也许您已经面临着在熊猫数据帧上进行并行计算的任务。这个问题既可以通过本机Python来解决,也可以借助一个出色的库pandarallel来解决。在本文中,我将展示该库如何允许您使用所有可用容量来处理数据。
该库使您不必考虑线程数,创建进程,并提供了用于监视进度的交互式界面。
安装
pip install pandas jupyter pandarallel requests tqdm
如您所见,我还安装了tqdm。借助它,我将清楚地证明顺序和并行方法在代码执行速度上的差异。
客制化
import pandas as pd
import requests
from tqdm import tqdm
tqdm.pandas()
from pandarallel import pandarallel
pandarallel.initialize(progress_bar=True)
您可以在pandarallel文档中找到设置的完整列表。
创建一个数据框
为了进行实验,请创建一个简单的数据框-100行1列。
df = pd.DataFrame(
[i for i in range(100)],
columns=["sample_column"]
)

适用于并行化的任务示例
众所周知,并非所有问题的解决方案都可以并行化。合适的任务的一个简单示例是调用某些外部源,例如API或数据库。在下面的函数中,我调用了一个API,该API向我返回了一个随机单词。我的目标是在数据框中添加一列,其中包含从此API派生的单词。
def function_to_apply(i):
r = requests.get(f'https://random-word-api.herokuapp.com/word').json()
return r[0]
df["sample-word"] = df.sample_column.progress_apply(function_to_apply)
, tqdm, — progress_apply apply. , , progress bar.

"" 35 .
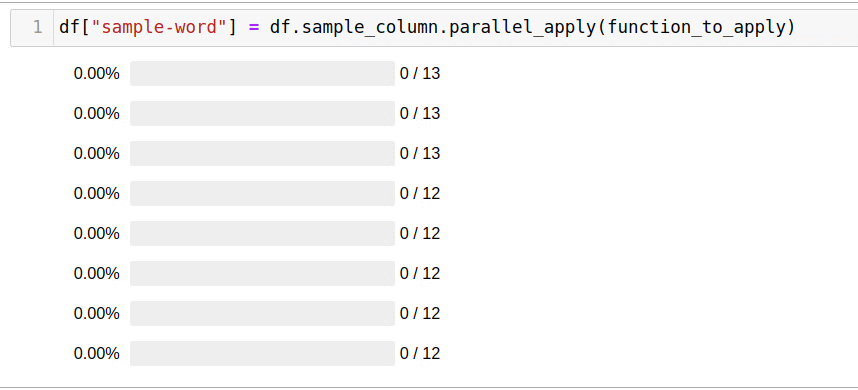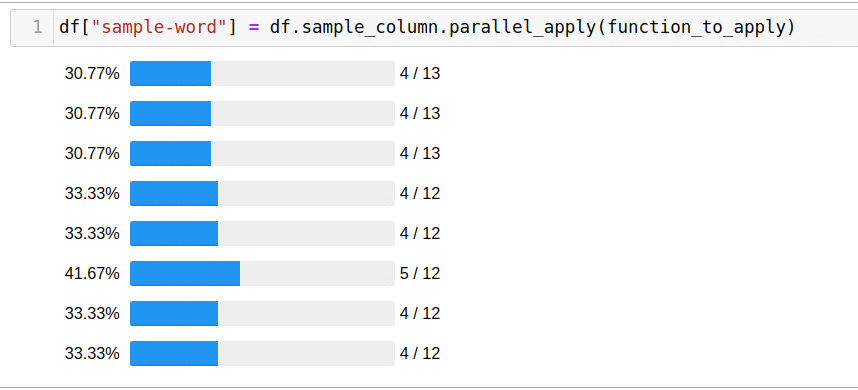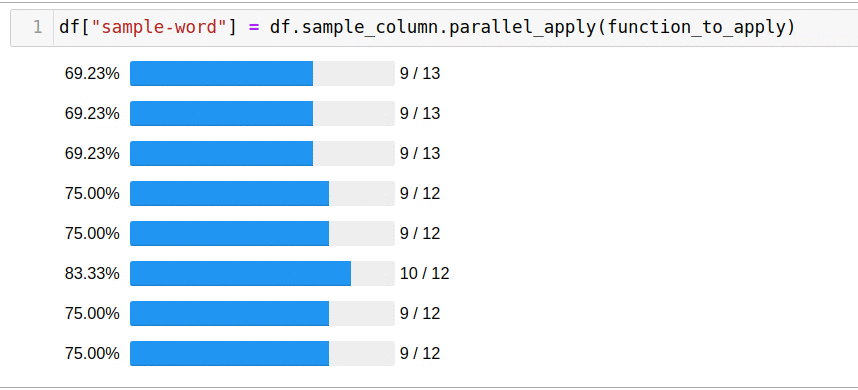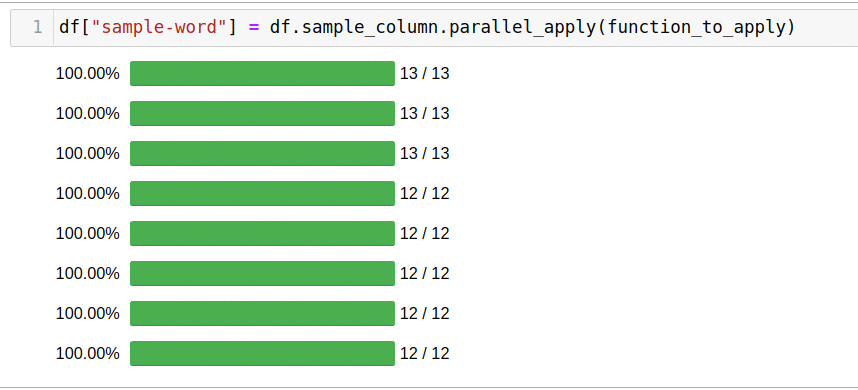
, parallel_apply:
df["sample-word"] = df.sample_column.parallel_apply(function_to_apply)
5 .
pandas , pandarallel, Github .

! — .