成迁移,但是为此,您首先需要配置Alembic,这也将在第5章中进行讨论。要使用命令alembic,您必须执行以下步骤:- 安装包:
pip install alembic - 初始化Alembic :
cd analyzer && alembic init db/alembic。
此命令将创建一个配置文件analyzer/alembic.ini和一个analyzer/db/alembic包含以下内容的文件夹:
env.py-每次启动Alembic时都会调用。连接到Alembic注册表sqlalchemy.MetaData,其中包含对数据库所需状态的描述,并包含有关开始迁移的说明。
script.py.mako -根据其生成迁移的模板。versions -Alembic将在其中搜索(并生成)迁移文件的文件夹。
- 在alembic.ini文件中指定数据库地址:
; analyzer/alembic.ini
[alembic]
sqlalchemy.url = postgresql://user:hackme@localhost/analyzer
- 指定所需数据库状态的描述(注册表
sqlalchemy.MetaData),以便Alembic可以自动生成迁移:
from analyzer.db import schema
target_metadata = schema.metadata
Alembic已配置并且可以使用,但在我们的情况下,此配置有几个缺点:- 该实用程序在当前工作目录中
alembic搜索alembic.ini。您alembic.ini可以指定命令行参数的路径,但这很不方便:我希望能够从任何文件夹中调用命令而无需其他参数。 - 要将Alembic配置为与特定数据库一起使用,您需要更改文件
alembic.ini。例如,为环境变量和/或命令行参数指定数据库设置会更加方便--pg-url。 - 该实用程序
alembic的名称与我们的服务名称并没有很好的关联(用户实际上可能根本没有Python,并且对Alembic一无所知)。例如,如果服务的所有可执行命令都具有公共前缀,则对于最终用户将更加方便analyzer-*。
这些问题可以用一个小的包装纸解决。 analyzer/db/__main__.py:- Alembic使用标准模块来处理命令行参数
argparse。它允许您--pg-url从环境变量中添加具有默认值的可选参数ANALYZER_PG_URL。
编码import os
from alembic.config import CommandLine, Config
from analyzer.utils.pg import DEFAULT_PG_URL
def main():
alembic = CommandLine()
alembic.parser.add_argument(
'--pg-url', default=os.getenv('ANALYZER_PG_URL', DEFAULT_PG_URL),
help='Database URL [env var: ANALYZER_PG_URL]'
)
options = alembic.parser.parse_args()
config = Config(file_=options.config, ini_section=options.name,
cmd_opts=options)
config.set_main_option('sqlalchemy.url', options.pg_url)
exit(alembic.run_cmd(config, options))
if __name__ == '__main__':
main()
alembic.ini可以相对于可执行文件的位置而不是用户的当前工作目录来计算文件的路径。
编码import os
from alembic.config import CommandLine, Config
from pathlib import Path
PROJECT_PATH = Path(__file__).parent.parent.resolve()
def main():
alembic = CommandLine()
options = alembic.parser.parse_args()
if not os.path.isabs(options.config):
options.config = os.path.join(PROJECT_PATH, options.config)
config = Config(file_=options.config, ini_section=options.name,
cmd_opts=options)
alembic_location = config.get_main_option('script_location')
if not os.path.isabs(alembic_location):
config.set_main_option('script_location',
os.path.join(PROJECT_PATH, alembic_location))
exit(alembic.run_cmd(config, options))
if __name__ == '__main__':
main()
准备好用于管理数据库状态
的实用程序后,可以将其注册setup.py为可执行命令,并使用最终用户可以理解的名称,例如analyzer-db:在setup.py中注册可执行命令from setuptools import setup
setup(..., entry_points={
'console_scripts': [
'analyzer-db = analyzer.db.__main__:main'
]
})
重新安装模块后,将生成一个文件,env/bin/analyzer-db并且该命令analyzer-db将变为可用:$ pip install -e '.[dev]'
我们产生移民
为了生成迁移,需要两个状态:所需状态(我们用SQLAlchemy对象描述了状态)和实际状态(在我们的例子中,数据库为空)。我认为提高Postgres的最简单方法是使用Docker,为方便起见,我添加了一个命令make postgres,该命令在后台使用PostgreSQL在端口5432上运行容器:提高PostgreSQL并生成迁移$ make postgres
...
$ analyzer-db revision --message="Initial" --autogenerate
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] Will assume transactional DDL.
INFO [alembic.autogenerate.compare] Detected added table 'imports'
INFO [alembic.autogenerate.compare] Detected added table 'citizens'
INFO [alembic.autogenerate.compare] Detected added index 'ix__citizens__town' on '['town']'
INFO [alembic.autogenerate.compare] Detected added table 'relations'
Generating /Users/alvassin/Work/backendschool2019/analyzer/db/alembic/versions/d5f704ed4610_initial.py ... done
Alembic通常在生成迁移的日常工作中做得很好,但是我想提请注意以下方面:- 在创建的表中指定的用户数据类型是自动创建的(在我们的示例中为-
gender),但是downgrade不会生成删除它们的代码。如果您应用,回滚,然后再次应用迁移,这将导致错误,因为指定的数据类型已经存在。
在降级方法中删除性别数据类型from alembic import op
from sqlalchemy import Column, Enum
GenderType = Enum('female', 'male', name='gender')
def upgrade():
...
op.create_table('citizens', ...,
Column('gender', GenderType, nullable=False))
...
def downgrade():
op.drop_table('citizens')
GenderType.drop(op.get_bind())
- 在该方法中,
downgrade有时可以删除某些操作(如果我们删除整个表,则不能单独删除其索引):
例如def downgrade():
op.drop_table('relations')
op.drop_index(op.f('ix__citizens__town'), table_name='citizens')
op.drop_table('citizens')
op.drop_table('imports')
固定并准备好迁移后,我们将其应用:$ analyzer-db upgrade head
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] Will assume transactional DDL.
INFO [alembic.runtime.migration] Running upgrade -> d5f704ed4610, Initial
应用
在开始创建处理程序之前,必须配置aiohttp应用程序。如果您查看aiohttp快速入门,则可以编写如下内容import logging
from aiohttp import web
def main():
logging.basicConfig(level=logging.DEBUG)
app = web.Application()
app.router.add_route(...)
web.run_app(app)
此代码引发了许多问题,并具有许多缺点:- 如何配置应用程序?至少必须指定用于连接客户端的主机和端口,以及用于连接数据库的信息。
我真的很想在模块的帮助下解决此问题ConfigArgParse:它扩展了标准模块,argparse并允许使用命令行参数,环境变量(对于配置Docker容器必不可少的)甚至配置文件(以及组合这些方法)进行配置。使用ConfigArgParse它,您还可以验证应用程序配置参数的值。
使用ConfigArgParse处理参数的示例from aiohttp import web
from configargparse import ArgumentParser, ArgumentDefaultsHelpFormatter
from analyzer.utils.argparse import positive_int
parser = ArgumentParser(
auto_env_var_prefix='ANALYZER_',
formatter_class=ArgumentDefaultsHelpFormatter
)
parser.add_argument('--api-address', default='0.0.0.0',
help='IPv4/IPv6 address API server would listen on')
parser.add_argument('--api-port', type=positive_int, default=8081,
help='TCP port API server would listen on')
def main():
args = parser.parse_args()
app = web.Application()
web.run_app(app, host=args.api_address, port=args.api_port)
if __name__ == '__main__':
main()
, ConfigArgParse, argparse, ( -h --help). :
$ python __main__.py --help
usage: __main__.py [-h] [--api-address API_ADDRESS] [--api-port API_PORT]
If an arg is specified in more than one place, then commandline values override environment variables which override defaults.
