本文的翻译是专门为“数据库”课程的学生准备的。
您可能不了解sysbench 随机数生成的知识 Sysbench是一种流行的性能测试工具。它最初由彼得·扎伊采夫(Peter Zaitsev)于2000年代初编写,现已成为测试和基准测试的事实上的标准。目前,它由Alexei Kopytov支持,并发布在Github 上。但是,我注意到,尽管分布广泛,但是sysbench中的许多内容还是有些陌生的时刻。例如,可以使用Lua轻松修改MySQL测试或配置内置随机数生成器的参数。这篇文章是关于什么的?
我写了这篇文章,以展示根据您的需求定制sysbench多么容易。有很多方法可以扩展sysbench的功能,其中一种方法是配置随机标识符(ID)的生成。默认情况下,sysbench带有五个用于生成随机数的不同选项。但是很多时候(实际上几乎从来没有),没有明确指出它们,甚至更少的时候您可以看到生成参数(对于可用的选项)。如果您有一个问题:“我为什么对此感兴趣?毕竟,默认值非常合适,''那么这篇文章旨在帮助您了解为什么并非总是如此。开始吧
在sysbench中生成随机数的方法有哪些?当前已实现以下功能(您可以通过--help选项轻松看到它们):- 特殊(特殊发行)
- 高斯(高斯分布)
- 帕累托(帕累托分布)
- Zipfian(Zipf分布)
- 均匀(均匀分布)
默认情况下,Special与以下参数一起使用:rand-spec-iter = 12 -特殊分布的迭代次数rand-spec-pct = 1 -具有特殊分布的``特殊''值落入的整个范围的百分比rand-spec-res = 75 -用于特殊分配的“特殊”值的百分比
由于我喜欢简单且易于重现的测试和脚本,因此将使用以下sysbench命令收集所有后续数据:- sysbench ./src/lua/oltp_read.lua -mysql_storage_engine = innodb –db-driver = mysql –tables = 10 –table_size = 100准备
- sysbench ./src/lua/oltp_read_write.lua –db-driver=mysql –tables=10 –table_size=100 –skip_trx=off –report-interval=1 –mysql-ignore-errors=all –mysql_storage_engine=innodb –auto_inc=on –histogram –stats_format=csv –db-ps-mode=disable –threads=10 –time=60 –rand-type=XXX run
随意尝试一下。脚本描述和数据可以在这里找到。为什么sysbench使用随机数生成器?目的之一是生成将在查询中使用的ID。因此,在我们的示例中,考虑到创建10个表(每个表有100行),将生成1到100之间的数字。如果您如上所述运行sysbench并仅更改-rand-type怎么办?我运行了该脚本,并使用常规日志来收集和分析生成的ID值的频率。结果是:特殊 均匀
均匀 齐夫式
齐夫式 Pareto
Pareto 高斯
高斯 可以看出这个参数很重要,对吧?毕竟,sysbench完全可以满足我们的期望。让我们仔细看一下每个分布。
可以看出这个参数很重要,对吧?毕竟,sysbench完全可以满足我们的期望。让我们仔细看一下每个分布。特别
默认情况下使用Special,因此,如果您不指定rand-type,则sysbench将使用Special。特殊使用非常有限数量的ID值。在我们的示例中,我们可以看到主要使用值50-51,在44-56之间的剩余值非常少,而实际上没有使用其他值。请注意,所选值在1-100的可用范围中间。在这种情况下,峰值约为代表样品2%的两个ID。如果我将记录数量增加到一百万,则峰值将保留,但将达到7493,占样本总数的0.74%。由于这将更具限制性,因此页面数可能会超过一页。均匀(均匀分布)
顾名思义,如果我们使用Uniform,则所有值都将用作ID,并且分布将是...统一的。Zipfian(Zipf分布)
Zipf分布,有时也称为zeta分布,是在语言学,保险和罕见事件建模中常用的离散分布。在这种情况下,sysbench将使用以最小(1)开头的数字,并很快减少使用频率,而转为更大的数字。帕累托(Pareto)
帕累托适用“ 80-20”规则。在这种情况下,生成的ID将被涂抹得更少,并且将更集中在一个小段中。在我们的示例中,所有ID中有52%的值是1,而前10个数字中有73%的值。高斯(高斯分布)
高斯分布(正态分布)是公知的和熟悉的。它主要用于围绕中心因素进行统计和预测。在这种情况下,使用的ID沿着钟形曲线分布,从平均值开始,然后逐渐减小到边缘。这有什么意义呢?
