在现代的x86 Intel处理器中,流水线可以分为两部分:前端和后端。前端负责从内存中加载代码并在微操作中对其进行解码。后端负责从前端执行微操作。由于这些微操作可以由内核无序执行,因此后端还确保这些微操作的结果严格对应于它们在代码中的执行顺序。在大多数情况下,对前端的低效使用不会对性能产生明显影响。大多数Intel处理器的峰值带宽是每个周期4个微操作,因此,例如,对于内存/ L3绑定代码,CPU将无法完全利用它。亲比较新的冰湖, Ice Lake 4 5 . , , .
但是,在某些情况下,性能上的差异可能会很大。重点是分析微操作缓存对性能的影响。文章内容
- 环境
- 前端Intel处理器概述
- 峰值带宽分析µop缓存-> IDQ
- 例
环境
对于本文中的所有测量,将使用i7-8550U Kaby LakeHT启用/ Ubuntu 18.04/Linux Kernel 5.3.0-45-generic。在这种情况下,这种环境可能很重要,因为 每个CPU型号都有自己的性能事件。特别是对于比Sandy Bridge年代久远的微体系结构,将来使用的某些事件根本就没有意义。前端Intel处理器概述
高级别流水线组织是可公开获得的信息,并已发布在有关软件优化的英特尔官方文档中。可以从其他知名资料中找到对正式文档中省略的某些功能的更详细描述,例如Agner Fog或Travis Downs。因此,例如,英特尔文档中Skylake的汇编管道方案如下所示: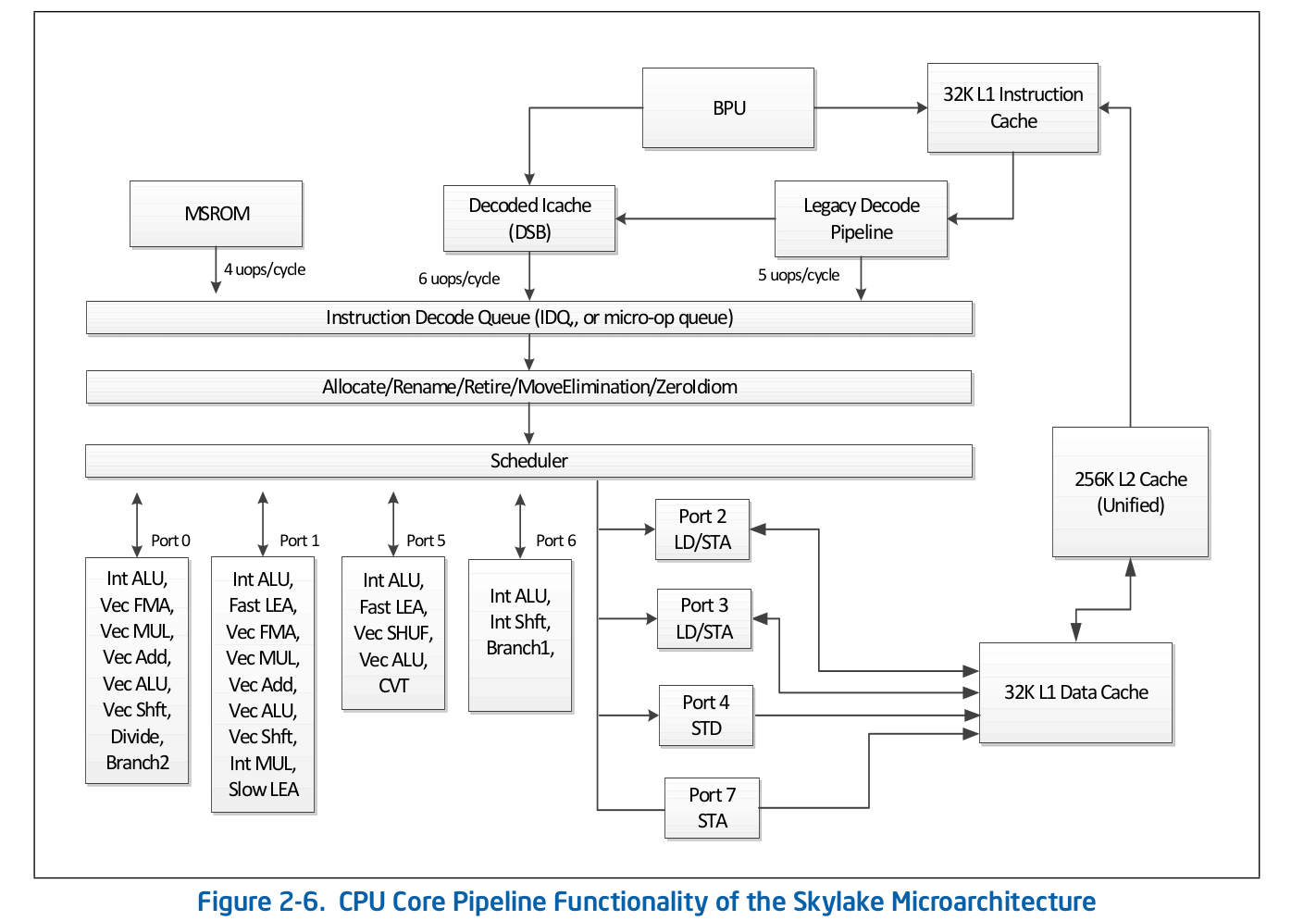 让我们仔细研究该方案的上部-前端。
让我们仔细研究该方案的上部-前端。 传统解码管道负责在微操作中解码代码。它包含以下组件:
传统解码管道负责在微操作中解码代码。它包含以下组件:- 指令获取单元-IFU
- 一级指令缓存-L1i
- 指令日志转换地址缓存-ITLB
- 指导老师
- 预解码器指令
- 预解码指令队列
- 微操作预解码指令解码器
分别考虑“旧版解码管道”的每个部分。指令获取单元。他负责加载代码,预编码(确定指令的长度和属性,例如“指令是否为分支”),并将预解码的指令传递到队列。一级指令缓存-L1i要下载代码,IFU使用代码和数据通用的L1i(第一级指令缓存)和L2 / LLC(第二级缓存和顶级离线缓存)。下载以16字节为单位进行,也与16字节对齐。当按顺序装入下一个16字节的代码段时,将调用L1i,如果未找到相应的行,则在L2中进行搜索,如果发生故障,则在LLC和内存中进行搜索。