在我作为软件开发人员和团队负责人15年的经验中,我经常遇到同一件事。编程变成一种信仰-很少有人尝试根据合理的选择,合理地考虑限制,可移植性,评估对供应商的依恋程度,实际价格,技术前景和许可自由来引入技术。开发人员参加会议或阅读文章-开始大肆宣传,他们的IT主管和经理不仅饱受事件,各种有远见的人,销售人员和顾问的故事的光明敏捷的未来。事实证明,这些技术都在项目中,没有考虑到开发和实施的便利性,项目的非功能性要求,而是因为它被炒作而google本身使用,亚马逊建议(尽管他们的空缺说他们自己不经常使用它)或公司管理层已做出最高决策来实施“此”。但是特别有趣的是选择数据库。存储的信息量越大,项目中的数据结构及其更改/演化越复杂,对响应时间或性能的要求越高,在项目后期开始时选择错误的代价就越大。我知道为什么会这样-简而言之,然后对不同的技术进行原型设计和比较是“昂贵的”(时间,许可,培训或逆向工程),并且倾向于开启古老的直觉,从耗时的证据部分转向有趣而简单,触动了非理性的深渊。我也这样做了,而且我也看到了最可笑的事情是如何在我和我的朋友的工作中发生的,而不仅仅是技术专家的决定。因此,可以根据网络中的帖子,会议报告,Gartner的管理人员手册或算命书,很好地选择编程语言,框架,消息队列或云提供商。很遗憾我不能讲很多我的作品,因为我担心那之后的生活...什么影响数据库的选择
从我的角度来看,在选择数据库时,我必须至少解决以下权衡问题:- 实时交易处理或在线分析处理
- 垂直或水平扩展
- 在分布式基础上-数据一致性/可用性/抗分离性(CAP定理)
- 特定的数据方案和数据库或存储中不需要数据方案的限制
- 数据模型-键值,层次结构,图形,文档或关系型
- 处理逻辑尽可能接近数据或应用程序中的所有处理
- 主要在RAM或磁盘子系统中工作
- 通用解决方案或专业
- 我们在数据库中使用了不适合项目要求的现有专业知识,或者在适当但不熟悉的培训中“血汗”开发了一个新的专家(这不仅适用于开发,而且适用于操作)
- 内置或在其他进程/网络中
