大家好。在Python神经网络课程开始之前,我们已经为您准备了另一篇有趣的材料的翻译。
我们很高兴介绍PyCaret,这是一个开放源代码的Python机器学习库,用于在低代码环境中在有教师和无教师的情况下学习和部署模型。 PyCaret允许您在选定的笔记本环境中几秒钟内从数据准备过渡到模型部署。与其他开放式机器学习库相比,PyCaret是一种低代码替代方案,可以用几句话替换数百行代码。更有效的实验速度将成倍增加。 PyCaret本质上是Python外壳,覆盖了多个机器学习库,例如scikit-learn,XGBoost,Microsoft LightGBM,spaCy还有很多其他PyCaret简单易用。PyCaret执行的所有操作都顺序存储在准备部署的管道中。无论是添加缺失值,转换分类数据,工程特征还是优化超参数,PyCaret都能使所有这些自动化。要了解有关PyCaret的更多信息,请观看此简短视频。PyCaret入门
可以使用pip安装PyCaret版本1.0.0的第一个稳定版本。使用命令行界面或笔记本环境,然后运行以下命令来安装PyCaret。pip install pycaret
如果您使用的是Azure笔记本或Google Colab,请运行以下命令:!pip install pycaret
当您安装PyCaret时,所有依赖项将自动安装。您可以在此处查看依赖项列表。再简单不过了
演练
