标准标头的压缩出现在HTTP / 2中,但是URI,Cookie,User-Agent值的正文仍可能是数十个千字节,并且需要标记化,搜索和比较子字符串。如果HTTP解析器需要处理大量恶意流量,则该任务就变得至关重要。标准库提供了广泛的字符串处理工具,但是HTTP字符串具有其自身的特性。为此,开发了Tempesta FW HTTP解析器。与现代开放源代码解决方案相比,其性能要高出数倍,并且超过了最快的解决方案。亚历山大·克里兹哈诺夫斯基(克里扎诺夫斯基)的创始人和系统架构师Tempesta Technologies,Linux / x86-64高性能计算专家。 Alexander将讨论HTTP字符串结构的特殊性,解释为什么标准库不适合处理它们,并介绍Tempesta FW解决方案。在猫之下:HTTP Flood如何将您的HTTP解析器变成瓶颈,在典型的HTTP解析器任务上出现分支错误预测,缓存和内存不足内存的x86-64问题,将FSM与直接跳转,GCC优化,自动矢量化,strspn()进行比较-和strcasecmp()-类似于HTTP字符串,SSE,AVX2和使用AVX2过滤注入攻击的算法。在Tempesta Technologies,我们开发定制软件:我们专注于与高性能相关的复杂领域。我们特别为Positive Technologies第一版WAF的核心开发感到自豪。Web应用程序防火墙(WAF)是HTTP代理:它对HTTP流量的攻击(Web和DDoS)进行了非常深入的分析。我们为此编写了第一个核心。除了咨询之外,我们还在开发Tempesta FW-这是应用程序交付控制器(ADC)。我们将谈论他。应用交付控制器
Application Delivery Controller是具有增强功能的HTTP代理。但是,我将讨论与安全性相关的功能-有关过滤DDoS和Web攻击。我还将提到这些限制,并通过代码示例展示其工作和功能。
性能
Tempesta FW内置在Linux TCP / IP Stack内核中。借助此功能和许多其他优化,它非常快-它可以在廉价的硬件上每秒处理180万个请求。在最高负载下,这比Nginx快3倍,并且与内核旁路方法相比也快。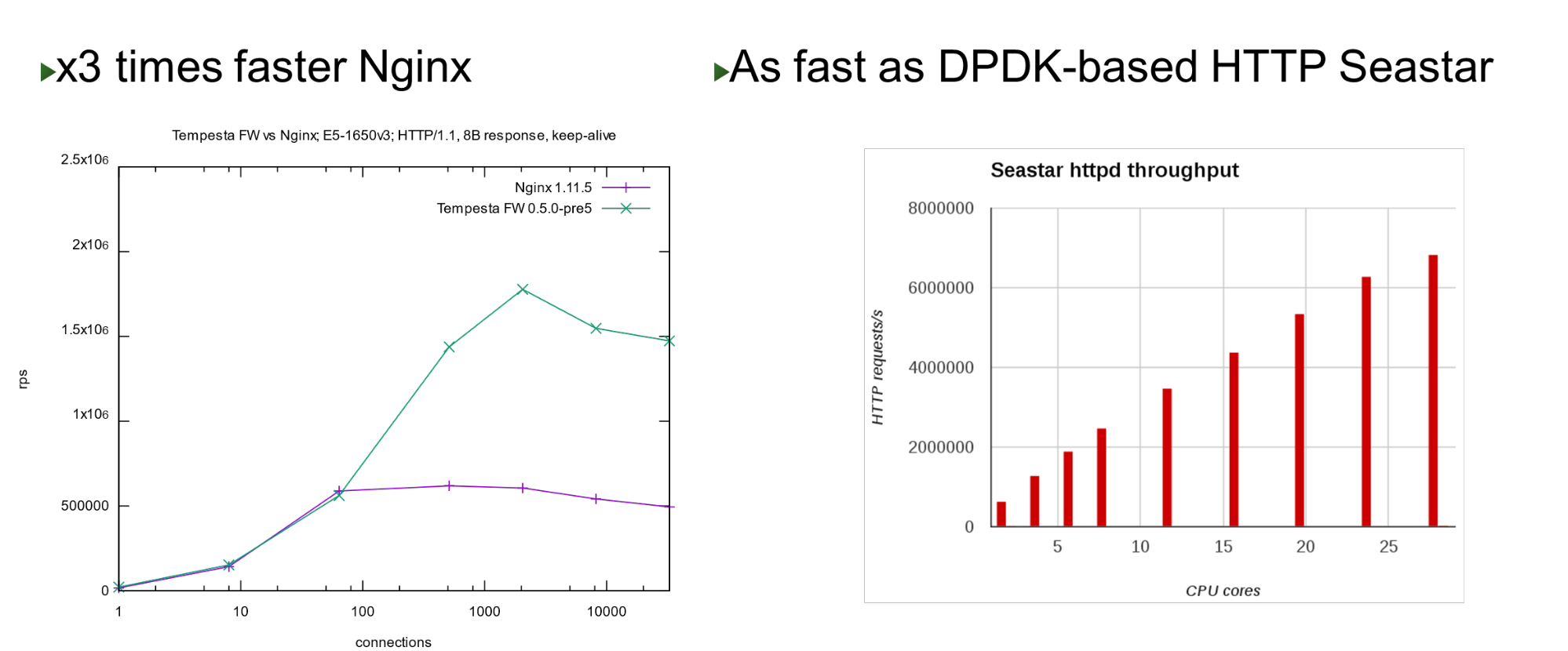 在少数内核上,它与ScyllaDB(用DPDK编写)中使用的Seastar项目显示出相似的性能。
在少数内核上,它与ScyllaDB(用DPDK编写)中使用的Seastar项目显示出相似的性能。问题
该项目诞生于我们在2013年开始进行PT AF时。该WAF基于一种流行的开源HTTP加速器。Nginx,HAProxy,Varnish或Apache Traffic是很好的HTTP加速器:它们可以提供内容精细,缓存,修改的功能,但是它们都不是为大量流量处理和过滤而设计的。因此,我们认为如果有网络级防火墙,为什么不继续这个想法并将其集成为TCP / IP堆栈作为应用程序级防火墙?实际上,事实证明Tempesta FW 是HTTP加速器和防火墙的混合体。注意:Nginx将作为报告中的示例,因为它是一个简单且流行的Web服务器。相反,可能有其他任何开放源HTTP服务器。HTTP
让我们看一下我们的HTTP请求(HTTP /(1,〜2))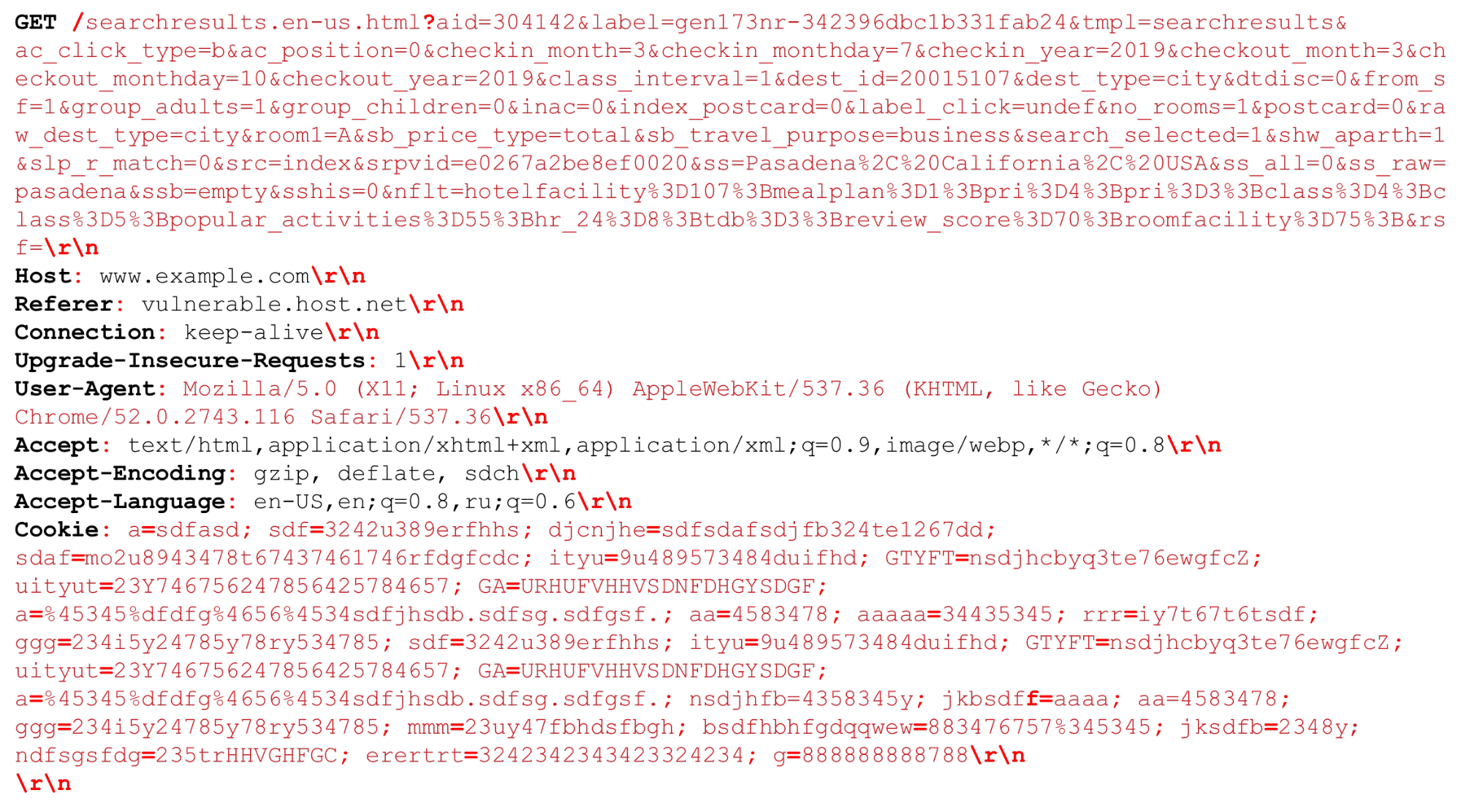 我们可以有一个非常大的URI。在HTTP解析时重要的分隔符以红色粗体突出显示。我将重点介绍这些功能:几千字节的大字符串以及不同的定界符,例如,我们需要解析的其他“分号”或序列“ \ r \ n”。还需要讲一点有关HTTP / 2的知识。
我们可以有一个非常大的URI。在HTTP解析时重要的分隔符以红色粗体突出显示。我将重点介绍这些功能:几千字节的大字符串以及不同的定界符,例如,我们需要解析的其他“分号”或序列“ \ r \ n”。还需要讲一点有关HTTP / 2的知识。HTTP / 2功能
