一旦变得有趣起来,LDA(Dirichlet的潜在位置)将在LiveJournal的材料上突出显示哪些主题。正如他们所说,有兴趣-没问题。首先,对LDA进行一些介绍,我们将不涉及数学细节(感兴趣的任何人都可以阅读)。因此,LDA-是用于建模主题的最常见算法之一。每个文档(无论是文章,书籍还是其他任何文本数据来源)都是主题的混合,而每个主题都是单词的混合。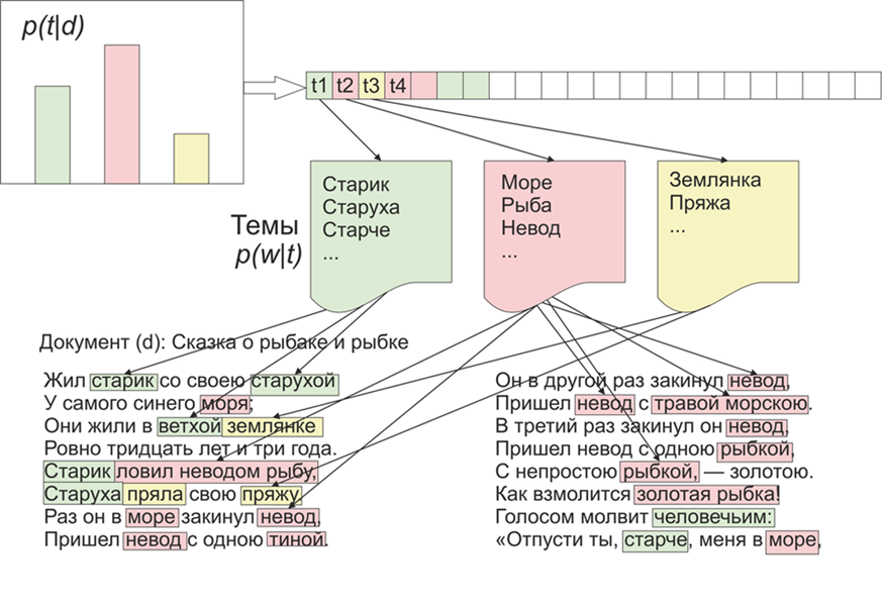 图片取自维基百科因此,LDA的任务是从文档集合中找到构成主题的单词组。然后,根据主题,您可以将文本聚类或仅突出显示关键字。从LifeJournal网站收到了大约1800篇文章,所有文章都转换为jsonl格式,我将未清理的文章留在Yandex磁盘上。我们将对数据进行一些清理和归一化:抛出注释,删除停用词(列表以及源代码可在github上找到)),我们会将所有单词减少为小写拼写,删除标点符号和不超过3个字母的单词。但是主要的预处理操作之一:原则上,删除频繁出现的单词可以仅限于仅删除停用词,但是,几乎所有主题中都包含频繁使用的单词的可能性很高。在这种情况下,可以对这些单词进行后处理和删除。这是你的选择。
图片取自维基百科因此,LDA的任务是从文档集合中找到构成主题的单词组。然后,根据主题,您可以将文本聚类或仅突出显示关键字。从LifeJournal网站收到了大约1800篇文章,所有文章都转换为jsonl格式,我将未清理的文章留在Yandex磁盘上。我们将对数据进行一些清理和归一化:抛出注释,删除停用词(列表以及源代码可在github上找到)),我们会将所有单词减少为小写拼写,删除标点符号和不超过3个字母的单词。但是主要的预处理操作之一:原则上,删除频繁出现的单词可以仅限于仅删除停用词,但是,几乎所有主题中都包含频繁使用的单词的可能性很高。在这种情况下,可以对这些单词进行后处理和删除。这是你的选择。stop=open('stop.txt')
stop_words=[]
for line in stop:
stop_words.append(line)
for i in range(0,len(stop_words)):
stop_words[i]=stop_words[i][:-1]
texts=[re.split( r' [\w\.\&\?!,_\-#)(:;*%$№"\@]* ' ,texts[i])[0].replace("\n","") for i in range(0,len(texts))]
texts=[test_re(line) for line in texts]
texts=[t.lower() for t in texts]
texts = [[word for word in document.split() if word not in stop_words] for document in texts]
texts=[[word for word in document if len(word)>=3]for document in texts]
接下来,我们将所有单词改成正常形式:为此,我们使用pymorphy2库,该库可以通过pip安装。morph = pymorphy2.MorphAnalyzer()
for i in range(0,len(texts)):
for j in range(0,len(texts[i])):
texts[i][j] = morph.parse(texts[i][j])[0].normal_form
是的,我们将丢失有关单词形式的信息,但是在这种情况下,我们对单词彼此之间的兼容性更感兴趣。这是我们的预处理完成的地方,还没有完成,但是足以了解LDA算法的工作原理。此外,原则上可以省略上述要点,但我认为结果更加充分,例如,您决定可以构建一个函数,该函数取决于文档的平均长度及其数量:counter = collections.Counter()
for t in texts:
for r in t:
counter[r]+=1
limit = len(texts)/5
too_common = [w for w in counter if counter[w] > limit]
too_common=set(too_common)
texts = [[word for word in document if word not in too_common] for document in texts]
让我们直接进行模型的训练,为此,我们需要安装gensim库,其中包含一堆很棒的面包。首先,您需要对所有单词进行编码,Dictionary函数将为我们完成此操作,然后我们将单词替换为其数值等效项。LDA调用的注释掉版本较长,因为它在每个文档之后都会更新,因此您可以使用设置并选择适当的选项。texts=preposition_text_for_lda(my_r)
dictionary = gensim.corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
lda = gensim.models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=10)
程序完成后,可以使用以下命令查看主题lda.show_topic(i,topn=30)
,其中i是主题编号,topn是要显示的主题中的单词数。现在,用于可视化主题的奖金很小,为此,您需要安装wordcloud库(例如,matplotlib中也包含类似的实用程序)。此代码可视化主题并将其保存在当前文件夹中。from wordcloud import WordCloud, STOPWORDS
for i in range(0,10):
a=lda.show_topic(i,topn=30)
wordcloud = WordCloud(
relative_scaling = 1.0,
stopwords = too_common
).generate_from_frequencies(dict(a))
wordcloud.to_file('society'+str(i)+'.png')
最后,给出一些我所了解的主题的示例:
 实验,您可以获得更有意义的结果。
实验,您可以获得更有意义的结果。