序幕
这是该系列文章中的四篇文章的第一篇,将深入了解指针,堆栈,堆,转义分析和Go /指针语义的机制和设计。这篇文章是关于堆栈和指针的。目录:- 堆栈和指针上的语言力学
- 逃生分析的语言力学(翻译)
- 记忆剖析的语言机制
- 数据与语义设计哲学
介绍
我不会反汇编-指针很难理解。如果使用不当,指针可能会导致令人不愉快的错误,甚至导致性能问题。在编写竞争性或多线程程序时尤其如此。毫不奇怪,许多语言都试图隐藏程序员的指针。但是,如果使用Go编写,则无法转义指针。如果没有对指针的清楚理解,您将很难编写干净,简单而有效的代码。边框
在帧的边界内执行功能,这些帧为每个相应功能提供了单独的存储空间。每个框架都允许该功能在其自己的上下文中工作,并提供流控制。函数可以通过指针直接访问其框架内的内存,但是访问框架外部的内存则需要间接访问。为了使功能在其框架之外访问存储器,必须将该存储器与该功能结合使用。必须首先了解和研究由这些边界设置的机制和限制。调用函数时,会在两个帧之间发生过渡。代码从调用函数的框架到被调用函数的框架。如果需要数据来调用该函数,则必须将该数据从一帧传输到另一帧。 Go中两个帧之间的数据传输是“按值”完成的。“按值”数据传输的优点是可读性。您在函数调用中看到的值是在另一端复制并接受的值。这就是为什么我将“按价值传递”与所见即所得相关联的原因,因为您所看到的就是所得到的。所有这一切都使您可以编写不隐藏两个功能之间切换成本的代码。这有助于保持良好的心理模型,以了解过渡期间每个函数调用将如何影响程序。看一下这个小程序,该程序通过“按值”传递整数数据来调用函数:清单1:01 package main
02
03 func main() {
04
05
06 count := 10
07
08
09 println("count:\tValue Of[", count, "]\tAddr Of[", &count, "]")
10
11
12 increment(count)
13
14 println("count:\tValue Of[", count, "]\tAddr Of[", &count, "]")
15 }
16
17
18 func increment(inc int) {
19
20
21 inc++
22 println("inc:\tValue Of[", inc, "]\tAddr Of[", &inc, "]")
23 }
当您的Go程序启动时,运行时将创建主goroutine以开始执行所有代码,包括main函数中的代码。 Gorutin是适合操作系统线程的执行路径,该线程最终运行在某些内核上。从版本1.8开始,每个goroutine都提供了一个初始的连续内存块,大小为2048字节,这形成了堆栈空间。多年来,此初始堆栈大小已更改,并且将来可能会更改。堆栈很重要,因为它为分配给每个单独功能的帧边界提供了物理存储空间。到主goroutine执行清单1中的main函数时,程序堆栈(非常高级)将如下所示:图1: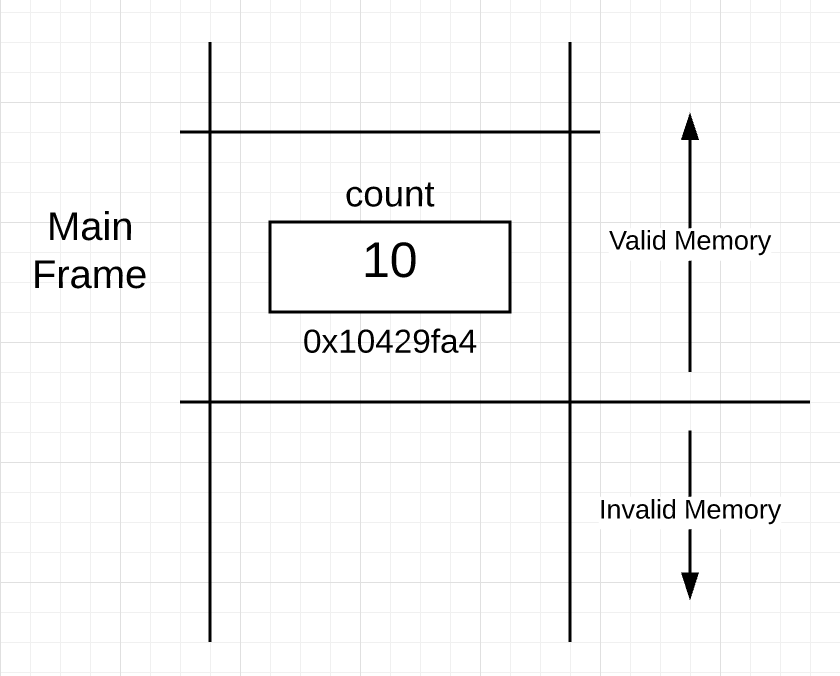 在图1中,您可以看到堆栈的一部分已针对主要功能进行了“框架化”。此部分称为“ 堆栈框架 ”,正是该框架表示堆栈上主要功能的边界。框架被设置为在调用函数时执行的代码的一部分。您还可以看到,count变量的内存已分配给main框架内的0x10429fa4。还有一个有趣的地方,如图1所示。活动帧下的所有堆栈内存均无效,但活动帧及其后的堆栈内存均有效。您需要清楚地了解堆栈的有效部分和无效部分之间的边界。
