在普遍自我隔离的背景下进行远程操作会导致非常严重的后果。和情感倦怠-不管走到哪里,它毕竟离屋顶都不远。在这方面,他和许多人一样,试图通过分配时间安排其他课程来“镇定”自己,并开始将最有趣的文章从英语翻译成俄语:“您将机器学习带给大众!”。如果您对俄语读者有关于语义内容和此文本翻译的建议,请参加讨论。 因此,这是来自tensorflow手册部分的时间序列预测页面的翻译:link。我所添加的内容以及翻译插图旨在帮助理解ML和计量经济学中最有趣的领域之一,即预测时间序列。翻译前的小介绍。该手册是对基于一维时间序列(单变量时间序列)和多元时间序列(多变量时间序列)的气温预测的描述。对于每个部分,输入数据应该做相应的准备。考虑到本指南中考虑的气象数据集,分离如下所示:
因此,这是来自tensorflow手册部分的时间序列预测页面的翻译:link。我所添加的内容以及翻译插图旨在帮助理解ML和计量经济学中最有趣的领域之一,即预测时间序列。翻译前的小介绍。该手册是对基于一维时间序列(单变量时间序列)和多元时间序列(多变量时间序列)的气温预测的描述。对于每个部分,输入数据应该做相应的准备。考虑到本指南中考虑的气象数据集,分离如下所示: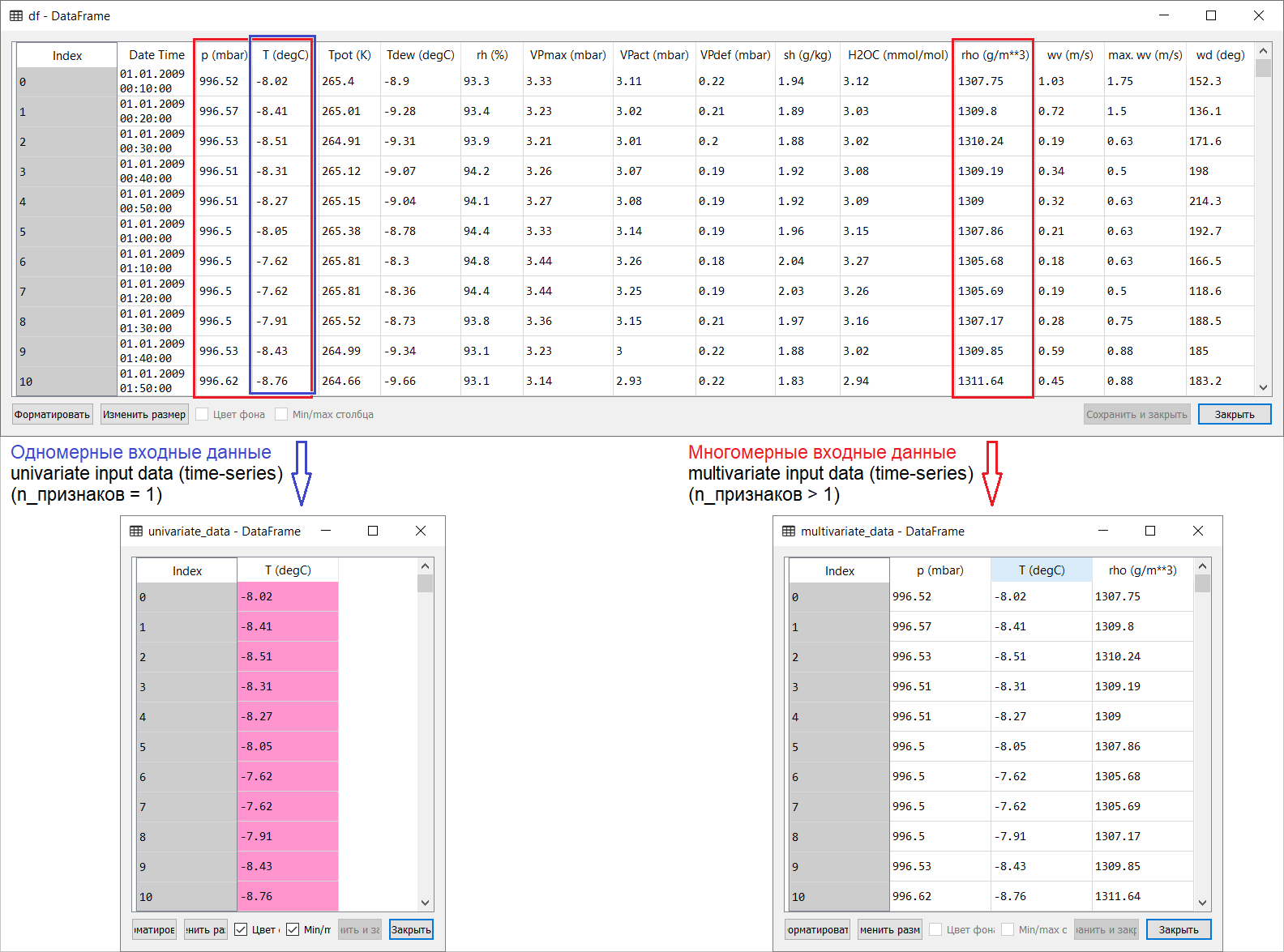 对于有关X取什么和Y取什么的问题,即如何为有监督训练的课程准备数据的问题,从以下插图中将显而易见。我只注意到用于一维和多维时间序列的目标向量(Y)的形成是相同的:目标向量是根据符号T(degC)进行编译的(气温)。它们之间的差异被“埋没”在形成一组输入到模型输入的特征中:对于预测未来温度的一维时间序列,输入矢量(X)包含一个特征:实际上是气温;并且对于多维-大于一个:除了空气温度外,在本指南的示例中还使用p(mbar)(大气压)和rho(g / m ** 3)(湿度)。首先,从使用多维输入的角度来看,一个温度预测的例子看起来很浅,令人信服:对于温度预测,最相关的符号是温度。但是,绝对不是这样:为了对空气温度进行定性预测,必须考虑许多因素,包括地球表面的空气摩擦等。另外,在实践中,有些事情远非显而易见,目标向量可能是大杂烩(或罗宋汤)的形式。在这方面,探索性的数据分析以及为后续形成多维输入而选择最相关的特征是唯一正确的决定。因此,下面介绍了手册的翻译。附加文本将以斜体显示。
对于有关X取什么和Y取什么的问题,即如何为有监督训练的课程准备数据的问题,从以下插图中将显而易见。我只注意到用于一维和多维时间序列的目标向量(Y)的形成是相同的:目标向量是根据符号T(degC)进行编译的(气温)。它们之间的差异被“埋没”在形成一组输入到模型输入的特征中:对于预测未来温度的一维时间序列,输入矢量(X)包含一个特征:实际上是气温;并且对于多维-大于一个:除了空气温度外,在本指南的示例中还使用p(mbar)(大气压)和rho(g / m ** 3)(湿度)。首先,从使用多维输入的角度来看,一个温度预测的例子看起来很浅,令人信服:对于温度预测,最相关的符号是温度。但是,绝对不是这样:为了对空气温度进行定性预测,必须考虑许多因素,包括地球表面的空气摩擦等。另外,在实践中,有些事情远非显而易见,目标向量可能是大杂烩(或罗宋汤)的形式。在这方面,探索性的数据分析以及为后续形成多维输入而选择最相关的特征是唯一正确的决定。因此,下面介绍了手册的翻译。附加文本将以斜体显示。时间序列预测
本指南是使用递归神经网络(RNS,来自英语递归神经网络,RNN)的时间序列预测的简介。它由两部分组成:第一部分描述基于一维时间序列的气温预测,第二部分基于多维时间序列。import tensorflow as tf
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
mpl.rcParams['figure.figsize'] = (8, 6)
mpl.rcParams['axes.grid'] = False
一组气象数据在生物地球化学研究所的水文气象台上记录的人工使用的气象数据时间序列的所有示例均以 马克斯·普朗克。此数据集包括自2003年以来每10分钟进行的14种不同气象指标的测量(例如气温,大气压,湿度)。为了节省时间和内存使用量,本手册将使用2009年至2016年的数据。数据集的这一部分是由FrançoisChollet为他的书《Python深度学习》准备的。zip_path = tf.keras.utils.get_file(
origin='https://storage.googleapis.com/tensorflow/tf-keras-datasets/jena_climate_2009_2016.csv.zip',
fname='jena_climate_2009_2016.csv.zip',
extract=True)
csv_path, _ = os.path.splitext(zip_path)
df = pd.read_csv(csv_path)
让我们看看我们有什么。df.head()