- 潮人或逆行
通常,我们对实现的解决方案有一个“礼物”:- “外星人”查询语言
- 唯一的用于处理数据库的本机API,这会使向其他数据库的转换复杂化(花费了时间,团队精力和项目预算)
- 其他平台/语言/操作系统的驱动程序不可用
- 缺少源代码,磁盘上数据格式的描述(或禁止使用逆向工程许可,尤其是具有Coherence缺陷的Oracle)
- 许可证成本逐年增长
- 自己的生态系统和寻找专家的困难
- , ,
系统的水平扩展非常复杂,需要团队专业知识。经验丰富的开发人员在市场上非常昂贵,而分布式应用程序更难以开发,调试和测试。因此,如果有可能将服务器更改为功能更强大的服务器,并且系统允许的数据量较大,则他们通常会这样做。现在,服务器上可以拥有TB级的RAM和数百个处理器核心。因此,前所未有地重要的是,最大限度地利用所有服务器资源。数据库许可证的成本也很重要,如果以处理器内核出售它们,那么即使是纵向扩展,其运行预算也可能要花费超大型空间计划的费用。因此,记住这一点很重要,以免由于许可证而无法扩展数据库性能。显然,在市场营销的帮助下,他们将试图说服您只有某个公司的解决方案才能解决您的所有问题(但他们对出现多少新问题保持沉默)。没有一个理想的数据库可以适合所有人并且适合所有情况。因此,在可预见的将来,我们仍将支持几个不同的数据库,以便为不同系统中的不同类型的查询处理相同的数据。没有数据缓存就没有Data Fabric解决方案,就性能和查询优化而言,Data Lake尚无法与大规模并行架构的数据库进行比较。事务性数据仍将存储在PostgreSQL,Oracle,MS Sql Server,Citus,Greenplum,Snowflake,Redshift,Vertica,Impala,Teradata中的分析查询中,HDFS / S3 / ADLS(Azure)中的原始数据沼泽将由Dremio管理。 ,Redshift Spectrum,Apache Spark,Presto。但是上面列出的解决方案不适合用于分析响应时间短的时间序列数据。根据其在处理时间序列数据中的受欢迎程度,现在它已成为InfluxDB的最爱。在内存数据库利基市场中,kdb +和memSQL保留了自己的位置。QuestDB