在Skylake LLC之前,缓存是包含在内的-L1(i / d)和L2中的每一行都应包含在LLC中。因此,LLC对所有内核中的所有行“知道”,并且在LLC丢失的情况下,已知其他内核中的缓存是否在Modified状态下包含所需的行,这意味着该行可以从另一个内核加载。 Skylake LLC成为了非包容性L2受害者缓存,但是L2大小增加了4倍。我不知道L2是否包含L1i。 L2对于L1d 不包括在内。指令逻辑地址的转换-ITLB在从缓存中下载数据之前,必须搜索相应的行。对于n双向关联缓存,每行可以n在缓存本身中的不同位置。为了确定高速缓存中的可能位置,使用了索引(通常是地址的低位)。为了确定该行是否与我们需要的地址匹配,使用了一个标签(地址的其余部分)。使用哪个地址:物理还是逻辑- 取决于缓存的实现。使用物理地址需要地址转换。对于地址转换,使用TLB缓冲区来缓存页面遍历的结果,从而减少后续调用中从逻辑地址接收物理地址的延迟。有关说明,有自己的指令TLB缓冲区,与数据TLB分开放置。 CPU内核还具有代码和数据通用的第二级TLB-STLB。我不知道STLB是否包含(相对于D / I TLB,有传言说它不是包含受害者的缓存)。使用软件预取说明prefetcht1您可以使用L2中的代码拉起该行,但是,相应的TLB记录将仅在DTLB中被拉起。如果STLB是不包括,那么当你寻找在高速缓存中的这行代码,你会得到ITLB小姐- > STLB小姐- >页面走(其实,这不是那么简单,因为内核可以发起一个投机页面走在它发生之前TLB小姐)。英特尔文档也不鼓励使用SW预取代码,《英特尔软件优化手册》 / 2.5.5.4:软件控制的预取用于预取数据,而不用于预取代码。
但是,特拉维斯·D(Travis D.)提到这样的预取可能非常有效(并且很可能是这样),但是到目前为止,这对我来说并不明显,为了使这一点变得令人信服,我将需要单独研究这个问题。指导老师访问未缓存的内存位置时,数据会加载到缓存(L1 / d,i,L2等)中。但是,如果仅在这种情况下发生这种情况,那么结果是我们将无法有效利用缓存带宽。例如,在用于L1d的Sandy Bridge上-2次读取操作,每个周期1个写入16字节;对于L1i-1个16字节的读取操作,文档中未指定写入吞吐量,也未找到Agner Fog。为了解决此问题,有些硬件预取器可以确定对内存的访问模式,并在代码实际对其进行寻址之前将必要的行拉入缓存。英特尔文档定义了4个预取器:2个用于L1d,2个用于L2:- L1 DCU-前缀串行高速缓存线。转发只读
