我们对死亡之神说什么? - 今天不行。
Sirio Trout,电视连续剧《权力的游戏》。冠状病毒COVID-19有多危险?世界上有多少人会死于冠状病毒?多少-在俄罗斯?在世界上大多数国家中是否确实采取了强有力的措施来对抗冠状病毒?什么会造成更多损害:冠状病毒导致的人员死亡或限制性措施导致的经济衰退?为了回答这些紧急问题,有必要进行数学建模并预测冠状病毒对个别国家乃至整个世界的损害。这种预测的结构专门用于本文。为了使所有读者都可以使用该材料,在本文开始时,我们将专注于定性分析和精美图片。最后,对于感兴趣的人,我们将提供使用Python执行计算的源代码。
不明飞行物护理分钟
大流行的COVID-19是由SARS-CoV-2冠状病毒(2019-nCoV)引起的潜在严重的急性呼吸道感染,已在全球正式宣布。关于Habré的很多信息都涉及此主题-始终记住,它既可靠又有用,反之亦然。
我们敦促您不要批评任何已发布的信息。
洗手,照顾亲人,尽可能呆在家里并远程工作。
阅读有关以下内容的出版物:冠状病毒 | 远程工作
只计算死亡
请注意,我们将评估与COVID-19相关的人类死亡人数。本文的大部分内容将致力于预测冠状病毒的死亡人数。我们通常拒绝考虑冠状病毒患者的数量并预测他们的数量。有几个原因。最主要的是,不可能比较不同国家中COVID-19病例数的统计数据。在某些国家,快速测试方法比在其他国家中可用得多。在一些国家,进行了几乎完整的人口检查,而在其他国家,仅对症状严重的人进行了检查。考虑到在很多情况下该疾病几乎是无症状的,我们发现患者死亡人数的分布范围很大:从不到0.5%到超过3.5%。死亡率数据的分散很可能主要是由于检测到COVID-19病例。在这种情况下,死亡率统计数据看起来更加可靠。自然地,当死亡原因未显示为冠状病毒而是伴随疾病时,我们可能会同时低估死亡人数,反之,当COVID-19被错误诊断时会高估高估死亡率,反之亦然。例如,人死于季节性流感。但是,我们可以预期死亡的统计数字更为可靠,因为 通常,在专家看来,无症状疾病的可能性很高,医生被迫分析每一个死亡病例。我们还注意到,对社会的真正损害是由其成员的死亡造成的,而不是由相对较快传播的轻度疾病造成的。您是否认为世界是由参展商统治的?和不!
一旦我们开始预测死亡人数,我们就立即遇到第一个神话:数以千计甚至数亿的人将死于冠状病毒。这个神话是基于这样的信念,即世界是由参展商统治的。看一下图表。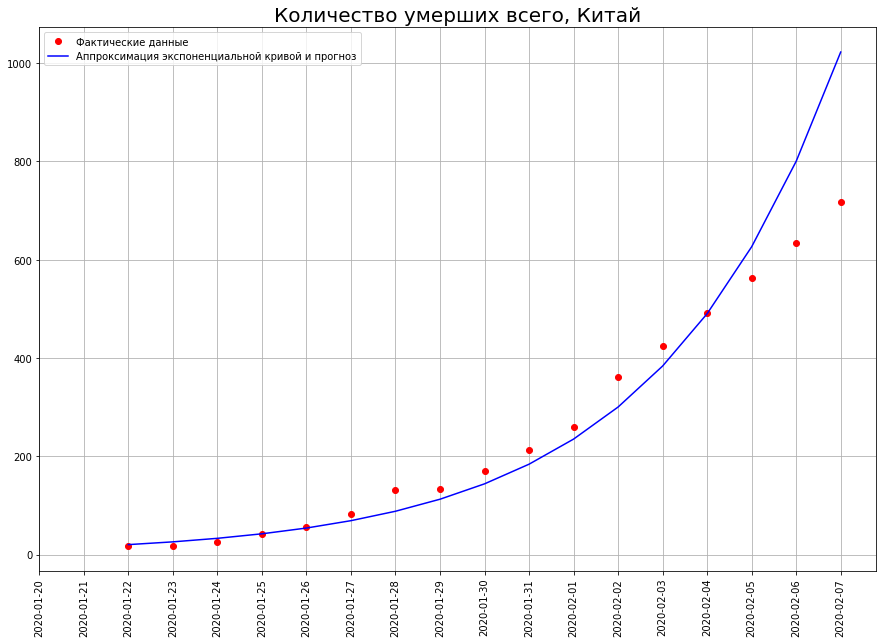 它显示了截至2月7日在中国死于COVID-19的人数。如果我们使用指数函数基于该图建立预测,那么到2月29日,中国将有5000万人死亡!
它显示了截至2月7日在中国死于COVID-19的人数。如果我们使用指数函数基于该图建立预测,那么到2月29日,中国将有5000万人死亡! 到底有多少人死亡?2837人。为什么会有如此巨大的差异?问题是世界不是由参展商统治,而是由逻辑曲线决定。与参展商不同,逻辑曲线不仅在学校而且在领先的技术大学(例如,莫斯科国立大学物理系和PhysTech)都没有通过。因此,物理学家和技术人员通常对此一无所知。尽管如此,经济学,生物学,社会学,科学技术中的大量现象正在完全按照这种数学模型发展。让我们仔细看看。她在这。时间绘制在x轴上,而y上的数字代表了我们研究的现象的特征(在我们的案例中,是死于冠状病毒的数目)。
到底有多少人死亡?2837人。为什么会有如此巨大的差异?问题是世界不是由参展商统治,而是由逻辑曲线决定。与参展商不同,逻辑曲线不仅在学校而且在领先的技术大学(例如,莫斯科国立大学物理系和PhysTech)都没有通过。因此,物理学家和技术人员通常对此一无所知。尽管如此,经济学,生物学,社会学,科学技术中的大量现象正在完全按照这种数学模型发展。让我们仔细看看。她在这。时间绘制在x轴上,而y上的数字代表了我们研究的现象的特征(在我们的案例中,是死于冠状病毒的数目)。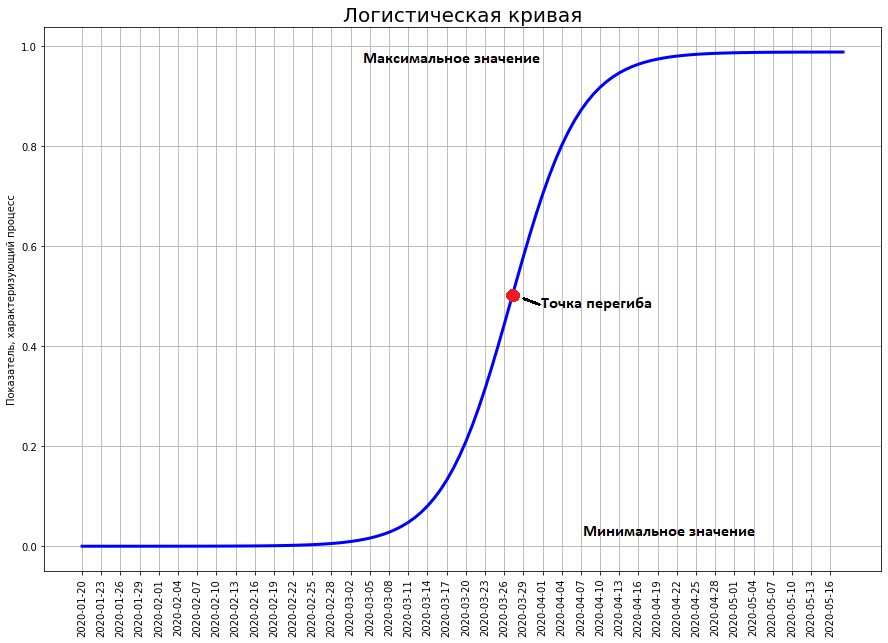
