一次,一位同事分享了他对分布式计算集群的API的想法,我开玩笑地回答:“显然,理想的API是一个简单的调用,telefork()以便您的进程在每台集群计算机上唤醒,并返回实例ID的值。”但是最后,这个主意让我占有了。我不明白为什么它如此愚蠢和简单,比任何用于远程工作的API都简单得多,以及为什么计算机系统似乎没有这种能力。我似乎也理解如何实现它,并且我已经有了一个好名字,这是任何项目中最困难的部分。所以我开始工作。在第一个周末,他做了一个基本的原型,第二个周末带来了一个可以它是什么样子的
我将代码实现为Rust库,但是从理论上讲,您可以将程序包装在C API中,然后通过FFI绑定运行以传送甚至Python进程。该实现仅约500行代码(加上200行注释):use telefork::{telefork, TeleforkLocation};
fn main() {
let args: Vec<String> = std::env::args().collect();
let destination = args.get(1).expect("expected arg: address of teleserver");
let mut stream = std::net::TcpStream::connect(destination).unwrap();
match telefork(&mut stream).unwrap() {
TeleforkLocation::Child(val) => {
println!("I teleported to another computer and was passed {}!", val);
}
TeleforkLocation::Parent => println!("Done sending!"),
};
}
我还yoyo向服务器编写了一个称为“ 电传叉” 的助手,执行传输的关闭,然后回传电叉。这产生了一种幻觉,即您可以轻松地在远程服务器上运行一段代码,例如,具有更大的处理能力。
let scene = create_scene();
let mut backbuffer = vec![Vec3::new(0.0, 0.0, 0.0); width * height];
telefork::yoyo(destination, || {
render_scene(&scene, width, height, &mut backbuffer);
});
save_png_file(width, height, &backbuffer);
Linux进程剖析
让我们看看在Linux(运行母主机OS的Linux)上的过程是什么样的telefork: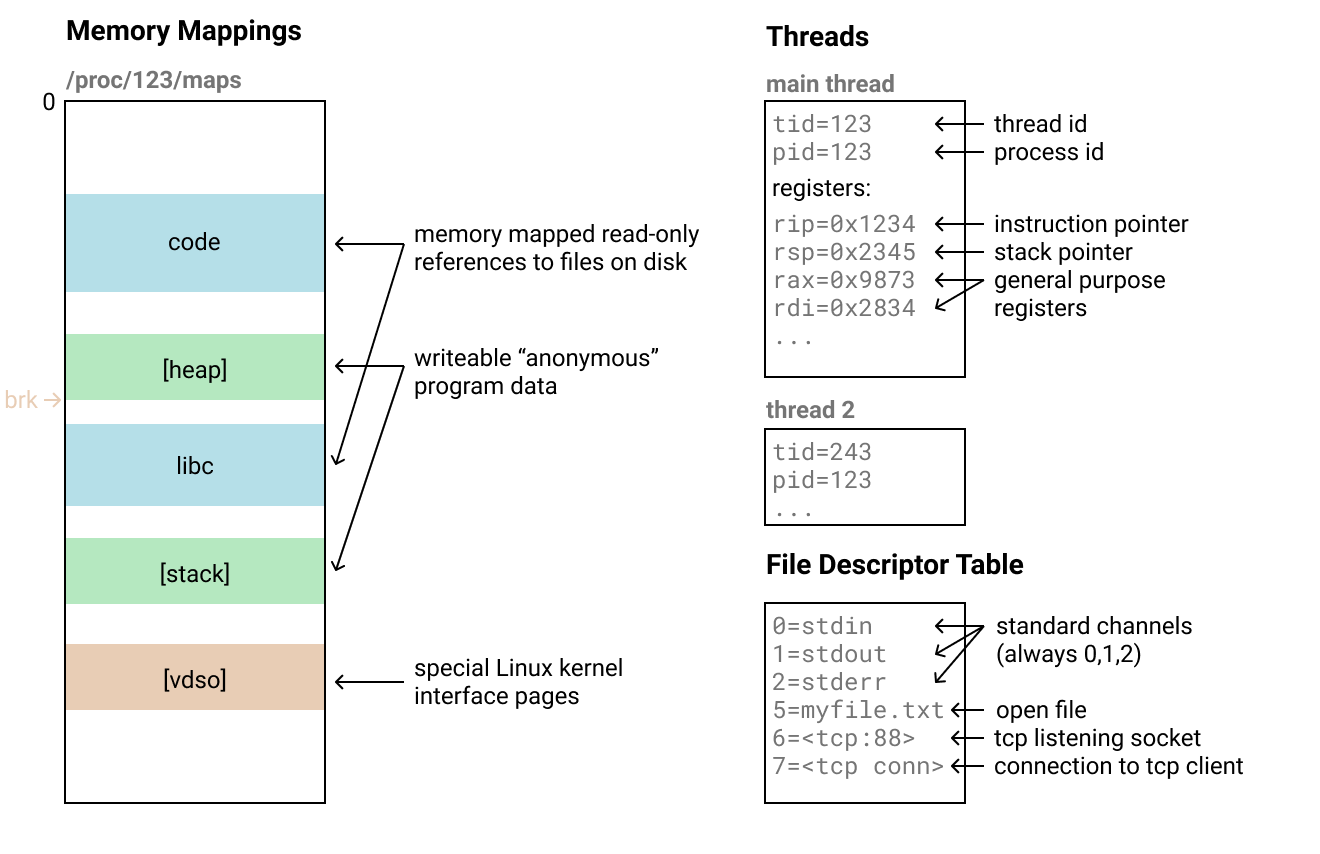
- (memory mappings): , . «» 4 .
/proc/<pid>/maps. , , .
- : , . , , - , , , . , .
- : , . - , . , , , TCP-, .
- . stdin/stdout/stderr, 0, 1 2.