 观察记录周期为10分钟的事实可以通过上表验证。因此,在一小时内您将获得6个观测值。反过来,每天会收集144个(6x24)观测值。假设您要预测温度,该温度将在未来6小时内出现。您根据一定时期内的数据进行此预测:例如,您决定使用5天的观察时间。因此,要训练模型,必须创建一个包含最后720个(5x144)观测值的时间间隔(由于可能有不同的配置,因此该数据集是进行实验的良好基础)。下面的函数返回上述训练模型的时间间隔。争论
观察记录周期为10分钟的事实可以通过上表验证。因此,在一小时内您将获得6个观测值。反过来,每天会收集144个(6x24)观测值。假设您要预测温度,该温度将在未来6小时内出现。您根据一定时期内的数据进行此预测:例如,您决定使用5天的观察时间。因此,要训练模型,必须创建一个包含最后720个(5x144)观测值的时间间隔(由于可能有不同的配置,因此该数据集是进行实验的良好基础)。下面的函数返回上述训练模型的时间间隔。争论history_size-这是最后一个时间间隔的大小,target_size-一个参数,确定模型应该学会预测的未来时间。换句话说,target_size是需要预测的目标向量。def univariate_data(dataset, start_index, end_index, history_size, target_size):
data = []
labels = []
start_index = start_index + history_size
if end_index is None:
end_index = len(dataset) - target_size
for i in range(start_index, end_index):
indices = range(i-history_size, i)
data.append(np.reshape(dataset[indices], (history_size, 1)))
labels.append(dataset[i+target_size])
return np.array(data), np.array(labels)
在本手册的两个部分中,前300,000行数据都将用于训练模型,其余的行将用于验证(验证)模型。在这种情况下,培训数据量约为2100天。TRAIN_SPLIT = 300000
为确保结果可重复,设置了种子功能。tf.random.set_seed(13)
第1部分。基于一维时间序列的预测
在第一部分中,您将仅使用一个属性(温度)训练模型。经过训练的模型将用于预测未来的温度。首先,我们仅从数据集中提取温度。uni_data = df['T (degC)']
uni_data.index = df['Date Time']
uni_data.head()
Date Time
01.01.2009 00:10:00 -8.02
01.01.2009 00:20:00 -8.41
01.01.2009 00:30:00 -8.51
01.01.2009 00:40:00 -8.31
01.01.2009 00:50:00 -8.27
Name: T (degC), dtype: float64
让我们看看这些数据如何随时间变化。uni_data.plot(subplots=True)

uni_data = uni_data.values
在训练人工神经网络(以下简称ANN)之前,重要的一步是数据缩放。进行缩放的常见方法之一是标准化(standardization),方法是减去平均值并除以每个特性的标准偏差。您也可以使用将tf.keras.utils.normalize值缩放到[0,1]范围的方法。注意:只能使用培训数据进行标准化。uni_train_mean = uni_data[:TRAIN_SPLIT].mean()
uni_train_std = uni_data[:TRAIN_SPLIT].std()
我们执行数据标准化。uni_data = (uni_data-uni_train_mean)/uni_train_std
接下来,使用一维输入为模型准备数据。记录的最后20个温度观测值将输入到模型的入口,并且必须训练模型以预测下一步的温度。univariate_past_history = 20
univariate_future_target = 0
x_train_uni, y_train_uni = univariate_data(uni_data, 0, TRAIN_SPLIT,
univariate_past_history,
univariate_future_target)
x_val_uni, y_val_uni = univariate_data(uni_data, TRAIN_SPLIT, None,
univariate_past_history,
univariate_future_target)
函数应用的结果univariate_data。print ('Single window of past history')
print (x_train_uni[0])
print ('\n Target temperature to predict')
print (y_train_uni[0])
Single window of past history
[[-1.99766294]
[-2.04281897]
[-2.05439744]
[-2.0312405 ]
[-2.02660912]
