您好,habrozhiteli!当我们的新闻在印刷厂印刷并且办公室在偏僻的地方时,我们决定分享Paul和Harvey Daytel的书“ Python:人工智能,大数据和云计算”的摘录。案例研究:没有老师的机器学习,第2部分-K平均聚类
在本节中,也许将介绍没有老师的最简单的机器学习算法-使用k平均法进行聚类。该算法分析未标记的样本,然后尝试将它们组合成簇。让我们解释一下,“ k均值方法”中的k代表应该将数据拆分为的簇数。该算法使用类似于k个最近邻居的聚类算法的距离度量,将样本分布到预定数量的聚类中。每个群集围绕质心(群集的中心点)分组。最初,该算法从数据集样本中选择k个随机质心,然后将其余样本分布在具有最接近质心的聚类中。接下来,执行质心的迭代重新计算,并在所有群集中重新分配样本,直到从给定质心到群集中包含的样本的距离对于所有群集最小。作为该算法的结果,将创建一维标签数组,以指定每个样本所属的簇,以及代表每个簇中心的质心的二维数组。虹膜数据集
我们将使用scikit-learn中包含的流行Iris数据集。通常在分类和聚类期间分析此集合。尽管数据集已标记,但我们不会使用这些标签来演示聚类。然后,将使用标签来确定k平均算法对样本进行聚类的程度。虹膜数据集是一个玩具数据集,因为它仅包含150个样本和四个属性。数据集描述了三种鸢尾花的50个样本-鸢尾花,鸢尾鸢尾和初春鸢尾花(见下图)。样品的特征:花被外皮的长度(掌长),花被外皮的宽度(掌骨的宽度),花被内皮的长度(花瓣的长度)和花被内皮的宽度(花瓣的宽度),以厘米为单位。14.7.1。下载虹膜数据集
使用ipython --matplotlib命令启动IPython,然后使用sklearn.datasets模块的load_iris函数获取具有数据集的Bunch对象:In [1]: from sklearn.datasets import load_iris
In [2]: iris = load_iris()
Bunch对象的DESCR属性指示该数据集包含150个“实例数”样本,每个样本均具有四个“属性数”。数据集中没有缺失值。样本用整数0、1和2进行分类,分别代表鸢尾鸢尾,杂色鸢尾和初春鸢尾。我们忽略标签,将样本类别的确定委托给使用k均值方法的聚类算法。粗体DESCR键的主要信息:In [3]: print(iris.DESCR)
.. _iris_dataset:
Iris plants dataset
--------------------
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class:
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica
:Summary Statistics:
============== ==== ==== ======= ===== ====================
Min Max Mean SD Class Correlation
============== ==== ==== ======= ===== ====================
sepal length: 4.3 7.9 5.84 0.83 0.7826
sepal width: 2.0 4.4 3.05 0.43 -0.4194
petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)
petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)
============== ==== ==== ======= ===== ====================
:Missing Attribute Values: None
:Class Distribution: 33.3% for each of 3 classes.
:Creator: R.A. Fisher
:Donor: Michael Marshall (MARSHALL%PLU@io.arc.nasa.gov)
:Date: July, 1988
...
检查样本数量,特征和目标值
模式和属性的数量可以在数据数组的shape属性中找到,目标值的数量可以在目标数组的shape属性中找到:In [4]: iris.data.shape
Out[4]: (150, 4)
In [5]: iris.target.shape
Out[5]: (150,)
