在ivi成立的10年中,我们已经建立了一个数据库,该数据库包含90,000个不同长度,大小和质量的视频。每周都会有成百上千的新事物出现。我们有千兆字节的元数据,可用于建议,简化服务导航和设置广告。但是两年前,我们才开始直接从视频中提取信息。在本文中,我将告诉您我们如何将胶片解析为结构元素以及为什么需要它。最后,提供了指向Github存储库的链接,其中包含算法代码和示例。
视频由什么组成?
视频剪辑具有层次结构。这是关于数字视频的,因此最低级别是像素,即构成静止图像的彩色圆点。静态图片称为帧 -它们彼此替换并产生运动效果。 在安装时,将框架切成组,按照导演的指示,将它们互换并粘回去。从一个组件粘贴到另一个组件的英语框架序列称为术语shot。不幸的是,俄语术语是不成功的,因为俄语中的此类组也称为框架。为了避免混淆,我们使用英语术语。只需输入俄语版本:“ shot”。镜头按含义分组,它们称为场景。场景的特点是地点,时间和人物的统一。由于数字视频编码算法是如此安排,因此我们可以轻松获得单个帧甚至这些帧的像素。此信息是复制所必需的。镜头和场景的边界很难获得。安装程序的来源可能会有所帮助,但我们无法使用它们。幸运的是,算法可以做到这一点,尽管不够准确。我将向您介绍划分场景的算法。
在安装时,将框架切成组,按照导演的指示,将它们互换并粘回去。从一个组件粘贴到另一个组件的英语框架序列称为术语shot。不幸的是,俄语术语是不成功的,因为俄语中的此类组也称为框架。为了避免混淆,我们使用英语术语。只需输入俄语版本:“ shot”。镜头按含义分组,它们称为场景。场景的特点是地点,时间和人物的统一。由于数字视频编码算法是如此安排,因此我们可以轻松获得单个帧甚至这些帧的像素。此信息是复制所必需的。镜头和场景的边界很难获得。安装程序的来源可能会有所帮助,但我们无法使用它们。幸运的是,算法可以做到这一点,尽管不够准确。我将向您介绍划分场景的算法。我们为什么需要这个?
我们解决了视频内的搜索问题,并希望自动在ivi上测试每部电影的每个场景。划分场景是该流程的重要组成部分。要了解场景的开始和结束位置,您需要创建合成预告片。我们已经有一个生成它们的算法,但是到目前为止,这里没有使用场景检测。推荐器系统对于划分场景也很有用。从他们那里获得标志,描述用户喜欢哪些电影的结构。解决问题的方法是什么?
这个问题从两个方面解决:- 他们拍摄整个视频并寻找场景的边界。
- 首先,他们将视频分成镜头,然后将它们组合成场景。
我们走了第二种方式,因为它更易于形式化,并且有关于此主题的科学文章。我们已经知道如何将视频分割为快照。仍然需要将这些镜头收集到场景中。您要尝试的第一件事是集群。拍摄照片,将它们变成矢量,然后使用经典聚类算法将矢量分成经典组。 这种方法的主要缺点是:它没有考虑到镜头和场景是相互跟随的。来自另一个场景的镜头不能停留在一个场景的两个镜头之间,并且通过聚类可以实现。2016年,Daniel Rothman和他的IBM同事提出了一种算法,该算法考虑了时间结构,并制定了将镜头组合到场景中的最佳顺序分组任务:
这种方法的主要缺点是:它没有考虑到镜头和场景是相互跟随的。来自另一个场景的镜头不能停留在一个场景的两个镜头之间,并且通过聚类可以实现。2016年,Daniel Rothman和他的IBM同事提出了一种算法,该算法考虑了时间结构,并制定了将镜头组合到场景中的最佳顺序分组任务:- 给定一个序列 发
- 需要将其分为 段,以便这种分离是最佳的。
什么是最佳分离?
现在,我们假设 给定 K,即已知场景数。只有他们的边界是未知的。显然,需要某种度量。发明了三个指标,它们基于镜头之间的成对距离的思想。准备步骤如下:- 我们将镜头转换为向量(直方图或神经网络倒数第二层的输出)
- 找到向量之间的成对距离(欧几里得,余弦或其他)
- 我们得到一个方阵 ,其中每个元素是镜头之间的距离和。
 该矩阵是对称的,并且在主对角线上它将始终为零,因为矢量与其自身的距离为零。沿对角线绘制了暗角正方形-相邻镜头彼此相似的区域,距离相对较小。如果我们选择反映镜头语义的良好嵌入并选择良好的距离函数,那么这些正方形就是场景。找到正方形的边界-我们将找到场景的边界。看看矩阵,以色列同事制定了三个最佳分区标准:
该矩阵是对称的,并且在主对角线上它将始终为零,因为矢量与其自身的距离为零。沿对角线绘制了暗角正方形-相邻镜头彼此相似的区域,距离相对较小。如果我们选择反映镜头语义的良好嵌入并选择良好的距离函数,那么这些正方形就是场景。找到正方形的边界-我们将找到场景的边界。看看矩阵,以色列同事制定了三个最佳分区标准:
是场景边界向量。选择哪种最佳分区标准?
