 膨胀表和索引(膨胀)的效果是众所周知的,不仅在Postgres中存在。有很多方法可以像VACUUM FULL或CLUSTER一样“开箱即用”处理,但是它们在操作过程中会阻塞表,因此不能总是使用。本文将对膨胀如何发生,如何处理,延迟的约束以及使用pg_repack扩展带来的问题有一些理论上的知识。本文基于我在PgConf.Russia 2020 上的演讲。
膨胀表和索引(膨胀)的效果是众所周知的,不仅在Postgres中存在。有很多方法可以像VACUUM FULL或CLUSTER一样“开箱即用”处理,但是它们在操作过程中会阻塞表,因此不能总是使用。本文将对膨胀如何发生,如何处理,延迟的约束以及使用pg_repack扩展带来的问题有一些理论上的知识。本文基于我在PgConf.Russia 2020 上的演讲。为什么会发生膨胀
Postgres基于多版本模型(MVCC)。其本质是表中的每一行可以具有多个版本,而事务处理只能看到这些版本中的一个,但不一定是同一版本。这使多个事务可以同时工作,并且几乎互不影响。显然,所有这些版本都需要存储。 Postgres逐页处理内存,而页面是可以从磁盘读取或写入的最小数据量。让我们看一个小例子,以了解这是如何发生的。假设我们有一个表,其中添加了几条记录。在存储表的文件的第一页中,出现了新数据。这些是字符串的实时版本,在提交后可用于其他事务(为简单起见,我们假定为“读已提交”隔离级别)。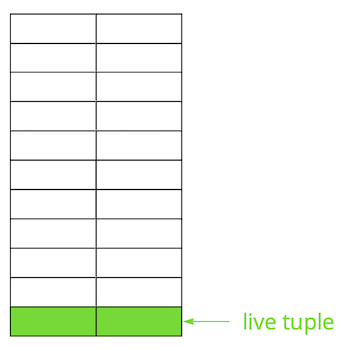 然后,我们更新了其中一项,从而将旧版本标记为不相关。
然后,我们更新了其中一项,从而将旧版本标记为不相关。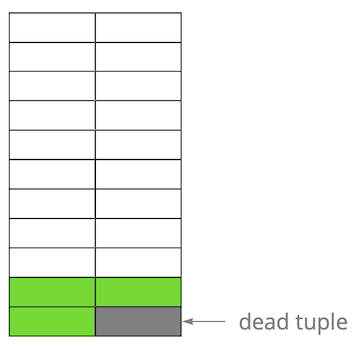 逐步,更新和删除行的版本,我们得到了一个页面,其中大约一半的数据是“垃圾”。该数据对任何交易都不可见。
逐步,更新和删除行的版本,我们得到了一个页面,其中大约一半的数据是“垃圾”。该数据对任何交易都不可见。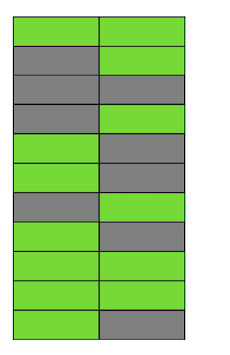 Postgres具有VACUUM机制,它会清理不相关的版本并释放新数据的空间。但是,如果没有对其进行足够积极的配置或在其他表中忙于工作,则“垃圾数据”仍然存在,我们必须使用其他页面来存储新数据。因此,在我们的示例中,该表在某个时间点将由四个页面组成,但其中只有一半的实时数据。结果,当访问表时,我们将读取比所需更多的数据。
Postgres具有VACUUM机制,它会清理不相关的版本并释放新数据的空间。但是,如果没有对其进行足够积极的配置或在其他表中忙于工作,则“垃圾数据”仍然存在,我们必须使用其他页面来存储新数据。因此,在我们的示例中,该表在某个时间点将由四个页面组成,但其中只有一半的实时数据。结果,当访问表时,我们将读取比所需更多的数据。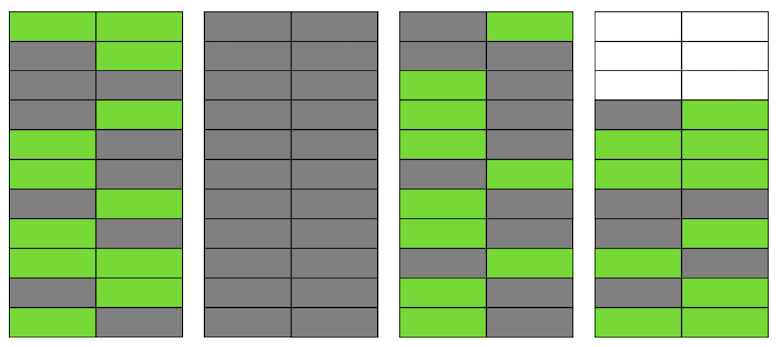 即使VACUUM现在删除了所有不相关的字符串版本,情况也不会显着改善。我们在页面甚至整个页面中都将有可用空间来换行,但是我们将继续读取比必要的更多的数据。顺便说一句,如果文件末尾有一个完全空白的页面(本例中的第二个页面),则VACUUM可以对其进行修剪。但是现在她在中间,所以她什么也做不了。
即使VACUUM现在删除了所有不相关的字符串版本,情况也不会显着改善。我们在页面甚至整个页面中都将有可用空间来换行,但是我们将继续读取比必要的更多的数据。顺便说一句,如果文件末尾有一个完全空白的页面(本例中的第二个页面),则VACUUM可以对其进行修剪。但是现在她在中间,所以她什么也做不了。 当此类空白页面或非常平坦的页面数量变大(称为膨胀)时,它开始影响性能。上面描述的所有内容都是表中出现膨胀的机制。在索引中,这发生的方式几乎相同。
