对于那些刚刚开始了解微服务架构和Apache Kafka服务的人来说,本文将是有用的。该材料并不声称是详细的教程,但是可以帮助您快速入门该技术。我将讨论如何在Windows 10上安装和配置Kafka。我们还将使用Intellij IDEA和Spring Boot创建一个项目。做什么的?
开发人员从未遇到过可能需要这些工具的情况,这往往会使人们难以理解各种工具。对于Kafka,这是完全相同的。我们描述了这种技术将有用的情况。如果您具有整体应用程序架构,那么您当然不需要任何Kafka。一切都随着向微服务的过渡而改变。实际上,每个微服务都是执行一个或另一个功能的独立程序,可以独立于其他微服务启动。可以将微服务与办公室中的员工进行比较,后者坐在分开的办公桌旁并独立解决他们的问题。如果没有中央协调,这样一个分散的团队的工作是不可想象的。员工应该能够彼此交换信息和工作结果。用于微服务的Apache Kafka旨在解决此问题。Apache Kafka是一个消息代理。借助它,微服务可以彼此交互,发送和接收重要信息。出现了一个问题,为什么不为此使用常规POST-请求,就可以在其主体中以相同的方式传输必要的数据并获得答案?这种方法有许多明显的缺点。例如,生产者(发送消息的服务)只能响应于消费者(接收数据的服务)的请求以响应的形式发送数据。假设使用者发送了一个POST请求,而生产者回答了该请求。此时,由于某种原因,消费者无法接受答案。数据将如何处理?他们会迷路的。使用者将再次必须发送请求,并希望在此期间他想要接收的数据没有改变,生产者仍准备接受该请求。Apache Kafka解决了在微服务之间交换消息时出现的这个问题和许多其他问题。不能忘记,不中断和方便的数据交换是确保微服务体系结构稳定运行所必须解决的关键问题之一。在Windows 10上安装和配置ZooKeeper和Apache Kafka
首先,您需要知道的第一件事是Apache Kafka在ZooKeeper服务之上运行。 ZooKeeper是一种分布式配置和同步服务,在这种情况下,我们需要了解的一切。在开始使用Kafka之前,我们必须下载,配置和运行它。在开始使用ZooKeeper之前,请确保已安装并配置了JRE。您可以从官方网站下载最新版本的ZooKeeper。我们将文件从下载的ZooKeeper存档中提取到磁盘上的文件夹中。在带有版本号的zookeeper文件夹中,我们找到conf文件夹,并在其中找到文件“ zoo_sample.cfg”。 复制它,并将副本名称更改为“ zoo.cfg”。打开复制文件,然后在其中找到行dataDir = / tmp / zookeeper。在这一行中,我们将完整路径写入到zookeeper-x.x.x文件夹中。对我来说看起来像这样:dataDir = C:\\ ZooKeeper \\ zookeeper-3.6.0
