
我最近进行了一项研究,其中有必要处理数十万套输入数据。对于每组-进行一些计算,将所有计算的结果收集在一起,并根据一些标准选择“最佳”。从本质上讲,这是暴力破解。使用来选择ML模型的参数时,也会发生同样的事情GridSearch。
但是,从某个角度看,即使使用来在多个进程中运行,对于一台计算机而言,计算的大小也可能变得太大joblib。或者,更准确地说,对于没有耐心的实验者来说,它变得太长了。
而且,由于在现代公寓中,您现在可以找到多台“欠载”计算机,并且该任务显然适合大规模并发-是时候组装您的家庭群集并在其上运行此类任务了。
Dask库(https://dask.org/)非常适合构建“家庭群集” 。它易于安装且对节点的要求不高,这严重降低了集群计算的“入口级别”。
要配置群集,需要在所有计算机上:
- 安装python解释器
- dask
- (scheduler) (worker)
, , — , .
(https://docs.dask.org/) . , .
python
Dask pickle, , python.
3.6 3.7 , . 3.8 - pickle.
" ", , , .
Dask
Dask pip conda
pip install dask distributed bokeh
dask, bokeh , , "-" dask dashboard.
. .
gcc, :
- MacOS xcode
- docker image docker-worker, "" ,
python:3.6-slim-buster . , python:3.6.
dask
- . . — .
$ dask-scheduler
- , .
$ dask-worker schedulerhost:8786 --nprocs 4 --nthreads 1 --memory-limit 1GB --death-timeout 120 -name MyWorker --local-directory /tmp/
nprocs / nthreads — , , . GIL -, - , numpy. .memory-limit — , . — - , . , .death-timeout — , - , . -. , , .name — -, . , "" -.local-directory — ,
- Windows
, dask-worker . , , dask-worker .
" " . NSSM (https://www.nssm.cc/).
NSSM, , , . , , - . NSSM .
NSSM . " "
Firewall
firewall: -.
, , -, — . , — . , , .
- . , .
Dask
:
from dask.distributed import Client
client = Client('scheduler_host:port')
— "" , .
, , . pandas, numpy, scikit-learn, tensorflow.
, .
, ? — pip
def install_packages():
try:
import sys, subprocess
subprocess.check_call([sys.executable, '-m', 'pip', 'install', 'mypackage'])
return (0)
except:
return (1)
from dask.distributed import Client
client = Client('scheduler:8786')
client.run(install_packages)
, , . . "" , , .
, , — .
, , Dask .
. Client upload_file(). , .
- , zip.
from dask.distributed import Client
import numpy as np
from my_module import foo
from my_package import bar
def zoo(x)
return (x**2 + 2*x + 1)
x = np.random.rand(1000000)
client = Client('scheduler:8786')
# .
#
r3 = client.map(zoo, x)
# foo bar ,
#
client.upload_file('my_module.py')
client.upload_file('my_package.zip')
#
r1 = client.map(foo, x)
r2 = client.map(bar, x)
joblib
joblib . joblib — :
joblib
from joblib import Parallel, delayed
...
res = Parallel(n_jobs=-1)(delayed(my_proc)(c, ref_data) for c in candidates)
joblib + dask
from joblib import Parallel, delayed, parallel_backend
from dask.distributed import Client
...
client = Client('scheduler:8786')
with parallel_backend('dask'):
res = Parallel(n_jobs=-1)(delayed(my_proc)(c, ref_data) for c in candidates)
, , . , — :

16 , .

— 10-20 , 200.
, - .
from joblib import Parallel, delayed, parallel_backend
from dask.distributed import Client
...
client = Client('scheduler:8786')
with parallel_backend('dask', scatter = [ref_data]):
res = Parallel(n_jobs=-1, batch_size=<N>, pre_dispatch='3*n_jobs')(delayed(my_proc)(c, ref_data) for c in candidates)
batch_size. — , , .
pre_dispatch.
