 互联网上充斥着有关基于N-gram的语言模型的文章。同时,准备就绪的库很少。有KenLM,SriLM和IRSTLM。它们很受欢迎,并在许多大型项目中使用。但是有问题:
互联网上充斥着有关基于N-gram的语言模型的文章。同时,准备就绪的库很少。有KenLM,SriLM和IRSTLM。它们很受欢迎,并在许多大型项目中使用。但是有问题:- 图书馆很老,没有发展。
- 对俄语的支持不佳。
- 仅适用于纯净,特别准备的文本
- 对UTF-8的支持不佳。例如,带有tolower标志的SriLM破坏了编码。
KenLM
从列表中脱颖而出。它得到定期支持,并且使用UTF-8不会有问题,但是对文本质量也有要求。一旦我需要一个库来构建语言模型。经过多次尝试和错误,我得出的结论是,准备用于教学语言模型的数据集太复杂且过程漫长。尤其是俄语!但是我想以某种方式使一切自动化。在研究中,他从SriLM库开始。我将立即指出,这不是代码借用或SriLM分支。所有代码都是完全从头开始编写的。一个小文本示例:
! .
句子之间缺少空格是一种很常见的错别字。在大量数据中很难找到这样的错误,同时会破坏令牌生成器。处理后,以下N-gram将出现在语言模型中:
-0.3009452 !
当然,还有许多其他问题,包括错别字,特殊字符,缩写,各种数学公式……所有这些都必须正确处理。ANYKS LM(ALM)
该库仅支持Linux,MacOS X和FreeBSD操作系统。我没有Windows,也没有计划的支持。功能简短说明
- 支持无第三方依赖项的UTF-8。
- 支持数据格式:Arpa,Vocab,映射序列,N-gram,二进制alm字典。
- : Kneser-Nay, Modified Kneser-Nay, Witten-Bell, Additive, Good-Turing, Absolute discounting.
- , , , .
- , N-, N- , N-.
- — N-, .
- : , -.
- N- — N-, backoff .
- N- backoff-.
- , : , , , , Python3.
- « », .
- 〈unk〉 .
- N- Python3.
- , .
- . : , , .
- 与其他语言模型不同,ALM保证从文本中收集所有N-gram,无论它们的长度如何(修改的Kneser-Nay除外)。所有稀有的N-gram都有强制注册的可能性,即使它们只有1次相遇也是如此。
在标准语言模型格式中,仅支持ARPA格式。老实说,我认为没有理由以各种格式支持整个动物园。ARPA格式区分大小写,这也是一个明确的问题。有时,仅了解N元语法中特定数据的存在很有用。例如,您需要了解N-gram中数字的存在,它们的含义不是那么重要。例:
, 2
结果,N-gram进入了语言模型:
-0.09521468 2
在这种情况下,具体数目并不重要。商店中的销售可以进行1、3和任意几天。为了解决此问题,ALM使用类标记。支持的令牌
标准:〈s〉 -句子开头的标记〈/ s〉 -句子的末尾标记〈unk〉 -未知单词的标记非标准:〈url〉 -URL 地址的标记〈num〉 -数字的标记(阿拉伯或罗马)〈date〉 -日期标记(2004年7月18日| 2004年7月18日)〈时间〉 -时间令牌(15:44:56)〈abbr〉 -缩写令牌(1st | 2nd | 20th)〉 anum〉 - 伪令牌数字(T34 | 895-M-86 | 39km)〈数学〉 -数学运算的记号(+ |-| = | / | * | ^)〈range〉 -数字范围的记号(1-2 | 100-200 | 300- 400)〈aprox〉-近似数字令牌(〜93 |〜95.86 | 10〜20)〈得分〉 -数字帐户令牌(4:3 | 01:04)〈dimen〉 -总体令牌(200x300 | 1920x1080)〈fract〉 -分数分数令牌(5/20 | 192/864)〈punct〉 -标点符号(。| ... |,|!|?|:|;)〈Specl〉 - 特殊符号(〜| @ |#|号|%|&| $ |§|±)〈isolat〉 -隔离符号标记(“ |'|” |“ |„ |” |`|(|)| [|] | {|})当然,如果以下情况可以禁用对每个标记的支持这样的n-gram是needed.If你需要处理其他标签(例如,你需要找到在文本国名),ALM 支持Python3中的外部脚本连接。令牌检测脚本的示例:
def init():
"""
:
"""
def run(token, word):
"""
:
@token
@word
"""
if token and (token == "<usa>"):
if word and (word.lower() == ""): return "ok"
elif token and (token == "<russia>"):
if word and (word.lower() == ""): return "ok"
return "no"
这样的脚本在标准标签列表中又增加了两个标签:〈usa〉和〈russia〉。除了令牌检测脚本之外,还支持用于已处理单词的预处理脚本。在将单词添加到语言模型之前,此脚本可以更改单词。文字处理脚本的示例:
def init():
"""
:
"""
def run(word, context):
"""
:
@word
@context
"""
return word
如果需要组装的语言模型包括这样的方法可能是有用的外稃或stemms。ALM支持的语言模型文本格式
ARPA:
\data\
ngram 1=52
ngram 2=68
ngram 3=15
\1-grams:
-1.807052 1- -0.30103
-1.807052 2 -0.30103
-1.807052 3~4 -0.30103
-2.332414 -0.394770
-3.185530 -0.311249
-3.055896 -0.441649
-1.150508 </s>
-99 <s> -0.3309932
-2.112406 <unk>
-1.807052 T358 -0.30103
-1.807052 VII -0.30103
-1.503878 -0.39794
-1.807052 -0.30103
-1.62953 -0.30103
...
\2-grams:
-0.29431 1-
-0.29431 2
-0.29431 3~4
-0.8407791 <s>
-1.328447 -0.477121
...
\3-grams:
-0.09521468
-0.166590
...
\end\
ARPA是Sphinx / CMU和Kaldi使用的自然语言模型的标准文本格式。NGRAMS:
\data\
ad=1
cw=23832
unq=9390
ngram 1=9905
ngram 2=21907
ngram 3=306
\1-grams:
<s> 2022 | 1
<num> 117 | 1
<unk> 19 | 1
<abbr> 16 | 1
<range> 7 | 1
</s> 2022 | 1
244 | 1
244 | 1
11 | 1
762 | 1
112 | 1
224 | 1
1 | 1
86 | 1
978 | 1
396 | 1
108 | 1
77 | 1
32 | 1
...
\2-grams:
<s> <num> 7 | 1
<s> <unk> 1 | 1
<s> 84 | 1
<s> 83 | 1
<s> 57 | 1
82 | 1
11 | 1
24 | 1
18 | 1
31 | 1
45 | 1
97 | 1
71 | 1
...
\3-grams:
<s> <num> </s> 3 | 1
<s> 6 | 1
<s> 4 | 1
<s> 2 | 1
<s> 3 | 1
2 | 1
</s> 2 | 1
2 | 1
2 | 1
2 | 1
2 | 1
2 | 1
</s> 2 | 1
</s> 3 | 1
2 | 1
...