复制它,并将副本名称更改为“ zoo.cfg”。打开复制文件,然后在其中找到行dataDir = / tmp / zookeeper。在这一行中,我们将完整路径写入到zookeeper-x.x.x文件夹中。对我来说看起来像这样:dataDir = C:\\ ZooKeeper \\ zookeeper-3.6.0 现在,我们添加系统环境变量:ZOOKEEPER_HOME = C:\ ZooKeeper \ zookeeper-3.4.9,并在系统变量Path的末尾添加条目:;%ZOOKEEPER_HOME %\ bin;运行命令行并编写命令:
现在,我们添加系统环境变量:ZOOKEEPER_HOME = C:\ ZooKeeper \ zookeeper-3.4.9,并在系统变量Path的末尾添加条目:;%ZOOKEEPER_HOME %\ bin;运行命令行并编写命令:zkserver
如果一切操作正确,您将看到类似以下的内容。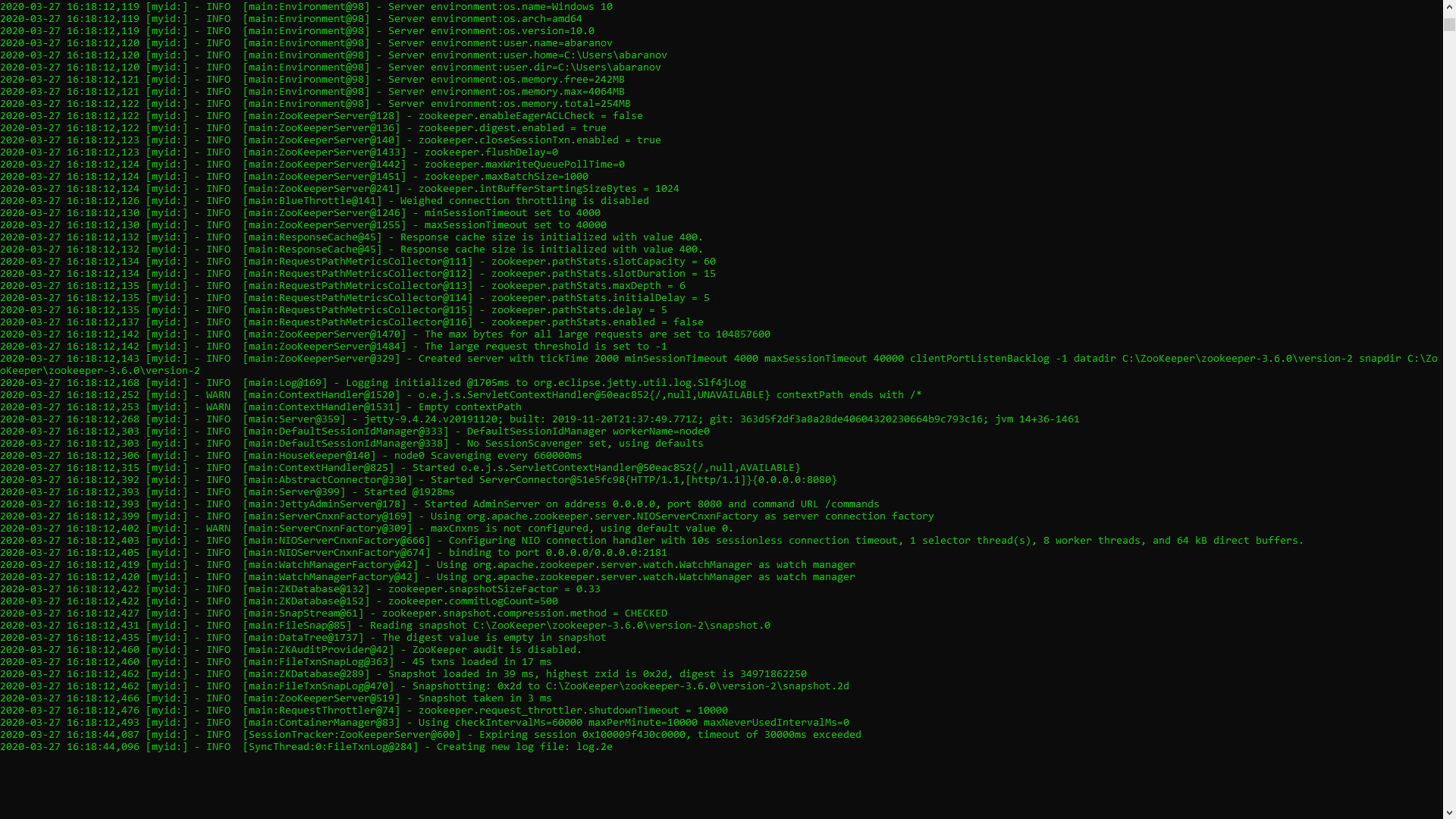 这意味着ZooKeeper正常启动。我们直接进行Apache Kafka服务器的安装和配置。从官方网站下载最新版本并提取存档的内容:kafka.apache.org/downloads在Kafka文件夹中,我们找到config文件夹,在其中找到server.properties文件并打开它。
这意味着ZooKeeper正常启动。我们直接进行Apache Kafka服务器的安装和配置。从官方网站下载最新版本并提取存档的内容:kafka.apache.org/downloads在Kafka文件夹中,我们找到config文件夹,在其中找到server.properties文件并打开它。 我们找到行log.dirs = / tmp / kafka-logs,并在其中指出Kafka将保存日志的路径:log.dirs = c:/ kafka / kafka-logs。
我们找到行log.dirs = / tmp / kafka-logs,并在其中指出Kafka将保存日志的路径:log.dirs = c:/ kafka / kafka-logs。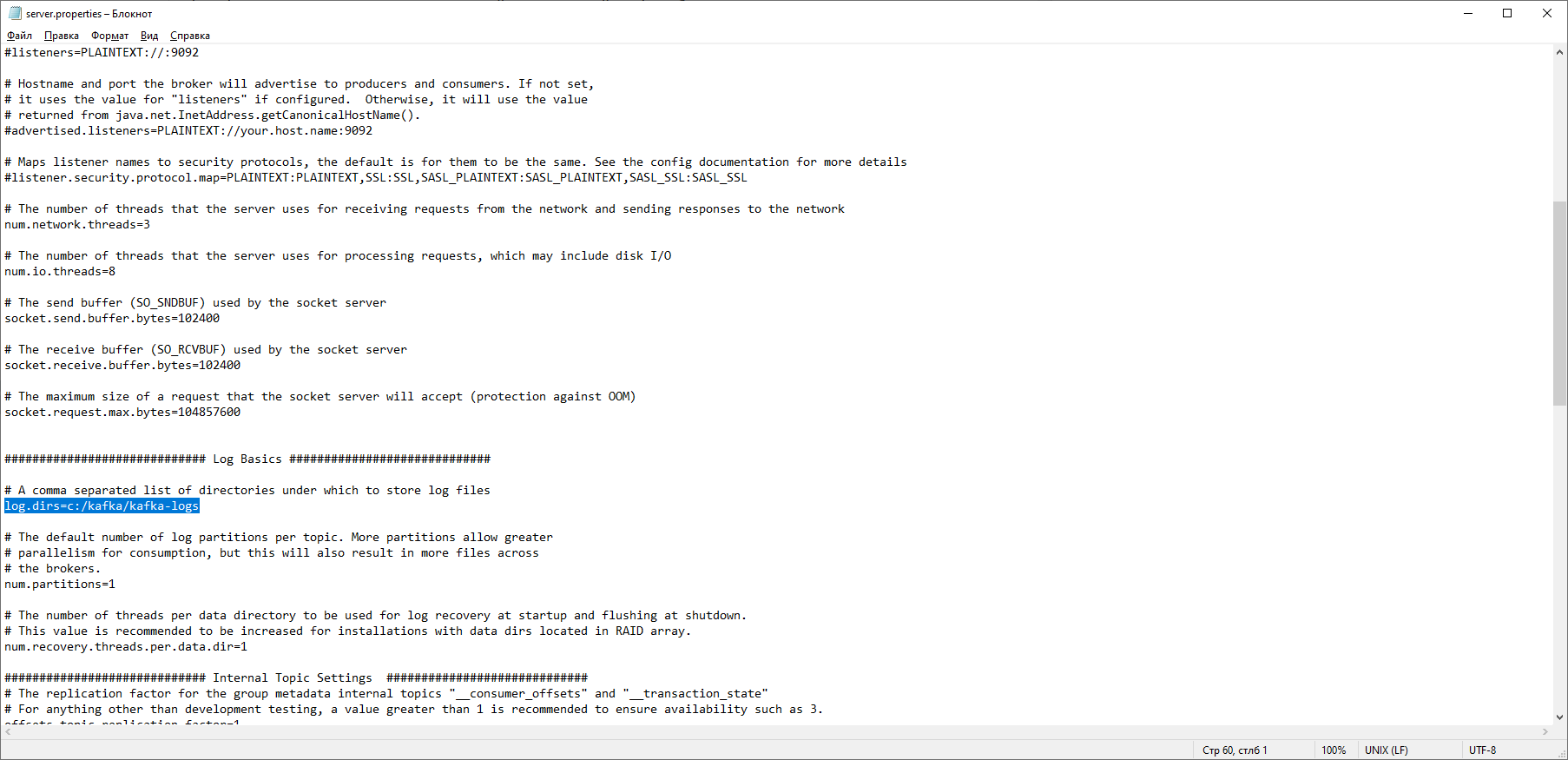 在同一文件夹中,编辑zookeeper.properties文件。我们将行dataDir = / tmp / zookeeper更改为dataDir = c:/ kafka / zookeeper-data,而不会忘记在磁盘名称后指出指向Kafka文件夹的路径。如果一切正确,则可以运行ZooKeeper和Kafka。
在同一文件夹中,编辑zookeeper.properties文件。我们将行dataDir = / tmp / zookeeper更改为dataDir = c:/ kafka / zookeeper-data,而不会忘记在磁盘名称后指出指向Kafka文件夹的路径。如果一切正确,则可以运行ZooKeeper和Kafka。 对于某些人来说,没有GUI来控制Kafka可能令人不快。也许这是因为该服务是专为苛刻的书呆子设计的,专门用于控制台。一种或另一种方式,要运行Kafka,我们需要一个命令行。首先,您需要启动ZooKeeper。在包含kafka的文件夹中,找到bin / windows文件夹,在其中找到启动zookeeper-server-start.bat服务的文件,单击该文件。什么都没发生?应该是这样。打开此文件夹中的控制台,然后输入:
