 您看到的图片是从DeepMind网站上拍摄的,显示了其最新开发的Agent57(在Habré上的评论)获得成功的57个游戏。数字57本身并不是从天花板上取下来的-恰好在2012年,有如此多的游戏被选为Atari游戏的AI开发人员中的一种基准,此后各种研究人员在此特定数据集上衡量他们的成就。在这篇文章中,我将尝试从不同角度审视这些成就,以评估其在应用任务中的价值,并说明为什么我不认为这是未来。好吧,是的,我警告说,剪下的照片很多。在上面的链接中,开发人员写了正确的东西,说
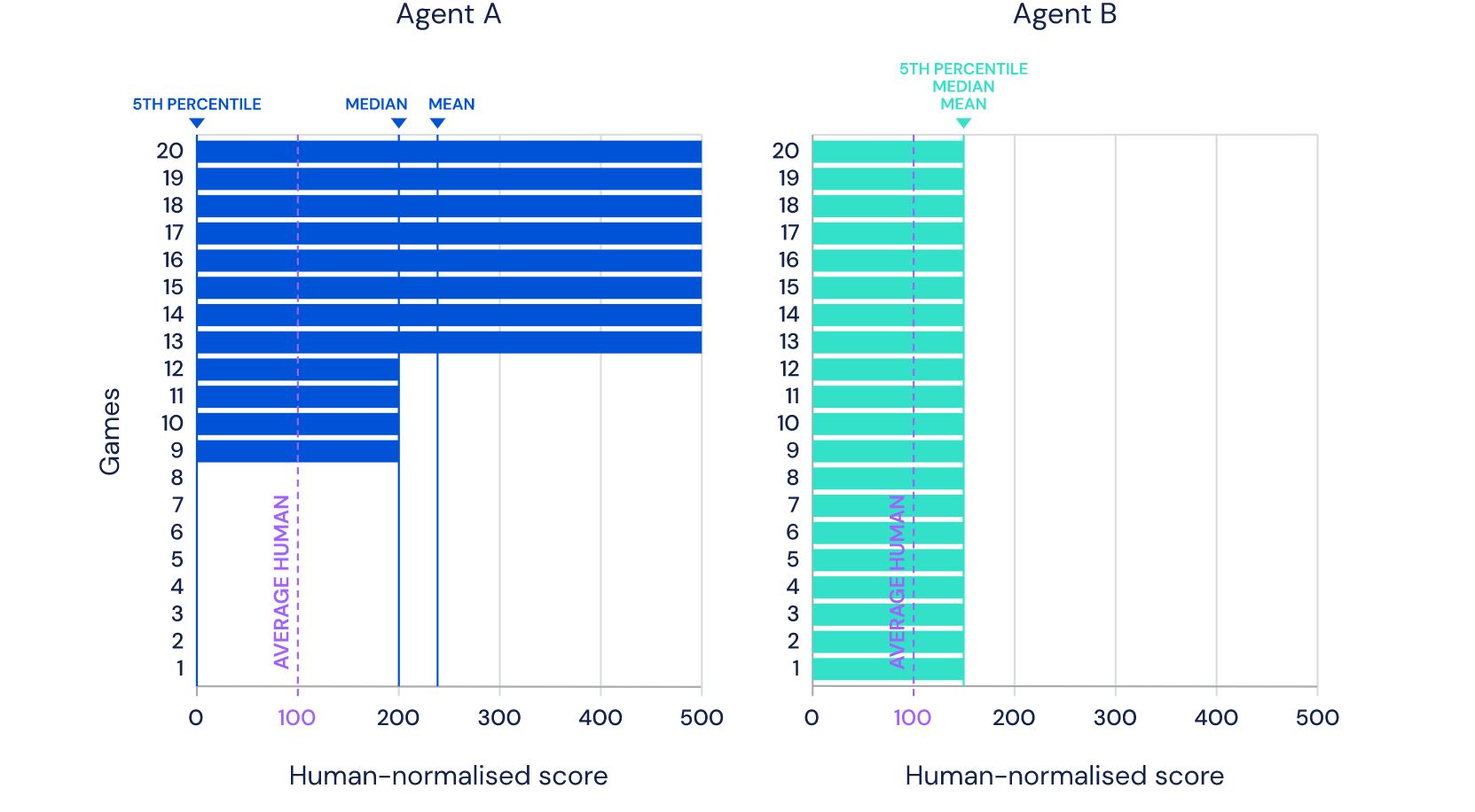
您看到的图片是从DeepMind网站上拍摄的,显示了其最新开发的Agent57(在Habré上的评论)获得成功的57个游戏。数字57本身并不是从天花板上取下来的-恰好在2012年,有如此多的游戏被选为Atari游戏的AI开发人员中的一种基准,此后各种研究人员在此特定数据集上衡量他们的成就。在这篇文章中,我将尝试从不同角度审视这些成就,以评估其在应用任务中的价值,并说明为什么我不认为这是未来。好吧,是的,我警告说,剪下的照片很多。在上面的链接中,开发人员写了正确的东西,说因此,尽管平均得分有所提高,但到目前为止,上述人类比赛的数量还没有增加。作为说明性示例,请考虑由二十个任务组成的基准。假设代理A在八项任务中获得500%的分数,在四项任务中获得200%的分数,而在八项任务中获得0%的分数(平均值= 240%,中位数= 200%),而代理B在所有任务中获得150%的分数(平均值=中位数= 150%)。平均而言,座席A的性能要优于座席B。但是,座席B具有更通用的能力:与座席A相比,它在更多任务上获得人为水平的表现。
 用手指指的是,在对每个人进行“平均”排名衡量之前,他们都挥舞了计算机难以解决的问题,但现在它们才刚刚开始。因此,他们比人获得了真正的优势,而不是对计算机友好案例的超级结果。但是,让我们从更全局的角度看问题,以了解是否是如此。DeepMind AI与视频游戏之间的交互是什么星号在下文中将表示通过算法创建的实体,这些算法不是在AI的帮助下而是在专家意见的帮助下创建的。在拆卸电路之前,让我们看一下另一种方法:
用手指指的是,在对每个人进行“平均”排名衡量之前,他们都挥舞了计算机难以解决的问题,但现在它们才刚刚开始。因此,他们比人获得了真正的优势,而不是对计算机友好案例的超级结果。但是,让我们从更全局的角度看问题,以了解是否是如此。DeepMind AI与视频游戏之间的交互是什么星号在下文中将表示通过算法创建的实体,这些算法不是在AI的帮助下而是在专家意见的帮助下创建的。在拆卸电路之前,让我们看一下另一种方法:影片摘要- + ,

