我最近讨论了如何使用标准配方来提高 PostgreSQL数据库中SQL“读取”查询的性能。今天,我们将讨论如何通过正确组织数据流,如何在不使用配置中的任何“扭曲”的情况下,更高效地在数据库中进行记录。#1。分区
关于如何以及为什么值得“理论上”组织应用分区的文章已经存在,这里我们将重点介绍在数百个PostgreSQL服务器的监视服务框架内使用某些方法的实践。“过去的日子……”
最初,像任何MVP一样,我们的项目在一个很小的负载下开始-监视仅针对十个最关键的服务器执行,所有表都相对紧凑...但是随着时间的流逝,受监视的主机越来越多,并且再次尝试使用其中一张大小为1.5TB的桌子,我们意识到尽管可以像这样继续生活,但非常不便。时代几乎是史诗般的,不同的PostgreSQL 9.x变体是相关的,因此所有分区都必须“手动”完成-通过表继承和动态路由触发器EXECUTE。结果解决方案具有足够的通用性,可以将其转换为所有表:PG10:
但是,通过继承进行分区一直以来都不适合与活动写流或大量子节一起使用。例如,您可能还记得用于选择所需节的算法具有二次复杂度,可以与100多个节一起使用,您了解如何...在PG10中,通过实现对本机分区的支持极大地优化了这种情况。因此,我们立即尝试在迁移存储后立即应用它,但是...在挖掘手册后发现,此版本中的本机分区表是:- 不支持索引描述
- 不支持触发器
- 本身不能是任何“后裔”
- 不支持
INSERT ... ON CONFLICT - 无法自动产生区域
我们痛苦地摸索着额头,我们意识到如果不修改应用程序就无法做,因此将进一步的研究推迟了六个月。PG10:第二次机会
因此,我们开始依次解决问题:- 由于
ON CONFLICT事实证明在某些地方需要触发器,因此我们制作了一个中间代理表来进行处理。 - 我们摆脱了触发器中的“路由” -即from
EXECUTE。 - 他们取出了一个带有所有索引的单独的模板表,因此它们甚至不存在于代理表中。
最后,在完成所有这些操作之后,主表已经进行了本地分区。创建新部分仍然取决于应用程序的良心。“锯”字典