在图1中,您可以看到堆栈的一部分已针对主要功能进行了“框架化”。此部分称为“ 堆栈框架 ”,正是该框架表示堆栈上主要功能的边界。框架被设置为在调用函数时执行的代码的一部分。您还可以看到,count变量的内存已分配给main框架内的0x10429fa4。还有一个有趣的地方,如图1所示。活动帧下的所有堆栈内存均无效,但活动帧及其后的堆栈内存均有效。您需要清楚地了解堆栈的有效部分和无效部分之间的边界。地址
变量用于为特定存储单元分配名称,以提高代码的可读性并帮助您了解所使用的数据。如果您有一个变量,那么您在内存中就有一个值,如果您有一个值在内存中,那么它必须有一个地址。在第09行,主函数调用内置的println函数以显示count变量的“值”和“地址”。清单2:09 println("count:\tValue Of[", count, "]\tAddr Of[", &count, "]")
使用&号获取变量位置的地址并不是什么新鲜事,其他语言也使用此运算符。如果在32位体系结构(例如Go Playground)上运行代码,则第09行的输出应类似于以下输出:清单3:count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
函数调用
接下来,在第12行,主要功能调用了增量功能。清单4:12 increment(count)
进行函数调用意味着程序必须在堆栈上创建新的内存部分。但是,一切都有些复杂。为了成功完成一个函数调用,期望在过渡期间跨帧边界传输数据并将其放置在新帧中。特别地,期望在呼叫期间复制并发送整数值。您可以通过查看第18行上的递增函数的声明来了解此需求。清单5:18 func increment(inc int) {
如果再次查看对第12行的增量函数的调用,您将看到代码传递了变量计数的“值”。该值将被复制,传输并放置在用于增量功能的新帧中。请记住,增量函数只能在其自己的帧中读写存储器,因此它需要inc变量来获取,存储和访问其自己的已传输计数器值的副本。在增量函数中的代码开始执行之前,程序堆栈(非常高的层次)将如下所示:图2: 您会看到堆栈上现在有两帧-一帧为主帧,一帧为增量帧。在增量框架内,您可以看到包含值10的inc变量,该变量在函数调用期间被复制并传递。inc变量地址为0x10429f98,它在内存中较小,因为帧被压入堆栈,这只是实现细节,没有任何意义。重要的是该程序从main框架中检索计数值,并将该值的副本放置在框架中以使用inc变量增加。其余代码在增量内递增,并显示inc变量的“值”和“地址”。清单6:
您会看到堆栈上现在有两帧-一帧为主帧,一帧为增量帧。在增量框架内,您可以看到包含值10的inc变量,该变量在函数调用期间被复制并传递。inc变量地址为0x10429f98,它在内存中较小,因为帧被压入堆栈,这只是实现细节,没有任何意义。重要的是该程序从main框架中检索计数值,并将该值的副本放置在框架中以使用inc变量增加。其余代码在增量内递增,并显示inc变量的“值”和“地址”。清单6:21 inc++
22 println("inc:\tValue Of[", inc, "]\tAddr Of[", &inc, "]")
操场上第22行的输出应如下所示:清单7:inc: Value Of[ 11 ] Addr Of[ 0x10429f98 ]
执行相同的代码行后,堆栈显示如下:图3: 执行第21和22行之后,递增函数结束,并将控制权返回给主函数。然后,main函数再次在第14行显示局部变量计数的“值”和“地址”。清单8:
执行第21和22行之后,递增函数结束,并将控制权返回给主函数。然后,main函数再次在第14行显示局部变量计数的“值”和“地址”。清单8:14 println("count:\tValue Of[",count, "]\tAddr Of[", &count, "]")
