哈Ha!我想告诉您我们如何编写和实现一项用于监视数据质量的服务。我们有许多数据来源:来自金融市场的数据,客户的交易活动,报价等等。所有这些每天在我们的流程中产生数十亿条记录。贸易数据的完整性和一致性是Exness业务的重要组成部分。如果您临近数据质量保证问题,并且对我们如何在家解决此问题感兴趣,那么欢迎您。 我叫Dmitry,我在一个团队中工作,该团队存储原始数据以及所有处理后的数据的转换,聚合和提供给公司所有部门。我们的数据被公司中的许多团队使用,例如商业智能,反欺诈,财务,并且我们还将其提供给我们的b2b合作伙伴。处理数据是一项负责任且艰巨的任务,因为停止一个ETL流程可能导致Exness业务的一部分瘫痪。 为了解决ETL问题,我们使用多种工具:
我叫Dmitry,我在一个团队中工作,该团队存储原始数据以及所有处理后的数据的转换,聚合和提供给公司所有部门。我们的数据被公司中的许多团队使用,例如商业智能,反欺诈,财务,并且我们还将其提供给我们的b2b合作伙伴。处理数据是一项负责任且艰巨的任务,因为停止一个ETL流程可能导致Exness业务的一部分瘫痪。 为了解决ETL问题,我们使用多种工具: 我们每天面临的挑战:
我们每天面临的挑战:- 每天有数千万笔交易记录;
- 每天有十亿个市场进入(报价等);
- 数据源的异质性(例如市场数据的外部源,不同的交易平台);
- 为重要数据(金融交易)仅提供一次语义;
- 确保数据的完整性和完整性;
- 提供保证,在规定的时间内将事务添加到所有必要的表和汇总中。
为了提供这样的保证,有必要学习如何跟踪,测量和主动应对数据质量的偏差。鉴于我们的数据收集和处理流程的复杂性,以及ETL流程的开发和修改的高速化,有必要在最后时刻监视数据质量。我们通常有一个Clickhouse或PostgreSQL数据库。这些指标将告诉我们我们的流程完成的速度:SELECT server,
avg(updated - close_time)
FROM trades
WHERE close_time > subtractHours(Now(), 2)
GROUP BY server
它们将帮助查找数据中的重复项(Clickhouse中没有唯一的约束):SELECT SUM(count) FROM (
SELECT
COUNT(*) AS count
FROM trades
GROUP BY order_id
HAVING count > 1
)
您可以提出大量查询(我们已经使用了许多查询)来帮助监视数据质量:比较源表和目标表中的行数,表中最后一次插入的时间,比较两个查询的内容等等。指标是症状。它们本身并不能指示问题的原因,但可以让我们证明存在问题。这将触发工程师注意问题并找出根本原因。打个比方:如果一个人有温度,则说明他的身体已经破裂。温度是足以开始理解并查找故障原因的症状。我们正在寻找可以为我们收集此类症状指标的现成解决方案。我们的要求:- 支持各种数据源(数据库,队列,http请求);
- ;
- ( , );
- .
在本文的开头,我列出了我们在ETL中使用的技术。如您所见,我们是开源解决方案的支持者!一个例子:我们使用面向列的Clickhouse数据库作为主要数据仓库。我们的团队多次对Clickhouse源代码进行了更改(主要是修复错误)。作为使用指标和时间序列的工具,我们使用:生态系统influxdb,普罗米修斯和维多利亚指标,zabbix。令我们惊讶的是,事实证明,没有适合我们选择的技术的现成且方便的工具来监视数据质量。还是我们看起来不好?是的,zabbix能够运行自定义脚本和telegraf您可以教授如何运行SQL查询并将其结果转换为指标。但是,这需要认真完成,并且无法按照我们想要的方式进行。因此,我们编写了自己的服务(守护程序)以监视数据质量。见神经!神经功能
在意识形态上,神经可以用以下短语来描述:该服务运行计划的,异构的,自定义的任务以收集数值,并将结果显示为不同度量标准收集系统的度量标准。
该计划的主要特点:- 支持不同类型的任务:查询,比较查询等;
- 能够使用Python作为运行时插件编写您的任务类型;
- 使用不同类型的资源:Clickhouse,Postgres等;
- 像普罗米修斯一样对数据指标进行建模
metric_name{label="value"} 123.3;
- pull prometheus;
- : crontab-style;
- WEB UI ;
- yaml ;
- Twelve-Factor App.
