序幕
这是该系列文章中的第二篇,共四篇,将深入介绍指针,堆栈,堆,转义分析和Go /指针语义的机制和设计。这篇文章是关于堆和转义分析的。目录:- 堆栈和指针上的语言力学(翻译)
- 转义分析的语言力学
- 记忆剖析的语言机制
- 数据与语义设计哲学
介绍
在本系列的第一篇文章中,我使用一个示例讨论了指针机制的基础,在该示例中,值在goroutines之间的堆栈中分布。我没有告诉您拆分堆栈上的值时会发生什么。要理解这一点,您需要找出可能值所在的另一个内存区域:关于``堆''的信息。有了这些知识,您就可以开始研究“转义分析”。转义分析是编译器用来确定程序创建的值的位置的过程。特别是,编译器执行静态代码分析,以确定是否可以将值放置在构建它的函数的堆栈框架上,或者是否应该将该值“转义”到堆中。Go中没有一个关键字或函数可以用来告诉编译器做出哪个决定。只有有条件地编写代码的方式才能影响此决策。堆
堆是除堆栈之外用于存储值的第二个内存区域。堆不会像堆栈那样自清理,因此使用此内存会更昂贵。首先,成本与垃圾收集器(GC)有关,垃圾收集器(GC)应保持该区域清洁。 GC启动时,它将使用处理器可用功率的25%。此外,它可能会造成微秒级的“停止世界”延迟。使用GC的优点是,您不必担心过去一直很复杂且容易出错的堆内存管理。堆中的值会激发Go中的内存分配。这些分配给GC带来了压力,因为必须删除指针不再引用的堆中的每个值。您需要检查和删除的值越多,GC在每次启动时必须完成的工作越多。因此,刺激算法一直在努力平衡堆大小和执行速度。堆栈共享
在Go中,不允许goroutines具有指向另一个goroutine堆栈上的内存的指针。这是由于以下事实:当堆栈应增加或减少时,goroutine的堆栈存储器可以替换为新的存储块。如果在运行时必须在另一个goroutine中跟踪堆栈指针,则您将不得不进行过多的管理,并且在更新指向这些堆栈的指针时的“停止世界”延迟将是惊人的。这是一个由于增长而被替换多次的堆栈示例。查看第2行和第6行中的输出。您将在主堆栈帧内看到两次字符串值的地址更改。play.golang.org/p/pxn5u4EBSI逃生力学
每次在函数的堆栈框架区域之外共享值时,会将其放置(或分配)到堆中。逃逸分析算法的任务是查找此类情况并维持程序中的完整性级别。诚信是为了确保获得任何价值始终是准确,一致和高效的。看一下这个例子,学习逃生分析的基本机制。play.golang.org/p/Y_VZxYteKO清单101 package main
02
03 type user struct {
04 name string
05 email string
06 }
07
08 func main() {
09 u1 := createUserV1()
10 u2 := createUserV2()
11
12 println("u1", &u1, "u2", &u2)
13 }
14
15
16 func createUserV1() user {
17 u := user{
18 name: "Bill",
19 email: "bill@ardanlabs.com",
20 }
21
22 println("V1", &u)
23 return u
24 }
25
26
27 func createUserV2() *user {
28 u := user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", &u)
34 return &u
35 }