1.数据采集在本演练中,我们将使用糖尿病数据集,我们的目标是根据压力,血液胰岛素水平,年龄等几个因素预测患者的结果(二进制0或1)。 。该数据集可在PyCaret GitHub存储库上找到。直接从存储库导入数据集的最简单方法是使用get_data模块中的函数pycaret.datasets。from pycaret.datasets import get_data
diabetes = get_data('diabetes')
 PyCaret可以直接与pandas2个数据帧一起使用设置环境在PyCaret中进行机器学习的任何实验都始于通过导入必要的模块并进行初始化来设置环境
PyCaret可以直接与pandas2个数据帧一起使用设置环境在PyCaret中进行机器学习的任何实验都始于通过导入必要的模块并进行初始化来设置环境setup()。在此示例中将使用的模块是pycaret.classification。导入模块后,setup()通过定义数据框('diabetes')和目标变量('Class variable')对其进行初始化。from pycaret.classification import *
exp1 = setup(diabetes, target = 'Class variable')
 所有预处理都在中进行
所有预处理都在中进行setup()。 PyCaret使用20多个函数在机器学习之前准备数据,根据函数中定义的参数创建了一系列转换setup()。它会自动构建管道中的所有依赖项,因此您无需手动控制对测试或新(不可见)数据集的转换的顺序执行。PyCaret管道可以轻松地从一种环境转移到另一种环境或部署到生产环境。在下面,您可以熟悉自第一版以来PyCaret中可用的预处理功能。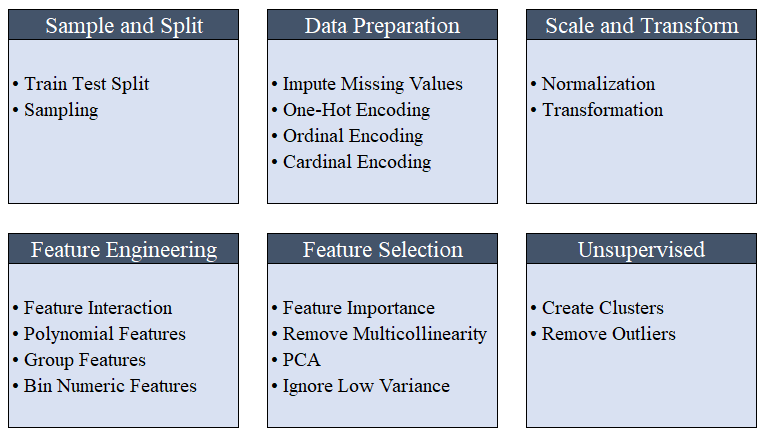 数据预处理步骤对于机器学习是必不可少的,例如在初始化过程中会自动执行添加缺失值,编码质量变量,编码标签(1或0的是或否)以及训练分离测试