当此类空白页面或非常平坦的页面数量变大(称为膨胀)时,它开始影响性能。上面描述的所有内容都是表中出现膨胀的机制。在索引中,这发生的方式几乎相同。我会肿吗?
有几种方法可以确定您是否肿胀。第一种想法是使用内部Postgres统计信息,其中包含有关表中行数,“活动”行数等的大概信息。在Internet上,您可以找到许多现成脚本的变体。我们以PostgreSQL专家的脚本为基础,该脚本可以评估bloat表以及toast和bloat btree索引。根据我们的经验,其误差为10-20%。另一种方法是使用pgstattuple扩展名,它使您可以查看页面内部并获取估计的和准确的膨胀值。但是在第二种情况下,您必须扫描整个表。我们认为可接受的小膨胀值高达20%。可以将其视为表和索引的fillfactor的类似物。在50%以上时,可能会出现性能问题。处理膨胀的方法
在Postgres中,有几种方法可以立即解决膨胀问题,但是它们并不总是适合所有人。设置AUTOVACUUM,以免发生膨胀。更准确地说,是将其保持在可接受的水平。这似乎是“船长的”建议,但实际上这并不总是容易实现的。例如,您正在通过定期更改数据架构进行开发,或者正在进行某种类型的数据迁移。因此,您的负载配置文件可能会频繁更改,并且通常,对于不同的表,负载配置文件可能会有所不同。这意味着您需要不断地在曲线之前工作,并将AUTOVACUUM调整为每个表的变化曲线。但这显然并不容易。AUTOVACUUM没有时间处理表的另一个常见原因是存在冗长的事务,由于这些事务可用数据,因此阻止了清除数据。这里的建议也很明显-摆脱挂起的事务,并最小化活动事务的时间。但是,如果应用程序的负载是OLAP和OLTP的混合,那么同时您可以有许多频繁的更新和简短的请求,以及冗长的操作-例如,生成报告。在这种情况下,值得考虑将负载分散到不同的基准,这将允许对每个基准进行更好的调整。另一个示例-即使概要文件是统一的,但是数据库承受的负载很高,即使最激进的AUTOVACUUM也可能无法应付,并且会出现膨胀。缩放(垂直或水平)是唯一的解决方案。但是,当您配置AUTOVACUUM时,情况又如何呢?VACUUM FULL命令重建表和索引的内容,只在其中保留相关数据。为了消除膨胀,它可以完美工作,但是在执行过程中,将捕获表上的排他锁(AccessExclusiveLock),这将不允许查询该表,甚至不允许进行查询。如果您有能力停止一段时间或停止一部分服务(从数十分钟到几小时,具体取决于数据库和硬件的大小),那么此选项是最佳选择。不幸的是,我们在预定的维护期间没有时间运行VACUUM FULL,因此这种方法不适合我们。集群命令它也重建表的内容,就像VACUUM FULL一样,它同时允许您指定索引,根据该索引将在磁盘上对数据进行物理排序(但是将来不能保证顺序)。在某些情况下,这对于许多查询是一个很好的优化-通过索引读取多个记录。该命令的缺点与VACUUM FULL相同-它在操作期间锁定表。REINDEX命令与前两个命令相似,但是会重建表上的特定索引或所有索引。锁稍弱一些:表上的ShareLock(防止修改,但允许您选择)和可调索引上的AccessExclusiveLock(阻止使用该索引的请求)。但是,在Postgres的版本12中,CONCURRENTLY参数,它使您可以重建索引而不会阻止并行添加,修改或删除记录。在早期版本的Postgres中,使用CREATE INDEX CONCURRENTLY可以实现类似于REINDEX CONCURRENTLY的结果。