金丝雀是只不断唱歌的小鸟。这些鸟类对甲烷和一氧化碳敏感。即使空气中少量的过量气体,它们也会失去知觉或死亡。黄金矿工和矿工把鸟当做猎物:金丝雀在唱歌的时候,你可以工作,如果你闭嘴,矿里有瓦斯,该离开了。矿工们牺牲了一只小鸟,以便活着脱出地雷。 在IT中也发现了类似的做法。例如,在将新版本的服务或应用程序部署到生产中并在此之前进行测试的标准任务中。测试环境可能过于昂贵,自动化测试无法涵盖我们想要的所有内容,并且存在测试和牺牲质量的风险。正是在这种情况下,当在新版本上启动了一些实际生产流量时,Canary Deployment方法会有所帮助。该方法有助于安全地测试新版本的生产,以牺牲小事情为大目标。更详细地讲,该方法的工作原理,有用的方法以及如何实施,将告诉Andrey Markelov(安德烈(Andrey_V_Markelov)),并使用Infobip上的实现示例。Infobip的首席软件工程师Andrey Markelov从事金融和电信领域的Java应用程序开发已有11年了。他开发开源产品,积极参与Atlassian社区,并为Atlassian产品编写插件。传教士Prometheus,Docker和Redis。
在IT中也发现了类似的做法。例如,在将新版本的服务或应用程序部署到生产中并在此之前进行测试的标准任务中。测试环境可能过于昂贵,自动化测试无法涵盖我们想要的所有内容,并且存在测试和牺牲质量的风险。正是在这种情况下,当在新版本上启动了一些实际生产流量时,Canary Deployment方法会有所帮助。该方法有助于安全地测试新版本的生产,以牺牲小事情为大目标。更详细地讲,该方法的工作原理,有用的方法以及如何实施,将告诉Andrey Markelov(安德烈(Andrey_V_Markelov)),并使用Infobip上的实现示例。Infobip的首席软件工程师Andrey Markelov从事金融和电信领域的Java应用程序开发已有11年了。他开发开源产品,积极参与Atlassian社区,并为Atlassian产品编写插件。传教士Prometheus,Docker和Redis。关于Infobip