HTTP / 2是字符串和二进制数据的混合体。这种混合更多地是关于优化连接带宽而不是节省服务器资源。HPACK中的HTTP / 2使用动态表。来自客户端的第一个请求未优化,不在表中。您必须对其进行分析,以便将其添加到表中。如果使用HTTP / 2 DDoS,情况就是这样。在正常情况下,HTTP / 2是一个二进制协议,但是您仍然需要解析文本:文本标题名称,数据。霍夫曼编码。这是一种简单的编码,但是Huffman难以快速编程以进行压缩:Huffman编码越过字节边界,您不能使用向量扩展名,而需要按字节进行编码。您将无法快速处理32或16字节的数据。Cookies,User-Agent,Referer,URI可能非常大。首先,删除Huffman,然后将其发送到与HTTP / 1中相同的常规HTTP解析器。尽管RFC允许,但不建议压缩cookie,因为它是机密数据-您不应向攻击者提供有关其大小的信息。HTTP处理缓慢。所有HTTP服务器首先解码HTTP / 2,然后将这些行发送到HTTP / 1已经使用的HTTP / 1解析器。HTTP / 1解析有什么问题?- 您需要快速对状态机进行编程。
- 您需要快速处理连续的行。
恶意流量的目标是过程中最慢(最弱)的部分。因此,如果要制作过滤器,必须注意较慢的部分,以便它们也可以快速工作。Nginx个人资料
让我们看一下HTTP泛洪下的Nginx配置文件。禁用访问日志,以使文件系统不会变慢。当甚至请求常规索引页时,解析器都位于顶部。左-“平面轮廓”。有趣的是,其中最热的点不比下一个重,并且轮廓之后平滑下降。例如,这意味着两次优化第一个功能将无助于显着提高性能。这就是为什么我们没有优化相同的Nginx,而是创建了一个新项目来改善配置文件整个尾部的性能的原因。常规HTTP解析器的编码方式
通常,我们有一个while沿线运行的循环()和两个变量:状态(state)和当前数据(str_ptr)。我们进入循环(1),然后查看当前状态(检查状态)。我们传递给接收的数据(符号'b')并实现一些逻辑。我们进入第二状态(2)。 转到末尾
转到末尾switch(3)-这是相对于代码开头的第二次转换,并且可能是指令高速缓存中的第二次未命中。然后我们开始while(4),吃下一个字符 ……,然后在里面的指令中再次查找状态
……,然后在里面的指令中再次查找状态case 2:。当一个变量已经被分配一个state值2,我们可以直接转到下一条指令。但是相反,他们又上升又下降了。我们通过代码“切圆”,而不仅仅是走下坡路。普通解析器不会,例如,Ragel生成具有直接转换的解析器。
Nginx HTTP解析器
关于Nginx解析器及其环境的几句话。Nginx使用普通的套接字API-传递到适配器的数据将复制到用户空间。结果,我们有一个庞大的数据块,我们正在寻找所需的数据。Nginx使用一种算法,该算法分两次进行:首先搜索长度,然后进行检查。第一步,他在字符串中扫描令牌,搜索第一个令牌(“试用版”)。在第二个令牌上,根据令牌的大小检查请求的结尾(Get),然后启动switch。for (p = b->pos; p < b->last; p++) {
...
switch (state) {
...
case sw_method:
if (ch == ' ') {
m = r->request_start;
switch (p - m) {
case 3:
if (ngx_str3_cmp(m, 'G', 'E', 'T', ' ')) {
...
}
if ((ch < 'A' || ch > 'Z') && ch != '_' && ch != '-')
return NGX_HTTP_PARSE_INVALID_METHOD;
break;
...