optional arguments:
-h, --help show this help message and exit
--api-address API_ADDRESS
IPv4/IPv6 address API server would listen on [env var: ANALYZER_API_ADDRESS] (default: 0.0.0.0)
--api-port API_PORT TCP port API server would listen on [env var: ANALYZER_API_PORT] (default: 8081)
- — , «» . , .
os.environ.clear(), Python (, asyncio?), , ConfigArgParser.
import os
from typing import Callable
from configargparse import ArgumentParser
from yarl import URL
from analyzer.api.app import create_app
from analyzer.utils.pg import DEFAULT_PG_URL
ENV_VAR_PREFIX = 'ANALYZER_'
parser = ArgumentParser(auto_env_var_prefix=ENV_VAR_PREFIX)
parser.add_argument('--pg-url', type=URL, default=URL(DEFAULT_PG_URL),
help='URL to use to connect to the database')
def clear_environ(rule: Callable):
"""
,
rule
"""
for name in filter(rule, tuple(os.environ)):
os.environ.pop(name)
def main():
args = parser.parse_args()
clear_environ(lambda i: i.startswith(ENV_VAR_PREFIX))
app = create_app(args)
...
if __name__ == '__main__':
main()
- stderr/ .
9 , logging.basicConfig() stderr.
, . aiomisc.
aiomiscimport logging
from aiomisc.log import basic_config
basic_config(logging.DEBUG, buffered=True)
- , ? ,
fork , (, Windows ).
import os
from sys import argv
import forklib
from aiohttp.web import Application, run_app
from aiomisc import bind_socket
from setproctitle import setproctitle
def main():
sock = bind_socket(address='0.0.0.0', port=8081, proto_name='http')
setproctitle(f'[Master] {os.path.basename(argv[0])}')
def worker():
setproctitle(f'[Worker] {os.path.basename(argv[0])}')
app = Application()
run_app(app, sock=sock)
forklib.fork(os.cpu_count(), worker, auto_restart=True)
if __name__ == '__main__':
main()
- - ? , ( — ) ,
nobody. — .
import os
import pwd
from aiohttp.web import run_app
from aiomisc import bind_socket
from analyzer.api.app import create_app
def main():
sock = bind_socket(address='0.0.0.0', port=8085, proto_name='http')
user = pwd.getpwnam('nobody')
os.setgid(user.pw_gid)
os.setuid(user.pw_uid)
app = create_app(...)
run_app(app, sock=sock)
if __name__ == '__main__':
main()
create_app, .
所有成功的处理程序响应都将以JSON格式返回。客户也可以方便地以序列化形式接收有关错误的信息(例如,查看哪些字段未通过验证)。该文档aiohttp提供了一种方法json_response,该方法接受一个对象,将其序列化为JSON,然后返回一个内部aiohttp.web.Response包含标头Content-Type: application/json和序列化数据的新对象。如何使用json_response序列化数据from aiohttp.web import Application, View, run_app
from aiohttp.web_response import json_response
class SomeView(View):
async def get(self):
return json_response({'hello': 'world'})
app = Application()
app.router.add_route('*', '/hello', SomeView)
run_app(app)
但是还有另一种方法:aiohttp允许您在注册表中为特定类型的响应数据注册任意串行器aiohttp.PAYLOAD_REGISTRY。例如,您可以aiohttp.JsonPayload为Mapping类型的对象指定序列化程序。在这种情况下,处理程序返回一个Response参数为的响应数据的对象就足够了body。aiohttp将找到与数据类型匹配的序列化器并序列化响应。除了在一个地方描述对象的序列化这一事实之外,这种方法还更加灵活-它使您可以实现非常有趣的解决方案(我们将在处理程序中考虑其中一种用例GET /imports/$import_id/citizens)。如何使用aiohttp.PAYLOAD_REGISTRY序列化数据from types import MappingProxyType
from typing import Mapping
from aiohttp import PAYLOAD_REGISTRY, JsonPayload
from aiohttp.web import run_app, Application, Response, View
PAYLOAD_REGISTRY.register(JsonPayload, (Mapping, MappingProxyType))
class SomeView(View):
async def get(self):
return Response(body={'hello': 'world'})
app = Application()
app.router.add_route('*', '/hello', SomeView)
run_app(app)
重要的是要了解json_response,像一样aiohttp.JsonPayload,它们使用json.dumps无法序列化复杂数据类型的标准方法,例如,datetime.date或asyncpg.Record(asyncpg从数据库作为此类的实例返回记录)。而且,某些复杂的对象可能包含其他对象:在数据库的一条记录中可能有一个type字段datetime.date。Python开发人员已经解决了这个问题:该方法json.dumps允许您使用参数default指定需要序列化不熟悉的对象时调用的函数。该函数应将不熟悉的对象转换为可以序列化json模块的类型。如何扩展JsonPayload以序列化任意对象import json
from datetime import date
from functools import partial, singledispatch
from typing import Any
from aiohttp.payload import JsonPayload as BaseJsonPayload
from aiohttp.typedefs import JSONEncoder
@singledispatch
def convert(value):
raise NotImplementedError(f'Unserializable value: {value!r}')
@convert.register(Record)
def convert_asyncpg_record(value: Record):
"""
,
asyncpg
"""
return dict(value)
@convert.register(date)
def convert_date(value: date):
"""
date —
.
..
