在二进制图像中搜索和标记连接的组件是图像分析和处理的基本算法之一。特别是,该算法可以在机器视觉中用于搜索和计数图像中的常见结构,并对其进行后续分析。在本文的框架中,将考虑两种标记连接的组件的算法,并显示了它们在编程语言F#中的实现。并且,对算法进行比较分析,寻找弱点。实施算法的原始资料摘自《计算机视觉》一书(作者L. Shapiro,J.Stockman。A。Boguslavsky的英语翻译,S。M. Sokolov编辑)。介绍
值为v的连通分量是一组C,此类像素的值为v,并且这些像素中的每一对都与值为v相连
这听起来很深刻,所以让我们看一下图片。我们假设二进制图像的前景像素标记为1,而背景像素标记为0。使用连接的组件的标记算法处理图像后,我们得到以下图片。在此,代替像素,形成彼此连接的组件,其数量彼此不同。在此示例中,找到了5个组件,可以像使用单独的实体一样使用它们。图1:标记的连接组件
下面将考虑可以用来解决该问题的两种算法。递归标记算法
我们将从最明显的基于递归的算法开始。这种算法的工作原理如下:分配一个标签,我们将标记相关组件的初始值。- 我们对表格中的所有点进行排序,从坐标0x0(左上角)开始。处理下一点后,将标签增加一个
- 如果当前坐标处的像素为1,则我们将扫描该点的所有四个邻居(上,下,右,左)
- 1, , 0
- , .
因此,对数组中的所有点进行排序并为每个点调用一个递归算法,然后在搜索结束时,我们得到一个完全标记的表。由于将检查是否已标记给定点,因此每个点将仅被处理一次。递归深度将仅取决于与当前点相连的邻居的数量。该算法非常适合没有较大图像填充的图像。也就是说,图像中有细线和短线,其他所有图像都是未经处理的背景图像。而且,这种算法的速度可能比逐行算法更高(我们将在本文后面讨论)。由于二维二进制图像是二维矩阵,因此在编写算法时,我将使用矩阵的概念进行操作,为此我撰写了一篇单独的文章,可以在此处阅读以线性代数理论中的矩阵运算示例为例的函数式编程,让我们详细考虑并分析实现的F#函数连接二值图像分量的递归标记算法let recMarkingOfConnectedComponents matrix =
let copy = Matrix.clone matrix
let (|Value|Zero|Out|) (x, y) =
if x < 0 || y < 0
|| x > (copy.values.[0, *].Length - 1)
|| y > (copy.values.[*, 0].Length - 1) then
Out
else
let row = copy.values.[y, *]
match row.[x] with
| 0 -> Zero
| v -> Value(v)
let rec markBits x y value =
match (x, y) with
| Value(v) ->
if value > v then
copy.values.[y, x] <- value
markBits (x + 1) y value
markBits (x - 1) y value
markBits x (y + 1) value
markBits x (y - 1) value
| Zero | Out -> ()
let mutable value = 2
copy.values
|> Array2D.iteri (fun y x v -> if v = 1 then
markBits x y value
value <- value + 1)
copy
我们声明了recMarkingOfConnectedComponents
函数,该函数采用二维矩阵数组,打包成Matrix类型的记录。该函数不会更改原始数组,因此首先创建它的副本,该副本将由算法处理并返回。let copy = Matrix.clone matrix
为了简化对数组外部请求点的索引的检查,请创建一个活动模板,该模板返回三个值之一。Out-所请求的索引超出了二维数组的范围零 -该点包含一个背景像素(等于零)Value-所请求的索引位于该数组内此模板将简化在下一递归帧处检查图像点的坐标:let (|Value|Zero|Out|) (x, y) =