这是一个全球电信平台,使银行,零售商,在线商店和运输公司可以使用SMS,推送,信件和语音消息向其客户发送消息。在这样的业务中,稳定性和可靠性很重要,这样客户才能及时收到消息。Infobip IT基础架构的数量:- 全球15个数据中心;
- 提供500种独特的服务;
- 2500个服务实例,远远超过团队;
- 每月流量4.5 TB;
- 45亿个电话号码;
业务在增长,发布的数量也在增加。我们每天要发布60个版本,因为客户需要更多功能。但这很难-有很多服务,但团队很少。您必须快速编写可以在生产环境中正常运行的代码。发布
与我们一起发布的典型版本如下。例如,有服务A,B,C,D和E,每个服务都是由独立的团队开发的。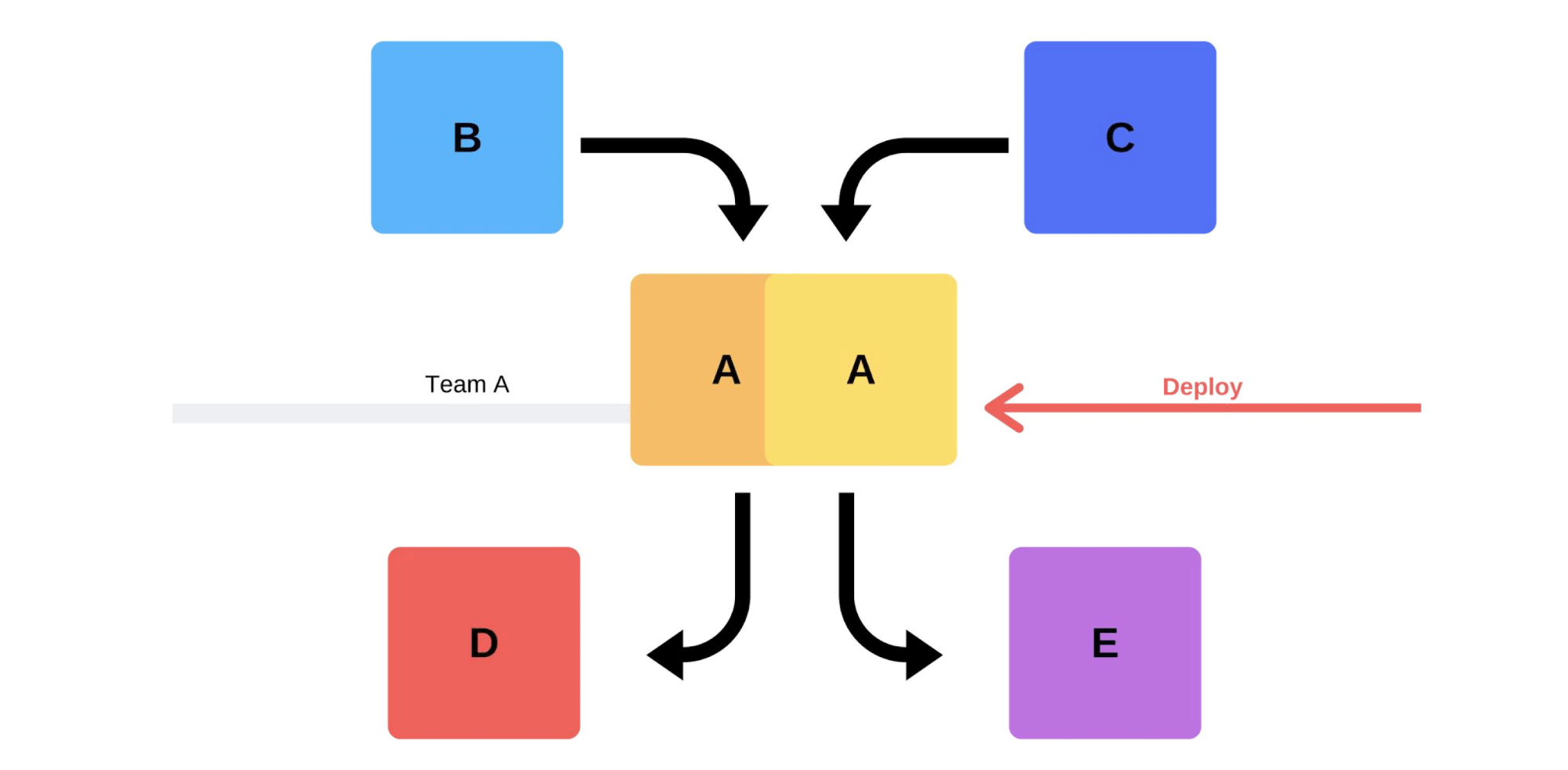 在某个时候,服务团队A决定部署新版本,但是服务团队B,C,D和E不知道这一点。服务团队A的到达方式有两种。将执行增量发行:首先它将替换一个版本,然后是第二个版本。
在某个时候,服务团队A决定部署新版本,但是服务团队B,C,D和E不知道这一点。服务团队A的到达方式有两种。将执行增量发行:首先它将替换一个版本,然后是第二个版本。 但是还有第二种选择:团队将找到更多的容量和机器,部署新版本,然后切换路由器,该版本将开始在生产中使用。
但是还有第二种选择:团队将找到更多的容量和机器,部署新版本,然后切换路由器,该版本将开始在生产中使用。 无论如何,即使测试了版本,部署后几乎总是会有问题。您可以用手对其进行测试,可以自动化,也不能测试-在任何情况下都会出现问题。解决这些问题的最简单,最正确的方法是回滚到工作版本。只有这样,您才能处理损坏,原因并加以纠正。那我们想要什么?我们不需要问题。如果客户发现它们的速度比我们快,那么它将损害我们的声誉。因此,我们必须比客户更快地发现问题。通过积极主动,我们将损失降到最低。同时,我们要加快部署这样就可以快速,轻松地单独进行,而无需团队的压力。工程师,DevOps工程师和程序员必须受到保护-新版本的发布压力很大。团队不是消耗品;我们努力合理地利用人力资源。
