如果我想在数据库中写下比其承受的容量大得多的许多“事实”,该怎么办?首先,当然,我们将数据转换为更经济的标准格式,并获得“字典”,我们将编写一次。但是如何最有效地做到这一点?这正是我们在开发监视和分析PostgreSQL服务器日志时遇到的问题,而在其他方面优化数据库记录的方法也用尽了。我们将立即
预约我们的收集器正在运行Node.js,因此我们不会以任何方式与处理器寄存器和缓存进行交互。使用“数百”或外部缓存服务/数据库的选项给数百Mbps的传入流带来了太多延迟。因此,我们尝试将所有内容都缓存在RAM中,尤其是在JavaScript进程的内存中。关于如何更有效地组织此活动,我们将走得更远。可用性缓存
我们的主要任务是确保任何对象的唯一实例进入数据库。这些是SQL查询的重复重复的原始文本,实现计划的模板,这些计划的节点—简而言之,是一些文本块。历史上,我们使用- UUID值作为标识符,该值是根据对象文本直接计算MD5哈希值而获得的。之后,我们检查进程内存中本地“字典”中此类哈希的可用性,如果不存在,则仅在“字典”表中写入数据库。也就是说,我们不需要存储原始文本值本身(有时需要花费数十个千字节),仅在字典中存在相应哈希的事实就足够了。关键词典
这样的字典可以保留在中Array,并用于Array.includes()检查可用性,但这是非常多余的-搜索(至少在V8的早期版本中)从数组大小O(N)线性下降。在现代实现中,尽管进行了所有优化,但损失速度为2-3%。因此,在ES6之前的时代,存储是传统的解决方案Object,以存储的值作为键。但是每个人都为他想要的键分配了值-例如Boolean:var dict = {};
function has(key) {
return dict[key] !== undefined;
}
function add(key) {
dict[key] = true;
}
但是很明显,我们显然将多余的存储在这里-没人需要的密钥的真正价值。但是,如果根本不存储该怎么办?于是Set对象出现了。测试表明,在帮助下进行搜索的Set.has()速度比密钥验证c快20-25%Object。但这不是他唯一的优势。由于我们存储较少,因此我们应该需要较少的内存 -当涉及成千上万的此类密钥时,这将直接影响性能。因此,Object在一个文本表示形式中有100个UUID密钥,它在内存中占用6,216字节:
Set具有相同的内容-2,632字节: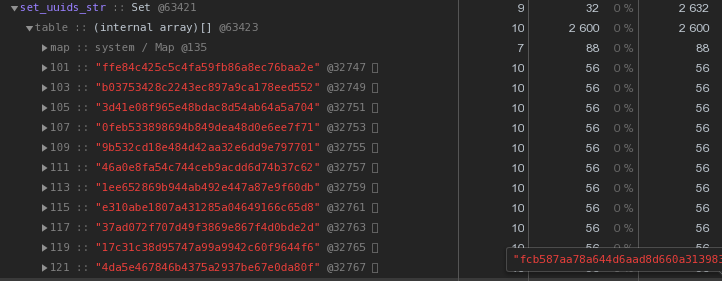 也就是说,它
也就是说,它Set工作更快,同时占用内存减少2.5倍 -获胜者显而易见。我们优化了UUID密钥的存储
通常,在分布式系统的性质中,UUID密钥非常常见- 在我们的VLSI中,它们至少用于识别电子文档管理中的文档和法规,消息传递中的人员……现在,让我们仔细看一下上图-每个UUID是存储在十六进制表示形式中的密钥“消耗”了我们56个字节的内存。但是我们有成千上万个,所以合理地问:“有可能减少吗?”首先,回想一下UUID是一个16字节的标识符。本质上是二进制数据。对于通过电子邮件进行的传输,例如,二进制数据是在base64中编码的-尝试应用它:let str = Buffer.from(uuidstr, 'hex').toString('base64');
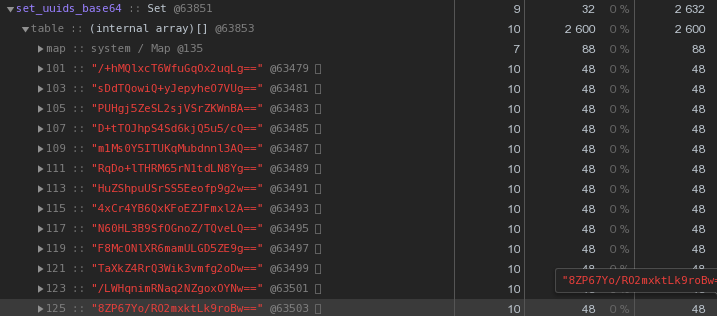 每个字节已经有48个字节更好,但并不完美。让我们尝试将十六进制表示形式直接转换为字符串:
每个字节已经有48个字节更好,但并不完美。让我们尝试将十六进制表示形式直接转换为字符串:let str = Buffer.from(uuidstr, 'hex').toString('binary');
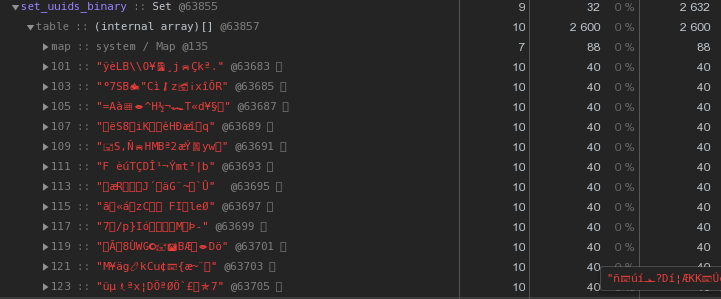 而不是每个密钥56个字节-40个字节,节省了将近30%!