数据预处理步骤对于机器学习是必不可少的,例如在初始化过程中会自动执行添加缺失值,编码质量变量,编码标签(1或0的是或否)以及训练分离测试setup()。您可以在此处了解有关PyCaret中预处理功能的更多信息。3.模型比较这是在进行教师培训(分类或回归)时建议执行的第一步。此功能训练模型库中的所有模型,并使用针对K块(默认为10个块)的交叉验证相互比较估计的指标。估计使用如下:- 分类:精度,AUC,召回率,精度,F1,Kappa
- 回归:MAE,MSE,RMSE,R2,RMSLE,MAPE
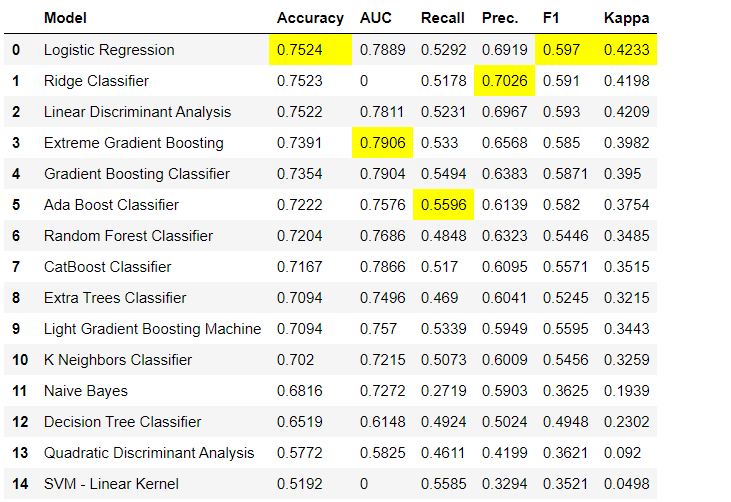 默认情况下,使用10个以上的块进行交叉验证来评估指标。可以通过更改参数的值来更改块数
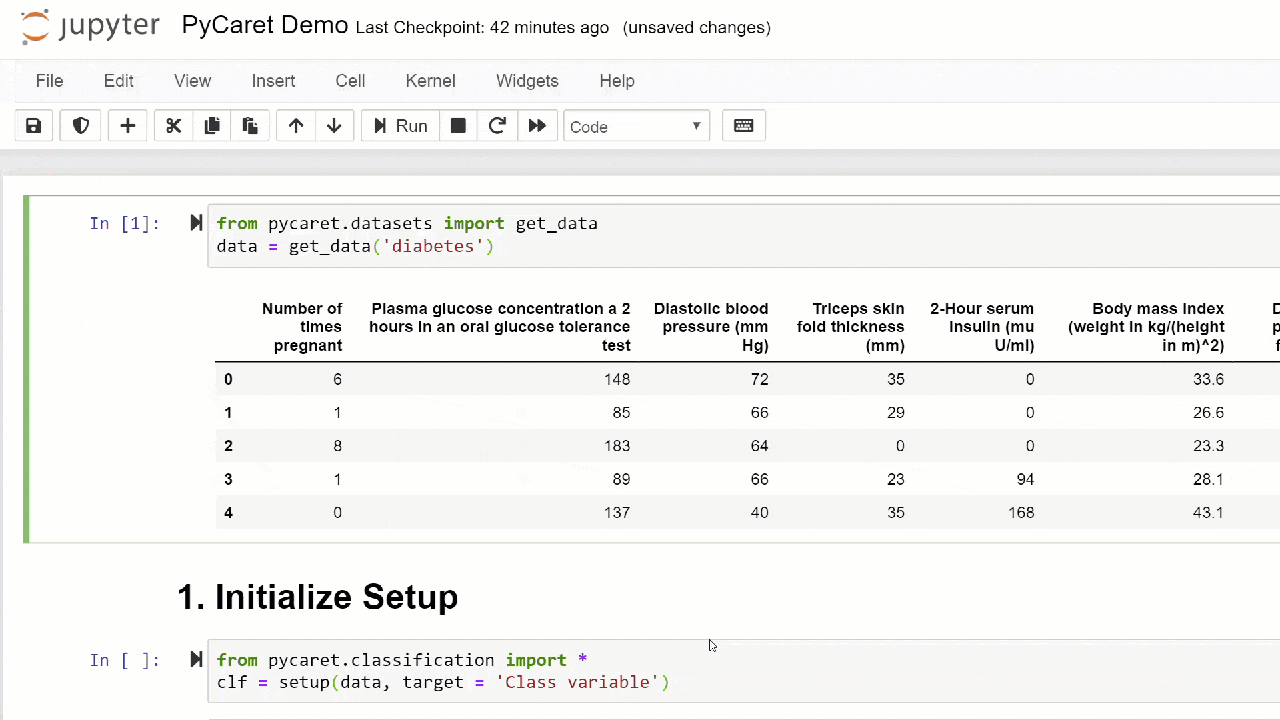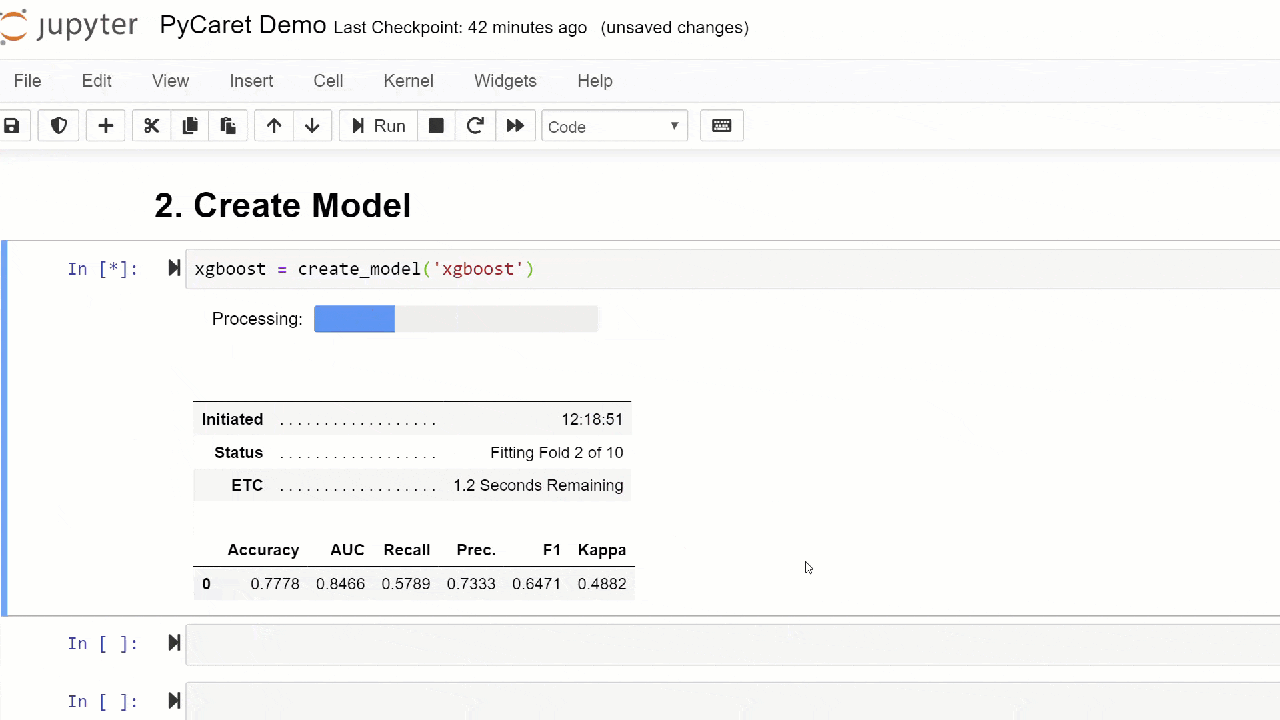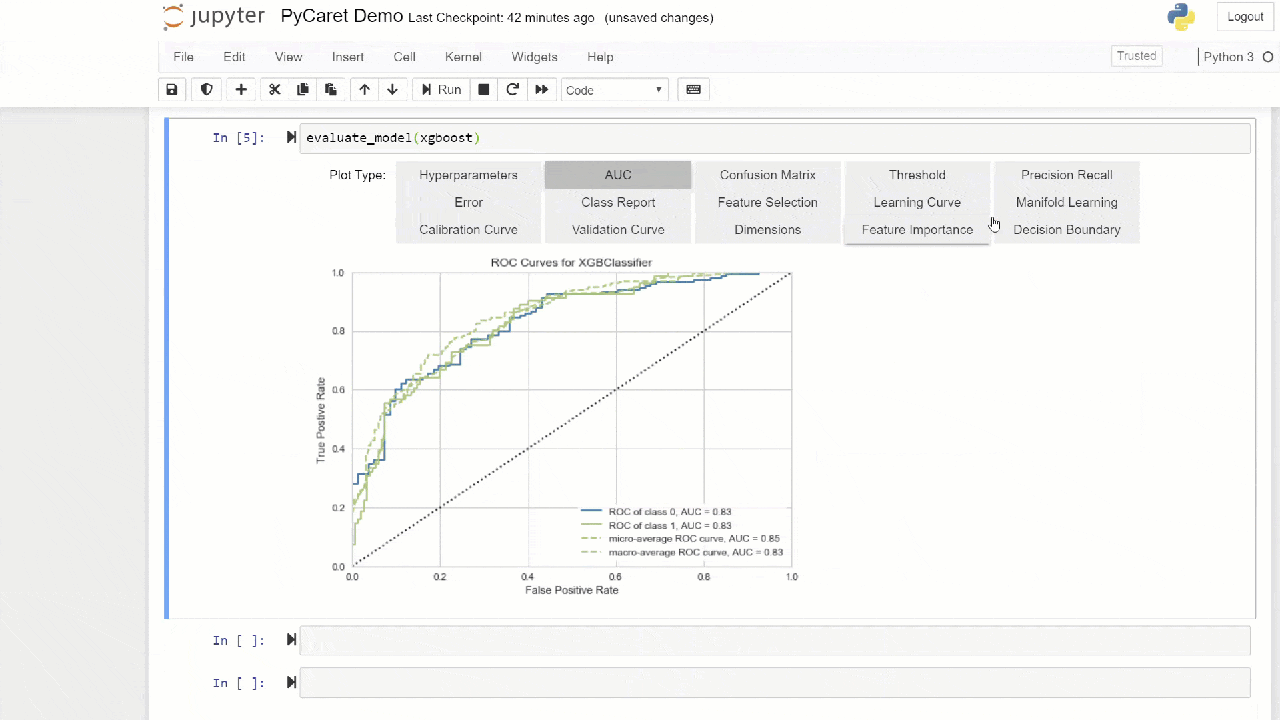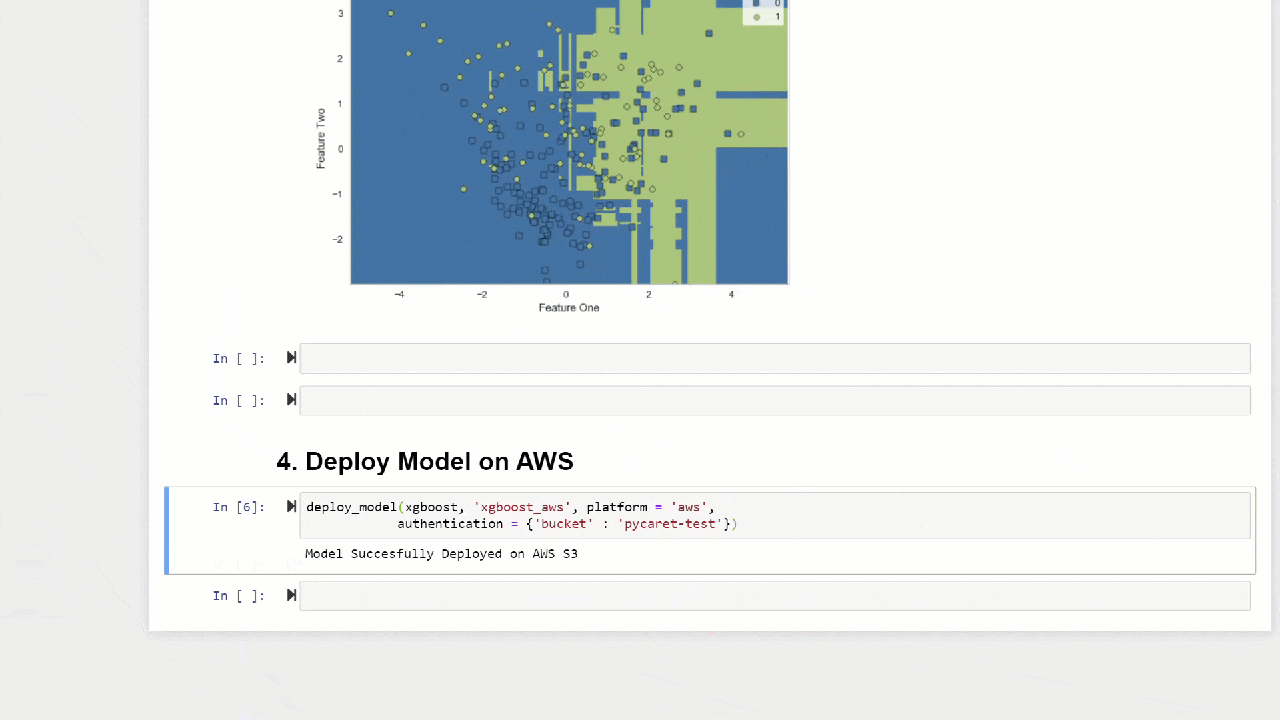
默认情况下,使用10个以上的块进行交叉验证来评估指标。可以通过更改参数的值来更改块数fold。默认表按“精度”从最高到最低排序。也可以使用选项更改排序顺序sort。4.创建模型在任何PyCaret模块中创建模型非常简单,您只需要编写模型即可create_model。该函数在输入处采用一个参数,即 型号名称作为字符串传递。此函数返回具有交叉验证分数和训练有素的模型对象的表。adaboost = create_model('ada')
