 (图像取自此处)
(图像取自此处)
今天,我们想告诉您有关基于字段先验知识对文本字段识别结果进行后处理的任务。之前,我们已经写过有关基于三字组的字段校正方法的文章,该方法使您可以校正用自然语言编写的单词的某些识别错误。但是,重要文件(包括身份证明文件)中的很大一部分是性质不同的字段-日期,数字,汽车的VIN码,TIN和SNILS号码,机器可读区域与他们的校验和等等。尽管不能将它们归因于自然语言的字段,但是,这些字段通常具有某些(有时是隐式的)语言模型,这意味着某些校正算法也可以应用于它们。在本文中,我们将讨论两种用于后处理识别结果的机制,这些机制可用于大量文档和字段类型。该领域的语言模型可以有条件地分为三个部分:- 语法:规则,用于控制文本字段表示的结构。示例:机器可读区域中的“文档到期日期”字段表示为七个数字“ DDDDDDD”。
- : , . : “ ” - – , 3- 4- – , 5- 6- – , 7- – .
- : , . : “ ” , , “ ”.
有了有关文档和已识别字段的语义和句法结构的信息,您可以构建用于对识别结果进行后处理的专用算法。但是,考虑到支持和开发识别系统的需求以及其开发的复杂性,有趣的是考虑“通用”的方法和工具,这些方法和工具将允许(开发人员)以最小的努力来构建一个相当好的后处理算法,该算法可以与广泛的类一起工作。文档和字段。建立和支持这种算法的方法将统一起来,只有语言模型将成为算法结构的可变组成部分。值得注意的是,文本字段识别结果的后处理并不总是有用的,有时甚至是有害的:如果您有一个很好的行识别模块,并且在具有标识文档的关键系统中工作,那么某种后处理最好尽量减少并“按原样”产生结果,或者清楚地监视任何更改并将其报告给客户。但是,在许多情况下,当已知文档有效且该领域的语言模型可靠时,使用后处理算法可以显着提高最终识别质量。因此,本文将讨论两种声称具有通用性的后处理方法。第一种是基于加权的有限转换器,需要以有限状态机的形式描述语言模型,不是很容易使用,但是更通用。第二种方法更易于使用,效率更高,只需要编写一个用于检查字段值有效性的函数,还具有许多缺点。加权末端发送器方法
一个美丽而相当普遍的模式,让您能够建立后处理识别结果的通用算法描述了这项工作。该模型依赖于加权有限状态传感器(WFST)的数据结构。WFSTs是加权有限状态机的一般化-如果加权有限状态机编码一些加权语言 (即,在一定的字母表的加权组线
(即,在一定的字母表的加权组线 ),然后WFST编码语言的加权地图
),然后WFST编码语言的加权地图 字母表上述
字母表上述 成语言
成语言 字母表以上
字母表以上 。加权有限状态机,
。加权有限状态机, 在字母上取一个字符串,为其分配一些权重
在字母上取一个字符串,为其分配一些权重 ,而WFST,取一个字符串
,而WFST,取一个字符串 在字母表上,与之相关联的是一组(可能是无限的)对
在字母表上,与之相关联的是一组(可能是无限的)对 ,其中
,其中 字母表上方的线是要转换为的线,并且
字母表上方的线是要转换为的线,并且 是该转换的权重。转换器的每个转换都有两个状态(在两个状态之间进行转换),输入字符(来自字母),输出字符(来自字母)和转换权重。空字符(空字符串)被视为两个字母的元素。字符串
是该转换的权重。转换器的每个转换都有两个状态(在两个状态之间进行转换),输入字符(来自字母),输出字符(来自字母)和转换权重。空字符(空字符串)被视为两个字母的元素。字符串 到字符串转换
到字符串转换 的权重是沿所有路径的过渡权重乘积的总和,在这些路径上输入字符的串联构成字符串,而输出字符的串联构成字符串,并将转换器从初始状态转移到终端状态之一。合成操作是在WFST上确定的,后处理方法基于WFST。让两个变压器被赋予
的权重是沿所有路径的过渡权重乘积的总和,在这些路径上输入字符的串联构成字符串,而输出字符的串联构成字符串,并将转换器从初始状态转移到终端状态之一。合成操作是在WFST上确定的,后处理方法基于WFST。让两个变压器被赋予 与
与 和转换线以上
和转换线以上 的线上面
的线上面 有重量
有重量 ,并转换过的线
,并转换过的线 上面
上面 与重量
与重量 。然后,转换器
。然后,转换器 (称为转换器的组成部分)将字符串转换为具有权重的字符串
(称为转换器的组成部分)将字符串转换为具有权重的字符串 。换能器的组成在计算上是昂贵的操作,但是它可以延迟计算-可以在需要访问换能器的时刻构造最终换能器的状态和转换。基于WFST的识别结果的后处理算法基于三个主要的信息源-假设
。换能器的组成在计算上是昂贵的操作,但是它可以延迟计算-可以在需要访问换能器的时刻构造最终换能器的状态和转换。基于WFST的识别结果的后处理算法基于三个主要的信息源-假设 模型,错误模型
模型,错误模型 和语言模型
和语言模型 。这三种模型均以加权最终换能器的形式表示:
。这三种模型均以加权最终换能器的形式表示:- ( WFST – , ), , . ,
 , ():
, ():  ,
,  –
–  - ,
- ,  – () .