"""
return value.strftime('%d.%m.%Y')
dumps = partial(json.dumps, default=convert)
class JsonPayload(BaseJsonPayload):
def __init__(self,
value: Any,
encoding: str = 'utf-8',
content_type: str = 'application/json',
dumps: JSONEncoder = dumps,
*args: Any,
**kwargs: Any) -> None:
super().__init__(value, encoding, content_type, dumps, *args, **kwargs)
处理程序
aiohttp允许您使用异步函数和类来实现处理程序。类具有更大的可扩展性:首先,可以将属于一个处理程序的代码放在一个位置,其次,类允许您使用继承来消除代码重复(例如,每个处理程序都需要数据库连接)。处理程序基类from aiohttp.web_urldispatcher import View
from asyncpgsa import PG
class BaseView(View):
URL_PATH: str
@property
def pg(self) -> PG:
return self.request.app['pg']
由于很难读取一个大文件,因此我决定将处理程序拆分为多个文件。小文件会导致弱连接,例如,如果处理程序中有环导入,则意味着实体的组成可能有问题。开机自检/导入
输入处理程序接收带有有关居民数据的json。允许的最大请求大小在aiohttp由选项控制client_max_size和是2 MB默认。如果超出限制,则aiohttp将返回状态为413:请求实体太大错误的HTTP响应。同时,具有最长行和数字的正确json重约63兆字节,因此需要扩展对请求大小的限制。接下来,您需要检查并反序列化数据。如果它们不正确,则需要返回HTTP响应400: Bad Request。我需要两个方案Marhsmallow。第一个CitizenSchema,检查每个居民的数据,并将生日快乐字符串反序列化为对象datetime.date:- 所有必填字段的数据类型,格式和可用性;
- 缺乏陌生的田野;
- 出生日期必须以格式表示,
DD.MM.YYYY并且从将来起就没有任何意义; - 每个居民的亲属列表必须包含此上载中存在的居民的唯一标识符。
第二种方案ImportSchema是整体检查卸载:citizen_id 卸货中的每个居民应是唯一的;- 家庭关系应该是双向的(如果1号居民在亲戚名单中有2号居民,那么2号居民也必须有1号亲戚)。
如果数据正确,则必须使用新的唯一数据将其添加到数据库中import_id。要添加数据,您将需要在不同的表中执行几个查询。为了避免在发生错误或异常(例如,断开未收到完整响应的客户端时,aiohttp 会抛出CancelledError异常)时,部分避免在数据库中部分添加数据,必须使用transaction。有必要将数据部分添加到表中,因为在对PostgreSQL的一次查询中,参数不能超过32,767。表中有citizens9个字段。因此,对于1个查询,只能将32,767 / 9 = 3,640行插入到此表中,并且在一次上载中,最多可容纳10,000个居民。GET /进口/ $ import_id /公民
处理程序返回所有居民,以指定的进行卸载import_id。如果指定的上传不存在,则必须返回404:未找到HTTP响应。对于需要现有卸载的处理程序,此行为似乎很常见,因此我将验证代码放入了单独的类中。带卸载处理程序的基类from aiohttp.web_exceptions import HTTPNotFound
from sqlalchemy import select, exists
from analyzer.db.schema import imports_table
class BaseImportView(BaseView):
@property
def import_id(self):
return int(self.request.match_info.get('import_id'))
async def check_import_exists(self):
query = select([
exists().where(imports_table.c.import_id == self.import_id)
])
if not await self.pg.fetchval(query):
raise HTTPNotFound()
要获取每个居民的亲属列表,您将需要在LEFT JOIN表citizens与表之间进行relations汇总,汇总relations.relative_id由import_id和分组的字段citizen_id。如果居民没有亲戚,那么他LEFT JOIN将在该字段中为他返回relations.relative_id值,NULL并且由于汇总,亲戚列表将如下所示[NULL]。要修复此错误值,我使用了array_remove函数。数据库以某种格式存储日期YYYY-MM-DD,但是我们需要一种格式DD.MM.YYYY。从技术上讲,您可以在序列化响应时使用SQL查询或在Python端格式化日期json.dumps(asyncpg将字段值birth_date作为类的实例返回datetime.date)我选择在Python端进行序列化,因为它birth_date是datetime.date项目中唯一具有单一格式的对象(请参见“序列化数据”一节)。尽管处理器执行了两个请求(检查是否存在卸载和居民列表请求),但是并不需要使用事务。缺省情况下,PostgreSQL使用隔离级别,READ COMMITTED即使在一个事务中,对其他已成功完成的事务的所有更改也将可见(添加新行,更改现有行)。文本视图中最大的上传可能需要约63兆字节-这是很多,尤其是考虑到可能同时到达多个接收数据的请求时。有一种相当有趣的方法,可以使用游标从数据库中获取数据并将其分部分发送给客户端。为此,我们需要实现两个对象:- 从数据库返回记录的
SelectQuery类型对象AsyncIterable。在第一次调用时,它连接到数据库,打开一个事务并创建一个游标;在进一步的迭代中,它从数据库中返回记录。它由处理程序返回。
SelectQuery代码from collections import AsyncIterable
from asyncpgsa.transactionmanager import ConnectionTransactionContextManager
from sqlalchemy.sql import Select
class SelectQuery(AsyncIterable):
"""
, PostgreSQL
, ,
"""
PREFETCH = 500
__slots__ = (
'query', 'transaction_ctx', 'prefetch', 'timeout'
)
def __init__(self, query: Select,
transaction_ctx: ConnectionTransactionContextManager,
prefetch: int = None,
timeout: float = None):
self.query = query
self.transaction_ctx = transaction_ctx
self.prefetch = prefetch or self.PREFETCH
self.timeout = timeout
async def __aiter__(self):
async with self.transaction_ctx as conn:
cursor = conn.cursor(self.query, prefetch=self.prefetch,
timeout=self.timeout)
async for row in cursor:
yield row
- 一个
AsyncGenJSONListPayload可以在异步生成器上进行迭代,将数据从异步生成器序列化为JSON并将数据分批发送给客户端的序列化器。它被注册aiohttp.PAYLOAD_REGISTRY为对象的序列化器AsyncIterable。
AsyncGenJSONListPayload代码import json
from functools import partial
from aiohttp import Payload
dumps = partial(json.dumps, default=convert, ensure_ascii=False)
class AsyncGenJSONListPayload(Payload):
"""
AsyncIterable,
JSON
"""
def __init__(self, value, encoding: str = 'utf-8',
content_type: str = 'application/json',
root_object: str = 'data',
*args, **kwargs):
self.root_object = root_object
super().__init__(value, content_type=content_type, encoding=encoding,
*args, **kwargs)
async def write(self, writer):
await writer.write(
('{"%s":[' % self.root_object).encode(self._encoding)