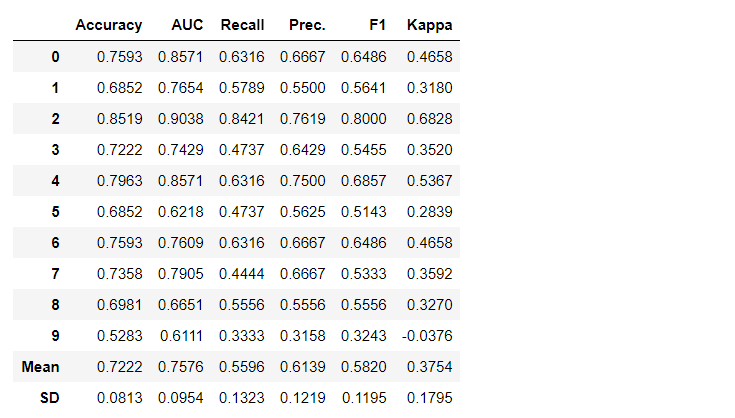 变量“ adaboost”存储训练后的模型的对象,该对象返回一个函数
变量“ adaboost”存储训练后的模型的对象,该对象返回一个函数create_model,该函数在后台是scikit-learn评估程序。可以使用period ( . )变量后面的函数来访问训练对象的源属性。您可以在下面找到使用示例。 PyCaret具有60多个开源即用型算法。在PyCaret提供评估/型号的完整列表,可以发现在这里。5.模型设置该功能
PyCaret具有60多个开源即用型算法。在PyCaret提供评估/型号的完整列表,可以发现在这里。5.模型设置该功能tune_model用于自动配置机器学习模型的超参数。PyCaret的用途random grid search在特定的搜索空间中。该函数返回一个带有交叉验证的估计值的表格和一个训练模型的对象。tuned_adaboost = tune_model('ada')
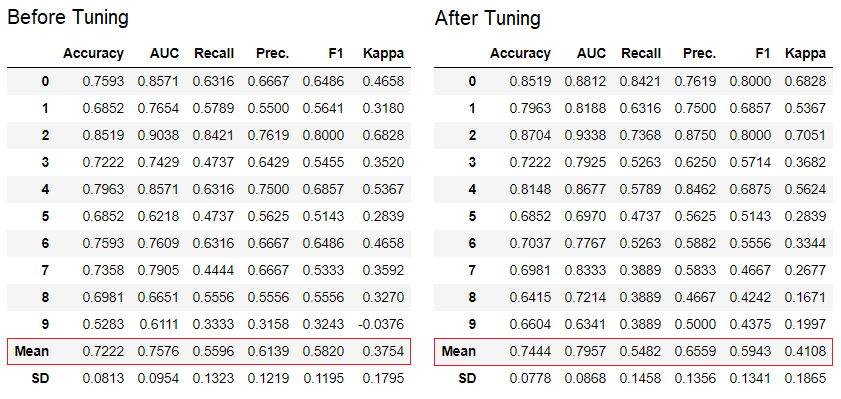 可以将