[-2.00113649]
[-1.95134907]
[-1.95134907]
[-1.98492663]
[-2.04513467]
[-2.08334362]
[-2.09723778]
[-2.09376424]
[-2.09144854]
[-2.07176515]
[-2.07176515]
[-2.07639653]
[-2.08913285]
[-2.09260639]
[-2.10418486]]
Target temperature to predict
-2.1041848598100876
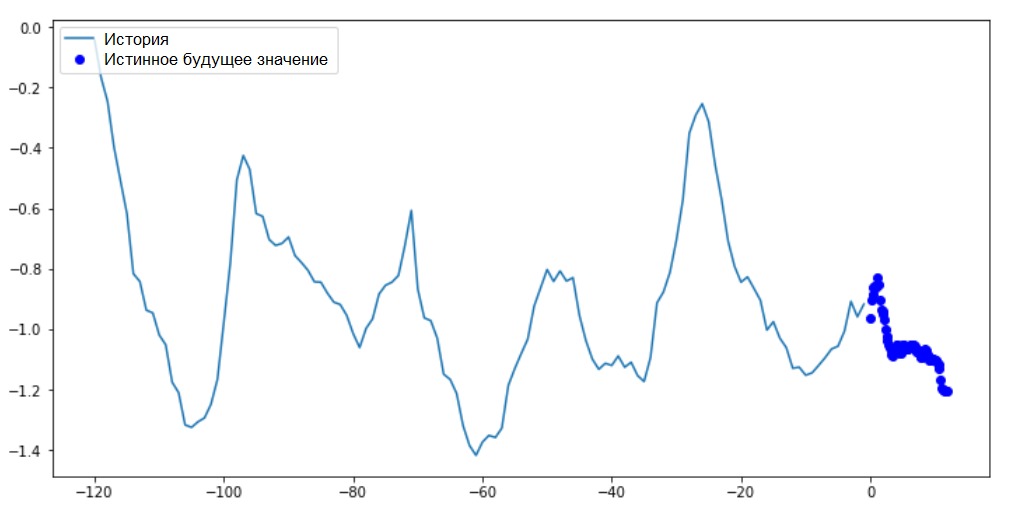
另外:下图示意性地显示了为具有一维输入的模型准备数据(为方便起见,在此图和后续图中,数据在标准化之前以“原始”形式显示,并且也没有“日期时间”属性作为索引): 现在,数据经过适当准备,请考虑一个具体示例。传输到ANN的信息以蓝色突出显示,红叉表示ANN应该预测的未来值。
现在,数据经过适当准备,请考虑一个具体示例。传输到ANN的信息以蓝色突出显示,红叉表示ANN应该预测的未来值。def create_time_steps(length):
return list(range(-length, 0))
def show_plot(plot_data, delta, title):
labels = ['History', 'True Future', 'Model Prediction']
marker = ['.-', 'rx', 'go']
time_steps = create_time_steps(plot_data[0].shape[0])
if delta:
future = delta
else:
future = 0
plt.title(title)
for i, x in enumerate(plot_data):
if i:
plt.plot(future, plot_data[i], marker[i], markersize=10,
label=labels[i])
else:
plt.plot(time_steps, plot_data[i].flatten(), marker[i], label=labels[i])
plt.legend()
plt.xlim([time_steps[0], (future+5)*2])
plt.xlabel('Time-Step')
return plt
show_plot([x_train_uni[0], y_train_uni[0]], 0, 'Sample Example')
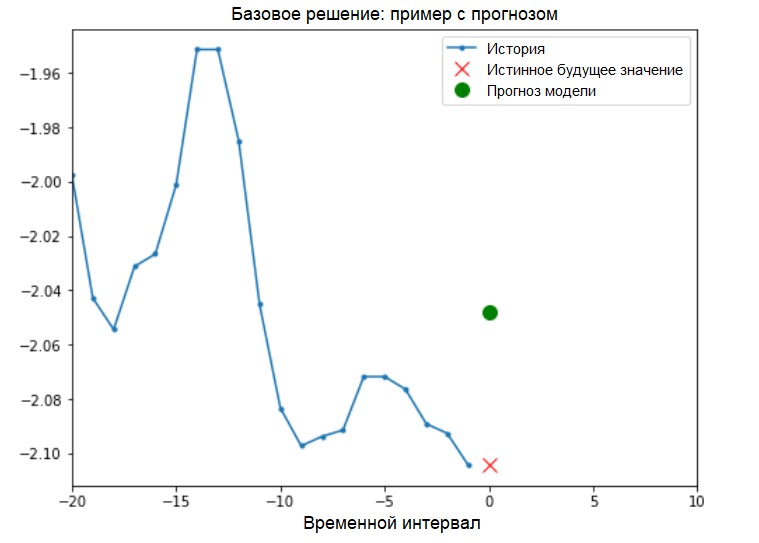
 基本解决方案(不涉及机器学习)在开始模型训练之前,我们将安装一个简单的基本解决方案(基线)。它包含以下内容:对于给定的输入向量,基本求解方法“扫描”整个历史记录,并预测下一个值作为最后20个观察值的平均值。
基本解决方案(不涉及机器学习)在开始模型训练之前,我们将安装一个简单的基本解决方案(基线)。它包含以下内容:对于给定的输入向量,基本求解方法“扫描”整个历史记录,并预测下一个值作为最后20个观察值的平均值。def baseline(history):
return np.mean(history)
show_plot([x_train_uni[0], y_train_uni[0], baseline(x_train_uni[0])], 0,
'Baseline Prediction Example')
 让我们看看是否可以使用递归神经网络超越“平均”的结果。递归神经网络递归神经网络(RNS)是一种非常适合解决时间序列问题的ANN。 RNS逐步处理数据的时间序列,对数据元素进行排序,并保留通过处理之前的元素而获得的内部状态。您可以在以下指南中找到有关RNS的更多信息。本指南将使用称为长期短时记忆(LSTM)的RNC专门层。进一步使用
让我们看看是否可以使用递归神经网络超越“平均”的结果。递归神经网络递归神经网络(RNS)是一种非常适合解决时间序列问题的ANN。 RNS逐步处理数据的时间序列,对数据元素进行排序,并保留通过处理之前的元素而获得的内部状态。您可以在以下指南中找到有关RNS的更多信息。本指南将使用称为长期短时记忆(LSTM)的RNC专门层。进一步使用tf.data随机播放,批处理和缓存数据集。补充:
更多关于tensorflow页面上的随机,批处理和缓存方法:BATCH_SIZE = 256
BUFFER_SIZE = 10000
train_univariate = tf.data.Dataset.from_tensor_slices((x_train_uni, y_train_uni))
train_univariate = train_univariate.cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE).repeat()
val_univariate = tf.data.Dataset.from_tensor_slices((x_val_uni, y_val_uni))