阴险的曲线打破了整个宣传
Logistic曲线显示了两个稳定状态之间的过渡。通常将较低状态视为零。上层状态是原则上可以实现的最大现象。曲线趋近于任意闭合,但从未达到最大值。曲线上最重要的点是拐点。它恰好位于最小值和最大值之间的中间。正是在这一点上曲线的最大增长率。但是其中出现了一个拐点。至此,曲线的增长只会加速。之后-仅消失。通常起初没有人注意到某种现象(因为直到1月底才注意到冠状病毒)。此时,曲线的值接近零。逐渐地,这种现象越来越多,他们开始注意到它,并在它周围引起了炒作。炒作既可以是积极的(例如,在加加林(Gagarin)飞行时,全世界的人们都因太空而生病)和消极的(目前的冠状病毒的情况)。在大肆宣传之时,每个人都预言这种现象将获得不可思议的比例,并使世界颠倒。因此,在加加林飞行期间,甚至专业人士都认为征服太阳系将在20世纪发生。他们根本没有想到,航天的所有成功都将在1969年人类登上月球时结束。在最大炒作时,曲线达到其未来最大值的一半。然后增长逐渐减弱,这种现象完全不能证明对它的希望(以及恐惧)。中国逻辑曲线
让我们看看中国发生了什么。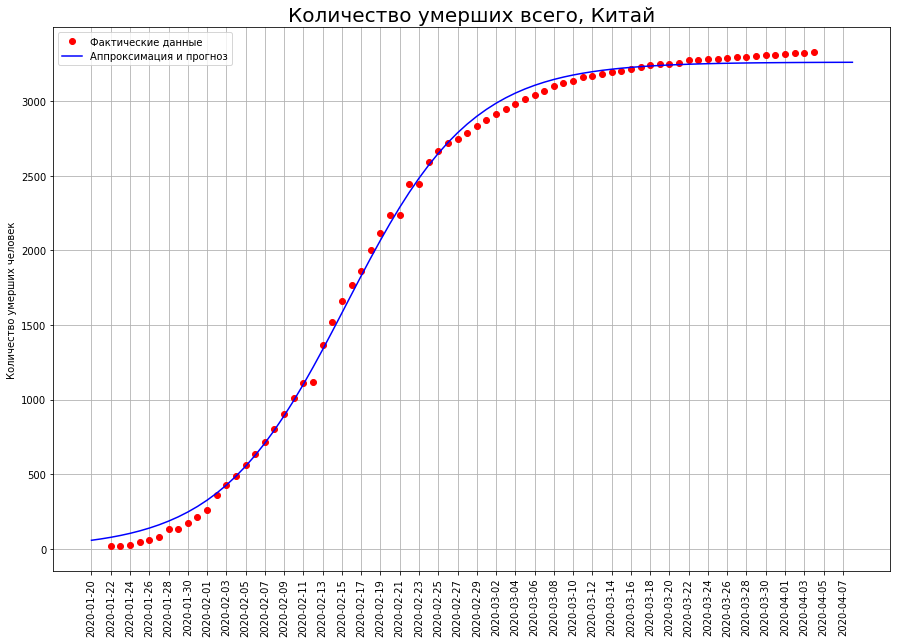 在下图中,红点表示给定日期病毒死亡的数量。蓝色曲线是近似真实数据的逻辑曲线。我们看到数据几乎完美地落在它上面。下图显示了在特定日期发生的死亡人数。实际上,这就是今天和昨天的逻辑曲线值之间的差异。从数学的角度来看,这是逻辑曲线的一阶导数。
在下图中,红点表示给定日期病毒死亡的数量。蓝色曲线是近似真实数据的逻辑曲线。我们看到数据几乎完美地落在它上面。下图显示了在特定日期发生的死亡人数。实际上,这就是今天和昨天的逻辑曲线值之间的差异。从数学的角度来看,这是逻辑曲线的一阶导数。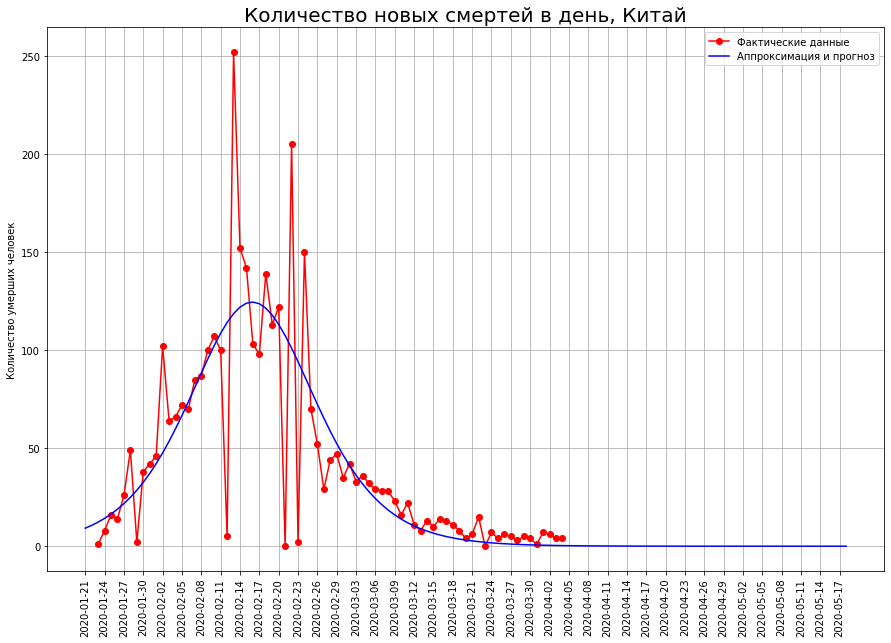 我们看到,起初新死亡人数几乎呈指数增长。然后增长开始放缓,当逻辑曲线达到最大值的一半时,新死亡的曲线在拐点处达到最大值。然后,新死亡人数减少,并趋于零。红点表示新的死亡,蓝色曲线是逻辑曲线的近似导数。请注意,逻辑曲线关于其拐点对称,并且其一阶导数相对于通过该点的垂直线。我们还注意到,理想情况下,实际数据位于对数曲线上,但它们相对于其一阶导数“跳舞”。事实是,某一点的死亡率具有很高的分散性,总死亡率就是这些指标的总和。根据中心极限定理进行平滑。因此,我们发现逻辑曲线可以有效地用于预测冠状病毒的死亡。此处的重要属性是对称性。当达到拐点时,我们可以从曲线的一半中高精度地恢复另一半。反过来,为了确定是否达到拐点,您只需要查看一阶导数的图即可。他一坐下来,就到达了相应的点。
我们看到,起初新死亡人数几乎呈指数增长。然后增长开始放缓,当逻辑曲线达到最大值的一半时,新死亡的曲线在拐点处达到最大值。然后,新死亡人数减少,并趋于零。红点表示新的死亡,蓝色曲线是逻辑曲线的近似导数。请注意,逻辑曲线关于其拐点对称,并且其一阶导数相对于通过该点的垂直线。我们还注意到,理想情况下,实际数据位于对数曲线上,但它们相对于其一阶导数“跳舞”。事实是,某一点的死亡率具有很高的分散性,总死亡率就是这些指标的总和。根据中心极限定理进行平滑。因此,我们发现逻辑曲线可以有效地用于预测冠状病毒的死亡。此处的重要属性是对称性。当达到拐点时,我们可以从曲线的一半中高精度地恢复另一半。反过来,为了确定是否达到拐点,您只需要查看一阶导数的图即可。他一坐下来,就到达了相应的点。意大利的灾难将如何结束?
