现在,编程越来越深入到生活的各个领域。也许这要归功于现在非常流行的python。如果是5年前的数据分析,则必须使用一整套完整的各种工具:用于卸载(或笔)的C#,Excel,MatLab,SQL,并不断在其中“跳转”,清理,检查和协调数据。现在,由于拥有大量出色的库和模块,python首先可以近似安全地替换所有这些工具,并且与SQL结合使用时,通常“山峰可以卷起来”。那我在做什么 我对学习如此受欢迎的python感兴趣。众所周知,最好的学习方法是练习。我也对房地产感兴趣。我遇到了一个有关莫斯科房地产的有趣问题:要按平均odnushka的平均租金来对莫斯科地区进行排名?父亲,我想,这里是地理位置,可以从站点上载,还可以进行数据分析-这是一项艰巨的实际任务。受到Habré上精彩文章的启发(在文章结尾,我将添加链接),让我们开始吧!我们的任务是浏览python内部现有的工具,分解该技术-如何解决此类问题并乐于花时间,而不仅仅是受益。- 刮青色
- 单数据帧
- 数据框处理
- 结果
- 有关使用地理数据的一些知识
刮青色
到2020年3月中旬,有可能收集到近9000份关于在莫斯科租用青色的一居室公寓的建议,该网站显示了54页。我们将使用jupyter-notebook 6.0.1,python 3.7。我们从站点上载数据,并使用请求库将其保存到文件中。为了使网站不受禁止,我们会通过添加请求延迟和设置标题来伪装成一个人,以便从网站的侧面看起来像一个非常聪明的人通过浏览器发出请求。不要忘记每次都检查站点的响应,否则我们会突然被发现并且已经被禁止。您可以阅读有关网站抓取的越来越详细的信息,例如,在这里:使用python进行网站抓取。添加装饰器以评估我们的功能和记录速度也很方便。设置级别= logging.INFO允许您指定日志中显示的消息类型。您也可以配置模块以将日志输出到文本文件,对于我们来说这是不必要的。编码def timer(f):
def wrap_timer(*args, **kwargs):
start = time.time()
result = f(*args, **kwargs)
delta = time.time() - start
print (f' {f.__name__} {delta} ')
return result
return wrap_timer
def log(f):
def wrap_log(*args, **kwargs):
logging.info(f" {f.__doc__}")
result = f(*args, **kwargs)
logging.info(f": {result}")
return result
return wrap_log
logging.basicConfig(level=logging.INFO)
@timer
@log
def requests_site(N):
headers = ({'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.5 Safari/605.1.15'})
pages = [106 + i for i in range(N)]
n = 0
for i in pages:
s = f"https://www.cian.ru/cat.php?deal_type=rent&engine_version=2&page={i}&offer_type=flat®ion=1&room1=1&type=-2"
response = requests.get(s, headers = headers)
if response.status_code == 200:
name = f'sheets/sheet_{i}.txt'
with open(name, 'w') as f:
f.write(response.text)
n += 1
logging.info(f" {i}")
else:
print(f" {i} response.status_code = {response.status_code}")
time.sleep(np.random.randint(7,13))
return f" {n} "
requests_site(300)
单数据帧
对于抓取页面,请选择BeautifulSoup和lxml。我们仅将“美丽汤”作为其很酷的名称,尽管他们说lxml更快。您可以做的很漂亮,使用os库从文件夹中获取文件列表,过滤掉所需的扩展名并逐一检查。但是,由于我们知道文件的确切数量及其确切名称,因此我们将使其变得更容易。除非我们使用进度条的形式添加装饰,否则请使用tqdm库编码
from bs4 import BeautifulSoup
import re
import pandas as pd
from dateutil.parser import parse
from datetime import datetime, date, time
def read_file(filename):
with open(filename) as input_file:
text = input_file.read()
return text
import tqdm
site_texts = []
pages = [1 + i for i in range(309)]
for i in tqdm.tqdm(pages):
name = f'sheets/sheet_{i}.txt'
site_texts.append(read_file(name))
print(f" {len(site_texts)} .")