val_univariate = val_univariate.batch(BATCH_SIZE).repeat()
以下可视化效果应帮助您了解批处理后数据的外观。 可以看出,LSTM需要某种形式的数据输入,并提供给它。
可以看出,LSTM需要某种形式的数据输入,并提供给它。simple_lstm_model = tf.keras.models.Sequential([
tf.keras.layers.LSTM(8, input_shape=x_train_uni.shape[-2:]),
tf.keras.layers.Dense(1)
])
simple_lstm_model.compile(optimizer='adam', loss='mae')
检查模型输出。for x, y in val_univariate.take(1):
print(simple_lstm_model.predict(x).shape)
(256, 1)
另外:
一般来说,RNS与序列一起使用。这意味着提供给模型输入的数据应具有以下形式:
[, , - ]
具有一维输入的模型的训练数据的形式应具有以下形式:print(x_train_uni.shape)
(299980, 20, 1)接下来,我们将研究模型。由于数据集很大,并且为了节省时间,每个历元将仅执行200步(steps_per_epoch = 200),而不是通常的完整训练数据。EVALUATION_INTERVAL = 200
EPOCHS = 10
simple_lstm_model.fit(train_univariate, epochs=EPOCHS,
steps_per_epoch=EVALUATION_INTERVAL,
validation_data=val_univariate, validation_steps=50)
Train for 200 steps, validate for 50 steps
Epoch 1/10
200/200 [==============================] - 2s 11ms/step - loss: 0.4075 - val_loss: 0.1351
Epoch 2/10
200/200 [==============================] - 1s 4ms/step - loss: 0.1118 - val_loss: 0.0360
Epoch 3/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0490 - val_loss: 0.0289
Epoch 4/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0444 - val_loss: 0.0257
Epoch 5/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0299 - val_loss: 0.0235
Epoch 6/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0317 - val_loss: 0.0224
Epoch 7/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0287 - val_loss: 0.0206
Epoch 8/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0263 - val_loss: 0.0200
Epoch 9/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0254 - val_loss: 0.0182
Epoch 10/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0228 - val_loss: 0.0174
使用简单的LSTM模型进行预测在完成简单的LSTM模型准备之后,我们将进行一些预测。for x, y in val_univariate.take(3):
plot = show_plot([x[0].numpy(), y[0].numpy(),
simple_lstm_model.predict(x)[0]], 0, 'Simple LSTM model')
plot.show()
 它看起来比基本水平更好。现在您已经熟悉了基础知识,让我们继续第二部分,它描述了使用多维时间序列。
它看起来比基本水平更好。现在您已经熟悉了基础知识,让我们继续第二部分,它描述了使用多维时间序列。第2部分:多维时间序列预测
如前所述,原始数据集包含14种不同的气象指标。为了简单和方便起见,在第二部分中仅考虑了其中三个-空气温度,大气压和空气密度。要使用更多功能,必须将其名称添加到feature_considered列表中。features_considered = ['p (mbar)', 'T (degC)', 'rho (g/m**3)']
features = df[features_considered]
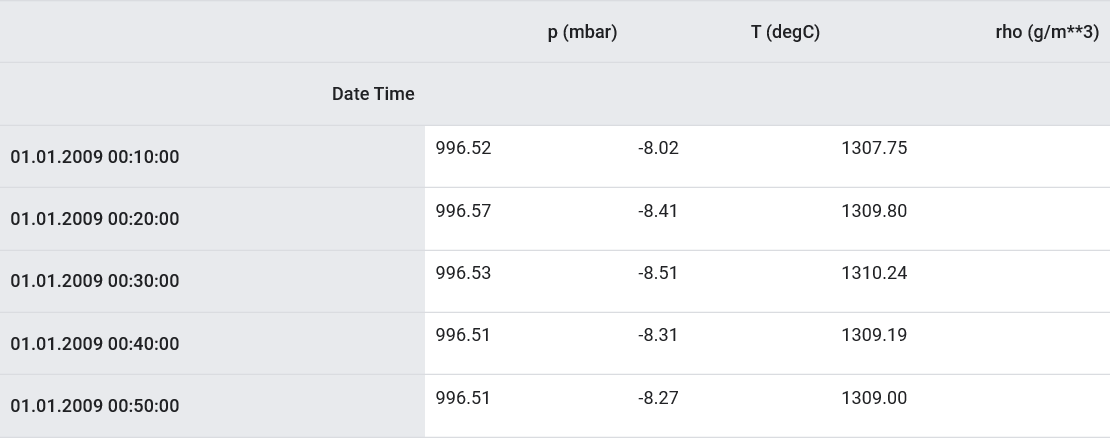
