 朋友们,美好的一天!本文从网络音频API(WAA)的音乐理论中解释了一些概念。了解了这些概念,您可以在设计应用程序中的音频时做出明智的决定。本文不会使您成为经验丰富的声音工程师,但可以帮助您了解WAA为何以这种方式工作。
朋友们,美好的一天!本文从网络音频API(WAA)的音乐理论中解释了一些概念。了解了这些概念,您可以在设计应用程序中的音频时做出明智的决定。本文不会使您成为经验丰富的声音工程师,但可以帮助您了解WAA为何以这种方式工作。音频电路
WAA的本质是在音频上下文中用声音执行某些操作。该API专为模块化路由而设计。声音的基本操作是音频节点,它们相互连接并形成一个路由图(音频路由图)。在单个上下文中处理具有不同类型的通道的多个源。这种模块化设计为创建具有动态效果的复杂功能提供了必要的灵活性。音频节点通过输入和输出互连,形成一条链,该链从一个或多个源开始,经过一个或多个节点,然后在目的地终止。原则上,例如,如果我们只想可视化一些音频数据,则可以没有目的地。典型的网络音频工作流程如下所示:- 创建音频上下文
- 在上下文中,创建源-例如<audio>,振荡器(声音生成器)或流
- 创建效果节点,例如混响,双二阶滤波器,声像或压缩器
- 选择音频的目的地,例如用户计算机上的扬声器
- 通过效果到目的地在源之间建立连接

频道指定
可用音频通道的数量通常以数字格式表示,例如2.0或5.1。这称为通道指定。第一位数字指示信号包括的整个频率范围。第二位数字表示为低频效果输出- 低音炮保留的通道数。每个输入或输出均包含一个或多个根据特定音频电路构建的通道。有各种离散的通道结构,例如单声道,立体声,四声道,5.1等。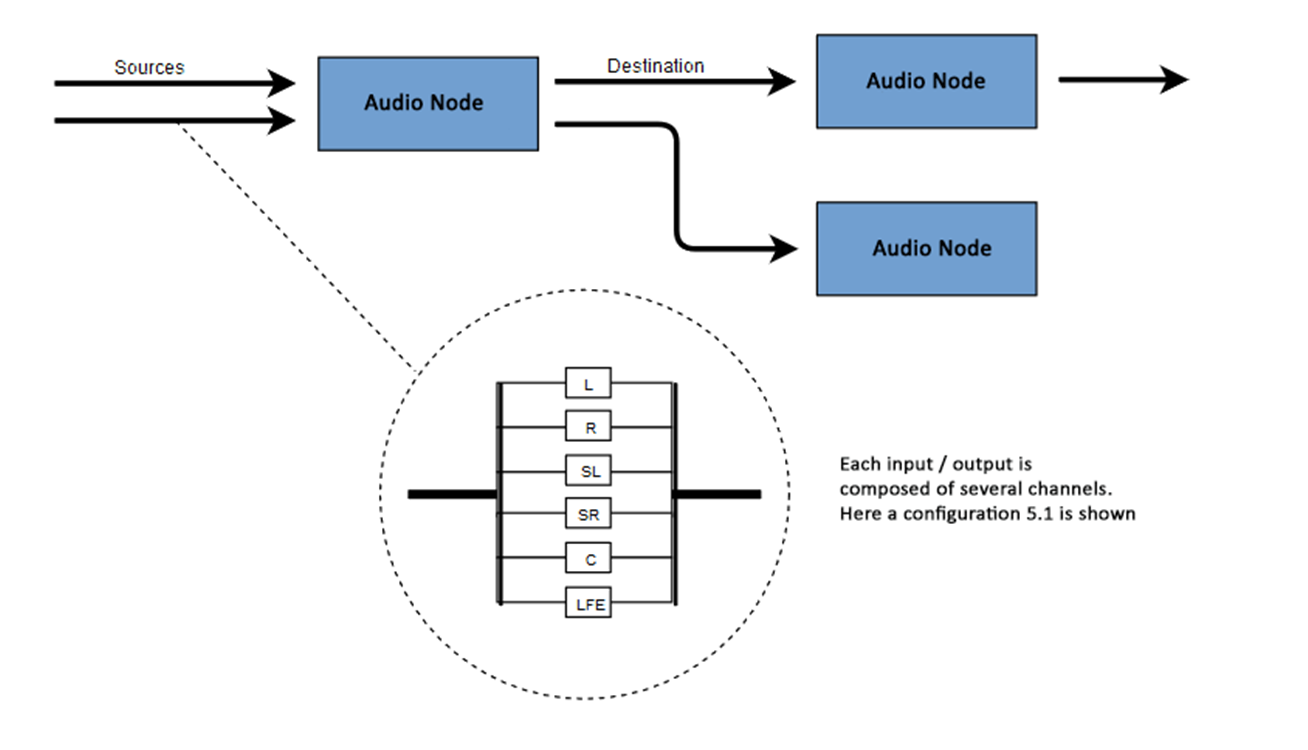 音频源可以通过多种方式获得。声音可能是:
音频源可以通过多种方式获得。声音可能是:- 由JavaScript通过音频节点(例如振荡器)生成
- 使用PCM(脉冲代码调制)从原始数据创建
- 派生自HTML媒体元素(例如<video>或<audio>)
- 源自WebRTC媒体流(例如网络摄像头或麦克风)
采样是指将连续信号转换为离散(分频)(模拟到数字)信号。换句话说,连续的声波(例如现场音乐会)被转换为样本序列,从而使计算机可以在单独的块中处理音频。音频缓冲区:帧,样本和通道
AudioBuffer接受通道数作为参数(单声道为1,立体声为2等),长度-缓冲区内的样本帧数,以及采样频率-每秒的帧数。样本是一个简单的32位浮点值(float32),它是特定时间点和特定通道(左或右等)中音频流的值。样本帧或帧是在某个时间点重现的所有通道的一组值:在同一时间重现的所有通道的所有样本(两个用于立体声,六个用于5.1等)。采样率是指采样(或帧,因为一帧中的所有采样都一次播放)的数量,以秒为单位播放,以赫兹(Hz)为单位。频率越高,声音质量越好。让我们看一下以44100 Hz的频率重现的,每秒钟长的单声道和立体声缓冲器:- 单声道缓冲区将具有44100个样本和44100个帧。“长度”属性的值为44100