- , , , .
- 杂项:进程状态的其他一些部分在复制复杂性方面有所不同。但是在大多数情况下,它们并不重要,例如brk(堆指针)。其中一些只能借助奇怪的技巧或特殊的系统调用(如PR_SET_MM_MAP)来恢复,这会使恢复过程变得复杂。
因此,基本实现telefork可以通过主线程的内存和寄存器的简单映射来完成。对于主要执行计算而不与OS资源(例如文件)进行交互的简单程序而言,这已经足够了(从原则上讲,对于传送来说,只需在系统中打开文件并在调用之前将其关闭即可telefork)。如何用电传处理
我不是第一个考虑在另一台计算机上重新创建进程的人。因此,rr调试和记录调试器的作用非常相似。我向该程序的作者@rocallahan发送了几个问题,他告诉我有关CRIU系统的信息,该系统用于在主机之间“热”迁移容器。 CRIU可以将Linux进程转移到另一个系统,支持恢复各种文件描述符和其他状态,但是,代码确实很复杂,并且使用许多需要特殊内核程序集和root权限的系统调用。使用CRIU Wiki页面上的链接,我发现为超级计算机上的分布式任务的快照创建了DMTCP,以便稍后可以重新启动它们,并且使用此程序原来的代码更简单。这些示例并没有强迫我放弃尝试实现自己的系统的尝试,因为它们是极其复杂的程序,需要特殊的运行程序和基础结构,因此,我想以库调用的形式实现尽可能简单的进程传送。因此,我研究了源代码的片段rr,CRIU,DMTCP和一些ptrace示例-并组合了自己的过程telefork。我的方法以其自己的方式工作,它融合了各种技术。要传送一个进程,您需要在调用的原始进程中做一些工作telefork,并在函数调用端进行一些工作,该函数在服务器上接收流处理并从流中重新创建它(函数telepad)它们可以同时发生,但是所有序列化也可以在下载之前完成,例如,将其拖放到文件中,然后再下载。以下是这两个过程的简化概述。如果您想详细了解,我建议阅读源代码。它包含在一个文件中,并进行了严格注释,以按顺序阅读并理解所有内容。使用提交流程 telefork
该函数telefork接收具有写功能的流,通过该流可以传输其过程的整个状态。- «» . , , . fork .
- .
/proc/<pid>/maps , . proc_maps crate.
- . DMTCP, , , . ,
[vdso], , , .
- . , , process_vm_readv , .
- 转移寄存器。我将选项
PTRACE_GETREGS用于ptrace系统调用。它允许您获取子进程寄存器的所有值。然后,我将它们写在频道的消息中。
在子进程中运行系统调用
要将目标进程转换为传入进程的副本,您将需要强制该进程对其自身执行一堆系统调用,而无需访问任何代码,因为我们删除了所有内容。我们使用ptrace进行远程系统调用,ptrace是用于处理和检查其他进程的通用系统调用:- syscall. syscall , . ,
process_vm_readv [vdso] , , , syscall Linux, . , [vdso].