)
first = True
async for row in self._value:
if not first:
await writer.write(b',')
else:
first = False
await writer.write(dumps(row).encode(self._encoding))
await writer.write(b']}')
此外,在处理程序中,可以创建一个对象SelectQuery,向其传递一个SQL查询和一个函数以打开事务,然后将其返回给Response body:处理程序代码
from aiohttp.web_response import Response
from aiohttp_apispec import docs, response_schema
from analyzer.api.schema import CitizensResponseSchema
from analyzer.db.schema import citizens_table as citizens_t
from analyzer.utils.pg import SelectQuery
from .query import CITIZENS_QUERY
from .base import BaseImportView
class CitizensView(BaseImportView):
URL_PATH = r'/imports/{import_id:\d+}/citizens'
@docs(summary=' ')
@response_schema(CitizensResponseSchema())
async def get(self):
await self.check_import_exists()
query = CITIZENS_QUERY.where(
citizens_t.c.import_id == self.import_id
)
body = SelectQuery(query, self.pg.transaction())
return Response(body=body)
aiohttp它为注册表中类型的对象检测已注册的aiohttp.PAYLOAD_REGISTRY序列化AsyncGenJSONListPayload程序AsyncIterable。然后,序列化程序将遍历该对象SelectQuery并将数据发送到客户端。在第一个调用中,对象SelectQuery接收到数据库的连接,打开一个事务并创建一个游标;在进一步的迭代中,它将使用游标从数据库接收数据并逐行返回它们。这种方法不允许每次请求都为全部数据分配内存,但是它具有特殊性:如果发生错误,则应用程序将无法将相应的HTTP状态返回给客户端(毕竟,HTTP状态,标头已经发送到客户端并且正在写入数据)。发生异常时,除了断开连接之外,别无其他。当然,可以确保有异常,但是客户端将无法准确了解发生了什么错误。另一方面,即使处理器从数据库中接收了所有数据,也可能出现类似情况,但是在向客户端传输数据时网络会闪烁-没有人对此感到安全。修补程序/进口/ $ import_id /公民/ $ civil_id
处理程序将接收到unload的标识符import_id,常驻居民citizen_id以及带有有关常驻居民的新数据的json。如果不存在卸载或驻留,则必须返回HTTP响应404: Not Found。客户端传输的数据必须经过验证和反序列化。如果它们不正确,则必须返回HTTP响应400: Bad Request。我实现了一个棉花糖计划PatchCitizenSchema来检查:- 指定字段的数据类型和格式。
- 出生日期。必须以一种格式指定它,
DD.MM.YYYY并且从将来起就不再有意义。 - 每个居民的亲戚名单。它必须具有居民的唯一标识符。
字段中指示的亲戚是否存在relatives不能单独检查:如果将relations不存在的居民添加到表中,PostgreSQL将返回一个ForeignKeyViolationError可以处理的错误,并且可以返回HTTP状态400: Bad Request。如果客户端为不存在的居民或正在卸载的客户发送了不正确的数据,应该返回什么状态?从语义上讲,首先检查卸载和驻留程序的存在(如果不存在,则返回404: Not Found),然后检查客户端是否发送了正确的数据(如果没有,则返回return 400: Bad Request),是更正确的选择。实际上,首先检查数据通常更便宜,并且只有在数据正确的情况下才访问数据库。这两个选项都是可以接受的,但是我决定选择一个更便宜的第二个选项,因为在任何情况下,操作的结果都是不会影响任何错误的错误(客户端将更正数据,然后发现该居民不存在)。如果数据正确,则必须更新有关数据库中居民的信息。在处理程序中,您将需要对不同的表进行几个查询。如果发生错误或异常,则必须撤消对数据库的更改,因此必须在transaction中执行查询。该方法PATCH 仅允许您为居民转移某些字段。必须以这样的方式编写处理程序:在访问客户端未指定的数据时,处理程序不会崩溃,并且也不会对未更改数据的表执行查询。如果客户指定了该字段relatives,则必须获取现有亲属的列表。如果已更改,请确定relatives必须删除表中的哪些记录以及添加哪些记录,以使数据库与客户的要求保持一致。默认情况下,PostgreSQL使用事务隔离 READ COMMITTED。这意味着,作为当前事务的一部分,更改将对其他已完成事务的现有(以及新记录)记录可见。这可能导致竞争要求之间出现竞争状态。假设居民正在卸货#1... #2,#3没有血缘关系。该服务同时收到两个更改居民编号1 {"relatives": [2]}和的请求{"relatives": [3]}。 aiohttp将创建两个处理程序,这些处理程序同时从PostgreSQL接收居民的当前状态。每个处理程序都不会检测到单个相关关系,而是会决定添加具有指定亲属的新关系。结果,居民#1与亲戚有相同的领域[2,3]。 这种行为不能被称为明显。预期有两种方法可以决定比赛的结果:仅完成第一个请求,第二个返回HTTP响应
这种行为不能被称为明显。预期有两种方法可以决定比赛的结果:仅完成第一个请求,第二个返回HTTP响应409: Conflict(以便客户端重复请求),或依次执行请求(仅在第一个请求完成后处理第二个请求)。可以通过打开隔离模式来实现第一个选项SERIALIZABLE。如果在处理请求期间有人已经设法更改和提交数据,则将引发异常,可以处理该异常并返回相应的HTTP状态。该解决方案的缺点-PostgreSQL中的大量锁SERIALIZABLE会引发异常,即使竞争性查询更改了来自不同卸载的居民记录。您还可以使用推荐锁定机制。如果您获得了这样的锁定import_id,则针对不同卸载的竞争性请求将能够并行运行。要在一个上传中处理竞争性请求,您可以实现任何选项的行为:该函数pg_try_advisory_xact_lock尝试获取锁定,然后它立即返回布尔结果(如果无法获取锁,则可能引发异常),并pg_advisory_xact_lock等待直到资源可用于阻塞(在这种情况下,请求将按顺序执行,我决定使用此选项)。结果,处理程序必须返回有关已更新resident的当前信息。可以限制自己将数据从他的请求返回给客户端(因为我们正在将响应返回给客户端,这意味着没有异常,并且所有请求都已成功完成)。或-在修改数据库并从结果生成响应的查询中使用RETURNING关键字。但是,这两种方法都不允许我们通过国家竞争来审视和检验案件。该服务没有高负载要求,所以我决定再次请求有关居民的所有数据,并从数据库返回客户真实的结果。GET /进口/ $ import_id /公民/生日
处理程序计算卸货的每个居民将送给其亲戚的礼物数量(一阶)。该数字按月份分组,并使用指定的进行上传import_id。如果上传不存在,则必须返回HTTP响应404: Not Found。有两个实现选项:- 从数据库中获取有亲戚的居民的数据,并且在Python方面,按月汇总数据并为数据库中没有数据的月份生成列表。
- 在数据库中编译一个json请求,并为缺少的月份添加存根。
我选择了第一个选项-看起来更容易理解和支持。可以通过将JOIN具有家庭关系的表(relations.citizen_id-我们认为其亲戚的生日的居民)从表中citizens(包含要获取月份的出生日期)中获得给定月份的生日数。月值不得包含前导零。birth_date使用该函数从字段中获得的月份date_part可能包含前导零。要删除它,我在SQL查询中执行cast了integer。尽管处理程序需要满足两个请求(检查是否存在卸载并获取有关生日和礼物的信息),但不需要进行交易。缺省情况下,PostgreSQL使用READ COMMITTED模式,在该模式中,所有新记录(由其他事务添加)和现有记录(由其他事务修改)在成功完成后都将在当前事务中可见。例如,如果在接收数据时添加了新上传,则不会影响现有上传。如果在接收数据时执行了更改居民的请求,则该数据将不可见(如果尚未完成更改数据的交易),或者该交易将完全完成并且所有更改将立即可见。从数据库获得的完整性将不会受到侵犯。GET /进口/ $ import_id /城镇/统计/百分位数/年龄
处理程序使用指定的import_id计算样本中按城市划分的居民年龄(完整年)的第50、75和99%。如果上传不存在,则必须返回HTTP响应404: Not Found。尽管处理器执行了两个请求(检查是否存在卸载并获取居民列表),但是并不需要使用事务。有两个实现选项:- 从数据库中按城市分组,获取居民的年龄,然后在python端使用numpy(在任务中指定为参考)计算百分位数,并四舍五入到小数点后两位。
- PostgreSQL: percentile_cont , SQL-, numpy .