def parse_tag(tag, tag_value, item):
key = tag
value = "None"
if item.find('div', {'class': tag_value}):
if key == 'link':
value = item.find('div', {'class': tag_value}).find('a').get('href')
elif (key == 'price' or key == 'price_meter'):
value = parse_digits(item.find('div', {'class': tag_value}).text, key)
elif key == 'pub_datetime':
value = parse_date(item.find('div', {'class': tag_value}).text)
else:
value = item.find('div', {'class': tag_value}).text
return key, value
def parse_digits(string, type_digit):
digit = 0
try:
if type_digit == 'flats_counts':
digit = int(re.sub(r" ", "", string[:string.find("")]))
elif type_digit == 'price':
digit = re.sub(r" ", "", re.sub(r"₽", "", string))
elif type_digit == 'price_meter':
digit = re.sub(r" ", "", re.sub(r"₽/²", "", string))
except:
return -1
return digit
def parse_date(string):
now = datetime.strptime("15.03.20 00:00", "%d.%m.%y %H:%M")
s = string
if string.find('') >= 0:
s = "{} {}".format(now.day, now.strftime("%b"))
s = string.replace('', s)
elif string.find('') >= 0:
s = "{} {}".format(now.day - 1, now.strftime("%b"))
s = string.replace('',s)
if (s.find('') > 0):
s = s.replace('','mar')
if (s.find('') > 0):
s = s.replace('','feb')
if (s.find('') > 0):
s = s.replace('','jan')
return parse(s).strftime('%Y-%m-%d %H:%M:%S')
def parse_text(text, index):
tag_table = '_93444fe79c--wrapper--E9jWb'
tag_items = ['_93444fe79c--card--_yguQ', '_93444fe79c--card--_yguQ']
tag_flats_counts = '_93444fe79c--totalOffers--22-FL'
tags = {
'link':('c6e8ba5398--info-section--Sfnx- c6e8ba5398--main-info--oWcMk','undefined c6e8ba5398--main-info--oWcMk'),
'desc': ('c6e8ba5398--title--2CW78','c6e8ba5398--single_title--22TGT', 'c6e8ba5398--subtitle--UTwbQ'),
'price': ('c6e8ba5398--header--1df-X', 'c6e8ba5398--header--1dF9r'),
'price_meter': 'c6e8ba5398--term--3kvtJ',
'metro': 'c6e8ba5398--underground-name--1efZ3',
'pub_datetime': 'c6e8ba5398--absolute--9uFLj',
'address': 'c6e8ba5398--address-links--1tfGW',
'square': ''
}
res = []
flats_counts = 0
soup = BeautifulSoup(text)
if soup.find('div', {'class': tag_flats_counts}):
flats_counts = parse_digits(soup.find('div', {'class': tag_flats_counts}).text, 'flats_counts')
flats_list = soup.find('div', {'class': tag_table})
if flats_list:
items = flats_list.find_all('div', {'class': tag_items})
for i, item in enumerate(items):
d = {'index': index}
index += 1
for tag in tags.keys():
tag_value = tags[tag]
key, value = parse_tag(tag, tag_value, item)
d[key] = value
results[index] = d
return flats_counts, index
from IPython.display import clear_output
sum_flats = 0
index = 0
results = {}
for i, text in enumerate(site_texts):
flats_counts, index = parse_text(text, index)
sum_flats = len(results)
clear_output(wait=True)
print(f" {i + 1} flats = {flats_counts}, {sum_flats} ")
print(f" sum_flats ({sum_flats}) = flats_counts({flats_counts})")
一个有趣的细微差别是,页面顶部指示的数字表示应要求提供的公寓总数在不同页面之间有所不同。因此,在我们的示例中,默认排序的这5,402个句子在5343到5402的范围内,随着请求的页数增加(而不是所显示的广告数量)而逐渐减少。此外,可以继续卸载超出站点指示的页面数限制的页面。在我们的案例中,该网站上仅提供了54页,但是我们仅使用较旧的广告就可以卸载309页,共计8640套公寓出租广告。对这一事实的调查将不在本文的讨论范围之内。数据框处理
因此,我们有一个包含8640个报价的原始数据的数据框。我们将对各地区的平均价格和中位数进行表面分析,计算出公寓每平方米的平均租金价格以及该地区“平均”的公寓成本。我们将根据以下假设进行研究:- 缺乏重复性:找到的所有公寓都是真正的现有公寓。在第一阶段,我们消除了地址和正交位置上的重复单元,但是如果单元的正交或地址略有不同,我们将这些选项视为不同的单元。
- — .