拥有Apache许可证的
所有这些开源QuestDB解决方案都可以反对什么?- 尝试最大程度地利用硬件来执行分析查询-聚合函数的矢量化,通过内存映射文件处理数据
- SQL作为DML查询和DDL操作的语言,用于管理数据库结构
- 支持特定于时间序列数据库的联接表
- 支持SQL中的窗口和聚合功能
- 在JVM上的应用程序中嵌入数据库的能力
- JVM, ServiceLoader
- Influx DB line protocol (ILP) UDP Telegraf. «What makes QuestDB faster than InfluxDB»
- PostgreSql 11 PostgreSQL: JDBC, ODBC psql
- web - REST endpoint , SQL json
- ,
- zero-GC API, .
- ( )
- 64 Windows, Linux, OSX, ARM Linux FreeBSD
- , open source,
当此数据库对您有用时-如果您正在以低延迟在JVM上开发财务系统,并且需要用于RAM中数据分析的解决方案。由于许可证费用,因此可以替代kdb +。如果使用Influx / Telegraf协议收集指标,但是InfluxDB的性能和可用性并不令人满意。如果您的项目在JVM上运行,并且您需要一个内置数据库来存储仅添加而不更新的指标或应用程序数据。支持SIMD指令的新版本4.2.0引起了Reddit的热议。为了让粉丝参加现代硬件知识及其有效编程的竞赛,我建议在评论中与数据库的作者(bluestreak01)交谈!SIMD操作
该项目团队对综合数据进行了测试,并将QuestDB 4.2.0与kdb 4.0 进行了比较,以利用处理器的SIMD指令汇总十亿个值。在Intel 8850H平台上: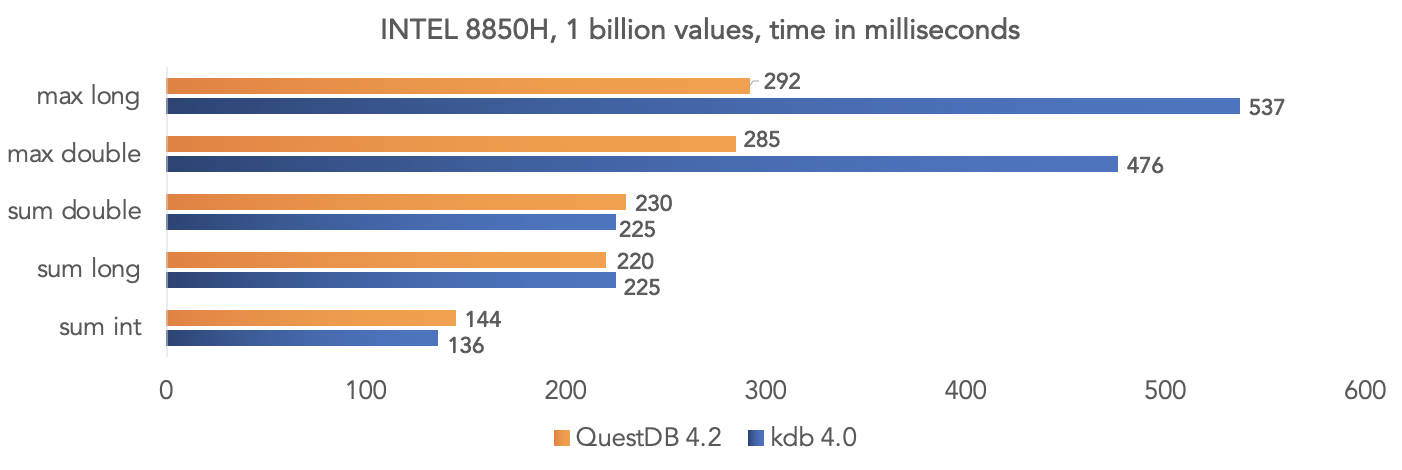 在AMD Ryzen 3900X平台上:
在AMD Ryzen 3900X平台上: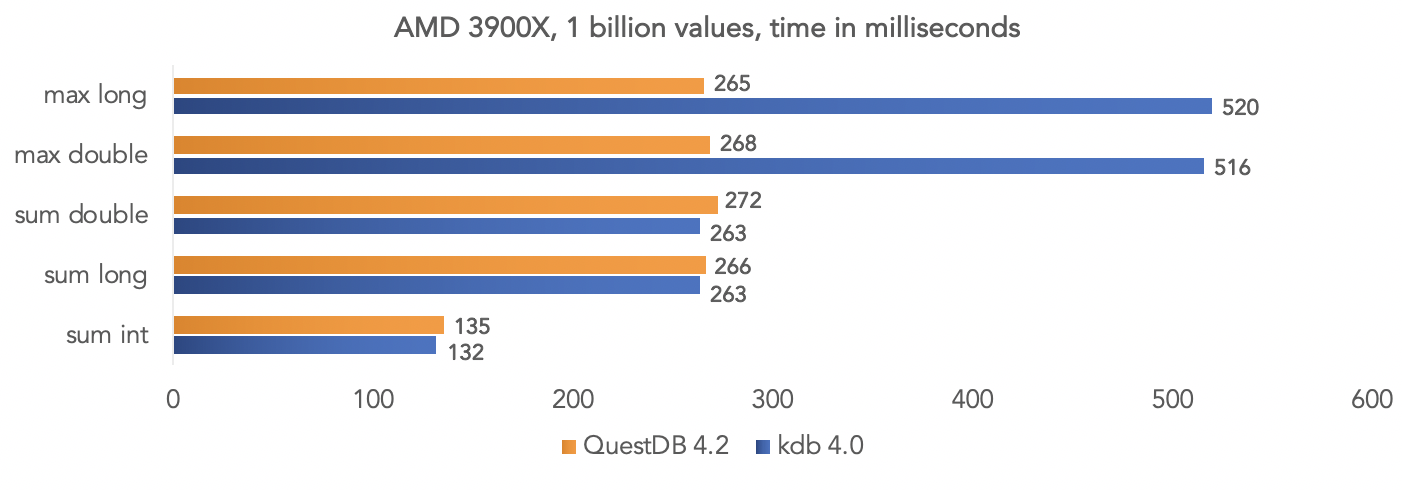 显然,所有这些测试都是在“真空”中进行的,但是如果您的项目使用kdb并与社区共享结果,则可以对数据进行比较。
显然,所有这些测试都是在“真空”中进行的,但是如果您的项目使用kdb并与社区共享结果,则可以对数据进行比较。运行docker数据库镜像
该数据库随每个发行版发布在dockerhub上。有关更多详细信息,请参见项目文档。获取QuestDB图像:docker pull questdb/questdb
我们推出:docker run --rm -it -p 9000:9000 -p 8812:8812 questdb/questdb
之后,您可以使用PostgreSQL协议连接到端口8812,Web控制台在端口9000上可用。Jdbc访问
根据我们的项目,我们添加PostrgreSQL jdbc驱动程序org.postgresql:postgresql:42.2.12,对于该测试,我将QuestDB模块用于testcontainers。该测试可在github上与构建脚本一起使用:import org.junit.jupiter.api.Test;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import static org.assertj.core.api.Assertions.*;
public class QuestDbDriverTest {
@Test
void containerIsUpTestByJdbcInvocation() throws Exception {
try (Connection connection = DriverManager.getConnection("jdbc:tc:questdb:///?user=admin&password=quest")){