if x < 0 || y < 0
|| x > (copy.values.[0, *].Length - 1)
|| y > (copy.values.[*, 0].Length - 1) then
Out
else
let row = copy.values.[y, *]
match row.[x] with
| 0 -> Zero
| v -> Value(v)
MarkBits
函数被声明为递归的,用于处理当前像素及其所有相邻像素(顶部,底部,左侧,右侧):let rec markBits x y value =
match (x, y) with
| Value(v) ->
if value > v then
copy.values.[y, x] <- value
markBits (x + 1) y value
markBits (x - 1) y value
markBits x (y + 1) value
markBits x (y - 1) value
| Zero | Out -> ()
该函数接受以下参数作为输入:x-行号y-列号值 -用于标记像素的当前标签值使用match / with结构和活动模板(上方),检查像素坐标,以使其不超出二维范围数组。如果该点在二维数组内,则进行初步检查,以免处理已经处理过的点。if value > v then
否则,将发生无限递归并且该算法将不起作用。接下来,用当前标记值标记点:copy.values.[y, x] <- value
然后我们处理其所有邻居,以递归方式调用相同的函数:markBits (x + 1) y value
markBits (x - 1) y value
markBits x (y + 1) value
markBits x (y - 1) value
实现算法后,必须使用它。请更详细地考虑代码。let mutable value = 2
copy.values
|> Array2D.iteri (fun y x v -> if v = 1 then
markBits x y value
value <- value + 1)
在处理图像之前,请设置标签的初始值,该初始值将标记连接的像素组。let mutable value = 2
事实是二进制图像中的前像素已经设置为1,因此,如果标签的初始值也为1,则该算法将不起作用。因此,标签的初始值必须大于1。还有另一种解决问题的方法。在开始算法之前,用初始值-1标记所有设置为1的像素。然后我们可以将值设置为1。如果需要,您可以自己进行操作。
使用Array2D.iteri函数的下一个构造将遍历数组中的所有点,并且在搜索过程中遇到的点设置为1,那么这意味着它未被处理,因此您需要使用当前标签值调用递归函数markBits。该算法将忽略所有设置为0的像素。在递归处理该点之后,我们可以假定保证标记了该点所属的整个连接组,并且可以将标签值增加1以将其应用于下一个连接点。考虑这种算法的应用示例。let a = array2D [[1;1;0;1;1;1;0;1]
[1;1;0;1;0;1;0;1]
[1;1;1;1;0;0;0;1]
[0;0;0;0;0;0;0;1]
[1;1;1;1;0;1;0;1]
[0;0;0;1;0;1;0;1]
[1;1;0;1;0;0;0;1]
[1;1;0;1;0;1;1;1]]
let A = Matrix.ofArray2D a
let t = System.Diagnostics.Stopwatch.StartNew()
let R = Algorithms.recMarkingOfConnectedComponents A
t.Stop()
printfn "origin =\n %A" A.values
printfn "rec markers =\n %A" R.values
printfn "elapsed recurcive = %O" t.Elapsed
origin =
[[1; 1; 0; 1; 1; 1; 0; 1]
[1; 1; 0; 1; 0; 1; 0; 1]
[1; 1; 1; 1; 0; 0; 0; 1]
[0; 0; 0; 0; 0; 0; 0; 1]