我使用go:noinline指令,以便编译器不会直接在main中嵌入这些函数的代码。嵌入将删除函数调用并使此示例复杂化。我将在下一篇文章中讨论嵌入的副作用。清单1显示了一个具有两个不同功能的程序,这些程序创建一个类型为user的值并将其返回给调用者。函数的第一个版本在返回时使用值的语义。清单216 func createUserV1() user {
17 u := user{
18 name: "Bill",
19 email: "bill@ardanlabs.com",
20 }
21
22 println("V1", &u)
23 return u
24 }
我说过该函数在返回时使用值的语义,因为此函数创建的类型为user的值被复制并传递给调用堆栈。这意味着调用函数将接收值本身的副本。您可以看到在第17至20行执行的类型为user的值的创建。然后,在第23行,该值的副本传递到调用堆栈并返回给调用者。返回函数后,堆栈如下所示。图1 在图1中,您可以看到在调用createUserV1之后,两个帧中都存在一个类型为user的值。在该函数的第二个版本中,指针语义用于返回。清单3
在图1中,您可以看到在调用createUserV1之后,两个帧中都存在一个类型为user的值。在该函数的第二个版本中,指针语义用于返回。清单327 func createUserV2() *user {
28 u := user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", &u)
34 return &u
35 }
我说过,函数在返回时会使用指针语义,因为此函数创建的user类型的值由调用堆栈共享。这意味着调用函数接收值所在的地址的副本。您可以看到在第28至31行中使用相同的结构文字来创建类型为user的值,但在第34行中,函数的返回结果不同。而不是将值的副本传递回调用堆栈,而是传递值的地址的副本。基于此,您可能认为调用之后的堆栈看起来像这样。图片2 如果您在图2中看到的确实发生了,那么您将遇到完整性问题。指针指向不再有效的对内存的调用堆栈。下次调用该函数时,所指定的存储器将被重新格式化并重新初始化。这是逃生分析开始保持完整性的地方。在这种情况下,编译器将确定在createUserV2堆栈框架内创建类型为user的值是不安全的,因此它将在堆上创建一个值。这将在28号线的施工过程中立即发生。
如果您在图2中看到的确实发生了,那么您将遇到完整性问题。指针指向不再有效的对内存的调用堆栈。下次调用该函数时,所指定的存储器将被重新格式化并重新初始化。这是逃生分析开始保持完整性的地方。在这种情况下,编译器将确定在createUserV2堆栈框架内创建类型为user的值是不安全的,因此它将在堆上创建一个值。这将在28号线的施工过程中立即发生。可读性
从上一篇文章中学到的,函数可以通过框架指针直接访问其框架内的内存,但是访问框架外部的内存则需要间接访问。这意味着必须通过指针间接访问落入堆中的值。记住createUserV2代码的样子。清单427 func createUserV2() *user {
28 u := user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", &u)
34 return &u
35 }
该语法隐藏了此代码中实际发生的情况。在第28行声明的变量u表示类型为user的值。 Go中的构造无法准确告诉您该值在内存中的存储位置,因此在第34行的return语句之前,您不知道该值将被堆放。这意味着尽管u表示类型为user的值,但必须通过指针访问该值。您可以在函数调用后可视化如下所示的堆栈。图片3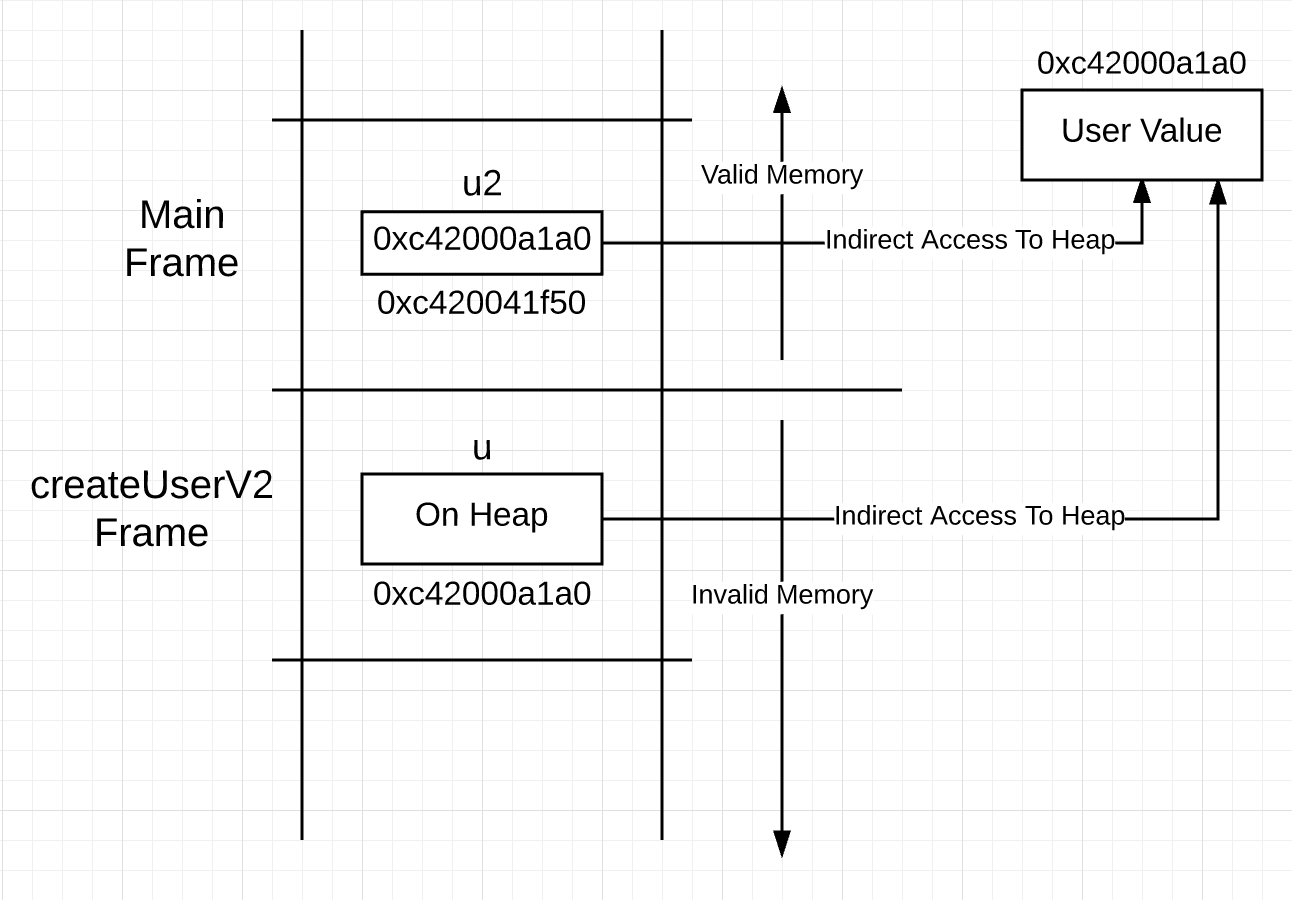 createUserV2的堆栈帧中的u变量表示堆上的值,而不是堆栈上的值。这意味着使用u访问值需要访问指针,而不是语法建议的直接访问。您可能会想,为什么不立即创建一个指针,因为访问它表示的值仍然需要使用指针?清单5