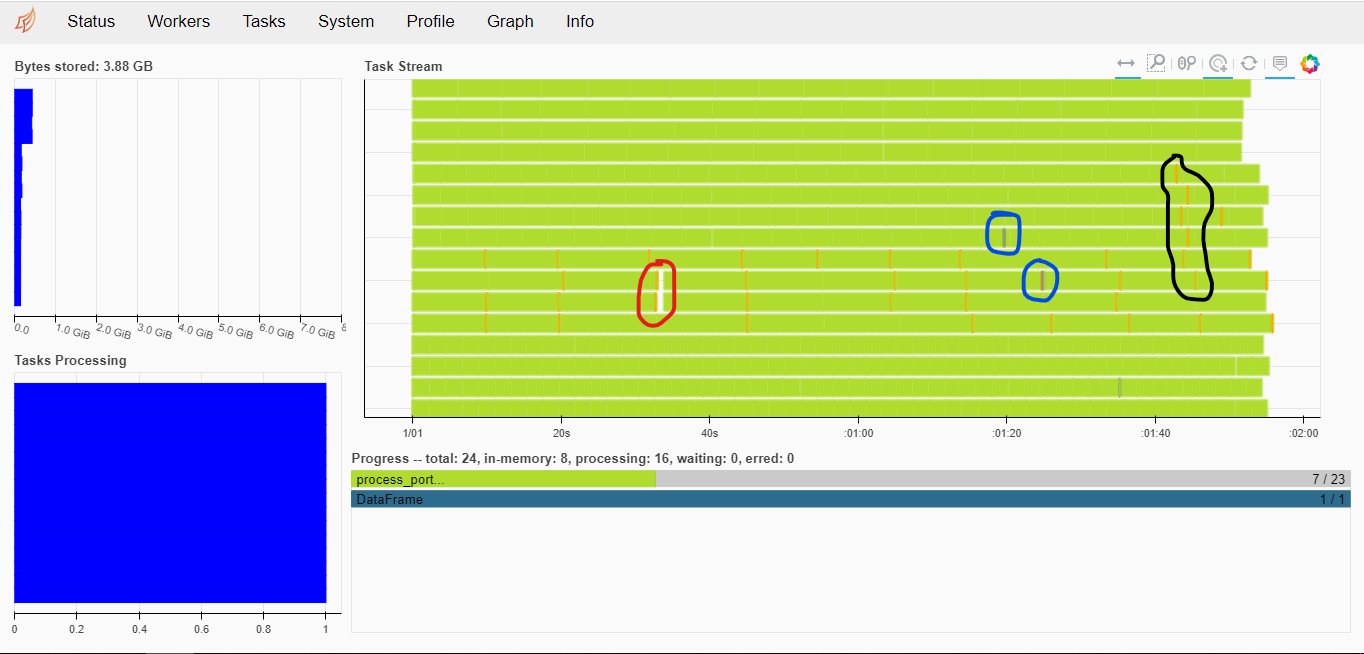
, .
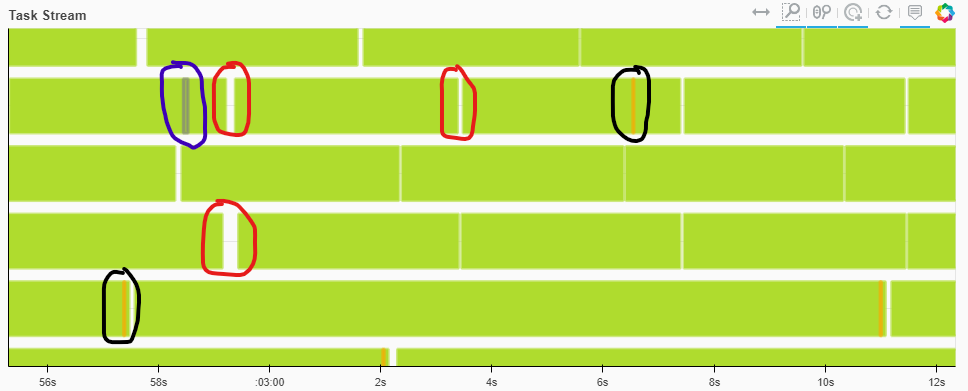
3.5-4 , . : , - , , .