像在任何分析系统中一样,我们也有“事实”和“删节”(字典)。在我们的案例中,以这种身份,例如,是相同类型的慢速查询的“模板”正文或查询本身的文本。我们的“事实”按天划分了很长时间,因此我们从容删除了过时的部分,它们没有打扰我们(日志!)。但是有了字典,麻烦就出现了…… 不是说有很多字典,而是事实证明大约100TB的“事实”是2.5TB的字典。您无法方便地从此类表格中删除任何内容,也无法在足够的时间内对其进行压缩,并且对其写入的速度逐渐变慢。好像是一本字典...在其中每个条目应该只显示一次...是的,但是!..没有人打扰我们每天都有一本单独的字典!是的,这带来了一定的冗余,但是它允许您:- 由于段大小较小,因此写入/读取速度更快
- 通过使用更紧凑的索引来消耗更少的内存
- 由于能够快速删除过时的功能,因此可以存储较少的数据
由于采取了多种措施,CPU负载减少了约30%,磁盘减少了约50%:同时,我们继续以更少的负载将完全相同的内容写入数据库。#2 数据库演进和重构
因此,我们确定了这样一个事实,即每天都有自己的数据部分。实际上,这CHECK (dt = '2018-10-12'::date)是分区键,并且记录属于特定部分的条件。由于我们服务中的所有报告都是根据特定日期生成的,因此“未分区时间”中的索引都是它们的所有类型(服务器,日期,计划模板),(服务器,日期,计划节点),(日期,错误类别,服务器),但是现在每个部分都有自己的每个此类索引的实例 ...并且每个部分中的日期都是恒定的 ...事实证明,现在我们在每个此类索引中我们简单地输入一个常数作为字段之一,这会使它的体积和搜索时间更长,但不会带来任何结果。自己丢下耙子,哎呀...优化的方向很明显-只需从分区表上的所有索引中删除日期字段即可。以我们的容量,大约每周增加1TB!现在,让我们注意到,仍然必须以某种方式记录此TB。也就是说,我们现在还必须加载更少的磁盘!在这张照片中,我们可以看到一周清洁所产生的效果: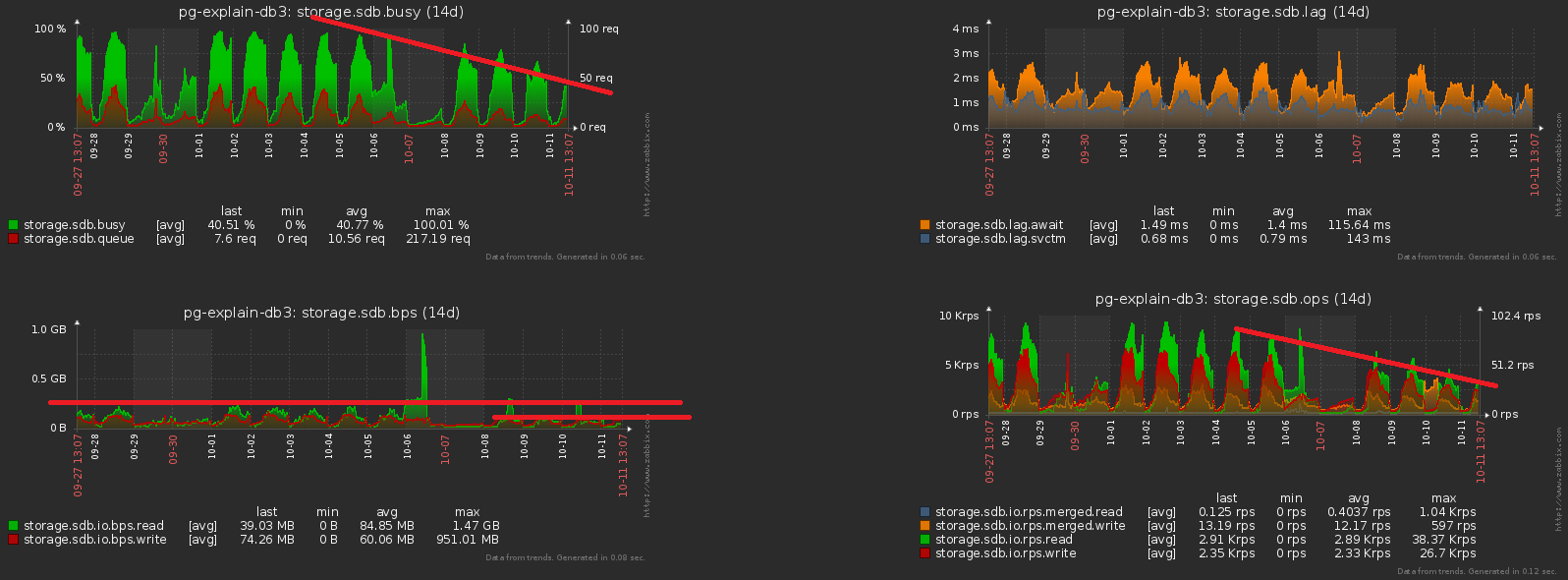
#3 “涂抹”峰值负荷