可以将tune_model非教师学习模块(例如pycaret.nlp,pycaret.clustering和pycaret.anomaly)中的功能与教师学习模块结合使用。例如,PyCaret中的NLP模块可用于number of topics通过与老师一起评估模型的目标函数或损失函数(例如“准确性”或“ R2”)来调整参数。6.模型集合该功能ensemble_model用于创建一组训练有素的模型。在输入处采用一个参数-训练模型的对象。该函数返回一个带有交叉验证的估计值的表格和一个训练模型的对象。
dt = create_model('dt')
dt_bagged = ensemble_model(dt)
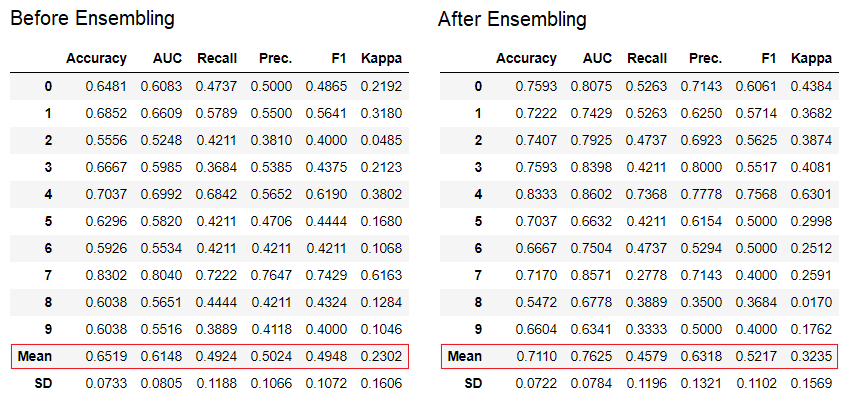 默认情况下,在创建整体时会使用“装袋”方法,可以使用
默认情况下,在创建整体时会使用“装袋”方法,可以使用method函数中的参数将其更改为“提升” ensemble_model。PyCaret还提供函数blend_models和stack_models来组合多个训练好的模型。7.模型可视化您可以使用函数评估性能并诊断经过训练的机器学习模型plot_model。它接受训练模型的对象和字符串形式的图形类型。
adaboost = create_model('ada')
plot_model(adaboost, plot = 'auc')
plot_model(adaboost, plot = 'boundary')
plot_model(adaboost, plot = 'pr')
plot_model(adaboost, plot = 'vc')
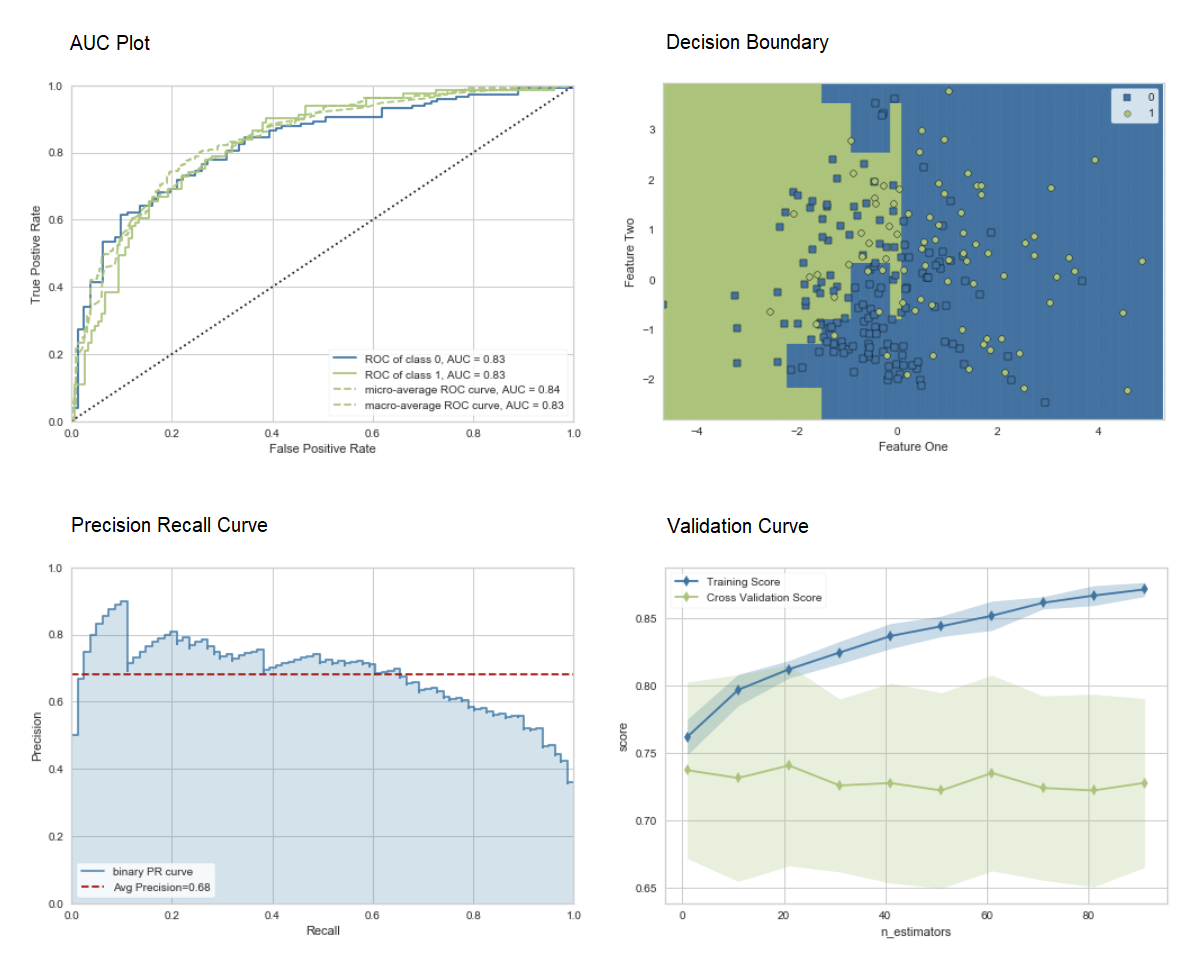 在这里,您可以了解有关PyCaret中可视化的更多信息。您还可以使用该功能