— «» ? ( ) , , , , . , , , . «» : . «» ( ) , .
我们将需要:price_per_month - 每月的价格租卢布广场 -梁州区-区,在这项研究中完整的地址是不是让我们感兴趣price_meter -每1平方米租赁价格编码df['price_per_month'] = df['price'].str.strip('/.').astype(int)
new_desc = df["desc"].str.split(",", n = 3, expand = True)
df["square"]= new_desc[1].str.strip(' ²').astype(int)
df["floor"]= new_desc[2]
new_address = df['address'].str.split(',', n = 3, expand = True)
df['okrug'] = new_address[1].str.strip(" ")
df['price_per_meter'] = (df['price_per_month'] / df['square']).round(2)
df = df.drop(['index','metro', 'price_meter','link', 'price','desc','address','pub_datetime','floor'], axis='columns')
现在,我们将根据时间表手动“处理”排放物。为了可视化数据,让我们看一下三个库:matplotlib,seaborn和plotly。数据直方图。Matplotlib使您可以快速轻松地显示我们感兴趣的数据组的所有图表,而我们不需要更多。下图删除了该图,根据该图,在Mitino中只有一项建议不能用作对普通公寓的定性评估。南部行政区的另一幅有趣的图画:租金低于1000卢布的大多数报价(超过500个单位),每平方米报价(近300个单位)激增1700卢布。将来,您会明白为什么会这样-在这些公寓的其他指标中翻阅。只需一行代码就可以给出分组数据集的直方图:hists = df['price_per_meter'].hist(by=df['okrug'], figsize=(16, 14), color = "tab:blue", grid = True)