“获取”始终位于相同的数据块中。Tempesta FW使用零副本。这意味着数据可以具有完全任意的大小:每个1字节或1000字节。这种“机制”不适合我们。让我们看看它如何switch在GCC中工作。海湾合作委员会
查找表。左侧是一个典型的枚举示例:以0开头,然后是连续的标签,26个常量,然后是一些处理所有这些的代码。右边是编译器生成的代码。 首先,将
首先,将stateEAX寄存器中的变量与常量进行比较。接下来,我们以8个字节的指针顺序数组(查找表)的形式显示所有标签。在此指令上,我们在此数组中传递偏移量-它是指针的双重解引用。右下角是我们从该表切换到的代码。事实证明,对内存进行了双重解引用:如果我们接收到秘密数据,则可以通过字节找到数组中的地址并转到该指针。重要的是要知道,生活仍然比示例中的情况更糟-对于查找表,编译器生成如果是针对Spectre攻击的脚本,则代码会更加复杂。二进制搜索。下一种情况switch不是使用顺序常量,而是使用任意常量。代码是一样的,但是现在GCC不能编译这么大的数组,并且不能使用常量作为数组的索引。他切换到二进制搜索。 在右侧,我们看到了顺序比较,到地址的转换以及比较的继续-二进制搜索是通过代码进行的。Nginx HTTP解析器。让我们看看什么是状态机nginx。它具有9 KB的代码-比启动基准测试的计算机上的一级缓存(如大多数x86-64处理器)少三倍。
在右侧,我们看到了顺序比较,到地址的转换以及比较的继续-二进制搜索是通过代码进行的。Nginx HTTP解析器。让我们看看什么是状态机nginx。它具有9 KB的代码-比启动基准测试的计算机上的一级缓存(如大多数x86-64处理器)少三倍。$ nm -S /opt/nginx-1.11.5/sbin/nginx
| grep http_parse | cut -d' ' -f 2
| perl -le '$a += hex($_) while (<>); print $a'
9220
$ getconf LEVEL1_ICACHE_SIZE
32768
$ grep -c 'case sw_' src/http/ngx_http_parse.c
84
Nginx标头解析器ngx_http_parse_header_line ()是一个简单的令牌生成器。它对标头的值及其名称不执行任何操作,而只是将HTTP标头的令牌放入哈希中。如果需要任何标题值,请扫描标题表并重复分析。出于安全原因,我们必须严格检查标题的名称和值。Tempesta FW:HTTP字符串的字符串验证
我们的状态机功能强大了一个数量级:我们执行RFC标头验证,并立即在解析器中处理几乎所有内容。如果nginx有80个州,那么我们有520个州,并且有更多的州。如果我们继续行驶switch,那将是10倍。我们拥有零拷贝的I / O-不同大小的块可以在不同位置切割数据。不同的块可以切割我们的数据。例如,在零拷贝I / O中,“ GET”可能(很少)以“ GET”,“ GE”和“ T”或“ G”,“ E”和“ T”的形式出现,因此您需要在数据之间存储状态。实际上,我们消除了I / O的成本,但是在配置文件中它却飞速发展-一切都很糟糕。大型HTTP解析器是项目中最关键的位置之一。$ grep -c '__FSM_STATE\|__FSM_TX\|__FSM_METH_MOVE\|__TFW_HTTP_PARSE_' http_parser.c
520
7.64% [tempesta_fw] [k] tfw_http_parse_req
2.79% [e1000] [k] e1000_xmit_frame
2.32% [tempesta_fw] [k] __tfw_strspn_simd
2.31% [tempesta_fw] [k] __tfw_http_msg_add_str_data
1.60% [tempesta_fw] [k] __new_pgfrag
1.58% [kernel] [k] skb_release_data
1.55% [tempesta_fw] [k] __str_grow_tree
1.41% [kernel] [k] __inet_lookup_established
1.35% [tempesta_fw] [k] tfw_cache_do_action
1.35% [tempesta_fw] [k] __tfw_strcmpspn
如何改善这种情况?FSM直接推荐
我们要做的第一件事不是使用循环,而是使用标签(go to)直接转换。像Ragel这样的普通解析器生成器可以做到这一点。 我们使用标记
我们使用标记switch和标记C使用相同的名称对每个状态进行编码。每次我们想去的时候,我们都会switch在代码中找到一个标签或直接访问相同的状态。第一次浏览时switch,然后在其中直接进入所需的标签。缺点:当我们要切换到下一个状态时,我们必须立即评估我们是否仍然有可用数据(因为零拷贝I / O)。条件体for它被复制到每个状态:根据状态数,我们有500个状态,而不是常规的开关驱动FSM中的一个状态。为每个状态生成代码不是很好。在大型状态机的情况下,对于for具有大switch的内部,也GTC重复的条件for的代码内数次。替换为switch直接过渡。下一个优化是我们不使用它switch,而是切换为直接跳转到已保存的元地址。进入功能后,我们希望立即转到所需的位置。 GCC允许您执行此操作。 GCC具有标准扩展名,可能会有所帮助。我们取标签名称(此处为
GCC具有标准扩展名,可能会有所帮助。我们取标签名称(此处为from),然后通过双“&”号将其地址分配给某些C变量。现在我们可以做出直接跳转指令jmp到此标签的地址goto。让我们看看结果如何。直接转换效果
在少数状态下,直接转换代码生成器甚至比正常速度慢一点switch。但是对于大型状态机,生产率提高了一倍。如果状态机很小,则最好使用通常的状态机switch。$ grep -m 2 'model name\|bugs' /proc/cpuinfo
model name : Intel(R) Core(TM) i7-6500U CPU @ 2.50GHz
bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf
$ gcc --version|head -1
gcc (GCC) 8.2.1 20181105 (Red Hat 8.2.1-5)
States Switch-driven automaton Goto-driven automaton
7 header_line: 139ms header_line: 156ms
27 request_line: 210ms request_line: 186ms
406 big_header_line: 1406ms goto_big_header_line: 727ms
注意:Tempesta代码比示例更复杂。GitHub具有所有基准测试,因此您可以详细了解所有内容。链接(主HTTP解析器)上提供了原始解析器代码。除此之外,在Tempesta FW中,还有一些较小的解析器,它们更容易使用FSM。为什么直接转换可能会更慢
在状态机中,我们需要处理大量代码,因此(预期)会有很多分支错误预测。让我们根据分支丢失预测进行“概要分析”:perf record -e branch-misses -g ./http_benchmark
406 states: switch - 38% on switch(),
direct jumps - 13% on header value parsing
7,27 states: switch - <18% switch(), up to 40% for()
direct jumps – up to 46% on header & URI parsing
在具有406个状态的大型状态机上,我们花费38%的时间处理中的过渡switch。在具有直接转换的状态机上,热点是行解析。在每种状态下解析字符串都包括检查字符串结尾的条件:for状态机中的条件on switch。perf stat -e L1-icache-load-misses ./http_benchmark
Switch-driven automaton Goto-driven automaton
big FSM code size: 29156 49202
L1-icache-load-misses: 4M 2M
接下来,我们通过事件L1指令高速缓存未命中来分析两种类型的状态机- switch对于直接跳转而言,将近30 KB,对于直接跳转,则约为50 KB(比第一级指令的高速缓存还多)。似乎,如果我们不适合缓存,那么对于这种状态机,应该有很多缓存未命中。但不,它们少2倍。那是因为缓存工作得更好:我们按顺序使用代码,并设法从较早的缓存中提取数据。编译器更改代码顺序
当在上编写状态机代码时go to,我们首先具有在接收到数据时首先要调用的状态:HTTP方法,URI,然后是HTTP标头。在我们遍历数据时,将代码从上到下依次加载到处理器缓存中似乎是合乎逻辑的。但这是完全错误的。如果您看一下汇编代码,您会发现很棒的事情。 左边是我们编程的内容:首先我们解析方法
左边是我们编程的内容:首先我们解析方法GET,POST然后在不太可能的方法之下的某个地方UNLOCK。因此,我们希望看到解析 GET,并在汇编程序的开始POST,然后UNLOCK。但是一切都恰恰相反:GET在中间,POST最后和UNLOCK上面。这是因为编译器不了解数据是如何到达我们的。他根据自己漂亮的代码来分配代码。为了使他以正确的顺序排列代码,我们必须使用编译器barrier。编译器屏障是一个程序集虚拟对象,通过它,编译器将不会重新排序。通过简单地设置此类障碍,我们将生产率提高了4%。STATE(sw_method) {
...