加载系统的最大麻烦之一是某些不需要它的操作的过度同步。有时是“因为他们没有注意到”,有时是“比较容易”,但迟早您必须摆脱它。我们将上一张图片拉近一些-我们发现磁盘在相邻样本之间的负载“震动”了两倍,这显然不应该在这么多的操作下“统计”: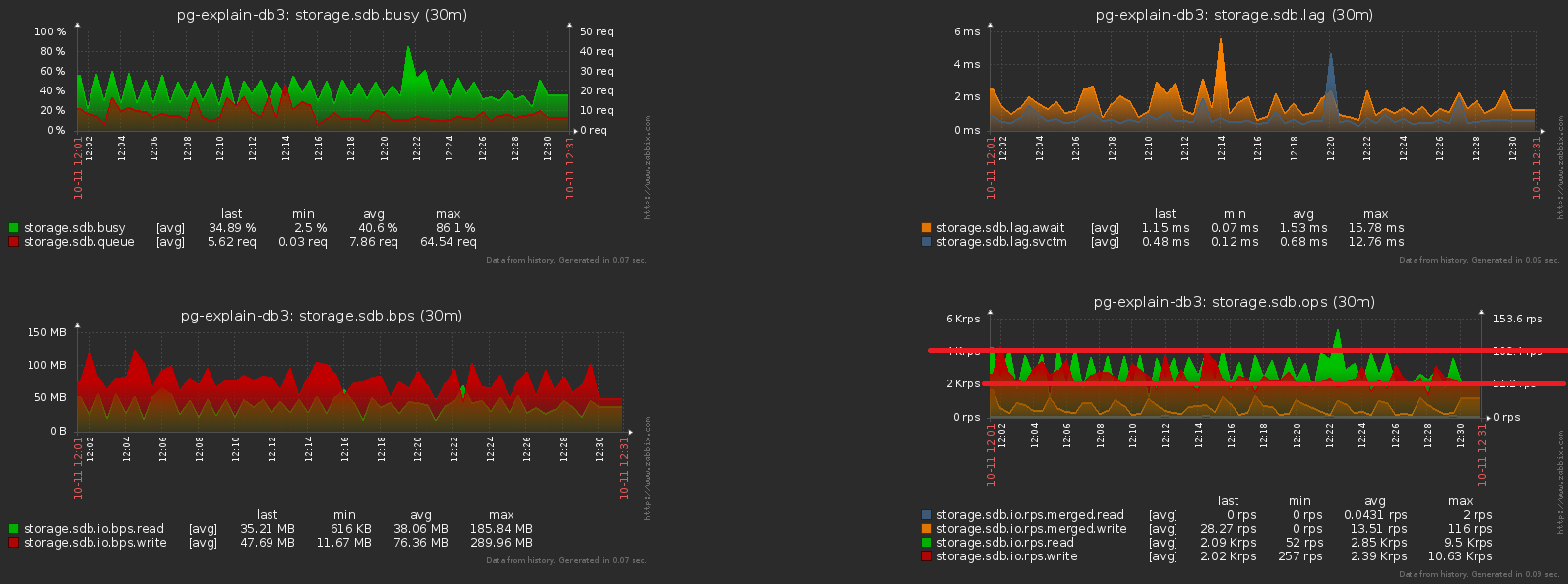 实现这一点非常简单。已经启动了将近1000台服务器进行监视,每个服务器都由单独的逻辑流进行处理,并且每个流以一定的频率转储累积的信息以发送到数据库,如下所示:
实现这一点非常简单。已经启动了将近1000台服务器进行监视,每个服务器都由单独的逻辑流进行处理,并且每个流以一定的频率转储累积的信息以发送到数据库,如下所示:setInterval(sendToDB, interval)
这里的问题恰恰在于所有线程大约在同一时间启动,因此它们的发送时间几乎总是“到点”一致。糟糕2号...幸运的是,通过添加“随机”时间跨度可以很容易地纠正此问题:setInterval(sendToDB, interval * (1 + 0.1 * (Math.random() - 0.5)))
#4。缓存,这需要可
第三个传统的高负荷的问题是缺乏缓存它可能是。例如,我们可以分析计划中各个节点的细目分类(所有这些Seq Scan on users),但立即忘记了它们基本上已经被遗忘了。不,当然,什么也不会重复写入数据库,这可以通过切断触发器INSERT ... ON CONFLICT DO NOTHING。但是无论如何,数据都无法到达基础,因此您必须做额外的读取才能检查冲突。糟糕3 ...在启用缓存之前/之后发送到数据库的记录数差异是显而易见的: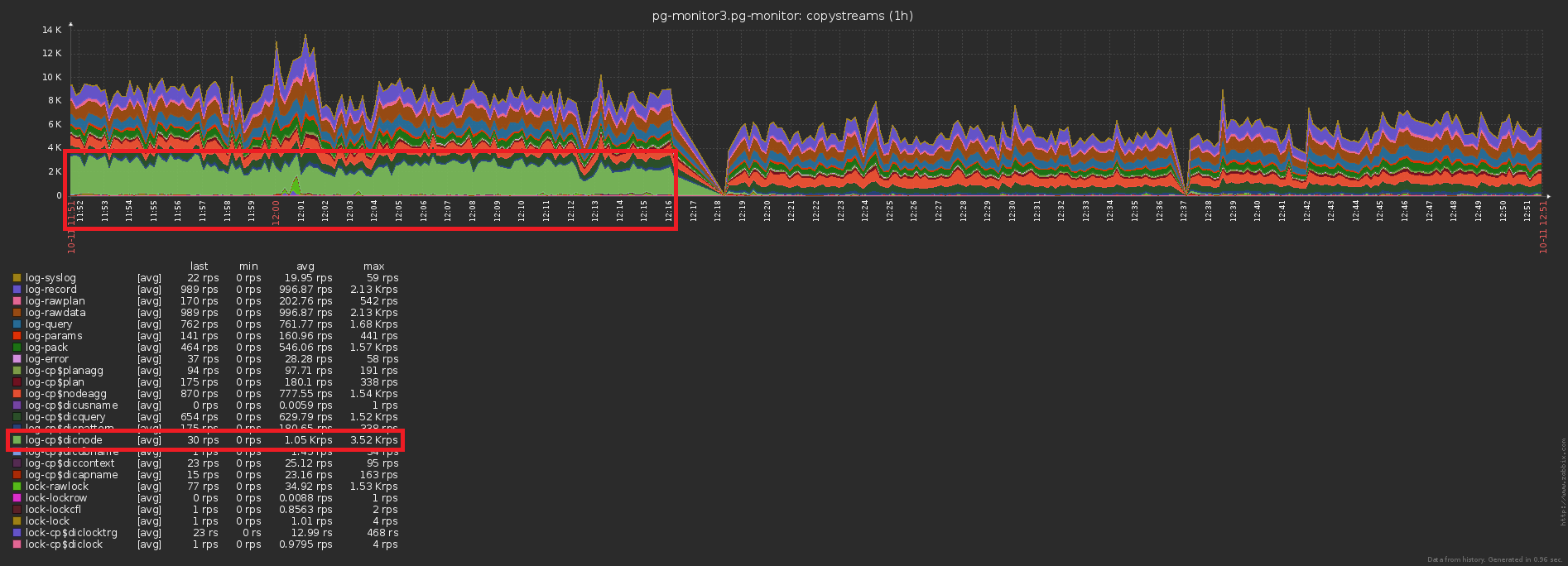 这伴随着存储负载的下降:
这伴随着存储负载的下降:
总
每天只有TB级的声音听起来令人恐惧。如果一切正确,那么这仅2 ^ 40字节/ 86400秒=〜12.5MB / s,甚至连桌面IDE螺丝也能容纳。:)但是,严重的是,即使白天负载有十倍的“偏差”,您也可以轻松满足现代SSD的需求。