对于某些人来说,没有GUI来控制Kafka可能令人不快。也许这是因为该服务是专为苛刻的书呆子设计的,专门用于控制台。一种或另一种方式,要运行Kafka,我们需要一个命令行。首先,您需要启动ZooKeeper。在包含kafka的文件夹中,找到bin / windows文件夹,在其中找到启动zookeeper-server-start.bat服务的文件,单击该文件。什么都没发生?应该是这样。打开此文件夹中的控制台,然后输入: start zookeeper-server-start.bat
不再工作了吗?这是常态。这是因为zookeeper-server-start.bat需要使用zookeeper.properties文件中指定的参数,正如我们回想的那样,该文件位于config文件夹中以进行工作。我们写到控制台:start zookeeper-server-start.bat c:\kafka\config\zookeeper.properties
现在一切应该正常开始。 再次打开此文件夹中的控制台(不要关闭ZooKeeper!),然后运行kafka:
再次打开此文件夹中的控制台(不要关闭ZooKeeper!),然后运行kafka:start kafka-server-start.bat c:\kafka\config\server.properties
为了不每次都在命令行上编写命令,可以使用旧的行之有效的方法并创建一个具有以下内容的批处理文件:start C:\kafka\bin\windows\zookeeper-server-start.bat C:\kafka\config\zookeeper.properties
timeout 10
start C:\kafka\bin\windows\kafka-server-start.bat C:\kafka\config\server.properties
需要超时10行来设置启动zookeeper和kafka之间的暂停。如果一切正确,单击批处理文件时,将打开两个控制台,分别运行zookeeper和kafka,现在我们可以直接从命令行创建带有必需参数的消息生产者和使用者。但是,实际上,除非测试服务,否则可能需要它。我们将对如何使用IDEA的kafka更加感兴趣。与IDEA的kafka一起使用
我们将编写最简单的应用程序,该应用程序将同时是消息的生产者和使用者,然后向其添加有用的功能。创建一个新的spring项目。最方便的方法是使用弹簧初始化器。添加依赖项org.springframework.kafka和spring-boot-starter-web
 结果,pom.xml文件应如下所示:
结果,pom.xml文件应如下所示: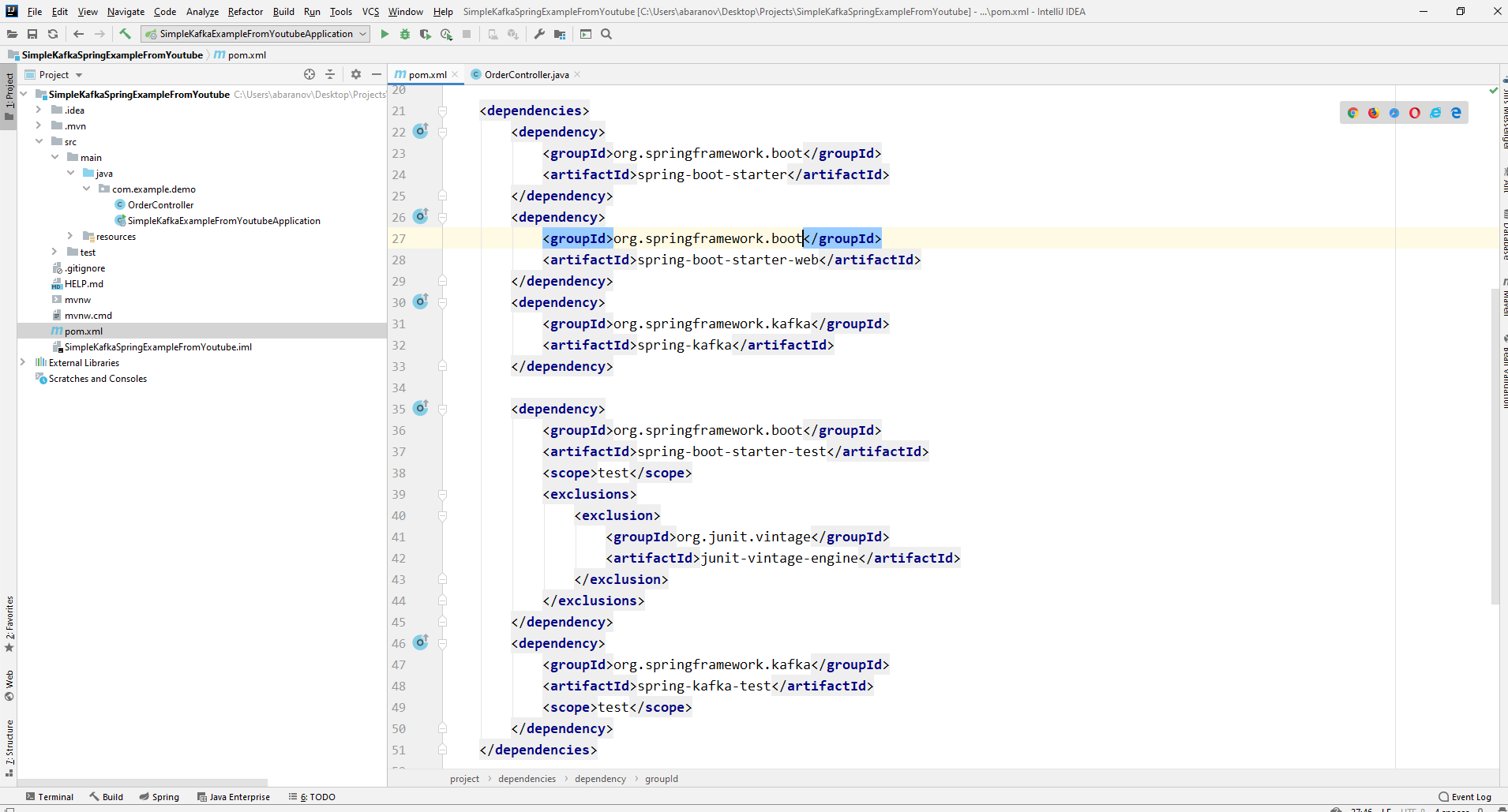 为了发送消息,我们需要KafkaTemplate <K,V>对象。如我们所见,对象已输入。第一个参数是密钥的类型,第二个参数是消息本身。现在,我们将两个参数都表示为String。我们将在类控制器中创建对象。声明KafkaTemplate并要求Spring通过注释对其进行初始化自动接线。