MATCH(NGX_HTTP_GET, "GET ");
MATCH(NGX_HTTP_POST, "POST");
__asm__ __volatile__("": : :"memory");
...
METH_MOVE(Req_MethU, 'N', Req_MethUn);
METH_MOVE(Req_MethUn, 'L', Req_MethUnl);
METH_MOVE(Req_MethUnl, 'O', Req_MethUnlo);
METH_MOVE(Req_MethUnlo, 'C', Req_MethUnloc);
METH_MOVE_finish(Req_MethUnloc, 'K', NGX_HTTP_UNLOCK)
用自己的方式编写代码
由于编译器没有按照我们的要求排列数据,因此我们将进行探查器引导的优化(在探查器的控制下进行优化)。Profiler引导式优化(PGO)是样本总数,而不是调用序列。例如,与方法分析相比,URI接收的样本更多,因此它将在处理方法之前定位URI处理代码。怎么运行的?我们将编写代码,在上面运行基准测试,将分析结果提供给编译器,然后它将为我们的负载生成最佳代码。但是问题在于它只是编译最热的代码部分,而没有跟踪时间依赖性。如果负载中最大的URI,那么这将是最热门的地方。URI将上升到函数的顶部,并且PGO不会显示方法名称始终在URI之前。因此,PGO不起作用。Req_Method: {
if (likely(PI(p) == CHAR4_INT('G', 'E', 'T', ' '))) {
...
goto Req_Uri;
}
if (likely(PI(p) == CHAR4_INT('P', 'O', 'S', 'T'))) {
...
goto Req_UriSpace;
}
goto Req_Meth_SlowPath;
}
...
Req_Uri:
...
Req_Meth_SlowPath:
...
有什么用?likely/ unlikely 宏(对于Linux内核代码,GCC内在函数在用户空间中可用__builtin_expect())。他们说要靠近的代码。例如,可能报告请求主体应紧随其后if。然后,预取代码(预取处理器)将选择该代码,一切都会很快。 图片显示了解析方法的开始,结束和障碍。我们没想到看到障碍后面的代码。看来这不应该-我们已经设置了障碍。但是现实中会发生什么呢?编译器看到了
图片显示了解析方法的开始,结束和障碍。我们没想到看到障碍后面的代码。看来这不应该-我们已经设置了障碍。但是现实中会发生什么呢?编译器看到了likely条件-很可能我们将输入条件的主体,然后我们将切换到无条件跳转到标签Req_Uri。事实证明,在“热路径”中未处理我们条件之后的代码。if尽管有障碍,编译器仍将代码移动到标签后面的标签下,因为符合热代码条件。为此,GCC进行了扩展:标签的属性hot和cold。他们说哪个标签是热的(最有可能)和哪个标签是冷的(不太可能)。 在这里,我们就
在这里,我们就GET更有可能达成共识,POST然后交给他likely。在这种情况下,URI处理上升,然后POST下降。因为标签是冷的,所以最不可能的状态机的所有其他代码都保持在下面。-昧-O3
让我们看一下编译器优化。首先想到的是不使用O2,而是使用O3-应该更快。但是事实并非如此-O3有时会生成更糟糕的代码。 O3是一些优化的集合。如果我们将它们分别添加到O2中,则会得到不同的选择:某些优化会有所帮助,有些会产生干扰。对于我们的特定代码,我们仅选择那些可以更好地生成代码的优化。我们留下最好的结果-相对于1,838和1,858,这是1,820秒。一些选项以绿色突出显示-这是自动向量化。
O3是一些优化的集合。如果我们将它们分别添加到O2中,则会得到不同的选择:某些优化会有所帮助,有些会产生干扰。对于我们的特定代码,我们仅选择那些可以更好地生成代码的优化。我们留下最好的结果-相对于1,838和1,858,这是1,820秒。一些选项以绿色突出显示-这是自动向量化。自动向量化
来自GCC指南的循环实例。int a[256], b[256], c[256];
void foo () {
for (int i = 0; i < 256; i++)
a[i] = b[i] + c[i];
}
如果我们有一些重复的变量数组,我们可以优化循环-分解为向量。默认情况下,在优化的第三个级别-O3启用自动矢量化:GCC会在可能的情况下生成矢量代码。但是并非所有代码都可以自动向量化(即使原则上也可以向量化)。我们可以启用GCC选项-fopt-info-vec-all,该选项显示已矢量化的内容和未矢量化的内容。我们得到的结果是,对于我们的基准,没有向量化,但是代码仍然生成得更糟。因此,矢量化并不总是有效:有时会减慢代码速度。但是,我们始终可以看到已矢量化的内容和未矢量化的内容,并在必要时关闭矢量化。对齐方式:如何将字符串与GET进行比较?
我们做了一个小小的修改,就像在nginx中一样:我们不按字节分析行,而是int用它们计算和比较行。#define CHAR4_INT(a, b, c, d) ((d << 24) | (c << 16) | (b << 8) | a)
if (p == CHAR4_INT('G', 'E', 'T', ' ')))
我们知道,如果int未对齐,则速度会降低2-3倍。我们写了一个小的基准来证明这一点。$ ./int_align
Unaligned access = 6.20482
Aligned access = 2.87012
Read four bytes = 2.45249
然后尝试对齐int。我们将查看地址是否int对齐,然后用int字节(如果不对齐)进行比较。 (((long)(p) & 3)
? ((unsigned int)((p)[0]) | ((unsigned int)((p)[1]) << 8)
| ((unsigned int)((p)[2]) << 16) | ((unsigned int)((p)[3]) << 24))
: *(unsigned int *)(p));
但事实证明,这种方法的效果更差:full request line: no difference
method only: unaligned - 214ms
aligned - 231ms
bytes - 216ms
简而言之:隔离的,不可优化的基准测试代码与内联的解析器代码之间存在差异,由于大量的代码而失去了优化。进行分析时不会受到任何惩罚。注意:有关为什么在我们的任务中发生这种情况的详细讨论可以在GitHub上阅读。为什么HTTP字符串对我们很重要?