[1; 1; 1; 1; 0; 1; 0; 1]
[0; 0; 0; 1; 0; 1; 0; 1]
[1; 1; 0; 1; 0; 0; 0; 1]
[1; 1; 0; 1; 0; 1; 1; 1]]
rec markers =
[[2; 2; 0; 2; 2; 2; 0; 3]
[2; 2; 0; 2; 0; 2; 0; 3]
[2; 2; 2; 2; 0; 0; 0; 3]
[0; 0; 0; 0; 0; 0; 0; 3]
[4; 4; 4; 4; 0; 5; 0; 3]
[0; 0; 0; 4; 0; 5; 0; 3]
[6; 6; 0; 4; 0; 0; 0; 3]
[6; 6; 0; 4; 0; 3; 3; 3]]
elapsed recurcive = 00:00:00.0037342
递归算法的优点包括其编写和理解简单。这对于包含大背景并散布着少量像素(例如,线条,小斑点等)的二进制图像非常有用。在这种情况下,图像处理速度可能会很高,因为该算法会一次处理整个图像。缺点也很明显-这是递归。如果图像由大斑点组成或被完全淹没,则处理速度将急剧下降(下降几个数量级),并且由于堆栈上的可用空间不足,可能会导致程序完全崩溃。不幸的是,尾部递归原理不能应用于该算法,因为尾部递归有两个要求:- 每个递归帧都必须执行计算并将结果添加到累加器中,该累加器将沿着堆栈传输。
- 在一个递归框架中最多只能有一个递归函数调用。
在我们的情况下,递归不执行任何最终计算,可以将其传递到下一帧递归,而只需修改二维数组即可。原则上,可以通过简单地返回一个数字来避免这种情况,这本身并不意味着任何事情。我们还需要递归进行4次调用,因为我们需要处理该点的所有四个邻居。基于数据结构标记组合搜索的经典算法
该算法还有另一个名称“渐进标记算法”,在这里我们将尝试对其进行解析。该算法分两遍处理图像。在第一遍,确定等效类并分配临时标签。在第二遍,每个临时标记将被相应的等价类的标记代替。在第一遍和第二遍之间,处理以二进制表形式存储的记录的等价关系集,以确定等价类。
上面的定义更加令人困惑,因此我们将尝试以不同的方式处理算法原理,并且从头开始。首先,我们将处理当前点的四连接和八连接邻域的定义。查看下面的图片,了解它的含义和区别。图2:四连接组件
图2:八个连接的分量第一张图片显示了一个点的四个连接的分量,也就是说,这意味着该算法处理了当前点的四个邻居(左,右,上和下)。因此,一个点的八连分量表示它具有8个邻居。在本文中,我们将使用四个连接的组件。
现在,您需要找出在某些集合上建立的用于组合搜索的数据结构是什么?
例如,假设我们有两个集合
这些集合以以下树的形式进行组织: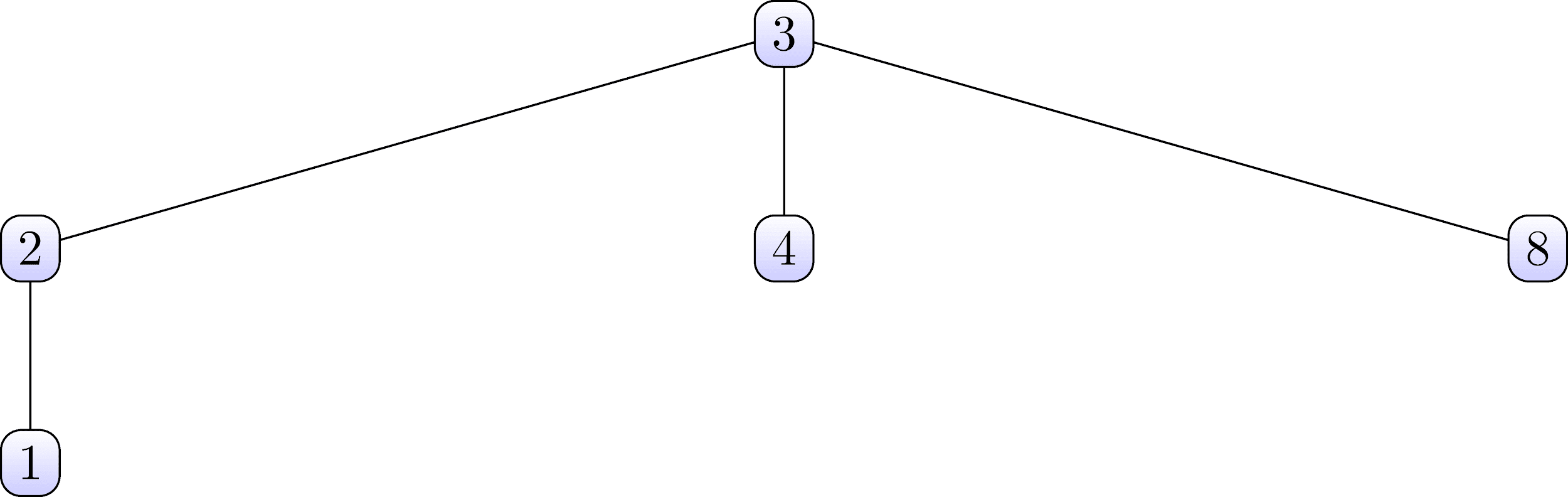
 请注意,在第一个集合中,节点3是根,在第二个集合中,节点6。现在,我们考虑搜索联盟的数据结构,其中包含这两个集合,并且还组织了它们的树结构。 。图4:搜索联盟数据结构
仔细看一下上面的表,然后尝试找到与上面显示的集合树的关系。该表应在垂直列中查看。可以看出数字3
请注意,在第一个集合中,节点3是根,在第二个集合中,节点6。现在,我们考虑搜索联盟的数据结构,其中包含这两个集合,并且还组织了它们的树结构。 。图4:搜索联盟数据结构
仔细看一下上面的表,然后尝试找到与上面显示的集合树的关系。该表应在垂直列中查看。可以看出数字3
第一行对应第二行中的数字0。在第一棵树中,数字3是第一集合的根。以此类推,您可以发现第一行的数字7对应于第二行的数字0。数字7也是第二组树的根。因此,我们得出结论,上排的数字是集合的子节点,下排的对应数字是它们的父节点。按照此规则,您可以轻松地从上表中还原两棵树。我们分析了这些细节,以便以后让我们更容易理解渐进标记算法的工作原理。。现在,让我们详细讨论一下第一行中的一系列数字始终是从1到某个最大数字的数字。实际上,第一行的最大数量是将标记所找到的已连接组件的标签的最大值。各个集合是由于第一次通过而形成的标签之间的过渡(我们将在后面详细讨论)。在继续之前,请考虑该算法将使用的某些函数的伪代码。我们将表示联接搜索的数据结构的表表示为PARENT。下一个函数称为find,它将当前标签X作为参数和PARENT数组。此过程跟踪父指针直到树的根,并找到X所属的树的根节点的标签。 ̆ ̆ .