为了发送消息,我们需要KafkaTemplate <K,V>对象。如我们所见,对象已输入。第一个参数是密钥的类型,第二个参数是消息本身。现在,我们将两个参数都表示为String。我们将在类控制器中创建对象。声明KafkaTemplate并要求Spring通过注释对其进行初始化自动接线。@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
原则上,我们的生产者已经准备就绪。剩下要做的就是在其上调用send()方法。此方法有多个重载版本。我们在项目中使用具有3个参数的选项-发送(字符串主题,K键,V数据)。由于KafkaTemplate是用字符串键入的,因此send方法中的键和数据将是字符串。第一个参数指定主题,即消息将发送到的主题,以及消费者可以订阅以接收消息的主题。如果send方法中指定的主题不存在,它将自动创建。完整的类文本如下所示。@RestController
@RequestMapping("msg")
public class MsgController {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@PostMapping
public void sendOrder(String msgId, String msg){
kafkaTemplate.send("msg", msgId, msg);
}
}
控制器映射到本地主机:8080 / msg,密钥和消息本身在请求主体中传输。消息发送者已准备就绪,现在创建一个侦听器。Spring还可以让您轻松完成此操作。创建一个方法并用@KafkaListener批注对其进行标记就足够了,在该批注的参数中,您仅可以指定要收听的主题。在我们的情况下,它看起来像这样。@KafkaListener(topics="msg")
标有注释的方法本身可以指定一个可接受的参数,该参数具有生产者发送的消息类型。将在其中创建使用者的类必须用@EnableKafka批注标记。@EnableKafka
@SpringBootApplication
public class SimpleKafkaExampleApplication {
@KafkaListener(topics="msg")
public void msgListener(String msg){
System.out.println(msg);
}
public static void main(String[] args) {
SpringApplication.run(SimpleKafkaExampleApplication.class, args);
}
}
另外,在application.property设置文件中,您必须指定礼宾参数groupe-id。如果不这样做,该应用程序将无法启动。该参数的类型为String,可以是任何值。spring.kafka.consumer.group-id=app.1