例如,这是一个普通的URI: 如果您对酒店足够挑剔,请前往“预订”并设置一些过滤器,获取一个大于一千字节的URI。Nginx在
如果您对酒店足够挑剔,请前往“预订”并设置一些过滤器,获取一个大于一千字节的URI。Nginx在switch/ 上有一个相当庞大的解析器case。它不能很快地工作。另外,在Tempesta FW的情况下,我们不仅需要解析URI,还需要检查是否有注入。case sw_check_uri:
if (usual[ch >> 5] & (1U << (ch & 0x1f)))
break;
switch (ch) {
case '/':
r->uri_ext = NULL;
state = sw_after_slash_in_uri;
break;
case '.':
r->uri_ext = p + 1;
break;
case ' ':
r->uri_end = p;
state = sw_check_uri_http_09;
break;
case CR:
r->uri_end = p;
r->http_minor = 9;
state = sw_almost_done;
break;
case LF:
r->uri_end = p;
r->http_minor = 9;
goto done;
case '%':
r->quoted_uri = 1;
...
另一个URI:/redir_lang.jsp?lang=foobar%0d%0aContent-Length:%200%0d% 0a%0d%0aHTTP / 1.1%20200%20OK%0d%0aContent-Type:%20text /html%0d%0aContent -长度:%2019%0d%0a%0d%0aShazam </html>。它看起来像第一个,但是有注射剂。您必须深入研究才能理解这一点。让我们进行测试:获取第一个URI,输入wrk,将其设置为nginx,然后看解析nginx会变得非常热。 如果在以前的常规索引查询中清楚地知道解析器已经在顶部,那么它就更热了。
如果在以前的常规索引查询中清楚地知道解析器已经在顶部,那么它就更热了。8.62% nginx [.] ngx_http_parse_request_line
2.52% nginx [.] ngx_http_parse_header_line
1.42% nginx [.] ngx_palloc
0.90% [kernel] [k] copy_user_enhanced_fast_string
0.85% nginx [.] ngx_strstrn
0.78% libc-2.24.so [.] _int_malloc
0.69% nginx [.] ngx_hash_find
0.66% [kernel] [k] tcp_recvmsg
HTTP字符串有什么特别之处?有不同的分隔符' : '和' , ',甚至是行尾,可以是双字节\r\n或单字节\n,这在开头已经讨论过。C线没有0端接-出于安全原因,我们希望更准确地检查要发生的事情。我们有两个帮助解析器的标准功能。strspn:检查字母(字符串中的可用字符),动态编译有效字母,尽管在程序编译阶段就知道该字母。strcasecmp()。无需转换大小写以x与进行比较Foo:。在大多数情况下strcasecmp(),只需遵守/不遵守,您就无需知道行中的位置。
他们工作缓慢。让我们看一下基准,了解它们的问题所在。快速解析器
有几个解析器。Nginx是最简单的解析器,它严格检查RFC符合性。还有PicoHTTPParser(H2O)和Cloudflare解析器。它们可以更快地处理数据,但是可以跳过 RFC不允许的字符。PCMESTRI。解析器使用几种不同的方法。第一个是PCMESTRI指令,该指令在Pico解析器中使用。我们在说明中设置范围。不幸的是,我们可以加载16个字符或8个范围。如果范围仅包含一个字符-请重复。由于此限制,Pico解析器无法完全验证RFC符合性,因为RFC在此位置具有8个以上的范围。 我们将字母加载到寄存器中,加载字符串,执行指令。在出口处,我们快速查看是否有巧合。AVX2-CloudFlare方法。使用AVX2的CloudFlare解析器一次处理32个字节的字符串,而不是使用Pico解析器处理16个字节。 CloudFlare的解析效果更好,因为它已传输到AVX2。
我们将字母加载到寄存器中,加载字符串,执行指令。在出口处,我们快速查看是否有巧合。AVX2-CloudFlare方法。使用AVX2的CloudFlare解析器一次处理32个字节的字符串,而不是使用Pico解析器处理16个字节。 CloudFlare的解析效果更好,因为它已传输到AVX2。 我们将所有字符检查到ASCII表中的空格,所有字符都大于128,并取其间的范围。简单的代码很快。比较PCMESTRI和AVX2。对我们来说,当前的限制是1500。这是我们所能得到的最大包装尺寸。我们看到,大数据上的AVX2代码比Pico解析器快得多。但是,它在小数据上的运行速度较慢,因为AVX2中的指令量较大。
我们将所有字符检查到ASCII表中的空格,所有字符都大于128,并取其间的范围。简单的代码很快。比较PCMESTRI和AVX2。对我们来说,当前的限制是1500。这是我们所能得到的最大包装尺寸。我们看到,大数据上的AVX2代码比Pico解析器快得多。但是,它在小数据上的运行速度较慢,因为AVX2中的指令量较大。 可比
可比strspn。如果我们决定使用strspn,情况会变得更糟,尤其是在大数据上。在“战斗”解析器中不能使用strspn。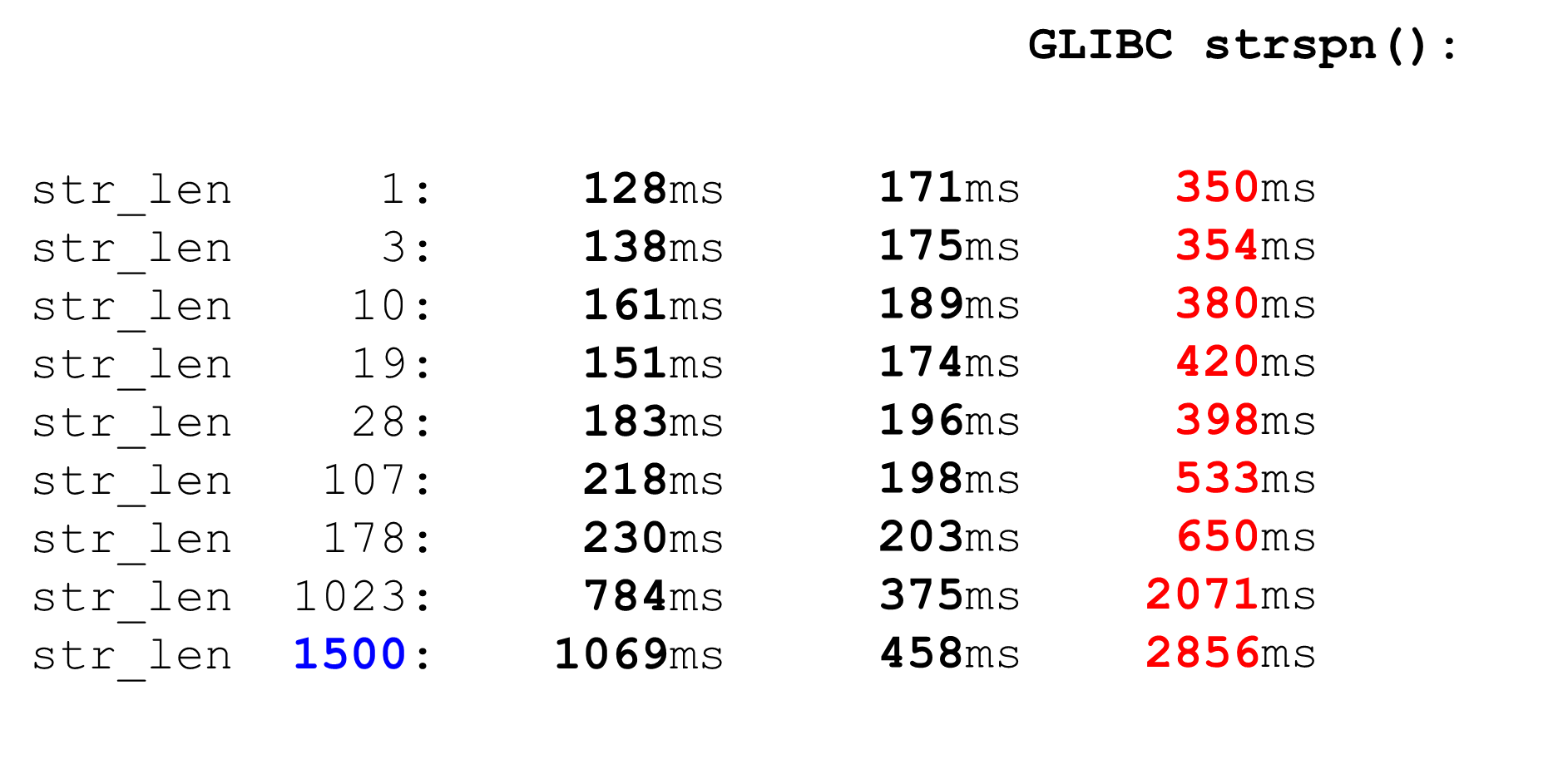
Tempesta匹配器更快,更准确
我们的速度解析器就像这两个。在小数据上,它与Pico解析器一样快,在大数据上(如CloudFlare)。但是,它不会跳过无效字符。 解析器如何安排?我们作为nginx定义了一个字节数组,并通过它检查输入数据-这是该函数的序言。在这里,我们只使用短期术语,我们使用
解析器如何安排?我们作为nginx定义了一个字节数组,并通过它检查输入数据-这是该函数的序言。在这里,我们只使用短期术语,我们使用likely它是因为分支错误预测对于短行比对长行更痛苦。我们处理这段代码。由于最后一行,我们限制为4-我们必须编写一个相当强大的条件。如果我们处理4个以上的字节,则条件会更难,代码也会更慢。static const unsigned char uri_a[] __attribute__((aligned(64))) = {
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
...