features.index = df['Date Time']
features.head()
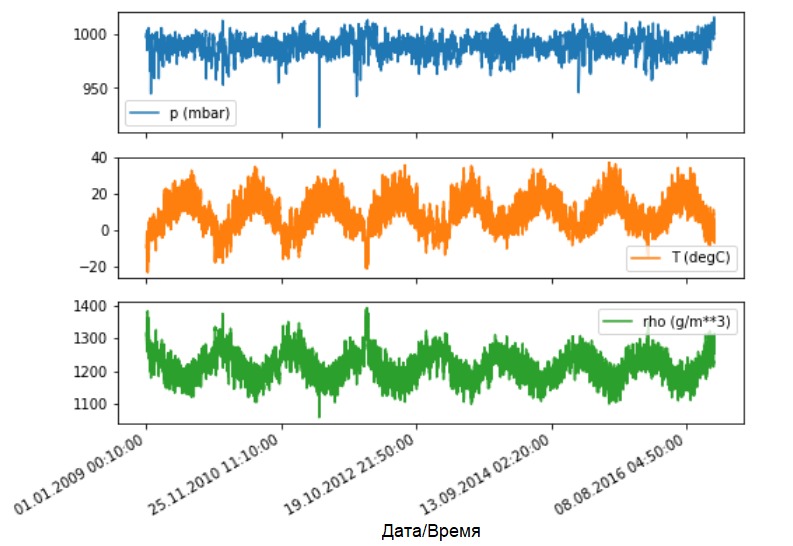
 让我们看看这些指标如何随时间变化。
让我们看看这些指标如何随时间变化。features.plot(subplots=True)
 和以前一样,第一步是通过计算训练数据的平均值和标准偏差来标准化数据集。
和以前一样,第一步是通过计算训练数据的平均值和标准偏差来标准化数据集。dataset = features.values
data_mean = dataset[:TRAIN_SPLIT].mean(axis=0)
data_std = dataset[:TRAIN_SPLIT].std(axis=0)
dataset = (dataset-data_mean)/data_std
另外:
在手册中,我们将进一步讨论点和区间预测。
底线如下。如果您需要模型来预测将来的一个值(例如,12小时后的温度值)(单步/单步模型),则必须对模型进行训练,使其将来只能预测一个值。如果任务是预测未来的值范围(例如未来12小时的每小时温度)(多步模型),则还应训练该模型以预测将来的值范围。 点预测在这种情况下,训练模型基于一些可用历史记录来预测将来的一个值。下面的函数执行组织时间间隔的相同任务,所不同的是,这里的函数基于给定的步长选择最新的观测值。
点预测在这种情况下,训练模型基于一些可用历史记录来预测将来的一个值。下面的函数执行组织时间间隔的相同任务,所不同的是,这里的函数基于给定的步长选择最新的观测值。def multivariate_data(dataset, target, start_index, end_index, history_size,
target_size, step, single_step=False):
data = []
labels = []
start_index = start_index + history_size
if end_index is None:
end_index = len(dataset) - target_size
for i in range(start_index, end_index):
indices = range(i-history_size, i, step)
data.append(dataset[indices])
if single_step:
labels.append(target[i+target_size])
else:
labels.append(target[i:i+target_size])
return np.array(data), np.array(labels)
在本指南中,ANN会处理最近五(5)天的数据,即720个观测值(6x24x5)。假设数据选择不是每10分钟执行一次,而是每小时进行一次:在60分钟之内,预计不会出现急剧变化。因此,最近五天的历史包括120个观测值(720/6)。对于执行斑点预测的模型,目标是在将来的12小时后读取温度。在这种情况下,目标向量将是72次(12x6)观测后的温度(请参阅以下附加内容-近似转换器)。past_history = 720
future_target = 72
STEP = 6
x_train_single, y_train_single = multivariate_data(dataset, dataset[:, 1], 0,
TRAIN_SPLIT, past_history,
future_target, STEP,
single_step=True)
x_val_single, y_val_single = multivariate_data(dataset, dataset[:, 1],
TRAIN_SPLIT, None, past_history,
future_target, STEP,
single_step=True)
检查时间间隔。print ('Single window of past history : {}'.format(x_train_single[0].shape))
Single window of past history : (120, 3)
train_data_single = tf.data.Dataset.from_tensor_slices((x_train_single, y_train_single))
train_data_single = train_data_single.cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE).repeat()
val_data_single = tf.data.Dataset.from_tensor_slices((x_val_single, y_val_single))
val_data_single = val_data_single.batch(BATCH_SIZE).repeat()
single_step_model = tf.keras.models.Sequential()
single_step_model.add(tf.keras.layers.LSTM(32,