无论如何,即使测试了版本,部署后几乎总是会有问题。您可以用手对其进行测试,可以自动化,也不能测试-在任何情况下都会出现问题。解决这些问题的最简单,最正确的方法是回滚到工作版本。只有这样,您才能处理损坏,原因并加以纠正。那我们想要什么?我们不需要问题。如果客户发现它们的速度比我们快,那么它将损害我们的声誉。因此,我们必须比客户更快地发现问题。通过积极主动,我们将损失降到最低。同时,我们要加快部署这样就可以快速,轻松地单独进行,而无需团队的压力。工程师,DevOps工程师和程序员必须受到保护-新版本的发布压力很大。团队不是消耗品;我们努力合理地利用人力资源。部署问题
客户端流量不可预测。无法预测什么时候客户端流量会最小。我们不知道客户何时何地开始他们的广告系列-也许是今晚在印度,明天是在香港。由于时差较大,即使在凌晨2点进行部署也无法保证客户不会受到影响。提供程序问题。信使和提供者是我们的合作伙伴。有时它们会因崩溃而导致在部署新版本时出错。分布式团队。开发客户端和后端的团队位于不同的时区。因此,他们之间常常无法达成共识。数据中心不能在舞台上重复。一个数据中心中有200个机架-在沙箱中重复此操作甚至无法解决。不允许停机!例如,当我们99.99%的时间工作时,我们就具有可接受的可访问性级别(错误预算),其余百分比是“犯错的权利”。不可能达到100%的可靠性,但是持续监视停机时间和停机时间很重要。经典解决方案
编写没有错误的代码。当我还是一个年轻的开发人员时,经理与我联系,要求发布没有错误的版本,但这并不总是可能的。编写测试。测试有效,但有时根本不是企业想要的。赚钱不是测试任务。在舞台上测试。在Infobip工作的3.5年中,我从未见过至少与生产部分重合的舞台状态。 我们甚至尝试提出这个想法:首先,我们有一个阶段,然后是预生产,然后是预生产预生产。但这也无济于事-他们甚至在权力方面也不一致。有了Stage,我们可以保证基本的功能,但是我们不知道它在负载下如何工作。该版本由开发人员制作。