在这里,您可以了解有关PyCaret中可视化的更多信息。您还可以使用该功能evaluate_model通过笔记本计算机用户界面查看图形。模块中 的功能可用于可视化文本主体和语义主题模型。在这里您可以了解有关它们的更多信息。8.模型的解释
当数据是非线性的,这在现实生活中经常发生时,我们总是看到树状模型比简单的高斯模型要好得多。但是,这是由于无法解释,因为树模型不像线性模型那样提供简单的系数。 PyCaret实施SHAP(
的功能可用于可视化文本主体和语义主题模型。在这里您可以了解有关它们的更多信息。8.模型的解释
当数据是非线性的,这在现实生活中经常发生时,我们总是看到树状模型比简单的高斯模型要好得多。但是,这是由于无法解释,因为树模型不像线性模型那样提供简单的系数。 PyCaret实施SHAP(plot_modelpycaret.nlpSHapley Additive exPlanations)使用函数interpret_model。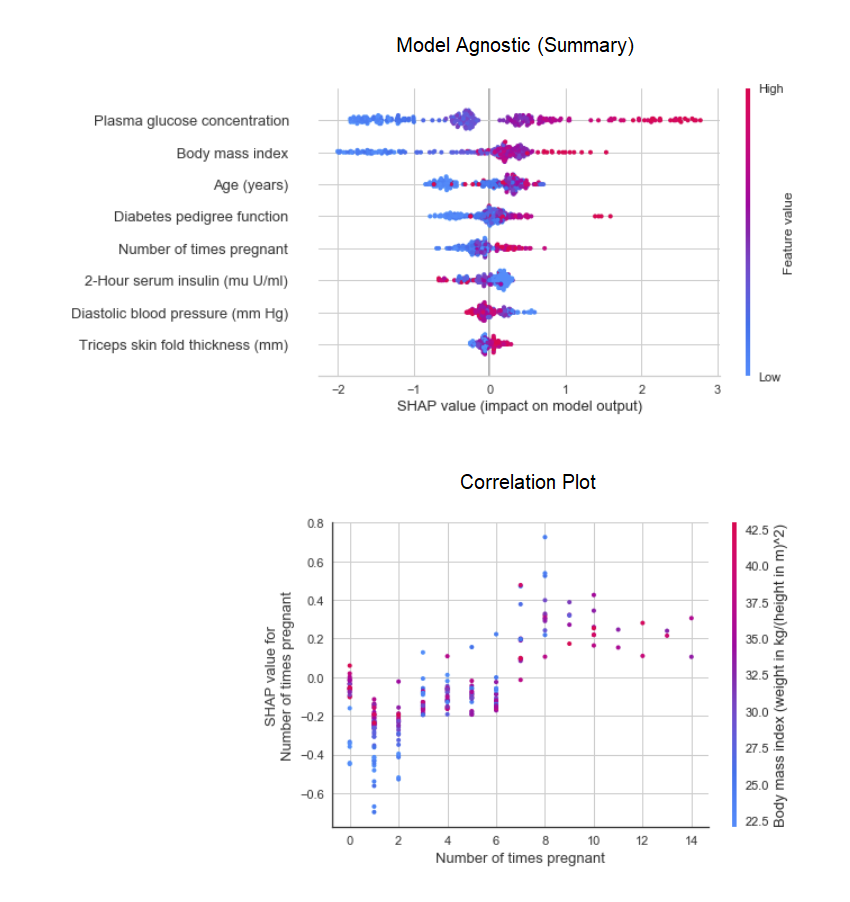 可以使用“原因”图来估算测试数据集中特定数据点的解释。在下面的示例中,我们测试了测试数据集中的第一个实例。
可以使用“原因”图来估算测试数据集中特定数据点的解释。在下面的示例中,我们测试了测试数据集中的第一个实例。 9.预测模型到目前为止,我们获得的结果基于训练数据集上K块的交叉验证(默认为70%)。为了查看测试/保留数据集上的预测和模型性能,使用了一个函数