任务和资源是配置和使用神经的基本实体。任务-一种类型化的定期动作,作为结果,我们获得指标。资源-一个对象,其中包含用于处理特定数据源的特定配置和逻辑。让我们看一个例子如何神经。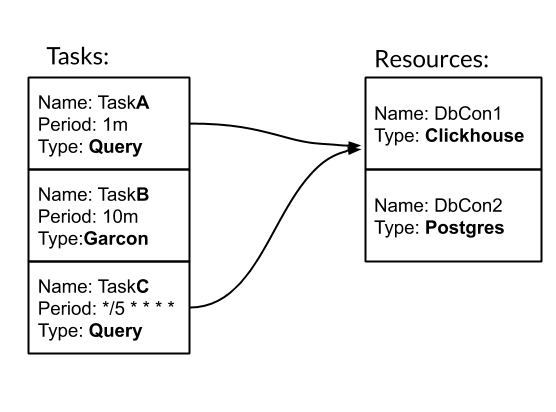 我们有三个任务。其中两个的类型为Query-SQL查询。一个是Garcon类型的-这是一项自定义任务,属于我们的一项服务。任务的频率可以按时间段设置。例如,10m表示每十分钟一次。或crontab样式的“ * / 5 * * * *”-每五分之一分钟。任务TaskA和TaskC与DbCon1资源相关联,该资源的类型为Clickhouse。让我们看看配置的外观:
我们有三个任务。其中两个的类型为Query-SQL查询。一个是Garcon类型的-这是一项自定义任务,属于我们的一项服务。任务的频率可以按时间段设置。例如,10m表示每十分钟一次。或crontab样式的“ * / 5 * * * *”-每五分之一分钟。任务TaskA和TaskC与DbCon1资源相关联,该资源的类型为Clickhouse。让我们看看配置的外观:tasks:
- name: TaskA
type: Query
resources: DbCon1
period: 1m
config:
query: SELECT COUNT(*) FROM ticks
gauge: metric_count{table="ticks"}
- name: TaskB
type: Garcon
period: 10m
config:
url: "http://hostname:9003/api/v1/orders/backups/"
gauge: backup_ago
- name: TaskC
type: Query
period: "*/5 * * * *"
resources: DbCon1
config:
query: SELECT now() - toDateTime(time_msc/1000)
FROM deals WHERE trade_server= 'Real'
ORDER BY deal DESC LIMIT 1
gauge: orders_lag
resources:
- name: DbCon1
type: Clickhouse
config:
host: clickhouse.env
port: 9000
user: readonly
password: "***"
database: data
results:
common_labels:
env="prod"
task_types_paths:
- "./tasks"
“ ./tasks”路径是定制任务的路径。特别是,在那里定义了Garcon任务类型。在本文中,我将省略创建任务类型的时间。通过这样的配置启动神经服务的结果是,可以在WEB UI中监视任务的执行方式: 并且在/ metrics中可以使用收集度量标准:
并且在/ metrics中可以使用收集度量标准: 查询我们团队中最常用的任务类型。因此,我们扩展了其使用GROUP BY和模板的功能。这些机制使一次收集一个请求就可以收集有关数据的大量信息:
查询我们团队中最常用的任务类型。因此,我们扩展了其使用GROUP BY和模板的功能。这些机制使一次收集一个请求就可以收集有关数据的大量信息: TradesLag任务将收集每台交易服务器每五分钟将关闭的订单进入交易表的最大延迟,同时仅考虑最近两个小时内关闭的订单。关于实现的几句话。Nerve是一个多线程python3〜3k LoC应用程序,可轻松通过Docker运行,并通过任务配置对其进行补充。
TradesLag任务将收集每台交易服务器每五分钟将关闭的订单进入交易表的最大延迟,同时仅考虑最近两个小时内关闭的订单。关于实现的几句话。Nerve是一个多线程python3〜3k LoC应用程序,可轻松通过Docker运行,并通过任务配置对其进行补充。发生了什么
有了勇气,我们得到了想要的东西。目前,除了我们的团队以外,Exness中的其他团队也对他表现出了兴趣。它以每天30秒的频率旋转约40个任务。Nerve收集了约500个有关我们数据的指标。添加新指标大约需要5-10分钟。使用指标的全部流程如下所示:神经→普罗米修斯→Victoria Metrics→Grafana仪表板→PagerDuty中的警报。我们也很紧张地开始收集业务指标:我们定期选择交易系统中的原始事件以评估交易条件。哈勃罗夫斯克公民,谢谢您阅读我的文章。我预见到您的问题:github的链接在哪里?答案是这样的:我们还没有在开放源代码方面发表过神经。这需要我们做更多的工作来改进文档并完成几个功能。如果这篇文章受到社区的欢迎,这将使我们有更多的动力与您分享我们的发展!对所有人都好!