最佳顺序分组任务的良好损失函数具有两个属性:- 如果电影由一个场景组成,那么无论我们在哪里尝试将其分为两部分,该功能的值将始终相同。
- 如果正确地划分为场景,则该值将小于不正确的情况。
原来 和无法满足这些要求,并且应对。为了说明这一点,我们将进行两个实验。
在第一个实验中,我们将制作成对距离的合成矩阵,并用均匀的噪声填充它。如果我们尝试分为两个场景,则会得到以下图片: 说,在视频中间,场景发生了变化,这实际上是不正确的。在异常跳跃,如果你把该分区的开头或在视频的结尾。只要符合要求。
在第二个实验中,我们将制作具有相同噪声的相同矩阵,但是要减去两个正方形,就好像我们有两个彼此略有不同的场景一样。
要检测这种粘连,该功能必须在
说,在视频中间,场景发生了变化,这实际上是不正确的。在异常跳跃,如果你把该分区的开头或在视频的结尾。只要符合要求。
在第二个实验中,我们将制作具有相同噪声的相同矩阵,但是要减去两个正方形,就好像我们有两个彼此略有不同的场景一样。
要检测这种粘连,该功能必须在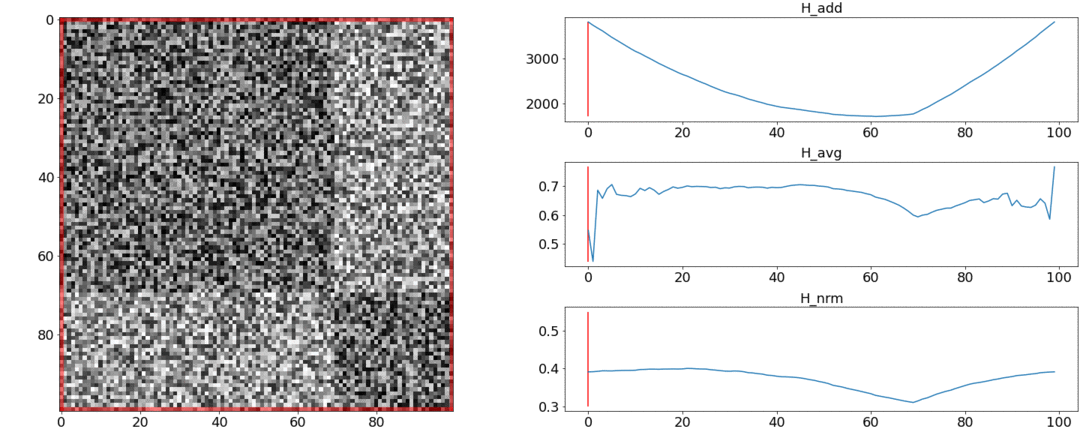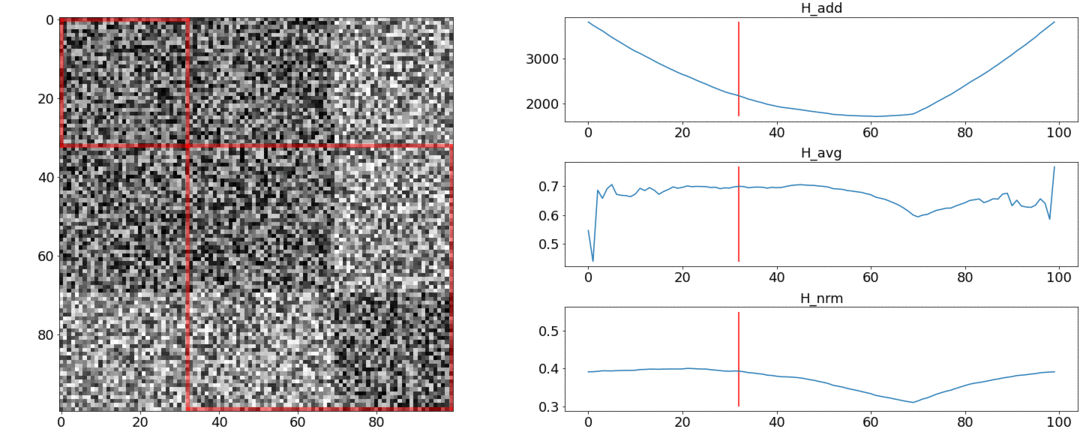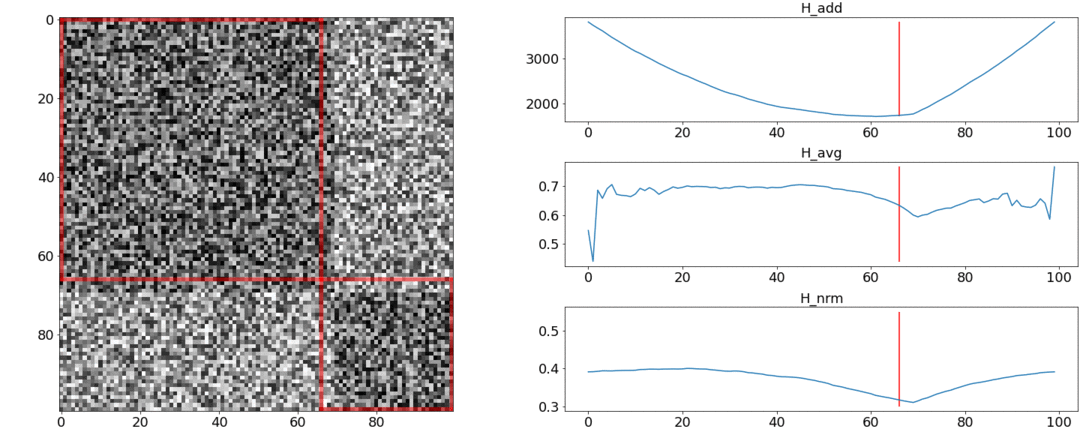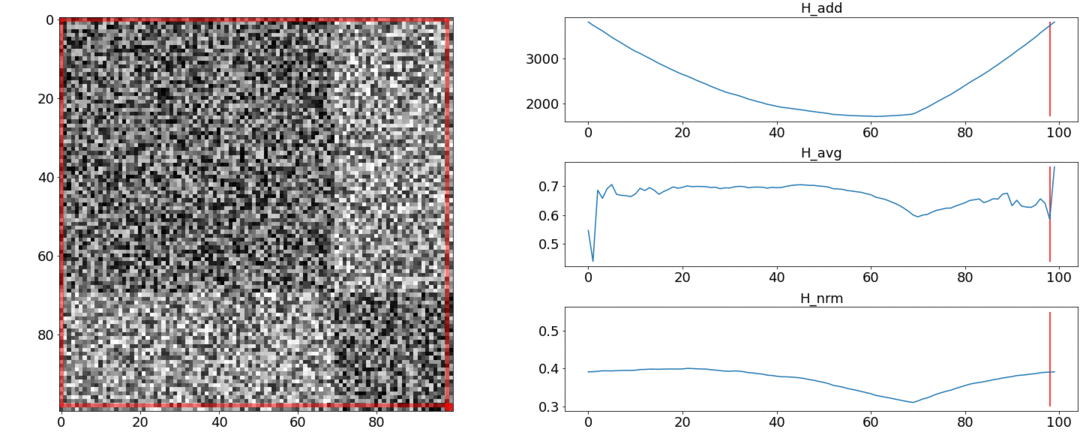 。但是最低仍更接近分段的中间位置,而从头开始。在在。
