您好亲爱的订户!您可能已经知道我们已经开设了新课程“计算机视觉”,它将在未来几天内开始课程。期待上课,我们准备了另一篇有趣的译文,以浸入CV领域。
我的爱好是玩棋盘游戏,并且由于我对卷积神经网络有点熟悉,因此我决定创建一个可以在纸牌游戏中击败某个人的应用程序。我想使用自己的数据集从头开始构建模型,并查看它与小型数据集的配合情况。我决定从简单的Dobble游戏(也称为Spot it!)开始。如果您不知道Dobble是什么,那么我将简要回顾一下游戏规则:Dobble是一款简单的模式识别游戏,玩家可以尝试找到同时在两张卡上描绘的图片。原始Dobble游戏中的每张卡都包含八个不同的角色,并且在不同的卡上它们的大小不同。任何两张卡只有一个公共符号。如果您首先找到该符号,则拿起一张卡片。当一副55张牌结束时,获胜最多的一张获胜。 自己尝试一下:这两张卡的共同符号是什么?
自己尝试一下:这两张卡的共同符号是什么?从哪里开始?
解决任何数据分析任务的第一步是收集数据。我在手机上为每张卡拍摄了六张照片。总共有330张照片。您在下面看到其中的四个。您可能会问,这足以创建一个良好的卷积神经网络吗?我们将回到这一点!
图像处理
好,我们有数据,下一步是什么?可能是成功道路上最重要的部分:图像处理。我们需要从每个图像中获取字符。这里有些困难等待着我们。在上面的照片中,值得注意的是,有些字符比其他字符更难区分:雪人和鬼魂(在第三张照片中)和针(在第四张照片中),污点(在第二张照片中)和感叹号(在第四张照片中)由几部分组成。要处理浅色字符,我们将添加对比度。之后,我们将调整大小并保存图像。添加对比
为了增加对比度,我们使用Lab颜色空间。L是亮度,a是从绿色到品红色的范围内的色度分量,b是从蓝色到黄色的范围内的色度分量。我们可以使用OpenCV轻松提取这些组件:import cv2
import imutils
imgname = 'picture1'
image = cv2.imread(f’{imgname}.jpg’)
lab = cv2.cvtColor(image, cv2.COLOR_BGR2LAB)
l, a, b = cv2.split(lab)
 从左到右:原始图像,亮度分量,分量a和分量b现在我们向亮度分量添加对比度,再次将所有分量组合在一起并转换为普通图像:
从左到右:原始图像,亮度分量,分量a和分量b现在我们向亮度分量添加对比度,再次将所有分量组合在一起并转换为普通图像:clahe = cv2.createCLAHE(clipLimit=3.0, tileGridSize=(8,8))
cl = clahe.apply(l)
limg = cv2.merge((cl,a,b))
final = cv2.cvtColor(limg, cv2.COLOR_LAB2BGR)
 从左到右:原始图像,亮度分量,高对比度图像以及转换回RGB的图像
从左到右:原始图像,亮度分量,高对比度图像以及转换回RGB的图像尺寸变更
现在调整大小并保存图像:resized = cv2.resize(final, (800, 800))
# save the image
cv2.imwrite(f'{imgname}processed.jpg', blurred)
做完了!卡和字符识别
现在图像已处理完毕,我们可以在图像中检测到卡片了。使用OpenCV,我们正在寻找外部轮廓。然后,我们将图像转换为半色调,选择阈值(在本例中为190)以创建黑白图像并搜索路径。编码:image = cv2.imread(f’{imgname}processed.jpg’)
gray = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
thresh = cv2.threshold(gray, 190, 255, cv2.THRESH_BINARY)[1]
# find contours
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
output = image.copy()
# draw contours on image
for c in cnts:
cv2.drawContours(output, [c], -1, (255, 0, 0), 3)
 使用阈值并选择外部轮廓将处理后的图像转换为半色调如果我们按区域对外部轮廓进行排序,我们将找到面积最大的轮廓-这就是我们的卡片。要提取字符,我们可以创建一个白色背景。
使用阈值并选择外部轮廓将处理后的图像转换为半色调如果我们按区域对外部轮廓进行排序,我们将找到面积最大的轮廓-这就是我们的卡片。要提取字符,我们可以创建一个白色背景。# sort by area, grab the biggest one
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[0]
# create mask with the biggest contour
mask = np.zeros(gray.shape,np.uint8)
mask = cv2.drawContours(mask, [cnts], -1, 255, cv2.FILLED)
# card in foreground
fg_masked = cv2.bitwise_and(image, image, mask=mask)
# white background (use inverted mask)
mask = cv2.bitwise_not(mask)
bk = np.full(image.shape, 255, dtype=np.uint8)
bk_masked = cv2.bitwise_and(bk, bk, mask=mask)
# combine back- and foreground
final = cv2.bitwise_or(fg_masked, bk_masked)
 遮罩,背景,前景图像,最终图像现在是字符识别的时候了!我们可以使用生成的图像再次检测其上的外部轮廓,这些轮廓将是符号。如果我们在每个符号周围创建一个正方形,则可以提取该区域。这里的代码要长一点:
遮罩,背景,前景图像,最终图像现在是字符识别的时候了!我们可以使用生成的图像再次检测其上的外部轮廓,这些轮廓将是符号。如果我们在每个符号周围创建一个正方形,则可以提取该区域。这里的代码要长一点:
gray = cv2.cvtColor(final, cv2.COLOR_RGB2GRAY)
thresh = cv2.threshold(gray, 195, 255, cv2.THRESH_BINARY)[1]
thresh = cv2.bitwise_not(thresh)
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:10]
i = 0
for c in cnts:
if cv2.contourArea(c) > 1000:
mask = np.zeros(gray.shape, np.uint8)
mask = cv2.drawContours(mask, [c], -1, 255, cv2.FILLED)
fg_masked = cv2.bitwise_and(image, image, mask=mask)
mask = cv2.bitwise_not(mask)
bk = np.full(image.shape, 255, dtype=np.uint8)
bk_masked = cv2.bitwise_and(bk, bk, mask=mask)
finalcont = cv2.bitwise_or(fg_masked, bk_masked)
output = finalcont.copy()
x,y,w,h = cv2.boundingRect(c)
if w < h:
x += int((w-h)/2)
w = h
else:
y += int((h-w)/2)
h = w
roi = finalcont[y:y+h, x:x+w]
roi = cv2.resize(roi, (400,400))
cv2.imwrite(f"{imgname}_icon{i}.jpg", roi)
i += 1
 黑白图像(阈值),检测到的轮廓,重影符号和心脏符号(使用遮罩提取的字符)
黑白图像(阈值),检测到的轮廓,重影符号和心脏符号(使用遮罩提取的字符)字符排序
现在最无聊了!您需要对字符进行排序。您将需要训练,测试和验证目录,每个目录有57个目录(我们总共有57个不同的字符)。文件夹结构如下:symbols
├── test
│ ├── anchor
│ ├── apple
│ │ ...
│ └── zebra
├── train
│ ├── anchor
│ ├── apple
│ │ ...
│ └── zebra
└── validation
├── anchor
├── apple
│ ...
└── zebra
将提取的字符(超过2500个)放入必要的目录需要一些时间!我有在GitHub上创建子文件夹,测试套件和验证套件的代码。也许下次最好根据聚类算法进行排序...卷积神经网络训练
在无聊的部分之后,乐趣又来了!现在是时候创建和训练卷积神经网络了。您可以在此处找到有关卷积神经网络的信息。模型架构
我们的任务是使用一个标签进行多类别分类。对于每个字符,我们需要一个标签。这就是为什么我们需要一个函数来激活具有57个节点的输出softmax层,并将分类交叉熵作为损失函数。最终模型的体系结构如下:
from keras import layers
from keras import models
from keras import optimizers
from keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(400, 400, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(256, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(256, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(57, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=optimizers.RMSprop(lr=1e-4), metrics=['acc'])
数据扩充
为了提高性能,我使用了数据扩充。数据扩充是增加输入数据的数量和种类的过程。这可以通过旋转,移动,缩放,裁剪和翻转现有图像来完成。Keras可以轻松扩充数据:
train_dir = 'symbols/train'
validation_dir = 'symbols/validation'
test_dir = 'symbols/test'
train_datagen = ImageDataGenerator(rescale=1./255, rotation_range=40, width_shift_range=0.1, height_shift_range=0.1, shear_range=0.1, zoom_range=0.1, horizontal_flip=True, vertical_flip=True)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(train_dir, target_size=(400,400), batch_size=20, class_mode='categorical')
validation_generator = test_datagen.flow_from_directory(validation_dir, target_size=(400,400), batch_size=20, class_mode='categorical')
如果您感兴趣,则增强后的幻像应如下所示:左侧鬼像 的原始图像,所有其他图片中的增强后的幻像
的原始图像,所有其他图片中的增强后的幻像模型训练
让我们训练模型,将其保存以用于预测,然后检查结果。history = model.fit_generator(train_generator, steps_per_epoch=100, epochs=100, validation_data=validation_generator, validation_steps=50)
model.save('models/model.h5')
 完美的预测!