操场上程序的完整输出应如下所示:清单9:count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
inc: Value Of[ 11 ] Addr Of[ 0x10429f98 ]
count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
main帧中的计数值在调用增量之前和之后是相同的。从函数返回
当函数退出并且控制权返回到调用函数时,堆栈上的内存实际上发生了什么?简短的答案是什么。返回增量函数后的堆栈如下所示:图4: 堆栈看上去与图3完全相同,只是现在将与增量函数关联的帧视为无效内存。这是因为main的框架现在处于活动状态。为增量功能创建的内存保持不变。清除返回函数的内存框架将浪费时间,因为尚不清楚是否会再次需要此内存。因此记忆仍然保持原样。在每个函数调用期间,当拍摄一个帧时,将清除该帧的堆栈存储器。这是通过初始化适合框架的任何值来完成的。由于所有值都初始化为它们的``零值'',因此每次函数调用都会正确清除堆栈。
堆栈看上去与图3完全相同,只是现在将与增量函数关联的帧视为无效内存。这是因为main的框架现在处于活动状态。为增量功能创建的内存保持不变。清除返回函数的内存框架将浪费时间,因为尚不清楚是否会再次需要此内存。因此记忆仍然保持原样。在每个函数调用期间,当拍摄一个帧时,将清除该帧的堆栈存储器。这是通过初始化适合框架的任何值来完成的。由于所有值都初始化为它们的``零值'',因此每次函数调用都会正确清除堆栈。价值共享
如果对于增量函数直接使用main框架中存在的count变量很重要,该怎么办?这是指针的时机到了。指针有一个目的-与函数共享一个值,以便该函数可以读取和写入此值,即使该值不直接存在于其框架中也是如此。如果您认为不需要“共享”值,则无需使用指针。学习指针时,请务必使用简洁的字典,而不是运算符或语法。请记住,指针旨在共享,并且在阅读代码时,将&运算符替换为短语“ sharing”。指针类型
对于您声明的或由语言本身直接声明的每种类型,您将获得一个可用于共享的免费指针类型。已经有一个称为int的内置类型,因此有一个名为* int的指针类型。如果声明一个名为User的类型,则免费获得一个名为* User的指针类型。所有类型的指针都有两个相同的特征。首先,它们以*字符开头。其次,它们在内存中的大小都相同,并且占据4或8个字节的表示形式代表该地址。在32位体系结构(例如,在游乐场)上,指针需要4字节的内存,而在64位体系结构(例如,您的计算机)上,指针则需要8字节的内存。在规范中,指针类型被认为是类型文字,这意味着它们是由现有类型组成的无名类型。间接内存访问
看一下这个小程序,它通过“按值”传递地址来进行函数调用。这将使用增量函数从主堆栈的堆栈帧中拆分count变量:清单10:01 package main
02
03 func main() {
04
05
06 count := 10
07
08
09 println("count:\tValue Of[", count, "]\t\tAddr Of[", &count, "]")
10
11
12 increment(&count)
13
14 println("count:\tValue Of[", count, "]\t\tAddr Of[", &count, "]")
15 }
16
17
18 func increment(inc *int) {
19
20
21 *inc++
22 println("inc:\tValue Of[", inc, "]\tAddr Of[", &inc, "]\tValue Points To[", *inc, "]")
23 }
