您好亲爱的Khabrovites,在这个小例子中,我想展示如何解析页面,页面上的数据是使用javascript小部件加载的。此外,即使本示例中的页面易于保存,由于这些小部件,您仍然无法从其中解析所有必要的照片。在这种情况下,我以cian.ru站点为例,该站点具有自己的api,我将不使用它,而是使用Selenium。我不在cian.ru工作,我仅以本网站为例。解析器中的代码很简单,专为初学者设计。
简短介绍-闲暇时我在cian.ru上查看维修示例,我认为保存我喜欢的照片会很好,但是手动保存它们会很长一段时间,此外这不是我们的方法,因此我决定编写此文件解析器。
解析器是从Anaconda,Selenium和chromedriver二进制发行版中以python3编写的,我与这些链接分开安装。(当然,必须在系统上安装Google Chrome浏览器)
下面是完整的解析器代码,然后我将分别分析要点。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import NoSuchElementException
import chromedriver_binary
import urllib
import time
print('start...')
site = "https://www.cian.ru/sale/flat/222059642/"
chrome_options = Options()
chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
driver.get(site)
i = 0
while True:
try:
url = driver.find_element_by_xpath("//div[contains(@class, 'fotorama__active')]/img").get_attribute('src')
except NoSuchElementException:
break
i += 1
print(i, url)
driver.find_element_by_xpath("//div[@class='fotorama__arr fotorama__arr--next']").click()
name = url.split('/')[-1]
urllib.request.urlretrieve(url, name)
time.sleep(2)
print('done.')
https://www.cian.ru/sale/flat/222059642/ . driver get. , Headless Chrome, .. webdriver.Chrome() --headless, , , chrome_options , .
site = "https://www.cian.ru/sale/flat/222059642/"
chrome_options = Options()
chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
driver.get(site)
, , , .. "next".
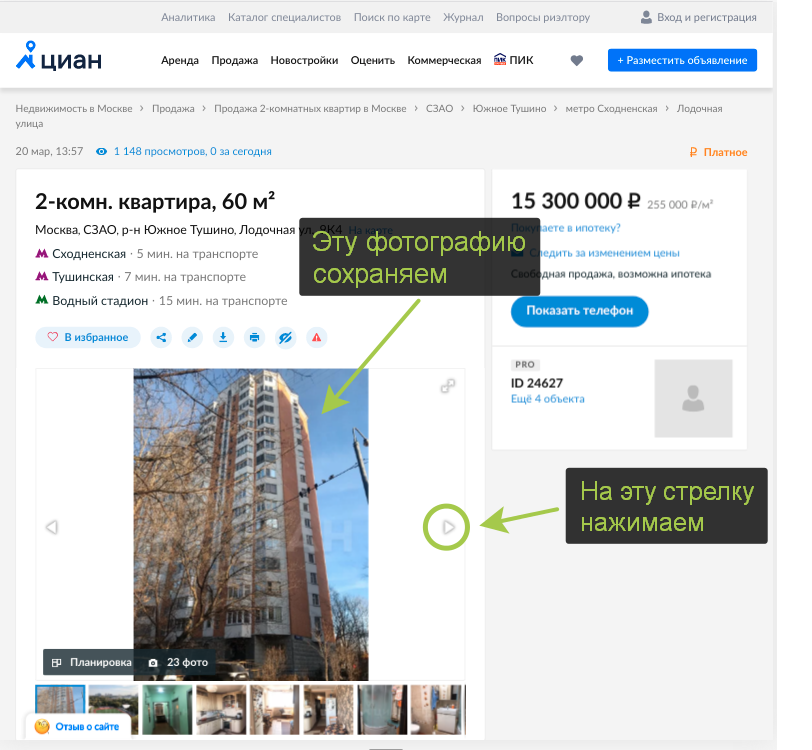
url , try/except NoSuchElementException, , Selenium .
try:
url = driver.find_element_by_xpath("//div[contains(@class, 'fotorama__active')]/img").get_attribute('src')
except NoSuchElementException:
break
.
driver.find_element_by_xpath("//div[@class='fotorama__arr fotorama__arr--next']").click()
urllib.
name = url.split('/')[-1]
urllib.request.urlretrieve(url, name)
, . ( Selenium)
time.sleep(2)
Selenium, , , - .
.