它允许您创建没有严格限制的索引(ShareUpdateExclusiveLock,它不会干扰并行查询),然后用新索引替换旧索引并删除旧索引。这消除了膨胀索引,而不会干扰您的应用程序。重要的是要考虑到,重建索引时,磁盘子系统上会有额外的负载。因此,如果索引有办法消除膨胀“热”,那么表就没有办法。各种外部扩展在这里起作用:pg_repack(以前为pg_reorg),pgcompact,pgcompacttable等。在本文的框架中,我将不对它们进行比较,而只会谈论pg_repack,经过一些改进,我们在家中使用它。pg_repack如何工作
假设我们自己有一个非常普通的表-带有索引,约束,但不幸的是膨胀。第一步是pg_repack创建一个日志表来存储有关操作期间所有更改的数据。触发器会将这些更改复制到每个插入,更新和删除操作。然后创建一个表,该表与原始结构类似,但是没有索引和限制,以免减慢插入数据的过程。接下来,pg_repack将数据从旧表传输到新表,自动过滤所有不相关的行,然后为新表创建索引。在执行所有这些操作期间,更改将累积在日志表中。下一步是将更改转移到新表。迁移是通过多次迭代执行的,当日志表中剩余少于20个条目时,pg_repack会捕获严格的锁定,并传输最新数据,并用Postgres系统表中的新表替换旧表。这是您无法使用表格的唯一且非常短的时间点。之后,将删除旧表和带有日志的表,并释放文件系统中的空间。该过程完成。从理论上讲,一切看起来都不错,实际上呢?我们测试了pg_repack的空载和有载,在过早停止的情况下检查了它的操作(换句话说,Ctrl + C)。所有测试均为阳性。我们去了产品-然后一切都出了我们所期望的错误。产品上的第一个煎饼
在第一个集群上,我们收到有关违反唯一限制的错误:$ ./pg_repack -t tablename -o id
INFO: repacking table "tablename"
ERROR: query failed:
ERROR: duplicate key value violates unique constraint "index_16508"
DETAIL: Key (id, index)=(100500, 42) already exists.
该限制具有自动生成的名称index_16508-它是由pg_repack创建的。通过其组成中包含的属性,我们确定了与其对应的“我们的”限制。问题是这不是一个普通的限制,而是一个延迟的约束,即 它的验证比sql命令晚执行,这会导致意外的后果。延迟约束:为什么需要它们以及它们如何工作
关于延迟约束的一些理论。考虑一个简单的示例:我们有一个带有两个属性的汽车参考表-目录中汽车的名称和顺序。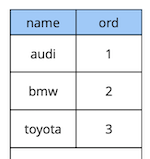
create table cars
(
name text constraint pk_cars primary key,
ord integer not null constraint uk_cars unique
);
假设我们需要交换第一和第二辆车。解决方案“在额头上”是将第一个值更新为第二个,然后将第二个更新为第一个:begin;
update cars set ord = 2 where name = 'audi';
update cars set ord = 1 where name = 'bmw';
commit;
但是执行此代码时,我们期望违反约束,因为表中值的顺序是唯一的:[23305] ERROR: duplicate key value violates unique constraint “uk_cars”
Detail: Key (ord)=(2) already exists.