第二个选项需要在应用程序和PostgreSQL之间传输较少的数据,但是并没有一个非常明显的陷阱:在PostgreSQL中,舍入是数学的(SELECT ROUND(2.5)返回3),而在Python-记帐中,舍入到最接近的整数(round(2.5)返回2)。要测试处理程序,PostgreSQL和Python中的实现必须相同(在Python中使用数学舍入来实现函数看起来更容易)。值得注意的是,当计算百分位数时,numpy和PostgreSQL可以返回略有不同的数字,但是考虑到四舍五入,这种差异将不明显。测试中
在此应用程序中需要检查什么?首先,要确保操作人员符合要求,并在尽可能接近战斗环境的环境中执行所需的工作。其次,更改数据库状态的迁移可以正常工作。第三,有许多辅助功能也可以通过测试正确覆盖。由于它的灵活性和易用性,我决定使用pytest框架。它提供了一种强大的机制来为测试准备环境- 夹具,即具有装饰器的功能pytest.mark.fixture其名称可以由测试中的参数指定。如果pytest在测试注释中检测到带有灯具名称的参数,它将执行该灯具并将结果传递给该参数的值。如果夹具是生成器,那么测试参数将使用返回的值yield,并且在测试完成之后,夹具的第二部分将被执行,这可以清除资源或关闭连接。对于大多数测试,我们需要一个PostgreSQL数据库。为了将测试彼此隔离,可以在每个测试之前创建一个单独的数据库,并在执行之后将其删除。为每个测试创建一个夹具数据库import os
import uuid
import pytest
from sqlalchemy import create_engine
from sqlalchemy_utils import create_database, drop_database
from yarl import URL
from analyzer.utils.pg import DEFAULT_PG_URL
PG_URL = os.getenv('CI_ANALYZER_PG_URL', DEFAULT_PG_URL)
@pytest.fixture
def postgres():
tmp_name = '.'.join([uuid.uuid4().hex, 'pytest'])
tmp_url = str(URL(PG_URL).with_path(tmp_name))
create_database(tmp_url)
try:
yield tmp_url
finally:
drop_database(tmp_url)
def test_db(postgres):
"""
, PostgreSQL
"""
engine = create_engine(postgres)
assert engine.execute('SELECT 1').scalar() == 1
engine.dispose()
考虑到不同数据库和驱动程序的功能,sqlalchemy_utils
模块出色地完成了此任务。例如,PostgreSQL不允许CREATE DATABASE在事务块中执行。创建数据库时,它将sqlalchemy_utils转换psycopg2(通常执行事务中的所有请求)为自动提交模式。另一个重要功能:如果至少一个客户端连接到PostgreSQL,则无法删除数据库,但是sqlalchemy_utils在删除数据库之前会断开所有客户端的连接。即使某些具有活动连接的测试挂起,数据库也将被成功删除。我们需要处于不同状态的PostgreSQL:为了测试迁移,我们需要一个干净的数据库,而处理程序则要求所有迁移都适用。您可以使用Alembic命令以编程方式更改数据库的状态;它们需要Alembic配置对象来调用它们。创建一个夹具Alembic配置对象from types import SimpleNamespace
import pytest
from analyzer.utils.pg import make_alembic_config
@pytest.fixture()
def alembic_config(postgres):
cmd_options = SimpleNamespace(config='alembic.ini', name='alembic',
pg_url=postgres, raiseerr=False, x=None)
return make_alembic_config(cmd_options)
请注意,灯具alembic_config具有参数postgres- pytest不仅可以指示测试对灯具的依赖性,还可以指示灯具之间的依赖性。这种机制使您可以灵活地分离逻辑并编写非常简洁且可重用的代码。处理程序
测试处理程序需要具有创建的表和数据类型的数据库。要应用迁移,您必须以编程方式调用upgrade Alembic命令。要调用它,您需要一个具有Alembic配置的对象,我们已经使用fixtures定义了它alembic_config。具有迁移功能的数据库看起来像一个完全独立的实体,可以表示为一个固定装置:from alembic.command import upgrade
@pytest.fixture
async def migrated_postgres(alembic_config, postgres):
upgrade(alembic_config, 'head')
return postgres
当项目中有许多迁移时,它们在每个测试中的应用程序可能会花费太多时间。为了加快这一过程,您可以创建一次带有迁移的数据库,然后将其用作模板。除了用于测试处理程序的数据库之外,您还需要一个正在运行的应用程序,以及一个配置为与此应用程序一起使用的客户端。为了使应用程序易于测试,我将其创建放入一个具有create_app运行参数的函数中:数据库,REST API的端口等。启动应用程序的参数也可以表示为单独的固定装置。要创建它们,您将需要确定用于运行测试应用程序的空闲端口以及迁移到的临时数据库的地址。为了确定空闲端口,我使用aiomisc_unused_port了aiomisc软件包中的灯具。一个标准的夹具aiohttp_unused_port也可以,但是它返回一个确定空闲端口的函数,同时它aiomisc_unused_port立即返回端口号。对于我们的应用程序,我们只需要确定一个空闲端口,因此我决定不使用call编写额外的代码行aiohttp_unused_port。@pytest.fixture
def arguments(aiomisc_unused_port, migrated_postgres):
return parser.parse_args(
[
'--log-level=debug',
'--api-address=127.0.0.1',
f'--api-port={aiomisc_unused_port}',
f'--pg-url={migrated_postgres}'
]
)
使用处理程序进行的所有测试均暗含对REST API的请求;aiohttp不需要直接与应用程序一起工作。因此,我制作了一个启动应用程序的夹具,并使用工厂aiohttp_client创建并返回了连接到该应用程序的标准测试客户端aiohttp.test_utils.TestClient。from analyzer.api.app import create_app
@pytest.fixture
async def api_client(aiohttp_client, arguments):
app = create_app(arguments)
client = await aiohttp_client(app, server_kwargs={
'port': arguments.api_port
})
try:
yield client
finally:
await client.close()
现在,如果在测试参数中指定夹具,api_client则会发生以下情况:postgres ( migrated_postgres).alembic_config Alembic, ( migrated_postgres).migrated_postgres ( arguments).aiomisc_unused_port ( arguments).arguments ( api_client).api_client .- .
api_client .postgres .
夹具使您可以避免重复代码,但是除了在测试中准备环境之外,还有另一个可能存在很多相同代码的潜在地方-应用程序请求。首先,发出请求,我们希望获得某种HTTP状态。其次,如果状态与期望的状态匹配,则在处理数据之前,需要确保它们具有正确的格式。在这里很容易出错,并编写一个处理程序以执行正确的计算并返回正确的结果,但由于响应格式不正确而无法通过自动验证(例如,忘记将答案包装在带有key的字典中data)。所有这些检查都可以在一个地方完成。在模块中analyzer.testing 我为每个处理程序准备了一个辅助函数,该函数检查HTTP的状态以及使用棉花糖的响应格式。GET /进口/ $ import_id /公民
我决定从返回居民的处理程序开始,因为它对于检查其他更改数据库状态的处理程序的结果非常有用。我故意没有使用从处理程序向数据库添加数据的代码POST /imports,尽管将其变成一个单独的函数并不困难。处理程序的代码具有更改的属性,并且如果添加到数据库中的代码中有任何错误,则测试有可能会停止按预期工作,并且对开发人员隐式停止显示错误。对于此测试,我定义了以下测试数据集:- 与几个亲戚一起卸货。检查每个居民是否正确地形成了带有亲戚标识符的列表。
- 与一位没有亲戚的居民一起卸货。检查该字段
relatives是否为空列表(由于LEFT JOINSQL查询,亲戚列表可能相等[None])。 - 与自己亲戚的居民一起卸货。
- 空卸货。检查处理程序是否允许添加空卸载,并且不会因错误而崩溃。
在每次上传单独运行相同的测试,我用另一种非常强大的pytest机制- 参数。这种机制允许您将测试函数包装在装饰器中,pytest.mark.parametrize并在其中描述每个单独的测试用例测试函数应采用哪些参数。如何参数化测试import pytest
from analyzer.utils.testing import generate_citizen
datasets = [
[
generate_citizen(citizen_id=1, relatives=[2, 3]),
generate_citizen(citizen_id=2, relatives=[1]),
generate_citizen(citizen_id=3, relatives=[1])
],
[
generate_citizen(relatives=[])
],
[
generate_citizen(citizen_id=1, name='', gender='male',
birth_date='17.02.2020', relatives=[1])
],
[],
]
@pytest.mark.parametrize('dataset', datasets)
async def test_get_citizens(api_client, dataset):
"""
4 ,
"""
因此,测试会将上传内容添加到数据库,然后使用对处理程序的请求,它将接收有关居民的信息,并将参考上传内容与接收到的内容进行比较。但是,您如何比较居民?每个居民都由标量字段和一个字段relatives-亲戚标识符列表组成。 Python中的列表是有序类型,在比较每个列表元素的顺序时确实很重要,但是在将列表与同级进行比较时,顺序不重要。如果您relatives在比较之前将其带入集合,则在进行比较时无法找出其中一个居民relatives重复的情况。如果使用亲属标识符对列表进行排序,则可以避免亲属标识符顺序不同的问题,但同时可以检测重复项。在将两个具有居民的清单进行比较时,一个人可能会遇到类似的问题:从技术上讲,卸货中居民的顺序并不重要,但重要的是要检测一个卸货中是否有两个居民具有相同的标识符,而另一个居民中没有。因此,除了与亲戚组织清单外,每个居民的亲戚还需要安排居民进行每次卸货。由于比较居民的任务将不只一次出现,因此我实现了两个功能:一个用于比较两个居民,第二个用于将两个列表与居民进行比较:比较居民from typing import Iterable, Mapping
def normalize_citizen(citizen):
"""
"""
return {**citizen, 'relatives': sorted(citizen['relatives'])}
def compare_citizens(left: Mapping, right: Mapping) -> bool:
"""
"""
return normalize_citizen(left) == normalize_citizen(right)
def compare_citizen_groups(left: Iterable, right: Iterable) -> bool:
"""
,
"""
left = [normalize_citizen(citizen) for citizen in left]
left.sort(key=lambda citizen: citizen['citizen_id'])
right = [normalize_citizen(citizen) for citizen in right]
right.sort(key=lambda citizen: citizen['citizen_id'])
return left == right
为了确保此处理程序不会返回其他卸载的居民,我决定在每次测试之前添加一个居民的额外卸载。开机自检/导入
我定义了以下数据集来测试处理程序:- 正确的数据,有望成功添加到数据库中。
- ( ).