我们最简单的kafka项目已准备就绪。我们有消息的发送者和接收者。它仍然只能运行。首先,使用我们先前编写的批处理文件启动ZooKeeper和Kafka,然后启动我们的应用程序。使用Postman发送请求最方便。在请求的正文中,不要忘记指定参数msgId和msg。 如果我们在IDEA中看到这样的图片,则一切正常:生产者发送了一条消息,消费者收到了该消息并将其显示在控制台上。
如果我们在IDEA中看到这样的图片,则一切正常:生产者发送了一条消息,消费者收到了该消息并将其显示在控制台上。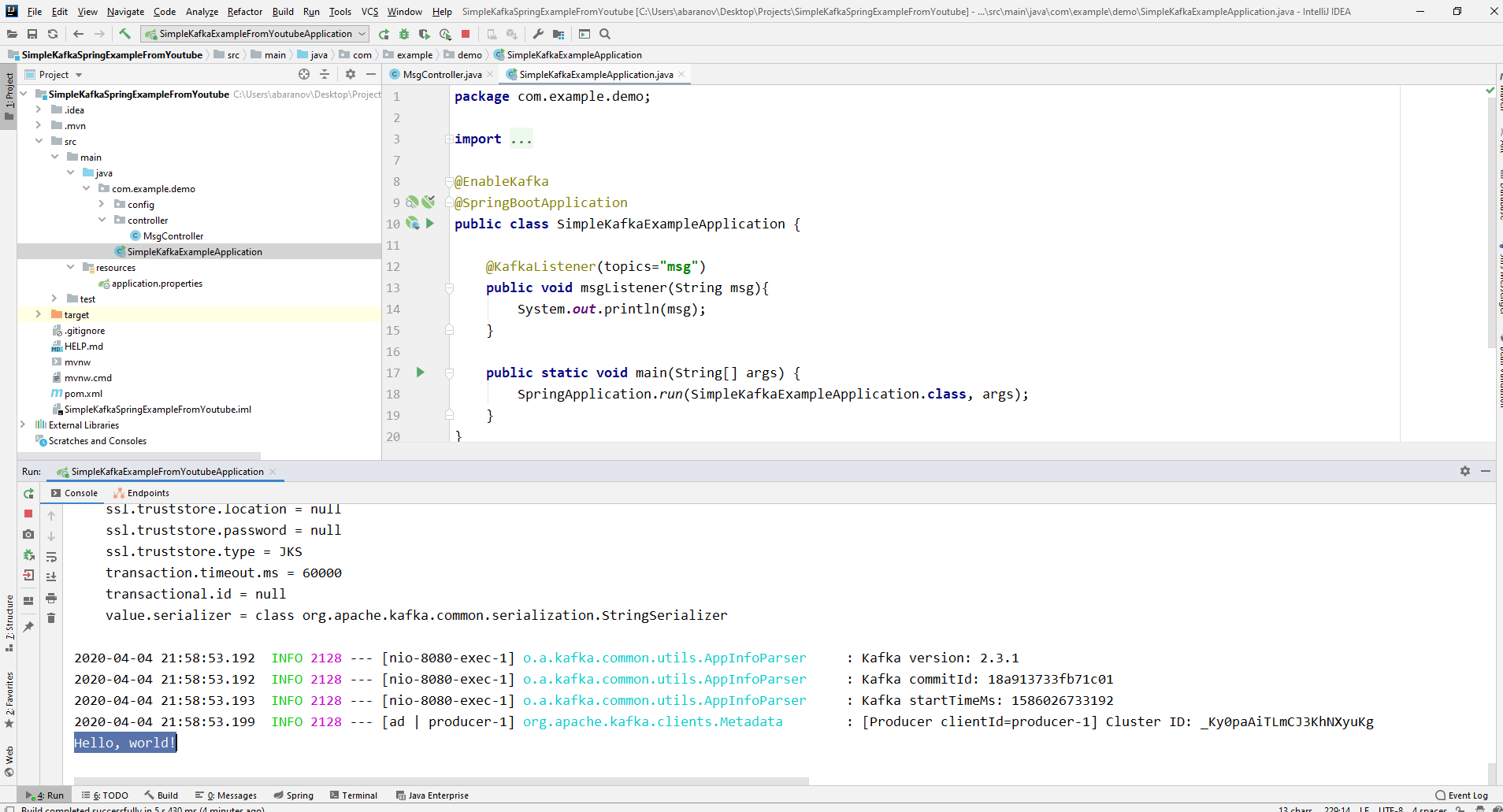
我们使项目复杂化
使用Kafka的实际项目肯定比我们创建的项目复杂。现在我们已经弄清了服务的基本功能,请考虑它提供了哪些附加功能。首先,我们将改善生产者。如果打开send()方法,您可能会注意到其所有变体的返回值均为ListenableFuture <SendResult <K,V >>。现在,我们将不详细考虑此接口的功能。在这里足以说出需要查看发送消息的结果。@PostMapping
public void sendMsg(String msgId, String msg){
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send("msg", msgId, msg);
future.addCallback(System.out::println, System.err::println);
kafkaTemplate.flush();
}
addCallback()方法接受两个参数-SuccessCallback和FailureCallback。它们都是功能接口。从名称中您可以理解,第一个方法将由于成功发送消息而被调用,第二个方法将由于错误而被调用。现在,如果我们运行该项目,我们将在控制台上看到类似以下内容的内容:SendResult [producerRecord=ProducerRecord(topic=msg, partition=null, headers=RecordHeaders(headers = [], isReadOnly = true), key=1, value=Hello, world!, timestamp=null), recordMetadata=msg-0@6]
让我们再次仔细看看我们的制作人。有趣的是,如果密钥不是String,而是Long,但是作为传输的消息,甚至更糟-某种复杂的DTO,会发生什么?首先, 让我们尝试将键更改为数字值... 如果在生产者中将Long指定为键,则应用程序将正常启动,但是当您尝试发送消息时,将抛出ClassCastException并且将报告Long类无法转换为String类。