– () .  - , :
- , :  - ,
- ,  - – ,
- – ,  -
-  -
-  . - , . , .
. - , . , .
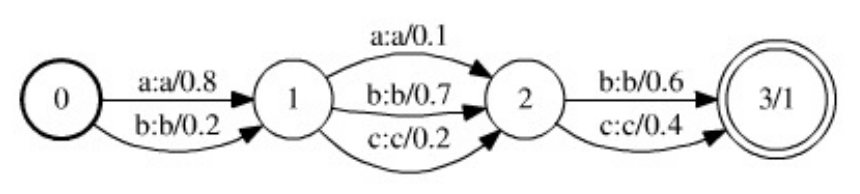
. 1. , WFST ( ). .
- , , . WFST ( ). . , .
- . .. , ( ).
在定义了假设,错误和语言模型之后,现在可以提出如下处理后识别结果的任务:考虑所有三个模型的组成 (就WFST组成而言)。转换器
(就WFST组成而言)。转换器 将假设模型中字符串的所有可能转换编码为语言模型中的字符串,并将错误模型中编码的转换应用于字符串。此外,这种转换的权重包括原始假设的权重,转换的权重和所得字符串的权重(在加权语言模型的情况下)。因此,在这种模型中,识别结果的最佳后处理将对应于转换器中的最佳(就重量而言)路径将其从初始状态转换为终端状态之一。沿着该路径的输入线将对应于所选的初始假设,而输出线将对应于校正后的识别结果。可以使用用于在有向图中找到最短路径的算法来寻找最佳路径。这种方法的优点是它的通用性和灵活性。例如,可以以考虑到字符的删除和添加的方式轻松扩展错误模型(为此,仅应将错误输出或输入符号分别为空的过渡添加到错误模型中)。但是,该模型具有明显的缺点。首先,这里的语言模型应该表示为有限加权的有限变换器。对于复杂的语言,这种自动机可能非常麻烦,并且在更改或完善语言模型的情况下,有必要对其进行重建。还应注意的是,这三个换能器的组成通常会带来更大的换能器,每次开始对一个识别结果进行后处理时,都会计算此组成。由于组合物的体积大,实际上必须使用启发式方法(例如A * -search)执行对最佳路径的搜索。使用验证语法模型,可以构造一个更简单的后处理识别结果任务模型,该模型不会像基于WFST的模型那样通用,但是易于扩展和易于实现。检查语法是一对
将假设模型中字符串的所有可能转换编码为语言模型中的字符串,并将错误模型中编码的转换应用于字符串。此外,这种转换的权重包括原始假设的权重,转换的权重和所得字符串的权重(在加权语言模型的情况下)。因此,在这种模型中,识别结果的最佳后处理将对应于转换器中的最佳(就重量而言)路径将其从初始状态转换为终端状态之一。沿着该路径的输入线将对应于所选的初始假设,而输出线将对应于校正后的识别结果。可以使用用于在有向图中找到最短路径的算法来寻找最佳路径。这种方法的优点是它的通用性和灵活性。例如,可以以考虑到字符的删除和添加的方式轻松扩展错误模型(为此,仅应将错误输出或输入符号分别为空的过渡添加到错误模型中)。但是,该模型具有明显的缺点。首先,这里的语言模型应该表示为有限加权的有限变换器。对于复杂的语言,这种自动机可能非常麻烦,并且在更改或完善语言模型的情况下,有必要对其进行重建。还应注意的是,这三个换能器的组成通常会带来更大的换能器,每次开始对一个识别结果进行后处理时,都会计算此组成。由于组合物的体积大,实际上必须使用启发式方法(例如A * -search)执行对最佳路径的搜索。使用验证语法模型,可以构造一个更简单的后处理识别结果任务模型,该模型不会像基于WFST的模型那样通用,但是易于扩展和易于实现。检查语法是一对 ,在哪里是字母,并且
,在哪里是字母,并且 是字符串在字母上的可容许性的谓词,即
是字符串在字母上的可容许性的谓词,即 。检查语法在字母表上编码某种语言,如下所示:
。检查语法在字母表上编码某种语言,如下所示: 如果谓词在该行上取真值,则该行属于该语言。值得注意的是,检查语法是一种比状态机更通用的语言模型表示方式。实际上,任何表示为有限状态机的语言可以用检查语法的形式表示(带有谓词
如果谓词在该行上取真值,则该行属于该语言。值得注意的是,检查语法是一种比状态机更通用的语言模型表示方式。实际上,任何表示为有限状态机的语言可以用检查语法的形式表示(带有谓词 ,其中
,其中 是自动机接受的行的集合。但是,在一般情况下,并不是所有可以表示为检查文法的语言都可以表示为有限自动机(例如,长度不受限制的单词语言)字母
是自动机接受的行的集合。但是,在一般情况下,并不是所有可以表示为检查文法的语言都可以表示为有限自动机(例如,长度不受限制的单词语言)字母 ,其中字符数
,其中字符数 大于字符数