. , , insert , . - ( , ).
, .
- .
, . :)
, aiohttp PostgreSQL 32 767 ( ).
- 空卸载
处理程序应考虑到这种情况,不要摔倒,尝试对有居民的表进行空插入。
- 数据错误,期望HTTP响应为400:请求错误。
- 出生日期不正确(未来时态)。
- citizen_id在上载中不是唯一的。
- 亲戚关系显示不正确(只有一位居民到另一位居民,但没有反馈)。
- 居民在卸货中没有亲戚。
- 家庭纽带不是唯一的。
如果处理器成功运行并且添加了数据,则需要将居民添加到数据库中,并将其与标准卸载进行比较。为了获得居民,我使用了已经测试过的处理程序GET /imports/$import_id/citizens,为了进行比较,使用了一个function compare_citizen_groups。修补程序/进口/ $ import_id /公民/ $ civil_id
数据验证在许多方面类似于处理程序中描述的方法,但POST /imports有一些例外:只有一个居民,并且客户端只能传递他想要的那些字段。我决定对错误的数据使用以下集合,以验证处理程序将返回HTTP响应400: Bad request:- 指定了该字段,但数据类型和/或格式不正确
- 出生日期不正确(未来时间)。
- 该字段
relatives包含一个在卸载中不存在的亲戚。
还需要验证处理程序是否正确更新了有关居民及其亲属的信息。为此,请创建一个包含三个居民的上传文件,其中两个是亲戚,然后为所有标量字段发送一个具有新值的请求,并在该字段中添加一个新的相对标识符relatives。为了确保处理程序在测试之前区分不同卸货的居民(例如,不要将具有相同标识符的居民与另一个卸货的居民进行更改),我创建了一个额外的卸货,其中三个居民具有相同的标识符。处理程序必须保存标量字段的新值,添加新的指定亲戚并删除与旧的未指定亲戚的关系。亲属关系的所有变化都应是双边的。其他卸载不应更改。由于此类处理程序可能会遇到竞争条件(这在“开发”部分中进行了讨论),因此我添加了两个附加测试。一个复制了竞争状态的问题(扩展了处理程序类并删除了锁),第二个复制了竞争状态的问题没有被复制。GET /进口/ $ import_id /公民/生日
为了测试此处理程序,我选择了以下数据集:- 居民在一个月内有一个亲戚,在另一个月有两个亲戚的卸货。
- 与一位没有亲戚的居民一起卸货。检查处理程序是否在计算中未将其考虑在内。
- 空卸货。检查处理程序是否不会失败,并在响应中返回12个月的正确字典。
- 与自己亲戚的居民一起卸货。检查居民是否会购买其出生月份的礼物。
处理程序必须在响应中返回所有月份,即使这些月份中没有生日也是如此。为避免重复,我制作了一个函数,您可以将字典传递给该函数,以便对缺失月份的值进行补充。为了确保处理程序能够区分不同卸货的居民,我添加了两个亲戚的额外卸货。如果处理程序在计算中错误地使用它们,则结果将不正确,并且处理程序将因错误而掉落。GET /进口/ $ import_id /城镇/统计/百分位数/年龄
该测试的独特之处在于它的工作结果取决于当前时间:根据当前日期计算居民的年龄。为确保测试结果不会随时间变化,必须记录当前日期,居民的出生日期和预期结果。这将使重现任何甚至边缘的情况变得容易。最佳修复日期是什么?处理程序使用PostgreSQL函数计算居民的年龄AGE,该函数将第一个参数作为需要计算年龄的日期,将第二个参数作为基准日期(由常量定义TownAgeStatView.CURRENT_DATE)。我们将处理程序中的基准日期替换为测试时间from unittest.mock import patch
import pytz
CURRENT_DATE = datetime(2020, 2, 17, tzinfo=pytz.utc)
@patch('analyzer.api.handlers.TownAgeStatView.CURRENT_DATE', new=CURRENT_DATE)
async def test_get_ages(...):
...
为了测试处理程序,我选择了以下数据集(对于所有指示一个城市的居民,因为处理程序按城市汇总结果):- 与几位生日为明天(年龄-364天)的居民进行卸货。检查处理器在计算中仅使用整整年数。
- 与今天(年龄-刚好是几年)生日的居民一起卸货。它检查区域情况-今天不应将其生日减去今天的居民的年龄再减去1年。
- 空卸货。处理程序不应该掉在上面。
计算百分位数的numpy基准- 带有线性插值,以及我为它们计算的测试基准结果。您还需要将分数百分比值四舍五入到小数点后两位。如果使用PostgreSQL在处理程序中进行四舍五入,并使用Python计算参考数据,则可能会注意到在Python 3和PostgreSQL中四舍五入会产生不同的结果。例如# Python 3
round(2.5)
> 2
-- PostgreSQL
SELECT ROUND(2.5)
> 3
事实是,Python使用四舍五入到最接近的偶数,而PostgreSQL 使用数学(半数)。如果在PostgreSQL中执行计算和舍入,那么在测试中也使用数学舍入是正确的。最初,我以文本格式描述了具有出生日期的数据集,但是阅读这种格式的测试很不方便:每次我不得不计算脑海中每个居民的年龄以记住特定数据集正在检查的内容时。当然,您可以通过代码中的注释来解决问题,但是我决定走得更远,并编写了一个函数age2date,该函数可以让您以年龄的形式描述出生日期:年数和天数。像这样import pytz
from analyzer.utils.testing import generate_citizen
CURRENT_DATE = datetime(2020, 2, 17, tzinfo=pytz.utc)
def age2date(years: int, days: int = 0, base_date=CURRENT_DATE) -> str:
birth_date = copy(base_date).replace(year=base_date.year - years)
birth_date -= timedelta(days=days)
return birth_date.strftime(BIRTH_DATE_FORMAT)
generate_citizen(birth_date='17.02.2009')
generate_citizen(birth_date=age2date(years=11))
为了确保处理程序能够区分不同卸货的居民,我为来自另一城市的一名居民添加了另一项卸货:如果处理程序错误地使用了卸货,结果中将出现一个额外的城市,并且测试将中断。一个有趣的事实:当我在2020年2月29日编写此测试时,由于Faker中的一个错误,我突然停止了向居民产生卸载(2020年是leap年,而Faker选择的其他年份也并非总是leap年)不是2月29日)。记住要记录日期并测试边缘情况!