对原始程序进行了三个有趣的更改。第一个更改在第12行:清单11:12 increment(&count)
这次,在第12行,代码不复制“值”并将其传递给count变量,而是传递其“ address”而不是count变量。现在您可以说:“我正在共享”带有函数增量的变量计数。这就是&运算符所说的“共享”。知道这仍然是“按值传递”,唯一的区别是传递的值是地址,而不是整数。地址也是值;这就是复制并跨过框架边界传递的内容,以调用该函数。由于地址值已复制并传递,因此您需要在增量框架内添加一个变量来获取和保存该整数地址。第18行上有一个整数指针变量声明。清单12:18 func increment(inc *int) {
如果传递了类型为User的值的地址,则必须将变量声明为* User。尽管所有指针变量都存储了地址值,但它们不能传递任何地址,只能传递与指针类型关联的地址。共享值的基本原理是接收函数必须读取或写入该值。您需要有关任何值类型的信息,以便对其进行读写。编译器将确保此函数仅使用与正确的指针类型关联的值。调用递增函数后,堆栈如下所示:图5: 图5显示了使用地址作为值执行“按值传递”时的堆栈外观。现在,增量功能框架内的指针变量指向位于main框架内的count变量。现在,使用指针变量,该函数可以对位于main框架内的count变量执行间接读取和更改操作。清单13:
图5显示了使用地址作为值执行“按值传递”时的堆栈外观。现在,增量功能框架内的指针变量指向位于main框架内的count变量。现在,使用指针变量,该函数可以对位于main框架内的count变量执行间接读取和更改操作。清单13:21 *inc++
这次,*字符充当运算符,并应用于指针变量。使用*作为运算符意味着“指针指向的值”。指针变量提供对使用它的函数框架之外的内存的间接访问。有时,这种间接读取或写入称为指针取消引用。增量函数仍然需要在其框架中具有一个指针变量,可以直接读取该指针变量以执行间接访问。图6显示了第21行之后的堆栈外观。图6: 这是该程序的最终输出:清单14:
这是该程序的最终输出:清单14:count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
inc: Value Of[ 0x10429fa4 ] Addr Of[ 0x10429f98 ] Value Points To[ 11 ]
count: Value Of[ 11 ] Addr Of[ 0x10429fa4 ]
您可能会注意到inc指针变量的“值”与计数变量的“地址”匹配。这建立了共享关系,允许间接访问框架外的内存。增量函数通过指针写入后,一旦将控制返回给主函数,该更改便对主函数可见。指针变量并不特殊
指针变量不是特殊的,因为它们是与任何其他变量相同的变量。它们具有内存分配,并且包含含义。碰巧的是,所有指针变量(无论它们可以指向的值的类型)始终具有相同的大小和表示形式。令人困惑的是,*字符充当代码内的运算符,并用于声明指针类型。如果可以将类型声明与指针操作区分开,则可以帮助消除一些混乱。结论
这篇文章描述了指针的用途,堆栈的操作以及Go中指针的机制。这是理解编写连贯且可读的代码所需的机制,设计原理和使用技术的第一步。最后,这是您学到的知识:- 在帧边界内执行功能,这为每个相应功能提供了单独的存储空间。
- 调用函数时,会在两个帧之间发生过渡。
- “按值”数据传输的优点是可读性。
- 堆栈很重要,因为它为分配给每个单独功能的帧边界提供了物理存储空间。
- 活动框架下方的所有堆栈内存均无效,但活动框架及其上方的所有堆栈内存均有效。
- , .
- , , .
- — , , .
- , , , , .
- - , .
- - - , , . , .