这是一个好习惯:即使有人更改了评论的名称,它也会立即将其添加到生产中。这有助于培养责任感,而不是忘记所做的更改。还有其他困难。对于开发人员而言,这很麻烦-花大量时间手动检查所有内容。商定发行版本。此选项通常提供管理功能:“让我们同意您每天都会测试并添加新版本。” 这是行不通的:总会有一个团队在等待其他人,反之亦然。
我们甚至尝试提出这个想法:首先,我们有一个阶段,然后是预生产,然后是预生产预生产。但这也无济于事-他们甚至在权力方面也不一致。有了Stage,我们可以保证基本的功能,但是我们不知道它在负载下如何工作。该版本由开发人员制作。这是一个好习惯:即使有人更改了评论的名称,它也会立即将其添加到生产中。这有助于培养责任感,而不是忘记所做的更改。还有其他困难。对于开发人员而言,这很麻烦-花大量时间手动检查所有内容。商定发行版本。此选项通常提供管理功能:“让我们同意您每天都会测试并添加新版本。” 这是行不通的:总会有一个团队在等待其他人,反之亦然。烟雾测试
解决部署问题的另一种方法。让我们看看在上一个示例中,当团队A要部署新版本时,烟雾测试如何工作。首先,团队将一个实例部署到生产中。从模拟到实例的消息模拟实际流量,使其与正常的每日流量匹配。如果一切顺利,该团队将新版本切换为用户流量。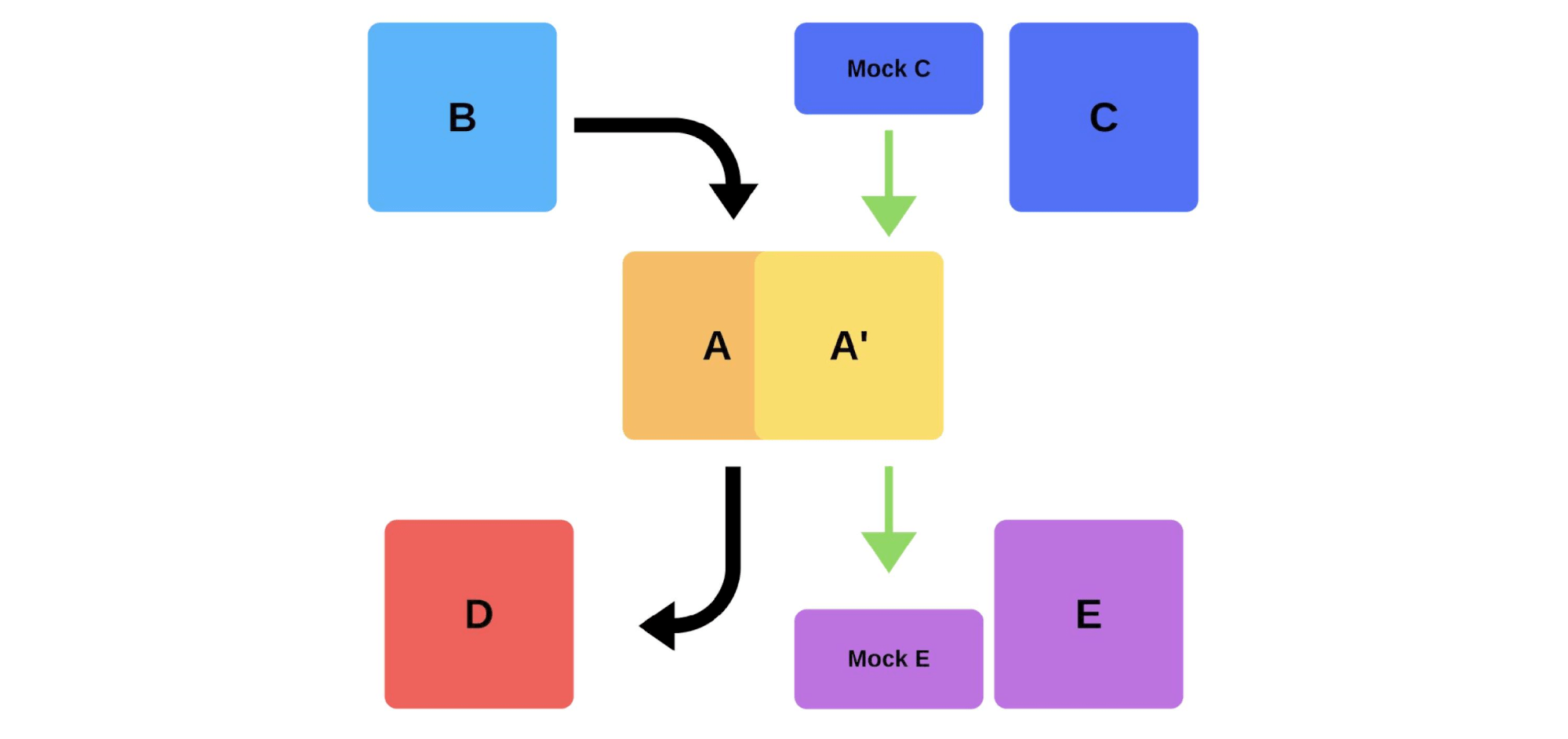 第二种选择是部署额外的铁。团队对其进行生产测试,然后进行切换,一切正常。
第二种选择是部署额外的铁。团队对其进行生产测试,然后进行切换,一切正常。 烟雾测试的缺点:
烟雾测试的缺点:- 测试不能被信任。在哪里获得与生产相同的流量?您可以使用昨天或一周前的日期,但并不总是与当前日期一致。
- 很难维护。当活动记录发送到存储库时,您将必须支持测试帐户,并在每次部署之前不断重置它们。这比在沙箱中编写测试要难。
这里唯一的好处是您可以检查性能。金丝雀发布
由于冒烟测试的缺陷,我们开始使用金丝雀释放。这种做法类似于矿工使用金丝雀指示IT中发现的瓦斯水平的方式。我们正在努力争取新版本的实际生产量,同时努力满足服务水平协议(SLA)。SLA是我们的“犯错的权利”,我们可以每年使用一次(或其他一段时间)。如果一切顺利,请增加流量。如果没有,我们将返回以前的版本。