\end\
Ngrams-语言模型的非标准文本格式,是ARPA格式的修改。描述:- ad- 附件中的文档数
- cw- 语料库中所有文档中的单词数
- unq- 收集的唯一单词数
VOCAB:
\data\
ad=1
cw=23832
unq=9390
\words:
33 244 | 1 | 0.010238 | 0.000000 | -3.581616
34 11 | 1 | 0.000462 | 0.000000 | -6.680889
35 762 | 1 | 0.031974 | 0.000000 | -2.442838
40 12 | 1 | 0.000504 | 0.000000 | -6.593878
330344 47 | 1 | 0.001972 | 0.000000 | -5.228637
335190 17 | 1 | 0.000713 | 0.000000 | -6.245571
335192 1 | 1 | 0.000042 | 0.000000 | -9.078785
335202 22 | 1 | 0.000923 | 0.000000 | -5.987742
335206 7 | 1 | 0.000294 | 0.000000 | -7.132874
335207 29 | 1 | 0.001217 | 0.000000 | -5.711489
2282019644 1 | 1 | 0.000042 | 0.000000 | -9.078785
2282345502 10 | 1 | 0.000420 | 0.000000 | -6.776199
2282416889 2 | 1 | 0.000084 | 0.000000 | -8.385637
3009239976 1 | 1 | 0.000042 | 0.000000 | -9.078785
3009763109 1 | 1 | 0.000042 | 0.000000 | -9.078785
3013240091 1 | 1 | 0.000042 | 0.000000 | -9.078785
3014009989 1 | 1 | 0.000042 | 0.000000 | -9.078785
3015727462 2 | 1 | 0.000084 | 0.000000 | -8.385637
3025113549 1 | 1 | 0.000042 | 0.000000 | -9.078785
3049820849 1 | 1 | 0.000042 | 0.000000 | -9.078785
3061388599 1 | 1 | 0.000042 | 0.000000 | -9.078785
3063804798 1 | 1 | 0.000042 | 0.000000 | -9.078785
3071212736 1 | 1 | 0.000042 | 0.000000 | -9.078785
3074971025 1 | 1 | 0.000042 | 0.000000 | -9.078785
3075044360 1 | 1 | 0.000042 | 0.000000 | -9.078785
3123271427 1 | 1 | 0.000042 | 0.000000 | -9.078785
3123322362 1 | 1 | 0.000042 | 0.000000 | -9.078785
3126399411 1 | 1 | 0.000042 | 0.000000 | -9.078785
…
Vocab是语言模型中的非标准文本字典格式。描述:- OC -的情况下发生
- dc- 文件中的出现
- tf - (term frequency — ) — . , , : [tf = oc / cw]
- idf - (inverse document frequency — ) — , , : [idf = log(ad / dc)]
- tf-idf - : [tf-idf = tf * idf]
- wltf - , : [wltf = 1 + log(tf * dc)]
MAP:
1:{2022,1,0}|42:{57,1,0}|279603:{2,1,0}
1:{2022,1,0}|42:{57,1,0}|320749:{2,1,0}
1:{2022,1,0}|42:{57,1,0}|351283:{2,1,0}
1:{2022,1,0}|42:{57,1,0}|379815:{3,1,0}
1:{2022,1,0}|42:{57,1,0}|26122748:{3,1,0}
1:{2022,1,0}|44:{6,1,0}
1:{2022,1,0}|48:{1,1,0}
1:{2022,1,0}|51:{11,1,0}|335967:{3,1,0}
1:{2022,1,0}|53:{14,1,0}|371327:{3,1,0}
1:{2022,1,0}|53:{14,1,0}|40260976:{7,1,0}
1:{2022,1,0}|65:{68,1,0}|34:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|3277:{3,1,0}
1:{2022,1,0}|65:{68,1,0}|278003:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|320749:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|11353430797:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|34270133320:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|51652356484:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|66967237546:{2,1,0}
1:{2022,1,0}|2842:{11,1,0}|42:{7,1,0}
…
Map-文件的内容,具有纯粹的技术含义。用于与翻译文件一起,你可以将几个语言模型,修改,存储,分发,并出口到任何格式(ARPA,n元语法,二元ALM)。ALM支持的辅助文本文件格式
通常,在组装语言模型时,在文本中会遇到拼写错误,这是字母的替换(在视觉上类似另一个字母的字母)。ALM通过使用看起来相似的字母的文件解决了此问题。p
c
o
t
k
e
a
h
x
b
m
如果在讲授语言模型时,传输带有第一级域和缩写列表的文件,则ALM可以帮助更准确地检测〈url〉和〈abbr〉类标记。缩写列表文件:
…
域区域列表文件:
ru
su
cc
net
com
org
info
…
为了更准确地检测到<url>令牌,您应该添加一级域区域(示例中的所有域区域均已预先安装)。ALM语言模型的二进制容器
要为语言模型构建二进制容器,您需要创建一个带有参数说明的JSON文件。JSON选项:
{
"aes": 128,
"name": "Name dictionary",
"author": "Name author",
"lictype": "License type",
"lictext": "License text",
"contacts": "Contacts data",
"password": "Password if needed",
"copyright": "Copyright author"
}
描述:- aes -AES加密大小(128、192、256)位
- 名称 -字典名称
- 作者 -词典作者
- lictype-许可证类型
- lictext-许可文本
- 联系人 -作者联系方式
- 密码 -加密密码(如果需要),仅在设置密码时执行加密
- 版权 -词典所有者的版权
除容器名称外,所有参数都是可选的。分词器操作
标记器在输入处接收文本,并在输出处生成JSON。$ echo 'Hello World?' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
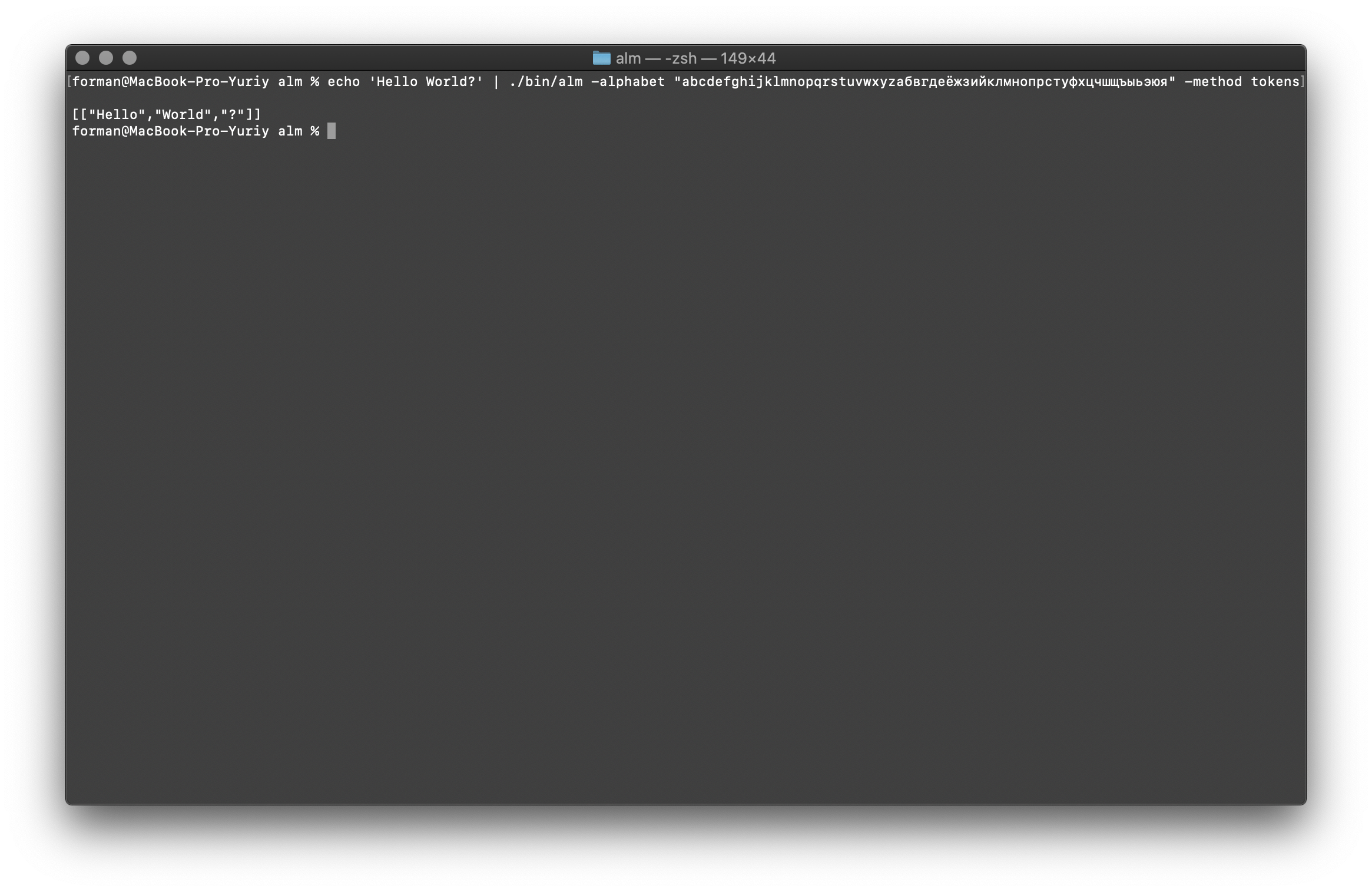 测试:
测试:Hello World?