让我们尝试将键更改为数字值... 如果在生产者中将Long指定为键,则应用程序将正常启动,但是当您尝试发送消息时,将抛出ClassCastException并且将报告Long类无法转换为String类。 如果尝试手动创建KafkaTemplate对象,则会看到ProducerFactory <K,V>接口对象(例如DefaultKafkaProducerFactory <>)作为参数传递给构造函数。为了创建DefaultKafkaProducerFactory,我们需要将包含其生产者设置的Map传递给其构造函数。用于配置和创建生产者的所有代码都将放在单独的类中。为此,请创建配置包,并在其中创建KafkaProducerConfig类。
如果尝试手动创建KafkaTemplate对象,则会看到ProducerFactory <K,V>接口对象(例如DefaultKafkaProducerFactory <>)作为参数传递给构造函数。为了创建DefaultKafkaProducerFactory,我们需要将包含其生产者设置的Map传递给其构造函数。用于配置和创建生产者的所有代码都将放在单独的类中。为此,请创建配置包,并在其中创建KafkaProducerConfig类。@Configuration
public class KafkaProducerConfig {
private String kafkaServer="localhost:9092";
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
kafkaServer);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
LongSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class);
return props;
}
@Bean
public ProducerFactory<Long, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<Long, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
在producerConfigs()方法中,使用配置创建一个映射,并指定LongSerializer.class作为密钥的序列化器。我们开始,发送来自Postman的请求,然后看到一切正常运行:生产者发送消息,而消费者接收消息。现在,让我们更改传输值的类型。如果我们没有Java库中的标准类,而是某种自定义DTO,该怎么办?这么说吧。@Data
public class UserDto {
private Long age;
private String name;
private Address address;
}
@Data
@AllArgsConstructor
public class Address {
private String country;
private String city;
private String street;
private Long homeNumber;
