在用Python编写应用程序时,对象关系映射器(ORM)通常用于处理数据库。ORM的示例包括SQLALchemy,PonyORM和Django随附的对象关系映射器。选择ORM时,其性能起着相当重要的作用。
在Habr以及整个Internet上,可能找不到一项性能测试。作为高质量python ORM基准的示例,您可以使用Tortoise ORM基准(指向存储库的链接)。此基准分析了针对11种不同类型的SQL查询的六个ORM的速度。
通常,乌龟基准测试可以在使用不同的ORM时评估查询执行的速度,但是我发现这种测试方法存在一个问题。ORM通常用在Web应用程序中,其中几个用户可以同时发送不同的请求,但是我还没有找到一个单一的基准来评估在这种情况下ORM的性能。结果,我决定编写我的基准,并将其与PonyORM和SQLAlchemy进行比较。作为基础,我采用了TPC-C基准。
自1988年以来,TPC公司就开发了针对数据处理的测试。它们早已成为行业标准,几乎所有设备供应商都在各种硬件和软件样本上使用它们。这些测试的主要特征是它们旨在在尽可能接近真实条件的巨大负载下进行测试。
TPC-C模拟仓库网络。它包括五个同时执行的各种类型和复杂性的事务的组合。该数据库由具有大量记录的九个表组成。TPC-C测试中的性能以每分钟的交易数衡量。
我决定使用适用于此任务的TPC-C测试方法测试两个Python ORM(SQLALchemy和PonyORM)。该测试的目的是评估多个虚拟用户同时访问数据库时事务处理的速度。
测试说明
在我编写的测试中,首先创建并填充了一个数据库,它是一个仓库网络的数据库。数据库模式如下所示: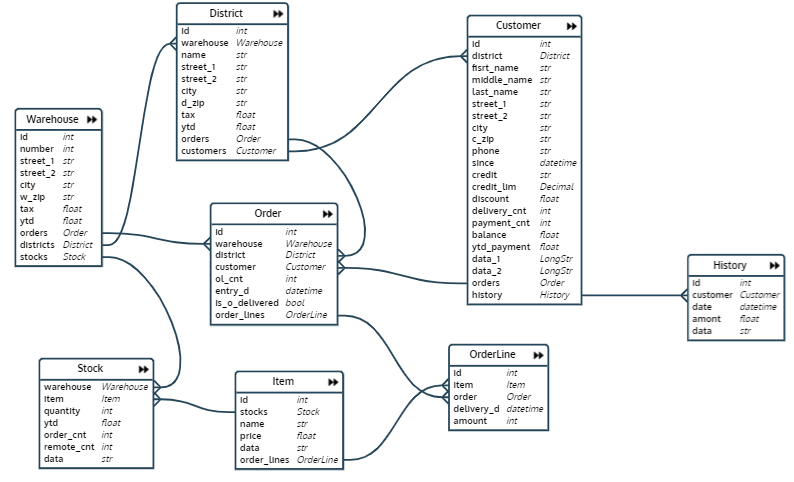
该数据库包含八个关系:
- 仓库-仓库
- 区-仓库面积
- 订购-订购
- OrderLine-订单行(订单项)
- 库存-特定仓库中某种产品的数量
- 项目-项目
- 客户-客户
- 历史记录-客户付款历史记录
, e . . , :
- new_order ( ) — 45%
- payment ( ) — 43%
- order_status ( ) — 4%
- delivery ( ) — 4%
- stock_level ( ) — 4%
, TPC-C.
TPC-C , , ORM, . 64+ , .
:
- ,
- . : Stock 100 000 * W, W — , : 100 * W
- 5 . Payment ID, . ID,
- NewOrder. , , Order, NewOrder. , NewOrder. , , , , , . Order bool “is_o_delivered”, False, ,
, .
New Order
- : id id
- id
- ()
- . Item.
- , .
Payment
- : id id
- id
- .
- 1
- , ,
- .
订单状态
- 客户ID服务的交易
- 客户和他的最后订单来自数据库
- 状态取自订单(已交付或未交付)和订单项目
交货
- 仓库编号服务的交易
- 通过ID及其所有部分从数据库中请求仓库
- 对于每个站点,均采用最旧的未交付订单。在每一个中,交付状态都更改为True
- 从数据库中获取在此交易期间已下达订单的用户,他们每个人都增加了交付计数器
库存水平
- 仓库编号服务的交易
- 通过ID从数据库请求仓库
- 从数据库请求该仓库的最后20个订单
- 对于数据库中这些订单的每一项,都要求仓库中剩余货物的数量
试验结果
两个ORM参与测试:- SQL炼金术 曲线用蓝线表示。
- PonyORM。这些图用黄线表示。
10 2 , . multiprocessing.
—
—
PostgreSQL
, TPC-C. Pony .

:
Pony — 2543 /
SQLAlchemy — 1353.4 /
ORM . .