, batch_size pre_dispatch . 8-10 .
, , - (, , ), scatter. .
, .
GridSearchCV
scikit-learn joblib , — dask
:
...
lr = LogisticRegression(C=1, solver="liblinear", penalty='l1', max_iter=300)
grid = {"C": 10.0 ** np.arange(-2, 3)}
cv = GridSearchCV(lr, param_grid=grid, n_jobs=-1, cv=3,
scoring='f1_weighted',
verbose=True, return_train_score=True )
client = Client('scheduler:8786')
with joblib.parallel_backend('dask'):
cv.fit(x1, y)
clf = cv.best_estimator_
print("Best params:", cv.best_params_)
print("Best score:", cv.best_score_)
:
Fitting 3 folds for each of 5 candidates, totalling 15 fits
[Parallel(n_jobs=-1)]: Using backend DaskDistributedBackend with 12 concurrent workers.
[Parallel(n_jobs=-1)]: Done 8 out of 15 | elapsed: 2.0min remaining: 1.7min
[Parallel(n_jobs=-1)]: Done 15 out of 15 | elapsed: 16.1min finished
/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/sklearn/linear_model/_logistic.py:1539: UserWarning: 'n_jobs' > 1 does not have any effect when 'solver' is set to 'liblinear'. Got 'n_jobs' = 16.
" = {}.".format(effective_n_jobs(self.n_jobs)))
Best params: {'C': 10.0}
Best score: 0.9748830491726451
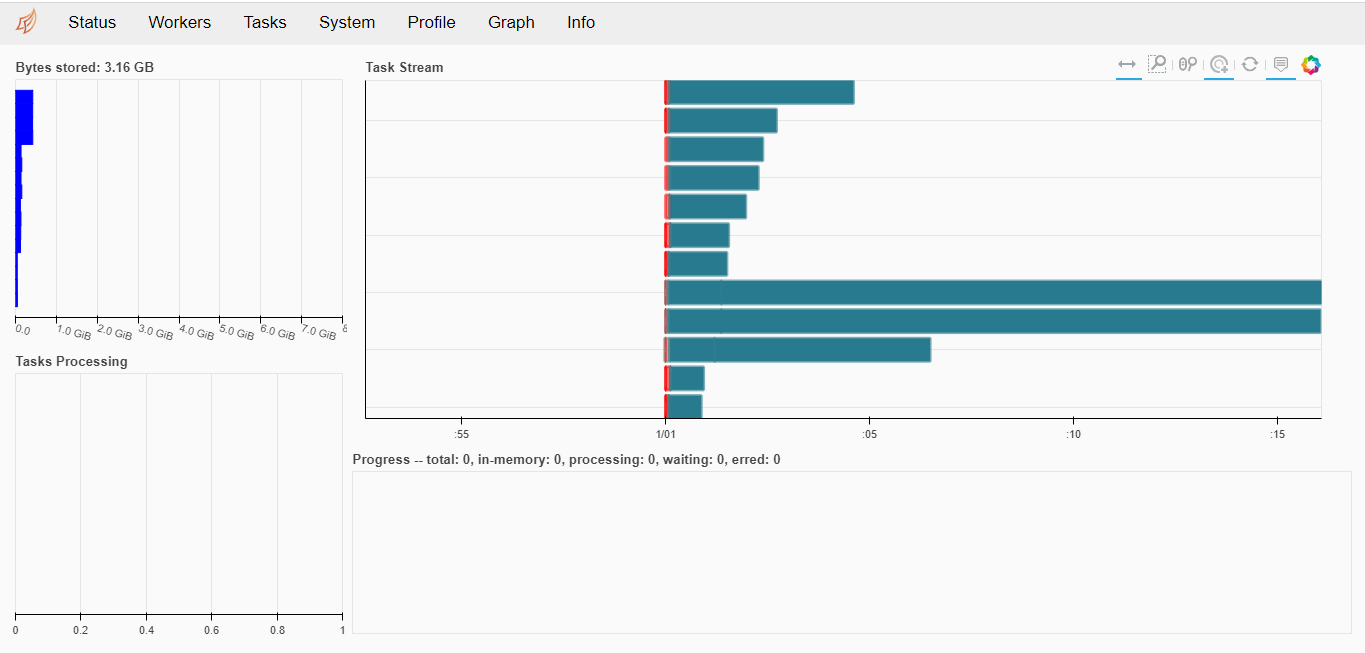
dask. -.