- L1 IP — (. 0x5555555545a0, 0x5555555545b0, 0x5555555545c0, ...), , ,
- L2 Spatial — L2 -, 128-. LLC
- L2 Streamer — . L1 DCU «». LLC
英特尔文档没有描述L1i完善器的原理。众所周知,该过程涉及分支预测单元(BPU),因此,英特尔软件优化手册/ 2.6.2: Agner Fog也看不到任何详细信息。L2 / LLC中的代码预取仅为Streamer明确定义。优化手册/ 2.5.5.4数据预处理:
Agner Fog也看不到任何详细信息。L2 / LLC中的代码预取仅为Streamer明确定义。优化手册/ 2.5.5.4数据预处理:Streamer:此预取器监视L1高速缓存中的读取请求,以了解地址的升序和降序。监视的读取请求包括由加载和存储操作以及硬件预取器发起的L1 DCache请求,以及对代码提取的L1 ICache请求。
对于Spatial预取程序,显然没有说明:空间预取器:此预取器力图用成对的行来完成提取到L2高速缓存的每条高速缓存行,从而将其完成为128字节对齐的块。
但这可以得到验证。MSR 0x1A4如模型专用寄存器手册中所述,可以使用关闭这些预取器中的每一个。关于MSR 0x1A4MSR L2 Spatial L1i. . , LLC. L2 Streamer 2.5 .
Linux msr , msr . $ sudo wrmsr -p 1 0x1a4 1 L2 Streamer 1.
预解码器指令加载下一个16字节代码后,它们属于预解码器指令。它的任务是确定指令的长度,解码前缀并标记相应的指令是否为分支(很可能仍然有许多不同的属性,但是有关它们的文档是静默的)。英特尔软件优化手册/ 2.6.2.2:The predecode unit accepts the sixteen bytes from the instruction cache or prefetch buffers and carries out the following tasks:
- Determine the length of the instructions
- Decode all prefixes associated with instructions
- Mark various properties of instructions for the decoders (for example, “is branch.”)