X —
PARENT — , ̆ -
procedure find(X, PARENT);
{
j := X;
while PARENT[j] <> 0
j := PARENT[j]; return(j);
}
考虑如何在F#上实现这样的功能let rec find x =
let index = Array.tryFindIndex ((=)x) parents.[0, *]
match index with
| Some(i) ->
match parents.[1, i] with
| p when p <> 0 -> find p
| _ -> x
| None -> x
这里我们声明的递归函数查找,这需要当前标签的X。PARRENT数组未在此处传递,因为我们已经在全局名称空间中有了它,并且该函数已经看到它并可以使用它。首先,该函数尝试在顶行上找到标签的索引(因为您需要找到位于下一行的标签的父级。let index = Array.tryFindIndex ((=)x) parents.[0, *]
如果搜索成功,则获取其父级并与0比较。如果父级不等于0,则此节点也有一个父级,并且该函数递归调用自身,直到父级等于0为止。这意味着我们已经找到了集合的根节点。match index with
| Some(i) ->
match parents.[1, i] with
| p when p <> 0 -> find p
| _ -> x
| None -> x
我们需要的下一个函数称为union。它需要两个标签X和Y以及一个PARENT数组。这种结构修改(如果必要的话)PARENT含有标签的融合子集X,与该组包括标签ÿ。该过程将搜索两个标签的根节点,如果它们不匹配,则将其中一个标签的节点指定为第二个标签的父节点。因此,存在两个集合的并集。 .
X — , .
Y — , .
PARENT — , ̆ -.
procedure union(X, Y, PARENT);
{
j := X;
k := Y;
while PARENT[j] <> 0
j := PARENT[j];
while PARENT[k]] <> 0
k := PARENT[k];
if j <> k then PARENT[k] := j;
}
F#实现看起来像这样let union x y =
let j = find x
let k = find y
if j <> k then parents.[1, k-1] <- j
请注意,这里已经使用了我们已经实现的find函数。该算法还需要两个附加函数,称为邻居和标签。neighbors函数从给定像素向左和顶部返回相邻点集(因为在本例中,算法适用于四个连接的组件),labels函数返回已经分配给neighbors函数返回的给定像素集的标签集。在我们的例子中,我们将不会实现这两个函数,而只会创建一个将两个函数组合在一起并返回找到的标签的函数。let neighbors_labels x y =
match (x, y) with
| (0, 0) -> []
| (0, _) -> [step1.[0, y-1]]
| (_, 0) -> [step1.[x-1, 0]]
| _ -> [step1.[x, y-1]; step1.[x-1, y]]
|> List.filter ((<>)0)
展望未来,我将立即说使用该函数的数组step1已存在于全局空间中,并且包含在第一遍处理算法的结果。我要特别注意其他过滤器。|> List.filter ((<>)0)
它将截断所有为0的结果。也就是说,如果标签包含0,那么我们正在处理的背景图像中不需要处理的点。这是本书中未提及的非常重要的细微差别,我们以其中为例进行说明,但是,如果没有这种检查,该算法将无法正常工作。逐步地,我们逐步接近算法的本质。让我们再次看一下我们需要处理的图像。图5:原始二进制图像
在处理之前,创建一个空数组step1,其中将保存第一遍的结果。图6:用于存储主要处理结果的数组step1
考虑主要数据处理的前几个步骤(仅原始二进制图像的前三行)。在逐步研究算法之前,让我们看一下解释一般操作原理的伪代码。 .