if (likely(len <= 4)) {
switch (len) {
case 0:
return 0;
case 4:
c3 = uri_a[s[3]];
case 3:
c2 = uri_a[s[2]];
case 2:
c1 = uri_a[s[1]];
case 1:
c0 = uri_a[s[0]];
}
return (c0 & c1) == 0 ? c0 : 2 + (c2 ? c2 + c3 : 0);
}
主循环和大尾巴。在主要处理周期中,我们对数据进行划分:如果数据足够长,则每个处理128、64、32或16个字节。每个处理128个是有意义的:并行地,我们使用几个处理器通道(几个流水线)和一个超标量处理器。for ( ; unlikely(s + 128 <= end); s += 128) {
n = match_symbols_mask128_c(__C.URI_BM, s);
if (n < 128)
return s - (unsigned char *)str + n;
}
if (unlikely(s + 64 <= end)) {
n = match_symbols_mask64_c(__C.URI_BM, s);
if (n < 64)
return s - (unsigned char *)str + n;
s += 64;
}
if (unlikely(s + 32 <= end)) {
n = match_symbols_mask32_c(__C.URI_BM, s);
if (n < 32)
return s - (unsigned char *)str + n;
s += 32;
}
if (unlikely(s + 16 <= end)) {
n = match_symbols_mask16_c(__C.URI_BM128, s);
if (n < 16)
return s - (unsigned char *)str + n;
s += 16;
}
尾巴。函数的结尾类似于开头。如果少于16个字节,则循环处理4个字节,最后不超过3个字节。while (s + 4 <= end) {
c0 = uri_a[s[0]];
c1 = uri_a[s[1]];
c2 = uri_a[s[2]];
c3 = uri_a[s[3]];
if (!(c0 & c1 & c2 & c3)) {
n = s - (unsigned char *)str;
return !(c0 & c1) ? n + c0 : n + 2 + (c2 ? c2 + c3 : 0);
}
s += 4;
}
c0 = c1 = c2 = 0;
switch (end - s) {
case 3:
c2 = uri_a[s[2]];
case 2:
c1 = uri_a[s[1]];
case 1:
c0 = uri_a[s[0]];
}
n = s - (unsigned char *)str;
return !(c0 & c1) ? n + c0 : n + 2 + c2;
我们加载位掩码和数据-这是函数主体的主要算法。我们展示了一个16行8列的ASCII表(如图所示)。首先,我们将表行编码在BM URI的第一个寄存器中:第一行和第二行。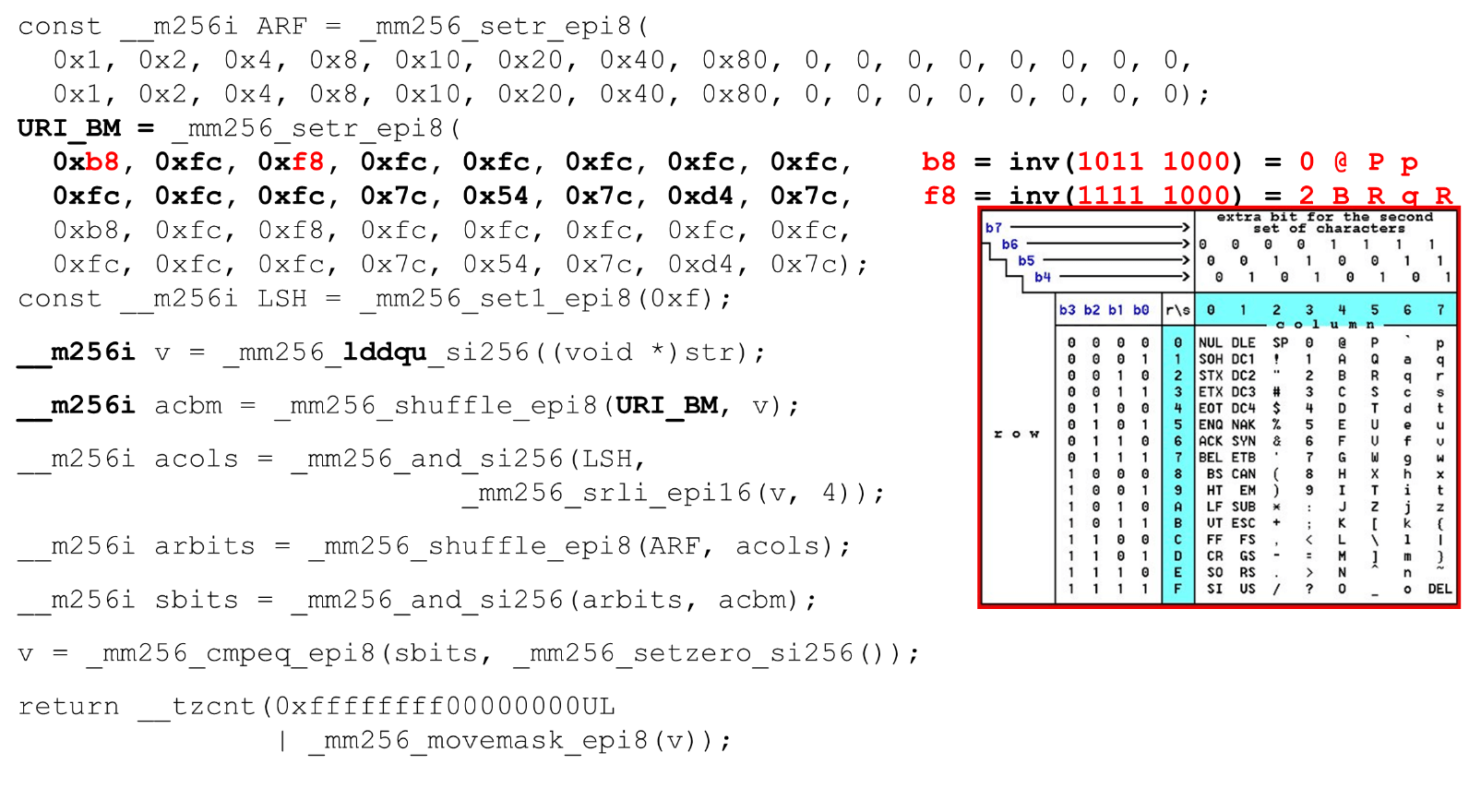 我们允许的实际符号是
我们允许的实际符号是0 @ P p和2 B R q R。它们的编码如下:b8 = inv(1011 1000) = 0 @ P p,f8 = inv(1111 1000) = 2 B R q R。我们以相反的顺序编码:我们从0开始,不允许使用第一个服务字符,然后允许使用单位。设置ASCII位掩码。例如,输入一行"pr":第一行的第一个字符为ASCII,第二行的第二个字符。我们运行shuffle语句,该语句根据输入中这些字符的顺序对编码的表行进行混洗。 输入的列ID。接下来,我们将ASCII表的列放在另一个寄存器中。然后我们“交叉”列和行的寄存器,并得到一个对应关系:我们的字符与否。由于列是字节后的最高4位,因此我们向左移动。 AVX的偏移量仅为2个字节,因此首先将其移位,然后再加上我们的掩码n即可得到有效位。