private Long flatNumber;
}
要将DTO作为消息发送,您需要对生产者配置进行一些更改。将JsonSerializer.class指定为消息值的序列化器,并且不要忘记在所有地方都将String类型更改为UserDto。@Configuration
public class KafkaProducerConfig {
private String kafkaServer="localhost:9092";
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
kafkaServer);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
LongSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
JsonSerializer.class);
return props;
}
@Bean
public ProducerFactory<Long, UserDto> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<Long, UserDto> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
发送信息。控制台中将显示以下行: 现在,我们将使使用者复杂化。在此之前,带有注释@KafkaListener(topics =“ msg”)标记的方法public void msgListener(String msg)将String作为参数并将其显示在控制台上。如果我们想获取传输消息的其他参数,例如密钥或分区,该怎么办?在这种情况下,必须更改传输值的类型。
现在,我们将使使用者复杂化。在此之前,带有注释@KafkaListener(topics =“ msg”)标记的方法public void msgListener(String msg)将String作为参数并将其显示在控制台上。如果我们想获取传输消息的其他参数,例如密钥或分区,该怎么办?在这种情况下,必须更改传输值的类型。@KafkaListener(topics="msg")
public void orderListener(ConsumerRecord<Long, UserDto> record){
System.out.println(record.partition());
System.out.println(record.key());
System.out.println(record.value());
}
从ConsumerRecord对象中,我们可以获得我们感兴趣的所有参数。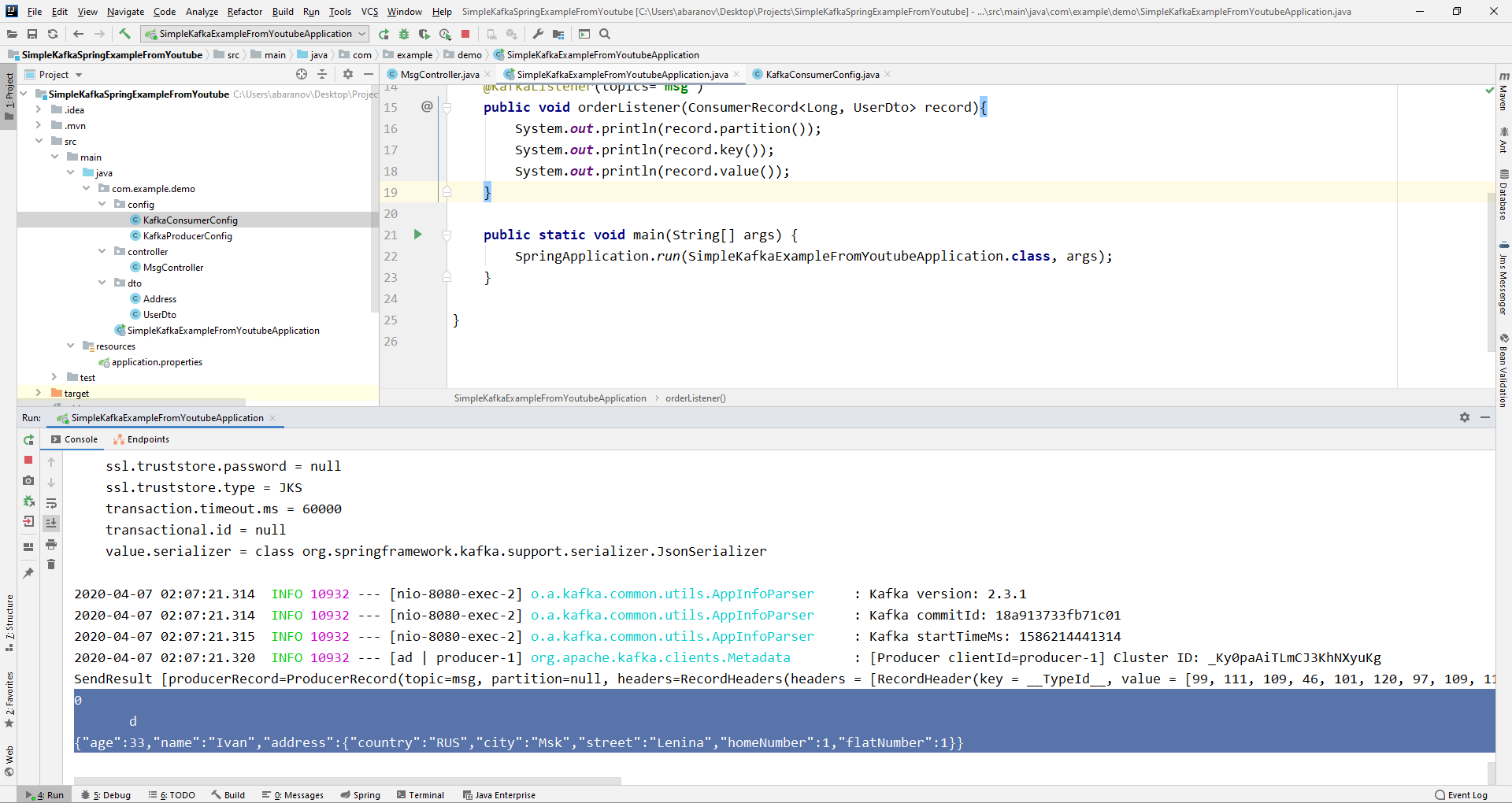 我们看到代替控制台上的键,而是显示了某种krakozyabry。这是因为默认情况下使用StringDeserializer来反序列化键,并且如果我们希望以整数格式正确显示键,则必须将其更改为LongDeserializer。要在config包中配置使用者,请创建KafkaConsumerConfig类。