一行预解码的指令。从IFU,将指令添加到预编码的指令队列中。自Nehalem以来,根据Intel文档,此队列已出现,其大小为18条指令。Agner Fog还提到该队列最多容纳64个字节。同样在Core2中,此队列用作循环缓存。如果循环中的所有微操作都在队列中,则在某些情况下可以避免加载和预编码的成本。循环流检测器(LSD)可以传递队列中已经存在的指令,直到BPU发出周期已结束的信号。Agner Fog关于Core2上的LSD有许多有趣的注释:- 由4行16字节组成
- 每个周期的峰值吞吐量高达32个字节的代码
从Sandy Bridge开始,此循环缓存已从预解码的指令队列移回到IDQ。微操作中预解码指令的解码器从预解码指令队列中,将代码发送到微操作中进行解码。解码器负责解码-总共有4个,根据Intel文档,其中一个解码器可以解码由4个或更少的微操作组成的指令。其余的解码指令由一个微操作(微/宏融合)组成,《英特尔软件优化手册》 / 2.5.2.1:There are four decoding units that decode instruction into micro-ops. The first can decode all IA-32 and Intel 64 instructions up to four micro-ops in size. The remaining three decoding units handle single-micro-op instructions. All four decoding units support the common cases of single micro-op flows including micro-fusion and macro-fusion.
在大量微操作中解码的指令(例如,rep movsb,用于在某些大小的复制内存中的libc中的memcpy的实现中使用)来自Microcode Sequencer(MS ROM)。定序器的峰值带宽是每个周期4个微操作。正如您在装配线图中所看到的,“旧版解码管道”可以在Skylake上每个周期最多解码5个微操作。在Broadwell和更旧的版本上,旧版解码管道的峰值吞吐量是每个周期4次微操作。微操作缓存在微操作中对指令进行解码后,它们会从“旧式解码管道”中落入特殊的微操作队列-指令解码队列(IDQ)以及所谓的微操作缓存(解码的ICache,µop缓存)。微操作缓存最初是在Sandy Bridge中引入的,用于避免在微操作中获取和解码指令,从而提高了以IDQ交付微操作的吞吐量-每个周期最多6个。进入IDQ后,微操作将以每个周期4个微操作的峰值吞吐量转到后端执行。根据英特尔文档,微操作缓存由32组组成,每组包含8行,每行最多可以缓存6个微操作(微/宏融合),总共可以缓存多达32 * 8 * 6 = 1536个微操作。微操作缓存的粒度为32个字节,即 遵循来自不同32字节区域的指令的微操作不能落入一行。但是,最多3个不同的高速缓存行可以对应一个32字节区域。因此,μop缓存中最多18个微操作可以对应于每个32字节区域。英特尔软件优化手册/ 2.5.5.2The Decoded ICache consists of 32 sets. Each set contains eight Ways. Each Way can hold up to six micro-ops. The Decoded ICache can ideally hold up to 1536 micro-ops. The following are some of the rules how the Decoded ICache is filled with micro-ops:
- ll micro-ops in a Way represent instructions which are statically contiguous in the code and have their EIPs within the same aligned 32-byte region.
- Up to three Ways may be dedicated to the same 32-byte aligned chunk, allowing a total of 18 micro-ops to be cached per 32-byte region of the original IA program.
- A multi micro-op instruction cannot be split across Ways.
- Up to two branches are allowed per Way.
- An instruction which turns on the MSROM consumes an entire Way.
- A non-conditional branch is the last micro-op in a Way.
- Micro-fused micro-ops (load+op and stores) are kept as one micro-op.
- A pair of macro-fused instructions is kept as one micro-op.
- Instructions with 64-bit immediate require two slots to hold the immediate.