大于字符数 。)让识别结果(假设模型)作为单元格序列给出(与上一节相同)。为方便起见,我们假设每个单元格包含K个替代项,并且所有替代项估计值都为正值。字符串的评估值(权重)将被视为该字符串每个字符的等级的乘积。如果在一个检查文法的形式指定的语言模型,则后处理问题可以被配制为在一组控件的离散优化(最大化)问题
。)让识别结果(假设模型)作为单元格序列给出(与上一节相同)。为方便起见,我们假设每个单元格包含K个替代项,并且所有替代项估计值都为正值。字符串的评估值(权重)将被视为该字符串每个字符的等级的乘积。如果在一个检查文法的形式指定的语言模型,则后处理问题可以被配制为在一组控件的离散优化(最大化)问题 (设定长度的所有行的在字母表与受理谓词)和功能性
(设定长度的所有行的在字母表与受理谓词)和功能性 ,其中,
,其中, 是所述符号估计
是所述符号估计 中的第i个小区。可以使用控件的完整枚举来解决任何离散的优化问题(即使用一组有限的控件)。所描述的算法以功能值的降序有效地遍历控件(行),直到有效性谓词接受真实值为止。我们将
中的第i个小区。可以使用控件的完整枚举来解决任何离散的优化问题(即使用一组有限的控件)。所描述的算法以功能值的降序有效地遍历控件(行),直到有效性谓词接受真实值为止。我们将 算法的最大迭代次数设置为具有谓词的最大估计值的最大行数。首先,我们按降序估计秩序的替代品,而我们进一步假设,对于任何细胞的不平等
算法的最大迭代次数设置为具有谓词的最大估计值的最大行数。首先,我们按降序估计秩序的替代品,而我们进一步假设,对于任何细胞的不平等 的是真实的
的是真实的 。该位置将是
。该位置将是 与该行对应的索引序列
与该行对应的索引序列 。职位评估,即该职位的功能价值,请考虑与该职位中包含的指数相对应的产品替代评估
。职位评估,即该职位的功能价值,请考虑与该职位中包含的指数相对应的产品替代评估 。要存储位置,您需要PositionBase数据结构,该结构允许您添加新位置(获取其地址),获取该地址处的位置并检查是否将指定位置添加到数据库中。在列出职位的过程中,我们将选择一个未评级最高的职位,然后通过将一个当前位置所包含的索引之一添加到当前队列中,将所有可以从当前职位获得的职位添加到队列中以供考虑。考虑队列PositionQueue将包含三元组
。要存储位置,您需要PositionBase数据结构,该结构允许您添加新位置(获取其地址),获取该地址处的位置并检查是否将指定位置添加到数据库中。在列出职位的过程中,我们将选择一个未评级最高的职位,然后通过将一个当前位置所包含的索引之一添加到当前队列中,将所有可以从当前职位获得的职位添加到队列中以供考虑。考虑队列PositionQueue将包含三元组 ,其中
,其中 -对未
-对未 复查位置的估计,-在PositionBase中从中获得该位置
复查位置的估计,-在PositionBase中从中获得该位置 的位置的地址,-位置元素的索引,其地址增加了一个以获得该位置。定位PositionQueue队列将需要一个数据结构,该数据结构允许您添加另一个三元组,以及检索具有最大评级的三元组。在算法的第一次迭代中,必须考虑
的位置的地址,-位置元素的索引,其地址增加了一个以获得该位置。定位PositionQueue队列将需要一个数据结构,该数据结构允许您添加另一个三元组,以及检索具有最大评级的三元组。在算法的第一次迭代中,必须考虑 具有最大估计值的位置。如果谓词在与该位置对应的线上取真值,则算法结束。否则,将位置添加到PositionBase中,并在PositionQueue全部添加视图的所有三元组,其中
具有最大估计值的位置。如果谓词在与该位置对应的线上取真值,则算法结束。否则,将位置添加到PositionBase中,并在PositionQueue全部添加视图的所有三元组,其中 ,所有位置都是PositionBase中起始位置的地址。在算法的每个后续迭代中,从PositionQueue中提取具有估计最大值的三元组,将所讨论的位置恢复到初始位置和索引的地址。如果该位置已经被添加到考虑的PositionBase位置的数据库中,则将其跳过,并从PositionQueue中提取具有估计最大值的下三个位置。否则,在与position对应的行上检查谓词值。如果谓词