 价值的分散。下面显示了使用所有三个库的图。seaborn默认情况下是更加美观亮丽,但plotly可以让你当你的鼠标,这是非常有利于我们选择“离群”,我们将删除的值立即显示值。matplotlib
价值的分散。下面显示了使用所有三个库的图。seaborn默认情况下是更加美观亮丽,但plotly可以让你当你的鼠标,这是非常有利于我们选择“离群”,我们将删除的值立即显示值。matplotlibfig, axes = plt.subplots(nrows=4,ncols=3,figsize=(15,15))
for i, (name, group) in enumerate(df_copy.groupby('okrug')):
axes = axes.flatten()
axes[i].scatter(group['price_per_meter'],group['square'], color ='blue')
axes[i].set_title(name)
axes[i].set(xlabel=' 1 ..', ylabel=', 2')
fig.tight_layout()
 海博恩
海博恩sns.pairplot(vars=["price_per_meter","square"], data=df_copy, hue="okrug", height=5)
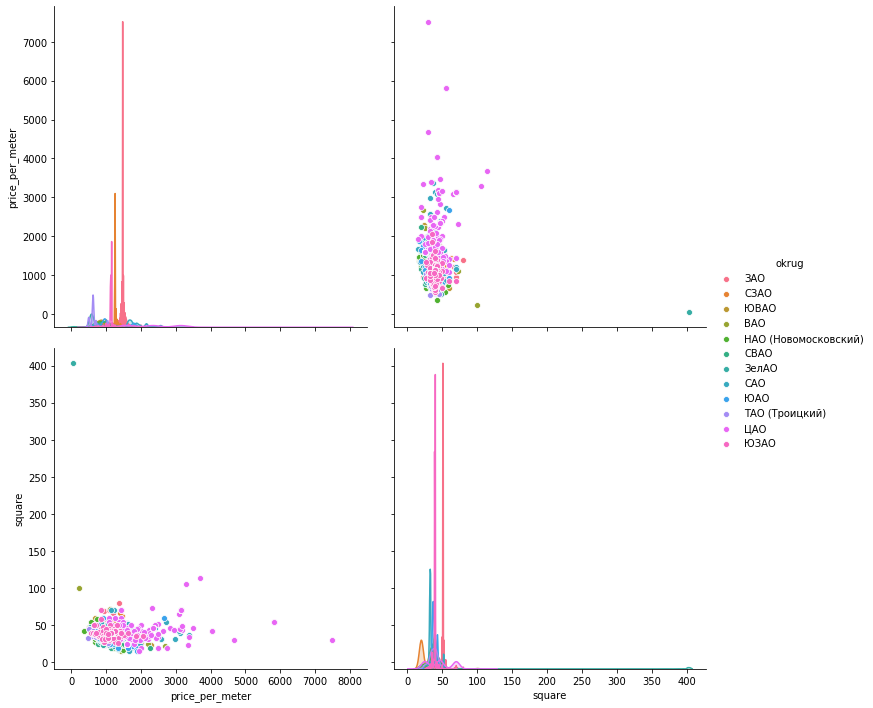 plotly我认为会有一个区足够的例子。
plotly我认为会有一个区足够的例子。import plotly.express as px
for i, (name, group) in enumerate(df_copy.groupby('okrug')):
fig = px.scatter(group, x="price_per_meter", y="square", facet_col="okrug",