input_shape=x_train_single.shape[-2:]))
single_step_model.add(tf.keras.layers.Dense(1))
single_step_model.compile(optimizer=tf.keras.optimizers.RMSprop(), loss='mae')
我们将在训练和验证阶段检查样本并得出损耗曲线。for x, y in val_data_single.take(1):
print(single_step_model.predict(x).shape)
(256, 1)
single_step_history = single_step_model.fit(train_data_single, epochs=EPOCHS,
steps_per_epoch=EVALUATION_INTERVAL,
validation_data=val_data_single,
validation_steps=50)
Train for 200 steps, validate for 50 steps
Epoch 1/10
200/200 [==============================] - 4s 18ms/step - loss: 0.3090 - val_loss: 0.2646
Epoch 2/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2624 - val_loss: 0.2435
Epoch 3/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2616 - val_loss: 0.2472
Epoch 4/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2567 - val_loss: 0.2442
Epoch 5/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2263 - val_loss: 0.2346
Epoch 6/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2416 - val_loss: 0.2643
Epoch 7/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2411 - val_loss: 0.2577
Epoch 8/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2410 - val_loss: 0.2388
Epoch 9/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2447 - val_loss: 0.2485
Epoch 10/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2388 - val_loss: 0.2422
def plot_train_history(history, title):
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(loss))
plt.figure()
plt.plot(epochs, loss, 'b', label='Training loss')
plt.plot(epochs, val_loss, 'r', label='Validation loss')
plt.title(title)
plt.legend()
plt.show()
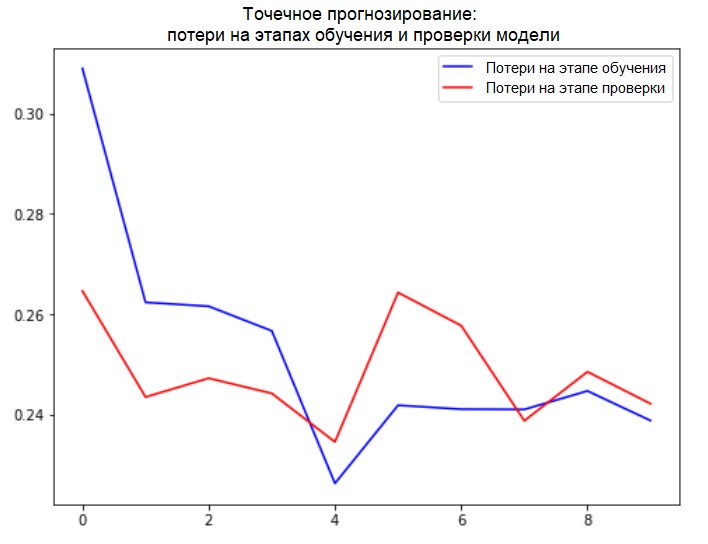
plot_train_history(single_step_history,
'Single Step Training and validation loss')
 另外:
另外:
下图示意性地显示了具有多维输入执行点预测的模型的数据准备。为了方便起见和更直观地表示数据准备,自变量STEP为1。请注意,在给定的生成器函数中,自变量STEP 仅用于形成历史,而不用于目标向量。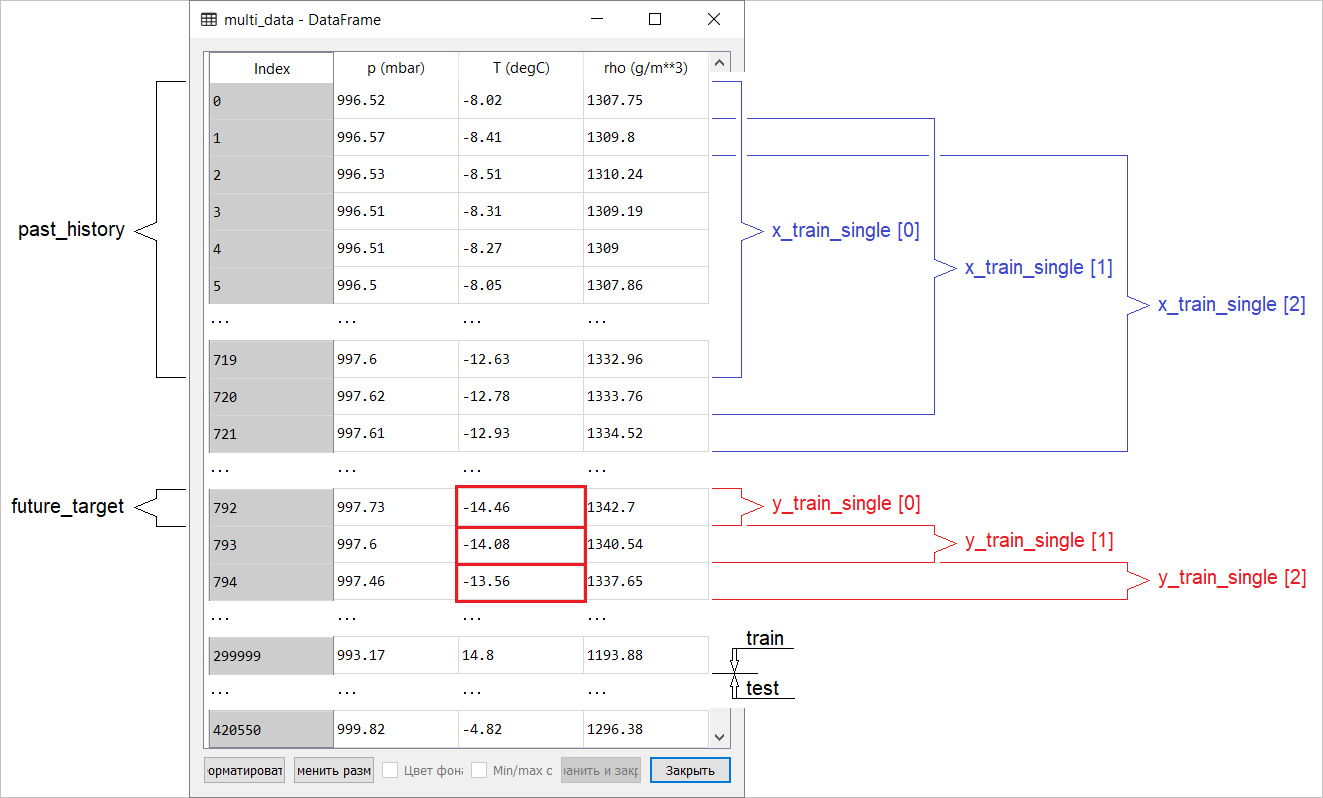 在这种情况下,它
在这种情况下,它x_train_single具有的形式(299280, 720, 3)。
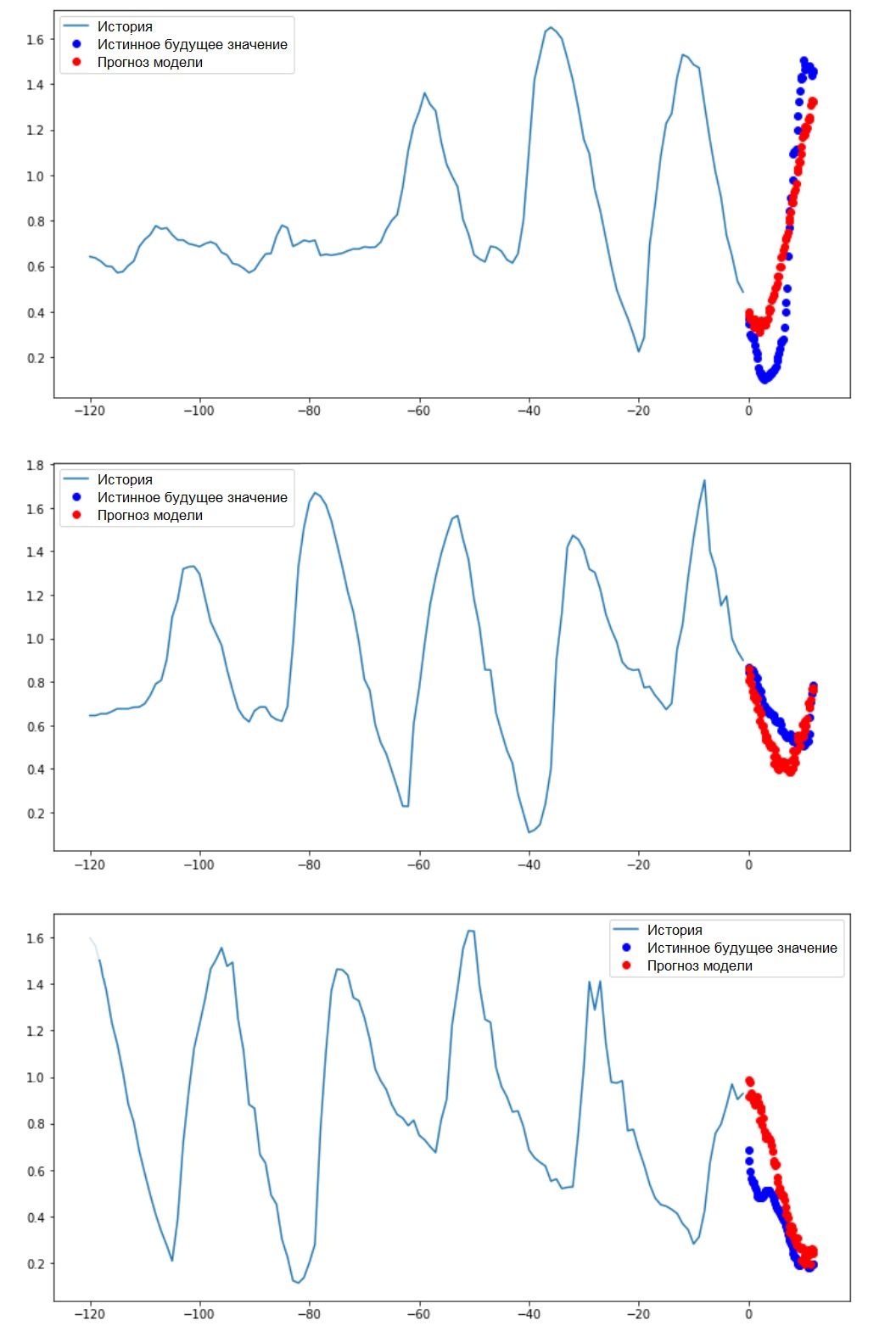
当为时STEP=6,该表单将采用以下形式:(299280, 120, 3)并且函数的速度将显着提高。通常,您需要感谢程序员:手册中介绍的生成器在内存消耗方面非常繁琐。执行点预测现在已经对模型进行了训练,我们将执行几个测试预测。每小时选择一次(时间间隔= 120)最近5天观察到的3个信号的历史记录被输入到模型输入中。由于我们的目标是仅预测温度,因此过去的温度值(历史记录)在图表上以蓝色显示。预测是在未来半天进行的(因此,历史记录与预测值之间存在差距)。for x, y in val_data_single.take(3):