实施和细微差别
我们如何实施金丝雀发布?例如,一群客户通过我们的服务发送消息。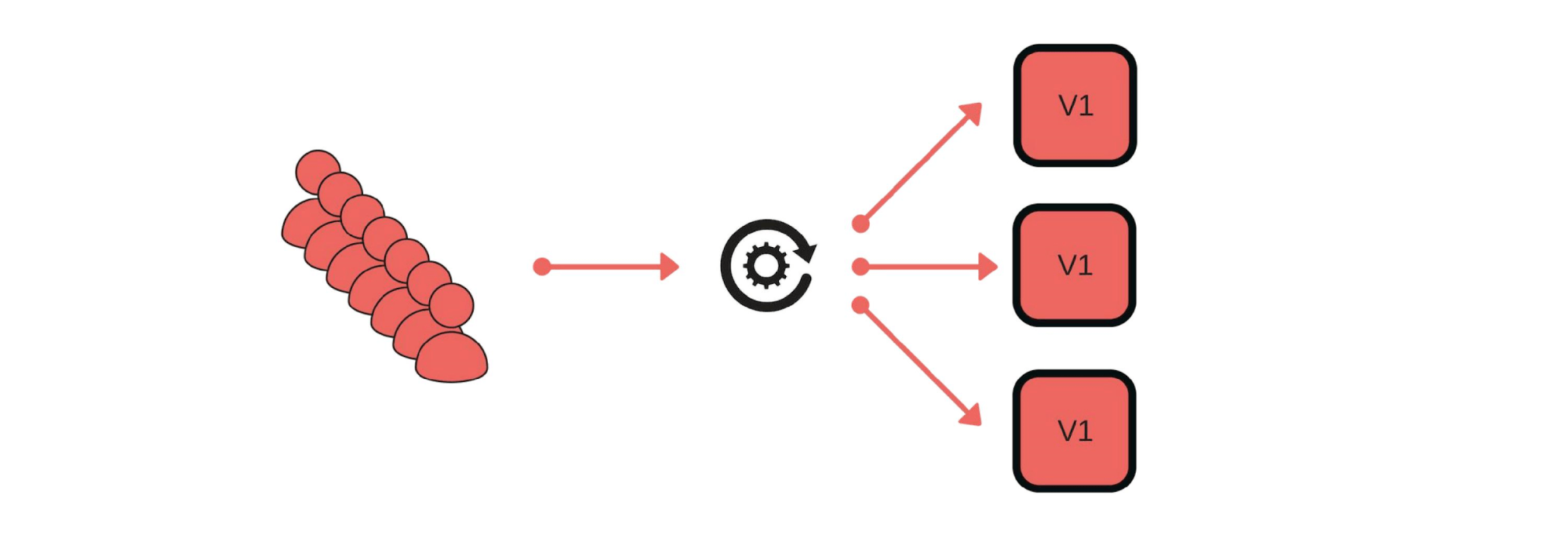 部署过程如下:从平衡器下面删除一个节点(1),更改版本(2)并分别启动一些流量(3)。
部署过程如下:从平衡器下面删除一个节点(1),更改版本(2)并分别启动一些流量(3)。 通常,即使一个用户不满意,组中的每个人也会很高兴。如果一切顺利-更改所有版本。
通常,即使一个用户不满意,组中的每个人也会很高兴。如果一切顺利-更改所有版本。 我将示意性地展示在大多数情况下它如何寻找微服务。有服务发现和另外两个服务:S1N1和S2。第一个服务(S1N1)启动时会通知服务发现,服务发现会记住它。具有两个节点(S2N1和S2N2)的第二个服务也会在启动时通知服务发现。
我将示意性地展示在大多数情况下它如何寻找微服务。有服务发现和另外两个服务:S1N1和S2。第一个服务(S1N1)启动时会通知服务发现,服务发现会记住它。具有两个节点(S2N1和S2N2)的第二个服务也会在启动时通知服务发现。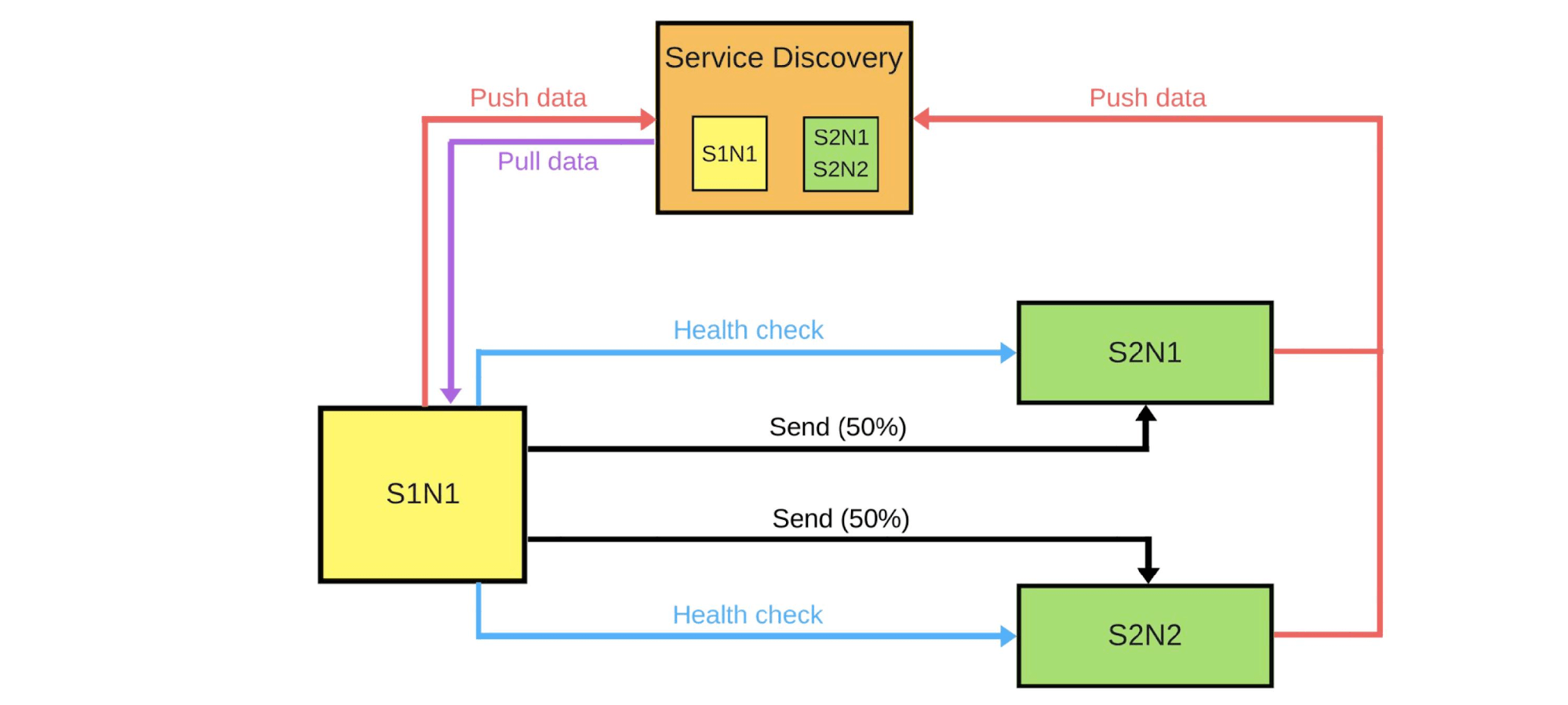 第一个服务的第二个服务充当服务器。第一个从Service Discovery请求有关其服务器的信息,并在接收到信息后搜索并检查它们(“运行状况检查”)。当他检查时,他将向他们发送消息。当某人想要部署第二个服务的新版本时,他告诉Service Discovery第二个节点将是一个金丝雀节点:由于现在将部署该节点,因此将向它发送较少的流量。我们从平衡器下方移除了金丝雀节点,并且第一个服务不会向其发送流量。