width=400, height=400)
fig.update_layout(
margin=dict(l=20, r=20, t=20, b=20),
paper_bgcolor="LightSteelBlue",
)
fig.show()
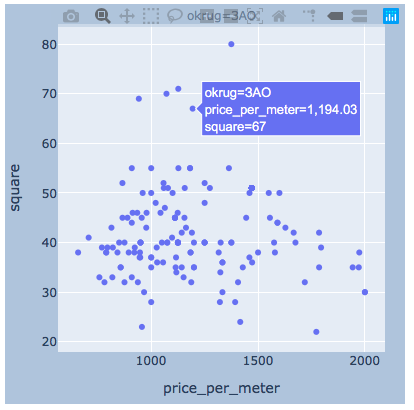
结果
因此,在清理了数据,巧妙地消除了排放之后,我们提供了8602个“清洁”报价。接下来,我们根据数据计算的主要统计数据:平均,中位数,标准差,我们得到了莫斯科地区的以下评级为平均公寓的平均租金跌幅: 您可以通过比较得出美丽的直方图,例如,平均值和中位数价格在区:
您可以通过比较得出美丽的直方图,例如,平均值和中位数价格在区: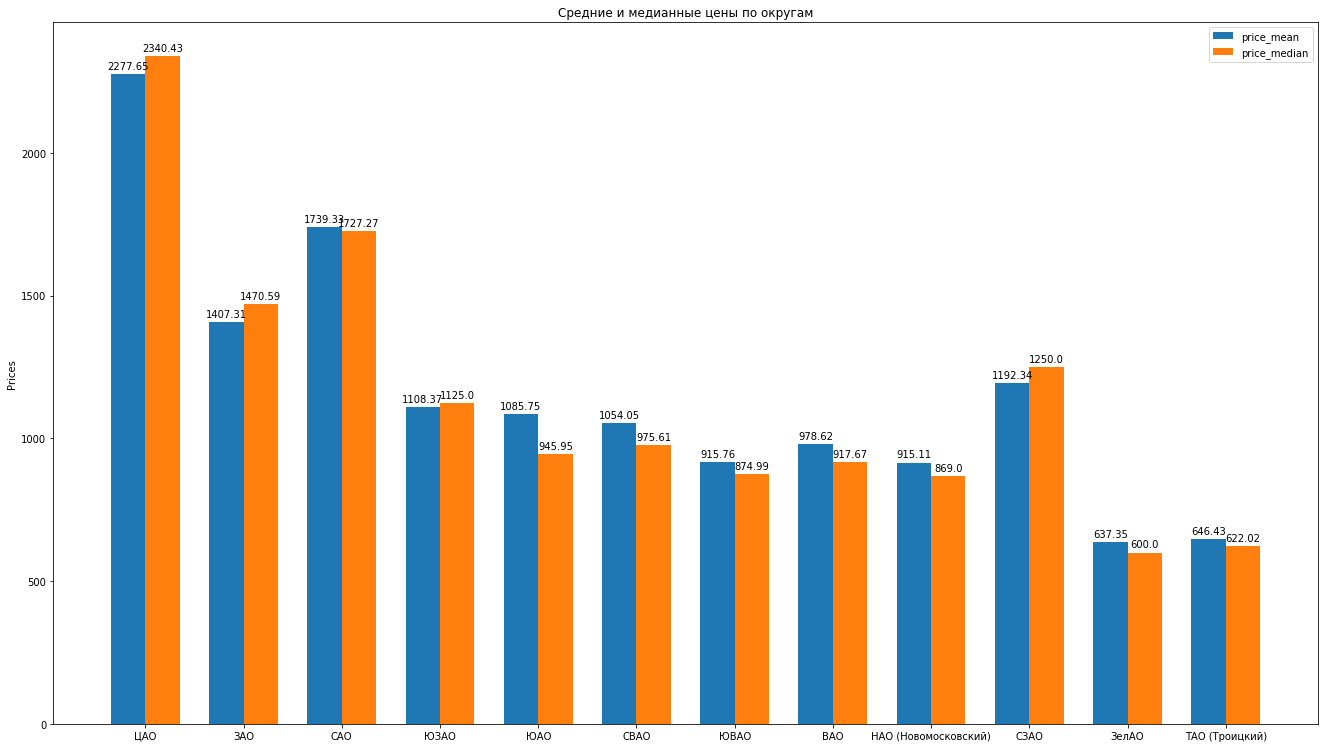 还有什么可以根据数据说出出租公寓提案的结构:
还有什么可以根据数据说出出租公寓提案的结构:- , , , . “” , ( ). , , , , , , “” . , , .
- . . « ». , «» — . . . , , , , , - , , . . .
- , “” , . , , — .
地理数据是一个单独的,令人难以置信的,美丽的章节,它是与地图相关的数据显示。您可以在以下文章中查看非常详细的内容:使用Jupitter笔记本电脑Likbez中的地图在莫斯科地图上的选举结果的可视化,以及使用OpenStreetMap 图像作为地理数据源的制图投影。简而言之,OpenStreetMap是我们的一切,便捷的工具是:geopandas,cartoframes(他们说已经是死了?)和叶,我们将使用它们。这就是我们的数据在交互式地图上的样子。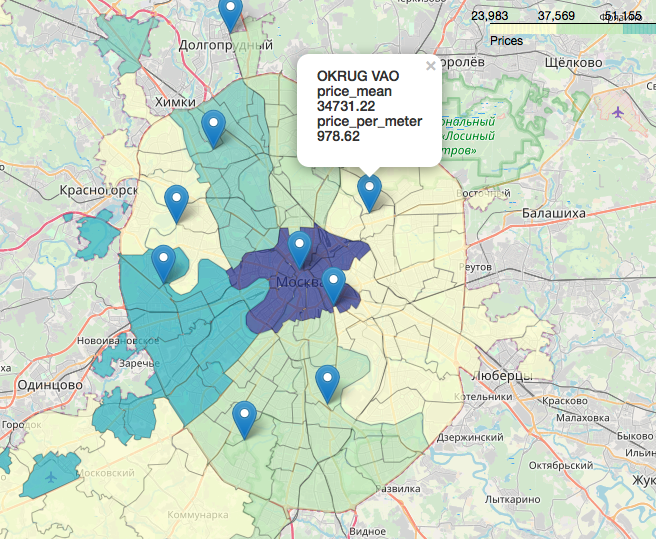 事实证明对本文工作有用的材料:我希望你像我一样有兴趣。感谢您的阅读。欢迎进行建设性的批评。源和数据集在这里的github上发布。
事实证明对本文工作有用的材料:我希望你像我一样有兴趣。感谢您的阅读。欢迎进行建设性的批评。源和数据集在这里的github上发布。