B — .
LB — .
procedure classical_with_union-find(B, LB);
{
“ .” initialize();
“ 1 ̆ L .”
for L := 0 to MaxRow
{
“ L ”
for P := 0 to MaxCol
LB[L,P] := 0;
“ L.”
for P := 0 to MaxCol
if B[L,P] == 1 then
{
A := prior_neighbors(L,P);
if isempty(A)
then {M := label; label := label + 1;};
else M := min(labels(A));
LB[L,P] := M;
for X in labels(A) and X <> M
union(M, X, PARENT);
}
}
“ 2 , 1, .”
for L := 0 to MaxRow
for P := 0 to MaxCol
if B[L, P] == 1
then LB[L,P] := find(LB[L,P], PARENT);
};
LB ( step1) ( ).
图7:步骤1.点(0,0),标号= 1
图8:步骤2。点(1,0),标签= 1
图9:步骤2.点(2.0),标号= 1
图10:步骤4.点(3.0),标号= 2
图11:最后一步,第一遍的最终结果
请注意,由于对原始图像进行了初步处理,我们得到了两套
在视觉上,这可以看作是标记1和2(点(1,3)和(2,3)的坐标)与标记3和7(点(7,7)和(7,6)的坐标)的接触。从搜索联合的数据结构的角度来看,可以得到此结果。图12:用于搜索聚合的计算数据结构
使用获得的数据结构最终处理图像后,我们得到以下结果。图13:最终结果
现在,所有连接的组件都具有唯一的标签,并且可以在后续算法中进行处理。F#代码的实现如下let markingOfConnectedComponents matrix =
// up to 10 markers
let parents = Array2D.init 2 10 (fun x y -> if x = 0 then y+1 else 0)
// create a zero initialized copy
let step1 = (Matrix.cloneO matrix).values
let rec find x =
let index = Array.tryFindIndex ((=)x) parents.[0, *]
match index with
| Some(i) ->
match parents.[1, i] with
| p when p <> 0 -> find p
| _ -> x
| None -> x
let union x y =
let j = find x
let k = find y
if j <> k then parents.[1, k-1] <- j
// returns up and left neighbors of pixel
let neighbors_labels x y =
match (x, y) with
| (0, 0) -> []
| (0, _) -> [step1.[0, y-1]]
| (_, 0) -> [step1.[x-1, 0]]
| _ -> [step1.[x, y-1]; step1.[x-1, y]]
|> List.filter ((<>)0)
let mutable label = 0
matrix.values
|> Array2D.iteri (fun x y v ->
if v = 1 then
let n = neighbors_labels x y
let m = if n.IsEmpty then
label <- label + 1
label
else
n |> List.min
n |> List.iter (fun v -> if v <> m then union m v)
step1.[x, y] <- m)
let step2 = matrix.values
|> Array2D.mapi (fun x y v ->
if v = 1 then step1.[x, y] <- find step1.[x, y]
step1.[x, y])
{ values = step2 }
如上文所述,对代码进行逐行解释不再有意义。在这里,您可以简单地将F#代码映射到伪代码,以明确其工作方式。基准测试算法
让我们比较两种算法(递归和逐行)的数据处理速度。let a = array2D [[1;1;0;1;1;1;0;1]
[1;1;0;1;0;1;0;1]
[1;1;1;1;0;0;0;1]
[0;0;0;0;0;0;0;1]