数组target_names包含数组数字标签的名称。表达式target-dtype ='<U10'表示其元素是最大长度为10个字符的字符串:In [6]: iris.target_names
Out[6]: array(['setosa', 'versicolor', 'virginica'], dtype='<U10')
feature_names数组包含数据数组中每一列的字符串名称列表:In [7]: iris.feature_names
Out[7]:
['sepal length (cm)',
'sepal width (cm)',
'petal length (cm)',
'petal width (cm)']
14.7.2。虹膜数据集研究:熊猫中的描述性统计
我们使用DataFrame集合检查虹膜数据集。与California Housing数据集一样,我们设置pandas参数以格式化列输出:In [8]: import pandas as pd
In [9]: pd.set_option('max_columns', 5)
In [10]: pd.set_option('display.width', None)
使用feature_names数组的内容作为列名,使用数据数组的内容创建一个DataFrame集合:In [11]: iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
然后添加一个列,其中包含每个样本的视图名称。以下代码段中的列表转换使用目标数组中的每个值在target_names数组中搜索相应的名称:In [12]: iris_df['species'] = [iris.target_names[i] for i in iris.target]
我们将使用熊猫来识别几个样本。和以前一样,如果pandas在列名的右侧输出\,则表示将在下面显示的列保留在输出中:In [13]: iris_df.head()
Out[13]:
sepal length (cm) sepal width (cm) petal length (cm) \
0 5.1 3.5 1.4
1 4.9 3.0 1.4
2 4.7 3.2 1.3
3 4.6 3.1 1.5
4 5.0 3.6 1.4
petal width (cm) species
0 0.2 setosa
1 0.2 setosa
2 0.2 setosa
3 0.2 setosa
4 0.2 setosa
我们为数字列计算一些描述性统计指标:In [14]: pd.set_option('precision', 2)
In [15]: iris_df.describe()
Out[15]:
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)
count 150.00 150.00 150.00 150.00
mean 5.84 3.06 3.76 1.20
std 0.83 0.44 1.77 0.76
min 4.30 2.00 1.00 0.10
25% 5.10 2.80 1.60 0.30
50% 5.80 3.00 4.35 1.30
75% 6.40 3.30 5.10 1.80
max 7.90 4.40 6.90 2.50
在“种类”列上调用describe方法可以确认它包含三个唯一值。我们预先知道数据由样本所属的三个类别组成,尽管在没有老师的情况下机器学习并非总是如此。In [16]: iris_df['species'].describe()
Out[16]:
count 150
unique 3
top setosa
freq 50
Name: species, dtype: object
14.7.3。Pairplot数据集可视化
我们将可视化此数据集中的特征。提取有关数据信息的一种方法是查看属性之间的相互关系。数据集具有四个属性。我们将无法在一个图中构造一个属性与其他三个属性的对应关系的图。但是,可以构建一个图表,在该图表上将显示两个特征之间的对应关系。片段[20]使用Seaborn库的pairplot函数创建图表表,其中每个功能都映射到其他功能之一:In [17]: import seaborn as sns
In [18]: sns.set(font_scale=1.1)
In [19]: sns.set_style('whitegrid')