结果:[
["Hello","World","?"]
]
让我们再努力一点...$ echo ' ??? ....' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
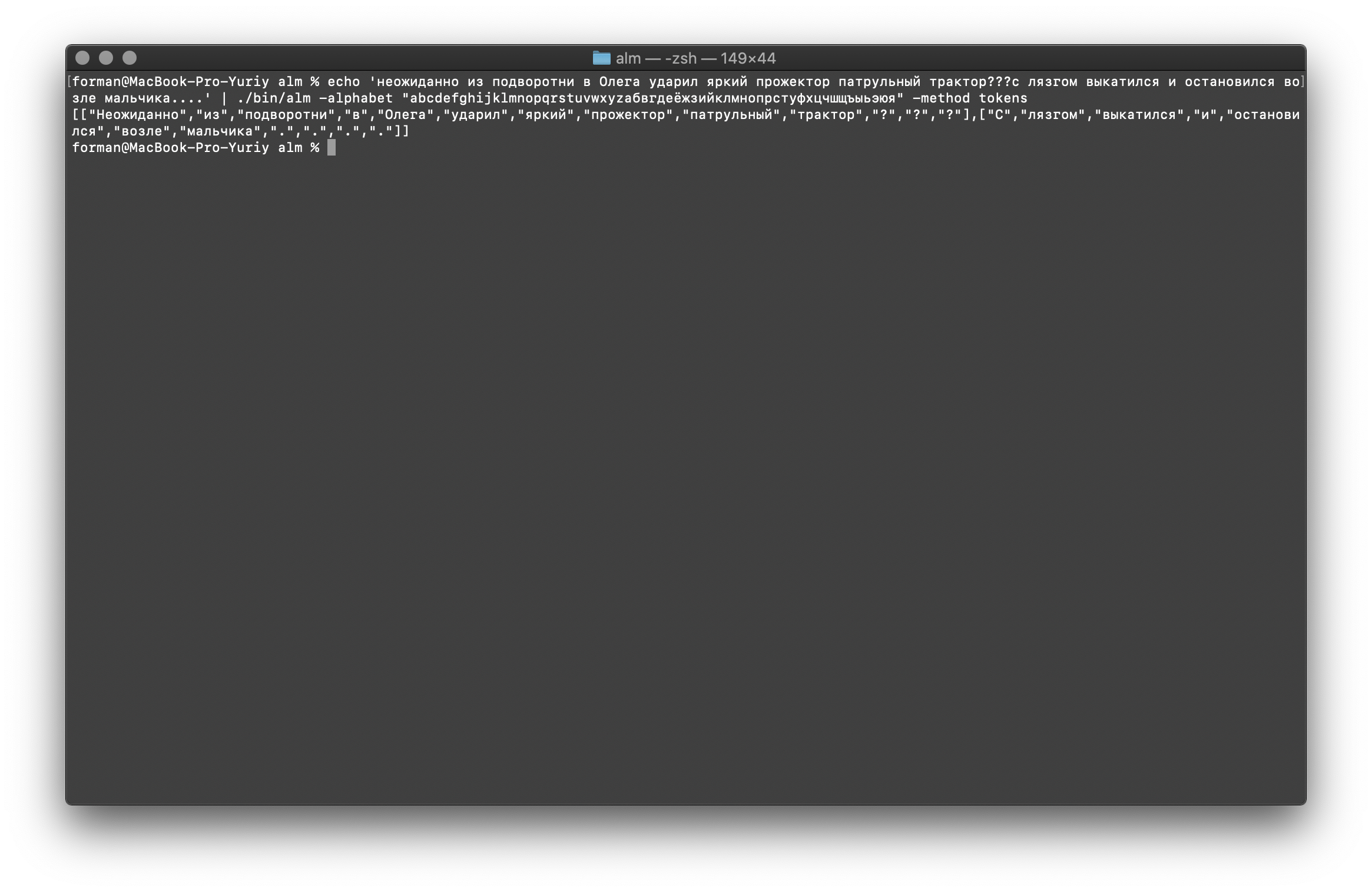 测试:
测试: ??? ....
结果:[
[
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"?",
"?",
"?"
],[
"",
"",
"",
"",
"",
"",
"",
".",
".",
".",
"."
]
]
如您所见,令牌生成器正常工作并修复了基本错误。稍微更改文本,然后查看结果。$ echo ' ... .' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
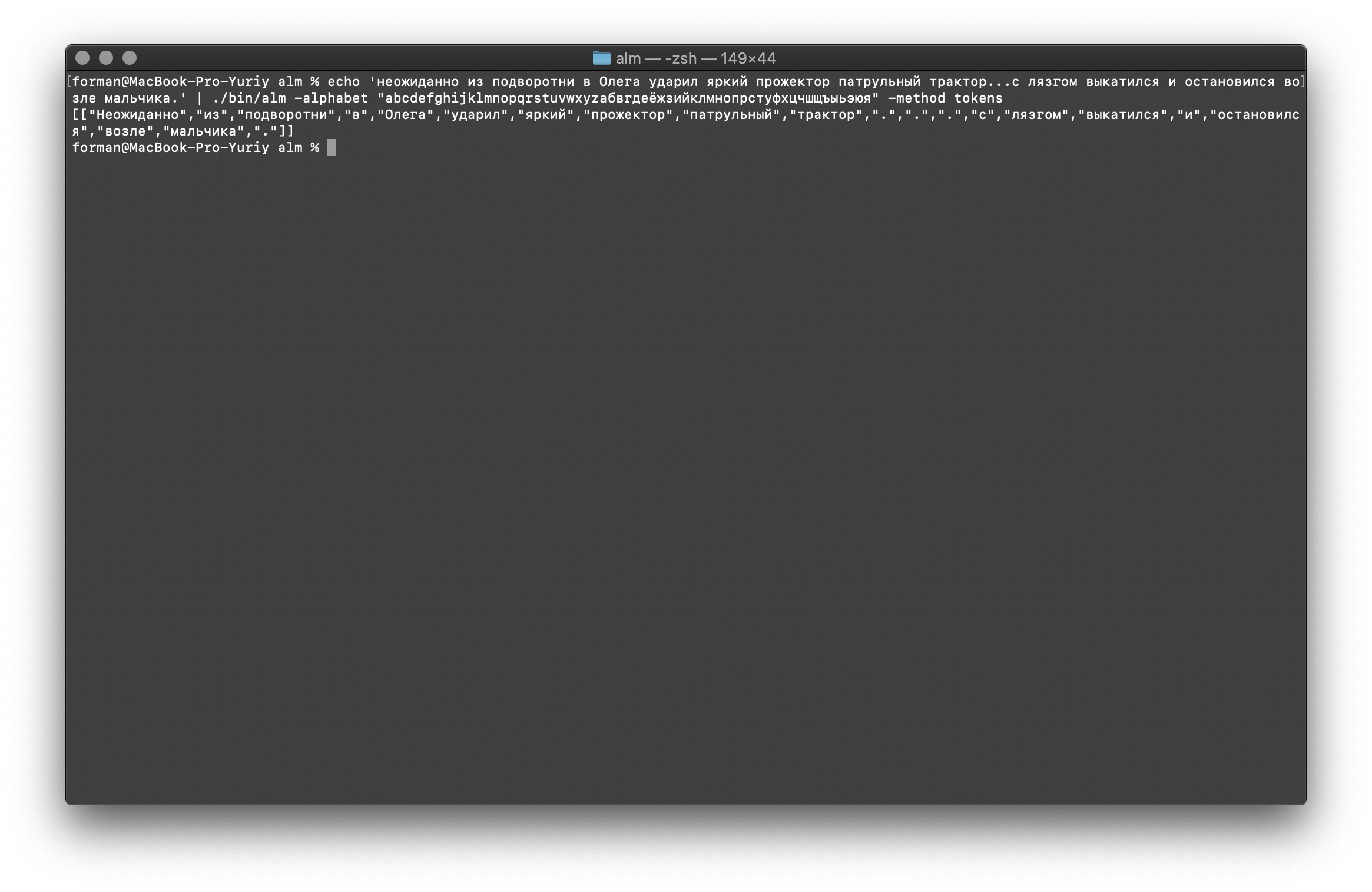 测试:
测试: ... .