而不是每个密钥56个字节-40个字节,节省了将近30%!主人,工人-在哪里存储词典?
考虑到来自工作人员的词汇数据相交很强,我们在主流程中进行了字典的存储并将其写入数据库,并通过IPC消息机制从工作人员传输了数据。但是,主机上的大部分时间都花在了channel.onread-即处理来自子进程的带有“字典”信息的数据包的接收上: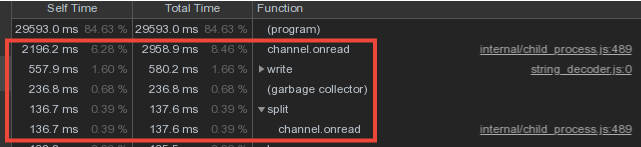
双组写屏障
现在让我们想一想-工人向船长发送和发送相同的词汇数据(基本上是计划模板和重复的请求正文),他不厌其烦地解析它们,并且...什么也不做,因为之前它们已经被发送到数据库了!因此,如果我们Set用字典“保护”数据库以免从主数据库中重新记录数据库,为什么不使用相同的方法“保护”主数据库免于从工作人员那里转移呢?..实际上,这样做可以减少三倍为交换通道提供服务的直接成本。:
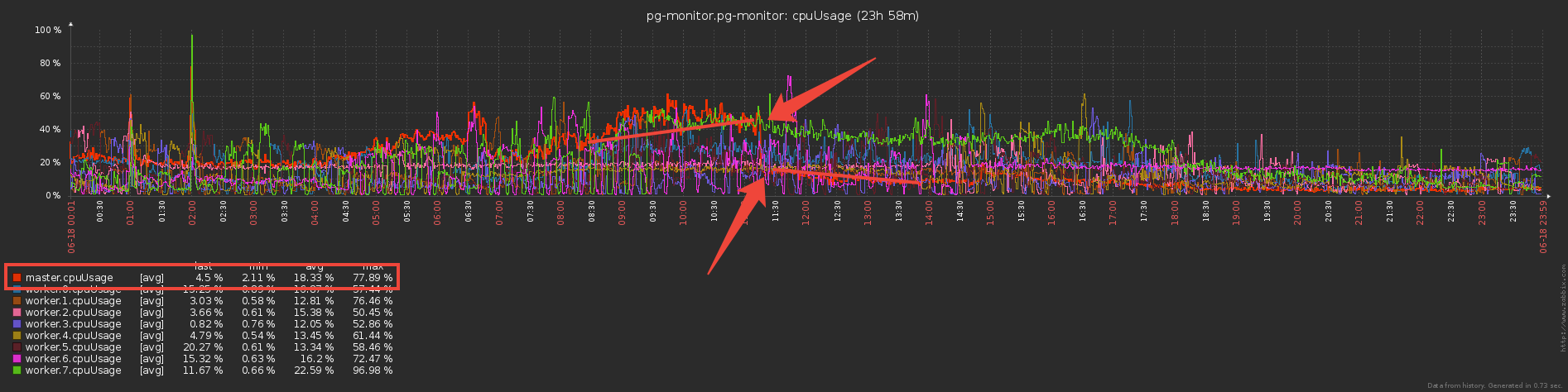 但是现在工人似乎还要做更多的工作-存储字典并对其进行过滤?是不是?..实际上,由于开始大量传输(甚至通过IPC!),它们并不便宜,因此它们开始工作的时间大大减少了。
但是现在工人似乎还要做更多的工作-存储字典并对其进行过滤?是不是?..实际上,由于开始大量传输(甚至通过IPC!),它们并不便宜,因此它们开始工作的时间大大减少了。不错的奖金
由于该向导现在开始接收的信息量要少得多,因此开始为这些容器分配更少的内存-这意味着花费在垃圾收集器工作上的时间大大减少,这对整个系统的延迟产生了积极的影响。这种方案可以防止在收集器级别重复输入,但是如果我们有多个收集器怎么办?只有触发器可以帮助您INSERT ... ON CONFLICT DO NOTHING。加快哈希计算
在我们的体系结构中,来自一台PostgreSQL服务器的整个日志流由一名工作人员处理。也就是说,一台服务器是工作人员的一项任务。同时,通过服务器任务的目的来平衡工作者的负载,从而使所有收集器的工作者所消耗的CPU大致相同。这是一个单独的服务调度程序。“平均而言”,每个工人处理数十项任务,这些任务产生的总负荷大致相同。但是,有些服务器的日志条目数量大大超过了其余的服务器。即使调度员将这项任务留给了工作人员上的唯一任务,其下载量也比其他任务高得多:我们删除了该工作程序的CPU配置文件: 在最上面几行,MD5哈希的计算。对于整个传入对象流,它们的计算量确实很大。
在最上面几行,MD5哈希的计算。对于整个传入对象流,它们的计算量确实很大。xx哈希
如何优化这部分,除了这些散列,我们不能?我们决定尝试另一个哈希函数xxHash,该函数实现了极快的非加密哈希算法。Node.js的模块是xxhash-addon,它使用最新版本的xxHash 0.7.3库和新的XXH3算法。通过在一组不同长度的行上运行每个选项来进行检查:const crypto = require('crypto');
const { XXHash3, XXHash64 } = require('xxhash-addon');
const hasher3 = new XXHash3(0xDEADBEAF);
const hasher64 = new XXHash64(0xDEADBEAF);
const buf = Buffer.allocUnsafe(16);
const getBinFromHash = (hash) => buf.fill(hash, 'hex').toString('binary');
const funcs = {
xxhash64 : (str) => hasher64.hash(Buffer.from(str)).toString('binary')