In [20]: grid = sns.pairplot(data=iris_df, vars=iris_df.columns[0:4],
...: hue='species')
...:
关键参数:- 一个DataFrame集合,在图表上绘制了一个数据集;
- vars-具有在图表上绘制的变量名称的序列。对于DataFrame集合,它包含列名。在这种情况下,将使用DataFrame的前四列,分别代表外花被的长度(宽度)和内花被的长度(宽度)。
- hue是DataFrame集合的一列,用于确定图表上绘制的数据的颜色。在这种情况下,数据将根据光圈的类型进行着色。
上一个对图调用构建了以下4×4图表表: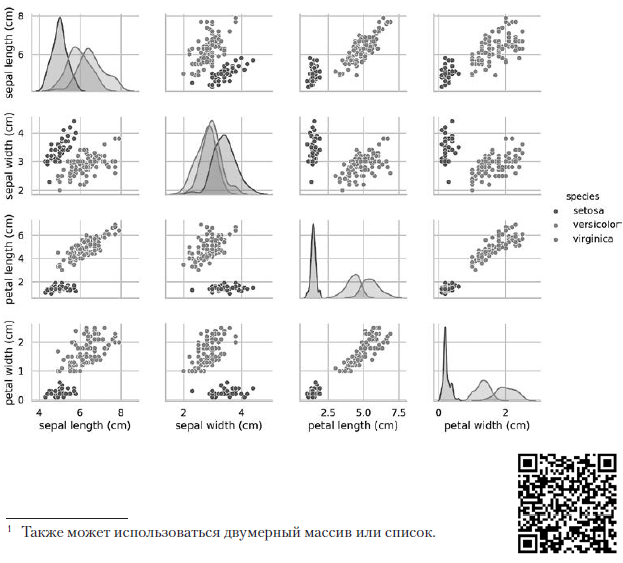 从左上角到右下角的对角线上的图显示了此列中显示的属性的分布,其值范围(从左到右)和具有这些值的样本数(从上到下) 。取外花被的长度分布:
从左上角到右下角的对角线上的图显示了此列中显示的属性的分布,其值范围(从左到右)和具有这些值的样本数(从上到下) 。取外花被的长度分布: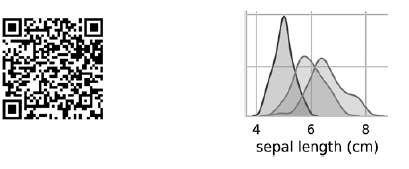 最高的阴影区域表示鸢尾鸢尾花的外部花被瓣长度(沿x轴)约为4-6厘米,对于大多数鸢尾鸢尾样品,其值在该范围的中间(约5厘米)。极右阴影区域表明,鸢尾属物种的花被外部花被瓣的长度范围(沿x轴)约为4-8.5厘米,对于大多数鸢尾属样品,其值在6至7厘米之间。在其他图中,该列显示了其他特征相对于沿x轴的特征的数据散布图。在第一列中,在前三张图中,y轴分别显示外花被的宽度,内花被的长度和内花被的宽度,x轴显示外花被的长度。执行此代码后,屏幕上会出现彩色图像,以单个字符的级别显示不同类型的虹膜之间的关系。有趣的是,在所有图中,鸢尾鸢尾的蓝色点与其他物种的橙色和绿色点明显分开;这表明鸢尾鸢尾确实是一个单独的类。您还可以注意到,有时会混淆其他两个物种,如橙色和绿色点重叠所示。例如,花被外瓣的宽度和长度的图显示,鸢尾花和鸢尾花的点混合在一起。这表明,如果仅可测量到花被片外缘,则将很难区分这两个物种。
最高的阴影区域表示鸢尾鸢尾花的外部花被瓣长度(沿x轴)约为4-6厘米,对于大多数鸢尾鸢尾样品,其值在该范围的中间(约5厘米)。极右阴影区域表明,鸢尾属物种的花被外部花被瓣的长度范围(沿x轴)约为4-8.5厘米,对于大多数鸢尾属样品,其值在6至7厘米之间。在其他图中,该列显示了其他特征相对于沿x轴的特征的数据散布图。在第一列中,在前三张图中,y轴分别显示外花被的宽度,内花被的长度和内花被的宽度,x轴显示外花被的长度。执行此代码后,屏幕上会出现彩色图像,以单个字符的级别显示不同类型的虹膜之间的关系。有趣的是,在所有图中,鸢尾鸢尾的蓝色点与其他物种的橙色和绿色点明显分开;这表明鸢尾鸢尾确实是一个单独的类。您还可以注意到,有时会混淆其他两个物种,如橙色和绿色点重叠所示。例如,花被外瓣的宽度和长度的图显示,鸢尾花和鸢尾花的点混合在一起。这表明,如果仅可测量到花被片外缘,则将很难区分这两个物种。输出对图以一种颜色显示
如果删除了hue key参数,则pairplot函数仅使用一种颜色来输出所有数据,因为它不知道如何区分输出中的视图:In [21]: grid = sns.pairplot(data=iris_df, vars=iris_df.columns[0:4])
从下图可以看出,在这种情况下,对角线上的图是具有该属性所有值分布的直方图,与类型无关。在研究图时,尽管我们知道数据集包含三种类型,但似乎只有两个簇。如果不知道簇数,那么您可以联系熟悉数据的主题领域的专家。专家可能知道数据集中存在三种数据。使用数据进行机器学习时,此信息会派上用场。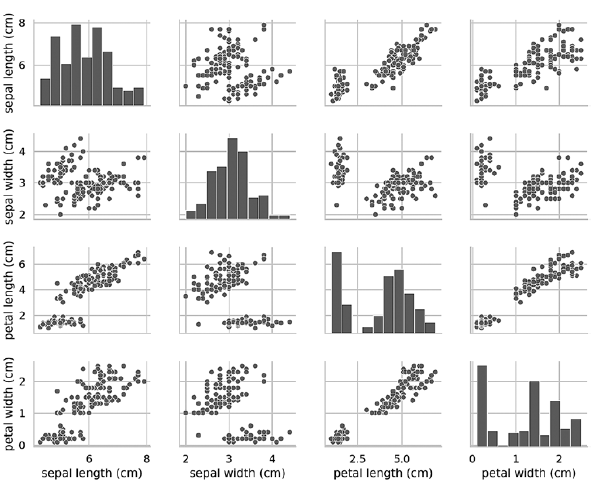 成对图可以很好地与少量特征或特征子集配合使用,从而限制行和列的数量,并与相对少量的图案配合使用,从而可以看到数据点。随着特征和模式数量的增加,数据散点图变得太小而无法读取数据。在大型数据集中,您可以在图表上绘制特征的子集,还可以选择随机选择模式的子集,以对数据有所了解。»有关这本书的更多信息,可以在出版商的网站上找到和购买
成对图可以很好地与少量特征或特征子集配合使用,从而限制行和列的数量,并与相对少量的图案配合使用,从而可以看到数据点。随着特征和模式数量的增加,数据散点图变得太小而无法读取数据。在大型数据集中,您可以在图表上绘制特征的子集,还可以选择随机选择模式的子集,以对数据有所了解。»有关这本书的更多信息,可以在出版商的网站上找到和购买