结果:[
[
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
".",
".",
".",
"",
"",
"",
"",
"",
"",
"",
"."
]
]
如您所见,结果已更改。现在尝试其他方法。$ echo ' 5–7 . : 1 . ( +37–38°), 5–10 . – ( +12–15°) ..»| |()' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
 测试:
测试: 5–7 . : 1 . ( +37–38°), 5–10 . – ( +12–15°) ..»| |()
结果:[
[
"",
"",
"",
"",
"5–7",
".",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
":",
"1",
".",
"",
"",
"(",
"+37–38°",
")",
",",
"",
"5–10",
".",
"–",
"",
"",
"(",
"+12–15°",
")",
"",
"..",
"»",
"|",
"|",
"(",
")"
]
]
将所有内容合并回文本
首先,还原第一个测试。$ echo '[["Hello","World","?"]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
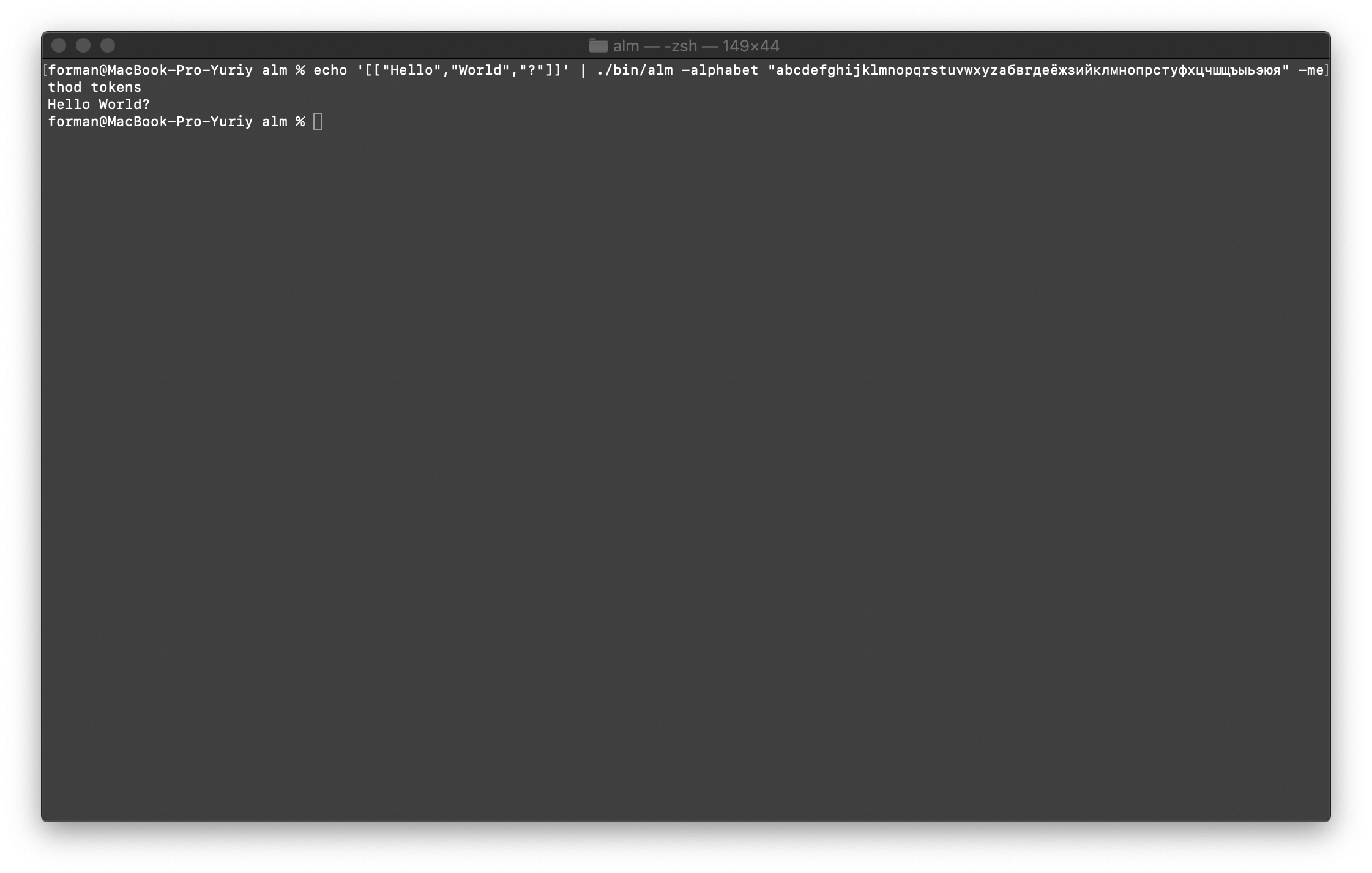 测试:
测试:[["Hello","World","?"]]
结果:Hello World?
现在,我们将还原更复杂的测试。$ echo '[["","","","","","","","","","","?","?","?"],["","","","","","","",".",".",".","."]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
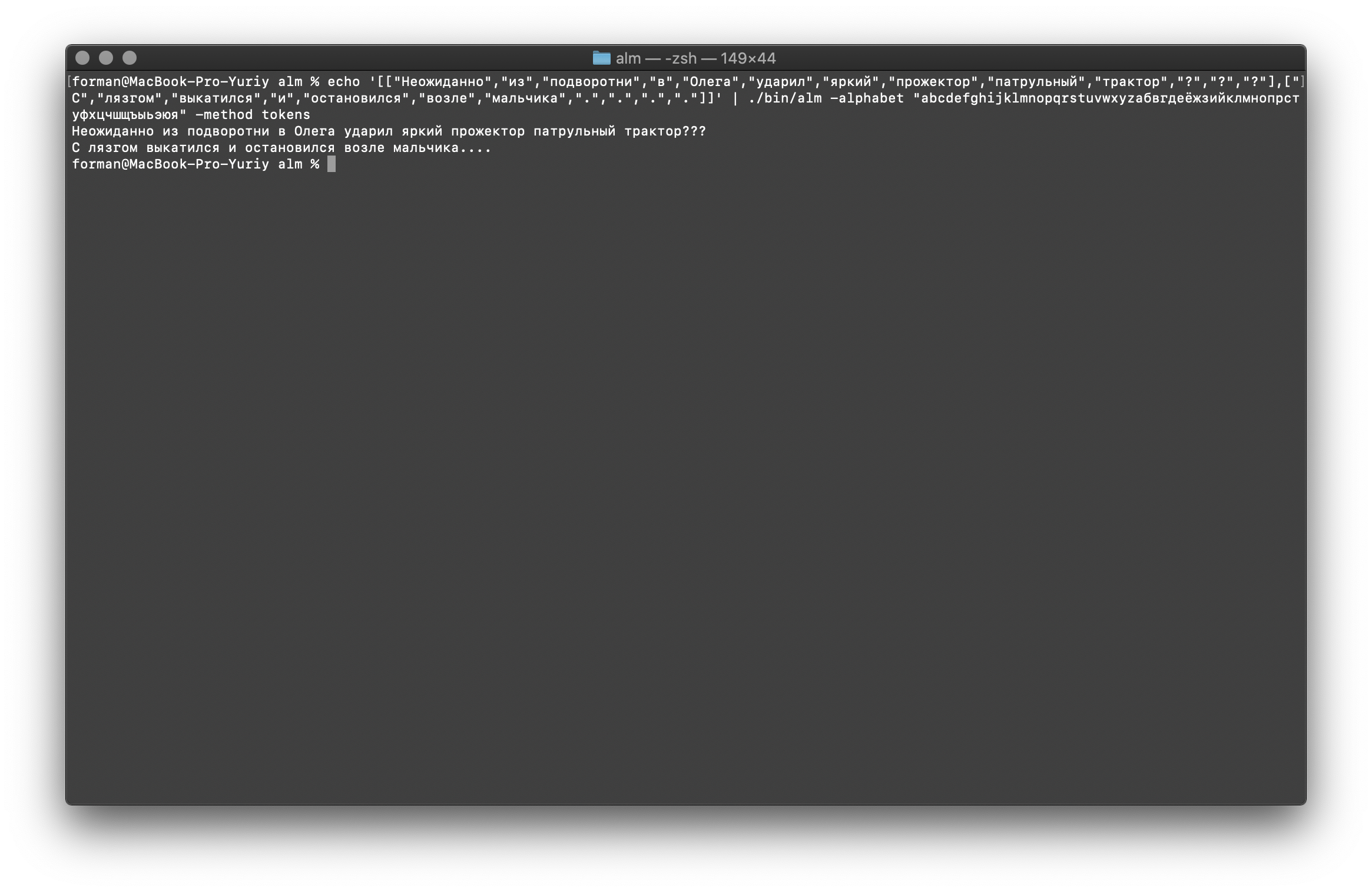 测试:
测试:[["","","","","","","","","","","?","?","?"],["","","","","","","",".",".",".","."]]