怎么做不同?选项一:用保证在表中不存在的顺序(例如“ -1”)添加该值的其他替换。在编程中,这称为``通过第三个交换两个变量的值''。此方法的唯一缺点是附加更新。选项二:重新设计表以使用浮点数据类型作为订单值而不是整数。然后,将值从1更新为例如2.5时,第一条记录将自动在第二条和第三条之间“站起来”。此解决方案有效,但是有两个限制。首先,如果该值在界面中的某处使用,它将对您不起作用。其次,根据数据类型的准确性,在重新计算所有记录的值之前,您将有数量有限的可能插入。选项三:推迟限制,以便仅在提交时检查它:create table cars
(
name text constraint pk_cars primary key,
ord integer not null constraint uk_cars unique deferrable initially deferred
);
由于我们最初请求的逻辑确保提交时所有值都是唯一的,因此它将成功。上面的示例当然是非常综合的,但它揭示了这个想法。在我们的应用程序中,我们使用延迟约束来实现逻辑,该逻辑负责解决冲突,同时使用板上的常见窗口小部件对象。使用这样的限制使我们可以使应用程序代码更容易一些。通常,根据Postgres中约束的类型,检查它们的粒度分为三个级别:行级别,事务级别和表达式。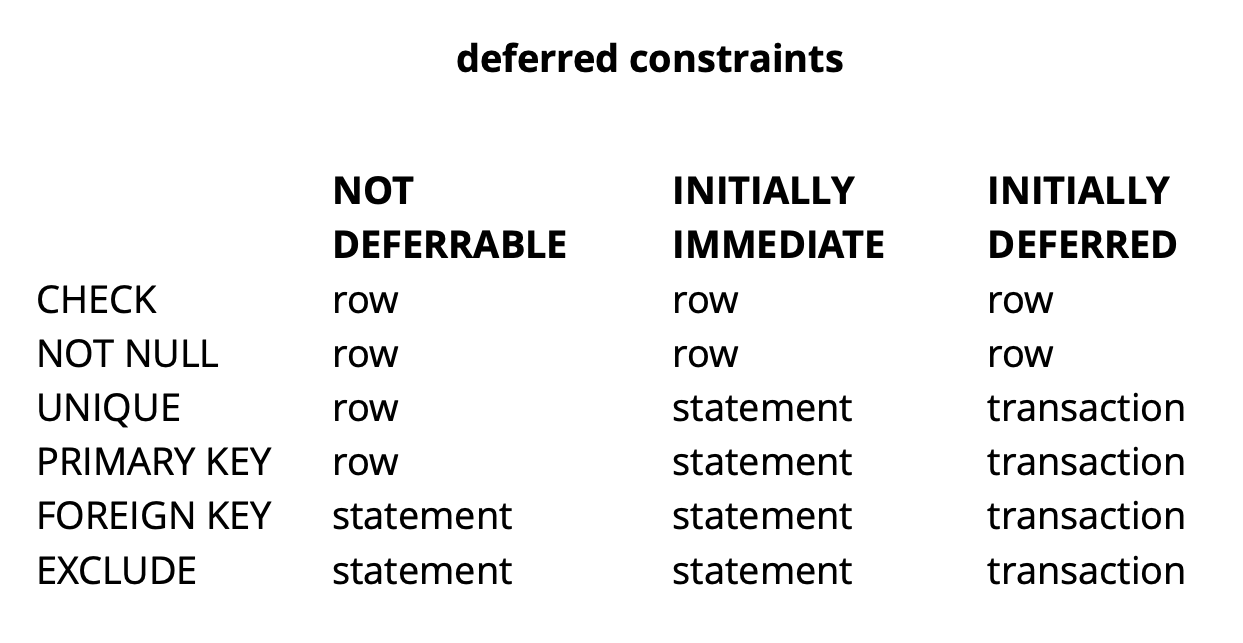 资料来源:乞gCHECK和NOT NULL总是在行级别检查,对于其他限制(从表中可以看出),有不同的选项。在这里阅读更多。简而言之,在某些情况下未决的限制提供了更具可读性的代码和更少的命令。但是,由于错误发生的时间和发现错误的时间是在时间上分开的,因此必须通过使调试过程复杂化来为此付出代价。另一个可能的问题是,如果请求中包含延迟约束,则调度程序无法始终构建最佳计划。
资料来源:乞gCHECK和NOT NULL总是在行级别检查,对于其他限制(从表中可以看出),有不同的选项。在这里阅读更多。简而言之,在某些情况下未决的限制提供了更具可读性的代码和更少的命令。但是,由于错误发生的时间和发现错误的时间是在时间上分开的,因此必须通过使调试过程复杂化来为此付出代价。另一个可能的问题是,如果请求中包含延迟约束,则调度程序无法始终构建最佳计划。精炼pg_repack
我们确定了哪些尚待解决的限制,但是它们与我们的问题有何关系?回想一下我们先前收到的错误:$ ./pg_repack -t tablename -o id
INFO: repacking table "tablename"
ERROR: query failed:
ERROR: duplicate key value violates unique constraint "index_16508"
DETAIL: Key (id, index)=(100500, 42) already exists.