, xxhash3 : (str) => hasher3.hash(Buffer.from(str)).toString('binary')
, md5 : (str) => getBinFromHash(crypto.createHash('md5').update(str).digest('hex'))
};
const check = (hash) => {
let log = [];
let cnt = 10000;
while (cnt--) log.push(crypto.randomBytes(cnt).toString('hex'));
console.time(hash);
log.forEach(funcs[hash]);
console.timeEnd(hash);
};
Object.keys(funcs).forEach(check);
结果:xxhash64 : 148.268ms
xxhash3 : 108.337ms
md5 : 317.584ms
正如预期,xxhash3是比MD5快很多!仍然需要检查是否有碰撞阻力。每天都会为我们创建词典表的各个部分,因此在一天的限制范围之外,我们可以安全地允许散列交集。但以防万一,我们在三天的间隔内进行了一次边际检查- 没有一次冲突比我们更适合。哈希替换
但是我们根本无法采用旧的UUID字段并将其更改为字典表中的新哈希,因为数据库和现有前端都等待对象继续被UUID标识。因此,我们将向收集器添加一个缓存 -已计算的MD5。现在将是一个Map,其中的键是xxhash3,值是MD5。对于相同的行,我们不再重述“昂贵的” MD5,而是从缓存中获取:const getHashFromBin = (bin) => Buffer.from(bin, 'binary').toString('hex');
const dictmd5 = new Map();
const getmd5 = (data) => {
const hash = xxhash(data);
let md5hash = dictmd5.get(hash);
if (!md5hash) {
md5hash = md5(data);
dictmd5.set(hash, getBinFromHash(md5hash));
return md5hash;
}
return getHashFromBin(md5hash);
};
我们删除了配置文件-计算哈希的时间比例明显减少了,干杯! 因此,现在我们计算xxhash3,然后检查MD5高速缓存并获取所需的MD5,然后检查字典高速缓存-如果此md5不存在,则将其发送到数据库以进行写入。太多检查...如果已经检查了MD5缓存,为什么还要检查字典缓存?事实证明,不再需要所有字典缓存,而仅拥有一个缓存就足够了-对于MD5,将执行所有基本操作:
因此,现在我们计算xxhash3,然后检查MD5高速缓存并获取所需的MD5,然后检查字典高速缓存-如果此md5不存在,则将其发送到数据库以进行写入。太多检查...如果已经检查了MD5缓存,为什么还要检查字典缓存?事实证明,不再需要所有字典缓存,而仅拥有一个缓存就足够了-对于MD5,将执行所有基本操作: 结果,我们用一个MD5缓存替换了多个“对象”字典中的检查,并且计算MD5的资源密集型操作是哈希仅对新条目执行,对传入流使用效率更高的xxhash。谢谢基洛 在撰写本文时寻求帮助。
结果,我们用一个MD5缓存替换了多个“对象”字典中的检查,并且计算MD5的资源密集型操作是哈希仅对新条目执行,对传入流使用效率更高的xxhash。谢谢基洛 在撰写本文时寻求帮助。