createUserV2的堆栈帧中的u变量表示堆上的值,而不是堆栈上的值。这意味着使用u访问值需要访问指针,而不是语法建议的直接访问。您可能会想,为什么不立即创建一个指针,因为访问它表示的值仍然需要使用指针?清单527 func createUserV2() *user {
28 u := &user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", u)
34 return u
35 }
如果这样做,您将失去可读性,而这在您的代码中是不会丢失的。离开函数主体一秒钟,然后专注于返回。清单634 return u
35 }
这是什么回事呢?他所说的只是将u的副本推送到调用堆栈中。同时,使用&运算符时返回的内容告诉您什么?清单734 return &u
35 }
感谢&return运算符,它现在告诉您您正在共享调用堆栈,因此进入了堆。请记住,指针旨在一起使用,在阅读代码时,它们将&运算符替换为短语“ sharing”。就可读性而言,它非常强大。这是我不想失去的东西。这是另一个使用指针语义构造值会降低可读性的示例。清单801 var u *user
02 err := json.Unmarshal([]byte(r), &u)
03 return u, err
为了使此代码正常工作,在第02行调用json.Unmarshal时,必须将指针传递给指针变量。 json.Unmarshal调用将创建类型为user的值,并将其地址分配给指针变量。play.golang.org/p/koI8EjpeIx这段代码说:01:创建一个值为null的user类型的指针。02:与json.Unmarshal函数共享u变量。03:将变量u的副本返回给调用方。由json.Unmarshal函数创建的类型为user的值传递给调用者并不完全明显。在变量声明期间使用值的语义时,可读性如何变化?清单901 var u user
02 err := json.Unmarshal([]byte(r), &u)
03 return &u, err
这段代码说的是:01:使用空值创建类型为user的值。02:与json.Unmarshal函数共享u变量。03:与调用方共享变量u。一切都非常清楚。第02行在json.Unmarshal的调用堆栈中拆分user类型的值,第03行将调用堆栈的值拆分回调用方。此共享将导致该值移动到堆。在创建值时使用值的语义,并利用&运算符的可读性来阐明如何分隔值。编译器报告
要查看编译器做出的决定,可以要求编译器提供报告。您要做的就是在调用go build时将-gcflags开关与-m选项一起使用。实际上,您可以使用4个级别的-m,但是在2个级别的信息之后,它变得太多了。我将使用2级-m。清单10$ go build -gcflags "-m -m"
./main.go:16: cannot inline createUserV1: marked go:noinline
./main.go:27: cannot inline createUserV2: marked go:noinline
./main.go:8: cannot inline main: non-leaf function
./main.go:22: createUserV1 &u does not escape
./main.go:34: &u escapes to heap
./main.go:34: from ~r0 (return) at ./main.go:34