输入的列ID。接下来,我们将ASCII表的列放在另一个寄存器中。然后我们“交叉”列和行的寄存器,并得到一个对应关系:我们的字符与否。由于列是字节后的最高4位,因此我们向左移动。 AVX的偏移量仅为2个字节,因此首先将其移位,然后再加上我们的掩码n即可得到有效位。 排列ASCII列运行第二次混洗,将色谱柱移至所需位置。在这两种情况下,输入字节均来自最后一列,因此在第一和第二位置,我们获得同一列。
排列ASCII列运行第二次混洗,将色谱柱移至所需位置。在这两种情况下,输入字节均来自最后一列,因此在第一和第二位置,我们获得同一列。 蒙版的列和行的交点。我们这样做
蒙版的列和行的交点。我们这样做and(将“列”与“列”交叉),并得到输入数据有效-结果and从列和行的交点开始不为零。 计算最后的零数。我们从向量中收集所有数据
计算最后的零数。我们从向量中收集所有数据int并将其返回到输出-非常简单。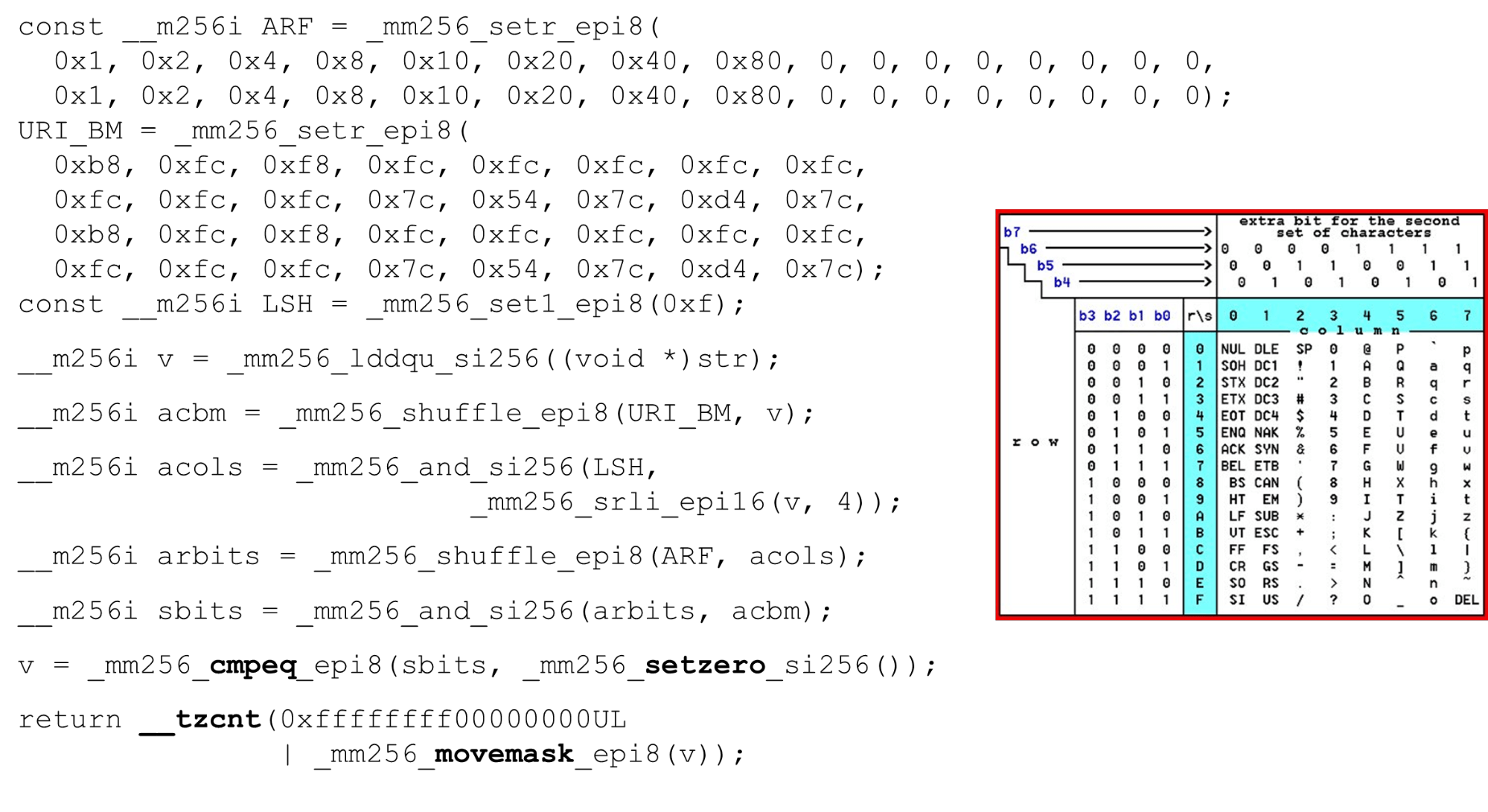 自定义字母。使用ASCII表,我们得到了一个便宜的功能:我们使用静态表,但是没有什么可以阻止我们询问用户哪些字母可用于不同标头的URI,名称和值。HTTP URI请求和标头使用8个字母(正负)来解析一个HTTP请求。可以将这些表加载到相同的代码中,并在用户指定的单个字母(有效URI)中进行比较。如果没有,那就不一样了。
自定义字母。使用ASCII表,我们得到了一个便宜的功能:我们使用静态表,但是没有什么可以阻止我们询问用户哪些字母可用于不同标头的URI,名称和值。HTTP URI请求和标头使用8个字母(正负)来解析一个HTTP请求。可以将这些表加载到相同的代码中,并在用户指定的单个字母(有效URI)中进行比较。如果没有,那就不一样了。进攻
少数情况下可能有用。BlackHat'17(“ SSRF的新时代”)对SSRF的攻击:http://foo@evil.com:80@google.com/-一个不太可能的“&”符号。在某些应用程序中使用它,在某些应用程序中不使用它。但是,如果您不使用它,则可以将其从有效字母中排除,从而阻止攻击。RCE攻击: “有效的是执行命令注入攻击,如”,BSides'16 :User-Agent: ...;echo NAELBD$((26+58))$echo(echo NAELBD)NAELBD...。User-Agent是静态标头,但是在某些情况下,shellUser-Agent带有非典型字符时会发生RCE攻击。我们保护自己,除了美元符号。相对路径覆盖。最后一种情况是Google在2016年的情况。大括号,冒号,来到了URI .../gallery?q=%0a{}*{background:red}/..//apis/howto_guide.html。这些不太可能的字符可以从字母表中排除。strcasecmp()
这是一个相当琐碎的代码。我们还比较了32个字节的字符串,每个字符串两个。__m256i CASE = _mm256_set1_epi8(0x20);
__m256i A = _mm256_set1_epi8('A' – 0x80);
__m256i D = _mm256_set1_epi8('Z' - 'A' + 1 – 0x80);
__m256i sub = _mm256_sub_epi8(str1, A);
__m256i cmp_r = _mm256_cmpgt_epi8(D, sub);
__m256i lc = _mm256_and_si256(cmp_r, CASE);
__m256i vl = _mm256_or_si256(str1, lc);
__m256i eq = _mm256_cmpeq_epi8(vl, str2);
return ~_mm256_movemask_epi8(eq);
我们只给寄存器一行,因为在第二行中,我们在解析器中将常量编程为小写。由于我们进行了大量比较,因此从每个字节中减去128(这是Hacker's Delight的技巧)。我们还比较了一个有效字符的范围:是否可以注册该字符串,是否是字母。在检查这一点时,我们只能使用一个比较(Hacker's Delight的技巧),而不是从a到z进行两次比较,并移至一个常数。性能strcasecmp()
Tempesta比GLIBC快得多,甚至是新版本(18或19)。该代码strcasecmp()还使用AVX,但不使用第二个版本。AVX2更快,因此Tempesta的代码更快。
Linux内核FPU