它是在将数据从日志表复制到新表时发生的。看起来很奇怪,因为日志表中的数据与原始表中的数据一起提交。如果它们满足原始表的约束,那么如何违反新表中的相同约束?事实证明,问题的根源在于pg_repack的上一步,在该步骤上仅创建索引,但没有限制:旧表具有唯一约束,而新表则创建了唯一索引。 此处需要注意的重要一点是,如果该限制是正常的并且没有被推迟,那么创建而不是它的唯一索引等效于该限制,因为 通过创建唯一索引来实现Postgres唯一约束。但是在延迟约束的情况下,其行为是不一样的,因为无法延迟索引,并且总是在执行sql命令时检查索引。因此,问题的实质在于检查的“推迟”:在原始表中,它发生在提交时,而在新表中,发生在sql命令执行时。因此,我们需要确保在两种情况下都以相同的方式执行检查:总是推迟,或者总是立即执行。那么我们有什么想法?
此处需要注意的重要一点是,如果该限制是正常的并且没有被推迟,那么创建而不是它的唯一索引等效于该限制,因为 通过创建唯一索引来实现Postgres唯一约束。但是在延迟约束的情况下,其行为是不一样的,因为无法延迟索引,并且总是在执行sql命令时检查索引。因此,问题的实质在于检查的“推迟”:在原始表中,它发生在提交时,而在新表中,发生在sql命令执行时。因此,我们需要确保在两种情况下都以相同的方式执行检查:总是推迟,或者总是立即执行。那么我们有什么想法?创建类似于递延的索引
第一个想法是在即时模式下执行两项检查。这可能会引起限制的一些误报触发因素,但是如果限制因素很少,那么这不会影响用户的工作,因为对他们而言,这种冲突是正常情况。例如,当两个用户开始同时编辑同一个窗口小部件,并且第二个用户的客户端没有时间获取该窗口小部件已被第一用户编辑锁定的信息时,就会发生这种情况。在这种情况下,服务器拒绝第二个用户,并且其客户端回滚更改并阻止窗口小部件。稍后,当第一个用户完成编辑时,第二个用户将收到有关该小部件不再被锁定的信息,并将能够重复其操作。为了确保检查始终处于紧急模式,我们创建了一个类似于原始延迟约束的新索引:CREATE UNIQUE INDEX CONCURRENTLY uk_tablename__immediate ON tablename (id, index);
DROP INDEX CONCURRENTLY uk_tablename__immediate;
在测试环境中,我们仅收到一些预期的错误。成功!我们再次在产品上启动了pg_repack,在一个小时的工作中,第一个集群出现了5个错误。这是可以接受的结果。但是,在第二个集群上,错误的数量增加了很多倍,我们不得不停止pg_repack。为什么会发生?错误的可能性取决于有多少用户同时使用相同的窗口小部件。显然,当时,数据存储在第一个集群中,竞争变化比其余集群少得多,即我们只是“幸运”。这个想法没有用。那时,我们看到了另外两个解决方案选项:重写我们的应用程序代码以放弃未决的限制,或者“教” pg_repack来使用它们。我们选择了第二个。用源表中的延迟约束替换新表中的索引
修订的目的很明显-如果原始表具有延迟的约束,那么对于新表,您需要创建这样的约束,而不是索引。为了测试我们的更改,我们编写了一个简单的测试:- 有递延限制表和一项记录;
- 在循环中插入与现有记录冲突的数据;
- 进行更新-数据不再冲突;
- 提交更改。
create table test_table
(
id serial,
val int,
constraint uk_test_table__val unique (val) deferrable initially deferred
);
INSERT INTO test_table (val) VALUES (0);
FOR i IN 1..10000 LOOP
BEGIN
INSERT INTO test_table VALUES (0) RETURNING id INTO v_id;
UPDATE test_table set val = i where id = v_id;
COMMIT;
END;
END LOOP;
pg_repack的原始版本总是在第一次插入时崩溃,修订版可以正常工作。精细。我们转到产品,然后在将数据从日志表复制到新表的同一阶段再次遇到错误:$ ./pg_repack -t tablename -o id
INFO: repacking table "tablename"
ERROR: query failed:
ERROR: duplicate key value violates unique constraint "index_16508"
DETAIL: Key (id, index)=(100500, 42) already exists.