以上每个选项都有其自己的用途,可以按用途分组。帕累托和特别关注热点。在这种情况下,应用程序一次又一次使用相同的页面/数据。这可能是我们需要的,但是我们必须了解我们在做什么,并且不要在这里犯错误。例如,如果我们在读取时测试InnoDB页面压缩的性能,则应避免使用Special或Pareto的默认值。如果我们有一个1 TB的数据集和一个30 GB的缓冲池,并且我们多次请求相同的页面,则该页面已经从磁盘读取,并且可以在内存中不压缩地使用。简而言之,这样的测试浪费了时间和精力。如果我们需要检查记录的性能,则同样。一遍又一遍地写同一页不是最好的选择。性能测试如何?同样,我们要测试性能,但是在什么情况下?重要的是要理解,生成随机数的方法会极大地影响测试结果。而您的“足够好的默认值”可能会导致错误的结论。下图显示了不同的延迟,具体取决于rand类型(测试类型,时间,其他参数和线程数在各处相同)。从类型到类型,延迟明显不同: 在这里,我正在读写,数据取自Performance Schema(
在这里,我正在读写,数据取自Performance Schema(sys.schema_table_statistics)不出所料,Pareto和Special花费的时间比其他时间长得多,导致该系统(MySQL-InnoDB)人为地受到一个“热点”竞争的影响。更改rand类型不仅会影响延迟,还会影响处理的行数(如性能模式所示)。
 鉴于以上所有内容,重要的是要了解我们正在尝试评估和测试的内容。如果我的目标是在所有级别上测试系统性能,则我可能更喜欢使用Uniform,它会平均加载数据集/数据库服务器/系统,并且更有可能平均分配读取/加载/写入。如果我的工作是处理热点,那么Pareto和Special可能是正确的选择。但是不要盲目使用默认值。它们可能适合您,但通常是针对极端情况的。以我的经验,您经常可以调整设置以获得所需的结果。例如,您想通过加宽间隔来使用中间的值,以使没有尖峰(默认情况下为Special)或钟形(Gaussian)。您可以配置特殊以获得以下内容:
鉴于以上所有内容,重要的是要了解我们正在尝试评估和测试的内容。如果我的目标是在所有级别上测试系统性能,则我可能更喜欢使用Uniform,它会平均加载数据集/数据库服务器/系统,并且更有可能平均分配读取/加载/写入。如果我的工作是处理热点,那么Pareto和Special可能是正确的选择。但是不要盲目使用默认值。它们可能适合您,但通常是针对极端情况的。以我的经验,您经常可以调整设置以获得所需的结果。例如,您想通过加宽间隔来使用中间的值,以使没有尖峰(默认情况下为Special)或钟形(Gaussian)。您可以配置特殊以获得以下内容: 在这种情况下,ID仍在附近,并且存在竞争。但是一个“热点”的影响较小,因此,现在可能与多个ID发生冲突,根据一个页面上的记录数,这些ID可能在多个页面上。另一个例子是分区。例如,如何检查系统如何处理分区,关注最新数据,归档旧数据?简单!还记得帕累托分布图吗?您可以根据需要进行更改。
在这种情况下,ID仍在附近,并且存在竞争。但是一个“热点”的影响较小,因此,现在可能与多个ID发生冲突,根据一个页面上的记录数,这些ID可能在多个页面上。另一个例子是分区。例如,如何检查系统如何处理分区,关注最新数据,归档旧数据?简单!还记得帕累托分布图吗?您可以根据需要进行更改。 通过指定-rand-pareto值,可以通过强制sysbench专注于较大的ID值来获得所需的结果。也可以设置Zipfian,尽管您无法像Pareto那样获得求逆,但是您可以轻松地从一个值的峰值切换到更均匀的分布。以下是一个很好的示例:
通过指定-rand-pareto值,可以通过强制sysbench专注于较大的ID值来获得所需的结果。也可以设置Zipfian,尽管您无法像Pareto那样获得求逆,但是您可以轻松地从一个值的峰值切换到更均匀的分布。以下是一个很好的示例: 最后要记住的一点是,在我看来,这些都是显而易见的事情,但是总比不说改变随机数生成参数时性能会好。比较延迟:
最后要记住的一点是,在我看来,这些都是显而易见的事情,但是总比不说改变随机数生成参数时性能会好。比较延迟: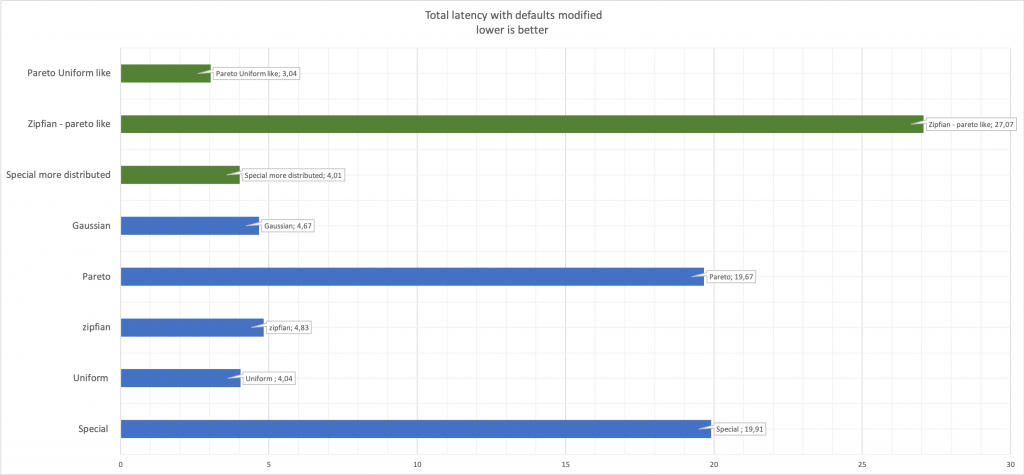 在这里,绿色显示与原始蓝色相比更改后的值。
在这里,绿色显示与原始蓝色相比更改后的值。
发现
至此,您应该已经了解在sysbench中设置随机数生成有多么容易,以及这对您有多大用处。请记住,以上内容适用于所有调用,例如,使用时sysbench.rand.default:local function get_id()
return sysbench.rand.default(1, sysbench.opt.table_size)
End
鉴于此,不要盲目地复制别人文章中的代码,而要思考并深入研究您需要什么以及如何实现这一点。在运行测试之前,请检查随机数生成选项,以确保它们适合您的需求。为了简化我的生活,我使用了这个简单的测试。此测试显示非常清晰的ID分发信息。我的建议是您应该了解自己的需求并正确进行测试/基准测试。参考文献
首先,这是sysbench的 本身。文章对Zipfian:帕累托:Percona上有关如何在sysbench中编写脚本的文章,本文使用的所有材料都在GitHub上。
→ 了解有关该课程的更多信息