测试还表明,使用。看来您需要接受它,一切都会好起来的。但是,让我们先来看一下优化算法的复杂性。
丹尼尔·罗斯曼(Daniel Rothman)和他的小组建议使用动态编程来寻找最佳分区。该任务以递归方式分为子任务,然后依次解决。此方法给出了全局最优值,但是要找到它,您需要遍历每个最优值从第0个镜头到第N个镜头的所有分区组合,然后选择最佳。这里 -场景数,以及 -拍摄数量。没有调整和加速优化 会及时工作 。在还有一个用于枚举的参数-分区的面积,并且在每一步都需要检查其所有值。因此,时间增加到。我们设法使用记忆技术进行了一些改进并加快了优化速度-将递归结果缓存在内存中,以免多次读取同一内容。但是,如下面的测试所示,速度并未实现强劲增长。
。但是最低仍更接近分段的中间位置,而从头开始。在在。
测试还表明,使用。看来您需要接受它,一切都会好起来的。但是,让我们先来看一下优化算法的复杂性。
丹尼尔·罗斯曼(Daniel Rothman)和他的小组建议使用动态编程来寻找最佳分区。该任务以递归方式分为子任务,然后依次解决。此方法给出了全局最优值,但是要找到它,您需要遍历每个最优值从第0个镜头到第N个镜头的所有分区组合,然后选择最佳。这里 -场景数,以及 -拍摄数量。没有调整和加速优化 会及时工作 。在还有一个用于枚举的参数-分区的面积,并且在每一步都需要检查其所有值。因此,时间增加到。我们设法使用记忆技术进行了一些改进并加快了优化速度-将递归结果缓存在内存中,以免多次读取同一内容。但是,如下面的测试所示,速度并未实现强劲增长。如何估算场景数量?