经典情况:一切都可以在测试环境下工作,但不能在生产环境下工作?APPLY_COUNT和两个批次的联合
我们开始逐行逐字逐句地分析代码,发现一个要点:将数据从日志表中批量转移到新表中,APPLY_COUNT常量指示批次的大小:for (;;)
{
num = apply_log(connection, table, APPLY_COUNT);
if (num > MIN_TUPLES_BEFORE_SWITCH)
continue;
...
}
问题在于,原始交易的数据(其中一些操作可能违反限制)可能在传输过程中传输到两批的联合中-一半的团队将在第一场比赛中提交,另一半在第二场比赛中提交。这是多么幸运的事情:如果第一批中的团队没有违反任何规则,那么一切都很好,但是如果违反了-就会发生错误。APPLY_COUNT等于1000个条目,这说明了我们的测试成功的原因-他们没有涵盖“批次连接”的情况。我们使用了两个命令-插入和更新,因此批处理中始终准确地放置了两个团队的500个事务,并且没有遇到问题。添加第二个更新后,我们的编辑停止工作:FOR i IN 1..10000 LOOP
BEGIN
INSERT INTO test_table VALUES (1) RETURNING id INTO v_id;
UPDATE test_table set val = i where id = v_id;
UPDATE test_table set val = i where id = v_id;
COMMIT;
END;
END LOOP;
因此,下一个任务是确保在一个事务中更改的源表中的数据也落入同一事务内的新表中。拒绝屠杀
同样,我们有两个解决方案。首先:让我们完全放弃批处理,并在一个事务中进行数据传输。支持此解决方案的是它的简单性-所需的代码更改最少(顺便说一下,在较旧的版本中pg_reorg就是这样工作的)。但是存在一个问题-我们正在创建一个多头交易,这正如前面所说的那样,对新的膨胀产生了威胁。第二种解决方案更复杂,但可能更正确:在日志表中创建一列,其中包含将数据添加到表中的事务的标识符。然后,在复制数据时,我们将能够通过该属性将它们分组,并确保相关的更改将一起转移。一批将由几笔交易(或一个大笔交易)组成,其大小将根据这些交易中已更改的数据量而有所不同。重要的是要注意,由于不同事务的数据以随机顺序落入日志表,因此不可能像以前一样顺序读取它。对于由tx_id过滤的每个请求,seqscan太昂贵了,您需要一个索引,但是由于更新该方法的开销,它将使该方法变慢。