Agner Fog还提到每个周期只能下载单行微操作(尽管可以轻松地手动检查,但英特尔文档中没有明确说明)。µop cache --> IDQ
在某些情况下,使用nop1个字节的长度来研究Front End的行为非常方便。同时,我们可以确保出于任何原因正在调查前端,而不是后端的资源停滞。事实是,nop连同其他指令一样,它们也在“旧版解码管道”中解码,混合在µop缓存中并发送到IDQ。此外nop,以及其他说明,都是后端。显着的区别在于后端上的资源nop仅使用重新排序缓冲区,而无需在预留站(也称为调度程序)中使用插槽。因此,在进入Reorder Buffer之后,它立即nop准备退役,它将根据程序代码中的顺序执行。要测试吞吐量,请声明一个函数void test_decoded_icache(size_t iteration_count);
实施nasm:align 32
test_decoded_icache:
;nop', 0 23
dec rdi
ja test_decoded_icache
ret
ja它不是偶然选择的。ja并dec使用不同的标志- ja从读取CF和ZF,dec在CF没有记录,所以宏融合不适。这样做纯粹是为了方便在一个周期内计数微操作-每条指令对应一个微操作。对于测量,我们需要满足以下条件PERF事件:1 uops_issued.any-用于计算的微操作是从更名IDQ需要。英特尔系统编程指南将此事件记录为重命名器放入预留站的微操作数:计算资源分配表(RAT)向预留站(RS)发出的微指令的数量。
此描述与可以从实验中获得的值不完全相关。特别地,它们nop落入该计数器中,尽管仅一个事实是预订站根本不需要它们。2. uops_retired.retire_slots-退役微操作考虑到微/宏融合的总数3 uops_retired.stall_cycles为其中没有一个单一的退休微操作蜱的数目-4. resource_stalls.any由于任何资源后端的不可访问空闲输送机的蜱的数目-在Intel软件优化手册/ B .4.1有表征上面描述的事件内容图: 5.
5. idq.all_dsb_cycles_4_uops-为其4(或更多)的指令,从高速缓存μop递送的时钟周期的数目。英特尔文档中没有描述此度量标准考虑到每个周期要执行4个以上的微操作这一事实,但与实验非常吻合。6.- idq.all_dsb_cycles_any_uops至少进行了一次微手术的措施数量。7. idq.dsb_cycles-在该交割从μop缓存蜱总数8 idq_uops_not_delivered.cycles_le_N_uop_deliv.core的号码- 蜱为其更名了一个N或更少的微操作,并有在后端侧无需停机,N1,2,3 -我们需要研究iteration_count = 1 << 31。我们通过检查微操作的数量开始分析CPU中发生的事情,首先是通过测量平均报废带宽,即uops_retired.retire_slots/uops_retired.total_cycle: 立即引起您注意的是,在7个微操作的周期大小下,退休吞吐量的下降。为了了解它是什么,让我们考虑μop缓存的平均传送速率-
立即引起您注意的是,在7个微操作的周期大小下,退休吞吐量的下降。为了了解它是什么,让我们考虑μop缓存的平均传送速率- idq.all_dsb_cycles_any_uops / idq.dsb_cycles: 以及如何将时钟周期总数与IDQ中为其传送μop缓存的周期联系起来:
以及如何将时钟周期总数与IDQ中为其传送μop缓存的周期联系起来: 因此可以看出,我们有6个微操作的周期有效µop缓存带宽利用率-每个周期6次微操作。由于重命名器无法拾取到µop缓存所提供的内容,因此某些µop缓存周期没有提供任何内容,这在上图中很明显。使用7个微操作的周期,我们的μop缓存的吞吐量急剧下降-每个周期3.5个微操作。同时,从上图可以看出,μop缓存一直在运行。因此,使用7个微操作的周期,我们无法充分利用带宽µop缓存。事实是,如前所述,每个周期的µop高速缓存只能从一条线进行微操作。在微操作7的情况下-前6个在一行中,其余的7在另一行中。这样,我们每2个周期获得7个微操作,或每个周期3.5个微操作。现在,让我们看看重命名器如何从IDQ进行微操作。为此,我们需要