第一个服务的第二个服务充当服务器。第一个从Service Discovery请求有关其服务器的信息,并在接收到信息后搜索并检查它们(“运行状况检查”)。当他检查时,他将向他们发送消息。当某人想要部署第二个服务的新版本时,他告诉Service Discovery第二个节点将是一个金丝雀节点:由于现在将部署该节点,因此将向它发送较少的流量。我们从平衡器下方移除了金丝雀节点,并且第一个服务不会向其发送流量。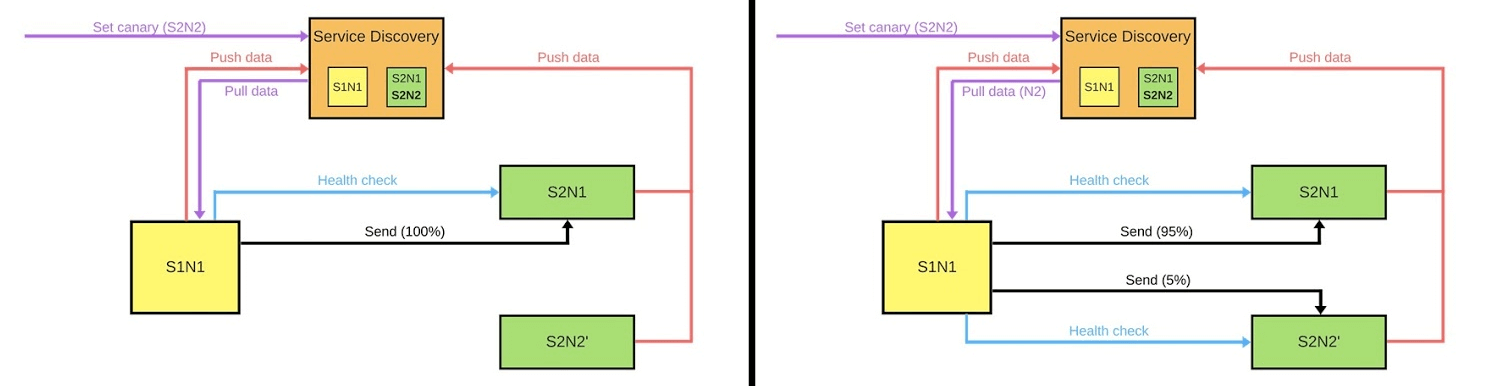 我们更改了版本,并且Service Discovery知道第二个节点现在是canary-您可以给它减少负载(5%)。如果一切正常,请更改版本,返回负载并继续操作。要实现所有这些,我们需要:
我们更改了版本,并且Service Discovery知道第二个节点现在是canary-您可以给它减少负载(5%)。如果一切正常,请更改版本,返回负载并继续操作。要实现所有这些,我们需要:- 平衡
- , , , ;
- , , ;
- — (deployment pipeline).
 这是我们应该考虑的第一件事。有两种平衡策略。最简单的选择是当一个节点始终为canary时。该节点始终获得较少的流量,因此我们开始从该节点进行部署。如果出现问题,我们将把她的工作与部署以及部署过程进行比较。例如,如果错误多出2倍,则损害增加了2倍。Canary节点是在部署过程中设置的。当部署结束并且我们从中删除了canary节点的状态时,流量平衡将恢复。随着汽车的减少,我们得到了诚实的分配。
这是我们应该考虑的第一件事。有两种平衡策略。最简单的选择是当一个节点始终为canary时。该节点始终获得较少的流量,因此我们开始从该节点进行部署。如果出现问题,我们将把她的工作与部署以及部署过程进行比较。例如,如果错误多出2倍,则损害增加了2倍。Canary节点是在部署过程中设置的。当部署结束并且我们从中删除了canary节点的状态时,流量平衡将恢复。随着汽车的减少,我们得到了诚实的分配。监控方式
金丝雀释放的基石。我们必须确切地了解为什么要这样做以及要收集哪些指标。我们从服务中收集的指标示例。- , . , . , .
- (latency). , .
- (throughput).
- .
- 95% .
- -: . , , .