让我们将三个国家的字母改为“ I”:意大利,伊朗和西班牙。查看特定日期的死亡曲线,我们很可能看到灾难的高峰已经过去了,现在该盘点了。

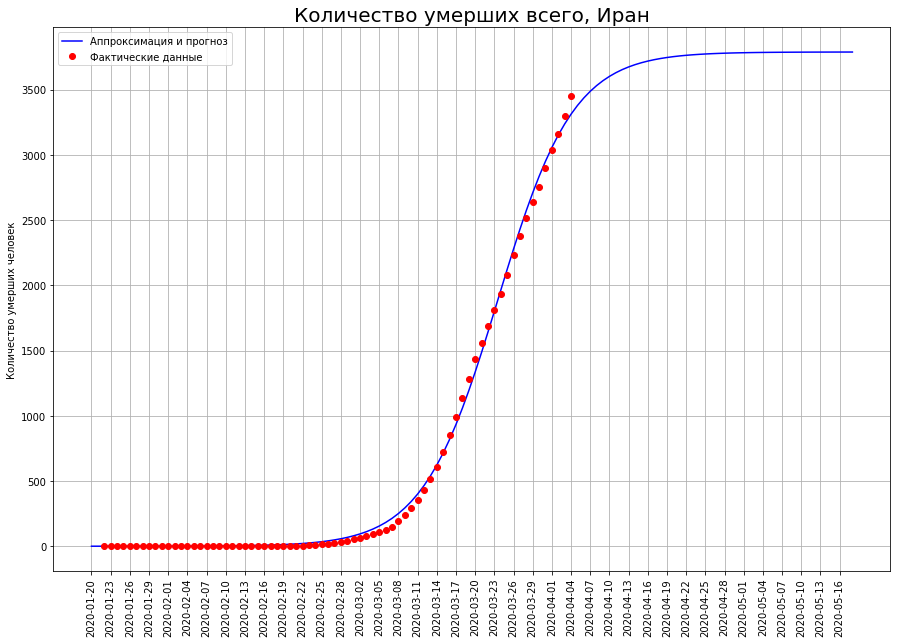
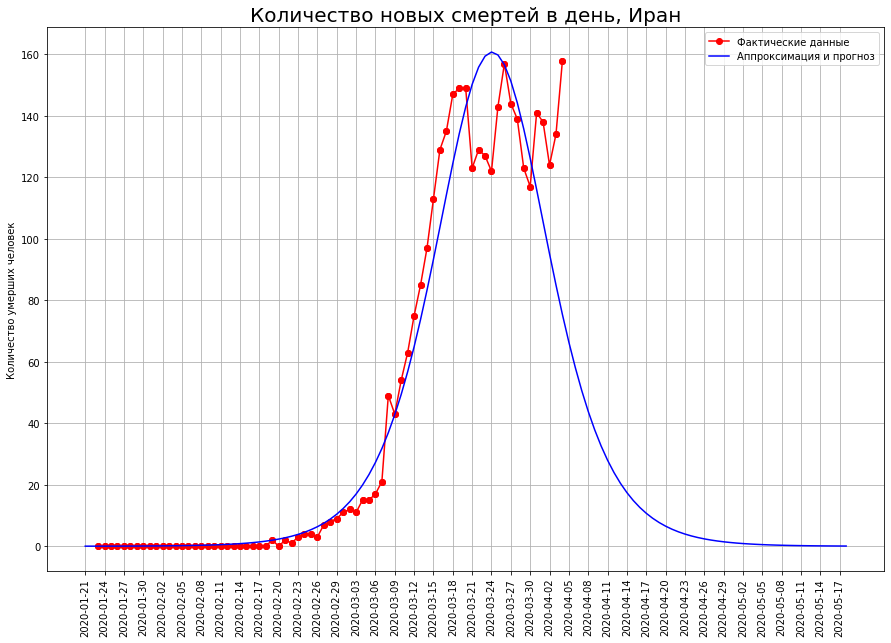
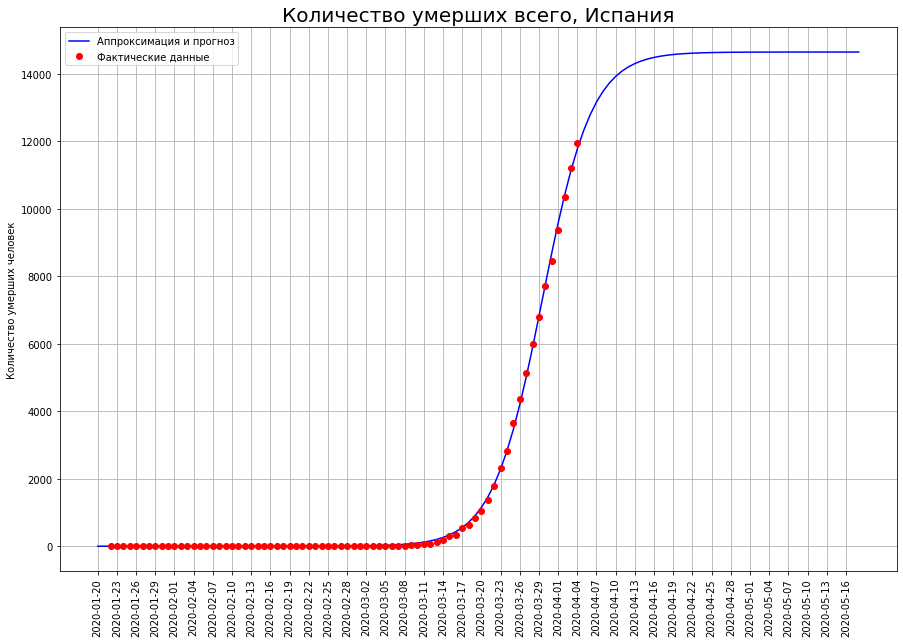
 根据我们的预测,只有COVID-19会死亡:在意大利-大约1.9 万人,在伊朗-大约4000例,在西班牙-大约1.5万人。
根据我们的预测,只有COVID-19会死亡:在意大利-大约1.9 万人,在伊朗-大约4000例,在西班牙-大约1.5万人。最终死亡率的一半
德国的流行病似乎已达到顶峰,该国死于冠状病毒的总数将达到2.6万人。
 在荷兰,瑞士和比利时等国家,数学模型表明该流行病正处于拐点。如果是这样,那么预期的死亡人数是:荷兰-约2.5万人,瑞士-约1.1万人,比利时-约2.2万人。
在荷兰,瑞士和比利时等国家,数学模型表明该流行病正处于拐点。如果是这样,那么预期的死亡人数是:荷兰-约2.5万人,瑞士-约1.1万人,比利时-约2.2万人。