,所有位置都是PositionBase中起始位置的地址。在算法的每个后续迭代中,从PositionQueue中提取具有估计最大值的三元组,将所讨论的位置恢复到初始位置和索引的地址。如果该位置已经被添加到考虑的PositionBase位置的数据库中,则将其跳过,并从PositionQueue中提取具有估计最大值的下三个位置。否则,在与position对应的行上检查谓词值。如果谓词
 在这条线上取真值,然后算法结束。如果谓词在此行上不接受真实值,则将该行添加到PositionBase(地址分配为
在这条线上取真值,然后算法结束。如果谓词在此行上不接受真实值,则将该行添加到PositionBase(地址分配为 ),所有派生的位置都添加到PositionQueue队列,然后进行下一次迭代。
),所有派生的位置都添加到PositionQueue队列,然后进行下一次迭代。FindSuitableString(M, N, K, P, C[1], ..., C[N]):
i : 1 ... N:
C[i]
( )
PositionBase PositionQueue
S_1 = {1, 1, 1, ..., 1}
P(S_1):
: S_1,
( )
S_1 PositionBase R(S_1)
i : 1 ... N:
K > 1, :
<Q * q[i][2] / q[i][1], R(S_1), i> PositionQueue
( )
( )
PositionBase M:
PositionQueue:
PositionQueue <Q, R, I> Q
S_from = PositionBase R
S_curr = {S_from[1], S_from[2], ..., S_from[I] + 1, ..., S_from[N]}
S_curr PositionBase:
:
S_curr PositionBase R(S_curr)
( )
P(S_curr):
: S_curr,
( )
i : 1 ... N:
K > S_curr[i]:
<Q * q[i][S_curr[i] + 1] / q[i][S_curr[i]],
R(S_curr),
i> PositionQueue
( )
( )
( )
( )
M
请注意,在迭代谓词将不超过检查一次,不会再有更多的增加的PositionBase,并且除了PositionQueue,从提取PositionQueue,以及在搜索PositionBase将不超过发生 一次。如果实现PositionQueue使用数据结构的“束”,并且对于组织PositionBase使用数据结构“ Bor”,则算法的复杂度为-
一次。如果实现PositionQueue使用数据结构的“束”,并且对于组织PositionBase使用数据结构“ Bor”,则算法的复杂度为-  其中
其中 ,最重要的测试取决于行的长度。基于检查语法的算法最重要的缺点可能是它无法处理不同长度的假设(这可能是由于分割错误而引起的:丢失或出现多余字符,粘连和剪切字符等),而可以在基于WFST的算法的错误模型中对假设的更改(例如“删除字符”,“添加字符”甚至“用一对替换字符”)进行编码。但是,速度和易用性(当使用新型字段时,您只需要使算法能够访问值验证功能),使得基于语法检查的方法成为文档识别系统开发人员中非常强大的工具。我们将这种方法用于大量的各个字段,例如各个日期,银行卡号(谓词-检查月球代码),带有校验和的机器可读文档区域的字段,以及许多其他字段。
,最重要的测试取决于行的长度。基于检查语法的算法最重要的缺点可能是它无法处理不同长度的假设(这可能是由于分割错误而引起的:丢失或出现多余字符,粘连和剪切字符等),而可以在基于WFST的算法的错误模型中对假设的更改(例如“删除字符”,“添加字符”甚至“用一对替换字符”)进行编码。但是,速度和易用性(当使用新型字段时,您只需要使算法能够访问值验证功能),使得基于语法检查的方法成为文档识别系统开发人员中非常强大的工具。我们将这种方法用于大量的各个字段,例如各个日期,银行卡号(谓词-检查月球代码),带有校验和的机器可读文档区域的字段,以及许多其他字段。
该出版物是根据以下文章准备的:基于验证语法的用于后处理识别结果的通用算法。K.B. 布拉托夫(D.P.)尼古拉耶夫(V.V. Postnikov。ISA RAS会议论文集,第65卷,第4期,2015年,第68-73页。