try (Statement statement = connection.createStatement()){
try (ResultSet resultSet = statement.executeQuery("select 42 from long_sequence(1)")){
resultSet.next();
assertThat(resultSet.getInt(1)).isEqualTo(42);
}
}
}
}
}
运行docker会导致额外的开销,这可以通过简单地实现org.questdb:core:jar:4.2.0作为对项目的依赖关系并运行io.questdb.ServerMain来避免。import io.questdb.ServerMain;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.io.TempDir;
import java.nio.file.Path;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.Statement;
public class QuestDbJdbcTest {
@Test
void embeddedServerStartTest(@TempDir Path tempDir) throws Exception{
ServerMain.main(new String[]{"-d", tempDir.toString()});
try (DriverManager.getConnection("jdbc:postgresql://localhost:8812/", "admin", "quest")){
try (Statement statement = connection.createStatement()){
try (ResultSet resultSet = statement.executeQuery("select 42 from long_sequence(1)")){
resultSet.next();
assertThat(resultSet.getInt(1)).isEqualTo(42);
}
}
}
}
}
嵌入Java应用程序
但这是使用进程内Java API处理数据库的最快方法:import io.questdb.cairo.CairoEngine;
import io.questdb.cairo.DefaultCairoConfiguration;
import io.questdb.griffin.CompiledQuery;
import io.questdb.griffin.SqlCompiler;
import io.questdb.griffin.SqlExecutionContextImpl;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.io.TempDir;
import java.nio.file.Path;
public class TruncateExecuteTest {
@Test
void truncate(@TempDir Path tempDir) throws Exception{
SqlExecutionContextImpl executionContext = new SqlExecutionContextImpl();
DefaultCairoConfiguration configuration = new DefaultCairoConfiguration(tempDir.toAbsolutePath().toString());
try (CairoEngine engine = new CairoEngine(configuration)) {
try (SqlCompiler compiler = new SqlCompiler(engine)) {