最流行的监视系统中指标的示例。计数器这是一个不断增加的值,例如错误数量。插值此指标并研究图表很容易:昨天有2个错误,今天有500个错误,然后出了点问题。每分钟或每秒的错误数是可以使用Counter计算的最重要的指标。这些数据清楚地说明了远距离的系统运行情况。让我们看一下两个生产系统版本每秒的错误数量图表的示例。 第一个版本中几乎没有错误;审核可能没有用。在第二版中,一切都变得更糟。我们可以肯定地说出问题,因此我们必须回滚该版本。量规指标类似于Counter,但我们记录的值可以增加或减少。例如,查询执行时间或队列大小。该图显示了响应时间(延迟)的示例。该图显示版本相似,您可以使用它们。但是,如果仔细观察,会发现数量如何变化。如果在添加用户时请求的执行时间增加了,那么很明显存在问题-以前不是这种情况。
第一个版本中几乎没有错误;审核可能没有用。在第二版中,一切都变得更糟。我们可以肯定地说出问题,因此我们必须回滚该版本。量规指标类似于Counter,但我们记录的值可以增加或减少。例如,查询执行时间或队列大小。该图显示了响应时间(延迟)的示例。该图显示版本相似,您可以使用它们。但是,如果仔细观察,会发现数量如何变化。如果在添加用户时请求的执行时间增加了,那么很明显存在问题-以前不是这种情况。 摘要 百分位是业务最重要的指标之一。该指标表明,在95%的情况下,我们的系统都按照我们想要的方式工作。如果某处存在问题,我们可以达成协议,因为我们了解一切都好坏的普遍趋势。
摘要 百分位是业务最重要的指标之一。该指标表明,在95%的情况下,我们的系统都按照我们想要的方式工作。如果某处存在问题,我们可以达成协议,因为我们了解一切都好坏的普遍趋势。工具类
ELK堆栈。您可以使用Elasticsearch实施金丝雀-当事件发生时,我们会在其中写入错误。只需调用API,您就可以随时获取错误,并将其与以前的细分进行比较:GET /applg/_cunt?q=level:errr。普罗米修斯。他在Infobip中表现出色。由于使用了标签,它使您可以实现多维指标。我们可以使用level,instance,service,他们在一个单一的系统结合起来。使用offset它,例如,您可以使用一个命令查看一周前的值GET /api/v1/query?query={query},其中{query}:rate(logback_appender_total{
level="error",
instance=~"$instance"
}[5m] offset $offset_value)
版本分析
有几种版本控制策略。查看仅金丝雀节点的指标。最简单的选择之一:部署新版本并仅研究工作。但是,如果工程师此时开始研究日志,并不断紧张地重新加载页面,则此解决方案与其余解决方案没有什么不同。金丝雀节点与任何其他节点进行比较。这是与其他在全部流量下运行的实例的比较。例如,如果流量小的情况比实际情况更糟,或者没有比实际情况更好,则出问题了。金丝雀节点过去曾与其自身进行过比较。可以将分配给金丝雀的节点与历史数据进行比较。例如,如果一周前一切都很好,那么我们可以专注于此数据以了解当前情况。自动化
我们希望工程师免于手动比较,因此实现自动化很重要。部署管道过程通常如下所示:- 我们开始;
- 从平衡器下面移除节点;
- 设置金丝雀节点;
- 开启流量已经有限的平衡器;
- 相比。
 至此,我们实现了自动比较。它的外观以及为什么比部署后的检查要好,我们将考虑Jenkins的示例。这是通往Groovy的管道。
至此,我们实现了自动比较。它的外观以及为什么比部署后的检查要好,我们将考虑Jenkins的示例。这是通往Groovy的管道。while (System.currentTimeMillis() < endCanaryTs) {
def isOk = compare(srv, canary, time, base, offset, metrics)