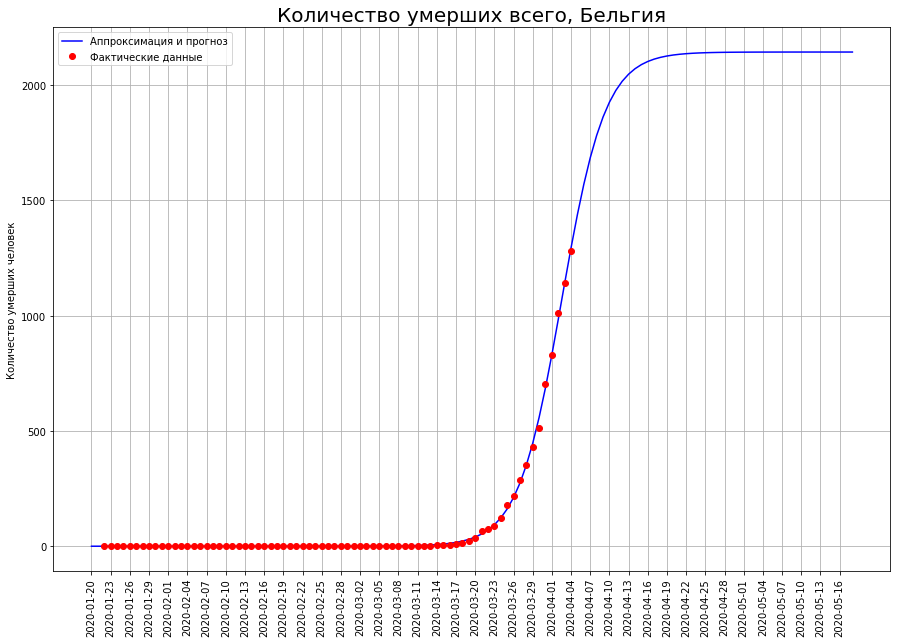
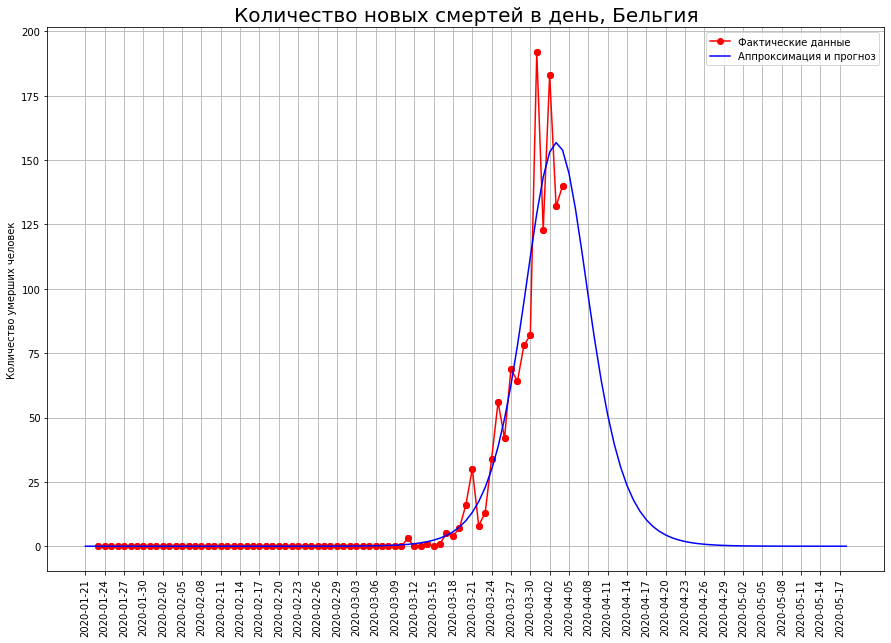
对于某人来说,这仅仅是开始
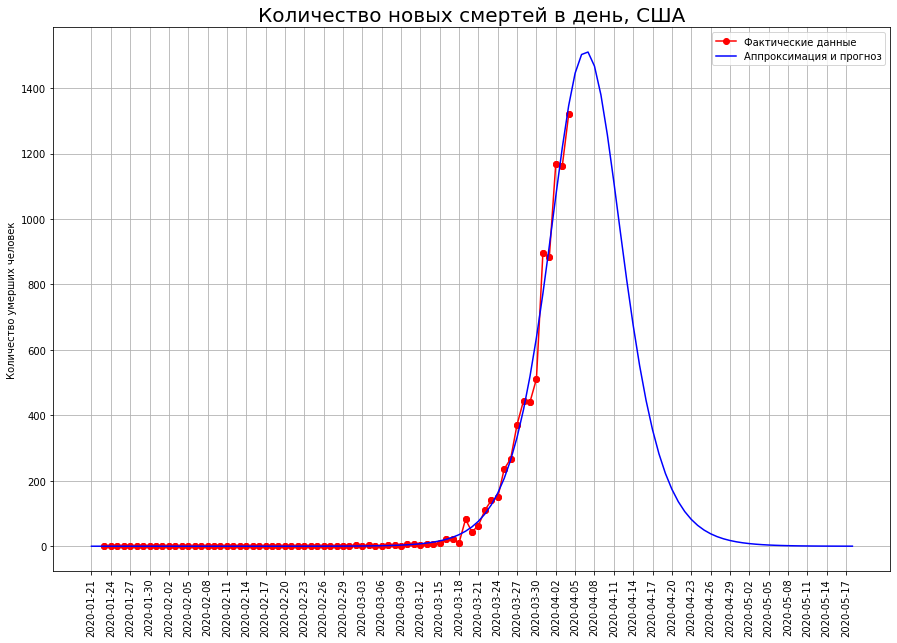
在美国,拐点尚未通过,因此可以大幅度调整它们的预测。目前,有23000人。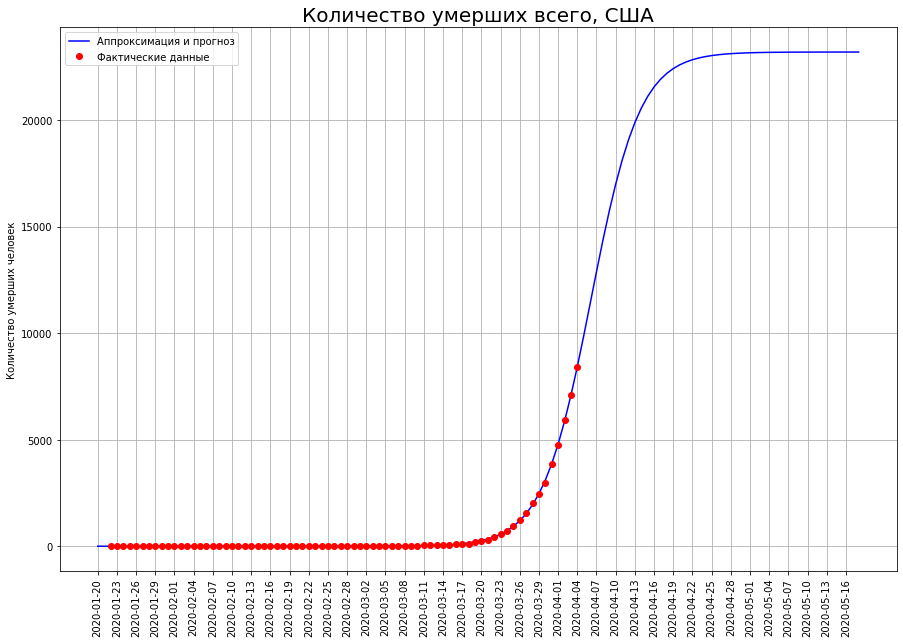
英国是悲剧的新中心吗?
最后,两国在达到拐点时仍存在高度不确定性。这些是英国和法国。

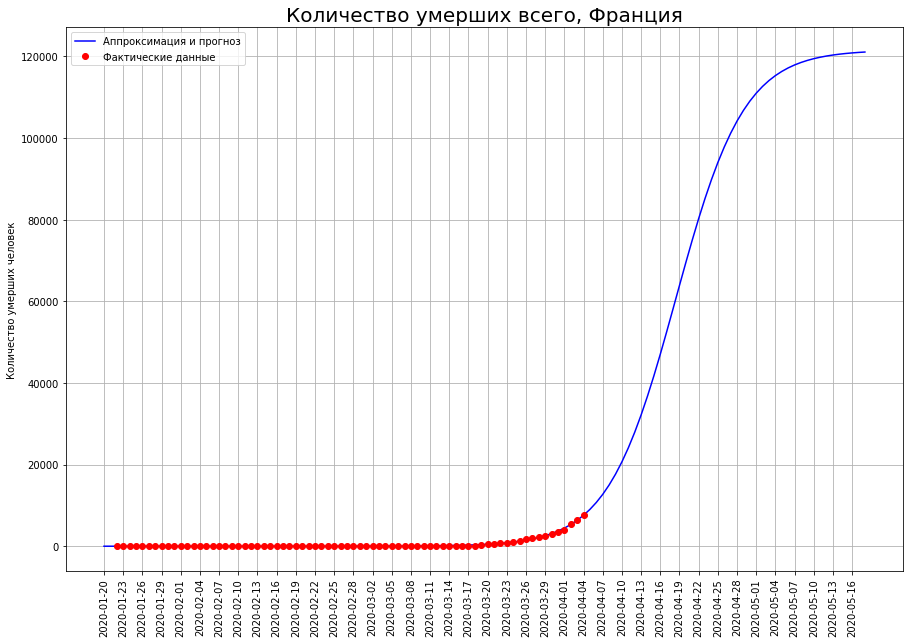
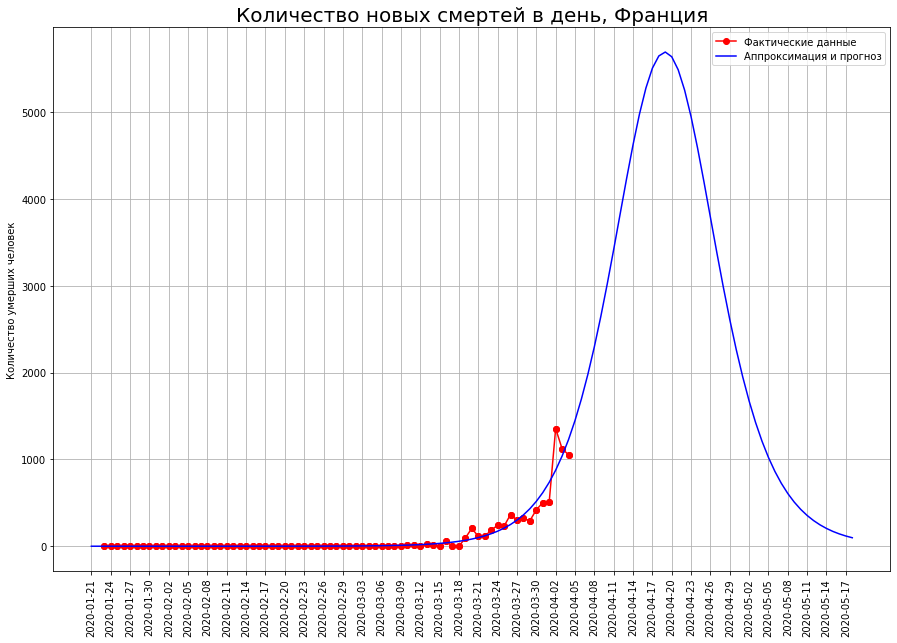 对他们最终死亡人数的预测正在不断增加。它们目前包括:作者希望这些预测是随机波动的结果,并在未来几天内将其下调。作者特别关注的是英国。根据截至3月25日的数据,作者预测该国的死亡率为1000人,根据截至01.04的数据为8000,目前的预测为3.3万人。