[1;1;1;1;0;1;0;1]
[0;0;0;1;0;1;0;1]
[1;1;0;1;0;0;0;1]
[1;1;0;1;0;1;1;1]]
let A = Matrix.ofArray2D a
let t1 = System.Diagnostics.Stopwatch.StartNew()
let R1 = Algorithms.markingOfConnectedComponents A
t1.Stop()
let t2 = System.Diagnostics.Stopwatch.StartNew()
let R2 = Algorithms.recMarkingOfConnectedComponents A
t2.Stop()
printfn "origin =\n %A" A.values
printfn "markers =\n %A" R1.values
printfn "rec markers =\n %A" R2.values
printfn "elapsed lines = %O" t1.Elapsed
printfn "elapsed recurcive = %O" t2.Elapsed
origin =
[[1; 1; 0; 1; 1; 1; 0; 1]
[1; 1; 0; 1; 0; 1; 0; 1]
[1; 1; 1; 1; 0; 0; 0; 1]
[0; 0; 0; 0; 0; 0; 0; 1]
[1; 1; 1; 1; 0; 1; 0; 1]
[0; 0; 0; 1; 0; 1; 0; 1]
[1; 1; 0; 1; 0; 0; 0; 1]
[1; 1; 0; 1; 0; 1; 1; 1]]
markers =
[[1; 1; 0; 1; 1; 1; 0; 3]
[1; 1; 0; 1; 0; 1; 0; 3]
[1; 1; 1; 1; 0; 0; 0; 3]
[0; 0; 0; 0; 0; 0; 0; 3]
[4; 4; 4; 4; 0; 5; 0; 3]
[0; 0; 0; 4; 0; 5; 0; 3]
[6; 6; 0; 4; 0; 0; 0; 3]
[6; 6; 0; 4; 0; 3; 3; 3]]
rec markers =
[[2; 2; 0; 2; 2; 2; 0; 3]
[2; 2; 0; 2; 0; 2; 0; 3]
[2; 2; 2; 2; 0; 0; 0; 3]
[0; 0; 0; 0; 0; 0; 0; 3]
[4; 4; 4; 4; 0; 5; 0; 3]
[0; 0; 0; 4; 0; 5; 0; 3]
[6; 6; 0; 4; 0; 0; 0; 3]
[6; 6; 0; 4; 0; 3; 3; 3]]
elapsed lines = 00:00:00.0081837
elapsed recurcive = 00:00:00.0038338
如您所见,在此示例中,递归算法的速度大大超过了逐行算法的速度。但是,一旦我们开始处理填充有纯色的图片,并且为了清晰起见,一切都会改变,我们还将其尺寸增加到100x100像素。let a = Array2D.create 100 100 1
let A = Matrix.ofArray2D a
let t1 = System.Diagnostics.Stopwatch.StartNew()
let R1 = Algorithms.markingOfConnectedComponents A
t1.Stop()
printfn "elapsed lines = %O" t1.Elapsed
let t2 = System.Diagnostics.Stopwatch.StartNew()
let R2 = Algorithms.recMarkingOfConnectedComponents A
t2.Stop()
printfn "elapsed recurcive = %O" t2.Elapsed
elapsed lines = 00:00:00.0131790
elapsed recurcive = 00:00:00.2632489
如您所见,递归算法已经比线性算法慢25倍。让我们将图片的大小增加到200x200像素。elapsed lines = 00:00:00.0269896
elapsed recurcive = 00:00:06.1033132
差异已经有数百倍了。我注意到,递归算法的尺寸已经为300x300像素,导致堆栈溢出,程序崩溃。摘要
在本文的框架中,以F#功能语言为例,研究了标记用于处理二进制图像的连接组件的基本算法之一。这里给出了递归和经典算法的实现示例,解释了它们的操作原理,并使用特定示例进行了比较分析。此处讨论的源代码也可以在MatrixAlgorithmsgithub上查看,我希望本文对那些对F#特别是图像处理算法感兴趣的人感兴趣。