- 立体声缓冲器将具有88,200个样本,但也有44,100帧。“ length”属性的值将为44100-长度等于帧数
 当缓冲区的回放开始时,我们首先会听到样本的最左边的帧,然后是最近的右边的帧,依此类推。对于立体声,我们同时听到两个声道。样本帧与通道数无关,并为非常精确的音频处理提供了机会。注意:要从帧数获取时间(以秒为单位),必须将帧数除以采样率。要从样本数中获取帧数,请用样本数除以通道数。例:
当缓冲区的回放开始时,我们首先会听到样本的最左边的帧,然后是最近的右边的帧,依此类推。对于立体声,我们同时听到两个声道。样本帧与通道数无关,并为非常精确的音频处理提供了机会。注意:要从帧数获取时间(以秒为单位),必须将帧数除以采样率。要从样本数中获取帧数,请用样本数除以通道数。例:let context = new AudioContext()
let buffer = context.createBuffer(2, 22050, 44100)
注意:在数字音频中,标准采样频率为44100 Hz或44.1 kHz。但是为什么是44.1 kHz?首先,因为可听频率范围(人耳可分辨的频率)从20到20,000 Hz不等。根据Kotelnikov定理,采样频率应该是信号频谱中最高频率的两倍以上。因此,采样频率应大于40 kHz。其次,必须使用低通滤波器对信号进行滤波。在采样之前,否则频谱的“尾部”会重叠(频率交换,频率掩蔽,混叠),并且重构信号的形状将失真。理想情况下,低通滤波器应通过低于20 kHz的频率(无衰减)并降低高于20 kHz的频率。在实践中,需要一些过渡带(在通带和抑制带之间),在该过渡带中,频率会部分衰减。一种更简单,更经济的方法是使用防更换过滤器。对于44.1 kHz的采样频率,过渡带为2.05 kHz。在上面的示例中,我们获得了具有两个通道的立体声缓冲器,该音频缓冲器在音频环境中以44100 Hz(标准)的频率进行再现,时长为0.5秒(22050帧/ 44100 Hz = 0.5 s)。let context = new AudioContext()
let buffer = context.createBuffer(1, 22050, 22050)
在这种情况下,我们得到了一个通道的单声道缓冲器,它在音频环境中以44100 Hz的频率进行再现,它将过采样到44100 Hz(并将帧增加到44100),1秒长(44100帧/ 44100 Hz = 1 s)。注意:音频重采样(“重采样”)与调整图像大小(“调整大小”)非常相似。假设我们有一个16x16的图片,但是我们想用32x32的尺寸填充该区域。我们会调整大小。结果会降低质量(根据缩放算法可能会模糊或撕裂),但是可以正常工作。重新采样的音频是一回事:我们可以节省空间,但实际上却不可能获得高质量的声音。平面和条带缓冲区
WAA使用平面缓冲区格式。左右声道交互如下:LLLLLLLLLLLLLLLLRRRRRRRRRRRRRRRR ( , 16 )
在这种情况下,每个通道都独立于其他通道工作。一种替代方法是使用备用格式:LRLRLRLRLRLRLRLRLRLRLRLRLRLRLRLR ( , 16 )