通常,与往常一样,您需要牺牲一些东西。因此,我们决定从第一个选项开始,作为一个简单的选项。首先,有必要了解长交易是否是一个真正的问题。由于从旧表到新表的主数据传输也发生在一个长事务中,因此问题变成了“我们将增加多少事务量?”第一次事务的持续时间主要取决于表的大小。新记录的持续时间取决于数据传输期间表中累积了多少更改,即从负载的强度。 pg_repack运行发生在服务的最小负载期间,与原始表大小相比,更改量小得无法比拟。我们决定可以忽略新事务的时间(为了进行比较,这平均为1小时2-3分钟)。实验是积极的。在产品上也运行。为了清楚起见,运行后的图片只有一个基础的大小: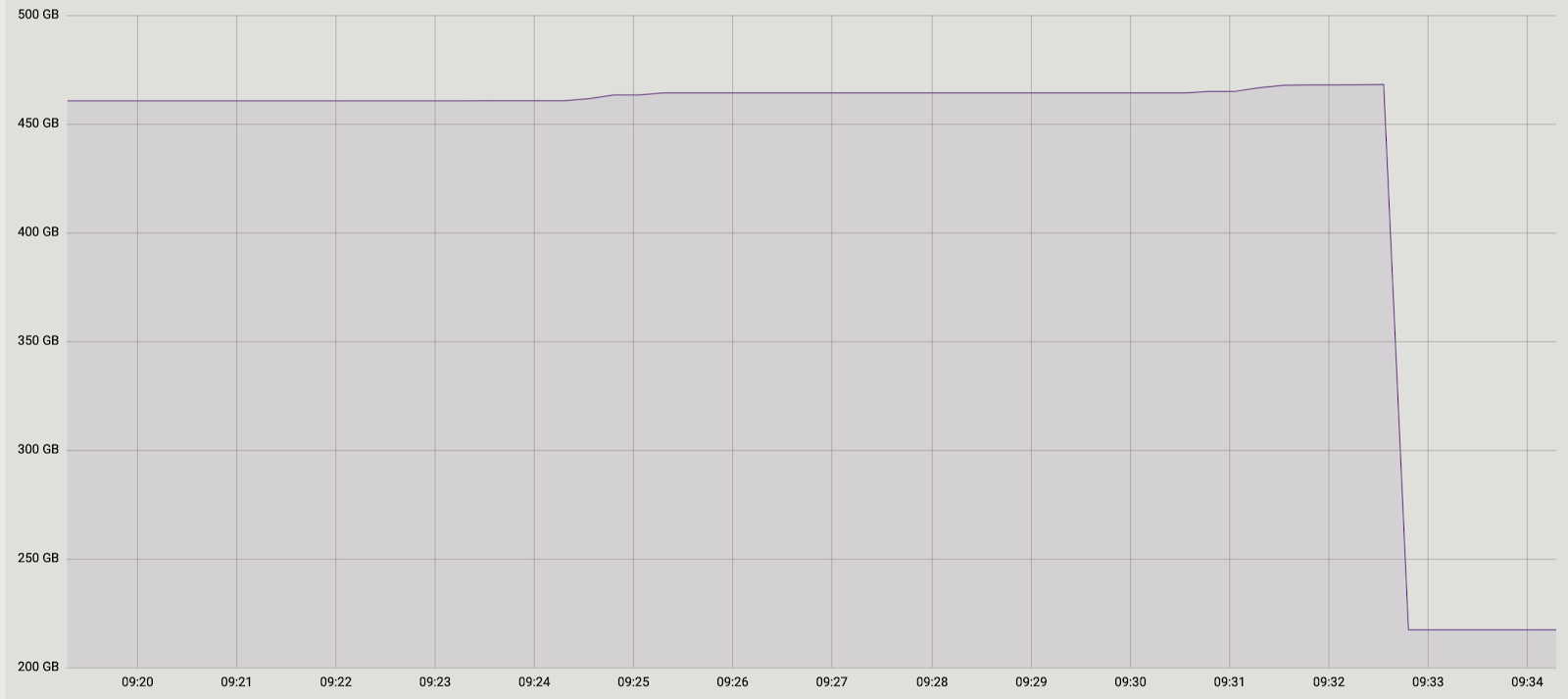 由于此解决方案完全适合我们,因此我们没有尝试实现第二个,但是我们正在考虑与扩展的开发人员讨论。不幸的是,我们的当前修订版尚未准备好发布,因为我们仅通过唯一的未决限制解决了该问题,并且对于完整的补丁程序,有必要提供其他类型的支持。我们希望将来能够做到这一点。也许您有一个问题,为什么我们在pg_repack完成后就加入了这个故事,而没有使用它的类似物?在某些时候,我们也考虑过这个问题,但是在没有待决限制的情况下在表上早点使用它的积极经验促使我们尝试理解问题的实质并加以解决。此外,要使用其他解决方案,还需要花费一些时间来进行测试,因此我们决定首先尝试解决其中的问题,如果我们意识到无法在合理的时间内解决问题,那么我们将开始考虑类似物。
由于此解决方案完全适合我们,因此我们没有尝试实现第二个,但是我们正在考虑与扩展的开发人员讨论。不幸的是,我们的当前修订版尚未准备好发布,因为我们仅通过唯一的未决限制解决了该问题,并且对于完整的补丁程序,有必要提供其他类型的支持。我们希望将来能够做到这一点。也许您有一个问题,为什么我们在pg_repack完成后就加入了这个故事,而没有使用它的类似物?在某些时候,我们也考虑过这个问题,但是在没有待决限制的情况下在表上早点使用它的积极经验促使我们尝试理解问题的实质并加以解决。此外,要使用其他解决方案,还需要花费一些时间来进行测试,因此我们决定首先尝试解决其中的问题,如果我们意识到无法在合理的时间内解决问题,那么我们将开始考虑类似物。发现
我们可以根据自己的经验推荐以下内容:- 监视您的膨胀。根据监视数据,您可以了解自动真空的配置情况。
- 设置AUTOVACUUM,以将膨胀保持在合理的水平。
- bloat “ ”, . – .
- – , .