- ,
PTRACE_SETREGS. syscall, rax Linux, rdi, rsi, rdx, r10, r8, r9.
- 使用参数
PTRACE_SINGLESTEP执行第一步,执行syscall命令。
- 读寄存器与
PTRACE_GETREGS恢复系统调用的返回值,看看它是否成功。
流程接受 telepad
使用这个和已经描述过的原语,我们可以重新创建过程:- 分叉一个冻结的子进程。与发送类似,但是这次我们需要一个子进程,我们可以对其进行操作以将其转换为已传输进程的克隆。
- 检查内存分配卡。这次,我们需要了解所有现有的内存分配卡,以便将其删除并为传入的进程腾出空间。
- . ,
munmap.
- .
mremap, .
- .
mmap , process_vm_writev .
- .
PTRACE_SETREGS , , rax. raise(SIGSTOP), . , telepad.
- 使用一个任意值,以便电传服务器可以传输该进程进入的TCP连接的文件描述符,并可以将数据发送回,或者在
yoyo传输回传到同一连接的情况下。
- 使用重新启动新内容的过程
PTRACE_DETACH。
更胜任的实施
我的Telefork实施的某些部分设计不完善。我知道如何修复它们,但是以目前的形式,我喜欢该系统,有时它们确实很难修复。以下是一些有趣的示例:- (vDSO).
mremap vDSO , DMTCP, , . vDSO, . - , CPU glibc vDSO . , vDSO, syscall, rr, vDSO vDSO .
brk . DMTCP, , brk , brk . , , — PR_SET_MM_MAP, .
- . Rust « », , FS GS, , , -
glibc pid tid, . CRIU, PID TID .
- . , , , / , / FUSE. , TCP-, DMTCP CRIU ,
perf_event_open.
- .
fork() Unix , , .
我认为您已经了解到,使用正确的低级接口,您可以实现某些人似乎无法实现的疯狂事情。这里有一些关于如何发展电传基本概念的想法。尽管以上大部分内容可能只能在全新的或固定的内核上完全实现:- 集群叉。Telefork的最初灵感来源是将流程流式传输到计算集群中的所有机器的想法。甚至可能会实现UDP多播或对等方法,以加快整个群集的分发。您可能还希望拥有通信原语。
- . CRIU , -
userfaultfd. , SIGSEGV mmap. , , — .
- ! , .
userfaultfd userfaultfd, , , MESI, . , , . — , . , , , . : syscall, -, syscall, . , . , , , . , , . , , ( , ) , .
我真的很喜欢它,因为这是我最喜欢的技术之一的示例-深入到鲜为人知的抽象层,该层相对容易地实现了我们认为几乎不可能实现的目标。传送计算似乎是不可能的或非常困难的。您可能会认为这将需要诸如序列化整个状态,将二进制可执行文件复制到远程计算机,然后使用特殊的命令行标志在此处启动以重新加载状态的方法。但是不,一切都简单得多。在您最喜欢的编程语言下是一个抽象层,您可以在其中选择一个相当简单的函数子集-并在周末用任何编程语言以500行代码实现对大多数纯净计算的传送。我认为这种跳到另一个抽象级别通常会导致更简单,更通用的解决方案。我的另一个类似项目是Numderline。乍一看,这样的项目似乎是极端的黑客,而且在很大程度上是这样。他们做的事情像没有人期望的那样,当它们崩溃时,它们会在抽象级别执行此操作,而在该级别上,类似的程序将不起作用–例如,文件描述符神秘地消失了。但是有时您可以正确设置抽象级别并对任何可能的情况进行编码,以便最终一切都能顺利神奇地进行。我认为这里的好例子是rr(尽管Telefork设法解决了这个问题)和虚拟机的实时云迁移(实际上是虚拟机管理程序级别的Telefork)。我还想将这些内容作为工作计算机系统替代方法的想法。为什么我们的集群计算API比将功能转换为集群的简单程序复杂得多?为什么网络系统编程比多线程复杂得多?当然,您可以给出各种各样的充分理由,但是它们通常是基于建立现有系统的示例的难度。还是通过正确的抽象或充分的努力,一切都将轻松,无缝地运行?从根本上讲,没有什么不可能的。