9.预测模型到目前为止,我们获得的结果基于训练数据集上K块的交叉验证(默认为70%)。为了查看测试/保留数据集上的预测和模型性能,使用了一个函数predict_model。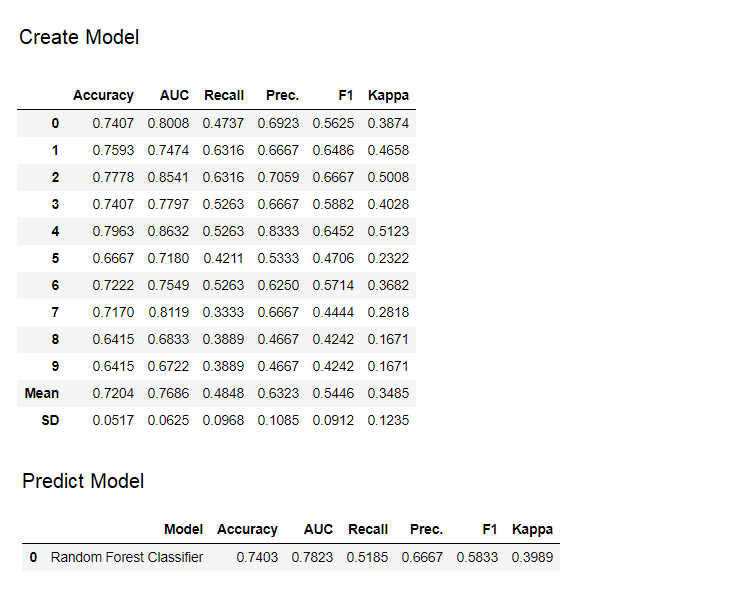 该函数
该函数predict_model用于预测不可见的数据集。现在,我们将使用与训练相同的数据集,作为新的不可见数据集的代理。在实践中,功能predict_model每次在新的不可见数据集上都将迭代使用。 该函数
该函数predict_model还可以对可以使用stack_models和create_stacknet函数创建的模型的顺序链进行预测。该函数predict_model还可以使用deploy_model函数直接对AWS S3上托管的模型进行预测。10.部署模型使用训练有素的模型为新数据集创建预测的方法之一是使用该功能。predict_model在训练模型的同一笔记本/ IDE中。但是,为新的(不可见的)数据集生成预测是一个迭代过程。根据使用情况,预测的频率可能会有所不同,从实时预测到批量预测。deploy_modelPyCaret中的功能允许您部署整个管道,包括笔记本环境中云中经过训练的模型。deploy_model(model = rf, model_name = 'rf_aws', platform = 'aws',
authentication = {'bucket' : 'pycaret-test'})
11.保存模型/保存实验
训练后,可以将包含所有预处理转换和训练模型的对象的整个管道保存在二进制pickle文件中。
adaboost = create_model('ada')