./main.go:31: moved to heap: u
./main.go:33: createUserV2 &u does not escape
./main.go:12: main &u1 does not escape
./main.go:12: main &u2 does not escape
您可以看到编译器正在报告将值转储到堆的决策。编译器怎么说?首先,再次查看createUserV1和createUserV2函数以刷新它们在内存中。清单1316 func createUserV1() user {
17 u := user{
18 name: "Bill",
19 email: "bill@ardanlabs.com",
20 }
21
22 println("V1", &u)
23 return u
24 }
27 func createUserV2() *user {
28 u := user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", &u)
34 return &u
35 }
让我们从报告中的这一行开始。清单14./main.go:22: createUserV1 &u does not escape
这表明对createUserV1函数内部的println函数的调用不会导致用户类型转储到堆中。这种情况必须检查,因为它与println函数一起使用。接下来,在报告中查看这些行。清单15./main.go:34: &u escapes to heap
./main.go:34: from ~r0 (return) at ./main.go:34
./main.go:31: moved to heap: u
./main.go:33: createUserV2 &u does not escape
这些行说与变量u关联的用户类型的值(具有命名的用户类型,在第31行创建)由于第34行的返回而被转储到堆中。最后一行与之前的内容相同,该行上的println调用33不重置用户类型。阅读这些报告可能会造成混淆,并且可能会有所不同,具体取决于所讨论的变量的类型是基于命名类型还是文字类型。像以前一样,将u变量修改为文字类型* user而不是命名类型user。清单1627 func createUserV2() *user {
28 u := &user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", u)
34 return u
35 }
再次运行报告。清单17./main.go:30: &user literal escapes to heap
./main.go:30: from u (assigned) at ./main.go:28
./main.go:30: from ~r0 (return) at ./main.go:34
现在该报告说,变量u所引用的用户类型的值(在第28行上创建的具有文字类型* user的值)由于在第34行上的返回而被转储到堆中。结论
创建值并不能确定其位置。只有值的分割方式将决定编译器将如何处理该值。每次您在调用堆栈中共享一个值时,该值都会转储到堆中。值可能会从堆栈中逸出还有其他原因。我将在下一篇文章中谈论它们。这些文章的目的是为选择对任何给定类型使用值语义或指针语义提供指导。每个语义都与利润和价值配对。值的语义将值存储在堆栈上,这减少了GC的负担。但是,必须存储,跟踪和维护具有相同值的不同副本。指针语义将值放入堆中,这可能会对GC造成压力。但是,它们是有效的,因为仅需要存储,跟踪和维护一个值。关键是正确,一致和平衡地使用每种语义。