我们使用矢量处理器扩展 -它们在内核中可用。向量指令由FPU处理器模块处理。这不是主处理器模块,也不是主寄存器,但是非常庞大。因此,Linux中存在优化。如果我们从内核转到用户空间然后再返回,则不会保存FPU寄存器(XMM,YMM,ZMM)的上下文:我们仅更改主处理器模块的寄存器的上下文。假定OS内核不适用于处理器的矢量扩展。但是,例如,如果您需要加密,则可以做到这一点,但是需要使用fpu_begin以及fpu_end保存和恢复FPU寄存器的上下文:__kernel_fpu_begin_bh();
memcpy_avx(dst, src, n);
__kernel_fpu_end_bh();
这些是本机宏,用于保存和恢复处理器模块的状态,该模块负责向量寄存器。这些是相当慢的资源。AVX和SSE
在保存和恢复FPU上下文的基准测试之前,有关于向量操作的几句话。为什么有时使用汇编程序有意义?有时,GCC会生成次优代码。问题在于,在较旧的处理器型号上,从SSE过渡到AVX会有很大的损失。GCC有一个新密钥vzeroupper-使用它不会产生此指令vzeroupper,从而清除寄存器并消除此代价。仅当您使用由某些第三方为SSE编译的旧代码时,才需要使用此说明。这不是我们的情况,我们可以放心地删除这些说明。FPU
我们在处理器中具有自动矢量化功能。这意味着在任何用户空间代码中都会有向量运算。 系统中的任何两个进程都使用矢量处理器扩展。当您的进程进入内核并返回时,您不会浪费时间来节省和恢复处理器的向量状态。但是,如果您从一个用户空间切换到另一个用户空间(上下文切换),则除了在那里禁用了一级缓存的事实外,FPU开始/结束上的上下文切换模块也无法正常工作。该操作相当昂贵-一个微基准测试。在微基准测试中,一切总是很戏剧性的,但是操作非常昂贵。因此,在用户空间中,长时间切换上下文。在内核中,我们没有上下文切换,因此一切都很快。对于足够大的一组软件包,我们只保存和恢复矢量处理器一次。
系统中的任何两个进程都使用矢量处理器扩展。当您的进程进入内核并返回时,您不会浪费时间来节省和恢复处理器的向量状态。但是,如果您从一个用户空间切换到另一个用户空间(上下文切换),则除了在那里禁用了一级缓存的事实外,FPU开始/结束上的上下文切换模块也无法正常工作。该操作相当昂贵-一个微基准测试。在微基准测试中,一切总是很戏剧性的,但是操作非常昂贵。因此,在用户空间中,长时间切换上下文。在内核中,我们没有上下文切换,因此一切都很快。对于足够大的一组软件包,我们只保存和恢复矢量处理器一次。智力世界
在开始时,我展示了一个用于优化开关代码的查找表选项:一个漫长的过程,枚举,将开关表编译成一个数组,然后对跳过该数组的指针进行双重解引用。这是利用推测执行的Spectre攻击的场景。Google 撰写了一篇很好的文章,介绍了从2018年初开始如何安排现代编译器中的指针双重取消引用。它不能很好地工作。如果在寄存器的较早位置存储了一个地址,然后我们转到了该地址,那么现在我们有了另一个代码。jmp *%r11
call l1
l0: pause
lfence
jmp l0
l1: mov %r11, (%rsp)
ret
它是如何工作的?我们在l1上“调用”该函数,过程转到该标签,然后进行破解:就好像我们从某个函数返回(不是)一样,但是我们重写了返回地址。当执行该指令时call,我们将返回地址,当前地址放在堆栈上,并用寄存器的必要内容重写它,然后转到l1。但是,当处理器运行其预取器时,它会看到有一个功能,然后是一个障碍。因此,一切都会变慢-排除了预取,我们摆脱了Spectre漏洞。代码很慢,性能下降了15%。下一个相对较新的攻击是Meltdown。。它仅特定于用户空间进程。从用户空间读取内核内存非常痛苦。内核主控表隔离(KPTI)阻止了该攻击,该内核默认情况下会在新内核中进行编译。但是KPTI非常昂贵,性能下降高达30-40%(由MariaDB衡量)。这是由于您不再具有惰性TLB优化:内核和处理器的地址空间在不同的页表中完全分开(之前,惰性TLB一直将内核空间映射到每个进程的页表)。这对于用户空间是很痛苦的,但对于Tempesta FW则不是很痛苦,后者完全在内核中工作。一些有用的链接:Saint HighLoad++ . , 6 -- ( , Saint HighLoad++) , web .
PHP Russia: 13 , . — KnowledgeConf, ++ TechLead Conf — . , , .