没有其他国家的预测会出现这种波动。冠状病毒死亡悲剧的震中也许正在逐渐转移到英国。该国局势的发展也可能与鲍里斯·约翰逊最初不负责任的政策有关,鲍里斯·约翰逊直到最近才拒绝施加严格的限制,并希望“为牛群免疫”。在这种情况下,作者希望约翰逊如此不屑一顾的公民在下次选举中,尤其是在特别选举中记住他的这一政策。
对他们最终死亡人数的预测正在不断增加。它们目前包括:作者希望这些预测是随机波动的结果,并在未来几天内将其下调。作者特别关注的是英国。根据截至3月25日的数据,作者预测该国的死亡率为1000人,根据截至01.04的数据为8000,目前的预测为3.3万人。没有其他国家的预测会出现这种波动。冠状病毒死亡悲剧的震中也许正在逐渐转移到英国。该国局势的发展也可能与鲍里斯·约翰逊最初不负责任的政策有关,鲍里斯·约翰逊直到最近才拒绝施加严格的限制,并希望“为牛群免疫”。在这种情况下,作者希望约翰逊如此不屑一顾的公民在下次选举中,尤其是在特别选举中记住他的这一政策。俄罗斯天气预报
由于俄罗斯的流行才刚刚开始,因此无法使用逻辑曲线预测死亡人数。下面我们将使用不同的预测方法。在全球范围内呢?