此格式通常用于MP3解码。WAA仅使用平面格式,因为它更适合声音处理。将数据发送到声卡进行播放时,平面格式将转换为交替格式。解码MP3时,将进行逆转换。音讯频道
不同的缓冲区包含不同数量的声道:从简单的单声道(一个声道)和立体声(左声道和右声道)到更复杂的集合(例如,quad和5.1),每个声道中的采样数不同,从而提供了更丰富(更丰富)的声音。频道通常用缩写表示:上混和下混
当输入和输出的通道数不匹配时,向上或向下进行混合。混合由AudioNode.channelInterpretation属性控制:可视化
可视化基于对输出音频数据(例如,振幅或频率数据)的接收,以及使用任何图形技术对其进行的后续处理。WAA的AnalyzerNode不会使通过它的信号失真。同时,它能够从音频中提取数据并将其进一步传输到例如&ltcanvas>。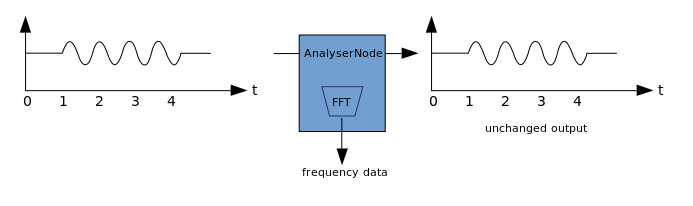 可以使用以下方法提取数据:
可以使用以下方法提取数据:- AnalyzerNode.getFloatByteFrequencyData()-将当前频率数据复制到Float32Array
- AnalyzerNode.getByteFrequencyData()-将当前频率数据复制到Uint8Array(无符号字节数组)
- AnalyserNode.getFloatTimeDomainData() — Float32Array
- AnalyserNode.getByteTimeDomainData() — Uint8Array
音频空间化(由PannerNode和AudioListener处理)使您可以模拟信号在空间中特定点的位置和方向,以及听众的位置。摇摄器的位置使用右手笛卡尔坐标描述;对于运动,使用创建多普勒效应所需的速度矢量;对于方向,使用方向性圆锥。在多向声源的情况下,此锥体可能会很大。 收听者的位置描述如下:移动-使用速度矢量,收听者头部所在的方向-使用两个方向矢量,前部和顶部。捕捉以正确的角度捕捉到听众的头部和鼻子的顶部。
收听者的位置描述如下:移动-使用速度矢量,收听者头部所在的方向-使用两个方向矢量,前部和顶部。捕捉以正确的角度捕捉到听众的头部和鼻子的顶部。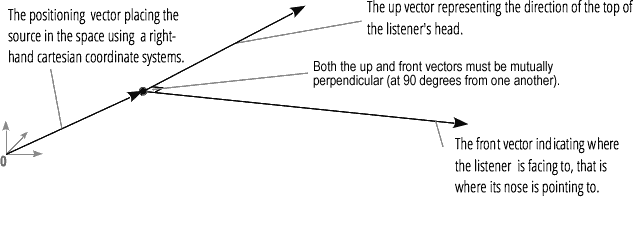
结点和分支
连接描述了一个过程,其中ChannelMergerNode接收几个输入单声道源并将它们组合成单个多通道输出信号。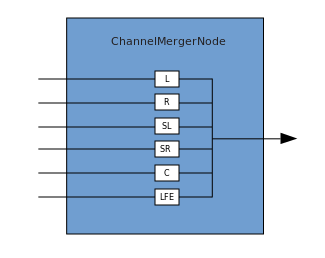 分支是相反的过程(通过ChannelSplitterNode实现)。
分支是相反的过程(通过ChannelSplitterNode实现)。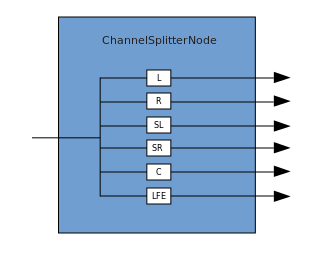 在此处可以找到使用WAA的示例。示例的源代码在此处。这是一篇有关其工作原理的文章。感谢您的关注。
在此处可以找到使用WAA的示例。示例的源代码在此处。这是一篇有关其工作原理的文章。感谢您的关注。