移居
迁移代码乍一看似乎很明显,而且最不容易出错,为什么要进行测试?这是一个非常危险的错误:最隐蔽的迁移错误会在最不适当的时刻表现出来。即使它们不会破坏数据,也可能导致不必要的停机时间。项目中存在的初始迁移会更改数据库的结构,但不会更改数据。哪些常见错误可以防止此类迁移?downgrade ( , , ).
, (--): , — .
- C .
- ( ).
这些错误大多数将通过楼梯测试检测到。他的想法-用一个单一的迁移,始终执行方法upgrade,downgrade,upgrade每个迁移。这样的测试足以将其添加到项目中一次,它不需要支持并且会忠实地服务。但是,如果迁移除了结构之外还会更改数据,则有必要编写至少一个单独的测试,以检查方法中的数据正确更改upgrade并返回中的初始状态downgrade。以防万一:一个带有测试不同迁移示例的项目,我准备了一份有关莫斯科Python中Alembic的报告。部件
我们将要部署的最终构件以及作为组装结果要获得的构件是Docker映像。要构建,必须使用Python 选择基本映像。官方映像的大小python:latest约为1 GB,如果用作基本映像,则带有应用程序的映像将很大。有些图像基于Alpine OS,其尺寸要小得多。但是,随着安装的软件包数量的增加,最终映像的大小将增加,结果,即使基于Alpine收集的映像也不会那么小。我选择了snakepacker / python作为基本映像-它比Alpine映像重一些,但是基于Ubuntu,Ubuntu提供了大量的软件包和库。另一种方式减少应用程序的映像大小 -在最终映像中不要包括带有程序集头的编译器,库和文件,而应用程序不需要这些文件,程序库和文件头。为此,您可以使用Docker 的多阶段组装:- 使用“大量”映像
snakepacker/python:all(〜1 GB,〜500 MB压缩),创建一个虚拟环境,将所有依赖项和应用程序包安装到其中。该映像是组装专用的,它可以包含编译器,所有必需的库和带标头的文件。
FROM snakepacker/python:all as builder
RUN python3.8 -m venv /usr/share/python3/app
COPY dist/ /mnt/dist/
RUN /usr/share/python3/app/bin/pip install /mnt/dist/*
- 我们将完成的虚拟环境复制到一个“轻量”映像
snakepacker/python:3.8(约100 MB,压缩后约50 MB)中,该映像仅包含所需版本的Python的解释器。
重要说明:在虚拟环境中,使用绝对路径,因此必须将其复制到在收集器容器中组装时所使用的相同地址。
FROM snakepacker/python:3.8 as api
COPY --from=builder /usr/share/python3/app /usr/share/python3/app
RUN ln -snf /usr/share/python3/app/bin/analyzer-* /usr/local/bin/
CMD ["analyzer-api"]
为了减少构建映像所花费的时间,可以在将其安装到虚拟环境中之前安装与应用程序相关的模块。然后,Docker将缓存它们,并且如果它们没有更改,将不会重新安装。完全Dockerfile
FROM snakepacker/python:all as builder
RUN python3.8 -m venv /usr/share/python3/app
RUN /usr/share/python3/app/bin/pip install -U pip
COPY requirements.txt /mnt/
RUN /usr/share/python3/app/bin/pip install -Ur /mnt/requirements.txt
COPY dist/ /mnt/dist/
RUN /usr/share/python3/app/bin/pip install /mnt/dist/* \
&& /usr/share/python3/app/bin/pip check
FROM snakepacker/python:3.8 as api
COPY --from=builder /usr/share/python3/app /usr/share/python3/app
RUN ln -snf /usr/share/python3/app/bin/analyzer-* /usr/local/bin/
CMD ["analyzer-api"]
为了便于组装,我添加了一个命令make upload,该命令收集Docker映像并将其上传到hub.docker.com。词
现在,代码已包含测试,并且我们可以构建Docker映像,是时候使这些过程自动化。想到的第一件事是:运行测试以创建池请求,并在向master分支添加更改时,收集一个新的Docker映像并将其上传到Docker Hub(或GitHub Packages,如果您不打算公开分发该映像)。我使用GitHub Actions解决了这个问题。为此,必须在文件夹中创建一个YAML文件,.github/workflows并在其中描述一个工作流程(包含两个任务:test和publish),我将其命名为CI。每当使用服务启动工作流时,都会执行该任务testCI使用PostgreSQL拾取一个容器,等待它可用,然后pytest在容器中启动snakepacker/python:all。该任务publish只有在变化已被添加到分支执行master,如果任务test成功。它通过容器收集源代码分发snakepacker/python:all,然后使用收集并加载Docker映像docker/build-push-action@v1。工作流程的完整描述name: CI
# Workflow
# - master
on:
push:
branches: [ master ]
pull_request:
branches: [ master ]
jobs:
# workflow
test:
runs-on: ubuntu-latest
services:
postgres:
image: docker://postgres
ports:
- 5432:5432
env:
POSTGRES_USER: user
POSTGRES_PASSWORD: hackme
POSTGRES_DB: analyzer
steps:
- uses: actions/checkout@v2
- name: test
uses: docker://snakepacker/python:all
env:
CI_ANALYZER_PG_URL: postgresql://user:hackme@postgres/analyzer
with:
args: /bin/bash -c "pip install -U '.[dev]' && pylama && wait-for-port postgres:5432 && pytest -vv --cov=analyzer --cov-report=term-missing tests"
# Docker-
publish:
# master
if: github.event_name == 'push' && github.ref == 'refs/heads/master'
# , test
needs: test
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: sdist
uses: docker://snakepacker/python:all
with:
args: make sdist
- name: build-push
uses: docker/build-push-action@v1
with:
username: ${{ secrets.REGISTRY_LOGIN }}
password: ${{ secrets.REGISTRY_TOKEN }}
repository: alvassin/backendschool2019
target: api
tags: 0.0.1, latest
现在,在GitHub的“操作”选项卡中向主服务器添加更改时,您可以看到测试的启动,Docker映像的组装和加载: 并且在master分支中创建池请求时,任务的结果也将显示在其中
并且在master分支中创建池请求时,任务的结果也将显示在其中test:
部署
要将应用程序部署在提供的服务器上,您需要安装Docker,Docker Compose,使用应用程序和PostgreSQL启动容器并应用迁移。使用Ansible的配置管理系统可以自动执行这些步骤。它是用Python编写的,不需要特殊的代理(直接通过ssh连接),使用jinja模板,并允许在YAML文件中声明性地描述所需的状态。声明性方法使您不必考虑系统的当前状态以及使系统进入所需状态所需的操作。所有这些工作都靠在Ansible模块的肩膀上。Ansible允许您将逻辑上相关的任务分组为角色,然后重用它们。我们将需要两个角色:docker(安装和配置Docker)和analyzer(安装和配置应用程序)。该角色docker将包含Docker的存储库添加到系统,安装并配置软件包docker-ce和docker-compose。(可选)您可以将REST API设置为在服务器重新引导后自动恢复。 Ubuntu允许您借助初始化系统解决此问题systemd。它控制代表各种资源(守护程序,套接字,安装点和其他)的单元。要将新单元添加到systemd,必须在单独的.service文件中描述其配置,并将该文件放置在一个特殊文件夹中,例如/etc/systemd/system。然后可以启动该设备,并为其启用自动加载功能。包docker-ce在安装过程中,它将自动创建具有设备配置的文件-您只需要确保该文件正在运行并在系统启动时打开即可。对于Docker,Compose docker-compose@.service将由Ansible创建。@名称中的符号向systemd指示该单元是模板。这使您可以docker-compose使用参数启动服务-例如,使用我们的服务名称,该名称将被替换,而不是%i在单元配置文件中:[Unit]