现在是对整个世界进行预测的时候了。
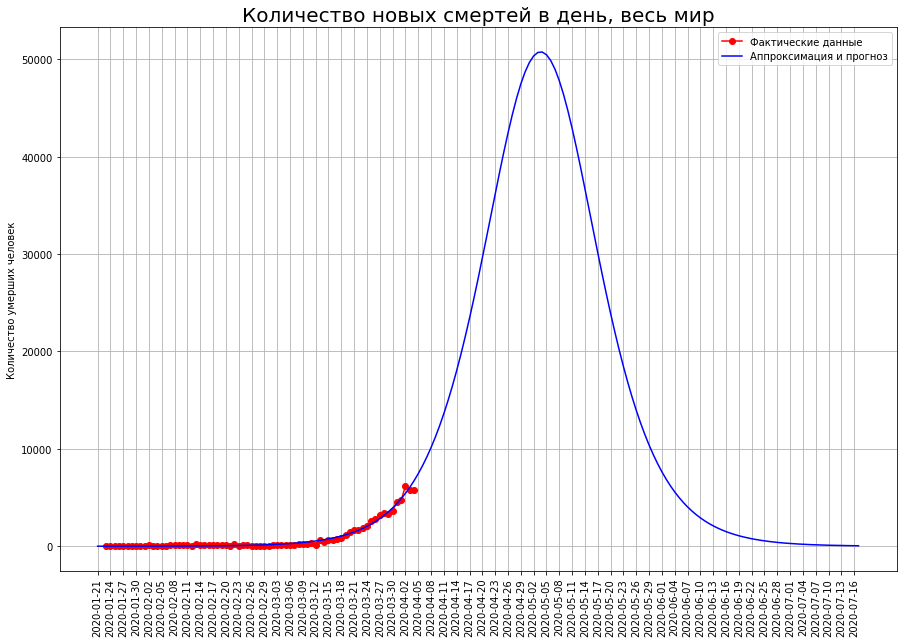 我们构建的逻辑曲线得出以下结果:危机的高峰将发生在5月的前10天,疫情将在7月中旬结束。它将杀死约100万人80万人。由于全球范围内的流行病仅在爆发,因此基于逻辑曲线的预测可能会得出错误的结果,因此我们将使用另一种预测方法。考虑我们做出预测的国家。
我们构建的逻辑曲线得出以下结果:危机的高峰将发生在5月的前10天,疫情将在7月中旬结束。它将杀死约100万人80万人。由于全球范围内的流行病仅在爆发,因此基于逻辑曲线的预测可能会得出错误的结果,因此我们将使用另一种预测方法。考虑我们做出预测的国家。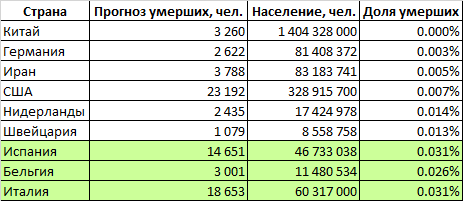 该表确定了死于冠状病毒的这些国家的人口比例(由于预测的高度不确定性,暂时将英国和法国排除在外)。我们看到这两组国家有很大不同。在意大利,西班牙和比利时等国家,预计死亡率为人口的0.029%。在一个更加繁荣的国家中(中国,德国,伊朗,美国,荷兰,瑞士),死亡率预计约为0.007%-低4倍。可以假设,整个世界将以更高的死亡率为特征。事实是,在我们的分析中,我们考察了相对富裕的国家,这些国家的政府实力雄厚,既有财政资源也有组织资源来应对这一流行病。但是在地球上,有许多州在财务和组织上都具有更为适度的能力。这些国家中许多都人口稠密。可以假设,与富裕的意大利,西班牙和比利时相比,在这些国家中,流行病会招致更大比例的受害者。另一方面,这些国家的老年人口比例较低,这降低了潜在的死亡率。如果我们以最差的一组国家的水平估计世界死亡率,那么世界上将有大约200万10万人死亡。如果使用平均值-则约为90万。我们对世界死亡人数的悲观预测是根据已故人口的份额计算的,令人惊讶地接近根据逻辑曲线计算的预测。因此,世界上将有1-2百万人死亡,而200万人的可能性更大。
该表确定了死于冠状病毒的这些国家的人口比例(由于预测的高度不确定性,暂时将英国和法国排除在外)。我们看到这两组国家有很大不同。在意大利,西班牙和比利时等国家,预计死亡率为人口的0.029%。在一个更加繁荣的国家中(中国,德国,伊朗,美国,荷兰,瑞士),死亡率预计约为0.007%-低4倍。可以假设,整个世界将以更高的死亡率为特征。事实是,在我们的分析中,我们考察了相对富裕的国家,这些国家的政府实力雄厚,既有财政资源也有组织资源来应对这一流行病。但是在地球上,有许多州在财务和组织上都具有更为适度的能力。这些国家中许多都人口稠密。可以假设,与富裕的意大利,西班牙和比利时相比,在这些国家中,流行病会招致更大比例的受害者。另一方面,这些国家的老年人口比例较低,这降低了潜在的死亡率。如果我们以最差的一组国家的水平估计世界死亡率,那么世界上将有大约200万10万人死亡。如果使用平均值-则约为90万。我们对世界死亡人数的悲观预测是根据已故人口的份额计算的,令人惊讶地接近根据逻辑曲线计算的预测。因此,世界上将有1-2百万人死亡,而200万人的可能性更大。祖国和我们会怎样?
至于俄罗斯,其人口为1.48亿,乐观的预测(基于除前三名外来者之外所有国家的平均数)为10,000人。悲观的(基于意大利,西班牙和比利时的死亡率)-4万。1万的可能性更大。事实是,俄罗斯有几个有利因素:人口密度低,大城市之间的距离较远,各地区(不包括大都市区)之间的移民流动相对较少,当局为应对这一流行病采取行动的果断性,充分性和及时性。这些因素为避免根据意大利-西班牙-比利时版本发展局势提供了希望。关于俄罗斯流行病完成的时间,我们转向下面的图表。在上面,我们在一张图中描绘了不同国家的逻辑曲线。在这种情况下,我们将所有曲线的高度归一化,以使最大值为1,然后合并拐点,将其置于零。该图显示该流行病在40-60天之内结束。如果我们以3月30日为起点,那么在俄罗斯,这种流行病必须在5月10日至30日结束。受害者有道理吗?