plot = show_plot([x[0][:, 1].numpy(), y[0].numpy(),
single_step_model.predict(x)[0]], 12,
'Single Step Prediction')
plot.show()
 间隔预测在这种情况下,根据一些可用的历史记录,训练模型以预测未来值的间隔。因此,与仅预测未来一个值的模型相反,该模型预测未来的一系列值。假设与执行点预测的模型一样,对于执行间隔预测的模型,训练数据是最近五天(720/6)的每小时测量值。但是,在这种情况下,必须训练模型以预测接下来12小时的温度。由于每10分钟记录一次观察,因此模型的输出应包含72个预测。要完成此任务,有必要再次准备数据集,但要使用不同的目标间隔。
间隔预测在这种情况下,根据一些可用的历史记录,训练模型以预测未来值的间隔。因此,与仅预测未来一个值的模型相反,该模型预测未来的一系列值。假设与执行点预测的模型一样,对于执行间隔预测的模型,训练数据是最近五天(720/6)的每小时测量值。但是,在这种情况下,必须训练模型以预测接下来12小时的温度。由于每10分钟记录一次观察,因此模型的输出应包含72个预测。要完成此任务,有必要再次准备数据集,但要使用不同的目标间隔。future_target = 72
x_train_multi, y_train_multi = multivariate_data(dataset, dataset[:, 1], 0,
TRAIN_SPLIT, past_history,
future_target, STEP)
x_val_multi, y_val_multi = multivariate_data(dataset, dataset[:, 1],
TRAIN_SPLIT, None, past_history,
future_target, STEP)
检查选择。print ('Single window of past history : {}'.format(x_train_multi[0].shape))
print ('\n Target temperature to predict : {}'.format(y_train_multi[0].shape))
Single window of past history : (120, 3)
Target temperature to predict : (72,)
train_data_multi = tf.data.Dataset.from_tensor_slices((x_train_multi, y_train_multi))
train_data_multi = train_data_multi.cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE).repeat()
val_data_multi = tf.data.Dataset.from_tensor_slices((x_val_multi, y_val_multi))
val_data_multi = val_data_multi.batch(BATCH_SIZE).repeat()
另外:下图显示了“间隔模型”与“点模型”的目标矢量的形成差异。 我们将准备可视化。
我们将准备可视化。def multi_step_plot(history, true_future, prediction):
plt.figure(figsize=(12, 6))
num_in = create_time_steps(len(history))
num_out = len(true_future)
plt.plot(num_in, np.array(history[:, 1]), label='History')
plt.plot(np.arange(num_out)/STEP, np.array(true_future), 'bo',
label='True Future')
if prediction.any():
plt.plot(np.arange(num_out)/STEP, np.array(prediction), 'ro',
label='Predicted Future')
plt.legend(loc='upper left')
plt.show()
在此图和后续类似的图表上,历史记录和将来的数据按小时排列。for x, y in train_data_multi.take(1):
multi_step_plot(x[0], y[0], np.array([0]))
 由于此任务比上一个任务复杂一些,因此该模型将由两个LSTM层组成。最后,由于执行了72个预测,因此输出层具有72个神经元。
由于此任务比上一个任务复杂一些,因此该模型将由两个LSTM层组成。最后,由于执行了72个预测,因此输出层具有72个神经元。multi_step_model = tf.keras.models.Sequential()
multi_step_model.add(tf.keras.layers.LSTM(32,
return_sequences=True,