IBM的一个小组建议,由于矩阵的许多行是线性相关的,因此沿对角线的正方形簇的数量将近似等于矩阵的秩。要获得它并同时滤除噪声,您需要对矩阵进行奇异分解。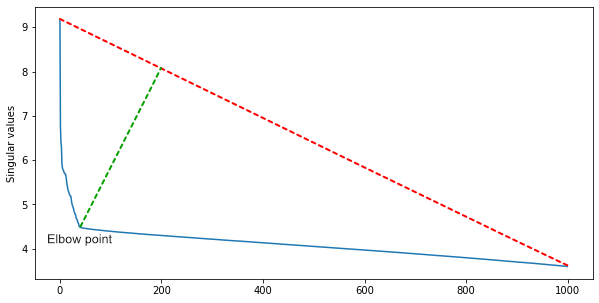 在奇异值之间,按降序排列,我们发现了弯头-弯头的值急剧下降。肘点索引是电影中场景的大概数量。对于第一个近似值,这已经足够了,但是您可以对不同类型的电影使用启发式算法来补充该算法。在动作片中,场景更多,而在艺术馆中,场景更少。
在奇异值之间,按降序排列,我们发现了弯头-弯头的值急剧下降。肘点索引是电影中场景的大概数量。对于第一个近似值,这已经足够了,但是您可以对不同类型的电影使用启发式算法来补充该算法。在动作片中,场景更多,而在艺术馆中,场景更少。测验
我们想了解两件事:- 速度差异如此显着吗?
- 使用更快的算法时,其准确性有多高?
测试分为两组:综合数据和真实数据。在综合测试中,比较了两种算法的质量和速度,而在实际测试中,他们测量了最快算法的质量。在MacBook Pro 2017、2.3 GHz Intel Core i5、16 GB 2133 MHz LPDDR3上进行了速度测试。综合质量测试
我们生成了999个成对距离的矩阵,大小从12到122张不等,将它们随机分为2-10个场景,并从上方添加了正常噪声。对于每个矩阵,根据 和 ,然后计算精度,召回率,F1和IoU指标。我们使用以下公式来考虑间隔的“精确度”和“调用率”:
我们认为F1像往常一样,用间隔Precision和Recall代替:
为了比较影片中的预测片段和真实片段,对于每个预测片段,我们找到具有最大交集的真实片段,并考虑这对度量。结果如下: 功能优化 就像算法作者的测试一样,在所有指标上均获胜。
功能优化 就像算法作者的测试一样,在所有指标上均获胜。综合速度测试
为了测试速度,我们进行了其他综合测试。第一个是算法的运行时间如何取决于镜头数量。场景数量固定: 测试确认了理论评估:优化时间 随着增长多项式增长 与线性时间相比 在 。如果确定拍摄数量 并逐渐增加场景数量 ,我们得到了更有趣的图片。起初,时间会增长,但随后会直线下降。事实是可能的分母值的数量(公式),我们需要按打破方式的数量进行比例检查 细分 。它是结合使用 通过 :
测试确认了理论评估:优化时间 随着增长多项式增长 与线性时间相比 在 。如果确定拍摄数量 并逐渐增加场景数量 ,我们得到了更有趣的图片。起初,时间会增长,但随后会直线下降。事实是可能的分母值的数量(公式),我们需要按打破方式的数量进行比例检查 细分 。它是结合使用 通过 :
随着成长 组合的数量先增加,然后随着您的接近而下降 。 这似乎很酷,但是场景数量很少等于拍摄数量,并且总是采用这样的值,即有很多组合。在已经提到的《复仇者联盟》中有2700张镜头和105个场景。组合数:
这似乎很酷,但是场景数量很少等于拍摄数量,并且总是采用这样的值,即有很多组合。在已经提到的《复仇者联盟》中有2700张镜头和105个场景。组合数:
为确保所有内容均已正确理解且不与原始文章的符号纠缠在一起,我们写了一封信给丹尼尔·罗斯曼。他确认 优化速度非常慢,不适合超过10分钟的视频,并且 在实践中给出可接受的结果。真实数据测试
因此,我们选择了一个指标 ,尽管精度较低,但工作速度要快得多。现在我们需要度量,我们将以此为基础寻找更好的算法。对于测试,我们标记了20部不同类型和年份的电影。标记分五个阶段完成:- 准备切割的材料:
- 在视频上呈现的帧号
- 带有帧号的印刷情节提要板,以便您可以立即捕获数十个帧并查看安装胶的边框。
- 使用准备好的材料,标记器在文本文件中写下与镜头边框相对应的帧号。
- 然后他将镜头分成场景。上面“视频由什么组成?”部分中介绍了将镜头组合成场景的标准。
- 完成的标记文件已由CV团队的开发人员检查。验证期间的主要任务是验证场景的边界,因为可以主观地解释标准。
- 该人员验证的标记是通过一个脚本驱逐掉的,该脚本发现拼写错误和错误,例如“镜头结尾的帧小于镜头开头”。
这是涂抹器和检查员屏幕的外观: 这就是电影“复仇者联盟:无限战争”的前300张照片如何划分场景。左边是真实的场景,右边是算法预测的场景:
这就是电影“复仇者联盟:无限战争”的前300张照片如何划分场景。左边是真实的场景,右边是算法预测的场景: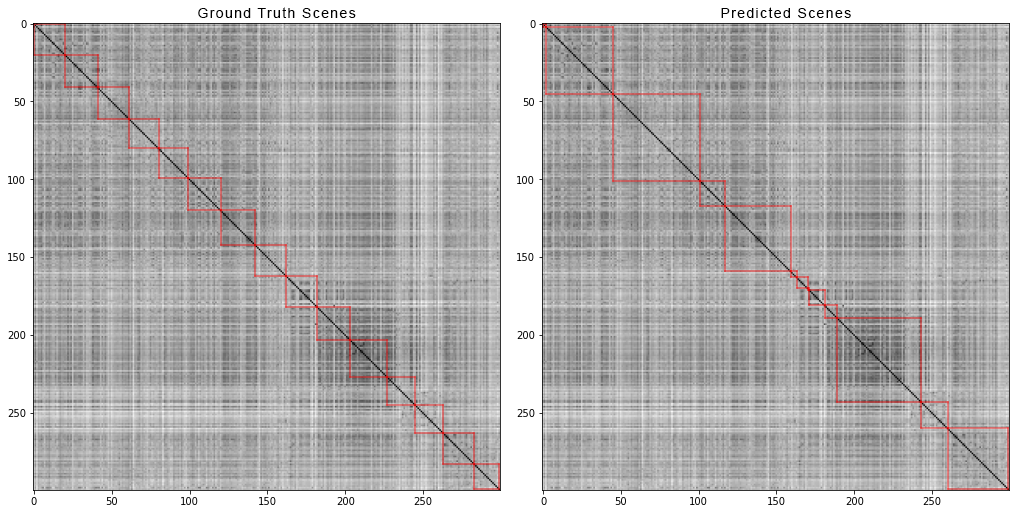 为了获得成对距离的矩阵,我们执行了以下操作:对于数据集中的每个视频,我们生成了成对距离的矩阵,并且就像合成数据一样,我们计算了四个指标。这是出来的数字:
为了获得成对距离的矩阵,我们执行了以下操作:对于数据集中的每个视频,我们生成了成对距离的矩阵,并且就像合成数据一样,我们计算了四个指标。这是出来的数字:- 精度:0.4861919030708739
- 召回:0.8225937459424839
- F1:0.513676858711775
- 借据:0.37560909807842874
所以呢?
我们得到的基线不能很好地工作,但是现在您可以在寻找更准确的方法的基础上进行构建。一些进一步的计划:- 尝试使用其他CNN架构进行特征提取。
- 尝试拍摄之间的其他距离度量。
- 尝试其他优化方法 例如遗传算法。
- 尽量减少整个电影分解成单独的部分 在合理的时间内完成任务,并比较质量损失。
在Github
上公开了合成数据的方法和实验的代码。您可以触摸并尝试加快速度。欢迎点赞和请求。再见,再见!