— .
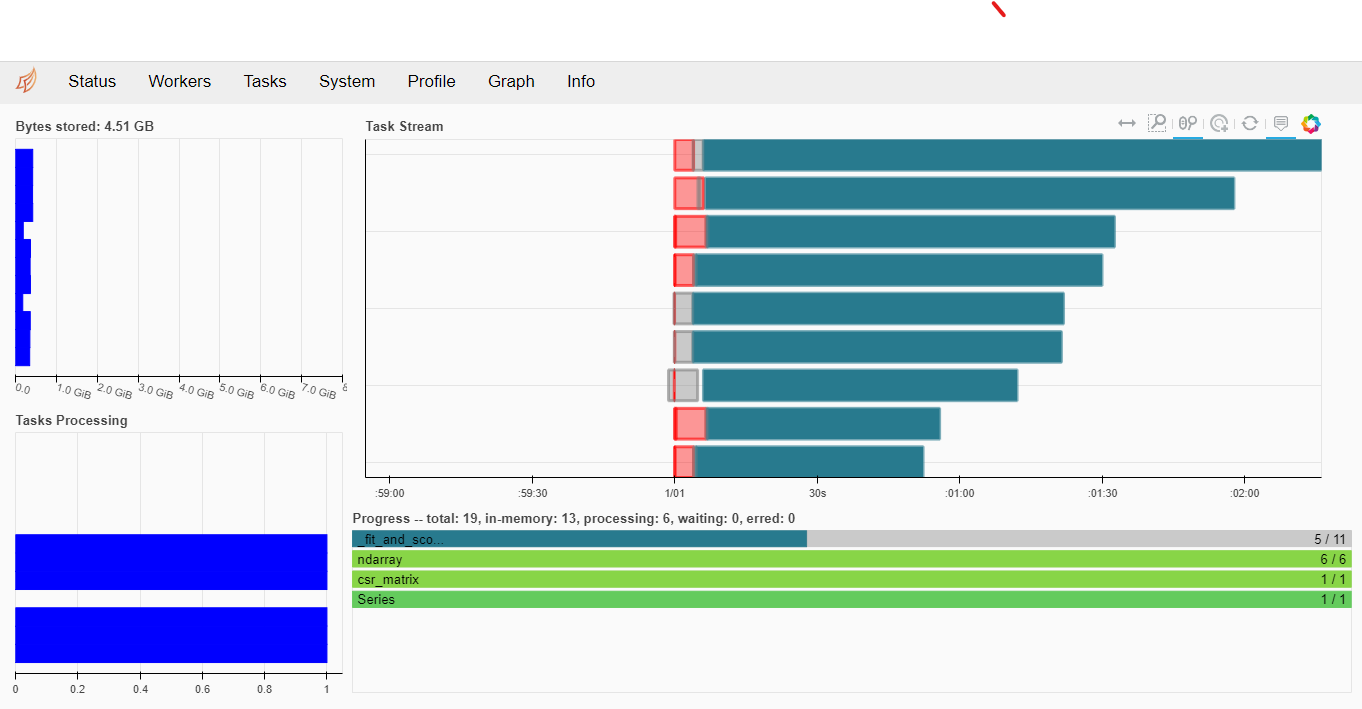
, ( ) — . — .
Dask库是用于扩展特定任务类别的出色工具。即使仅使用基本的dask.distributed,而保留了专门的扩展dask.dataframe,dask.array,dask.ml,也可以显着加快实验速度。在某些情况下,可以实现计算的几乎线性加速。
所有这些都是基于您在家中已有的东西,并用于观看视频,滚动无尽的新闻源或游戏。充分利用这些资源!