最后,文章开头提出的最后一个问题:世界上大多数国家/地区的政府采取严格的检疫措施有何道理?全世界每年约有五千八百万人死亡。根据悲观的预测,将有200万人死于冠状病毒,这一数字将增加3.5%。另一方面,大规模的世界隔离有可能升级为自大萧条以来最大的经济危机。结果,成千上万的人将没有工作。人口收入将下降,许多人将因饥饿或无力支付医疗费用而丧生。包括一些世界领导人在内,人们常常表达出这样的观点,那就是让人们走上命运,而不是破坏经济。最终,每年有300至65万人死于季节性流感,但没有人对经济采取这种破坏性的限制性措施。我们的模型允许我们陈述以下内容:COVID-19根本不是季节性流感。这种病毒是无比危险的。事实是逻辑曲线的拐点本身并不存在。它受到流行病状况的极大影响。 Logistic曲线描述了任何流行的过程,但是Logistic曲线是一个全族。我们记得拐点恰好是曲线最大值的一半。因此,死亡高峰越晚,最终死亡人数就越大。我们看到,在拐点附近,逻辑曲线尽可能快地增长。因此,如果疾病高峰在10天后过去,受害者人数可能会增加几倍!我们收到的关于逻辑曲线拐点的预测已经包括世界各国政府采取的所有检疫措施。如果没有此类措施,拐点将在很晚之后到达。在这种情况下,死亡率可能达到全世界人口的0.4-0.5%。我们为什么要估计未经控制的流行病的死亡率为人口的0.4-0.5%。我们假设在这种情况下,地球的整个人口将以一种或另一种形式感染该病毒。但是,在很多人中,这种疾病是无症状的。因此,我们使用了韩国和德国等国家/地区的统计数据,这些国家/地区成功地对人群进行了冠状病毒检测,并确定了大多数真实病例。我们认为,在其他国家/地区,由于案件数量被大大低估了,因此统计数据失真了。因此,死亡率高达3.5%。世界人口的0.4-0.5%是28-3500万人。在人类整个历史上进行的所有战争中,只有第二次世界大战的损失数量超过了这个数字。世界绝大多数国家的政府为了挽救人民做出了空前的经济牺牲,这一事实表明了世界上生命的代价已经增长了多少。人文主义思想和个人利益的优先考虑有多么广泛。这鼓舞了作者以人类为荣,并希望为全人类创造更美好的未来。本文最大的缺点
这是本文的最大缺点。不幸的是,经典统计不能为我们提供基于逻辑函数来估计预测误差的工具。这是由于函数的形式有所变化。如果没有这种变化,并且曲线将是单调的,我们将在Box-Cox变换的帮助下首先将函数变为线性形式。之后,使用误差方程式进行线性回归,我们将构建误差的上下边界,然后使用逆Box-Cox变换获得曲线误差边界,在此基础上,我们将构建冠状病毒死亡人数的最大和最小预测。las,经典统计工具无法在带有弯曲的曲线的情况下构造误差边界。但是机器学习方法可能对我们有帮助。在下一篇文章中,我将说明在这种情况下错误边界的构造方式,并将分别对上述每个国家和整个世界建立死亡人数的最小和最大预测。现在有很多代码和数字
好吧,实际上,对于那些想要了解我们如何得出上述结论的人来说,现在是数学。那些对无聊的计算不感兴趣的人无法进一步阅读。计算是在Jupiter环境中的Python中使用其他库scipy,numpy,pandas,datetime完成的。为了可视化,我们使用了matplotlib.pyplot包。在此链接上获得了死亡人数的初始数据,并在Excel中进行了预处理。截至4月4日的信息。这是带有源信息的文件链接。因此,我们导入库,稍后将使用它们:import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import pandas as pd
from IPython.display import display
import scipy as sp
from datetime import datetime
from scipy.optimize import minimize
我们读取源数据并将其转换为DataFrame对象。变量标签将转换为Timestamp对象。原则上,我们可以将自己限制为简单的numpy数组,但是我们使用DataFrame来方便地存储带有相应日期的数据,并使用Timestamp进行可视化,以便在图形上漂亮地显示这些日期。corona = pd.read_csv('D:/coronavirus.csv',sep=“;”)
corona.set_index('Date',
inplace = True)corona.index = pd.to_datetime(corona.index)
然后,从单个DataFrame中,创建与每个国家的总死亡率相对应的Series类型变量。X是一个变量,它等于从年初开始的天数。预测时将需要它。X = corona['X']
chi = corona['China']
fr = corona['France']
ir = corona['Iran']
it = corona['Italy']
sp = corona['Spain']
uk = corona['UK']
us = corona['US']
bg = corona['Belgium']
gm = corona['Germany']
nt = corona['Netherlands']
sw = corona['Switzerland']
tot = corona['Total']
此后,我们将计算特定日期的简单numpy阵列的死亡率。请注意,此类数组的长度比相应的Series变量的长度小1。dchi = chi[1:].values - chi[:-1].values
dfr = fr[1:].values - fr[:-1].values
dit = it[1:].values - it[:-1].values
diran = ir[1:].values - ir[:-1].values
dsp = sp[1:].values - sp[:-1].values
duk = uk[1:].values - uk[:-1].values
dus = us[1:].values - us[:-1].values
dbg = bg[1:].values - bg[:-1].values
dgm = gm[1:].values - gm[:-1].values
dnt = nt[1:].values - nt[:-1].values
dsw = sw[1:].values - sw[:-1].values
dtot = tot[1:].values - tot[:-1].values
我们引入了一个用于预测的附加变量。该数组开始于1月20日,结束于7月17日的180天。我们还创建与此数组相对应的Timestamp对象以对轴进行签名。X_long = np.arange(20, 200)
time_long = pd.date_range('2020-01-20', periods=180)
我们定义了resLogistic函数,其输入参数为3位数字的数组,输出为logistic曲线的值与中国流行病实际死亡人数之差的平方和。def resLogistic(coefficents):
A0 = coefficents[0]
A1 = coefficents[1]
A2 = coefficents[2]
teor = A0 / (1 + np.exp(A1 * (X.ravel() - A2)))
return np.sum((teor - chi) ** 2)
每个日期的死亡人数为累积总数。逻辑曲线由输入向量的3个分量确定。组件的零值(Python中数组元素的计数从零开始)负责最大值,第一个表示函数的增长率,第二个表示拐点在时间轴上的位置。teor-基于输入参数向量的每天死亡人数,chi-中国的实际死亡人数。该函数返回理论值与实际值之间平方差的总和。现在,使用scipy.optimize库的最小化方法,我们找到一个向量,该向量最小化平方偏差的总和。基于此向量构建的逻辑曲线是根据最小二乘法进行的预期死亡率预测。我们补充说,最小化方法需要一个起点。我们根据我们已知的逻辑函数的属性来选择它(最大值应大于任何经验死亡人数,拐点应接近表征每天新死亡人数的dtot曲线的最大值)。通常,最小化方法的结果与起点无关,但是也有例外。mimim.x是最小化向量的值。minim = minimize(resLogistic, [3200, -.16, 46])
minim.x
现在,我们在图表上显示实际死亡人数,逼近其逻辑预测曲线,并用日期在时间轴上签名。plt.figure(figsize=(15,10))
teorChi = minim.x[0] / (1 + np.exp(minim.x[1] * (X_long - minim.x[2])))
plt.plot(X,chi,'ro', label=' ')
plt.plot(X_long[:80], teorChi[:80],'b', label=' ')
plt.xticks(X_long[:80][::2], time_long.date[:80][::2], rotation='90');
plt.title(' , ', Size=20);
plt.ylabel(' ')
plt.legend()
plt.grid()