“New Order”

平均速度:
小马-3349.2转/分钟
SQLAlchemy-1415.3转/分钟
交易“付款”
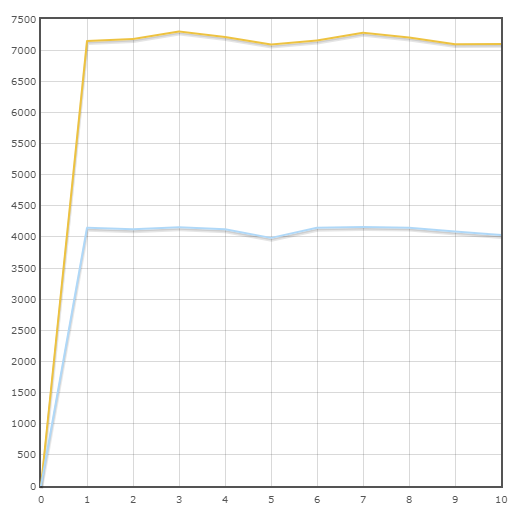
平均速度:
小马-7175.3转/分钟
SQLAlchemy-4110.6转/分钟
交易“订单状态”
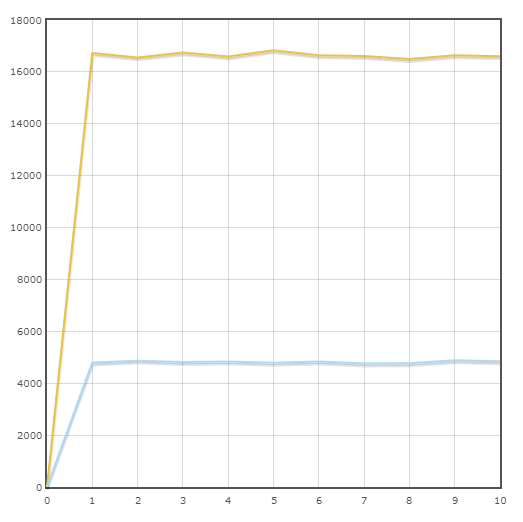
平均速度:
小马-16645.6 Trans / min
SQLAlchemy-4820.8 trans / min
交易“交付”
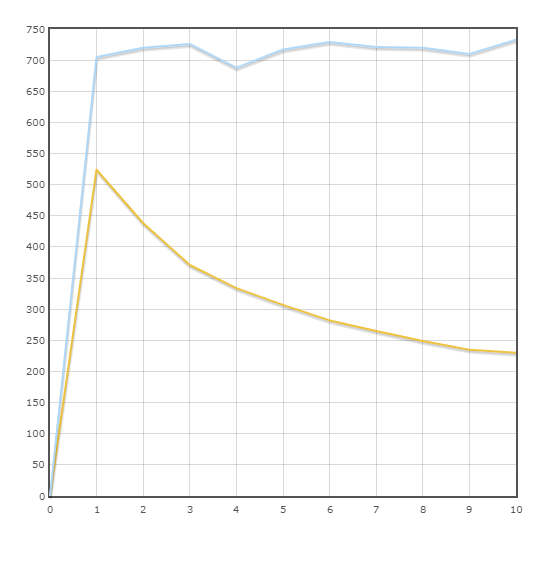
平均速度:
SQLAlchemy-716.9 trans / min
小马-323.5 trans / min
交易“库存水平”
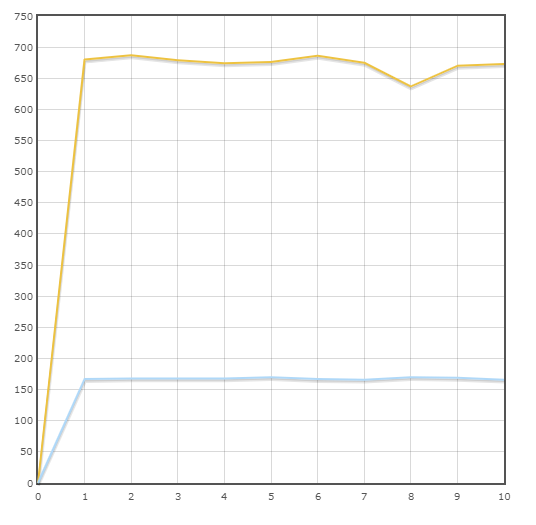
平均速度:
小马-677.3次/分
SQLAlchemy-167.9次/分
测试结果分析
收到结果后,我分析了为什么在各种情况下一个ORM比另一个ORM更快,并得出以下结论:4 5 PonyORM , , SQL PonyORM Python SQL, , SQLALchemy SQL . PonyORM:
stocks = select(stock for stock in Stock
if stock.warehouse == whouse
and stock.item in items).order_by(Stock.id).for_update()
SQLAlchemy:
stocks = session.query(Stock).filter(
Stock.warehouse == whouse, Stock.item.in_(items)).order_by(text("id")).with_for_update()
SQLAlchemy Delivery , UPDATE, , .
, SQLAlchemy:
INFO:sqlalchemy.engine.base.Engine:UPDATE order_line SET delivery_d=%(delivery_d)s WHERE order_line.id = %(order_line_id)s
INFO:sqlalchemy.engine.base.Engine:(
{'delivery_d': datetime.datetime(2020, 4, 6, 14, 33, 6, 922281), 'order_line_id': 316},
{'delivery_d': datetime.datetime(2020, 4, 6, 14, 33, 6, 922272), 'order_line_id': 317},
{'delivery_d': datetime.datetime(2020, 4, 6, 14, 33, 6, 922261))
Pony Update:
SELECT "id", "delivery_d", "item", "amount", "order"
FROM "orderline"
WHERE "order" = %(p1)s
{'p1':911}
UPDATE "orderline"
SET "delivery_d" = %(p1)s
WHERE "id" = %(p2)s
AND "order" = %(p3)s
{'p1':datetime.datetime(2020, 4, 7, 17, 48, 58, 585932), 'p2':5047, 'p3':911}
UPDATE "orderline"
SET "delivery_d" = %(p1)s
WHERE "id" = %(p2)s
AND "order" = %(p3)s
{'p1':datetime.datetime(2020, 4, 7, 17, 48, 58, 585990), 'p2':5048, 'p3':911}
根据测试的结果,我可以说Pony从数据库中获取时要快得多,在某些情况下,SQLAlchemy可以产生更快的Update查询。将来,我计划以这种方式测试其他ORM(Peewee,Django)。
参考文献
测试代码:
SQLAlchemy 存储库链接
:文档,社区
Pony:文档,社区