save_model(adaboost, model_name = 'ada_for_deployment')
 您还可以将包含所有中间输出的整个实验保存为单个二进制文件。save_experiment(EXPERIMENT_NAME =“my_first_experiment”)
您还可以将包含所有中间输出的整个实验保存为单个二进制文件。save_experiment(EXPERIMENT_NAME =“my_first_experiment”) 可以加载使用功能保存的模型和实验
可以加载使用功能保存的模型和实验load_model,并load_experiment从所有PyCaret模块。12.下一指南在下一指南中,我们将展示如何在Power BI中使用训练有素的机器学习模型在实际生产环境中生成批量预测。您还可以在以下模块中阅读初学者的记事本:什么是开发管道?
我们正在积极努力改善PyCaret。我们即将推出的开发流程包括新的时间序列预测模块,TensorFlow集成以及PyCaret的重大可扩展性改进。如果您想分享您的反馈意见并帮助我们改进,可以在网站上填写表格,或在GitHub或LinkedIn的页面上发表评论。想更多地了解特定模块?
从第一个发行版开始,PyCaret 1.0.0具有以下可用模块。请通过下面的链接熟悉文档和工作示例。分类回归聚类异常搜索自然文本处理(NLP)关联规则训练重要连结
如果您喜欢PyCaret,请将️放在GitHub上。要了解有关PyCaret的更多信息,可以在LinkedIn和Youtube上关注我们。
了解有关该课程的更多信息。