if (isOk) {
sleep DEFAULT SLEEP
} else {
echo "Canary failed, need to revert"
return false
}
}
在此周期中,我们设置为将新节点比较一个小时。如果canary进程尚未完成,我们将调用该函数。她报告说,一切都很好与否:def isOk = compare(srv, canary, time, base, offset, metrics)。如果一切顺利- sleep DEFAULT SLEEP例如,持续一秒钟,然后继续。如果没有,我们退出-部署失败。指标描述。让我们看一下功能如何compare在DSL示例中显示。metric(
'errorCounts',
'rate(errorCounts{node=~"$canaryInst"}[5m] offset $offset)',
{ baseValue, canaryValue ->
if (canaryValue > baseValue * 1.3) return false
return true
}
)
假设我们比较错误数量,并想知道最近5分钟内每秒的错误数量。我们有两个值:基本节点和金丝雀节点。金丝雀节点的值是当前值。基本- baseValue是任何其他非Canary节点的值。我们根据经验和观察结果设置的公式相互比较值。如果该值不canaryValue正确,则部署失败,并且我们回滚。为什么这一切都是必要的?人无法检查成千上万的指标特别是要快点做。自动比较有助于检查所有指标并迅速向您发出问题警报。通知时间很关键:如果在最近2秒钟内发生了某些事件,则损坏不会像15分钟前那样严重。除非有人发现问题,然后写支持,否则我们可能会失去客户回滚支持。如果该过程顺利进行,并且一切正常,我们将自动部署所有其他节点。工程师目前不执行任何操作。只有当他们运行canary时,他们才决定采用哪些指标,进行多长时间的比较以及使用哪种策略。 如果存在问题,我们将自动回退canary节点,使用以前的版本并修复发现的错误。通过度量标准,很容易找到并查看新版本带来的损害。
如果存在问题,我们将自动回退canary节点,使用以前的版本并修复发现的错误。通过度量标准,很容易找到并查看新版本带来的损害。障碍物
当然,要实现这一点并不容易。首先,我们需要一个通用的监控系统。工程师有他们自己的度量标准,支持人员和分析师有不同的度量标准,而业务则有第三。通用系统是业务和开发所使用的通用语言。在实践中有必要检查指标的稳定性。验证有助于了解确保质量所需的最少一组指标。如何实现呢?部署时不要使用canary服务。我们在旧版本上添加了一项特定服务,该服务可以随时使用任何已分配的节点,减少流量而无需部署。比较之后:我们研究错误并在达到质量时寻找那条线。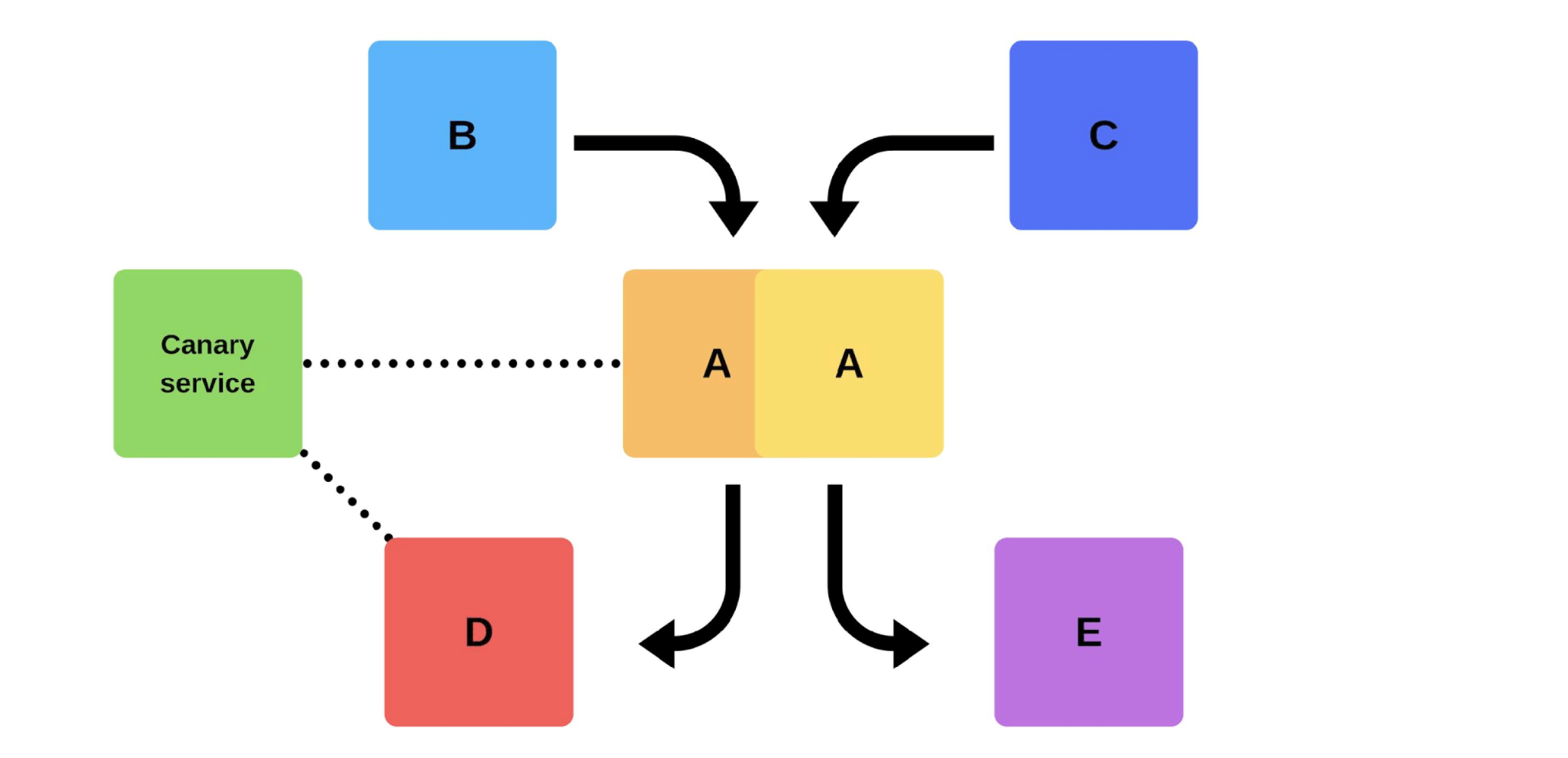
金丝雀发布给我们带来了什么好处
最大限度地减少了错误造成的损害百分比。大多数部署错误是由于某些数据或优先级不一致而发生的。这样的错误变得越来越小,因为我们可以在最初的几秒钟内解决问题。优化团队工作。初学者具有“犯错的权利”:他们可以部署到生产环境中,而不必担心犯错误,出现了额外的主动权,这是工作的动力。如果他们破坏了某些东西,那将不是关键,也不会解雇错误的人。自动化部署。这不再像以前那样是手动过程,而是真正的自动化过程。但是需要更长的时间。重要指标。整个公司(从业务和工程师开始)都了解在我们的产品中真正重要的是什么,例如度量用户的外流和流入。我们控制流程:我们测试指标,引入新指标,了解旧指标如何建立可提高收益的系统。我们有许多很酷的做法和系统可以为我们提供帮助。尽管如此,无论我们是否有能够帮助我们的系统,我们都致力于成为专业人士并有效地完成工作。— TechLead Conf. , , — .
TechLead Conf 8 9 . , , — , .