Description=%i service with docker compose
Requires=docker.service
After=docker.service
[Service]
Type=oneshot
RemainAfterExit=true
WorkingDirectory=/etc/docker/compose/%i
ExecStart=/usr/local/bin/docker-compose up -d --remove-orphans
ExecStop=/usr/local/bin/docker-compose down
[Install]
WantedBy=multi-user.target
该角色将从analyzerdocker-compose.yml地址处的模板生成文件/etc/docker/compose/analyzer,将应用程序注册为自动启动的服务,systemd然后应用迁移。角色准备好后,您需要描述剧本。---
- name: Gathering facts
hosts: all
become: yes
gather_facts: yes
- name: Install docker
hosts: docker
become: yes
gather_facts: no
roles:
- docker
- name: Install analyzer
hosts: api
become: yes
gather_facts: no
roles:
- analyzer
主机列表以及角色中使用的变量可以在清单文件中指定hosts.ini。[api]
130.193.51.154
[docker:children]
api
[api:vars]
analyzer_image = alvassin/backendschool2019
analyzer_pg_user = user
analyzer_pg_password = hackme
analyzer_pg_dbname = analyzer
准备好所有Ansible文件后,运行它:$ ansible-playbook -i hosts.ini deploy.yml
关于压力测试, , . , -
. : , — , 10 . , (, , CI-): .
, , , 10 . ? , , . , , .
RPS, : . , ,
import_id,
POST /imports . .
, Python 3,
Locust.
,
locustfile.py locust. - .
Locust . , .
self.round .
locustfile.py
import logging
from http import HTTPStatus
from locust import HttpLocust, constant, task, TaskSet
from locust.exception import RescheduleTask
from analyzer.api.handlers import (
CitizenBirthdaysView, CitizensView, CitizenView, TownAgeStatView
)
from analyzer.utils.testing import generate_citizen, generate_citizens, url_for
class AnalyzerTaskSet(TaskSet):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.round = 0
def make_dataset(self):
citizens = [
generate_citizen(citizen_id=1, relatives=[2]),
generate_citizen(citizen_id=2, relatives=[1]),
*generate_citizens(citizens_num=9998, relations_num=1000,
start_citizen_id=3)
]
return {citizen['citizen_id']: citizen for citizen in citizens}
def request(self, method, path, expected_status, **kwargs):
with self.client.request(
method, path, catch_response=True, **kwargs
) as resp:
if resp.status_code != expected_status:
resp.failure(f'expected status {expected_status}, '
f'got {resp.status_code}')
logging.info(
'round %r: %s %s, http status %d (expected %d), took %rs',
self.round, method, path, resp.status_code, expected_status,
resp.elapsed.total_seconds()
)
return resp
def create_import(self, dataset):
resp = self.request('POST', '/imports', HTTPStatus.CREATED,
json={'citizens': list(dataset.values())})
if resp.status_code != HTTPStatus.CREATED:
raise RescheduleTask
return resp.json()['data']['import_id']
def get_citizens(self, import_id):
url = url_for(CitizensView.URL_PATH, import_id=import_id)
self.request('GET', url, HTTPStatus.OK,
name='/imports/{import_id}/citizens')
def update_citizen(self, import_id):
url = url_for(CitizenView.URL_PATH, import_id=import_id, citizen_id=1)
self.request('PATCH', url, HTTPStatus.OK,
name='/imports/{import_id}/citizens/{citizen_id}',
json={'relatives': [i for i in range(3, 10)]})
def get_birthdays(self, import_id):
url = url_for(CitizenBirthdaysView.URL_PATH, import_id=import_id)
self.request('GET', url, HTTPStatus.OK,
name='/imports/{import_id}/citizens/birthdays')
def get_town_stats(self, import_id):
url = url_for(TownAgeStatView.URL_PATH, import_id=import_id)
self.request('GET', url, HTTPStatus.OK,
name='/imports/{import_id}/towns/stat/percentile/age')
@task
def workflow(self):
self.round += 1
dataset = self.make_dataset()
import_id = self.create_import(dataset)
self.get_citizens(import_id)
self.update_citizen(import_id)
self.get_birthdays(import_id)
self.get_town_stats(import_id)
class WebsiteUser(HttpLocust):
task_set = AnalyzerTaskSet
wait_time = constant(1)
100 c , , :

, ( — 95 , — ). .

— Ansible ~20.15 ~20.30 Locust.

还有什么可以做的?
对应用程序进行性能分析表明,在查询的总执行时间中,约有四分之一用于序列化和反序列化JSON:从服务发送和接收了大量数据。使用orjson库可以大大加快这些过程,但是必须对服务进行一点准备- orjson它不是标准模块的直接替代品,json通常,生产需要该服务的多个副本以确保容错能力和应付负载。要管理一组服务,您需要一个工具来显示该服务的副本是否“有效”。这个问题可以通过一个处理程序来解决,该处理程序/health轮询工作所需的所有资源,在本例中为数据库。如果SELECT 1在不到一秒钟的时间内执行,该服务仍然有效。如果没有,则需要注意。当应用程序非常密集地使用网络时,uvloop可以凉爽地提高性能。一个重要因素是代码的可读性。我的一位同事Yuri Shikanov编写了一个灰色模块,该模块结合了几种用于自动验证和执行代码的工具,可以轻松地将其添加到pre-commitGit挂钩中,并使用单个配置文件或环境变量进行设置。 Gray允许您对导入(isort)进行排序,根据新版本的语言(pyupgrade)优化python表达式,在函数调用,导入,列表等末尾添加逗号(add-trailing-comma),并且还引用了一种形式(unify)。* * *
这就是我的全部:我们开发了测试,进行了测试,组装和部署了服务,还进行了负载测试。致谢
我要对那些花时间参与本文,回顾代码,介绍我的想法和评论的人表示由衷的感谢:Maria Zelenova 泽尔马,弗拉基米尔·索洛马汀 en,阿纳斯塔西娅Semenova 莫尔科夫,尤里·希卡诺夫(Yuri Shikanov) 地藏,米哈伊尔(Mikhail Shushpanov) 米舒什,帕维尔·莫辛 帕夫卡兹 特别是德米特里·奥尔洛夫(Dmitry Orlov) Orlovdl。