input_shape=x_train_multi.shape[-2:]))
multi_step_model.add(tf.keras.layers.LSTM(16, activation='relu'))
multi_step_model.add(tf.keras.layers.Dense(72))
multi_step_model.compile(optimizer=tf.keras.optimizers.RMSprop(clipvalue=1.0), loss='mae')
我们将在训练和验证阶段检查样本并得出损耗曲线。for x, y in val_data_multi.take(1):
print (multi_step_model.predict(x).shape)
(256, 72)
multi_step_history = multi_step_model.fit(train_data_multi, epochs=EPOCHS,
steps_per_epoch=EVALUATION_INTERVAL,
validation_data=val_data_multi,
validation_steps=50)
Train for 200 steps, validate for 50 steps
Epoch 1/10
200/200 [==============================] - 21s 103ms/step - loss: 0.4952 - val_loss: 0.3008
Epoch 2/10
200/200 [==============================] - 18s 89ms/step - loss: 0.3474 - val_loss: 0.2898
Epoch 3/10
200/200 [==============================] - 18s 89ms/step - loss: 0.3325 - val_loss: 0.2541
Epoch 4/10
200/200 [==============================] - 18s 89ms/step - loss: 0.2425 - val_loss: 0.2066
Epoch 5/10
200/200 [==============================] - 18s 89ms/step - loss: 0.1963 - val_loss: 0.1995
Epoch 6/10
200/200 [==============================] - 18s 90ms/step - loss: 0.2056 - val_loss: 0.2119
Epoch 7/10
200/200 [==============================] - 18s 91ms/step - loss: 0.1978 - val_loss: 0.2079
Epoch 8/10
200/200 [==============================] - 18s 89ms/step - loss: 0.1957 - val_loss: 0.2033
Epoch 9/10
200/200 [==============================] - 18s 90ms/step - loss: 0.1977 - val_loss: 0.1860
Epoch 10/10
200/200 [==============================] - 18s 88ms/step - loss: 0.1904 - val_loss: 0.1863
plot_train_history(multi_step_history, 'Multi-Step Training and validation loss')
 执行间隔预测因此,让我们找出训练有素的人工神经网络如何成功应对未来温度值的预测。
执行间隔预测因此,让我们找出训练有素的人工神经网络如何成功应对未来温度值的预测。for x, y in val_data_multi.take(3):
multi_step_plot(x[0], y[0], multi_step_model.predict(x)[0])
下一步
本指南是使用RNS进行时间序列预测的简要介绍。现在,您可以尝试预测股票市场并成为亿万富翁(最初就是这样:)。 - 注意译者)。另外,您可以编写自己的生成器来准备数据,而不是uni / multivariate_data函数,以便更有效地使用内存。您还可以熟悉“ 时间序列窗口 ”的工作,并将其思想引入本指南。为了进一步理解,建议您阅读《使用Scikit-Learn,Keras和TensorFlow的应用机器学习》(Aurelien Geron,第二版)和本书的第6章第15章。“ Python深度学习”(Francois Scholl)。最后补充
当您待在家里时,不仅要注意身体健康,还要对被截断的数据集执行本手册中的示例,以怜悯计算机。例如,考虑到70x30的比例(训练/测试),您可以按以下方式对其进行限制:dataset = features[300000:].values
TRAIN_SPLIT = 85000