结果: ???
….
如您所见,令牌生成器能够还原最初损坏的文本。继续吧。$ echo '[["","","","","","","","","","",".",".",".","","","","","","","","."]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
 测试:
测试:[["","","","","","","","","","",".",".",".","","","","","","","","."]]
结果: ... .
最后,检查最困难的选项。$ echo '[["","","","","5–7",".","","","","","","","","","","","","","",":","1",".","","","(","+37–38°",")",",","","5–10",".","–","","","(","+12–15°",")","","..","»","|","|","(",")"]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
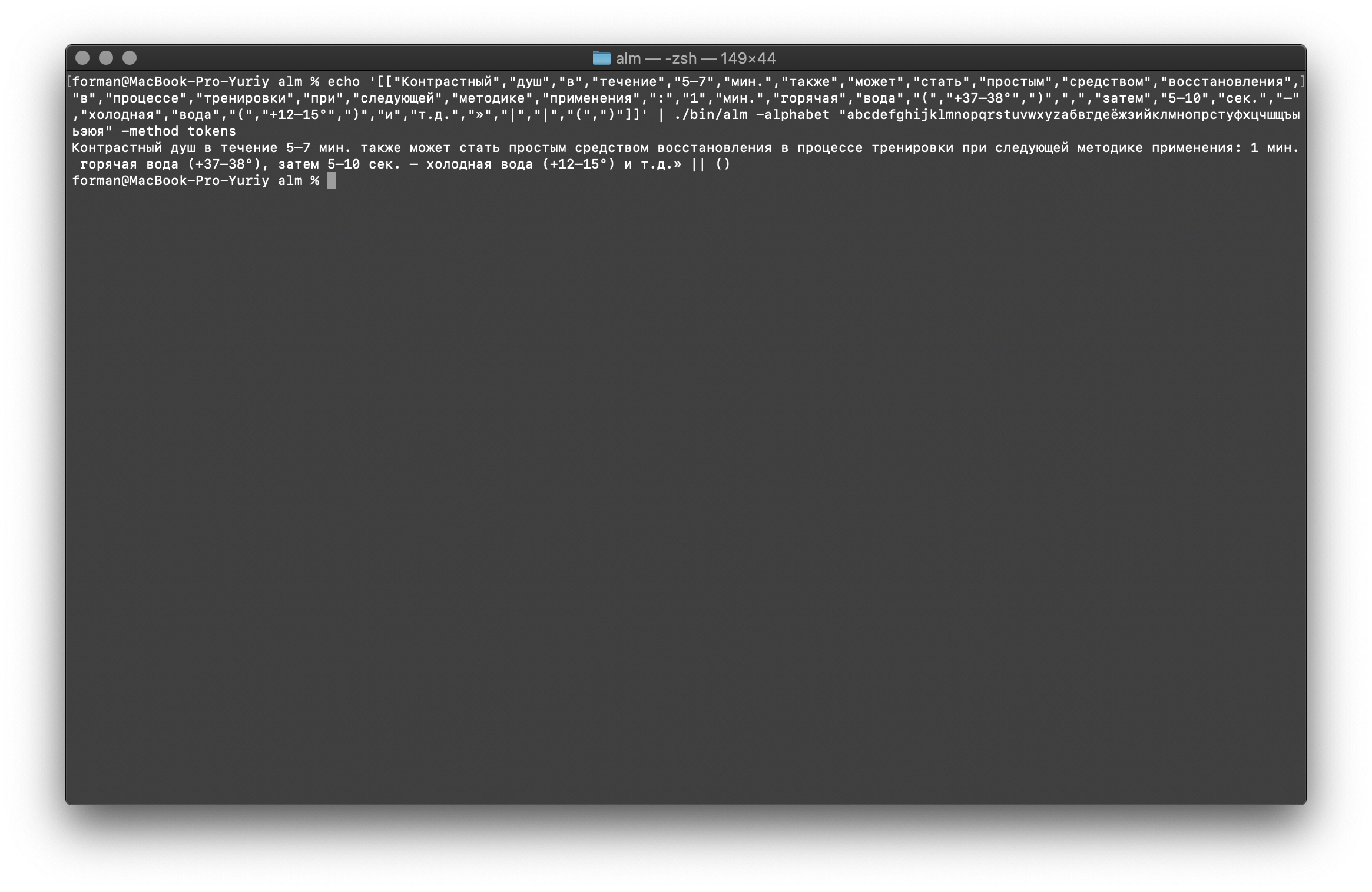 测试:
测试:[["","","","","5–7",".","","","","","","","","","","","","","",":","1",".","","","(","+37–38°",")",",","","5–10",".","–","","","(","+12–15°",")","","..","»","|","|","(",")"]]
结果: 5–7 . : 1 . (+37–38°), 5–10 . – (+12–15°) ..» || ()
从结果可以看出,令牌生成器可以修复文本设计中的大多数错误。语言模型训练
$ ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -size 3 -smoothing wittenbell -method train -debug 1 -w-arpa ./lm.arpa -w-map ./lm.map -w-vocab ./lm.vocab -w-ngram ./lm.ngrams -allow-unk -interpolate -corpus ./text.txt -threads 0 -train-segments
我将更详细地描述装配参数。- size -N克长度的大小(该大小设置为3克)
- 平滑 -平滑算法(由Witten-Bell选择的算法)
- 方法 -工作方法(方法指定的培训)
- debug-调试模式(已设置学习状态指示器)
- w-arpa — ARPA
- w-map — MAP
- w-vocab — VOCAB
- w-ngram — NGRAM
- allow-unk — 〈unk〉
- interpolate —
- corpus — . ,
- 线程 -使用多线程进行培训(0-进行培训,将提供所有可用的处理器内核,> 0参加培训的内核数)
- 培训部门 -培训大楼将在所有核心部分平均划分
可以使用[-help]标志获取更多信息。
困惑度计算
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method ppl -debug 2 -r-arpa ./lm.arpa -confidence -threads 0
 测试:
测试: ??? ….