我们看到代替控制台上的键,而是显示了某种krakozyabry。这是因为默认情况下使用StringDeserializer来反序列化键,并且如果我们希望以整数格式正确显示键,则必须将其更改为LongDeserializer。要在config包中配置使用者,请创建KafkaConsumerConfig类。@Configuration
public class KafkaConsumerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String kafkaServer;
@Value("${spring.kafka.consumer.group-id}")
private String kafkaGroupId;
@Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServer);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.GROUP_ID_CONFIG, kafkaGroupId);
return props;
}
@Bean
public KafkaListenerContainerFactory<?> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<Long, UserDto> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
@Bean
public ConsumerFactory<Long, UserDto> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
}
KafkaConsumerConfig类与我们之前创建的KafkaProducerConfig非常相似。还有一个Map,其中包含必要的配置,例如,键和值的反序列化器。创建的映射用于创建ConsumerFactory <>,而后者又需要用于创建KafkaListenerContainerFactory <?>。一个重要的细节:返回KafkaListenerContainerFactory <?>的方法应称为kafkaListenerContainerFactory(),否则Spring将无法找到所需的bean,并且项目将无法编译。我们开始。 我们看到现在密钥已按原样显示,这意味着一切正常。当然,Apache Kafka的功能远远超出了本文中介绍的功能,但是,我希望阅读后能对这项服务有所了解,最重要的是,您可以开始使用它。多洗手,戴口罩,不要无故外出,保持健康。
我们看到现在密钥已按原样显示,这意味着一切正常。当然,Apache Kafka的功能远远超出了本文中介绍的功能,但是,我希望阅读后能对这项服务有所了解,最重要的是,您可以开始使用它。多洗手,戴口罩,不要无故外出,保持健康。