在下图中,我们绘制了上面选择的逻辑曲线的一阶导数(蓝线)以及新死亡人数的真实曲线(红线)。plt.figure(figsize = (15,10))
plt.grid()
plt.title(' , ', Size=20);
plt.plot(X[1:], dchi, 'r', Marker='o', label=' ')
plt.xticks(X_long[1:120][::3], time_long.date[1:120][::3], rotation='90');
plt.plot(X_long[1:120], teorChi[1:120] - teorChi[:119],'b', label=' ')
plt.ylabel(' ')
plt.legend()
我们对文章中提到的每个国家都进行了类似的计算。然后作者写了一个不太漂亮的代码。有必要为所有国家/地区编写一个函数,并通过最小化方法的参数将实际死亡人数传递给该函数。但是作者没有时间来处理这种机制,因此他为每个国家/地区编写了自己的功能,并且在该功能内,他呼吁一个变量,该变量包含有关特定国家/地区的死亡人数的信息。以下是伊朗,意大利,西班牙和美国的计算。我认为,要恢复其他国家的计算,读者并不难。def resLogisticIr(coefficents):
A0 = coefficents[0]
A1 = coefficents[1]
A2 = coefficents[2]
teor = A0 / (1 + np.exp(A1 * (X.ravel() - A2)))
return np.sum((teor - ir) ** 2)
minim = minimize(resLogisticIr, [3200, -.16, 80])
minim.x
plt.figure(figsize=(15,10))
teorIr = minim.x[0] / (1 + np.exp(minim.x[1] * (X_long - minim.x[2])))
plt.plot(X_long[:120], teorIr[:120],'b', label=' ')
plt.xticks(X_long[:120][::3], time_long.date[:120][::3], rotation='90');
plt.title(' , ', Size=20);
plt.plot(X,ir,'ro', label=' ')
plt.grid()
plt.legend()
plt.ylabel(' ')
plt.figure(figsize = (15,10))
plt.grid()
plt.title(' , ', Size=20);
plt.plot(X[1:], diran, 'r', Marker='o', label=' ')
plt.plot(X[1:], diran, 'ro')
plt.xticks(X_long[1:120][::3], time_long.date[1:120][::3], rotation='90');
plt.plot(X_long[1:120], teorIr[1:120] - teorIr[:119],'b', label=' ')
plt.ylabel(' ')
plt.legend()
def resLogisticIt(coefficents):
A0 = coefficents[0]
A1 = coefficents[1]
A2 = coefficents[2]
teor = A0 / (1 + np.exp(A1 * (X.ravel() - A2)))
return np.sum((teor - it) ** 2)
minim = minimize(resLogisticIt, [3200, -.16, 46])
minim.x
plt.figure(figsize=(15,10))
teorIt = minim.x[0] / (1 + np.exp(minim.x[1] * (X_long - minim.x[2])))
plt.plot(X,it,'ro', label=' ')
plt.plot(X_long[:120], teorIt[:120],'b', label=' ')
plt.xticks(X_long[:120][::3], time_long.date[:120][::3], rotation='90');
plt.title(' , ', Size=20);
plt.ylabel(' ')
plt.grid()
plt.legend()
plt.figure(figsize = (15,10))
plt.grid()
plt.title(' , ', Size=20);
plt.plot(X[1:], dit, 'r', Marker='o', label=' ')
plt.xticks(X_long[1:120][::3], time_long.date[1:120][::3], rotation='90');
plt.plot(X_long[1:120], teorIt[1:120] - teorIt[:119],'b', label=' ')
plt.ylabel(' ')
plt.legend()
def resLogisticSp(coefficents):
A0 = coefficents[0]
A1 = coefficents[1]
A2 = coefficents[2]
teor = A0 / (1 + np.exp(A1 * (X.ravel() - A2)))
return np.sum((teor - sp) ** 2)
minim = minimize(resLogisticSp, [3200, -.16, 80])
minim.x
plt.figure(figsize=(15,10))
teorSp = minim.x[0] / (1 + np.exp(minim.x[1] * (X_long - minim.x[2])))
plt.plot(X_long[:120], teorSp[:120],'b', label=' ')
plt.xticks(X_long[:120][::3], time_long.date[:120][::3], rotation='90');
plt.title(' , ', Size=20);
plt.plot(X,sp,'ro', label=' ')
plt.grid()
plt.legend()
plt.ylabel(' ')
plt.figure(figsize = (15,10))
plt.grid()
plt.plot(X[1:], dsp, 'r', Marker='o', label=' ')
plt.plot(X[1:], dsp, 'ro')
plt.xticks(X_long[1:120][::3], time_long.date[1:120][::3], rotation='90');
plt.title(' , ', Size=20);
plt.plot(X_long[1:120], teorSp[1:120] - teorSp[:119],'b', label=' ')
plt.ylabel(' ')
plt.legend()
def resLogisticUs(coefficents):
A0 = coefficents[0]
A1 = coefficents[1]
A2 = coefficents[2]
teor = A0 / (1 + np.exp(A1 * (X.ravel() - A2)))
return np.sum((teor - us) ** 2)
minim = minimize(resLogisticUs, [3200, -.16, 100])
minim.x
plt.figure(figsize=(15,10))
teorUS = minim.x[0] / (1 + np.exp(minim.x[1] * (X_long - minim.x[2])))
plt.plot(X_long[:120], teorUS[:120],'b', label=' ')
plt.xticks(X_long[:120][::3], time_long.date[:120][::3], rotation='90');
plt.title(' , ', Size=20);
plt.plot(X,us,'ro', label=' ')
plt.grid()
plt.legend()
plt.ylabel(' ')
plt.figure(figsize = (15,10))
plt.grid()
plt.title(' , ', Size=20);
plt.plot(X[1:], dus, 'r', Marker='o', label=' ')
plt.plot(X[1:], dus, 'ro')
plt.xticks(X_long[1:120][::3], time_long.date[1:120][::3], rotation='90');
plt.plot(X_long[1:120], teorUS[1:120] - teorUS[:119],'b', label=' ')
plt.ylabel(' ')
plt.legend()