因此可以看出,我们有6个微操作的周期有效µop缓存带宽利用率-每个周期6次微操作。由于重命名器无法拾取到µop缓存所提供的内容,因此某些µop缓存周期没有提供任何内容,这在上图中很明显。使用7个微操作的周期,我们的μop缓存的吞吐量急剧下降-每个周期3.5个微操作。同时,从上图可以看出,μop缓存一直在运行。因此,使用7个微操作的周期,我们无法充分利用带宽µop缓存。事实是,如前所述,每个周期的µop高速缓存只能从一条线进行微操作。在微操作7的情况下-前6个在一行中,其余的7在另一行中。这样,我们每2个周期获得7个微操作,或每个周期3.5个微操作。现在,让我们看看重命名器如何从IDQ进行微操作。为此,我们需要idq_uops_not_delivered.core和idq_uops_not_delivered.cycles_le_N_uop_deliv.core: 您可能会注意到,使用7个微操作,一次只有3个微操作需要一半的重命名器周期。从这里,我们得到每个周期平均3.5个微操作的报废吞吐量。如果我们考虑退休的有效吞吐量,则可以看到与此示例相关的另一个有趣的观点。那些。不考虑
您可能会注意到,使用7个微操作,一次只有3个微操作需要一半的重命名器周期。从这里,我们得到每个周期平均3.5个微操作的报废吞吐量。如果我们考虑退休的有效吞吐量,则可以看到与此示例相关的另一个有趣的观点。那些。不考虑uops_retired.stall_cycles: 可以注意到,对于7个微操作,每7个度量执行4个微操作的退休,并且每8个度量空闲,而没有退休的微操作(退休停顿)。在进行了一系列实验之后,有可能发现在7个微操作中始终观察到这种行为,而不管其布局1-6、6-1、2-5、5-2、3-4、4-3。我不知道为什么会这样,例如,在一个循环中执行3个微操作,而在下一个循环中执行4个微操作,则不会。阿格纳·福格(Agner Fog)提到,分支过渡只能使用部分退休站槽。也许这种限制是造成这种退休行为的原因。
可以注意到,对于7个微操作,每7个度量执行4个微操作的退休,并且每8个度量空闲,而没有退休的微操作(退休停顿)。在进行了一系列实验之后,有可能发现在7个微操作中始终观察到这种行为,而不管其布局1-6、6-1、2-5、5-2、3-4、4-3。我不知道为什么会这样,例如,在一个循环中执行3个微操作,而在下一个循环中执行4个微操作,则不会。阿格纳·福格(Agner Fog)提到,分支过渡只能使用部分退休站槽。也许这种限制是造成这种退休行为的原因。例
为了了解这在实践中是否有效果,请考虑以下比nops 更实际的示例:给出了两个数组unsigned。必须累加每个索引的算术平均值,并将其写入第三个数组。一个示例实现可能如下所示:
static unsigned arr1[] = { ... };
static unsigned arr2[] = { ... };
static void arithmetic_mean(unsigned *arr1, unsigned *arr2, unsigned *out, size_t sz){
unsigned sum = 0;
size_t idx = 0;
while(idx < sz){
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
}
__asm__ __volatile__("" ::: "memory");
}
int main(void){
unsigned out[sizeof arr1 / sizeof(unsigned)];
for(size_t i = 0; i < 4096 * 4096; i++){
arithmetic_mean(arr1, arr2, out, sizeof arr1 / sizeof(unsigned));
}
}
用gcc标志编译-Werror
-Wextra
-Wall
-pedantic
-Wno-stack-protector
-g3
-O3
-Wno-unused-result
-Wno-unused-parameter
很明显,该函数arithmetic_mean不会出现在代码中,而是直接插入到main:(gdb) disas main
Dump of assembler code for function main:
#...