CompiledQuery createTable = compiler.compile("create table tr_table(id long,name string)", executionContext);
compiler.compile("truncate table tr_table", executionContext);
}
}
}
}
网络控制台
该项目包括一个Web控制台,用于查询QuestDB并将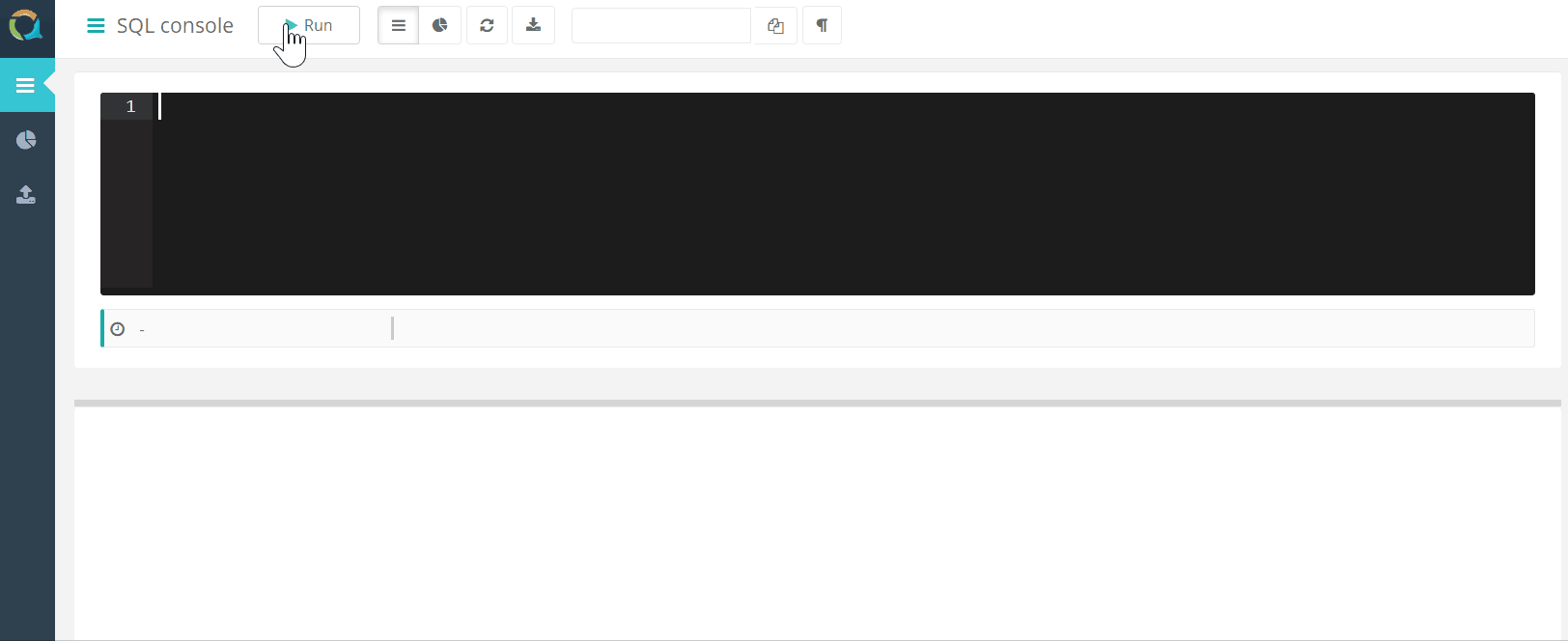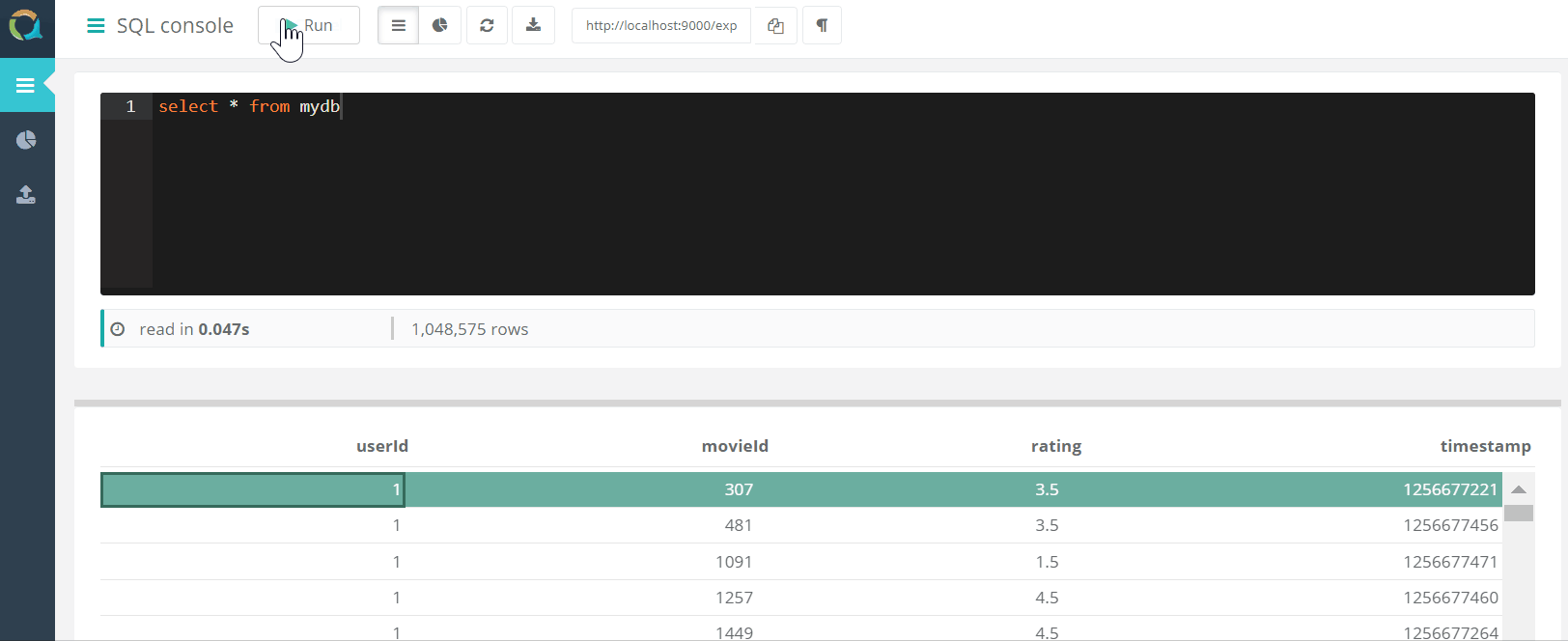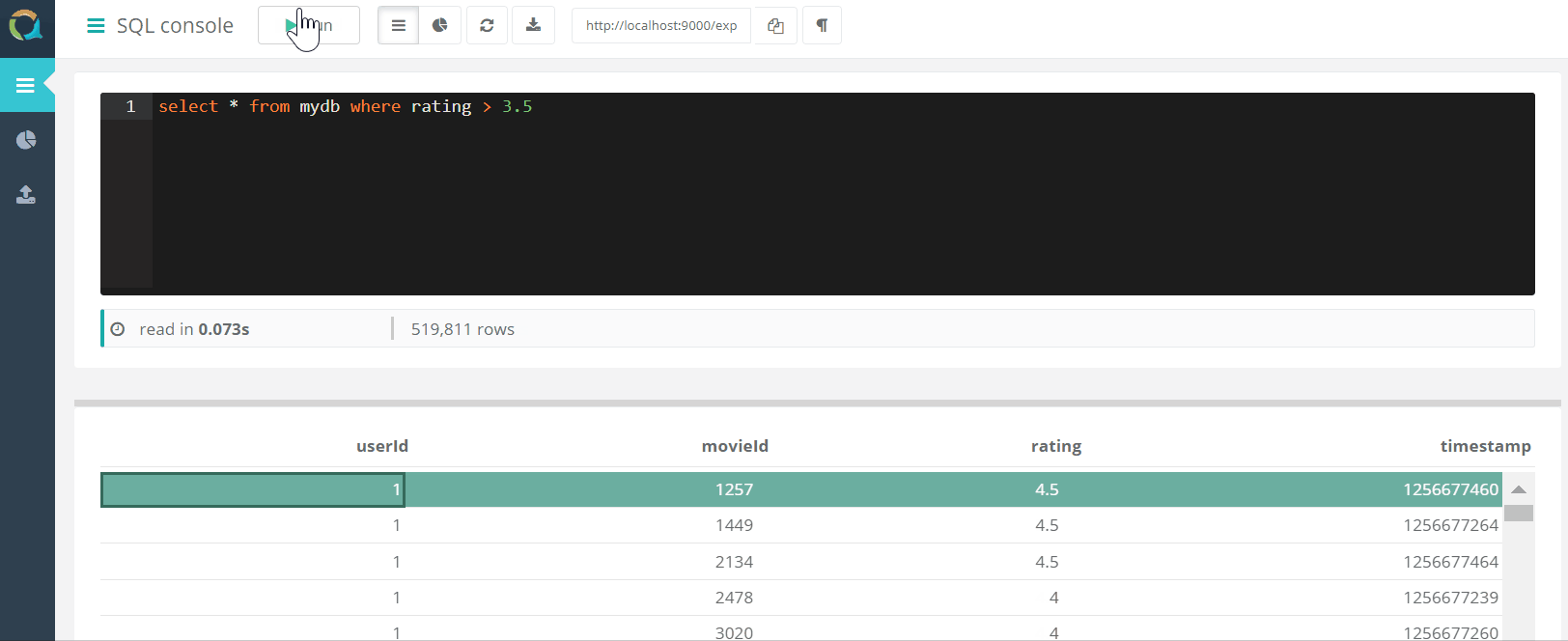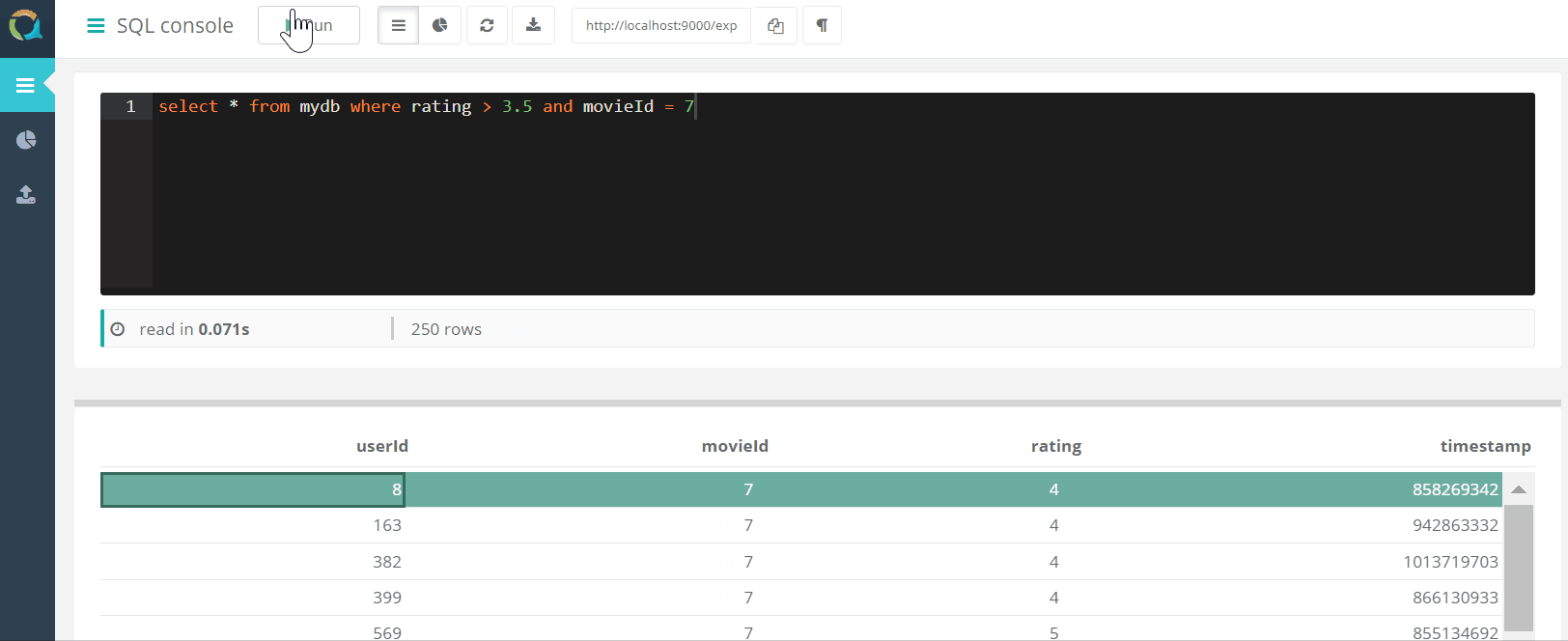 数据通过浏览器以csv格式下载到数据库。
数据通过浏览器以csv格式下载到数据库。
您是否需要另一个数据库?
这个项目还很年轻,仍然缺乏一些公司特征,但是它发展很快,一些贡献者正在积极地从事这个项目。自去年八月以来,我一直在关注QuestDB,并为此项目开发了几个扩展(jdbc函数和osquery),并将该项目与testcontainer集成在一起。现在,我正在尝试使用QuestDB通过增量数据上传,数据分区和对生产中的数据源的冗长事务来解决Dremio中的当前问题,并通过数据导出功能对其进行补充。我计划在以下出版物中分享我的经验。我可以在我熟悉的平台上调试功能和数据库,编写以光速运行的单元测试,这尤其使我受贿。您决定作为经验丰富的开发人员。再一次,QuestDB不能替代OLTP数据库-PostgreSQL,Oracle,MS Sql Server,DB2甚至是H2替代测试在JVM中。这是一个功能强大的专业开源数据库,支持PostgreSQL,Influx / Telegraf网络协议。如果您的使用方案适合其中实现的功能以及使用列数据库的主要方案,那么选择是合理的!