结果:info: <s> <punct> <punct> <punct> </s>
info: p( | <s> ) = [2gram] 0.00209192 [ -2.67945500 ] / 0.99999999
info: p( | ...) = [3gram] 0.91439744 [ -0.03886500 ] / 1.00000035
info: p( | ...) = [3gram] 0.86302624 [ -0.06397600 ] / 0.99999998
info: p( | ...) = [3gram] 0.98003368 [ -0.00875900 ] / 1.00000088
info: p( | ...) = [3gram] 0.85783547 [ -0.06659600 ] / 0.99999955
info: p( | ...) = [3gram] 0.95238819 [ -0.02118600 ] / 0.99999897
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( <punct> | ...) = [3gram] 0.78127873 [ -0.10719400 ] / 1.00000031
info: p( <punct> | <punct> ...) = [2gram] 0.29417110 [ -0.53140000 ] / 0.99999998
info: p( <punct> | <punct> ...) = [3gram] 0.51262054 [ -0.29020400 ] / 0.99999998
info: p( </s> | <punct> ...) = [3gram] 0.45569787 [ -0.34132300 ] / 0.99999998
info: 1 sentences, 13 words, 0 OOVs
info: 0 zeroprobs, logprob= -4.18477000 ppl= 1.99027067 ppl1= 2.09848266
info: <s> <punct> <punct> <punct> <punct> </s>
info: p( | <s> ) = [2gram] 0.00809597 [ -2.09173100 ] / 0.99999999
info: p( | ...) = [3gram] 0.19675329 [ -0.70607800 ] / 0.99999972
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.98007204 [ -0.00874200 ] / 0.99999931
info: p( | ...) = [3gram] 0.85785325 [ -0.06658700 ] / 1.00000018
info: p( | ...) = [3gram] 0.81482810 [ -0.08893400 ] / 1.00000027
info: p( | ...) = [3gram] 0.93507404 [ -0.02915400 ] / 1.00000058
info: p( <punct> | ...) = [3gram] 0.76391493 [ -0.11695500 ] / 0.99999971
info: p( <punct> | <punct> ...) = [2gram] 0.29417110 [ -0.53140000 ] / 0.99999998
info: p( <punct> | <punct> ...) = [3gram] 0.51262054 [ -0.29020400 ] / 0.99999998
info: p( <punct> | <punct> ...) = [3gram] 0.51262054 [ -0.29020400 ] / 0.99999998
info: p( </s> | <punct> ...) = [3gram] 0.45569787 [ -0.34132300 ] / 0.99999998
info: 1 sentences, 11 words, 0 OOVs
info: 0 zeroprobs, logprob= -4.57026500 ppl= 2.40356248 ppl1= 2.60302678
info: 2 sentences, 24 words, 0 OOVs
info: 0 zeroprobs, logprob= -8.75503500 ppl= 2.23975957 ppl1= 2.31629103
info: work time shifting: 0 seconds
我认为没有什么特别的评论,因此我们将继续。上下文存在检查
$ echo "<s> </s>" | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method checktext -debug 1 -r-arpa ./lm.arpa -confidence
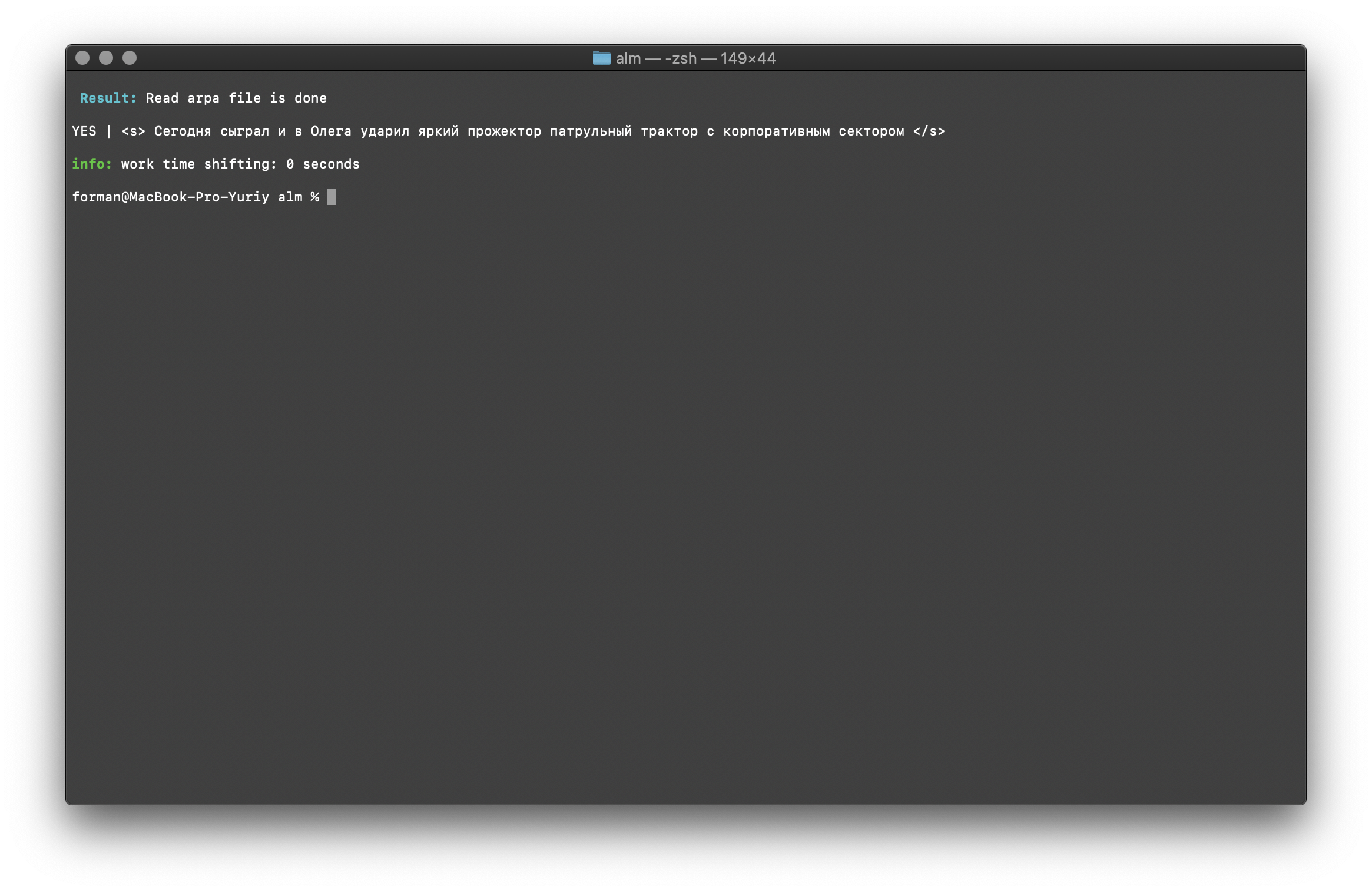 测试:
测试:<s> </s>
结果:YES | <s> </s>
结果表明,根据汇编语言模型,要检查的文本具有正确的上下文。标志[ -confidence ]-表示语言模型将在组装时加载,而不会过度标记。单词大小写更正
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method fixcase -debug 1 -r-arpa ./lm.arpa -confidence
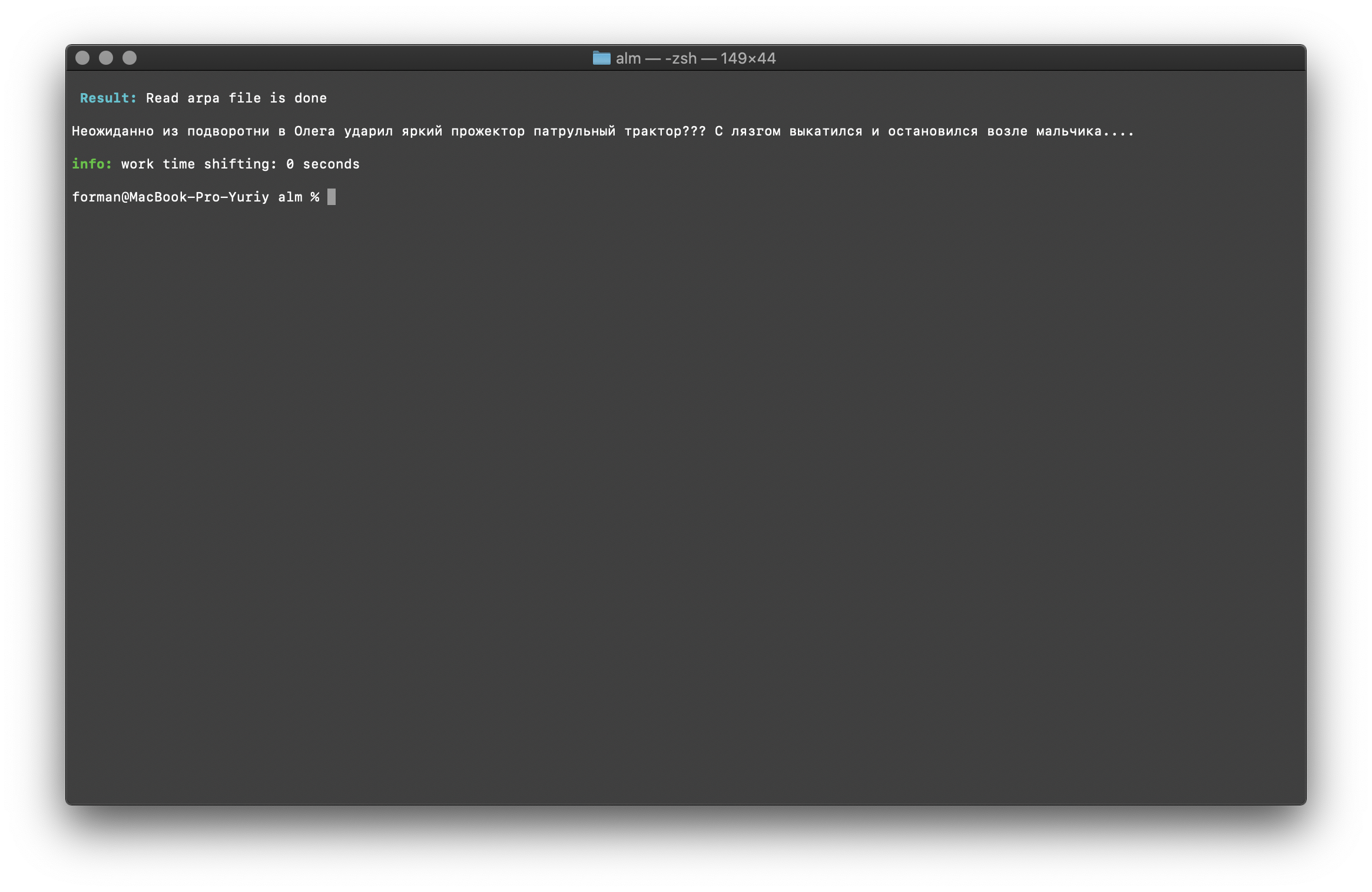 测试:
测试: ??? ....