0x00000000000005dc <+60>: nop DWORD PTR [rax+0x0]
0x00000000000005e0 <+64>: mov edx,DWORD PTR [rdi+rax*4]
0x00000000000005e3 <+67>: add edx,DWORD PTR [r8+rax*4]
0x00000000000005e7 <+71>: shr edx,1
0x00000000000005e9 <+73>: add ecx,edx
0x00000000000005eb <+75>: mov DWORD PTR [rsi+rax*4],ecx
0x00000000000005ee <+78>: add rax,0x1
0x00000000000005f2 <+82>: cmp rax,0x80
0x00000000000005f8 <+88>: jne 0x5e0 <main+64>
0x00000000000005fa <+90>: sub r9,0x1
0x00000000000005fe <+94>: jne 0x5d8 <main+56>
#...
请注意,编译器将循环代码对齐为32个字节(nop DWORD PTR [rax+0x0]),这正是我们所需要的。确保没有resource_stalls.any后端(所有测量都考虑到加热的L1d高速缓存)之后,我们可以开始考虑与向IDQ交付相关的计数器: Performance counter stats for './test_decoded_icache':
2 273 343 251 idq.all_dsb_cycles_4_uops (15,94%)
4 458 322 025 idq.all_dsb_cycles_any_uops (16,26%)
15 473 065 238 idq.dsb_uops (16,59%)
4 358 690 532 idq.dsb_cycles (16,91%)
2 528 373 243 idq_uops_not_delivered.core (16,93%)
73 728 040 idq_uops_not_delivered.cycles_0_uops_deliv.core (16,93%)
107 262 304 idq_uops_not_delivered.cycles_le_1_uop_deliv.core (16,93%)
108 454 043 idq_uops_not_delivered.cycles_le_2_uop_deliv.core (16,65%)
2 248 557 762 idq_uops_not_delivered.cycles_le_3_uop_deliv.core (16,32%)
2 385 493 805 idq_uops_not_delivered.cycles_fe_was_ok (16,00%)
15 147 004 678 uops_retired.retire_slots
4 724 790 623 uops_retired.total_cycles
1,228684264 seconds time elapsed
请注意,这种情况下的报废badwidth = 15147004678/4724790623 = 3.20585733562,并且只有3个微操作占用重命名器的时钟的一半。现在将手动循环升级添加到实现中:static void arithmetic_mean(unsigned *arr1, unsigned *arr2, unsigned *out, size_t sz){
unsigned sum = 0;
size_t idx = 0;
if(sz & 2){
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
}
while(idx < sz){
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
}
__asm__ __volatile__("" ::: "memory");
}
产生的性能计数器如下所示:Performance counter stats for './test_decoded_icache':
2 152 818 549 idq.all_dsb_cycles_4_uops (14,79%)
3 207 203 856 idq.all_dsb_cycles_any_uops (15,25%)
12 855 932 240 idq.dsb_uops (15,70%)
3 184 814 613 idq.dsb_cycles (16,15%)
24 946 367 idq_uops_not_delivered.core (16,24%)
3 011 119 idq_uops_not_delivered.cycles_0_uops_deliv.core (16,24%)
5 239 222 idq_uops_not_delivered.cycles_le_1_uop_deliv.core (16,24%)
7 373 563 idq_uops_not_delivered.cycles_le_2_uop_deliv.core (16,24%)
7 837 764 idq_uops_not_delivered.cycles_le_3_uop_deliv.core (16,24%)
3 418 529 799 idq_uops_not_delivered.cycles_fe_was_ok (16,24%)
3 444 833 440 uops_retired.total_cycles (18,18%)
13 037 919 196 uops_retired.retire_slots (18,17%)
0,871040207 seconds time elapsed
在这种情况下,我们的退休带宽= 13037919196/3444833440 = 3.78477491672,以及对重命名器带宽的有效利用。因此,我们不仅可以在一个周期内摆脱一个分支和一个增量操作,而且还可以通过有效利用微操作缓存的吞吐量来增加报废带宽,从而使性能总共提高28%。请注意,只有减少一个分支和增量操作才能使平均性能提高9%。小话
在用于执行这些实验的CPU上,LSD已关闭。LSD似乎可以处理这种情况。对于启用了LSD的CPU,将需要分别研究这种情况。