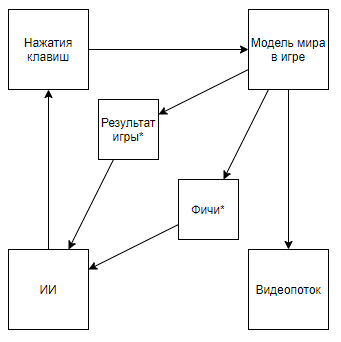 该方案变成这样。而且,如果您浏览作者的频道,则可以在复古游戏中找到它的应用。将方案更改为这一方案,我们得出的结论是,培训的速度和有效性正在以数量级增长,但是这种旅行所取得的成就的科学和工程价值接近于0(是的,我没有考虑普及值)。我们可以假设整个问题是从管道中抛出了视频,但是请考虑以下方案(我确定有人实现了类似的方案,但是手边没有链接):当知道必要特征的专家编写视频流解析器以使用关键像素计算特征时,将实现此功能。甚至是这样的方案:首先,对AI1进行了训练,以提取专家从视频中选择的特征。然后教AI2使用AI1从视频流中提取的特征进行播放。因此,我们有一个方案:
该方案变成这样。而且,如果您浏览作者的频道,则可以在复古游戏中找到它的应用。将方案更改为这一方案,我们得出的结论是,培训的速度和有效性正在以数量级增长,但是这种旅行所取得的成就的科学和工程价值接近于0(是的,我没有考虑普及值)。我们可以假设整个问题是从管道中抛出了视频,但是请考虑以下方案(我确定有人实现了类似的方案,但是手边没有链接):当知道必要特征的专家编写视频流解析器以使用关键像素计算特征时,将实现此功能。甚至是这样的方案:首先,对AI1进行了训练,以提取专家从视频中选择的特征。然后教AI2使用AI1从视频流中提取的特征进行播放。因此,我们有一个方案:- 使用视频流,无法直接访问世界模型。
- 不依赖专家编写的视频流解析器
- 它会比DeepMind的开发更容易,更有效地进行培训
但是...我们碰到同样的事情。同样,这种实现方式对复古游戏的应用既没有科学价值,也没有工程价值,因为AI1是现代图像处理算法的长期解决且非常原始的任务,而且AI2的创建也非常快速简单。确认上述视频的作者。那么,DeepMind算法对Atari游戏的价值是什么?我会尝试总结一下:价值在于当世界模型S(MM,t)的状态由某个失真函数F(S(MM,t))表示为严重失真时,DeepMind算法能够找到具有MM世界原始模型的游戏的最佳行为策略,仅可以评估决策的质量该函数接收一个F(S(MM,t))值序列和算法反应,并且该序列的长度未知(游戏可以以不同的步数结束),但是您可以无限次重复该实验。预期的问题, . S(MM, t) , , . F(S(MM, t)) , .