结果: ??? ....
考虑到语言模型的上下文,将还原文本中的寄存器。上面描述的用于统计语言模型的库是区分大小写的。例如,所述的N-gram“ 明天莫斯科将下雨 ”是不相同的N-gram“ 莫斯科天有雨 ”,这些是完全不同的n-gram。但是,如果要求区分大小写并且同时复制相同的N-gram是不合理的,该怎么办?ALM表示所有小写的N-gram。这消除了重复N-gram的可能性。ALM还在每个N-gram中保持其单词寄存器的排名。导出为语言模型的文本格式时,将根据寄存器的等级恢复寄存器。检查N克数
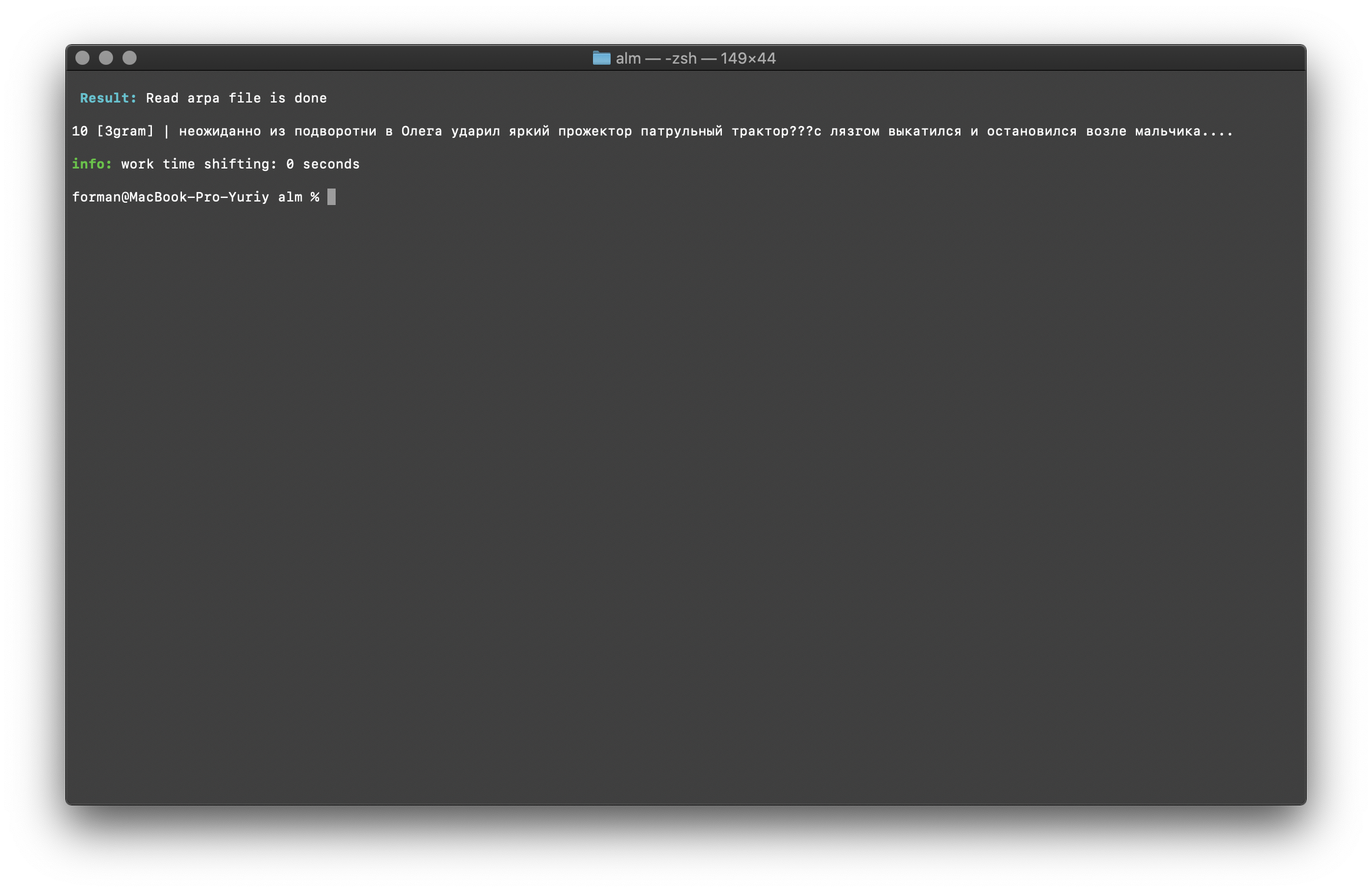
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method counts -debug 1 -r-arpa ./lm.arpa -confidence
 测试:
测试: ??? ....
结果:10 [3gram] |
N- , .