完美的预测!结果
我训练的基本模型没有数据扩充,数据丢失和更少的层。该模型给出了以下结果: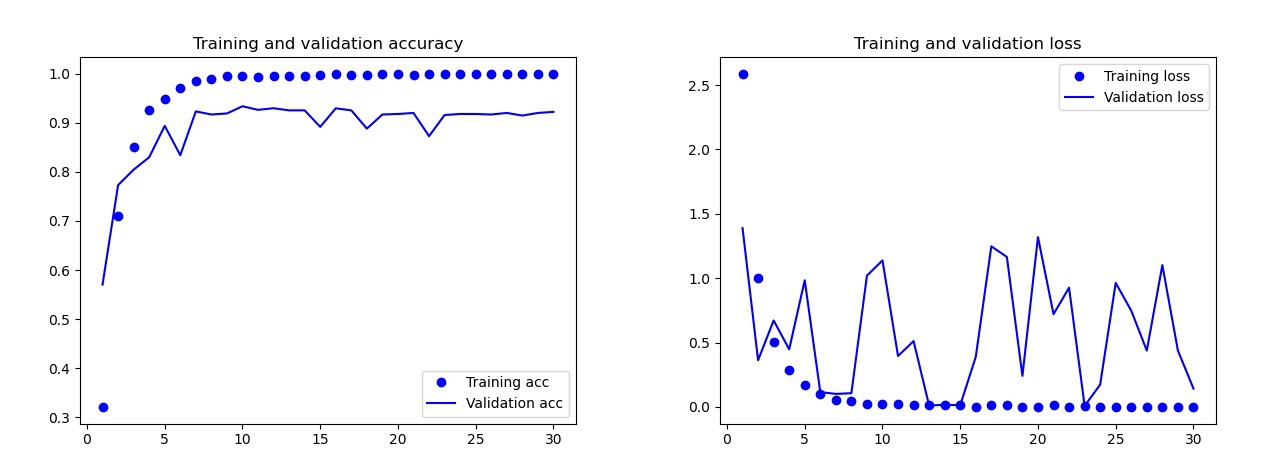 基本模型的结果用肉眼可以明显看出该模型是经过重新训练的。该模型的最终版本(其代码在前面的部分中提供)的结果要好得多。在下面的图形上,您可以在训练过程中以及在验证集中查看准确性和损失。
基本模型的结果用肉眼可以明显看出该模型是经过重新训练的。该模型的最终版本(其代码在前面的部分中提供)的结果要好得多。在下面的图形上,您可以在训练过程中以及在验证集中查看准确性和损失。 最终模型的结果在测试装置上,该模型仅犯了一个错误,它认为炸弹是下落的。我决定保留该模型,测试集的准确性为0.995。
最终模型的结果在测试装置上,该模型仅犯了一个错误,它认为炸弹是下落的。我决定保留该模型,测试集的准确性为0.995。识别两张卡上的通用符号
现在,您可以开始在两张卡上寻找通用符号。我们使用两张照片,我们将分别对每个图像进行预测,并使用集合的交集找出两张卡上的哪个符号。我们有3个工作选项:- 在预测过程中出了点问题:找不到共同的字符。
- 相交处有一个符号(预测可以为真或假)。
- 相交处有多个字符。在这种情况下,我选择概率最高的符号(两个预测的平均值)。
预测所有在目录中的谎言与两个图像组合代码GitHub上的main.py。结果如下:
结论
那不是完美的模型吗?抱歉不行。当我为卡片拍摄新照片并为它们提供预测模型时,雪人出现了一些问题。有时他认出眼睛或斑马是雪人!结果,有时结果很奇怪: 嗯,这里的雪人在哪里?这个模特比男人好吗?取决于我们的需求:人们可以完美地识别,但是模型可以更快地做到!我注意到计算机的处理时间:我给了55张卡片,每张两张卡片的组合必须有一个公共符号。总共有1485个组合。计算机在不到140秒的时间内完成了此操作。他犯了一些错误,但绝对可以打败任何人!
嗯,这里的雪人在哪里?这个模特比男人好吗?取决于我们的需求:人们可以完美地识别,但是模型可以更快地做到!我注意到计算机的处理时间:我给了55张卡片,每张两张卡片的组合必须有一个公共符号。总共有1485个组合。计算机在不到140秒的时间内完成了此操作。他犯了一些错误,但绝对可以打败任何人! 我认为创建100%有效的模型并不困难。这可以通过转学培训来实现。为了了解模型的作用,我们可以可视化测试图像的图层。您下次可以做!
我认为创建100%有效的模型并不困难。这可以通过转学培训来实现。为了了解模型的作用,我们可以可视化测试图像的图层。您下次可以做!
了解有关该课程的更多信息并通过入学考试