现在,我们尝试评估该值在解决与工具某种程度上相关联的现实世界问题上的适用性,即它们代表具有严重失真的真实状态,这意味着环境会对代理的行为做出响应,仅在经过一系列决策后才进行评估,并且但是,它们允许多次执行实验。乍一看,一个有趣的应用似乎是交易所上的一个游戏。甚至Google的暗示,也就是作为现实使用的唯一暗示而出卖的暗示,都暗示该话题很热门。我将立即指出一个重要点-几乎所有的市场分析方法(不包括分析现实世界对象的方法,例如超市前面的停车场,新闻,Twitter上提及股票的方法)都可以分为两种。第一种是将市场表示为时间序列的方法。第二,作为应用程序流。但是根本的区别不在于所使用的数据,而在于这样一个事实,即通常来说,那些按时间序列分析市场的人忽略了它们对市场的影响,认为有条件地在每日间隔内,他们的交易不会影响市场的进一步动态。尽管第二种方法的支持者都可以忽略,认为它们的数量与市场流动性无关紧要,而将市场视为反馈系统,却认为他们的行为会影响其他参与者的行为(例如,与大订单的最佳执行,做市,高频交易有关的研究和方法)。浏览搜索结果后,很明显,所有致力于使用强化训练进行交易的文章和帖子(与DeepMind成功案例最接近的主题)都致力于第一种方法。但是,有关该问题的方法的比例性出现了一个合理的问题。首先,让我们画一个类似于Atari游戏的图。客观现实, . , , , , — . , , . , , , , , . , .
看来一切都变得美好。而且,我怀疑这种相似性也会引起炒作。但是,如果我们稍微澄清一下方案,该怎么办:值得从“客观现实”模块中取出投资组合的状态(每次时刻有多少纸质和金钱,以及所有这些费用),大的反馈环如何消失以及无人训练的强化训练功能变得无人问津。您可以就什么和什么争论很长时间,使用了一种针对结构复杂得多的系统的工具-更通用的AlphaZero击败了专门的AlphaGo。但是,我冒昧地建议事实并非如此。毕竟,数据集的维度和收缩令人难以置信。的确,例如,如果我们有一个10,000点的时间序列,则与其进行培训(例如做出约10,000个决策),不如将整个决策评估为一个决策(许多交易),从而使自己失去了过度拟合的保护。以便,不能执行许多实验的条件。虽然,如果我们只限于科学。您可以从实际市场中提取任意数量的时间序列,而不是将其用于商业用途,并且该方法可能会带来利润(尽管不是由于市场上的利润,而是由于科学界的演讲和出版物)。预期自生成样本的问题, , , . , , . , , . , , , , , .
第二种方法(带有大量应用程序)看起来更有希望。所谓玻璃它通常充满了机器人的应用程序,这些机器人会搜寻价格的一小部分,在队列中的某个位置竞争,并且经常创建应用程序只是为了使需求或供应出现,并导致其他机器人采取不利的行动。如果您梦dream以求,似乎您可以创建一个交换模拟器并将HFT机器人放入其中,通过数十亿的决策,它可以自学,与自己的克隆人一起玩,从而制定出一种理想的策略,其中应考虑所有最佳的反策略。 ......可惜的是,如果发生这种情况,那么全世界大约5个人会发现它-高频交易者的商业原则意味着绝对保密,并且拒绝发布甚至不成功的结果,也不会给敌人留下踩踏同一个耙子的机会。我认为,在市场,人力资源,销售,管理和其他对象是人的领域中不可能采用这种方法尤其不值得,因为对于正确的应用,必须使AI进行数百万甚至数十亿次实验。而且,即使许多公司与AI可以做出决定的对象进行一百万次交互(根据其个人资料选择标语以显示潜在客户,解雇员工的决定),也没有人会得到一百万次相同的实验对象,这正是高质量应用程序所需要的。但是值得关注的是反欺诈和网络安全。我不知道是幸运还是不幸,但是在现代世界中,许多经济关系都是基于提供小的价值而没有义务来换取未来的期望值,这带来了许多免费来源和潜在的欺诈行为。例子:- 出租车聚集者的第一次免费乘车
- 赌博带来的每次转化费用为70美元,对于带来5美元的玩家而言
- 测试来自云提供商的300美元和试用期
此外,由于商人经常故意拒绝使用相同的3D安全性来简化用户体验,因此对信用卡交易的保护程度较低,可以支撑现代经济系统的欺诈潜力。因此,对于被盗卡的购买者来说,只要他们的余额的一小部分就可以被无限期地补充。应对此类案件的主要问题在于无法收集足够数量的数据集-欺诈操作的百分比比根据业务的良好操作的百分比低1-6个数量级。伪造的灵活性也存在问题,伪造很容易绕过静态算法,以适应根据过去经验进行过训练的反欺诈系统。而且,似乎在这里。在沙盒中启动的诸如Agent57之类的算法将使您能够创建理想的欺诈者,不断更新其技能,同时解决反问题-保持用于识别它的算法最新。但是有一个警告。对抗Atari游戏中嵌入的世界模型与从已经根据数百万玩家的行为进行训练的反欺诈系统中获得胜利完全不同,而且许多欺诈行为与复古游戏中玩家的许多行为不成比例。例如,即使是简单的操作(例如在注册表单上输入登录名)也已经包含数十亿个选择。从哪个用户代理转移到服务器开始,以输入第二个和第三个登录字符之间要等待的毫秒数结束...总的来说,我以某种方式看到了一切。太惨了。我真的希望我错了,在某个地方我没有考虑模型中的某些内容。如果在评论中看到反例,我将不胜感激。