通过语言模型中N-gram的大小来检查N-gram的数量。也有机会检查二元和三元组。双字检查
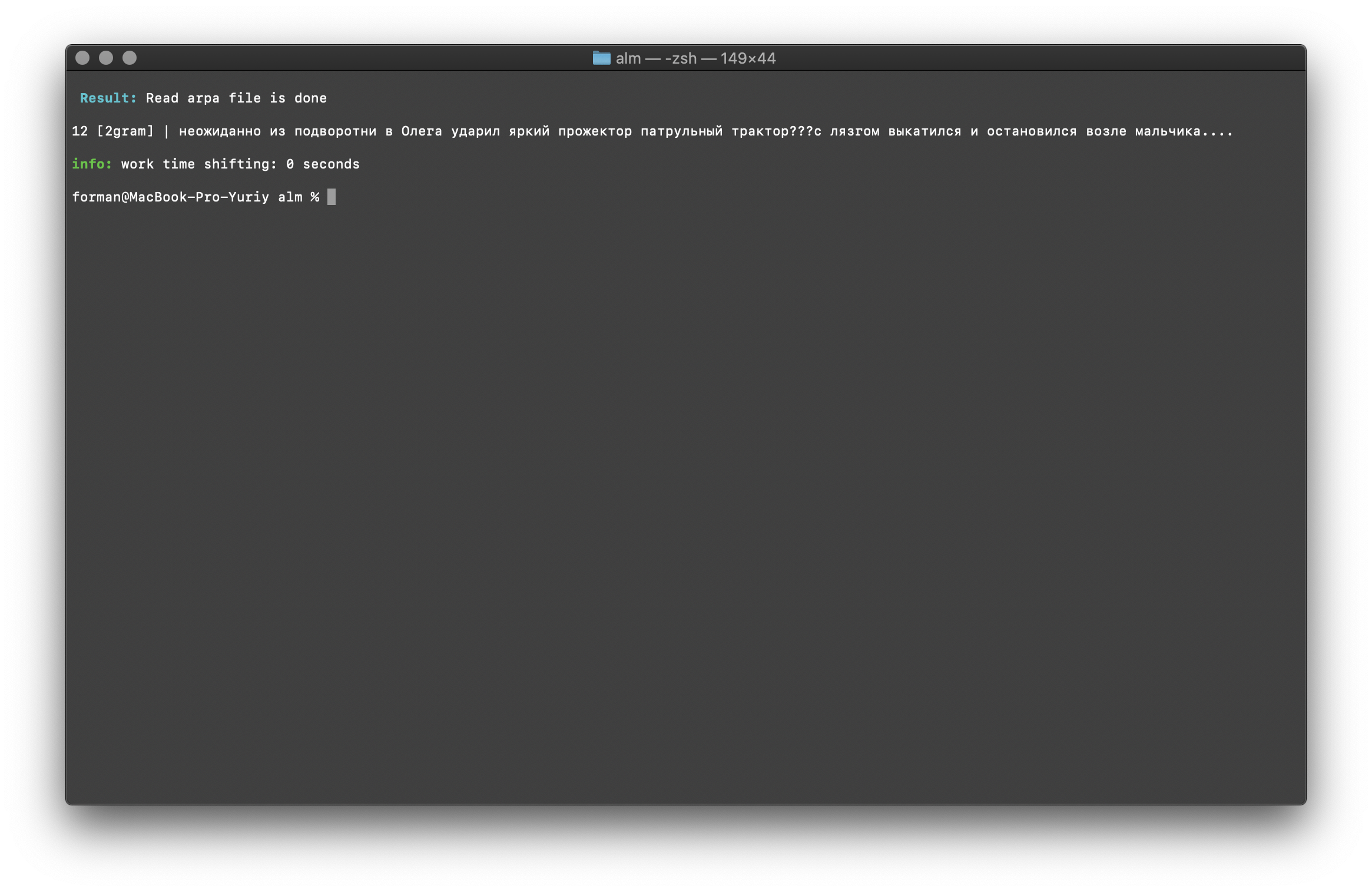
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method counts -ngrams bigram -debug 1 -r-arpa ./lm.arpa -confidence
 测试:
测试: ??? ....
结果:12 [2gram] | ??? ….
Trigram检查
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method counts -ngrams trigram -debug 1 -r-arpa ./lm.arpa -confidence
测试: ??? ....
结果:10 [3gram] | ??? ….
在文本中搜索N-gram
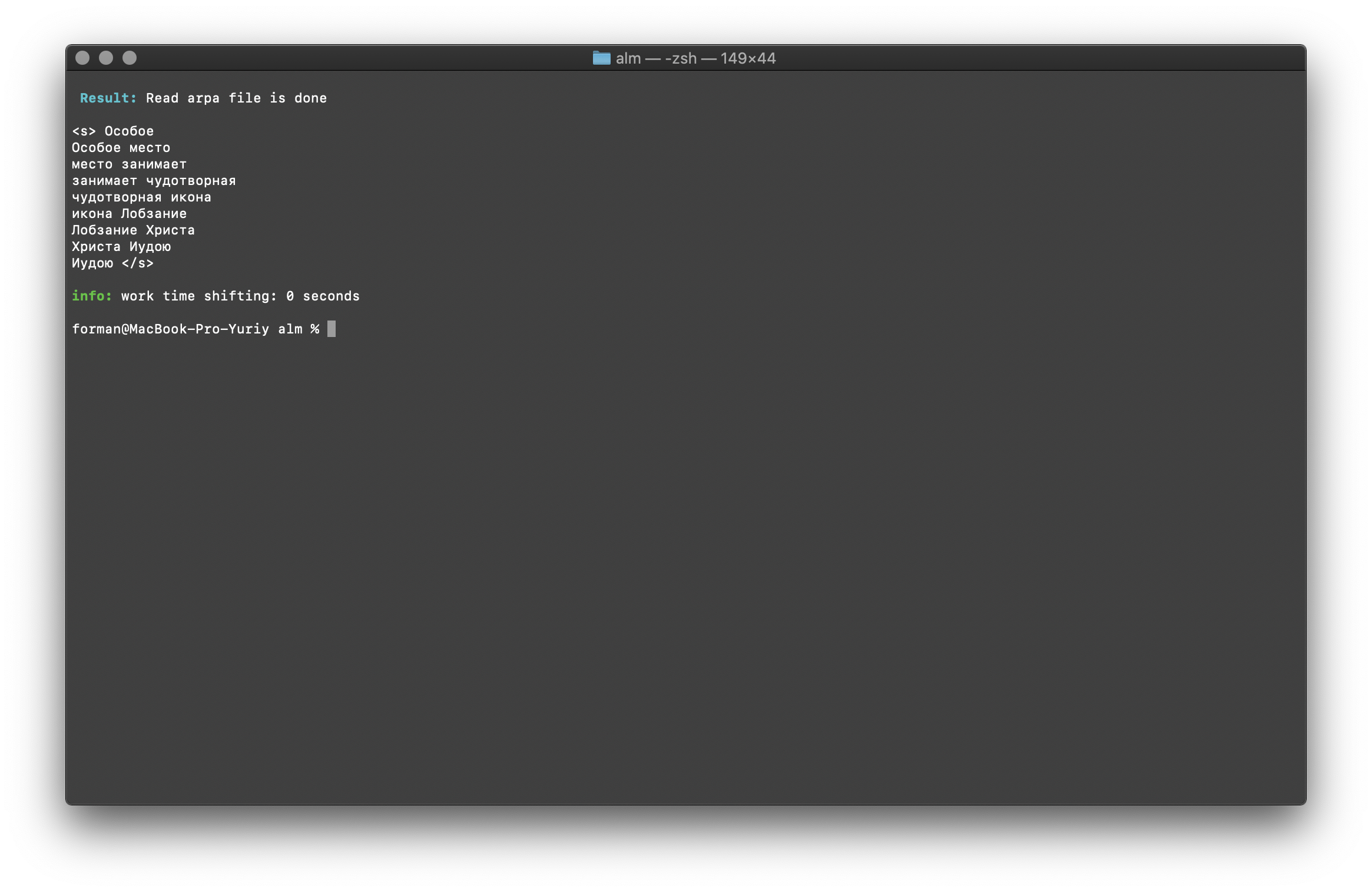
$ echo " " | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method find -debug 1 -r-arpa ./lm.arpa -confidence
 测试:
测试:
结果:<s>
</s>
在文本中找到的N-gram列表。这里没有什么特别的解释。环境变量
所有参数都可以通过环境变量传递。变量以前缀ALM_开头,并且必须大写。否则,变量名称对应于应用程序参数。如果同时指定了应用程序参数和环境变量,那么将优先考虑应用程序参数。$ export $ALM_SMOOTHING=wittenbell
$ export $ALM_W-ARPA=./lm.arpa
因此,组装过程可以自动化。例如,通过BASH脚本。结论
我知道,还有更多有前途的技术,例如RnnLM或Bert。但我确信统计N元语法模型将在很长一段时间内具有重要意义。这项工作花费了大量时间和精力。业余时间,他在晚上和周末都在图书馆从事基础工作。该代码未涵盖测试,可能会出现错误和错误。我将感谢您的测试。我也乐于接受有关改进和新库功能的建议。ALM是根据MIT许可证发行的,它使您几乎无限制地使用它。希望得到评论,批评,建议。项目现场项目资源库